Python爬虫实战:一键采集电商数据,掌握市场动态!
电商数据分析是个香饽饽,可市面上的数据采集工具要不贵得吓人,要不就是各种广告弹窗。干脆自己动手写个爬虫,想抓啥抓啥,还能学点技术。今天咱聊聊怎么用Python写个简单的电商数据爬虫。
打好基础:搞定请求头
别看爬虫很牛,但基础工作得做足。浏览器访问网页时会带上各种 请求头信息 ,咱们写爬虫也得模仿这个行为,不然分分钟被网站拦截。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5',
}
温馨提示:每个网站的反爬策略不一样,有时候可能需要加上Cookie、Referer等信息。要是遇到了再加就成。
发起请求:requests库来帮忙
发请求用 requests库 准没错,简单好用还稳定。pip安装一下就能用:
import requests
def get_page(url):
try:
response = requests.get(url, headers=headers, timeout=5)
return response.text
except Exception as e:
print(f'哎呀,出错了:{e}')
return None
解析数据:BeautifulSoup大显神通
拿到网页内容后,就该解析数据了。 BeautifulSoup 是个好帮手,把乱糟糟的HTML转成结构化的数据:
from bs4 import BeautifulSoup
def parse_product(html):
if not html:
return []
soup = BeautifulSoup(html, 'html.parser')
products = []
items = soup.find_all('div', class_='item') # 具体class名要看网站结构
for item in items:
product = {
'title': item.find('div', class_='title').text.strip(),
'price': item.find('span', class_='price').text.strip(),
'sales': item.find('span', class_='sales').text.strip()
}
products.append(product)
return products
存储数据:pandas帮你整理
数据爬下来了,得好好存起来。用 pandas 转成Excel,分析起来贼方便:
import pandas as pd
def save_data(products):
df = pd.DataFrame(products)
df.to_excel('products.xlsx', index=False)
print(f'搞定!共保存了{len(products)}条数据')
完整代码:整合一下
把上面的代码整合一下,就能一键采集数据了:
def main():
base_url = 'https://example.com/products?page={}' # 替换成实际的网站
all_products = []
for page in range(1, 6): # 采集5页数据
url = base_url.format(page)
print(f'正在爬取第{page}页...')
html = get_page(url)
products = parse_product(html)
all_products.extend(products)
time.sleep(1) # 别爬太快,对别人服务器好点
save_data(all_products)
if __name__ == '__main__':
main()
温馨提示:记得改成你要爬的网站地址,不同网站的HTML结构不一样,解析规则也得相应调整。
反爬处理:多动点小脑筋
网站肯定不愿意让你随便爬数据,咱得讲究点技巧:
-
IP代理池:换着IP访问,降低被封风险
-
随机延时:别一直用固定间隔,显得太机械
-
随机UA:多准备几个User-Agent轮着用
-
验证码处理:遇到验证码可以用OCR识别
这个爬虫还挺实用,不光能爬电商数据,改改解析规则,啥数据都能爬。写爬虫最重要的是要有耐心,遇到问题别着急,慢慢调试就成。代码写好了,运行起来那叫一个爽,分分钟几千条数据到手。
相关文章:

Python爬虫实战:一键采集电商数据,掌握市场动态!
电商数据分析是个香饽饽,可市面上的数据采集工具要不贵得吓人,要不就是各种广告弹窗。干脆自己动手写个爬虫,想抓啥抓啥,还能学点技术。今天咱聊聊怎么用Python写个简单的电商数据爬虫。 打好基础:搞定请求头 别看爬虫…...

STM32之I2C硬件外设
注意:硬件I2C的引脚是固定的 SDA和SCL都是复用到外部引脚。 SDA发送时数据寄存器的数据在数据移位寄存器空闲的状态下进入数据移位寄存器,此时会置状态寄存器的TXE为1,表示发送寄存器为空,然后往数据控制寄存器中一位一位的移送数…...

