Python-列表和元组
列表
列表是什么, 元组是什么
编程中, 经常需要使用变量, 来保存/表示数据.
如果代码中需要表示的数据个数比较少, 我们直接创建多个变量即可.
但是有的时候, 代码中需要表示的数据特别多, 甚至也不知道要表示多少个数据. 这个时候, 就需要用到列表.
列表是一种让程序猿在代码中批量表示/保存数据的方式、
元组和列表相比, 是非常相似的, 只是列表中放哪些元素可以修改调整, 元组中放的元素是创建元组的时 候就设定好的, 不能修改调整.
一个形象的比喻就是
就像我们去超市买辣条, 如果就只是买一两根辣条, 那咱们直接拿着辣条就走了.
但是如果一次买个十根八根的, 这个时候用手拿就不好拿, 超市老板就会给我们个袋子.
这个袋子, 就相当于 列表
列表就是买散装辣条, 装好了袋子之后, 随时可以把袋子打开, 再往里多加辣条或者拿出去一些辣条.
元组就是买包装辣条, 厂家生产好了辣条之后, 一包就是固定的这么多, 不能变动了.
创建列表
- 创建列表主要有两种方式.
- [ ] 表示一个空的列表.
- 如果需要往里面设置初始值, 可以直接写在 [ ] 当中.
- 列表中存放的元素允许是不同的类型. (差别在此).
alist = [1, 'hello', True]
print(alist)
访问下标
- 可以通过下标访问操作符 [ ] 来获取到列表中的任意元素.
alist = [1, 2, 3, 4]print(alist[2])
- 通过下标不光能读取元素内容, 还能修改元素的值.
alist = [1, 2, 3, 4]alist[2] = 100print(alist)
- 同样的,如果下标超出列表的有效范围, 会抛出异常.

- 不一样的是,下标可以取负数. 表示 "倒数第几个元素"
alist = [1, 2, 3, 4]print(alist[3])print(alist[-1])
切片操作
通过下标操作是一次取出里面第一个元素.
通过切片, 则是一次取出一组连续的元素, 相当于得到一个 子列表
使用 [ : ] 的方式进行切片操作.

alist[1:3] 中的 1:3 表示的是 [1, 3) 这样的由下标构成的前闭后开区间.
也就是从下标为 1 的元素开始(2), 到下标为 3 的元素结束(4), 但是不包含下标为 3 的元素.
所以最终结果只有 2, 3
- 切片操作中可以省略前后边界
alist = [1, 2, 3, 4]print(alist[1:]) # 省略后边界, 表示获取到列表末尾print(alist[:-1]) # 省略前边界, 表示从列表开头获取print(alist[:]) # 省略两个边界, 表示获取到整个列表.

- 切片操作还可以指定 "步长" , 也就是 "每访问一个元素后, 下标自增几步"
alist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]print(alist[::1])print(alist[::2])print(alist[::3])print(alist[::5])
- 切片操作指定的步长还可以是负数, 此时是从后往前进行取元素. 表示 "每访问一个元素之后, 下标自 减几步"
alist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]print(alist[::-1])print(alist[::-2])print(alist[::-3])print(alist[::-5])

- 如果切片中填写的数字越界了, 不会有负面效果. 只会尽可能的把满足条件的元素过去到.

遍历列表元素
"遍历" 指的是把元素一个一个的取出来, 再分别进行处理.
- 最简单的办法就是使用 for 循环
alist = [1, 2, 3, 4]for elem in alist:print(elem)
- 也可以使用 for 按照范围生成下标, 按下标访问
alist = [1, 2, 3, 4]for i in range(0, len(alist)):print(alist[i])- 还可以使用 while 循环. 手动控制下标的变化
alist = [1, 2, 3, 4]i = 0while i < len(alist):print(alist[i])i += 1
新增元素
- 使用 append 方法, 向列表末尾插入一个元素(尾插)
alist = [1, 2, 3, 4]alist.append('hello')print(alist)

