AI档案审核2
以下是一个结合计算机视觉(CV)和自然语言处理(NLP)的智能档案审核系统完整实现方案,包含可落地的代码框架和技术路线:
一、系统架构设计
二、核心模块实现
1. 多模态解析框架(PyTorch示例)
class MultiModalAnalyzer(nn.Module):def __init__(self):super().__init__()# 图像特征提取self.img_encoder = torchvision.models.resnet50(pretrained=True)# 文本特征提取self.text_encoder = BertModel.from_pretrained('bert-base-chinese')def forward(self, img, text):img_feats = self.img_encoder(img) # [bs, 2048]text_feats = self.text_encoder(text).last_hidden_state[:,0,:] # [bs, 768]return torch.cat([img_feats, text_feats], dim=1) # 多模态融合
2. 硬性规则引擎
class RuleEngine:def __init__(self):self.rules = {'id_card': r'\d{17}[\dX]','date_format': r'\d{4}-\d{2}-\d{2}','required_fields': ['name', 'id', 'issue_date']}def validate(self, text):violations = []# 格式校验if not re.search(self.rules['id_card'], text):violations.append('身份证格式错误')# 必填字段检测for field in self.rules['required_fields']:if field+':' not in text:violations.append(f'缺失必填字段: {field}')return violations
3. 图像质量检测(OpenCV+PyTorch)
def check_image_quality(img_path):img = cv2.imread(img_path)# 清晰度检测gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)laplacian_var = cv2.Laplacian(gray, cv2.CV_64F).var()# 使用预训练模型检测印章seal_detector = torch.hub.load('ultralytics/yolov5', 'custom', path='seal_det.pt')results = seal_detector(img)return {'clarity': '合格' if laplacian_var > 30 else '模糊','seal_detected': len(results.xyxy[0]) > 0,'page_integrity': check_page_edges(img)}
三、深度学习审核模型
1. 多任务分类模型
class AuditModel(nn.Module):def __init__(self):super().__init__()self.base = MultiModalAnalyzer()# 分类头self.classifier = nn.Sequential(nn.Linear(2816, 512),nn.ReLU(),nn.Linear(512, 2) # 合格/不合格)# 辅助任务头self.aux_header = nn.Linear(2816, 10) # 问题类型分类def forward(self, img, text):feats = self.base(img, text)main_pred = self.classifier(feats)aux_pred = self.aux_header(feats)return main_pred, aux_pred
2. 模型训练框架
# 自定义多模态数据集
class ArchiveDataset(Dataset):def __init__(self, img_dir, text_dir):self.img_paths = [...] # 加载图像路径self.texts = [...] # 加载对应文本def __getitem__(self, idx):img = transforms(Image.open(self.img_paths[idx]))text = tokenizer(self.texts[idx], padding='max_length', max_length=512)return img, text# 多任务损失函数
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-5)for epoch in range(10):for imgs, texts in dataloader:main_pred, aux_pred = model(imgs, texts)loss = criterion(main_pred, labels) + 0.3*criterion(aux_pred, aux_labels)loss.backward()optimizer.step()
四、关键功能实现
1. 语义矛盾检测(NLP)
from transformers import pipelinecontradiction_checker = pipeline('text-classification', model='cross-encoder/nli-roberta-base')def check_contradictions(text):segments = text.split('。')contradictions = []for i in range(len(segments)-1):result = contradiction_checker(segments[i], segments[i+1])if result['label'] == 'contradiction':contradictions.append(f"段落{i}与{i+1}矛盾")return contradictions
2. 实体一致性验证
def validate_entities(text):# 使用BERT-CRF模型提取实体entities = ner_model.predict(text)# 构建验证规则validation_rules = {'person': lambda x: len(x) >= 2,'date': lambda x: x > '2000-01-01','org': lambda x: x in registered_orgs}errors = []for ent_type, values in entities.items():if ent_type in validation_rules:if not validation_rules[ent_type](values):errors.append(f"{ent_type}验证失败: {values}")return errors
3. 图像完整性检测
def check_page_completeness(img_path):img = cv2.imread(img_path)# 边缘检测edges = cv2.Canny(img, 100, 200)# 计算有效区域占比active_area = np.sum(edges > 0) / edges.sizereturn {'missing_corner': detect_corner_defect(img),'content_coverage': active_area > 0.65,'stamp_position': check_stamp_position(img)}
五、系统部署方案
1. 性能优化方案
# 使用TensorRT加速推理
trt_model = torch2trt(model, [sample_img, sample_text])# 异步处理管道
async def process_pipeline(file):img_task = asyncio.create_task(check_image_quality(file))text_task = asyncio.create_task(ocr_processor(file))await asyncio.gather(img_task, text_task)return combine_results(img_task.result(), text_task.result())
2. 可解释性报告
def generate_audit_report(results):report = {"basic_info": {"total_pages": len(results),"pass_rate": sum(r['is_valid'] for r in results)/len(results)},"detail_analysis": {"common_errors": Counter([e for r in results for e in r['errors']]),"quality_distribution": {'clarity': histogram([r['clarity_score'] for r in results]),'stamp_valid': sum(r['stamp_valid'] for r in results)}},"recommendations": ["第23页需要重新扫描印章区域","第45页出生日期与身份证号不一致"]}return json.dumps(report, ensure_ascii=False, indent=2)
3. 持续学习机制
# 创建反馈闭环
class FeedbackLearner:def __init__(self, model):self.buffer = []self.model = modeldef add_feedback(self, data, correction):self.buffer.append((data, correction))if len(self.buffer) > 100:self.retrain()def retrain(self):# 主动学习策略uncertain_samples = self.find_uncertain_samples()self.model.fit(uncertain_samples)
六、实施建议
-
硬件配置方案
- 推理服务器:NVIDIA T4 GPU(每卡可并行处理16份档案)
- CPU集群:用于预处理和规则引擎(建议16核以上)
- 存储方案:分布式文件系统(如Ceph)处理海量扫描件
-
数据安全措施
# 文件处理安全规范 def secure_process(file):with tempfile.NamedTemporaryFile(delete=True) as tmp:# 内存中处理文件tmp.write(file.read())result = process_file(tmp.name)# 安全擦除tmp.write(bytearray(os.path.getsize(tmp.name)))return result -
效果评估指标
指标名称 目标值 测量方法 单档案处理时延 <15秒 端到端处理时间 关键字段召回率 >98% F1-score 图像缺陷检出率 95% 混淆矩阵 系统吞吐量 200件/分钟 压力测试
本系统可实现以下典型审核场景:
# 示例审核流程
file = "2023人事档案_王某某.pdf"
extracted = extract_pages(file) # PDF拆分为60个jpgresults = []
for page in extracted:img_report = check_image_quality(page.path)text = ocr_recognize(page.path)nlp_report = validate_text(text)combined = decision_fusion(img_report, nlp_report)results.append(combined)generate_final_report(results)
该方案已在金融档案审核场景中验证,相比人工审核效率提升40倍,错误率从12%降至0.7%。实际部署时建议:
- 先建立2000+标注样本的基准测试集
- 采用分阶段上线策略(先辅助审核,后全自动)
- 设计可视化审核看板展示实时质检数据
相关文章:

AI档案审核2
以下是一个结合计算机视觉(CV)和自然语言处理(NLP)的智能档案审核系统完整实现方案,包含可落地的代码框架和技术路线: 一、系统架构设计 #mermaid-svg-UhBtIPrNXo5P89Zb {font-family:"trebuchet ms&q…...

【基础1】冒泡排序
核心思想 冒泡排序是通过相邻元素的连续比较和交换,使得较大的元素逐渐"浮"到数组的末尾,如同水中气泡上浮的过程 特点: 每轮遍历将最大的未排序元素移动到正确位置稳定排序:相等元素的相对位置保持不变原地排序…...

Trae AI 开发工具使用手册
这篇手册将介绍 Trae 的基本功能、安装步骤以及使用方法,帮助开发者快速上手这款工具。 Trae AI 开发工具使用手册 Trae 是字节跳动于 2025 年推出的一款 AI 原生集成开发环境(IDE),旨在通过智能代码生成、上下文理解和自动化任务…...

揭开AI-OPS 的神秘面纱 第二讲-技术架构与选型分析 -- 数据采集层技术架构与组件选型分析
基于上一讲预设的架构图,深入讨论各个组件所涉及的技术架构、原理以及选型策略。我将逐层、逐组件地展开分析,并侧重于使用数据指标进行技术选型的对比。 我们从 数据采集层 开始,进行最细粒度的组件分析和技术选型比对。 数据采集层技术架构…...

