通过数据库网格架构构建现代分布式数据系统
在当今微服务驱动的世界中,企业在跨分布式系统管理数据方面面临着越来越多的挑战。数据库网格架构已成为应对这些挑战的强大解决方案,它提供了一种与现代应用架构相匹配的分散式数据管理方法。本文将探讨数据库网格架构的工作原理,以及如何使用 PostgreSQL 和 MongoDB 等流行数据库实施该架构。
究竟什么是数据库网格架构?
数据库网格架构是一种分散的数据基础架构管理方法,不同的数据库作为一个有凝聚力的系统协同工作,同时保持独立运行。与传统的单体数据库系统不同,数据库网格结构将数据管理分散到多个专业数据库中,每个数据库都服务于特定的业务领域或用例。这种方法使企业能够保持灵活性,同时确保整个系统的数据一致性和可访问性。
核心原则和组成部分
数据库网格架构的核心是面向领域的数据所有权原则。每个业务领域都对其数据和数据库选择拥有控制权,使团队能够就数据结构和管理方法做出独立决策。这种自主性与确保全系统一致性的标准化实践相平衡。
该架构还强调自助式基础设施,可根据预定义标准自动调配数据库资源。这种自动化可降低运营开销,同时在整个网状结构中保持一致的安全和性能标准。
互操作层是一个重要组成部分,可实现不同数据库系统之间的无缝通信。该层处理标准化的数据访问协议,实施一致的安全策略,并管理整个网状系统中的元数据。通过这一层,不同的数据库系统可以有效地协同工作,同时保持各自的专业角色。
通过流行数据库实施数据库网格
一个成功的数据库网格实施方案会将各种类型的数据库结合起来,以满足不同的需求:
- PostgreSQL 通常是事务数据的基础,提供强大的 ACID 合规性、复杂的分区功能和高级复制功能。此外,PostgreSQL 的许多扩展功能使其在网格结构中特别有价值,因为在网格结构中,灵活性和可扩展性至关重要。
- 对于面向文档的数据,MongoDB 凭借其灵活的模式设计和横向扩展功能提供了出色的功能。它对 JSON 文档的本机支持和内置的分片功能使其成为处理网格结构中各种不断变化的数据结构的理想选择。
- 高性能缓存需求通常使用 Redis 来解决,Redis 擅长内存数据存储和实时操作。它的 pub/sub 功能和可扩展的集群模式使其成为管理网格内快速变化数据的绝佳选择。
- 搜索功能通常使用 Elasticsearch 实现,它提供强大的全文搜索功能和分析功能。它的分布式架构与网格概念自然吻合,可在整个系统中实现高效的数据处理。
实施和管理提示
在实施数据库网格时,企业应从适度的范围开始,在扩展之前先关注几个定义明确的领域。这种方法允许团队在扩展架构之前验证模式和实践。标准化在成功实施中起着至关重要的作用,尤其是在命名约定、安全实践和数据所有权方面。
持续监控和优化对保持网格性能至关重要。团队应跟踪关键指标,监控数据一致性,并根据观察到的使用模式定期进行优化。 这种持续关注可确保网格随着业务需求的变化而保持高效和有效。
数据库网格的复杂性需要复杂的管理工具,这一点不足为奇。Navicat 通过为网格架构中常用的大多数数据库提供全面支持而脱颖而出。通过其界面,团队可以跨不同的数据库系统执行可视化数据库设计、查询优化、数据同步和性能监控。这种统一的管理方法大大简化了复杂网格架构的操作。
结语
数据库网格结构是处理分布式系统中复杂数据需求的一种先进方法。通过深思熟虑地结合不同的数据库技术,并使用 Navicat 等专业级工具对其进行管理,企业可以构建灵活、可扩展的数据基础架构,以满足现代业务需求,同时保持可管理性和性能。
相关文章:

通过数据库网格架构构建现代分布式数据系统
在当今微服务驱动的世界中,企业在跨分布式系统管理数据方面面临着越来越多的挑战。数据库网格架构已成为应对这些挑战的强大解决方案,它提供了一种与现代应用架构相匹配的分散式数据管理方法。本文将探讨数据库网格架构的工作原理,以及如何使…...