- 使用 insert 方法, 向任意位置插入一个元素
alist = [1, 2, 3, 4]alist.insert(1, 'hello')print(alist)
查找元素
- 使用 in 操作符, 判定元素是否在列表中存在. 返回值是布尔类型.
alist = [1, 2, 3, 4]print(2 in alist)print(10 in alist)- 使用 index 方法, 查找元素在列表中的下标. 返回值是一个整数. 如果元素不存在, 则会抛出异常.
alist = [1, 2, 3, 4]print(alist.index(2))print(alist.index(10))
删除元素
- 使用 pop 方法删除最末尾元素
alist = [1, 2, 3, 4]alist.pop()print(alist)
- pop 也能按照下标来删除元素
alist = [1, 2, 3, 4]alist.pop(2)print(alist)
- 使用 remove 方法, 按照值删除元素.
alist = [1, 2, 3, 4]alist.remove(2)print(alist)
连接列表
- 使用 + 能够把两个列表拼接在一起.
此处的 + 结果会生成一个新的列表. 而不会影响到旧列表的内容.
alist = [1, 2, 3, 4]blist = [5, 6, 7]print(alist + blist) 得到结果就是
- 使用 extend 方法, 相当于把一个列表拼接到另一个列表的后面.
a.extend(b) , 是把 b 中的内容拼接到 a 的末尾. 不会修改 b, 但是会修改 a.
alist = [1, 2, 3, 4]blist = [5, 6, 7]alist.extend(blist)print(alist)print(blist)
得到结果是
关于元组
元组的功能和列表相比, 基本是一致的.
元组使用 ( ) 来表示.
但是元组不能修改里面的元素, 列表则可以修改里面的元素
因此, 像读操作,比如访问下标, 切片, 遍历, in, index, + 等, 元组也是一样支持的.
但是, 像写操作, 比如修改元素, 新增元素, 删除元素, extend 等, 元组则不能支持.
那既然已经有了列表, 为啥还需要有元组?
元组相比于列表来说, 优势有两方面:
- 你有一个列表, 现在需要调用一个函数进行一些处理. 但是你有不是特别确认这个函数是否会 把你的列表数据弄乱. 那么这时候传一个元组就安全很多.
- 我们马上要讲的字典, 是一个键值对结构. 要求字典的键必须是 "可hash对象" (字典本质上也 是一个hash表). 而一个可hash对象的前提就是不可变. 因此元组可以作为字典的键, 但是列表 不行.
总的来说
- 列表和元组都是日常开发最常用到的类型. 最核心的操作就是根据 [ ] 来按下标操作.
- 在需要表示一个 "序列" 的场景下, 就可以考虑使用列表和元组.
- 如果元素不需要改变, 则优先考虑元组.
- 如果元素需要改变, 则优先考虑列表.
相关文章:
Python-列表和元组
列表 列表是什么, 元组是什么 编程中, 经常需要使用变量, 来保存/表示数据. 如果代码中需要表示的数据个数比较少, 我们直接创建多个变量即可. 但是有的时候, 代码中需要表示的数据特别多, 甚至也不知道要表示多少个数据. 这个时候, 就需要用到列表. 列表是一种让程序猿在代…...

PyTorch 中的混合精度训练方法,从 autocast 到 GradScalar
PyTorch 的混合精度训练主要由两个方法实现:amp.autocast 和 amp.GradScalar。在这两个工具的帮助下,可以实现以 torch.float16 的混合精度训练。当然,这两个方法都是模块化并且通常都会一起调用,但并不一定总是需要一起使用。 参…...

分享能在线运行C语言的网站
https://www.onlinegdb.com/# 我用vscode运行c语言总是报错,后面找到这个网站,可以在线调试和保存代码。 如下图,程序的效果是给变量x,y,z赋值,并打印出来。代码输入以后,右上角选择C语言&…...

AI-Deepseek + PPT
01--Deepseek提问 首先去Deepseek问一个问题: Deepseek的回答: 在汽车CAN总线通信中,DBC文件里的信号处理(如初始值、系数、偏移)主要是为了 将原始二进制数据转换为实际物理值,确保不同电子控制单元&…...

MacOS Big Sur 11 新机安装brew wget python3.12 exo
MacOS Big Sur 11,算是很老的系统了,所以装起来有点费劲。 首先安装brew 按照官网的方法,直接执行下面语句即可安装: export HOMEBREW_BREW_GIT_REMOTE"https://githubfast.com" # put your Git mirror of Homebrew/brew here …...

十大经典排序算法简介
一 概述 本文对十大经典排序算法做简要的总结(按常用分类方式排列),包含核心思想、时间/空间复杂度及特点。 二、比较类排序 1. 冒泡排序 (BUBBLE SORT) 思想:重复交换相邻逆序元素,像气泡上浮 复杂度: 时间:O(n^2)(最好情况O(n)) 空间:O(1) 特点:简单但效率低,稳…...

不小心更改了/etc权限为777导致sudo,ssh等软件都无法使用
修复流程 一、进入恢复模式(无网络或无法登录时必选) 1.重启系统,在 GRUB 启动菜单选择 Recovery Mode(按 Shift 或 Esc 呼出菜单)。2.以 root 身份挂载为可读写: bash 复制 mount -o remount,rw /确保文…...

AI档案审核2
以下是一个结合计算机视觉(CV)和自然语言处理(NLP)的智能档案审核系统完整实现方案,包含可落地的代码框架和技术路线: 一、系统架构设计 #mermaid-svg-UhBtIPrNXo5P89Zb {font-family:"trebuchet ms&q…...

