ES02 - ES语句
ES语句
文章目录
- ES语句
- 一:连接和基本的使用
- 1:显示详细信息
- 2:输出可显示列
- 3:查看分片
- 二:Http接口 - 索引(数据库)的增删改
- 2.1:插入数据
- 2.2:删除数据
- 2.3:更新数据
- 2.3.1:PUT方式-覆盖式
- 2.3.2:POST方式
- 2.3.3:全量更新,满足条件的全部修改
- 2.4:映射基本操作
- 2.4.1:映射原理
- 2.4.2:映射数据说明
- 2.4.3:查看映射-GET
- 2.4.4:索引映射关联-PUT
- 三:Http接口 - Query查询【重点】
- 三:Http接口 - Query查询【重点】
- 3.1:查询全部和结果字符说明
- 3.2:精准匹配term/terms
- 3.3:匹配和多重匹配match[重点]
- 3.3.1:基本匹配和匹配流程分析
- 3.3.2:match多个词语的匹配op
- 3.3.3:控制match的匹配精度
- 3.3.4:multi_match:多个字段的查询
- 3.3.5:term和match区别(面试)
- 3.4:match_pharse(难点)
- 3.4.1:slop容差
- 3.4.2:match_phrase_prefix
- 3.4.3:通配符个数max_expansions
- 3.5:bool查询[重点]
- 3.6:wildcard:通配符模糊查询
- 3.7:降级显示boosting query(了解)
- 3.8:固定得分查询constant_score(了解)
- 3.9:最佳匹配查询dis_max(了解)
- 3.10:函数查询function_score(了解)
- 3.11:query String(了解)
- 3.11.1:query_string
- 3.11.2:query_string_simple
- 3.12:interval类型(了解)
- 3.13:辅助查询[重要]
- 3.13.1:exist是否存在字段
- 3.13.2:ids对id查找
- 3.13.3:regexp正则匹配
- 3.13.4:fuzzy转换匹配(了解)
- 3.13.5:切片查询from / size
- 3.13.6:范围查询range
- 3.13.7:排序sort
- 四:聚合查询【重点】
- 4.1.1:对流程的控制
- 4.1.1.1:单值聚合
- 4.1.1.2:多个聚合
- 4.1.1.3:聚合嵌套
- 4.1.1.4:动态脚本的聚合(了解)
- 4.1.2:前置条件过滤filter
- 4.1.2.1:filter概述
- 4.1.2.1:filter的分组聚合:filters
- 4.1.2:range聚合支持
- 4.1.2.1:对number类型聚合
- 4.1.2.2:对ip类型聚合
- 4.1.2.3:对日期date的类型聚合
- 4.2:指标聚合
- 4.2.1:单值指标分析
- 4.2.1.1:avg平均值
- 4.2.1.2:最大值,最小值
- 4.2.1.3:sum总和
- 4.2.1.4:count个数
- 4.2.2:多值指标分析
一:连接和基本的使用
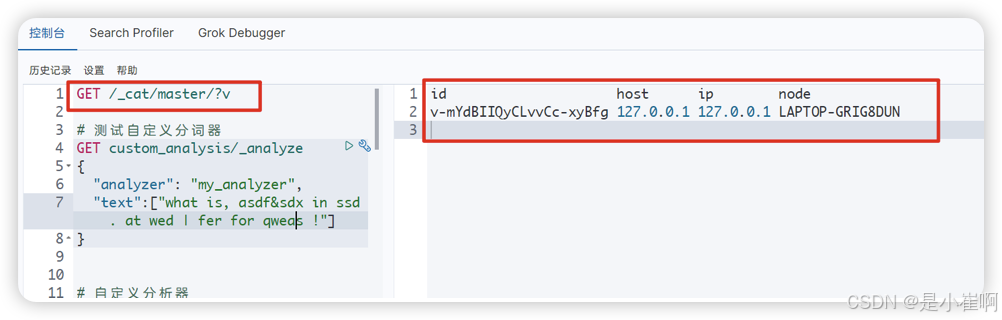
1:显示详细信息
# 使用?v参数
curl localhost:9200/_cat/master?v
master节点信息如下:
2:输出可显示列
curl localhost:9200/_cat/master?help
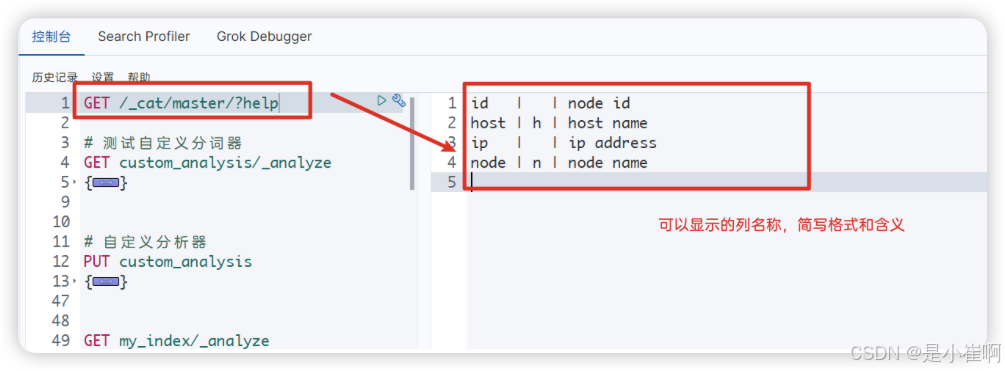
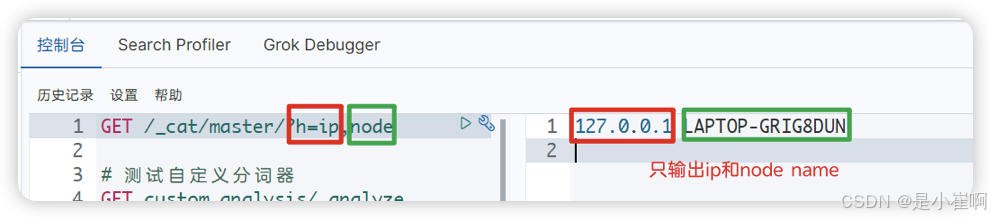
这样就可以指定输出对应的内容:
curl localhost:9200/_cat/master?h = ip, node
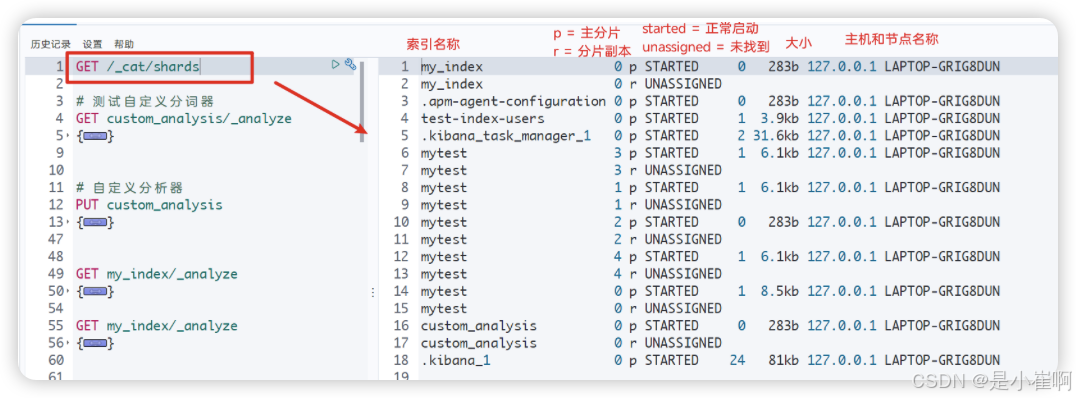
3:查看分片
curl localhost:9200/_cat/shards
二:Http接口 - 索引(数据库)的增删改
以Movies这个索引为例,演示增删改
PUT /movies
{# 字段结构映射"mappings": {"properties": {"title": {"type": "text","analyzer": "ik_max_word", # ik_max_word最细粒度的分词"search_analyzer": "ik_smart" # ik_smart最粗粒度的分词},"year": {"type": "date","format": "yyyy"},"type": {"type": "text","index": false # type字段的index为false,那么type这个字段是不会被分词被索引的,不能作为查询条件},"star": {"type": "float","fields": {"keyword": {"type": "keyword"}}},"director": {"type": "keyword"}}},# 索引属性设置 - 5分片,1副本"settings": {"index": {"number_of_shards": 5, # 每个索引的主分片数,默认值是 5 。这个配置在索引创建后不能修改。"number_of_replicas": 1 # 每个主分片的副本数,默认值是 1 。对于活动的索引库,这个配置可以随时修改。}}
}
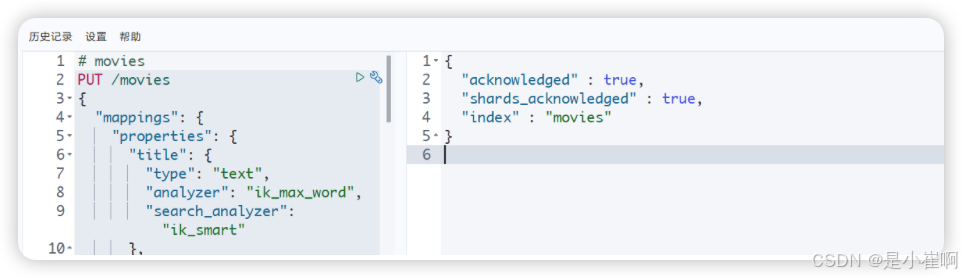
2.1:插入数据
POST /movies/_doc/
{"title": "AAAAAAAAAAAAAAAAAAAA","year": "2020","type": "剧情","star": 5.2,"director": "BBBBB"
}
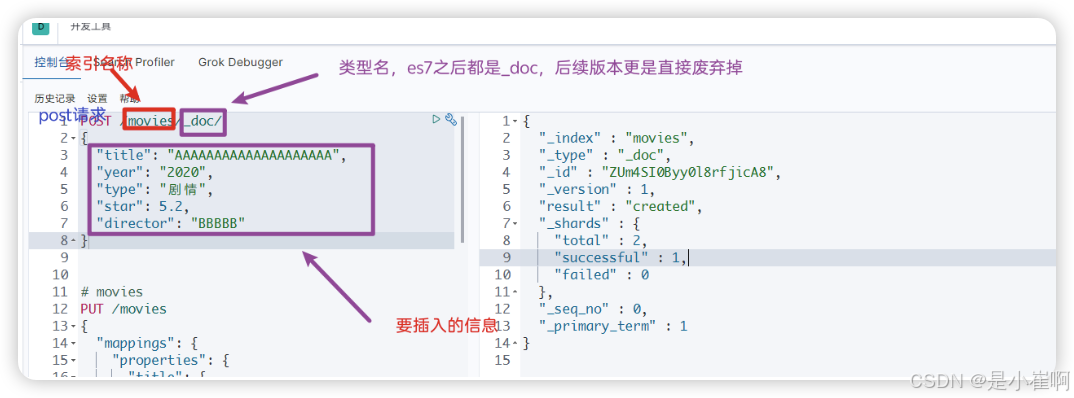
2.2:删除数据
# DELETE /库名/_doc/文档id , 根据文档id进行删除
DELETE /movies/_doc/1# 根据查询语句删除