Python基于Django的医用耗材网上申领系统【附源码、文档说明】
博主介绍:✌Java老徐、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇&…...

Python爬虫实战:一键采集电商数据,掌握市场动态!
电商数据分析是个香饽饽,可市面上的数据采集工具要不贵得吓人,要不就是各种广告弹窗。干脆自己动手写个爬虫,想抓啥抓啥,还能学点技术。今天咱聊聊怎么用Python写个简单的电商数据爬虫。 打好基础:搞定请求头 别看爬虫…...

STM32之I2C硬件外设
注意:硬件I2C的引脚是固定的 SDA和SCL都是复用到外部引脚。 SDA发送时数据寄存器的数据在数据移位寄存器空闲的状态下进入数据移位寄存器,此时会置状态寄存器的TXE为1,表示发送寄存器为空,然后往数据控制寄存器中一位一位的移送数…...

【C++】中的赋值初始化和直接初始化的区别
在C中,赋值初始化(也称为拷贝初始化)和直接初始化(也称为构造初始化)虽然常常产生相同的结果,但在某些情况下它们有不同的含义和行为。 赋值初始化(Copy Initialization) 使用等号…...
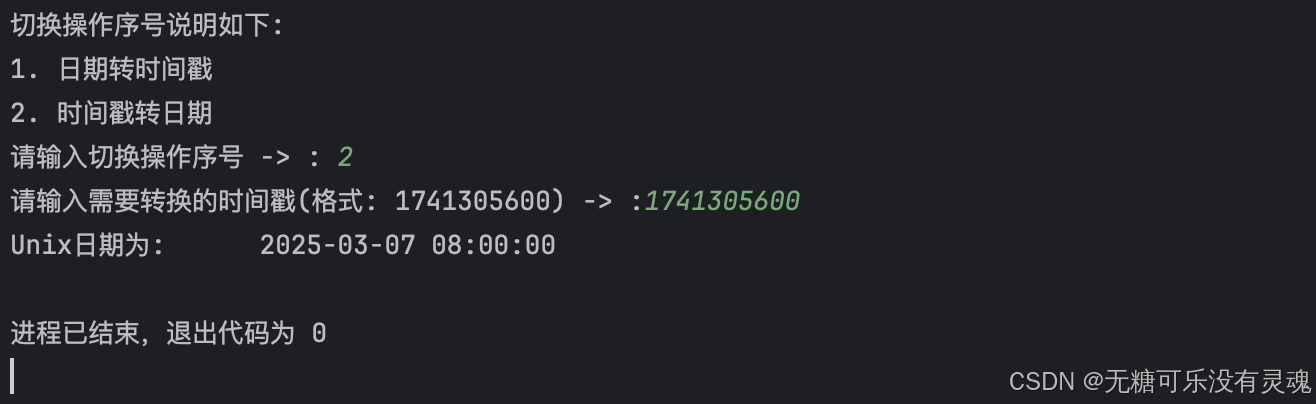
Python ❀ Unix时间戳转日期或日期转时间戳工具分享
设计一款Unix时间戳和日期转换工具,其代码如下: from datetime import datetimeclass Change_Date_Time(object):def __init__(self, date_strNone, date_numNone):self.date_str date_strself.date_num date_num# 转时间戳def datetime2timestamp(s…...

本地部署Dify及避坑指南
Dify作为开源的大模型应用开发平台,支持本地私有化部署,既能保障数据安全,又能实现灵活定制。但对于新手而言,从环境配置到服务启动可能面临诸多挑战。本文结合实战经验,手把手教你从零部署Dify,并总结高频…...