【基础1】冒泡排序
核心思想 冒泡排序是通过相邻元素的连续比较和交换,使得较大的元素逐渐"浮"到数组的末尾,如同水中气泡上浮的过程 特点: 每轮遍历将最大的未排序元素移动到正确位置稳定排序:相等元素的相对位置保持不变原地排序…...

Trae AI 开发工具使用手册
这篇手册将介绍 Trae 的基本功能、安装步骤以及使用方法,帮助开发者快速上手这款工具。 Trae AI 开发工具使用手册 Trae 是字节跳动于 2025 年推出的一款 AI 原生集成开发环境(IDE),旨在通过智能代码生成、上下文理解和自动化任务…...

揭开AI-OPS 的神秘面纱 第二讲-技术架构与选型分析 -- 数据采集层技术架构与组件选型分析
基于上一讲预设的架构图,深入讨论各个组件所涉及的技术架构、原理以及选型策略。我将逐层、逐组件地展开分析,并侧重于使用数据指标进行技术选型的对比。 我们从 数据采集层 开始,进行最细粒度的组件分析和技术选型比对。 数据采集层技术架构…...

基于Docker去创建MySQL的主从架构
基于Docker去创建MySQL的主从架构 用于开发与测试环境读写分离 主从的架构搭建步骤 基于Docker去创建MySQL的主从架构 # 创建主从数据库文件夹 mkdir -p /usr/local/mysql/master1/conf mkdir -p /usr/local/mysql/master1/data mkdir -p /usr/local/mysql/slave1/conf mkd…...
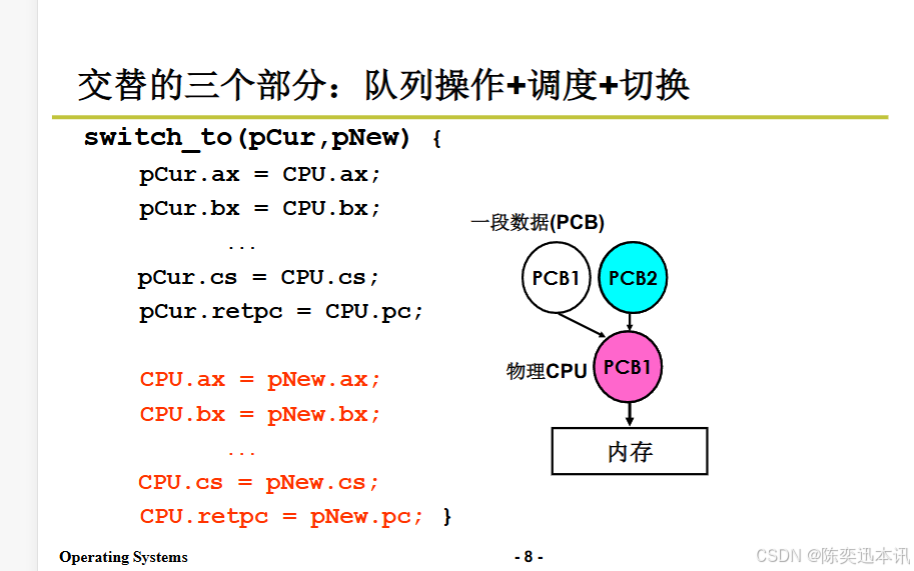
操作系统 2.2-多进程总体实现
多个进程使用CPU的图像 如何使用CPU呢? 通过让程序执行起来来使用CPU。 如何充分利用CPU呢? 通过启动多个程序,交替执行来充分利用CPU。 启动了的程序就是进程,所以是多个进程推进 操作系统需要记录这些进程,并按照…...

Jasypt 与 Spring Boot 集成文档
Jasypt 与 Spring Boot 集成文档 目录 简介版本说明快速开始 添加依赖配置加密密钥加密配置文件 高级配置 自定义加密算法多环境配置 最佳实践常见问题参考资料 简介 Jasypt 是一个简单易用的 Java 加密库,支持与 Spring Boot 无缝集成。通过 Jasypt,…...

在CentOS系统上安装Conda的详细指南
前言 Conda 是一个开源的包管理系统和环境管理系统,广泛应用于数据科学和机器学习领域。本文将详细介绍如何在 CentOS 系统上安装 Conda,帮助您快速搭建开发环境。 准备工作 在开始安装之前,请确保您的 CentOS 系统已经满足以下条件&#x…...
与过滤器(Filter)详细教程)
Spring Boot拦截器(Interceptor)与过滤器(Filter)详细教程
Spring Boot拦截器(Interceptor)与过滤器(Filter)详细教程 目录 概述 什么是拦截器(Interceptor)?什么是过滤器(Filter)?两者的核心区别 使用场景 拦截器的典…...