POST /my-index/_delete_by_query
{"query": { # 删除条件"match": {"user.id": "elkbee"}}
}
#删除所有数据
POST /my-index/_delete_by_query
{"query": {"match_all": {}}
}
2.3:更新数据
2.3.1:PUT方式-覆盖式
PUT /库名/_doc/文档id
PUT 在 restFull 里面代表两个意思: add 和 update, 当没有id时, 新增, 当有id时修改
在这里, 也是一样的. 当有指定的id时, 修改, 当没有指定的id时, 新增
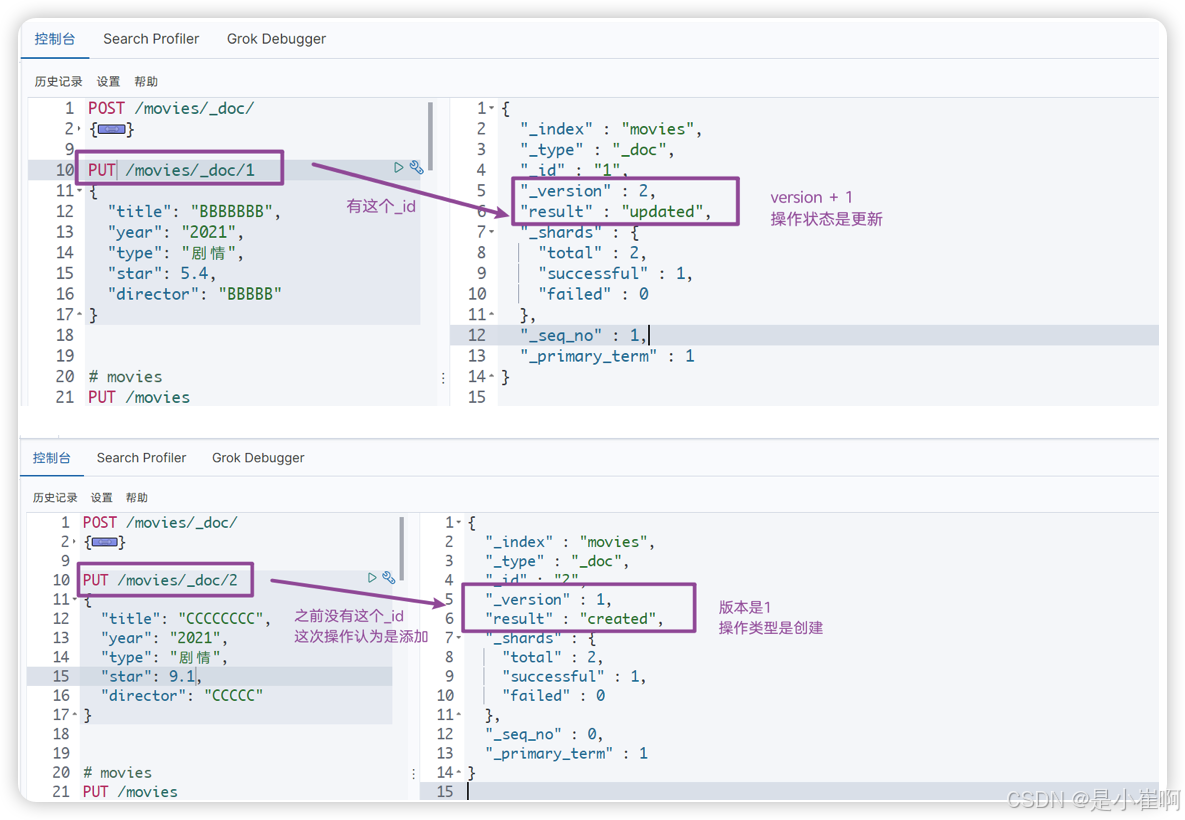
2.3.2:POST方式
POST /库名/_doc/文档id # 这也是一种覆盖式方式, 结果和 PUT 是一样的. 同样的, post也可以新增数据.POST /库名/_update/文档id # 非覆盖式方式, 他只有修改的功能, 没有新增文档的功能
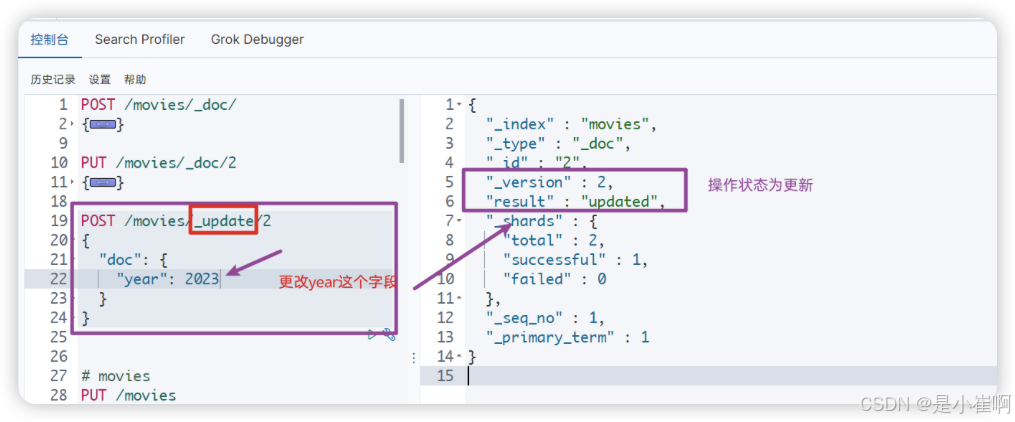
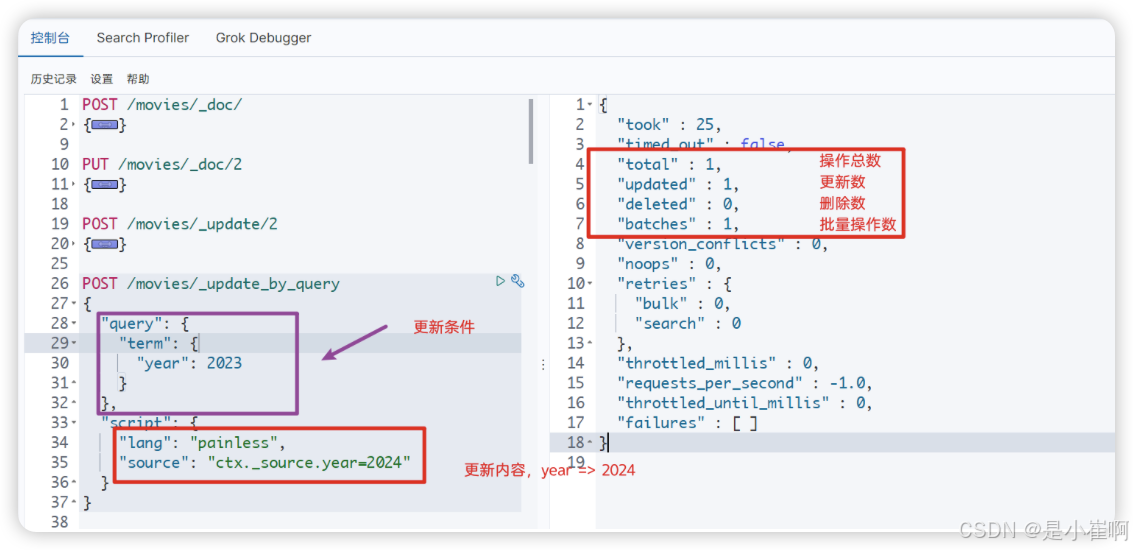
2.3.3:全量更新,满足条件的全部修改
POST /index_name/_update_by_query
{"query": {"term": {"is_stopped": true // 设置更新条件}},"script": {"lang": "painless","source": "ctx._source.is_stopped=false" // 设置更新内容}
}
2.4:映射基本操作
2.4.1:映射原理
有了索引库,等于有了数据库中的 database。
接下来就需要建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。
创建数据库表需要设置字段名称,类型,长度,约束等;
索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。
2.4.2:映射数据说明
-
字段名:任意填写,下面指定许多属性,例如:title、subtitle、images、price
-
type:类型,Elasticsearch 中支持的数据类型非常丰富,说几个关键的:
- String 类型,又分两种:
- text:可分词,支持模糊查询,支持准确查询,不支持聚合查询
- keyword:不可分词,数据会作为完整字段进行匹配,支持模糊查询,支持准确查询,支持聚合查询。
- Numerical:数值类型,分两类
- 基本数据类型:long、integer、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- Date:日期类型
- Array:数组类型
- Object:对象
- String 类型,又分两种:
-
index:是否索引,默认为 true,也就是说你不进行任何配置,所有字段都会被索引。
- true:字段会被索引,则可以用来进行搜索
- false:字段不会被索引,不能用来搜索
-
store:是否将数据进行独立存储,默认为 false
原始的文本会存储在 _source 里面,默认情况下其他提取出来的字段都不是独立存储 的,是从 _source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置 “store”: true 即可,获取独立存储的字段要比从 _source 中解析快得多,但是也会占用 更多的空间,所以要根据实际业务需求来设置。
-
analyzer:分词器,这里的 ik_max_word 即使用 ik 分词器
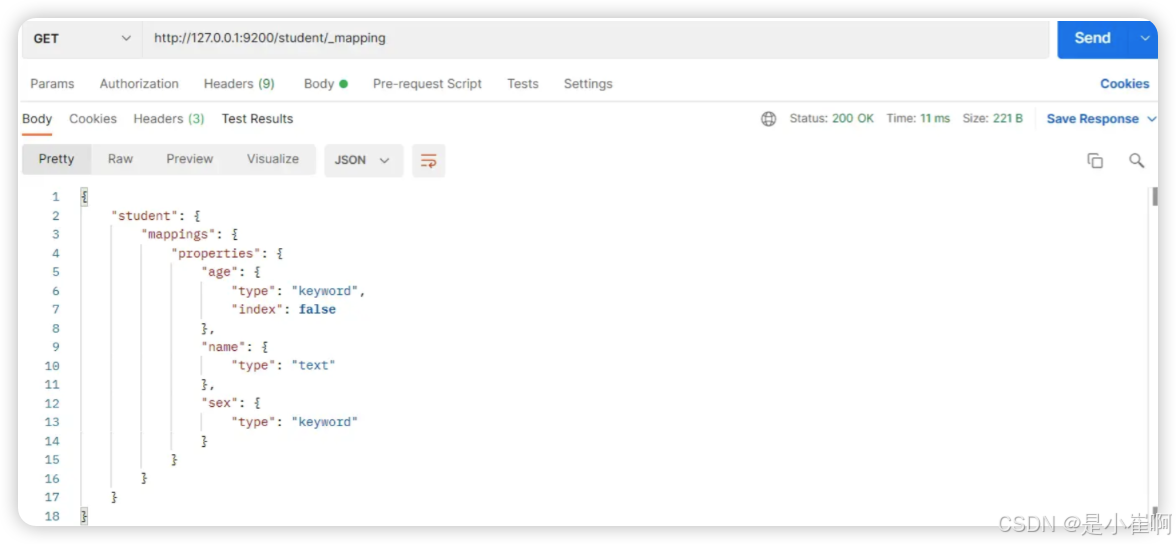
2.4.3:查看映射-GET
在 Postman 中,向 ES 服务器发 GET 请求:http://ip:port/索引名称/_mapping
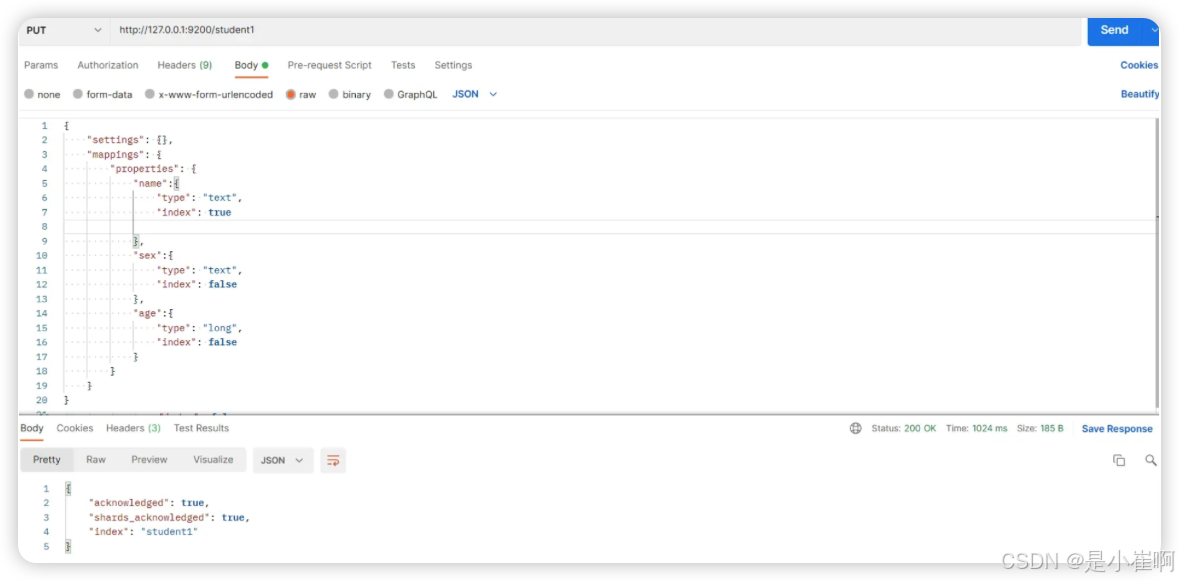
2.4.4:索引映射关联-PUT
创建新的索引 student1,与之前的 student 进行映射关联
在 Postman 中,向 ES 服务器发 PUT 请求:http://127.0.0.1:9200/student1
{"settings": {},"mappings": {"properties": {"name":{"type": "text","index": true},"sex":{"type": "text","index": false},"age":{"type": "long","index": false}}}
}
三:Http接口 - Query查询【重点】
三:Http接口 - Query查询【重点】
"query": {"搜索的方式": {"检索条件"}
}
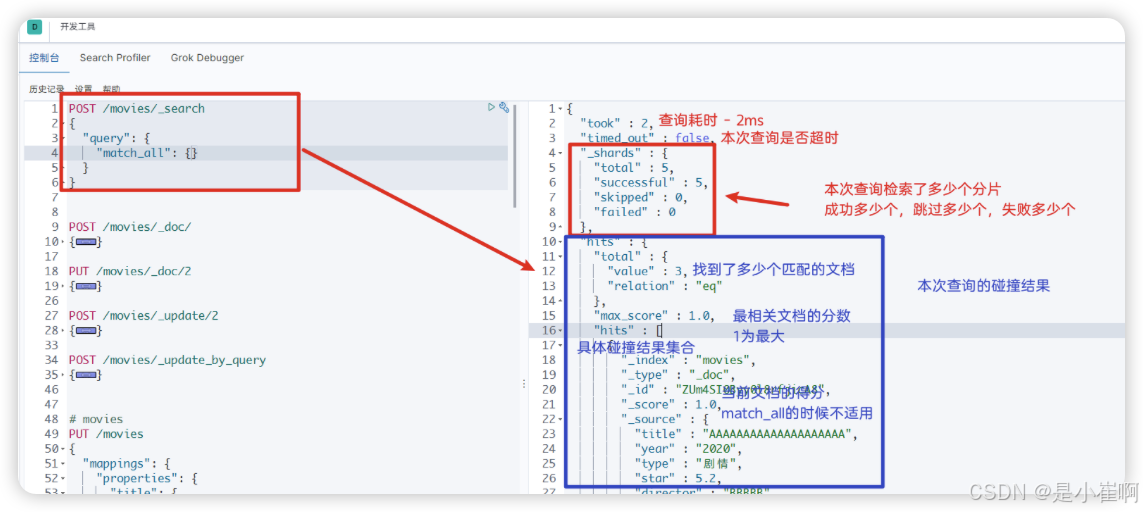
3.1:查询全部和结果字符说明
POST /movies/_search
{"query": {"match_all": {}}
}
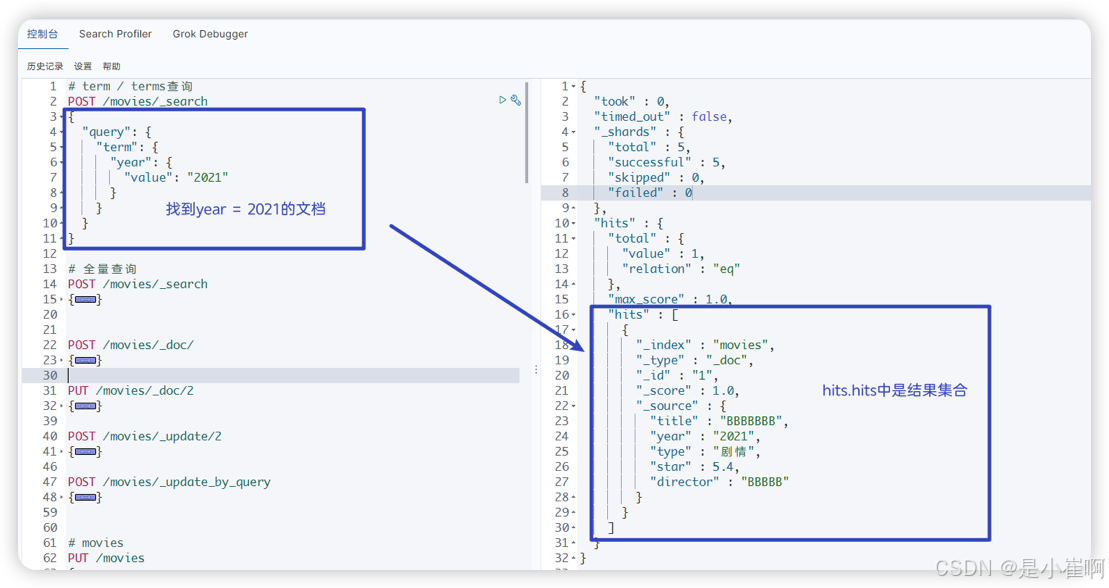
3.2:精准匹配term/terms
term -> select * from table where column_name = value
POST /索引名称/_search
{"query": {"term": {"field名称": "value1"}}
}
terms -> select * from table where column_name in [value1, value2, ...]
POST /索引名称/_search
{"query": {"terms": {"field名称": ["value1","value2"]}}
}