大白话CSS 优先级计算规则的详细推导与示例
大白话CSS 优先级计算规则的详细推导与示例 答题思路 引入概念:先通俗地解释什么是 CSS 优先级,让读者明白为什么要有优先级规则,即当多个 CSS 样式规则作用于同一个元素时,需要确定哪个规则起作用。介绍优先级的分类࿱…...
非真实感渲染(Non-Photorealistic Rendering, NPR))
OpenCV计算摄影学(19)非真实感渲染(Non-Photorealistic Rendering, NPR)
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 非真实感渲染(Non-Photorealistic Rendering, NPR)是一种计算机图形学技术,旨在生成具有艺术风格或其他非现实…...

深度学习(斋藤)学习笔记(五)-反向传播2
上一篇关于反向传播的代码仅支持单变量的梯度计算,下面我们将扩展代码使其支持多个输入/输出。增加了对多输入函数(如 Add),以实现的计算。 1.关于前向传播可变长参数的改进-修改Function类 修改方法: Function用于对…...

数据库基础练习1
目录 1.创建数据库和表 2.插入数据 创建一个数据库,在数据库种创建一张叫heros的表,在表中插入几个四大名著的角色: 1.创建数据库和表 #创建表 CREATE DATABASE db_test;#查看创建的数据库 show databases; #使用db_test数据库 USE db_te…...

TypeError: Cannot create property ‘xxx‘ on string ‘xxx‘
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》、《前端求职突破计划》 🍚 蓝桥云课签约作者、…...

极狐GitLab 17.9 正式发布,40+ DevSecOps 重点功能解读【三】
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 学习极狐GitLab 的相关资料: 极狐GitLab 官网极狐…...
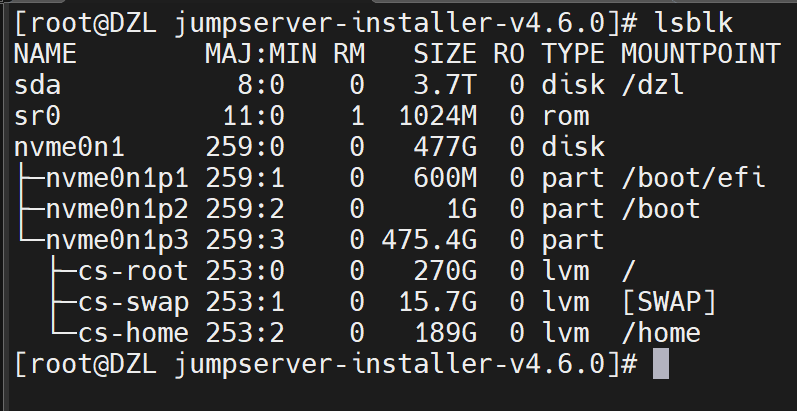
lsblk命令linux查询设备信息
lsblk命令是Linux中用于列出所有可用块设备信息的工具,它能够显示设备之间的依赖关系,但不会列出RAM盘的信息。块设备包括硬盘、闪存盘、CD-ROM等。lsblk命令包含在util-linux包中,该命令的常用参数包括: -d:仅列出磁盘…...

【智能体架构:Agent】LangChain智能体类型ReAct、Self-ASK的区别
1. 什么是智能体 将大语言模型作为一个推理引擎。给定一个任务, 智能体自动生成完成任务所需步骤, 执行相应动作(例如选择并调用工具), 直到任务完成。 2. 先定义工具:Tools 可以是一个函数或三方 API也…...

鸿蒙开发:弹性布局Flex
前言 代码案例基于Api13。 正在开发一个搜索组件,其中一个功能是针对历史搜索的内容进行展示,由于搜索的内容长度不一,需要进行流式布局展示,效果如下: 以上的效果,相信大家在很多的应用里或多或少都见到过…...

【DeepSeek】5分钟快速实现本地化部署教程
一、快捷部署 (1)下载ds大模型安装助手,下载后直接点击快速安装即可。 https://file-cdn-deepseek.fanqiesoft.cn/deepseek/deepseek_28348_st.exe (2)打开软件,点击立即激活 (3)选…...