【C++】中的赋值初始化和直接初始化的区别
在C中,赋值初始化(也称为拷贝初始化)和直接初始化(也称为构造初始化)虽然常常产生相同的结果,但在某些情况下它们有不同的含义和行为。 赋值初始化(Copy Initialization) 使用等号…...
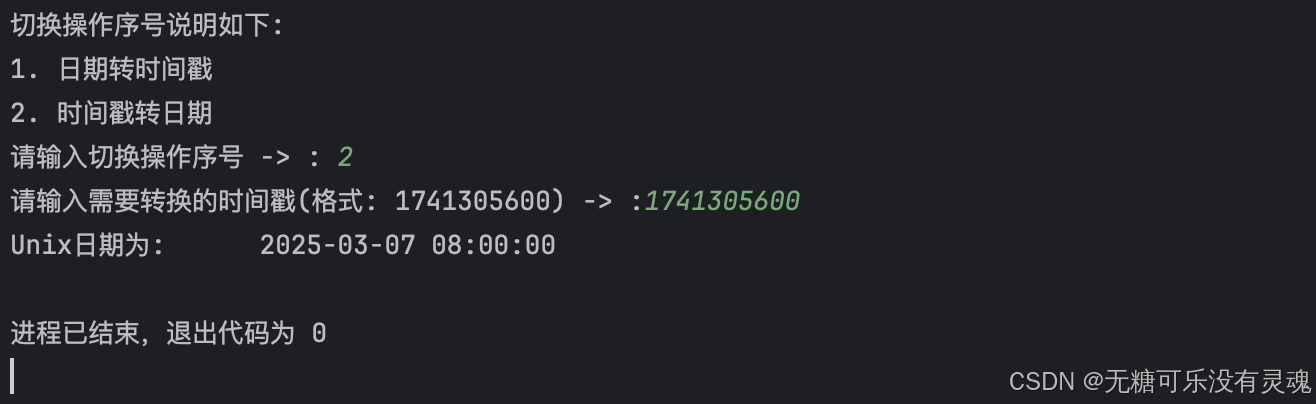
Python ❀ Unix时间戳转日期或日期转时间戳工具分享
设计一款Unix时间戳和日期转换工具,其代码如下: from datetime import datetimeclass Change_Date_Time(object):def __init__(self, date_strNone, date_numNone):self.date_str date_strself.date_num date_num# 转时间戳def datetime2timestamp(s…...

本地部署Dify及避坑指南
Dify作为开源的大模型应用开发平台,支持本地私有化部署,既能保障数据安全,又能实现灵活定制。但对于新手而言,从环境配置到服务启动可能面临诸多挑战。本文结合实战经验,手把手教你从零部署Dify,并总结高频…...

大白话CSS 优先级计算规则的详细推导与示例
大白话CSS 优先级计算规则的详细推导与示例 答题思路 引入概念:先通俗地解释什么是 CSS 优先级,让读者明白为什么要有优先级规则,即当多个 CSS 样式规则作用于同一个元素时,需要确定哪个规则起作用。介绍优先级的分类࿱…...
非真实感渲染(Non-Photorealistic Rendering, NPR))
OpenCV计算摄影学(19)非真实感渲染(Non-Photorealistic Rendering, NPR)
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 非真实感渲染(Non-Photorealistic Rendering, NPR)是一种计算机图形学技术,旨在生成具有艺术风格或其他非现实…...

深度学习(斋藤)学习笔记(五)-反向传播2
上一篇关于反向传播的代码仅支持单变量的梯度计算,下面我们将扩展代码使其支持多个输入/输出。增加了对多输入函数(如 Add),以实现的计算。 1.关于前向传播可变长参数的改进-修改Function类 修改方法: Function用于对…...

数据库基础练习1
目录 1.创建数据库和表 2.插入数据 创建一个数据库,在数据库种创建一张叫heros的表,在表中插入几个四大名著的角色: 1.创建数据库和表 #创建表 CREATE DATABASE db_test;#查看创建的数据库 show databases; #使用db_test数据库 USE db_te…...