3.3:匹配和多重匹配match[重点]
- match ->
where column_name like 分词后的value - multi_match ->
where fields中的列名称中 like 分词后的 query
3.3.1:基本匹配和匹配流程分析
一个简单的match查询,查询title中带有quick!的:
GET /test-dsl-match/_search
{"query": {"match": {"title": "QUICK!"}}
}
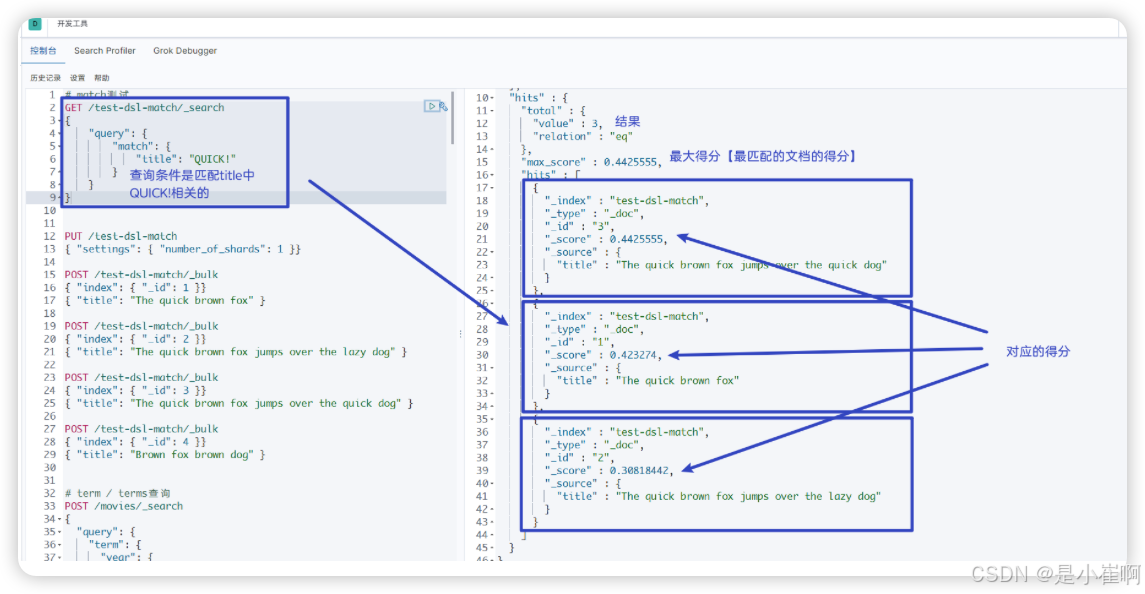
Elasticsearch 执行上面这个 match 查询的步骤是:
1:检查字段的类型
标题 title 字段是一个 string 类型( analyzed )已分析的全文字段,这意味着查询字符串本身也应该被分析
2:分析查询字符串
将查询的字符串 QUICK! 传入标准分析器中,输出的结果是单个项 quick 。
因为只有一个单词项,所以 match 查询执行的是单个底层 term 查询
3:查询匹配文档
用 term 查询在倒排索引中查找 quick 然后获取一组包含该项的文档
本例子的结果是文档1, 文档2, 文档3
4:结果评分
用 term 查询计算每个文档相关度评分 _score
这是种将词频(term frequency,即词 quick 在相关文档的 title 字段中出现的频率)和反向文档频率(inverse document frequency,即词 quick 在所有文档的 title 字段中出现的频率)以及字段的长度(即字段越短相关度越高)相结合的计算方式。
3.3.2:match多个词语的匹配op
GET /test-dsl-match/_search
{"query": {"match": {"title": "BROWN DOG"}}
}
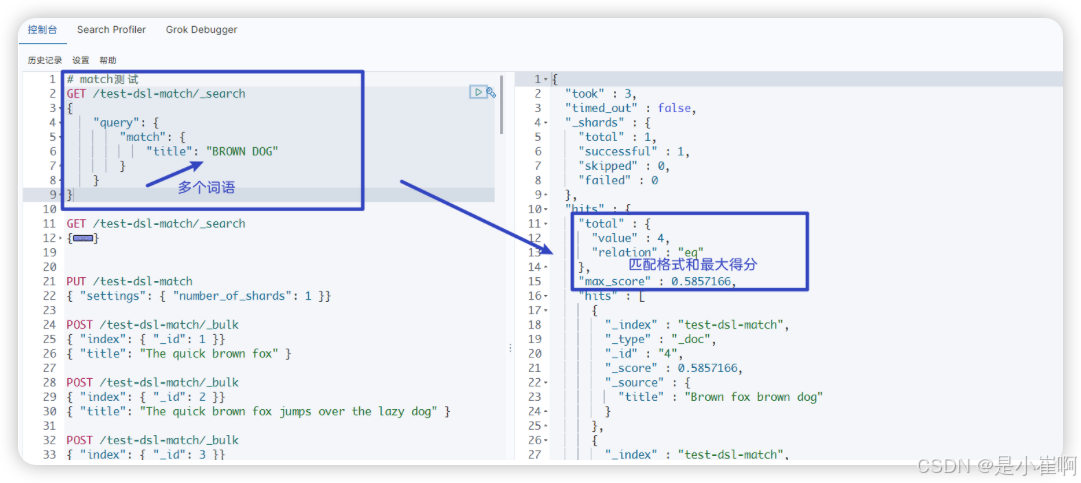
在内部实际上先执行两次 term 查询,然后将两次查询的结果合并作为最终结果输出。
match还有一个operator参数,默认是or,所以上面两个词语,只有在文档中找到一个就满足条件
GET /test-dsl-match/_search
{"query": {"match": {"title": {"query": "BROWN DOG","operator": "or" // 默认值,上面的查询条件等价于这个}}}
}
and操作
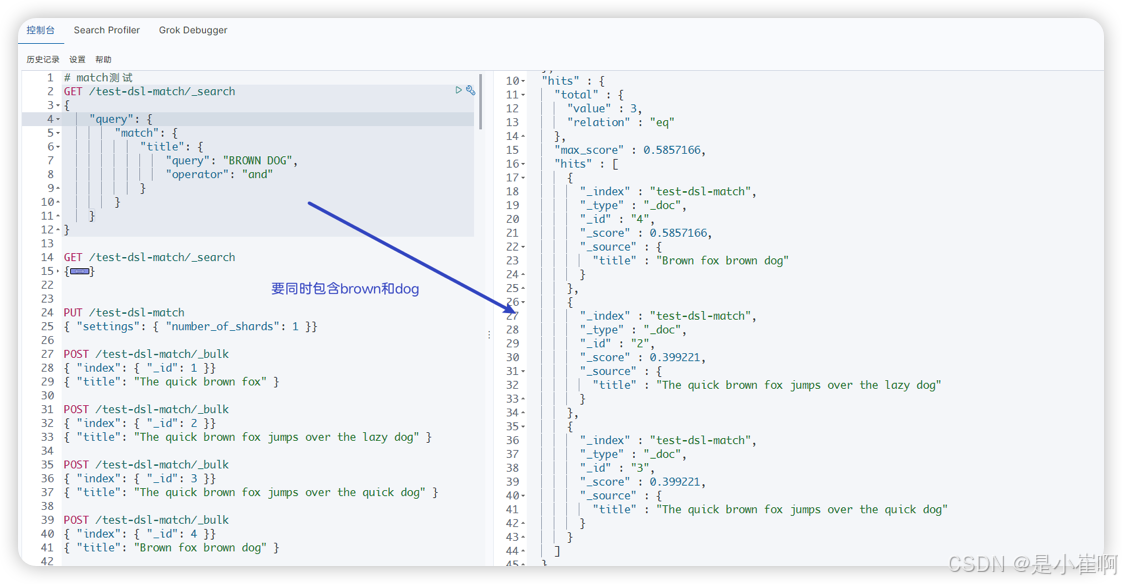
GET /test-dsl-match/_search
{"query": {"match": {"title": {"query": "BROWN DOG","operator": "and"}}}
}
3.3.3:控制match的匹配精度
match 查询支持 minimum_should_match 最小匹配参数,这让我们可以指定必须匹配的词项数用来表示一个文档是否相关。
我们可以将其设置为某个具体数字,更常用的做法是将其设置为一个百分数,因为我们无法控制用户搜索时输入的单词数量
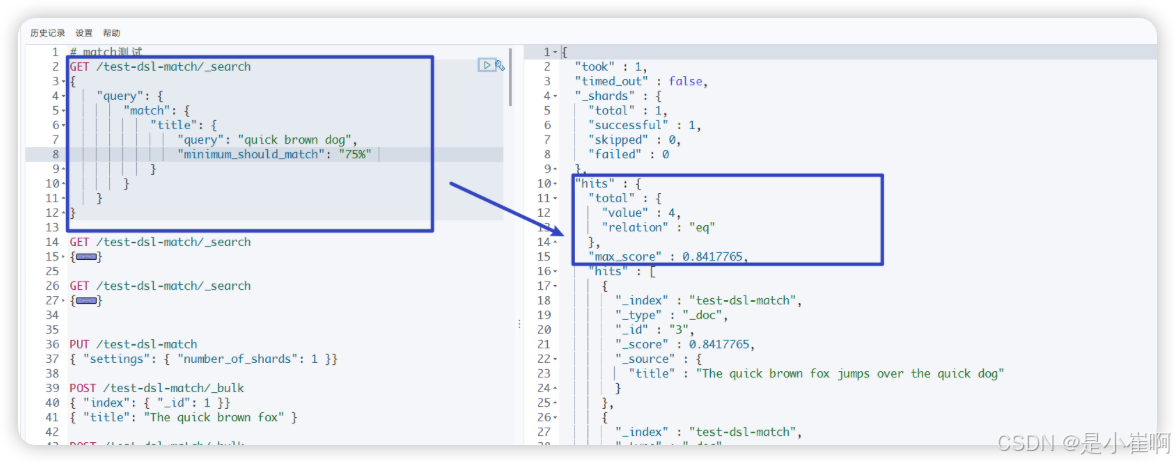
GET /test-dsl-match/_search
{"query": {"match": {"title": {"query": "quick brown dog","minimum_should_match": "75%" // 上面三个词语,至少要匹配上两个才行}}}
}
⛵️ 当给定百分比的时候, minimum_should_match 会做合适的事情:在之前三词项的示例中, 75%会自动被截断成 66.6% ,即三个里面两个词。无论这个值设置成什么,至少包含一个词项的文档才会被认为是匹配的
3.3.4:multi_match:多个字段的查询
// 对多个字段进行查询
{"query": {"multi_match" : {"query": "Will Smith","fields": [ "title", "_name" ] // 从title, _name两个字段中进行匹配,任意一个有即为成功}}
}
3.3.5:term和match区别(面试)
Term:
- 它用于完全匹配查询,即精确查询。
- 在执行查询之前,不会对搜索词进行分词解析。
- 它直接将整个搜索词作为单个术语与数据库中的记录进行比较。
Match:
- 它用于模糊匹配查询,即全文搜索。
- 在执行查询之前,会对搜索词进行分词解析。
- 然后,它会将分词后的搜索词与数据库中的记录进行匹配。
总结来说,term 通常用于精确匹配,而 match 通常用于模糊匹配或全文搜索。
在使用非 keyword 类型字段时,可以根据分词情况选择使用 term 或 match
3.4:match_pharse(难点)
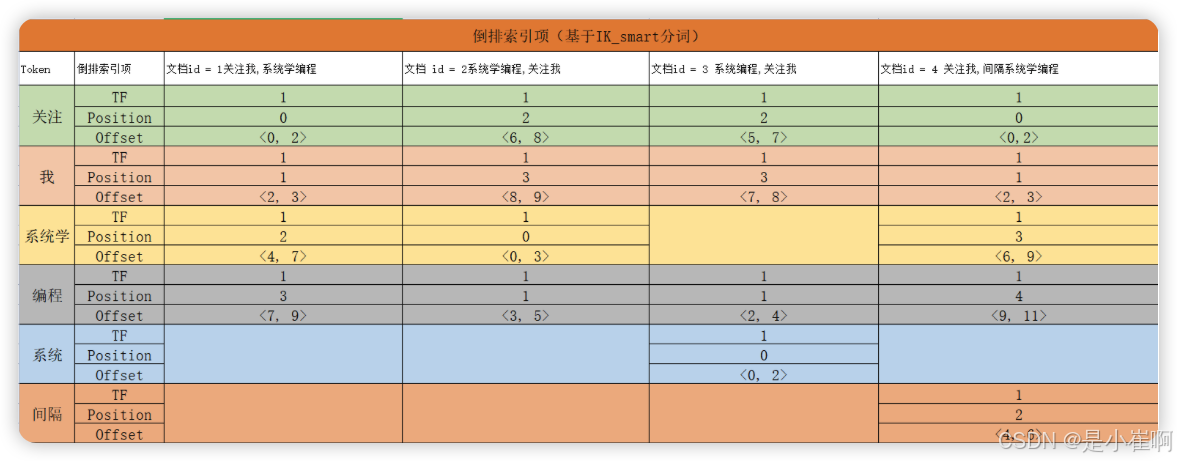
假设现在有如下的数据:
{ "id" : 1,"content":"关注我,系统学编程" }
{ "id" : 2,"content":"系统学编程,关注我" }
{ "id" : 3,"content":"系统编程,关注我" }
{ "id" : 4,"content":"关注我,间隔系统学编程" }
match_phrase查询分析文本并根据分析的文本创建一个短语查询。
match_phrase会将检索关键词分词。match_phrase的分词结果:
- 必须在被检索字段的分词中都包含
- 顺序必须相同
- 默认必须都是连续的。
// 使用match_phrase查询,ik_smart分词
GET /tehero_index/_doc/_search
{"query": {"match_phrase": {"content.ik_smart_analyzer": {"query": "关注我,系统学"}}}
}// 结果:只有文档1
"hits": [{"_index": "tehero_index","_type": "_doc","_id": "1","_score": 0.7370664,"_source": {"id": 1,// 分词都包含,顺序相同,连续 <- 只有这个而满足"content": "关注我,系统学编程"}}
]
上面的例子使用的分词器是ik_smart,所以检索词“关注我,系统学”会被分词为3个Token【关注、我、系统学】
而文档1、文档2 和文档4 的content被分词后都包含这3个关键词,但是只有文档1的Token的顺序和检索词一致,且连续。
所以使用 match_phrase 查询只能查询到文档1
- 文档2 -> Token顺序不一致
- 文档4 -> Token不连续
- 文档3 -> Token没有完全包含
3.4.1:slop容差
核心参数:slop参数 -> Token之间的位置距离容差值
// 将上面的 match_phrase 查询新增一个 slop参数
GET /tehero_index/_doc/_search
{"query": {"match_phrase": {"content.ik_smart_analyzer": {"query": "关注我,系统学","slop":1}}}
}
// 结果:文档1和文档4都被检索出来
为什么文档4这次可以搜索出来呢?
// 文档4 content 的分词
GET /_analyze
{"text": ["关注我,间隔系统学编程"],"analyzer": "ik_smart"
}
// 结果
{"tokens": [{"token": "关注","start_offset": 0,"end_offset": 2,"type": "CN_WORD","position": 0},{"token": "我","start_offset": 2,"end_offset": 3,"type": "CN_CHAR","position": 1},{"token": "间隔", // 我和系统学之间有个间隔分词,slop = 1允许这个容差,所以可以检索出来"start_offset": 4,"end_offset": 6,"type": "CN_WORD","position": 2},{"token": "系统学","start_offset": 6,"end_offset": 9,"type": "CN_WORD","position": 3},{"token": "编程","start_offset": 9,"end_offset": 11,"type": "CN_WORD","position": 4}]
}
通过分词测试,发现Token【我】与【系统学】的position差值为1(等于slop的值),所以也被检索出来了
3.4.2:match_phrase_prefix
GET tehero_index/_doc/_search
{"query": {"match_phrase_prefix": {"content.ik_smart_analyzer": {"query": "系","max_expansions": 1}}}
}
-- 对应的sql
where Token = 系 or Token like “系_”
3.4.3:通配符个数max_expansions
这个决定通配符的个数,最小值为1,默认为50
max_expansions:1 -> 系, 系统
max_expansions:2 -> 系, 系统,系统学
3.5:bool查询[重点]
使用bool查询来组合多个查询条件,bool查询只是复合查询一种
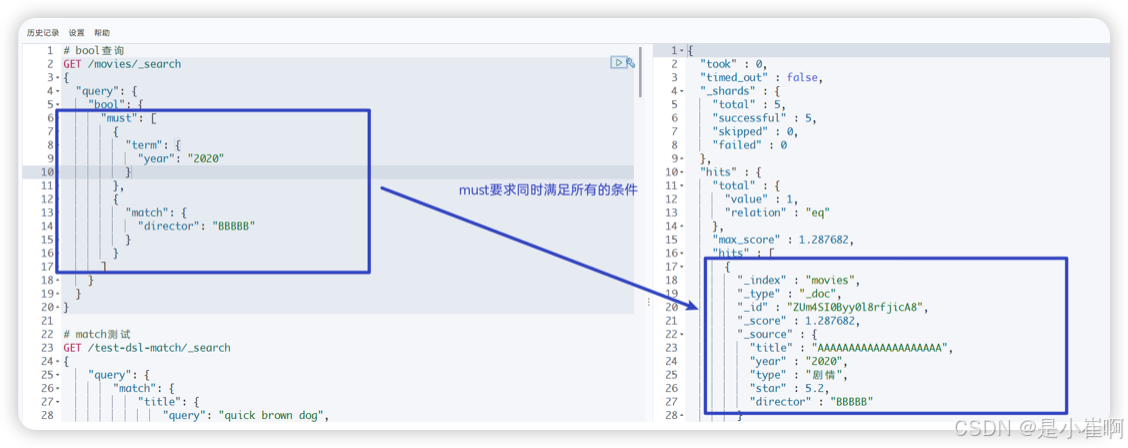
// age == 40 & states != ID
GET /bank/_search
{"query": {"bool": {"must": [{ "match": { "age": "40" } }],"must_not": [{ "match": { "state": "ID" } }]}}
}
- 子查询可以任意顺序出现
- 可以嵌套多个查询,包括bool查询
- 如果bool查询中没有must条件,should中必须至少满足一条才会返回结果