HTML-05NPM使用踩坑
2025-03-04-NPM使用踩坑 本文讲述了一个苦逼程序员在使用NPM的时候突然来了一记nmp login天雷,然后一番折腾之后,终究还是没有解决npm的问题😞😞😞,最终使用cnpm完美解决的故事。 文章目录 2025-03-04-NPM使用踩坑[toc…...

自学嵌入式第29天-----epoll、sqlite3
1. 正确选择触发模式(ET 和 LT) 水平触发(LT):默认模式,只要文件描述符处于就绪状态,epoll_wait 会持续通知。适合大多数场景,编程简单。 边缘触发(ET)&…...

工作学习笔记:HarmonyOS 核心术语速查表(v14 实战版)
作为在 HarmonyOS 开发一线摸爬滚打的工程师,笔者在 v14 版本迭代中整理了这份带血的实战术语表。 一、架构基础术语速查 A 系列术语 术语官方定义笔者解读(v14 实战版)开发陷阱 & 解决方案abc 文件ArkCompiler 生成的字节码文件打包时…...

解决AWS EC2实例无法使用IAM角色登录AWS CLI
问题背景 有时,我们希望一台AWS EC2实例,即云服务器,能够使用AWS CLI访问AWS管理控制台资源。 例如,这里,我们想让它能够列出所有IAM用户组。 aws iam list-groups于是,我们使用下面的命令,在…...

编程学习时怎么更好归纳自己的笔记
学了一个月,回头翻笔记,发现根本看不懂自己写了什么。 记了满满一本,真要查某个知识点时,翻来翻去找不到。 明明记过,用的时候大脑一片空白。这是不是你?笔记不是记过就算,而是要用得上。本文从…...

Ardb源码深度解析:从网络层到存储引擎的完整架构设计
Ardb源码深度解析:从网络层到存储引擎的完整架构设计 【免费下载链接】ardb A redis protocol compatible nosql, it support multiple storage engines as backend like Googles LevelDB, Facebooks RocksDB, OpenLDAPs LMDB, PerconaFT, WiredTiger, ForestDB. …...

书匠策AI毕业论文功能全揭秘:一个工具,把你从选题焦虑里捞出来!
各位正在和毕业论文死磕的同学们,大家好! 今天这篇内容,我不讲大道理,就给你们安利一个我最近反复在用的工具——书匠策AI(官网: 官网直达:www.shujiangce.com。如果你现在正处于"选题没…...

边缘节点就地智能处理方案
边缘节点就地智能处理方案 第1章项目概述 1.1项目背景 随着数字中国建设迈入深度落地与规模化赋能的全新阶段,2026年作为国家数据要素价值释放关键年、算力网络规模化落地之年以及“十五五”规划开局之年,全国各行业数字化、数智化转型正式从信息化补短板阶段迈入提质增效、深…...
Code Coverage:从覆盖率收集到报告生成的全流程实战)
【VCS】(6)Code Coverage:从覆盖率收集到报告生成的全流程实战
1. 代码覆盖率基础概念 第一次接触代码覆盖率这个概念时,我也是一头雾水。记得当时领导问我:"这个模块的验证覆盖率多少了?"我只能支支吾吾说还在跑仿真。后来才明白,代码覆盖率是衡量验证完整性的重要指标,…...

3个技巧让你的技术文档阅读体验提升300%:Markdown Viewer深度指南
3个技巧让你的技术文档阅读体验提升300%:Markdown Viewer深度指南 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer 还在为浏览器中那些丑陋的Markdown文件预览而烦恼吗…...

【linux应用开发】Linux树形结构与说明
一、文件结构1.1 运行流程 在终端中,执行如下指令: ./build.shbuild.sh源码#!/bin/bash #删除build文件夹 rm -rf build/ #新建build文件夹 mkdir build #切换到build文件夹 cd build #指定编译链 cmake -DCMAKE_TOOLCHAIN_FILE../toolchain-cortex-a7.c…...

风云T9长续航正式上市,限时红包价仅10.99万元起售
5月16日,超长续航智享SUV——风云T9长续航正式上市,上市指导价为11.99万元-13.99万元,限时红包价10.99万元起售。新车秉持“智电全能,超级进阶”的理念,基于全球超15万用户真实需求,围绕设计、续航、智能、…...

免费LLM API资源全解析:从选型接入到避坑实战指南
1. 项目概述:一个免费LLM API的“藏宝图”如果你最近在捣鼓一些AI小应用,或者想低成本地体验一下大语言模型的能力,大概率会和我一样,被一个问题卡住:去哪里找免费、稳定、还能用的LLM API?市面上各种模型服…...

现代C++中的编译期反射替代思路
现代C中的编译期反射替代思路C 长期缺乏完整标准反射能力,但工程上依然经常需要“遍历字段、生成元信息、自动序列化、自动注册”。在正式反射广泛可用之前,开发者通常通过宏、模板特化、tuple 适配和代码生成等方式实现替代方案。一种常见思路是手工提供…...