阿里推出全新推理模型(因果语言模型),仅1/20参数媲美DeepSeek R1
阿里Qwen 团队正式发布了他们最新的研究成果——QwQ-32B大语言模型!这款模型不仅名字萌萌哒(QwQ),实力更是不容小觑!😎
QwQ-32B 已在 Hugging Face 和 ModelScope 开源,采用了 Apache 2.0 开源协议。大家可通过 Qwen Chat 直接进行体验!
Qwen 团队却用320亿参数的 QwQ-32B,硬刚拥有6710亿参数的 DeepSeek-R1,并且在多项评测中取得了媲美甚至超越后者的惊人成绩!背后究竟是什么黑科技?答案就是——强化学习(Reinforcement Learning,RL)!
划重点:强化学习,大模型的新引擎!💪
Qwen 团队在博文中提到,他们深入探索了强化学习(RL)在提升大语言模型智能方面的巨大潜力。QwQ-32B 的成功发布,有力地证明了RL 是提升模型性能的强大引擎!
多项基准评测硬刚 DeepSeek-R1
官方给出基准评测结果,涵盖了数学推理、代码能力和通用问题解决等多个方面:

从数据中我们可以清晰地看到,在AIME24和IFEval等关键基准测试中,QwQ-32B 的表现甚至略微超过了参数量巨大的 DeepSeek-R1!而在其他基准测试中,也基本与 DeepSeek-R1 持平,远超其他对比模型。
这意味着 QwQ-32B 在仅有 DeepSeek-R1 约 1/20 参数量的情况下,用强化学习,实现了性能上的惊人跨越!
实例对比:我身高1.73米,拿着一根5.5米长的竹竿,能否通过高4米、宽3米的门?
这个问题目前只有腾讯元宝/问小白里的deepseek回答可以通过