bool查询包含四种操作符,分别是must,should,must_not,filter。他们均是一种数组,数组里面是对应的判断条件
must: 必须匹配。贡献算分must_not:过滤子句,必须不能匹配,但不贡献算分should: 选择性匹配,至少满足一条。贡献算分filter: 过滤子句,必须匹配,但不贡献算分
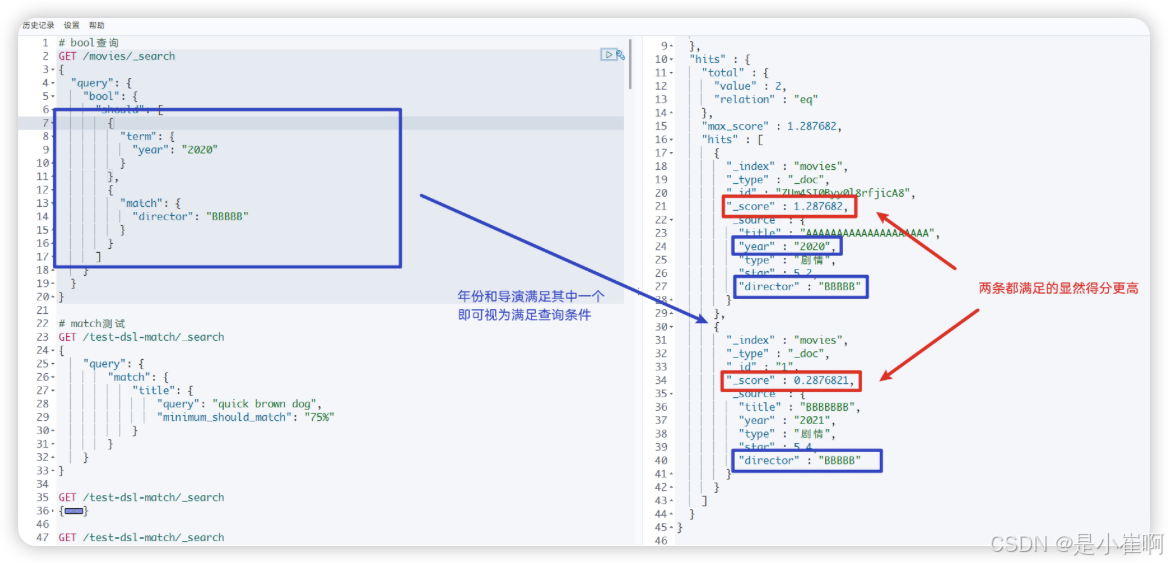
对于should,还可以指定最少满足条件的个数选项
GET /test-dsl-match/_search
{"query": {"bool": {"should": [{ "match": { "title": "quick" }},{ "match": { "title": "brown" }},{ "match": { "title": "dog" }}],"minimum_should_match": 2 # 上面三个至少匹配2个才会被命中}}
}
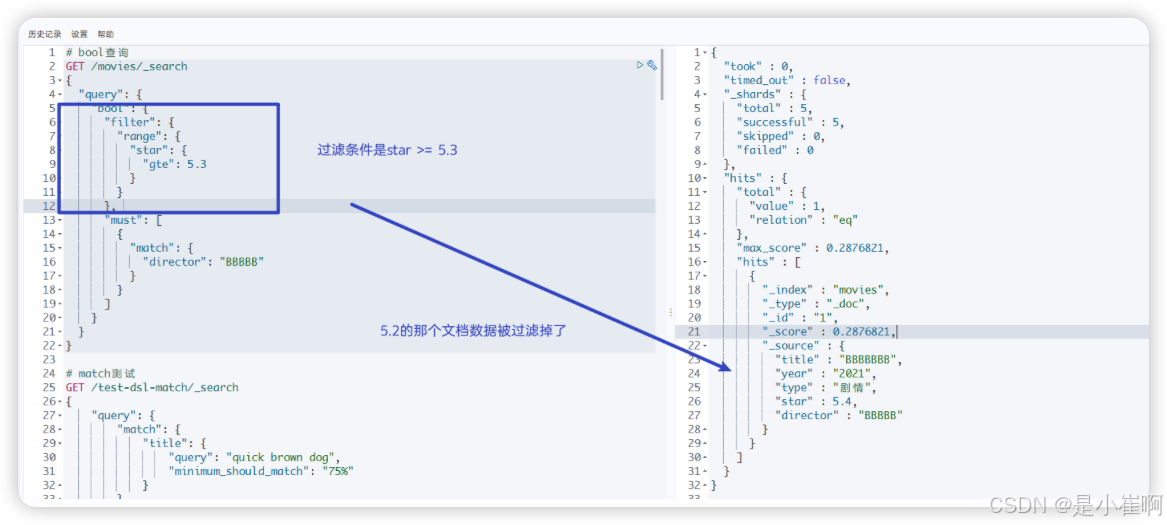
🎉 如果没有query, 只有filter,那么得分都是_score 0.0
3.6:wildcard:通配符模糊查询
| ? | 匹配任意字符 |
|---|---|
| * | 匹配0个或多个字符 |
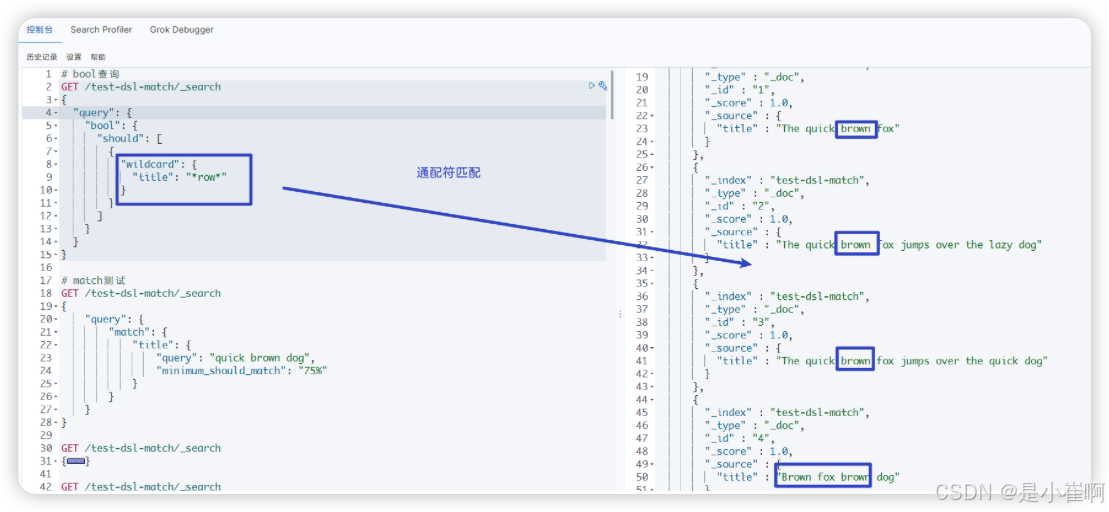
Wildcard 性能会比较慢。如果非必要,尽量避免在开头加通配符 ? 或者 *,这样会明显降低查询性能
如果查询的内容非空,直接用*
3.7:降级显示boosting query(了解)
不同于bool查询,bool查询中只要一个子查询条件不匹配那么搜索的数据就不会出现。
而boosting query则是降低显示的权重/优先级
比如搜索逻辑是name = 'apple' and type ='fruit',对于只满足部分条件的数据,不是不显示,而是降低显示的优先级
假设有如下数据
POST /test-dsl-boosting/_bulk
{ "index": { "_id": 1 }}
{ "content":"Apple Mac" }
{ "index": { "_id": 2 }}
{ "content":"Apple Fruit" }
{ "index": { "_id": 3 }}
{ "content":"Apple employee like Apple Pie and Apple Juice" }
对匹配
pie的做降级显示处理
GET /test-dsl-boosting/_search
{"query": {"boosting": {"positive": {"term": {"content": "apple"}},"negative": {"term": {"content": "pie"}},"negative_boost": 0.5}}
}
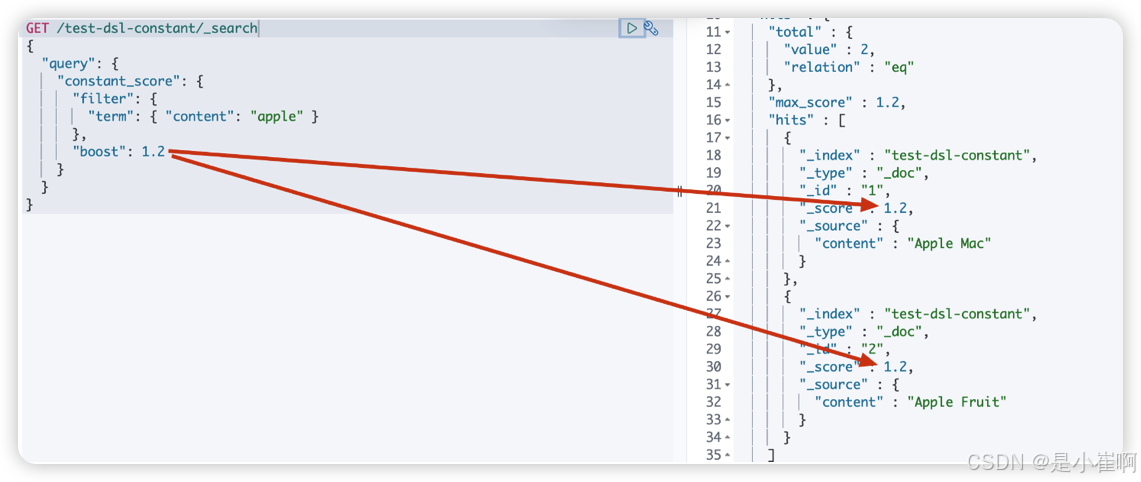
3.8:固定得分查询constant_score(了解)
查询某个条件时,固定的返回指定的score;
显然当不需要计算score时,只需要filter条件即可,因为filter context忽略score
GET /test-dsl-constant/_search
{"query": {"constant_score": {"filter": {"term": { "content": "apple" }},"boost": 1.2}}
}
3.9:最佳匹配查询dis_max(了解)
将任何与任一查询匹配的文档作为结果返回,但只将最佳匹配的评分作为查询的评分结果返回
假设现在有如下两个文档, 文档的内容如下:
POST /test-dsl-dis-max/_bulk
{ "index": { "_id": 1 }}
{"title": "Quick brown rabbits","body": "Brown rabbits are commonly seen."
}
{ "index": { "_id": 2 }}
{"title": "Keeping pets healthy","body": "My quick brown fox eats rabbits on a regular basis."
}
用户输入词组 “Brown fox” 然后点击搜索按钮。
事先,我们并不知道用户的搜索项是会在 title还是在body字段中被找到,但是,用户很有可能是想搜索相关的词组。
用肉眼判断,文档 2 的匹配度更高,因为它同时包括要查找的两个词
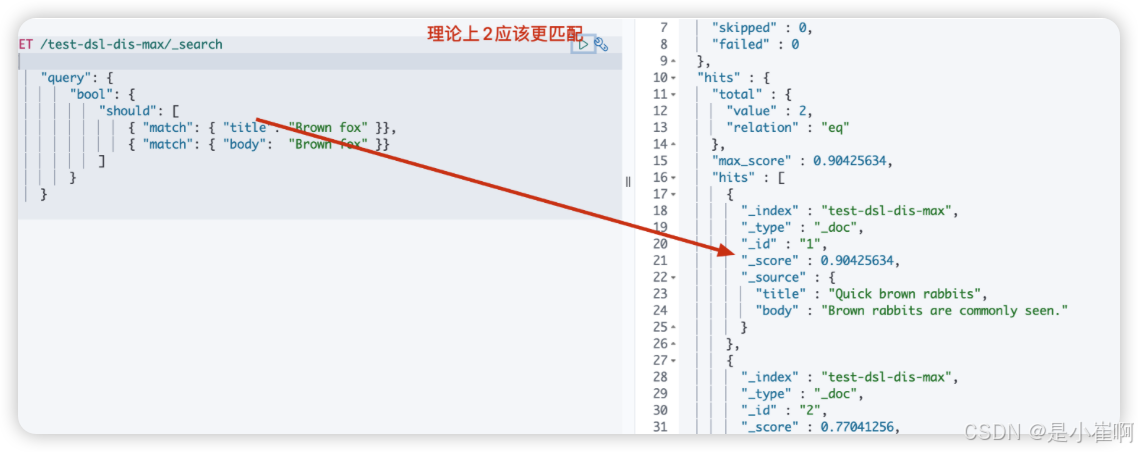
简单bool
// 如果简单的使用对应的bool
GET /test-dsl-dis-max/_search
{"query": {"bool": {"should": [{ "match": { "title": "Brown fox" }},{ "match": { "body": "Brown fox" }}]}}
}
发现对应的doc1的等分更好
dis_max
将任何与任一查询匹配的文档作为结果返回,但只将最佳匹配的评分作为查询的评分结果返回
GET /test-dsl-dis-max/_search
{"query": {"dis_max": {"queries": [{ "match": { "title": "Brown fox" }},{ "match": { "body": "Brown fox" }}],"tie_breaker": 0}}
}
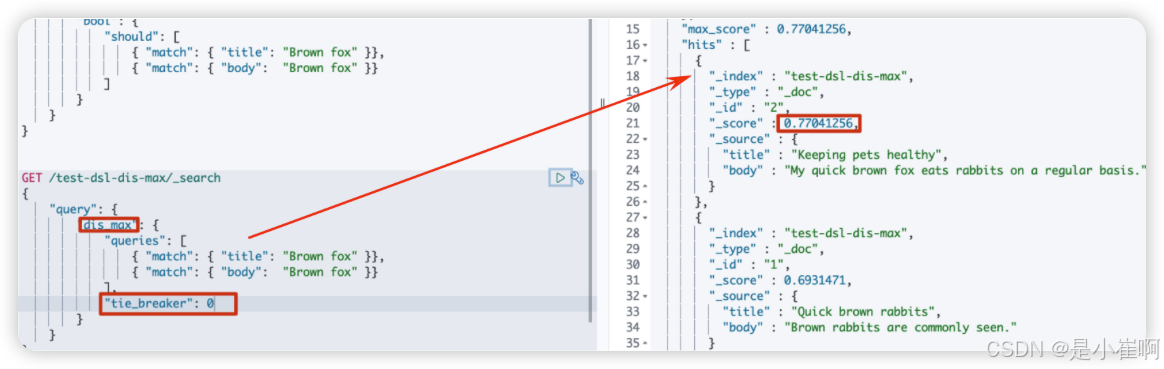
分数 = 第一个匹配条件分数 + tie_breaker 第二个匹配的条件的分数
3.10:函数查询function_score(了解)
用自定义function的方式来计算_score
自定义的function
script_score使用自定义的脚本来完全控制分值计算逻辑。如果你需要以上预定义函数之外的功能,可以根据需要通过脚本进行实现。weight对每份文档适用一个简单的提升,且该提升不会被归约:当weight == 2时,结果为2 _score。random_score使用一致性随机分值计算来对每个用户采用不同的结果排序方式,对相同用户仍然使用相同的排序方式。field_value_factor使用文档中某个字段的值来改变_score,比如将受欢迎程度或者投票数量考虑在内。- 衰减函数(
Decay Function) -linear,exp,gauss
GET /_search
{"query": {"function_score": {"query": { "match_all": {} },"boost": "5", "functions": [{"filter": { "match": { "test": "bar" } },"random_score": {}, "weight": 23},{"filter": { "match": { "test": "cat" } },"weight": 42}],"max_boost": 42,"score_mode": "max","boost_mode": "multiply","min_score": 42}}
}
script_score 可以使用如下方式
GET /_search
{"query": {"function_score": {"query": {"match": { "message": "elasticsearch" }},"script_score": {"script": {"source": "Math.log(2 + doc['my-int'].value)"}}}}
}
3.11:query String(了解)
3.11.1:query_string
此查询使用语法根据运算符(例如AND或OR)来解析和拆分提供的查询字符串NOT。然后查询在返回匹配的文档之前独立分析每个拆分的文本。
可以使用该query_string查询创建一个复杂的搜索,其中包括通配符,跨多个字段的搜索等等。尽管用途广泛,但查询是严格的,如果查询字符串包含任何无效语法,则返回错误
GET /test-dsl-match/_search
{"query": {"query_string": {"query": "(lazy dog) OR (brown dog)","default_field": "title"}}
}
3.11.2:query_string_simple
该查询使用一种简单的语法来解析提供的查询字符串并将其拆分为基于特殊运算符的术语。然后查询在返回匹配的文档之前独立分析每个术语。
尽管其语法比query_string查询更受限制 ,但simple_query_string 查询不会针对无效语法返回错误。而是将忽略查询字符串的任何无效部分。
GET /test-dsl-match/_search
{"query": {"simple_query_string" : {"query": "\"over the\" + (lazy | quick) + dog","fields": ["title"],"default_operator": "and"}}
}
3.12:interval类型(了解)
Intervals是时间间隔的意思,本质上将多个规则按照顺序匹配
GET /test-dsl-match/_search
{"query": {"intervals" : {"title" : {"all_of" : {"ordered" : true,"intervals" : [{"match" : {"query" : "quick", // ------------ 1"max_gaps" : 0,"ordered" : true}},{"any_of" : {"intervals" : [{ "match" : { "query" : "jump over" } }, // ------------ 2{ "match" : { "query" : "quick dog" } } ]}}]}}}}
}