易基因特异性R-loop检测整体研究方案
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。 01.技术简述 R-loop是由DNA:RNA 杂交体和被置换的单链DNA组成的三链核酸结构,广泛参与基因转录、表观遗传调控及DNA修复等关键生物学过程。异常的R-loop积累会导致基因组不稳…...
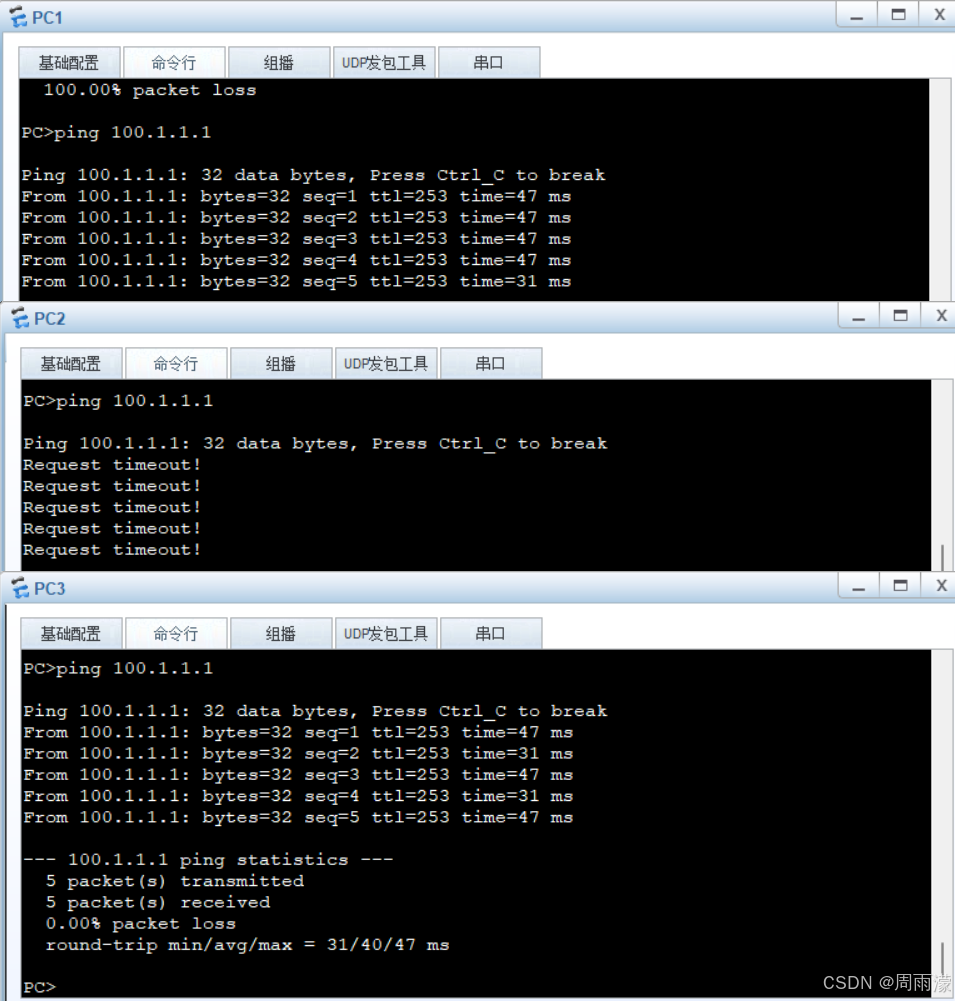
虚拟系统配置案例
安全策略要求: 1、只存在一个公网IP地址,公司内网所有部门都需要借用同一个接口访问外网 2、财务部禁止访问Internet,研发部门只有部分员工可以访问Internet,行政部门全部可以访问互联网 3、为三个部门的虚拟系统分配相同的资源类…...