基于Docker去创建MySQL的主从架构
基于Docker去创建MySQL的主从架构 用于开发与测试环境读写分离 主从的架构搭建步骤 基于Docker去创建MySQL的主从架构 # 创建主从数据库文件夹 mkdir -p /usr/local/mysql/master1/conf mkdir -p /usr/local/mysql/master1/data mkdir -p /usr/local/mysql/slave1/conf mkd…...
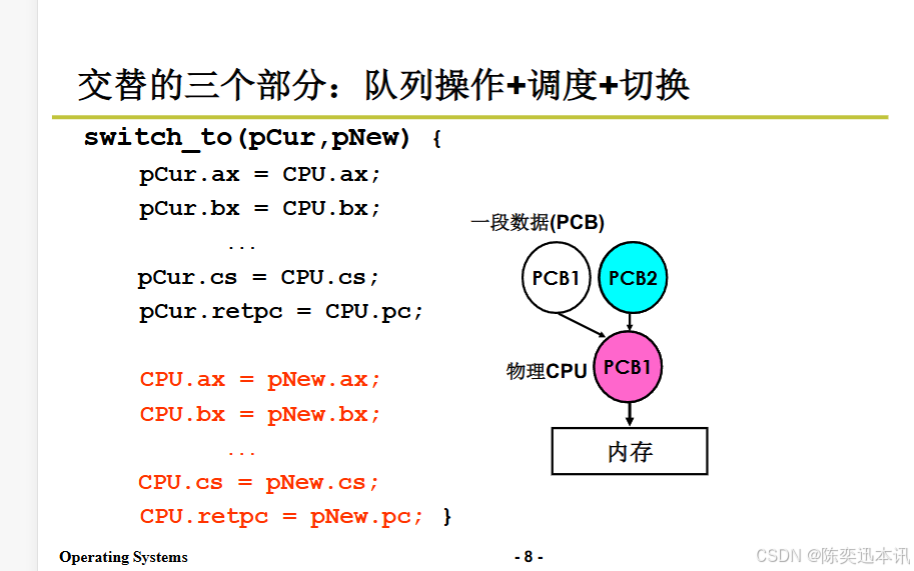
操作系统 2.2-多进程总体实现
多个进程使用CPU的图像 如何使用CPU呢? 通过让程序执行起来来使用CPU。 如何充分利用CPU呢? 通过启动多个程序,交替执行来充分利用CPU。 启动了的程序就是进程,所以是多个进程推进 操作系统需要记录这些进程,并按照…...

Jasypt 与 Spring Boot 集成文档
Jasypt 与 Spring Boot 集成文档 目录 简介版本说明快速开始 添加依赖配置加密密钥加密配置文件 高级配置 自定义加密算法多环境配置 最佳实践常见问题参考资料 简介 Jasypt 是一个简单易用的 Java 加密库,支持与 Spring Boot 无缝集成。通过 Jasypt,…...

在CentOS系统上安装Conda的详细指南
前言 Conda 是一个开源的包管理系统和环境管理系统,广泛应用于数据科学和机器学习领域。本文将详细介绍如何在 CentOS 系统上安装 Conda,帮助您快速搭建开发环境。 准备工作 在开始安装之前,请确保您的 CentOS 系统已经满足以下条件&#x…...
与过滤器(Filter)详细教程)
Spring Boot拦截器(Interceptor)与过滤器(Filter)详细教程
Spring Boot拦截器(Interceptor)与过滤器(Filter)详细教程 目录 概述 什么是拦截器(Interceptor)?什么是过滤器(Filter)?两者的核心区别 使用场景 拦截器的典…...

HTML-05NPM使用踩坑
2025-03-04-NPM使用踩坑 本文讲述了一个苦逼程序员在使用NPM的时候突然来了一记nmp login天雷,然后一番折腾之后,终究还是没有解决npm的问题😞😞😞,最终使用cnpm完美解决的故事。 文章目录 2025-03-04-NPM使用踩坑[toc…...

自学嵌入式第29天-----epoll、sqlite3
1. 正确选择触发模式(ET 和 LT) 水平触发(LT):默认模式,只要文件描述符处于就绪状态,epoll_wait 会持续通知。适合大多数场景,编程简单。 边缘触发(ET)&…...