3.13:辅助查询[重要]
3.13.1:exist是否存在字段
由于多种原因,文档字段的索引值可能不存在:
- 源JSON中的字段是null或[]
- 该字段已"index" : false在映射中设置
- 字段值的长度超出ignore_above了映射中的设置
- 字段值格式错误,并且ignore_malformed已在映射中定义
GET /XXX/_search
{"query": {"exists": {"field": "remarks"; // remarks索引值是不是存在}}
}
3.13.2:ids对id查找
GET /XXX/_search
{"query": {"ids": {"values": [3, 1]}}
}

3.13.3:regexp正则匹配
GET /test-dsl-term-level/_search
{"query": {"regexp": {"name": {"value": "Ja.", // name以Ja开头的"case_insensitive": true}}}
}
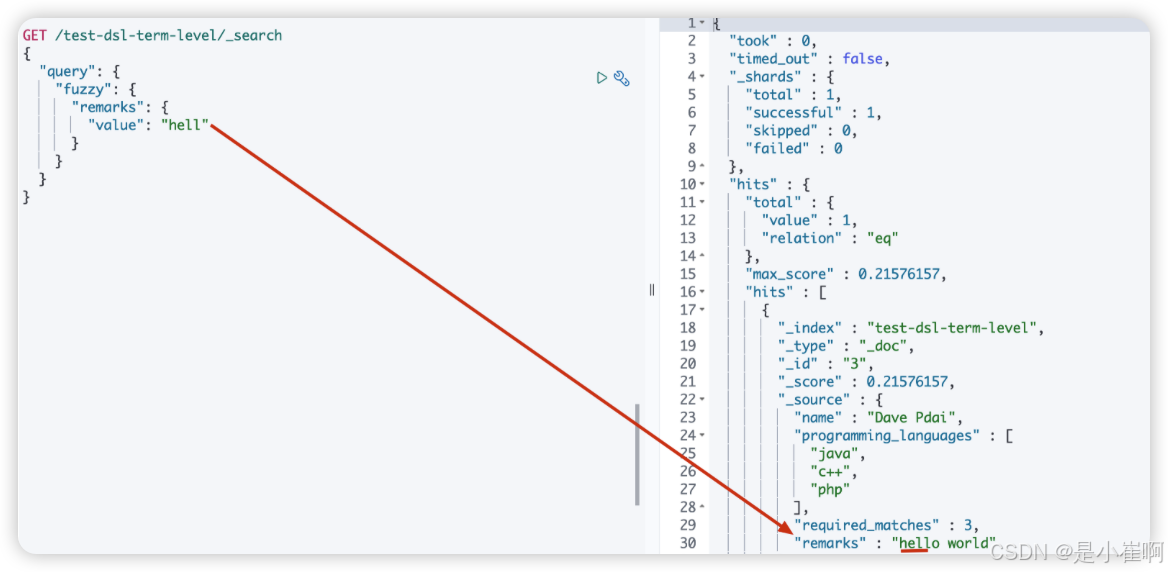
3.13.4:fuzzy转换匹配(了解)
编辑距离是将一个术语转换为另一个术语所需的一个字符更改的次数。这些更改可以包括:
- 更改字符(box → fox)
- 删除字符(black → lack)
- 插入字符(sic → sick)
- 转置两个相邻字符(act → cat)
GET /test-dsl-term-level/_search
{"query": {"fuzzy": {"remarks": {"value": "hell"}}}
}
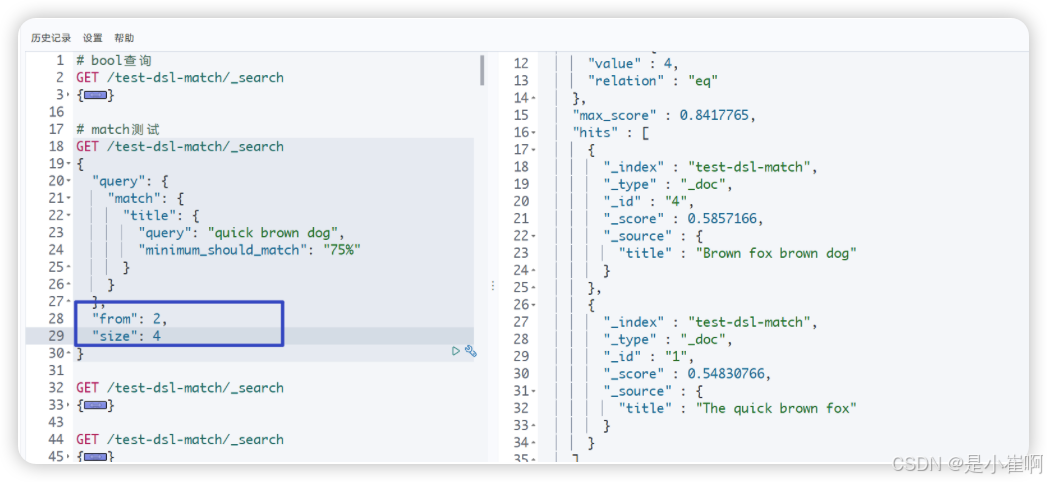
3.13.5:切片查询from / size
from & size -> limit start_index,size
GET /test-dsl-match/_search
{"query": {"match": {"title": {"query": "quick brown dog","minimum_should_match": "75%"}}},"from": 2, # 从第二条数据开始"size": 4 # 获取4条数据
}
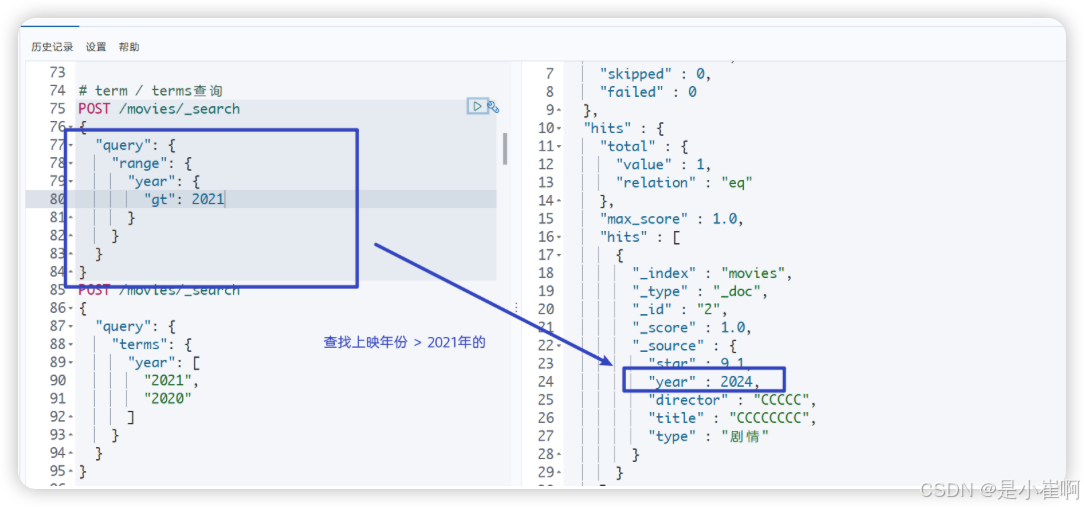
3.13.6:范围查询range
"query": {"range": {"要进行范围查询的字段": {"gte / gt": 范围下限 "lte / lt": 范围上限}}
}
-
range -> between…and
-
gt gte lte lt > >= <= <
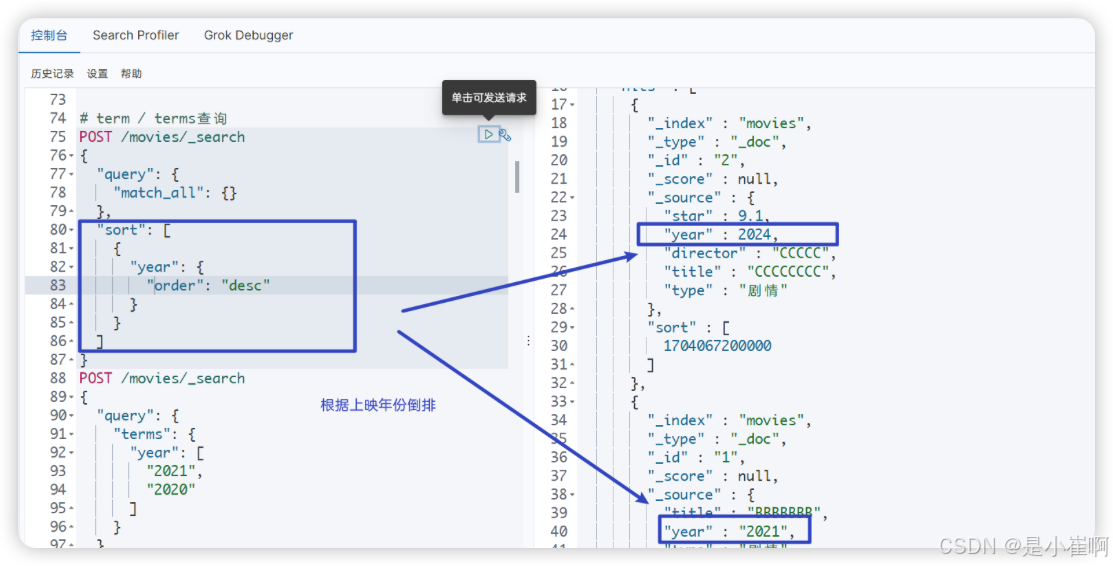
3.13.7:排序sort
sort -> 依据排序的字段 -> order【排序的方式 desc | asc】
"sort": { "要依据那个字段进行排序": {"order": "desc | asc" }
}
四:聚合查询【重点】
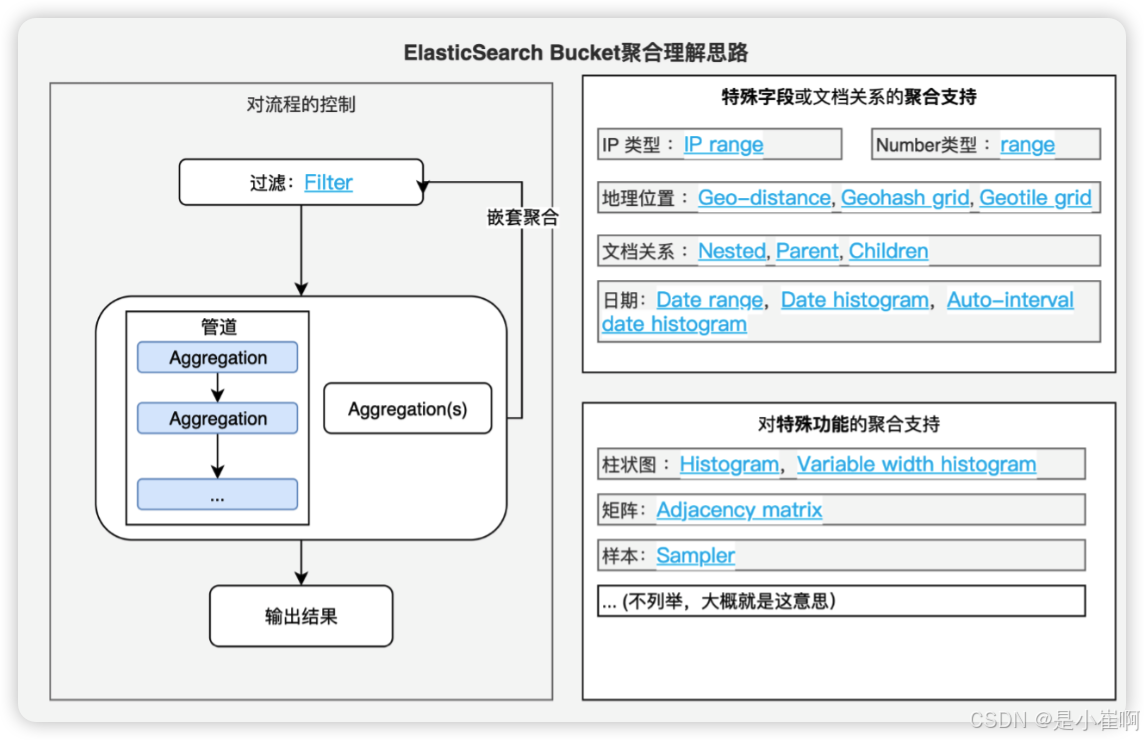
可以发现,在设计上桶聚合分成了三大类
- 对流程的控制【最常见】
- 特殊字段或者文档关系的聚合支持【IP,Number, 地理,文档关系,日期…】
- 对特殊功能的聚合支持【柱状图,矩阵,样本。。。】
// 桶聚合的结构
"aggs" : {"聚合结果的名称" : {"单个桶的类型" : {"field" : "字段"}}
}
4.1.1:对流程的控制
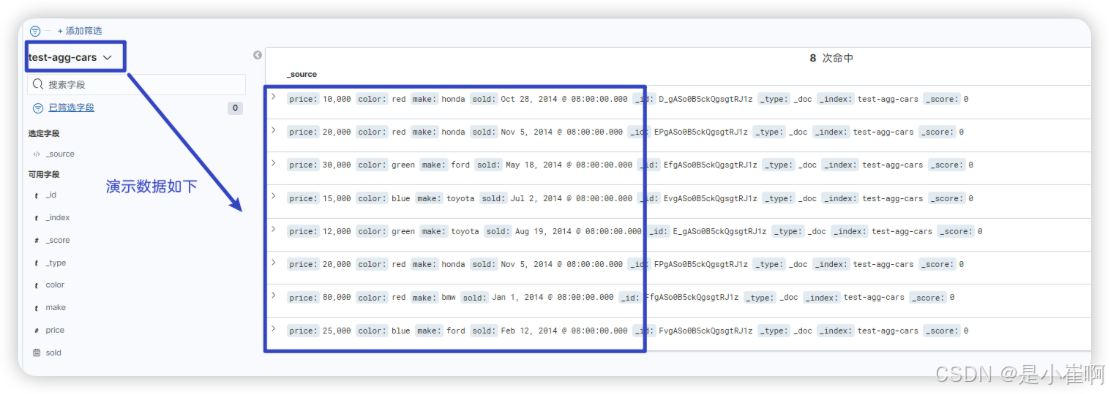
4.1.1.1:单值聚合
GET /test-agg-cars/_search
{"size" : 0, // 指定返回的hits的个数,0个就是不返回hits的条件// 聚合操作被置于顶层参数 aggs 之下(如果你愿意,完整形式 aggregations 同样有效)"aggs" : { // 聚合结果的名称"popular_colors" : { // 单个桶的类型"terms" : { "field" : "color.keyword"}}}
}
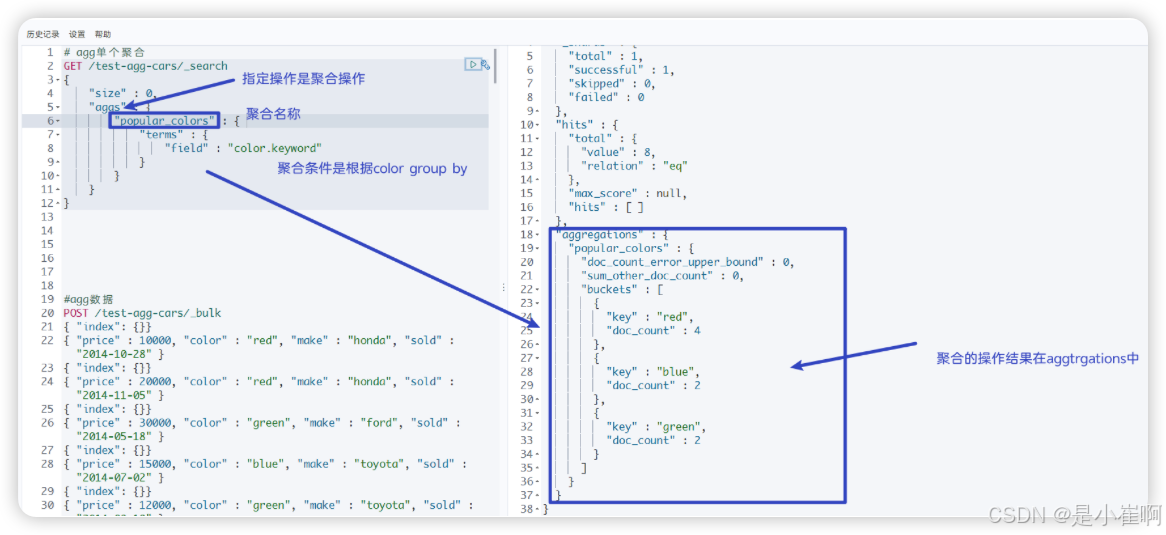
- 因为设置了 size 参数,所以不会有 hits 搜索结果返回
- popular_colors 聚合是作为 aggregations 字段的一部分被返回的
- 每个桶的key都与color字段里找到的唯一词对应。它总会包含doc_count字段,告诉我们包含该词项的文档数量
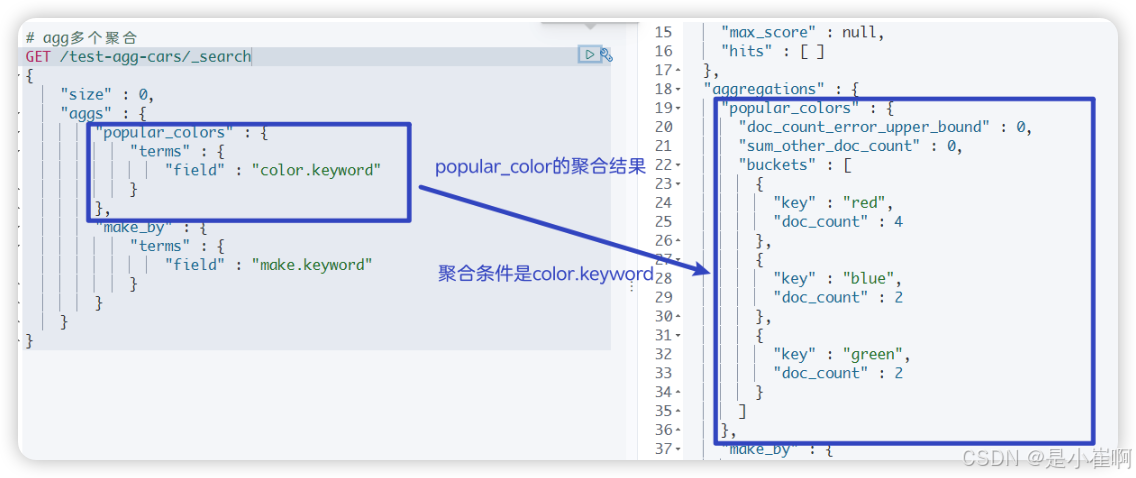
4.1.1.2:多个聚合
GET /test-agg-cars/_search
{"size" : 0, // 指定返回的hits的个数,0个就是不返回hits的条件// 聚合操作"aggs" : { "popular_colors" : { // 第一个聚合,聚合名称是popular_colors"terms" : { "field" : "color.keyword" // 聚合条件,group by(color.keyword)}},"make_by" : { // 第二个聚合,聚合名称是make_by"terms" : { "field" : "make.keyword" // 聚合条件,group by(make.keyword)}}}