TypeError: Cannot create property ‘xxx‘ on string ‘xxx‘
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》、《前端求职突破计划》 🍚 蓝桥云课签约作者、…...

极狐GitLab 17.9 正式发布,40+ DevSecOps 重点功能解读【三】
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 学习极狐GitLab 的相关资料: 极狐GitLab 官网极狐…...
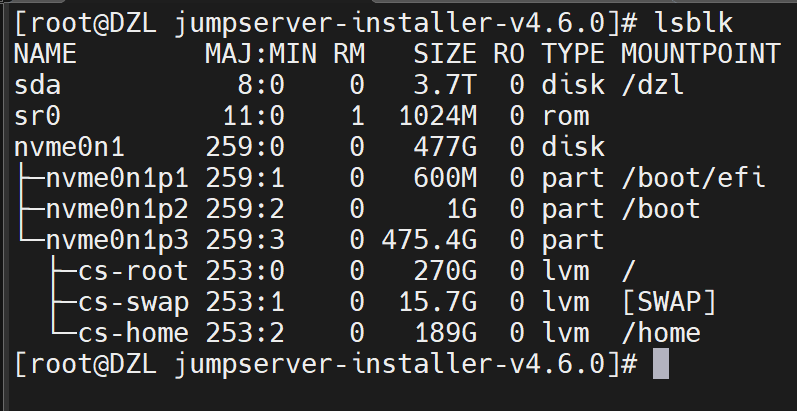
lsblk命令linux查询设备信息
lsblk命令是Linux中用于列出所有可用块设备信息的工具,它能够显示设备之间的依赖关系,但不会列出RAM盘的信息。块设备包括硬盘、闪存盘、CD-ROM等。lsblk命令包含在util-linux包中,该命令的常用参数包括: -d:仅列出磁盘…...

【智能体架构:Agent】LangChain智能体类型ReAct、Self-ASK的区别
1. 什么是智能体 将大语言模型作为一个推理引擎。给定一个任务, 智能体自动生成完成任务所需步骤, 执行相应动作(例如选择并调用工具), 直到任务完成。 2. 先定义工具:Tools 可以是一个函数或三方 API也…...

鸿蒙开发:弹性布局Flex
前言 代码案例基于Api13。 正在开发一个搜索组件,其中一个功能是针对历史搜索的内容进行展示,由于搜索的内容长度不一,需要进行流式布局展示,效果如下: 以上的效果,相信大家在很多的应用里或多或少都见到过…...

【DeepSeek】5分钟快速实现本地化部署教程
一、快捷部署 (1)下载ds大模型安装助手,下载后直接点击快速安装即可。 https://file-cdn-deepseek.fanqiesoft.cn/deepseek/deepseek_28348_st.exe (2)打开软件,点击立即激活 (3)选…...

易基因特异性R-loop检测整体研究方案
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。 01.技术简述 R-loop是由DNA:RNA 杂交体和被置换的单链DNA组成的三链核酸结构,广泛参与基因转录、表观遗传调控及DNA修复等关键生物学过程。异常的R-loop积累会导致基因组不稳…...
虚拟系统配置案例
安全策略要求: 1、只存在一个公网IP地址,公司内网所有部门都需要借用同一个接口访问外网 2、财务部禁止访问Internet,研发部门只有部分员工可以访问Internet,行政部门全部可以访问互联网 3、为三个部门的虚拟系统分配相同的资源类…...

C语言【进阶篇】之结构体 —— 从基础声明到复杂应用的进阶之路
目录 🚀前言✍️结构体类型的声明💯结构体定义💯结构的特殊声明 🦜结构的自引用💻结构体内存对齐💯对齐规则💯为什么存在内存对齐💯修改默认对齐数 🐍结构体传参…...

Python-列表和元组
列表 列表是什么, 元组是什么 编程中, 经常需要使用变量, 来保存/表示数据. 如果代码中需要表示的数据个数比较少, 我们直接创建多个变量即可. 但是有的时候, 代码中需要表示的数据特别多, 甚至也不知道要表示多少个数据. 这个时候, 就需要用到列表. 列表是一种让程序猿在代…...