技术揭秘:
冷启动+结果导向的强化学习策略
Qwen 团队在博文中也简单介绍了 QwQ-32B 背后的强化学习方法。他们采用了冷启动(cold-start checkpoint)的方式,并实施了结果导向(outcome-based rewards)的强化学习策略。
• 冷启动:从一个预训练模型的检查点开始训练。
• 结果导向:在初始阶段,主要针对数学和代码任务进行 RL 训练。
• 数学问题:使用准确率验证器(accuracy verifier)来确保答案的正确性。
• 代码生成:使用代码执行服务器(code execution server)来评估生成的代码是否能够成功运行。
• 通用奖励模型和规则验证器:后续阶段,会逐步引入更通用的奖励模型和规则验证器,提升模型在其他通用能力方面的表现。
这种策略的核心在于不依赖传统的奖励模型,而是直接根据任务结果(答案是否正确,代码是否运行成功)来指导模型的学习,更加高效和直接。
冷启动的基础上开展了大规模强化学习。在初始阶段,特别针对数学和编程任务进行了 RL 训练。与依赖传统的奖励模型(rewardmodel)不同,通过校验生成答案的正确性来为数学问题提供反馈,并通过代码执行服务器评估生成的代码是否成功通过测试用例来提供代码的反馈。随着训练轮次的推进,这两个领域中的性能均表现出持续的提升。在第一阶段的RL 过后,增加了另一个针对通用能力的 RL。此阶段使用通用奖励模型和一些基于规则的验证器进行训练。发现,通过少量步骤的通用RL,可以提升其他通用能力,同时在数学和编程任务上的性能没有显著下降。
特点:
• 类型:因果语言模型
• 训练阶段:预训练与后训练(监督微调和强化学习)
• 架构:带 RoPE、SwiGLU、RMSNorm 和注意力 QKV 偏置的 Transformer
• 参数数量:325 亿
• 非嵌入参数数量:310 亿
• 层数:64
• 注意力头数量(GQA):Q 为 40,KV 为 8
• 上下文长度:完整支持 131,072 个标记
环境要求
Qwen2.5 的代码已集成到最新版的 Hugging Facetransformers中,建议使用最新版本的transformers。
如果你使用的是transformers<4.37.0,可能会遇到以下错误:
KeyError: 'qwen2'
快速入门
API调用
from openai import OpenAI
import os# Initialize OpenAI client
client = OpenAI(# If the environment variable is not configured, replace with your API Key: api_key="sk-xxx"# How to get an API Key:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-keyapi_key=os.getenv("DASHSCOPE_API_KEY"),base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)reasoning_content = ""
content = ""is_answering = Falsecompletion = client.chat.completions.create(model="qwq-32b",messages=[{"role": "user", "content": "Which is larger, 9.9 or 9.11?"}],stream=True,# Uncomment the following line to return token usage in the last chunk# stream_options={# "include_usage": True# }
)print("\n" + "=" * 20 + "reasoning content" + "=" * 20 + "\n")for chunk in completion:# If chunk.choices is empty, print usageif not chunk.choices:print("\nUsage:")print(chunk.usage)else:delta = chunk.choices[0].delta# Print reasoning contentif hasattr(delta, 'reasoning_content') and delta.reasoning_content is not None:print(delta.reasoning_content, end='', flush=True)reasoning_content += delta.reasoning_contentelse:if delta.content != "" and is_answering is False:print("\n" + "=" * 20 + "content" + "=" * 20 + "\n")is_answering = True# Print contentprint(delta.content, end='', flush=True)content += delta.contenttransformers 本地加载
from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = "Qwen/QwQ-32B"model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)prompt = "单词 'strawberry' 中有几个字母 'r'?"
messages = [{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)generated_ids = model.generate(**model_inputs,max_new_tokens=32768
)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
使用指南
为了达到最佳性能,建议以下设置:
• 确保深思熟虑的输出:确保模型以"<think>"开头,以避免生成空洞的思考内容,这可能会降低输出质量。如果你使用apply_chat_template并设置add_generation_prompt=True,这已经自动实现,但可能会导致响应缺少开头的<think>标签。这是正常现象。
• 采样参数:
• 使用温度参数 Temperature=0.6 和 TopP=0.95,而不是贪婪解码,以避免无尽重复并增强多样性。
• 对于复杂的推理任务(如数学或编程),设置 TopK=40。
• 对于其他类型的问题,使用 TopK=20。
• 标准化输出格式:在基准测试时,建议使用提示词来标准化模型输出。
• 数学问题:在提示词中加入"请逐步推理,并将最终答案放在\boxed{}中。"
• 选择题:在提示词中加入以下 JSON 结构以标准化回答:“请在answer字段中显示你的选择,仅使用选项字母,例如,\"answer\": \"C\"。”
• 处理长输入:对于超过 32,768 个标记的输入,启用YaRN以提升模型对长序列信息的捕捉能力。
如果你需要支持的框架,可以在config.json中添加以下内容以启用 YaRN:
{...,"rope_scaling": {"factor": 4.0,"original_max_position_embeddings": 32768,"type": "yarn"}
}
目前,vLLM 仅支持静态 YaRN,这意味着缩放因子无论输入长度如何都保持不变,可能会对较短文本的性能产生影响。建议仅在需要处理长上下文时添加rope_scaling配置。
相关文章:
阿里推出全新推理模型(因果语言模型),仅1/20参数媲美DeepSeek R1
阿里Qwen 团队正式发布了他们最新的研究成果——QwQ-32B大语言模型!这款模型不仅名字萌萌哒(QwQ),实力更是不容小觑!😎 QwQ-32B 已在 Hugging Face 和 ModelScope 开源,采用了 Apache 2.0 开源协议。大家可通过 Qwen C…...
20250307学习记录
大家早上好呀,今天早上七点四十就起床了 第一部分,修改一下任务 完成 第二部分,整理MODIS数据 2023-5-30-GEE-土地覆盖处理_mcd12q1.061-CSDN博客 看完这个博客,我有了大致的思路 编写代码转换为tiff,并且将不同…...

设计模式-创建型模式详解
这里写目录标题 一、基本概念二、单例模式1. 模式特点2. 适用场景3. 实现方法4. 经典示例 三、简单工厂模式1. 模式特点2. 经典示例 四、工厂方法模式五、抽象工厂模式1. 适用场景2. 经典示例 六、建造者模式1. 模式特点2. 一般流程3. 适用场景4. 经典示例 七、原型模式 一、基…...

【蓝桥杯】每天一题,理解逻辑(2/90)【LeetCode 复写零】
闲话系列:每日一题,秃头有我,Hello!!!!!,我是IF‘Maxue,欢迎大佬们来参观我写的蓝桥杯系列,我好久没有更新博客了,因为up猪我寒假用自己的劳动换了…...