}
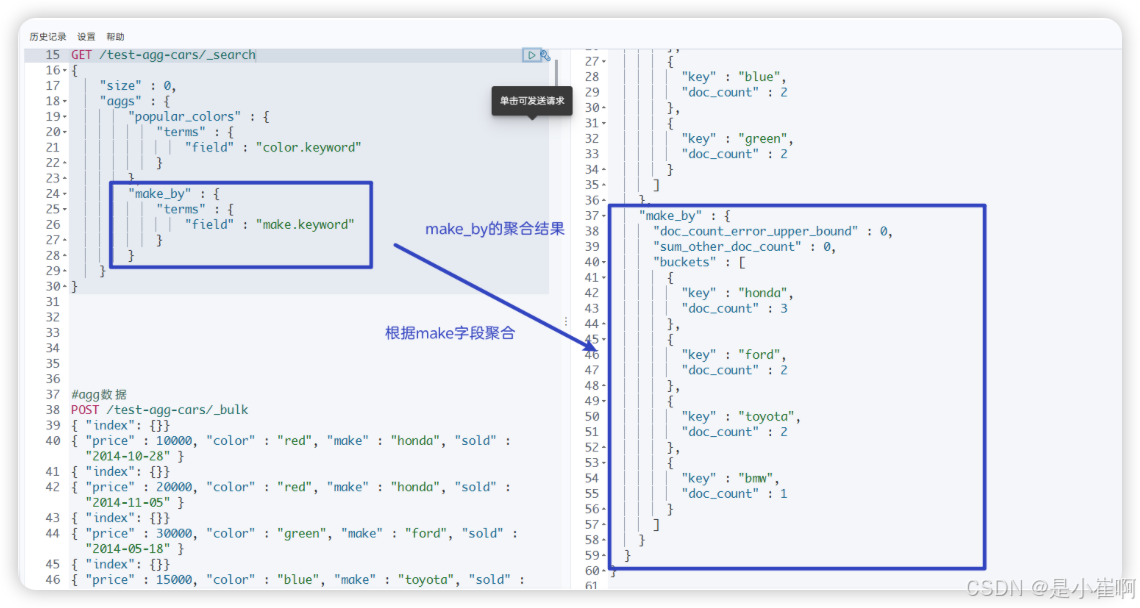
4.1.1.3:聚合嵌套
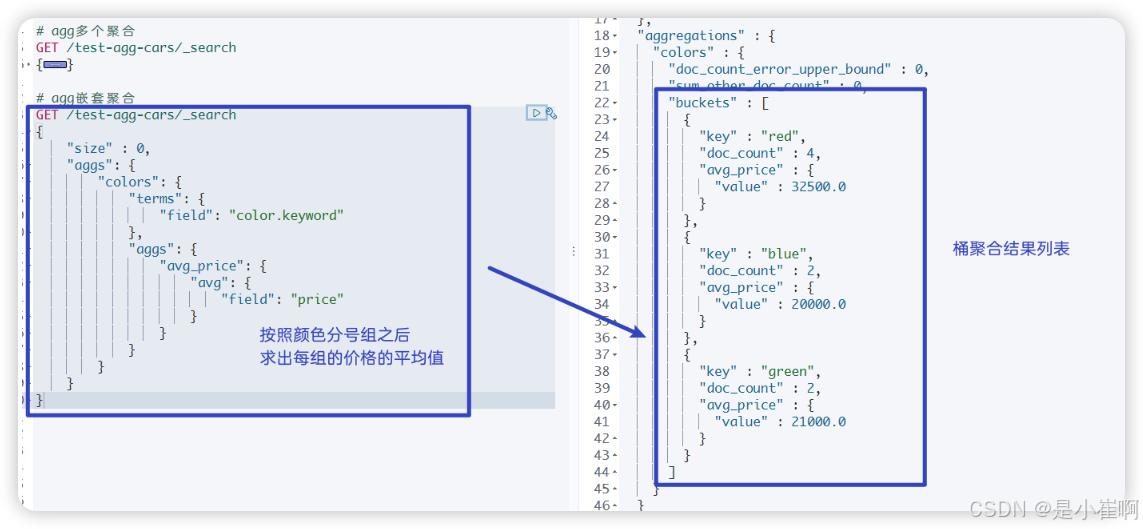
新的聚合层让我们可以将 avg 度量嵌套置于 terms 桶内。实际上,这就为每个颜色生成了平均价格
GET /test-agg-cars/_search
{"size" : 0, // 指定返回的hits的个数,0个就是不返回hits的条件"aggs": {"colors": { // 声明一个聚合名称叫做colors"terms": {"field": "color.keyword" // group by (color.keyword)},// 将每一个颜色被聚合的基础上将平均价格统计出来"aggs": { "avg_price": { "avg": {"field": "price" }}}}}
}
4.1.1.4:动态脚本的聚合(了解)
还支持一些基于脚本(生成运行时的字段)的复杂的动态聚合
GET /test-agg-cars/_search
{"runtime_mappings": {"make.length": {"type": "long", // 类型是long"script": "emit(doc['make.keyword'].value.length())" // 脚本条件是make.}},"size" : 0,"aggs": {"make_length": { // 聚合名称为make_length,生产商的名字的长度"histogram": {"interval": 1,"field": "make.length" // 指定脚本}}}
}
4.1.2:前置条件过滤filter
4.1.2.1:filter概述
在当前文档集上下文中定义与指定过滤器(Filter)匹配的所有文档的单个存储桶。
通常,这将用于将当前聚合上下文缩小到一组特定的文档
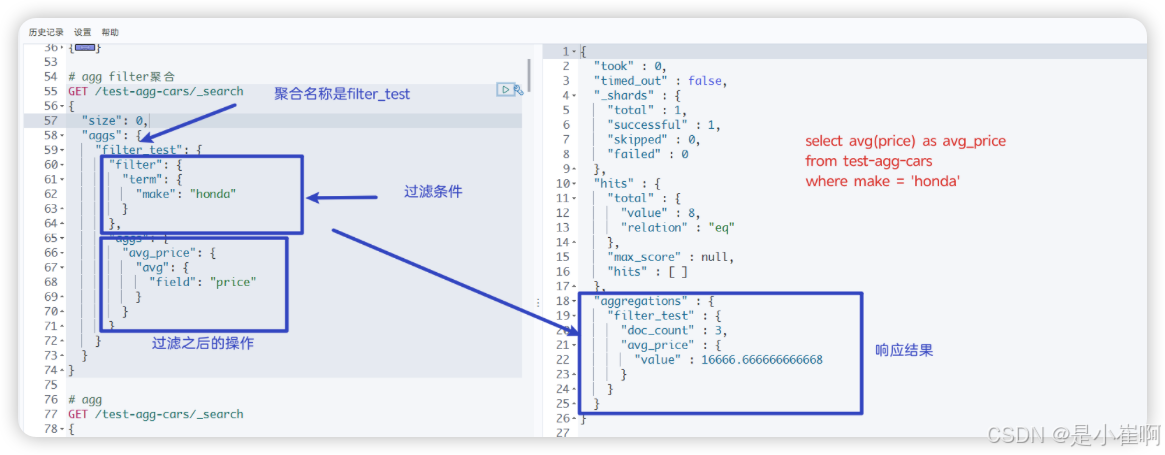
# agg filter聚合
GET /test-agg-cars/_search
{"size": 0, # 指定返回的hits的个数,0个就是不返回hits的条件"aggs": {"filter_test": { # 聚合操作的名称# ============ 下面是前置过滤条件 ========="filter": {"term": {"make": "honda" # 只对make = honda的进行聚合}},# =========== 下面的聚合操作是过滤之后的聚合操作 ==========# =========== 将当前聚合上下文缩小到一组特定的文档 ========"aggs": {"avg_price": {"avg": {"field": "price"}}}}}
}
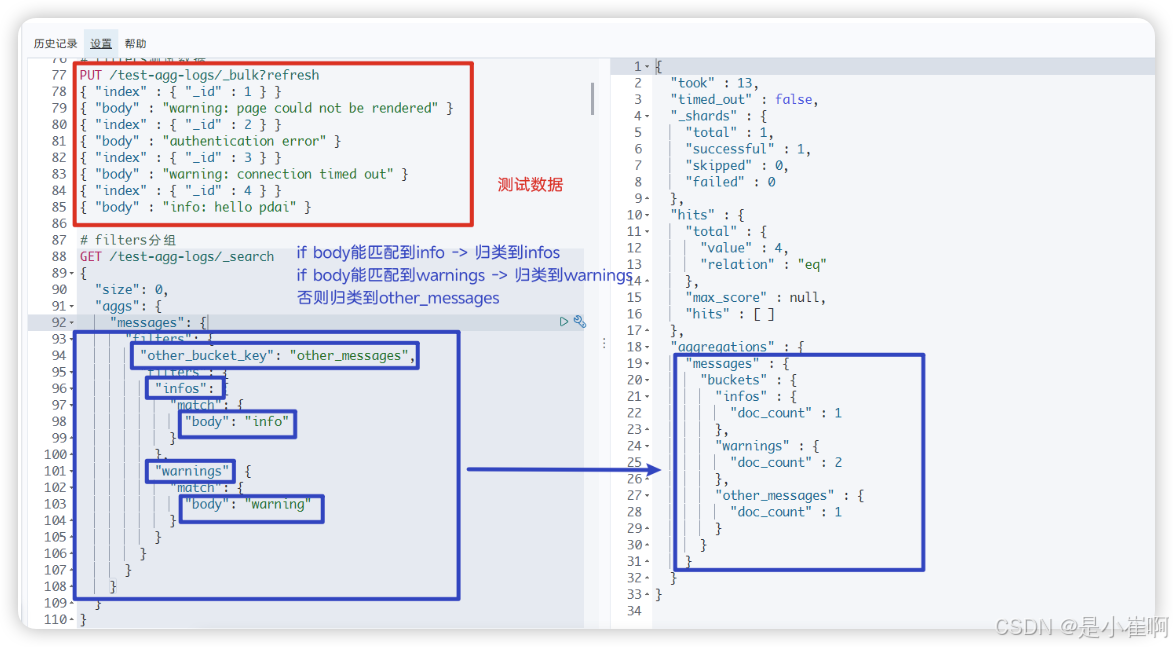
4.1.2.1:filter的分组聚合:filters
假设现在有如下的数据:
PUT /test-agg-logs/_bulk?refresh
{ "index" : { "_id" : 1 } }
{ "body" : "warning: page could not be rendered" }
{ "index" : { "_id" : 2 } }
{ "body" : "authentication error" }
{ "index" : { "_id" : 3 } }
{ "body" : "warning: connection timed out" }
{ "index" : { "_id" : 4 } }
{ "body" : "info: hello pdai" }
我们需要对包含不同日志类型的日志进行分组,这就需要filters
GET /test-agg-logs/_search
{"size": 0, // 指定返回的hits的个数,0个就是不返回hits的条件"aggs" : {"messages" : {"filters" : {"other_bucket_key": "other_messages","filters" : {"infos" : { "match" : { "body" : "info" }},"warnings" : { "match" : { "body" : "warning" }}}}}}
}
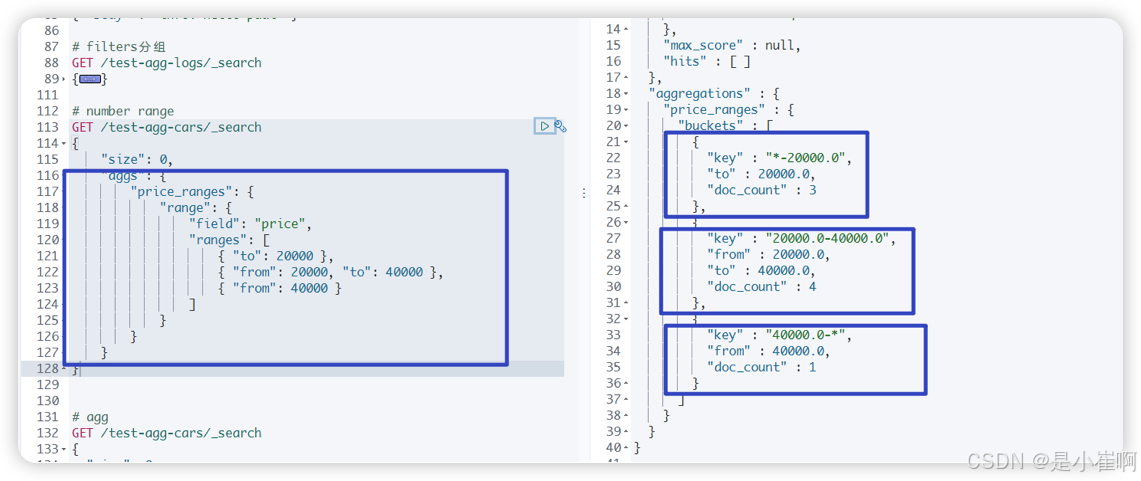
4.1.2:range聚合支持
"聚合后的name": {"range | ip_range | date_range | histrogram": {"field": "field字段","ranges": [{ "to": 20000 },{ "from": 20000, "to": 40000 },{ "from": 40000 }]}
}
4.1.2.1:对number类型聚合
基于多桶值源的聚合,使用户能够定义一组范围-每个范围代表一个桶。
在聚合过程中,将从每个存储区范围中检查从每个文档中提取的值,并“存储”相关/匹配的文档。