PyTorch 中的混合精度训练方法,从 autocast 到 GradScalar
PyTorch 的混合精度训练主要由两个方法实现:amp.autocast 和 amp.GradScalar。在这两个工具的帮助下,可以实现以 torch.float16 的混合精度训练。当然,这两个方法都是模块化并且通常都会一起调用,但并不一定总是需要一起使用。 参…...

书匠策AI毕业论文功能全揭秘:一个工具,把你从选题焦虑里捞出来!
各位正在和毕业论文死磕的同学们,大家好! 今天这篇内容,我不讲大道理,就给你们安利一个我最近反复在用的工具——书匠策AI(官网: 官网直达:www.shujiangce.com。如果你现在正处于"选题没…...

ARMv8-M架构安全扩展与嵌入式系统配置详解
1. ARM_AEMv8M架构概述ARM_AEMv8M是ARMv8-M架构的扩展实现,专为嵌入式系统设计,提供了硬件级的安全隔离能力。这个架构引入了TrustZone安全扩展和MPU内存保护机制,使得开发者能够在资源受限的嵌入式设备上实现强大的安全功能。1.1 核心特性解…...

LabVIEW生产者消费者模式:队列解耦与多任务架构实战
1. 项目概述:从“单线程”到“流水线”的思维跃迁如果你用过LabVIEW,大概率写过那种“一个While循环包打天下”的程序。按钮事件、数据采集、逻辑处理、界面更新,全都塞在一个循环里,顺序执行。程序简单时还好,一旦任务…...

Cursor Free VIP:终极免费解锁AI编程助手Pro功能的完整指南
Cursor Free VIP:终极免费解锁AI编程助手Pro功能的完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached you…...

AI 写作进入长篇记忆时代,AI让小说创作更可控
AI 写小说最常被讨论的问题,是写得快不快、文笔好不好。但对于真正写长篇的作者来说,还有一个更重要的问题:AI 记不记得住。 一部网文写到几十章、几百章后,人物关系会越来越复杂,伏笔会越来越多,世界观设…...
 2026)
Austroads:速度管理证据与指导回顾(英) 2026
这份报告是澳大利亚和新西兰道路运输委员会(Austroads)2025 年发布的《车速管理证据与指南回顾》,核心是为更新《道路安全指南:安全车速》(AGRS Part 3)梳理研究证据、 stakeholder 反馈并给出修订建议。下…...

arXiv论文源码怎么复用?手把手教你用Overleaf导入、编译与二次创作
arXiv论文源码复用指南:Overleaf导入、编译与二次创作全解析 当你从arXiv下载了一篇论文的LaTeX源码压缩包,却发现本地环境配置复杂、依赖缺失或路径错误导致编译失败时,这篇文章将成为你的救星。我们将以Overleaf为工具,深入解决…...

Input Leap:一款让多设备共享键盘鼠标变得简单高效的开源KVM软件
Input Leap:一款让多设备共享键盘鼠标变得简单高效的开源KVM软件 【免费下载链接】input-leap Open-source KVM software 项目地址: https://gitcode.com/gh_mirrors/in/input-leap 你是否厌倦了在多个电脑之间来回切换键盘和鼠标?是否希望用一套…...

如何快速优化EVE Online舰船配置:免费专业工具指南
如何快速优化EVE Online舰船配置:免费专业工具指南 【免费下载链接】Pyfa Python fitting assistant, cross-platform fitting tool for EVE Online 项目地址: https://gitcode.com/gh_mirrors/py/Pyfa Pyfa(Python Fitting Assistant)…...
)
从V1到V3:手把手教你用PyTorch复现MobileNet进化史(附完整代码)
从V1到V3:手把手教你用PyTorch复现MobileNet进化史(附完整代码) 在移动端和嵌入式设备上部署深度学习模型一直是计算机视觉领域的核心挑战之一。2017年,Google推出的MobileNet系列彻底改变了轻量级卷积神经网络的设计范式…...