米尔基于STM32MP25x核心板Debian系统发布,赋能工业设备
一、系统概述 MYD-LD25X搭载的Debian系统包含以太网、WIFI/BT、USB、RS485、RS232、CAN、AUDIO、HDMI显示和摄像头等功能,同时也集成了XFCE轻量化桌面、VNC远程操控、SWITCH网络交换和TSN时间敏感网络功能,为工业设备赋予“超强算力实时响应极简运维”的…...

ES02 - ES语句
ES语句 文章目录 ES语句一:连接和基本的使用1:显示详细信息2:输出可显示列3:查看分片 二:Http接口 - 索引(数据库)的增删改2.1:插入数据2.2:删除数据2.3:更新数据2.3.1:P…...

C++ 学生成绩管理系统
一、项目背景与核心需求 成绩管理系统是高校教学管理的重要工具,本系统采用C++面向对象编程实现,主要功能模块包括: 学生信息管理(学号/姓名/3门课程成绩) 成绩增删改查(CRUD)操作 数据持久化存储 统计分析与报表生成 用户友好交互界面 二、系统架构设计 1. 类结构设计 …...

项目管理工具 Maven
目录 1.Maven的概念 1.1什么是Maven 1.2什么是依赖管理 1.3什么是项目构建 1.4Maven的应用场景 1.5为什么使用Maven 1.6Maven模型 2.初识Maven 2.1Maven安装 2.1.1安装准备 2.1.2Maven安装目录分析 2.1.3Maven的环境变量 2.2Maven的第一个项目 2.2.1按照约…...

设计心得——分层和划分模块
一、分层 在实际的设计开发过程中,对于稍微大一些的项目,基本都涉及到分层。什么是分层呢?其实非常简单,就是利用某种逻辑或域的范围等把整个项目划分成多个层次。它们之间通过接口(可能是简单的函数接口也可以是服务…...

uniapp使用蓝牙,usb,局域网,打印机打印
使用流程(支持安卓和iOS) 引入SDK 引入原生插件包地址如下 https://github.com/oldfive20250214/UniPrinterDemo 连接设备 安卓支持经典蓝牙、ble蓝牙、usb、局域网(参考API) iOS支持ble蓝牙、局域网(参考API&…...

PQL查询和监控各类中间件
1 prometheus的PQL查询 1.1 Metrics数据介绍 prometheus监控中采集过来的数据统一称为Metrics数据,其并不是代表具体的数据格式,而是一种统计度量计算单位当需要为某个系统或者某个服务做监控时,就需要使用到 metrics prometheus支持的met…...
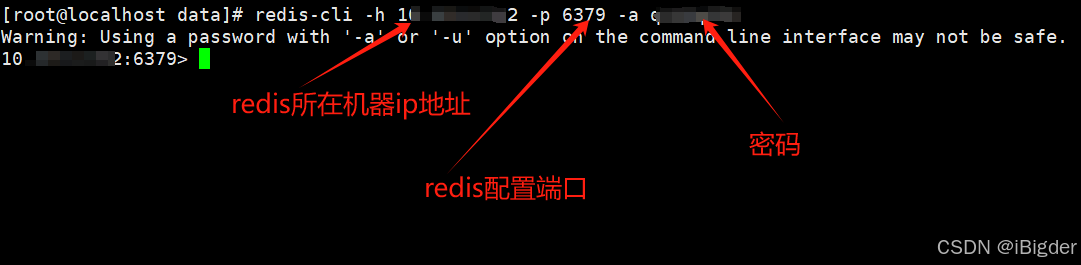
day1 redis登入指令
[rootlocalhost data]# redis-cli -h ip -p 6379 -a q123q123 Warning: Using a password with -a or -u option on the command line interface may not be safe. ip:6379> 以上, Bigder...

2025 年 AI 网络安全预测
🍅 点击文末小卡片 ,免费获取网络安全全套资料,资料在手,涨薪更快 微软和 OpenAI 宣布延长战略合作伙伴关系,加强对推进人工智能技术的承诺,这表明强大的 AI 将在未来占据主导地位。 随着人工智能 &#x…...
[Windows] 多系统键鼠共享工具 轻松跨系统控制多台电脑
参考原文:[Windows] 多系统键鼠共享工具 轻松跨系统控制多台电脑 还在为多台电脑需要多套键盘鼠标而烦恼吗?是不是在操控 Windows、macOS、Linux 不同系统电脑时手忙脚乱?现在,这些问题通通能解决!Deskflow 软件闪亮登…...