此聚合包括from值,但不包括to每个范围的值。【左闭右开】
GET /test-agg-cars/_search
{"size": 0, // 指定返回的hits的个数,0个就是不返回hits的条件"aggs": {"price_ranges": {"range": {"field": "price", // 根据price分桶"ranges": [{ "to": 20000 }, // [0, 20000)的一组{ "from": 20000, "to": 40000 }, // [20000, 40000)的一组{ "from": 40000 } // [40000, ∞)的一组]}}}
}
类比一下mongo
db.xxx.aggregate([{$bucket: {// 分桶操作groupBy: "$price", // 指定分桶字段boundaries: [ 0, 200, 400 ], // 制定分组的依据,0-200一组,200-400一组,其他一组default: "Other", // 如果没有price字段,将会默认分到Other中output: { // 指定输出的内容"count": { $sum: 1 }, // 统计每组的个数,作为count字段进行返回"titles" : { $push: "$title" } // 将本组的各个title字段放入titles中返回} }}
])
4.1.2.2:对ip类型聚合
针对IP相关的字段,es提供了特殊的ip_range对其进行处理
ip范围查询ip_range
GET /ip_addresses/_search
{"size": 10, "aggs": {"ip_ranges": {"ip_range": {"field": "ip","ranges": [{ "to": "10.0.0.5" },{ "from": "10.0.0.5" }]}}}
}
CIDR Mask分组
GET /ip_addresses/_search
{"size": 0,"aggs": {"ip_ranges": {"ip_range": {"field": "ip","ranges": [{ "mask": "10.0.0.0/25" },{ "mask": "10.0.0.127/25" }]}}}
}
增加key显示
GET /ip_addresses/_search
{"size": 0,"aggs": {"ip_ranges": {"ip_range": {"field": "ip","ranges": [{ "to": "10.0.0.5" },{ "from": "10.0.0.5" }],"keyed": true // here}}}
}
自定义key显示
GET /ip_addresses/_search
{"size": 0,"aggs": {"ip_ranges": {"ip_range": {"field": "ip","ranges": [{ "key": "infinity", "to": "10.0.0.5" },{ "key": "and-beyond", "from": "10.0.0.5" }],"keyed": true}}}
}
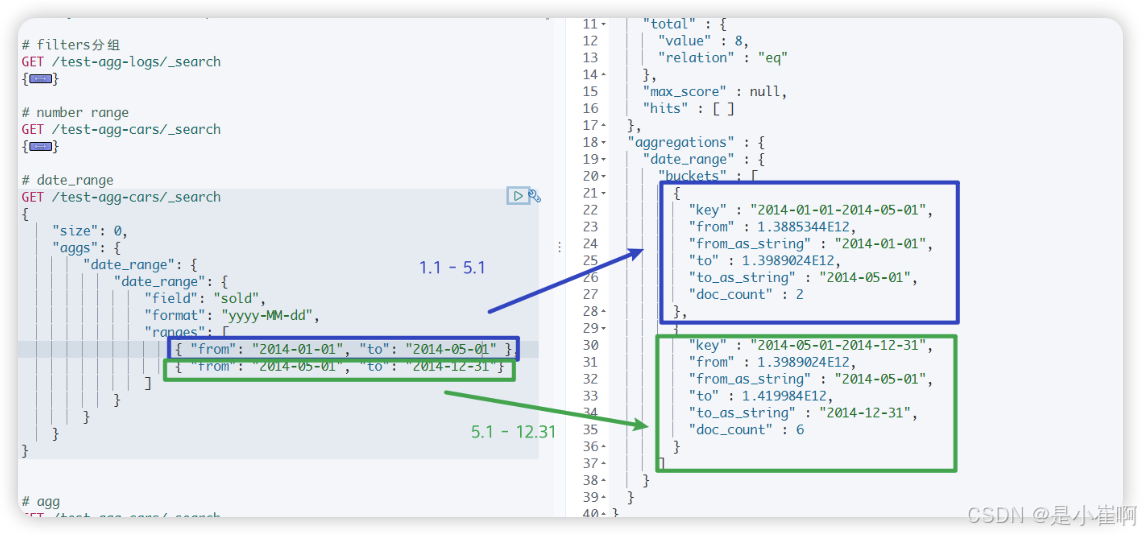
4.1.2.3:对日期date的类型聚合
对日期的聚合方面,es也提供了对应date_range方便我们在指定的日期区间中进行相应的检索
GET /test-agg-cars/_search
{"size": 0, # 指定返回的hits的个数,0个就是不返回hits的条件"aggs": {"date_range": { # 聚合名称 = date_range "date_range": {"field": "sold","format": "yyyy-MM-dd", # 日期格式"ranges": [ # 分桶{ "from": "2014-01-01", "to": "2014-05-01" }, { "from": "2014-05-01", "to": "2014-12-31"} ]}}}
}
4.2:指标聚合
4.2.1:单值指标分析
4.2.1.1:avg平均值
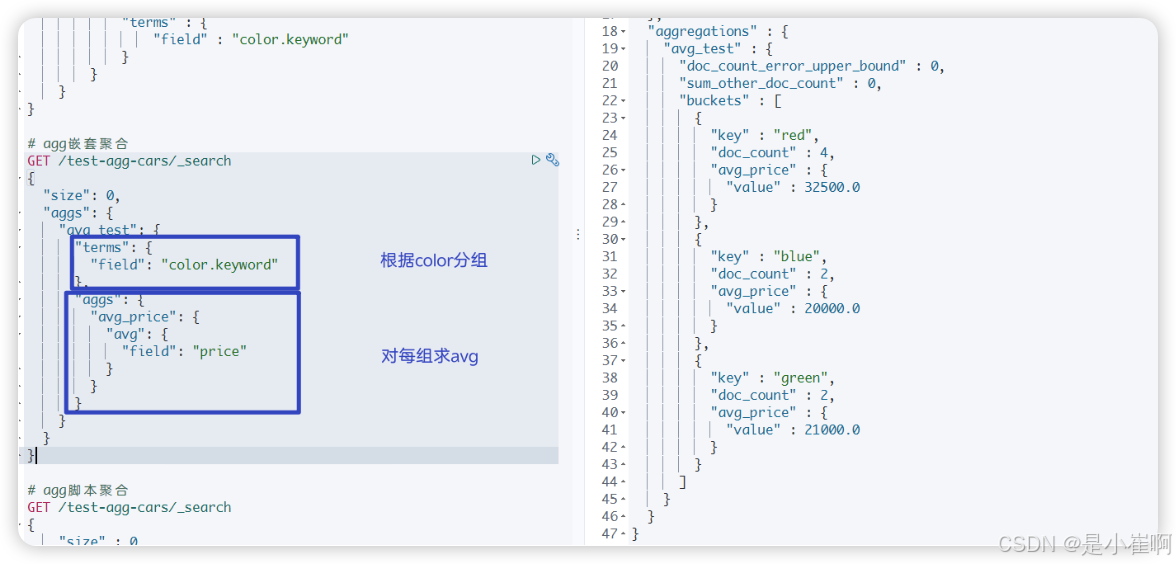
# agg嵌套聚合
GET /test-agg-cars/_search
{"size": 0, # 不显示hits值"aggs": {"avg_test": { # 聚合名称"terms": {"field": "color.keyword" # 根据color分组},# 对每组执行指标聚合"aggs": {"avg_price": {"avg": {"field": "price" # 对每组的price求平均值}}}}}
}
⚠️ 如果对于非数值字段进行avg操作将会报错
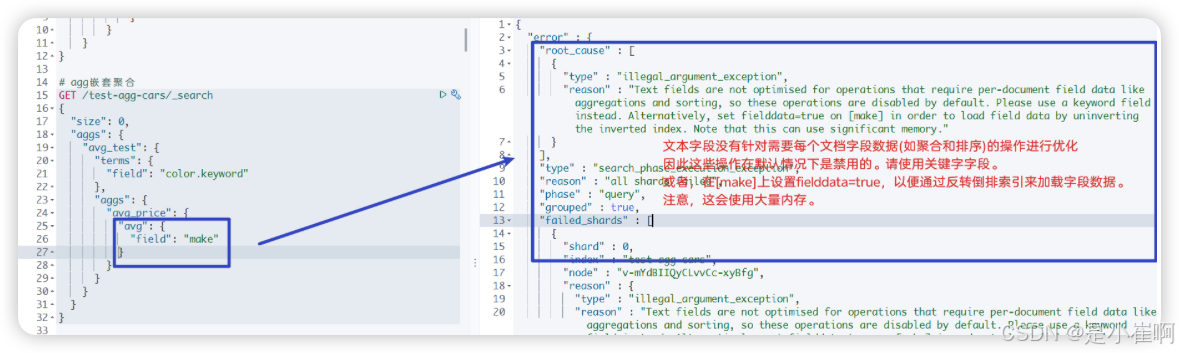
4.2.1.2:最大值,最小值
和avg同理
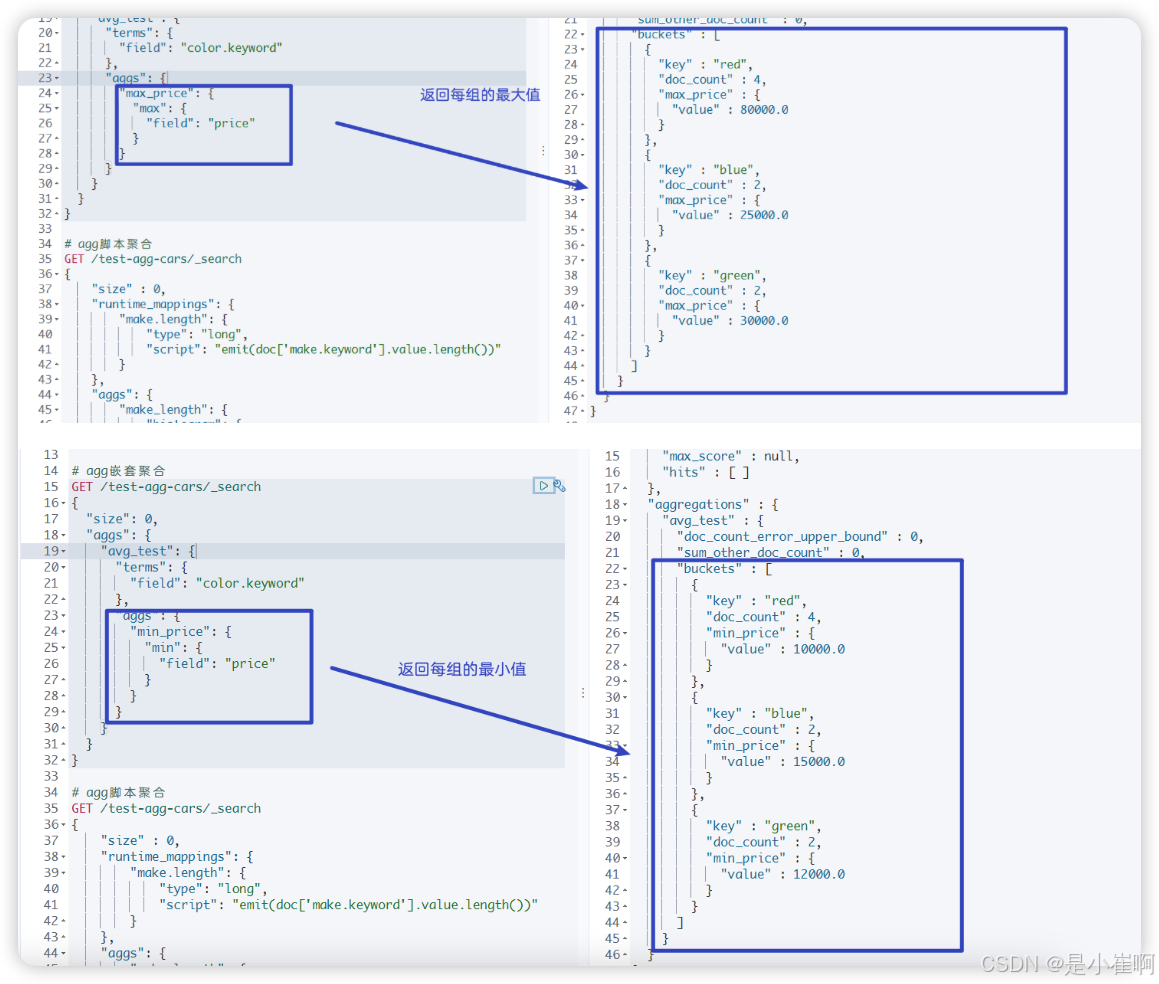
4.2.1.3:sum总和
和avg同理
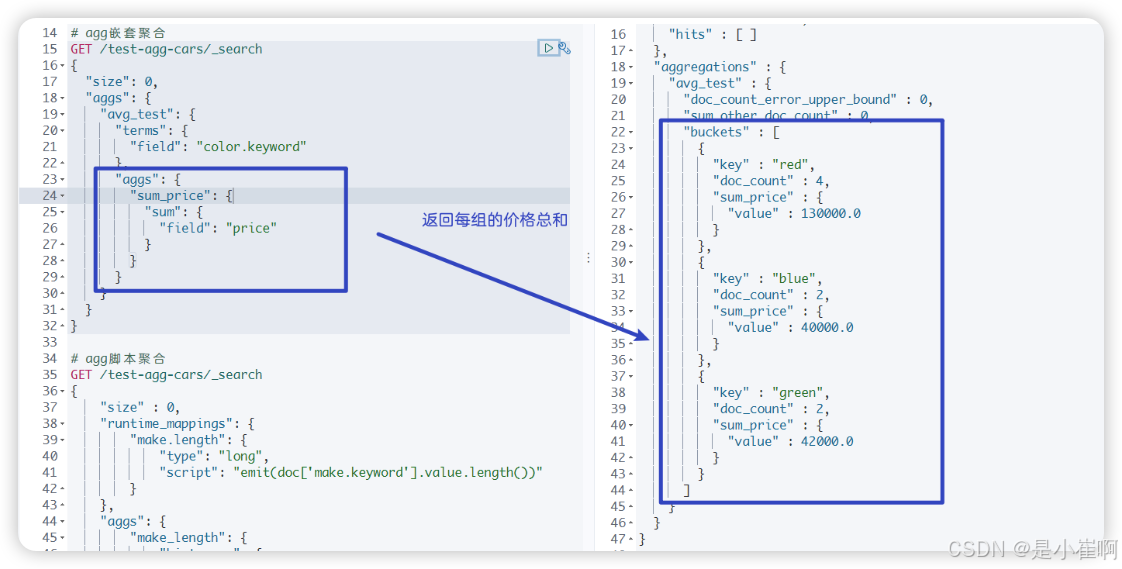
4.2.1.4:count个数
count可以施加在任何字段上,表示当前分组的个数