C语言【进阶篇】之结构体 —— 从基础声明到复杂应用的进阶之路
目录 🚀前言✍️结构体类型的声明💯结构体定义💯结构的特殊声明 🦜结构的自引用💻结构体内存对齐💯对齐规则💯为什么存在内存对齐💯修改默认对齐数 🐍结构体传参…...

加油卡小程序玩法全解析:刚需场景破局,从充值裂变到合规运营全攻略
国内私家车与新能源车主群体持续扩容,加油、充电作为高频刚性消费场景,自带稳定流量与强付费意愿,加油卡小程序凭借轻量化、易传播、直达用户的优势,成为加油站、第三方车主服务平台、车企布局私域流量的核心载体。不同于潮玩等娱…...

Swift-All镜像入门:手把手教你快速部署,无需配置轻松上手
Swift-All镜像入门:手把手教你快速部署,无需配置轻松上手 想体验600大模型和300多模态模型的强大能力,却被复杂的安装配置劝退?Swift-All镜像就是为你准备的"开箱即用"解决方案。本文将带你从零开始,一步步…...

Presto函数实战指南:从基础到高阶应用
1. Presto函数入门:从零开始掌握基础操作 第一次接触Presto函数时,我完全被它丰富的功能震撼到了。记得当时我需要快速分析一个包含数百万条记录的日志表,传统方法需要写复杂的MapReduce作业,而Presto仅用几行SQL函数就搞定了。下…...

Finalshell连接失败?排查SSH登录密码问题的终极指南
1. Finalshell连接失败的常见原因 当你使用Finalshell连接远程服务器时,遇到反复提示输入密码却无法连接的情况,这可能是由多种因素导致的。作为一个经常需要远程管理服务器的开发者,我遇到过太多次这种情况了。每次看到那个不断弹出的密码输…...

5步快速解锁付费内容:bypass-paywalls-chrome-clean终极指南 [特殊字符]
5步快速解锁付费内容:bypass-paywalls-chrome-clean终极指南 🚀 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在信息爆炸的时代,你是否经常遇到优…...

Project Sistine核心代码剖析:从图像分割到鼠标事件模拟
Project Sistine核心代码剖析:从图像分割到鼠标事件模拟 【免费下载链接】sistine Turn a MacBook into a Touchscreen with $1 of Hardware 项目地址: https://gitcode.com/gh_mirrors/si/sistine Project Sistine是一个创新的开源项目,它能让普…...

Insanely Fast Whisper终身学习模型:持续优化的语音识别系统设计
Insanely Fast Whisper终身学习模型:持续优化的语音识别系统设计 【免费下载链接】insanely-fast-whisper 项目地址: https://gitcode.com/GitHub_Trending/in/insanely-fast-whisper 你是否还在为语音识别速度慢、准确率低而烦恼?是否希望拥有一…...

小型电商自动化:OpenClaw+nanobot处理订单邮件
小型电商自动化:OpenClawnanobot处理订单邮件 1. 为什么选择OpenClaw处理电商订单 作为一个经营小型电商的个体商户,我每天要处理几十封来自Gmail的订单邮件。这些邮件包含客户信息、商品清单和收货地址,需要手动录入到库存表格、生成物流单…...

Qt操作Excel避坑指南:为什么我放弃了QAxObject而选择QXlsx?
Qt操作Excel的终极方案:从QAxObject到QXlsx的技术迁移实战 三年前接手一个工业数据采集项目时,我遇到了职业生涯中最棘手的Excel导出问题。客户现场同时安装了Office 2016和WPS,导致基于QAxObject开发的报表模块随机崩溃。更糟的是࿰…...

1.1 AI技术全景图:从传统ML到大模型
AI技术全景图:从传统ML到大模型本文适合谁:完全没有AI背景的读者。读完这篇,你会知道"AI/机器学习/深度学习/大模型"这几个词是什么关系,以及你将要学的东西在整个AI世界里处于什么位置。AI发展经历了三个时代——本文带…...