单片机的发展
一、引言 单片机自诞生以来,经历了四十多年的风风雨雨,从最初的工业控制逐步扩展到家电、通信、智能家居等各个领域。其发展过程就像是一场精彩的冒险,每一次技术的革新都像是在未知的海域中开辟新的航线。 二、单片机的发展历程 ÿ…...

Spring 构造器注入和setter注入的比较
一、比较说明 在 Spring 框架中,构造器注入(Constructor Injection)和 Setter 注入(Setter Injection)是实现依赖注入(DI)的两种主要方式。它们的核心区别在于依赖注入的时机、代码设计理念以及…...

uploadlabs通关思路
目录 靶场准备 复现 pass-01 代码审计 执行逻辑 文件上传 方法一:直接修改或删除js脚本 方法二:修改文件后缀 pass-02 代码审计 文件上传 1. 思路 2. 实操 pass-03 代码审计 过程: 文件上传 pass-04 代码审计 文件上传 p…...

迷你世界脚本自定义UI接口:Customui
自定义UI接口:Customui 彼得兔 更新时间: 2024-11-07 15:12:42 具体函数名及描述如下:(除前两个,其余的目前只能在UI编辑器内部的脚本使用) 序号 函数名 函数描述 1 openUIView(...) 打开一个UI界面(注意…...
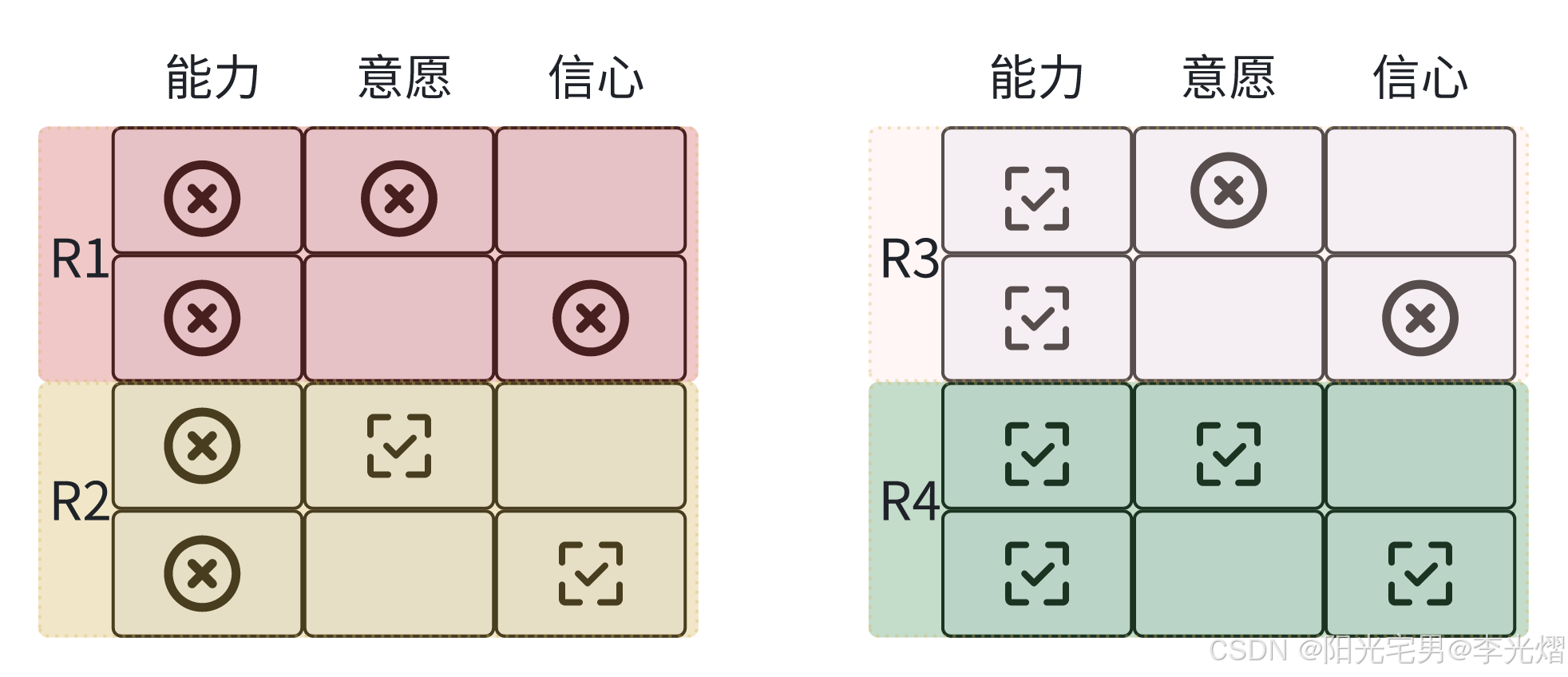
【情境领导者】评估情境——准备度水平
本系列是看了《情境领导者》一书,结合自己工作的实践经验所做的学习笔记。 在文章【情境领导者】评估情境——什么是准备度-CSDN博客我们提到准备度是由能力和意愿两部分组成的。 准备度水平 而我们要怎么去评估准备度呢?准备度水平是指人们在每项工作中…...