4.2.2:多值指标分析
GET /test-agg-cars/_search
{"size": 0, # 指定返回的hits的个数,0个就是不返回hits的条件"aggs": {"price_stats": { # 聚合名称"stats": { # 多值指标分析"field": "price" # 针对分析的字段是price字段}}}
}

相关文章:
ES02 - ES语句
ES语句 文章目录 ES语句一:连接和基本的使用1:显示详细信息2:输出可显示列3:查看分片 二:Http接口 - 索引(数据库)的增删改2.1:插入数据2.2:删除数据2.3:更新数据2.3.1:P…...

C++ 学生成绩管理系统
一、项目背景与核心需求 成绩管理系统是高校教学管理的重要工具,本系统采用C++面向对象编程实现,主要功能模块包括: 学生信息管理(学号/姓名/3门课程成绩) 成绩增删改查(CRUD)操作 数据持久化存储 统计分析与报表生成 用户友好交互界面 二、系统架构设计 1. 类结构设计 …...

项目管理工具 Maven
目录 1.Maven的概念 1.1什么是Maven 1.2什么是依赖管理 1.3什么是项目构建 1.4Maven的应用场景 1.5为什么使用Maven 1.6Maven模型 2.初识Maven 2.1Maven安装 2.1.1安装准备 2.1.2Maven安装目录分析 2.1.3Maven的环境变量 2.2Maven的第一个项目 2.2.1按照约…...

设计心得——分层和划分模块
一、分层 在实际的设计开发过程中,对于稍微大一些的项目,基本都涉及到分层。什么是分层呢?其实非常简单,就是利用某种逻辑或域的范围等把整个项目划分成多个层次。它们之间通过接口(可能是简单的函数接口也可以是服务…...

uniapp使用蓝牙,usb,局域网,打印机打印
使用流程(支持安卓和iOS) 引入SDK 引入原生插件包地址如下 https://github.com/oldfive20250214/UniPrinterDemo 连接设备 安卓支持经典蓝牙、ble蓝牙、usb、局域网(参考API) iOS支持ble蓝牙、局域网(参考API&…...

PQL查询和监控各类中间件
1 prometheus的PQL查询 1.1 Metrics数据介绍 prometheus监控中采集过来的数据统一称为Metrics数据,其并不是代表具体的数据格式,而是一种统计度量计算单位当需要为某个系统或者某个服务做监控时,就需要使用到 metrics prometheus支持的met…...
day1 redis登入指令
[rootlocalhost data]# redis-cli -h ip -p 6379 -a q123q123 Warning: Using a password with -a or -u option on the command line interface may not be safe. ip:6379> 以上, Bigder...

2025 年 AI 网络安全预测
🍅 点击文末小卡片 ,免费获取网络安全全套资料,资料在手,涨薪更快 微软和 OpenAI 宣布延长战略合作伙伴关系,加强对推进人工智能技术的承诺,这表明强大的 AI 将在未来占据主导地位。 随着人工智能 &#x…...
[Windows] 多系统键鼠共享工具 轻松跨系统控制多台电脑
参考原文:[Windows] 多系统键鼠共享工具 轻松跨系统控制多台电脑 还在为多台电脑需要多套键盘鼠标而烦恼吗?是不是在操控 Windows、macOS、Linux 不同系统电脑时手忙脚乱?现在,这些问题通通能解决!Deskflow 软件闪亮登…...

单片机的发展
一、引言 单片机自诞生以来,经历了四十多年的风风雨雨,从最初的工业控制逐步扩展到家电、通信、智能家居等各个领域。其发展过程就像是一场精彩的冒险,每一次技术的革新都像是在未知的海域中开辟新的航线。 二、单片机的发展历程 ÿ…...

Spring 构造器注入和setter注入的比较
一、比较说明 在 Spring 框架中,构造器注入(Constructor Injection)和 Setter 注入(Setter Injection)是实现依赖注入(DI)的两种主要方式。它们的核心区别在于依赖注入的时机、代码设计理念以及…...

uploadlabs通关思路
目录 靶场准备 复现 pass-01 代码审计 执行逻辑 文件上传 方法一:直接修改或删除js脚本 方法二:修改文件后缀 pass-02 代码审计 文件上传 1. 思路 2. 实操 pass-03 代码审计 过程: 文件上传 pass-04 代码审计 文件上传 p…...

迷你世界脚本自定义UI接口:Customui
自定义UI接口:Customui 彼得兔 更新时间: 2024-11-07 15:12:42 具体函数名及描述如下:(除前两个,其余的目前只能在UI编辑器内部的脚本使用) 序号 函数名 函数描述 1 openUIView(...) 打开一个UI界面(注意…...
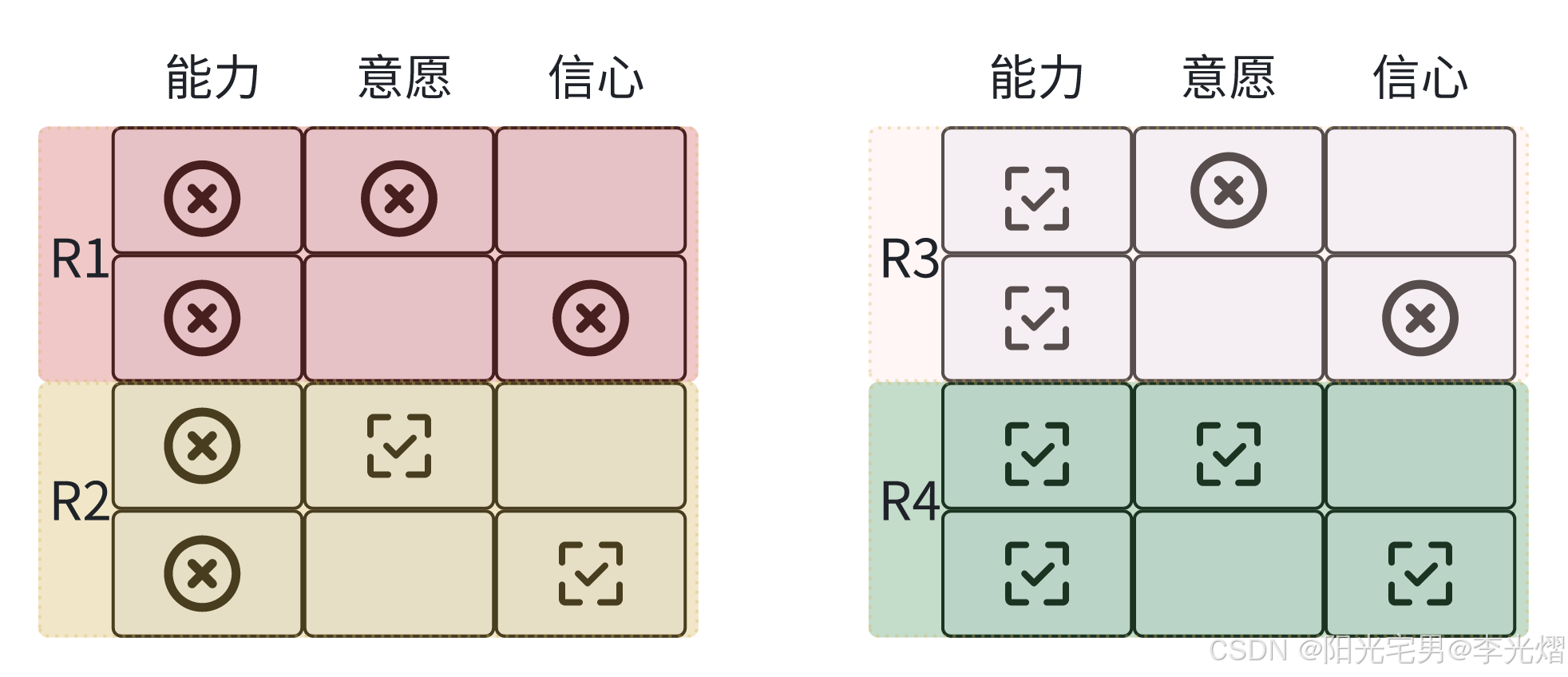
【情境领导者】评估情境——准备度水平
本系列是看了《情境领导者》一书,结合自己工作的实践经验所做的学习笔记。 在文章【情境领导者】评估情境——什么是准备度-CSDN博客我们提到准备度是由能力和意愿两部分组成的。 准备度水平 而我们要怎么去评估准备度呢?准备度水平是指人们在每项工作中…...

2025 ubuntu24.04系统安装docker
1.查看ubuntu版本(Ubuntu 24.04 LTS) rootmaster:~# cat /etc/os-release PRETTY_NAME"Ubuntu 24.04 LTS" NAME"Ubuntu" VERSION_ID"24.04" VERSION"24.04 LTS (Noble Numbat)" VERSION_CODENAMEnoble IDubun…...

Android中AIDL和HIDL的区别
在Android中,AIDL(Android Interface Definition Language) 和 HIDL(HAL Interface Definition Language) 是两种用于定义跨进程通信接口的语言。AIDL 是 Android 系统最早支持的 IPC(进程间通信࿰…...

通过数据库网格架构构建现代分布式数据系统
在当今微服务驱动的世界中,企业在跨分布式系统管理数据方面面临着越来越多的挑战。数据库网格架构已成为应对这些挑战的强大解决方案,它提供了一种与现代应用架构相匹配的分散式数据管理方法。本文将探讨数据库网格架构的工作原理,以及如何使…...

Python基于Django的医用耗材网上申领系统【附源码、文档说明】
博主介绍:✌Java老徐、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇&…...

Python爬虫实战:一键采集电商数据,掌握市场动态!
电商数据分析是个香饽饽,可市面上的数据采集工具要不贵得吓人,要不就是各种广告弹窗。干脆自己动手写个爬虫,想抓啥抓啥,还能学点技术。今天咱聊聊怎么用Python写个简单的电商数据爬虫。 打好基础:搞定请求头 别看爬虫…...

STM32之I2C硬件外设
注意:硬件I2C的引脚是固定的 SDA和SCL都是复用到外部引脚。 SDA发送时数据寄存器的数据在数据移位寄存器空闲的状态下进入数据移位寄存器,此时会置状态寄存器的TXE为1,表示发送寄存器为空,然后往数据控制寄存器中一位一位的移送数…...
)
用两个三极管+稳压管,手把手教你搭一个简易5V LDO(附原理图、PCB与实测避坑)
用两个三极管稳压管搭建简易5V LDO:从原理图到实测的完整避坑指南 在电子设计领域,线性稳压器(LDO)是电源管理的基础模块。虽然市面上有大量成熟的LDO芯片,但用分立元件搭建一个简易LDO仍然是理解电源原理的绝佳实践。本文将带你用最常见的SS…...

Arm Neoverse CMN-650一致性网格网络架构与配置解析
1. Arm Neoverse CMN-650 一致性网格网络架构解析在现代多核处理器设计中,一致性网格网络(Coherent Mesh Network)已成为解决核心间通信瓶颈的关键技术。Arm Neoverse CMN-650作为第二代一致性互连解决方案,其架构设计体现了三个核…...

JL-01多通道温湿度记录仪:环境监测的得力助手
在农业、林业与地质研究等领域,环境因子的精准监测是科研与生产决策的核心依据。JL-01多通道温湿度记录仪凭借小巧便携的机身、强大的功能配置与灵活的定制化服务,成为环境数据采集的得力工具,为各类场景下的温湿度监测提供可靠支持。一、功能…...

体验Taotoken官方价折扣与Token Plan带来的成本优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken官方价折扣与Token Plan带来的成本优势 1. 引言:从按需付费到计划性支出 对于频繁调用大模型API的开发者…...

Steam创意工坊模组下载终极指南:轻松获取1000+游戏模组的完整解决方案
Steam创意工坊模组下载终极指南:轻松获取1000游戏模组的完整解决方案 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为无法下载Steam创意工坊模组而烦恼吗&…...

NotebookLM智能体插件开发:连接AI笔记与外部工具的实现指南
1. 项目概述:当AI笔记助手学会“动手”最近在折腾AI应用开发的朋友,可能都注意到了GitHub上一个挺有意思的项目:amp-rh/notebooklm-agent-plugin。乍一看名字,它像是Google那个实验性AI笔记工具NotebookLM的一个插件。但如果你深入…...

ROFL-Player:打破英雄联盟回放观看壁垒的革命性工具
ROFL-Player:打破英雄联盟回放观看壁垒的革命性工具 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 你是否曾经因为游戏版本…...

从PAM到BanditPAM:k-Medoids聚类算法的演进、优化与实战选型指南
1. 为什么需要k-Medoids算法? k-Means算法大家应该都不陌生,它简单高效,是很多数据科学项目的入门首选。但我在实际项目中经常遇到这样的情况:当数据集中存在异常值或噪声点时,k-Means的表现就会大打折扣。这是因为k-M…...

从静态分析到代码自愈:构建自动化自我审查工具提升代码质量
1. 项目概述:从“自我审视”到“代码自愈”的工程实践在软件开发的日常中,我们常常会陷入一种“当局者迷”的困境:自己写的代码,怎么看都觉得逻辑清晰、结构完美,但一旦交给同事评审或者上线运行,各种潜在的…...
的情况.txt)