2025 ubuntu24.04系统安装docker
1.查看ubuntu版本(Ubuntu 24.04 LTS) rootmaster:~# cat /etc/os-release PRETTY_NAME"Ubuntu 24.04 LTS" NAME"Ubuntu" VERSION_ID"24.04" VERSION"24.04 LTS (Noble Numbat)" VERSION_CODENAMEnoble IDubun…...

爱普生SG-8201CJ石英可编程振荡器:精准频率控制,高效能工业级应用首选
引言在电子设计中,晶振是不可或缺的元器件,它为整个系统提供精准的时间基准。然而,面对市场上琳琅满目的晶振产品,工程师们常常感到选型困难,特别是在需要高精度、高稳定性和快速交付的情况下。今天,我们就…...

Go语言实现M3U8视频下载器:技术原理与实战应用深度解析
Go语言实现M3U8视频下载器:技术原理与实战应用深度解析 【免费下载链接】m3u8-downloader 一个M3U8 视频下载(M3U8 downloader)工具。跨平台: 提供windows、linux、mac三大平台可执行文件,方便直接使用。 项目地址: https://gitcode.com/gh_mirrors/m3u8d/m3u8-d…...

workbuddy 来解决 华南x99-4mf 设置avx2的bois信息的问题
baidu 抖音 都搜索不到 华南x99-4mf 设置avx2的bois信息 默认bois没有这个选项,用workbuddy 来解决 The user wants to search for information about the “华南X99-4MF” motherboard, specifically whether it supports AVX2 settings in BIOS, and wants to do…...

Linux多网卡主机路由检查方法
Linux多网卡主机路由检查方法多网卡主机在 Linux 环境中并不少见。它们可能用于业务隔离、管理面分离、双线接入、内外网分流或高可用部署。但多网卡也意味着更复杂的路由行为。很多“这台机器能 ping 通但服务异常”“流量出去后回不来”的问题,最终都与路由选择有…...

Linux僵死IO与不可中断睡眠分析
Linux僵死IO与不可中断睡眠分析在 Linux 系统里,有一类问题特别让人困惑:进程存在、CPU 不高,但命令卡住、服务停不下来、甚至 kill 也无效。很多这类现象最终都与不可中断睡眠状态有关,尤其常见于 IO 阻塞场景。中级阶段需要理解…...

MAX3421E USB主机控制器实战:为微控制器扩展USB外设连接能力
1. 项目概述:为你的微控制器打开USB主机世界的大门如果你玩过Arduino、ESP32或者树莓派Pico这类微控制器,肯定对它们的USB设备功能不陌生——插上电脑就能被识别成一个串口、一个键盘或者一个U盘。但你想过反过来吗?让你的微控制器项目变成“…...

5个步骤掌握ModEngine2:魂类游戏模组开发的终极解决方案
5个步骤掌握ModEngine2:魂类游戏模组开发的终极解决方案 【免费下载链接】ModEngine2 Runtime injection library for modding Souls games. WIP 项目地址: https://gitcode.com/gh_mirrors/mo/ModEngine2 你是否曾想过为《黑暗之魂3》或《艾尔登法环》这样的…...

阿里Qwen3.6系列实测
阿里Qwen3.6系列实测|1M上下文封神!企业香爆,个人用官方举步维艰AI圈彻底沸腾!阿里Qwen3.6系列甩出王炸——Plus/Flash支持1MToken超大上下文,思维链推理、全栈编程、多模态理解拉满,企业级生产力怪兽实锤&…...

3分钟拯救你的B站视频:m4s-converter零转码转换完全指南
3分钟拯救你的B站视频:m4s-converter零转码转换完全指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 想象一下,你花了…...

告别电脑“飞机起飞“噪音:FanControl风扇控制终极指南
告别电脑"飞机起飞"噪音:FanControl风扇控制终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tr…...