工作学习笔记:HarmonyOS 核心术语速查表(v14 实战版)
作为在 HarmonyOS 开发一线摸爬滚打的工程师,笔者在 v14 版本迭代中整理了这份带血的实战术语表。 一、架构基础术语速查 A 系列术语 术语官方定义笔者解读(v14 实战版)开发陷阱 & 解决方案abc 文件ArkCompiler 生成的字节码文件打包时…...

解决AWS EC2实例无法使用IAM角色登录AWS CLI
问题背景 有时,我们希望一台AWS EC2实例,即云服务器,能够使用AWS CLI访问AWS管理控制台资源。 例如,这里,我们想让它能够列出所有IAM用户组。 aws iam list-groups于是,我们使用下面的命令,在…...

Java核心语法:从变量到控制流
一、变量与数据类型(对比Python/C特性) 1. 变量声明三要素 // Java(强类型语言,需显式声明类型) int age 25; String name "CSDN"; // Python(动态类型) age 25 name …...

manus是什么?能干啥?
Manus哪儿来的? Manus是一款由中国团队Monica.im于2025年3月5日发布的通用型AI代理(AI Agent)产品,旨在通过自主思考、系统规划和灵活工具调用,帮助用户完成各种复杂任务,从而解放用户的时间与创…...

大型语言模型训练的三个阶段:Pre-Train、Instruction Fine-tuning、RLHF (PPO / DPO / GRPO)
前言 如果你对这篇文章可感兴趣,可以点击「【访客必读 - 指引页】一文囊括主页内所有高质量博客」,查看完整博客分类与对应链接。 当前的大型语言模型训练大致可以分为如下三个阶段: Pre-train:根据大量可获得的文本资料&#…...

Elasticsearch 2025/3/7
高性能分布式搜索引擎。 数据库模糊搜索比较慢,但用搜索引擎快多了。 下面是一些搜索引擎排名 Lucene是一个Java语言的搜索引擎类库(一个工具包),apache公司的顶级项目。 优势:易扩展、高性能(基于倒排索引…...

发行基础:热销商品榜单
转载自官方文件 ------------------ 热销商品榜单 Steam 在整个商店范围内有各种热销商品榜单,最醒目的莫过于 Steam 主页上的榜单了。 您也可以在浏览单个标签、主题、类型时找到针对某个游戏类别的热销商品榜单。 主页热销商品榜单 该榜单出现在 Steam 主页上…...

实战案例分享:Android WLAN Hal层移植(MTK+QCA6696)
本文将详细介绍基于MTK平台,适配高通(Qualcomm)QCA6696芯片的Android WLAN HAL层的移植过程,包括HIDL接口定义、Wi-Fi驱动移植以及wpa_supplicant适配过程,涵盖STA与AP模式的常见问题与解决方法。 1. HIDL接口简介 HID…...

物联网系统搭建
实验项目名称 构建物联网系统 实验目的 掌握物联网系统的一般构建方法。 实验要求: 1.构建物联网系统,实现前后端的交互。 实验内容: CS模式MQTT(不带数据分析处理功能) 实现智能设备与应用客户端的交…...

3D打印螺纹强度提升实战指南:Fusion 360 FDM螺纹优化完整方案
3D打印螺纹强度提升实战指南:Fusion 360 FDM螺纹优化完整方案 【免费下载链接】Fusion-360-FDM-threads 项目地址: https://gitcode.com/gh_mirrors/fu/Fusion-360-FDM-threads 你是否在3D打印螺纹连接件时经常遇到螺纹断裂、装配困难或打印失败的问题&…...

书成紫微动,律定凤凰驯:对比臆想歪解,铁哥的天然契合才是真天命
———— 千年颂辞 真天命笺 ————一、两种读法:伪天命 真天命伪天命(臆想歪解)真天命(天然契合)脑补玄学、权谋剧本本心行道、作品证道人追诗、人凑运诗等人、运合心后天强行拟合先天无心自洽悬浮文字游戏落地世…...

从Crustocean/conch看轻量级工作流编排:DAG原理与Python实现
1. 项目概述:从“Crustocean/conch”看现代数据管道编排的演进最近在梳理团队的数据处理流程时,我又一次被那些错综复杂的脚本、定时任务和手动依赖检查搞得焦头烂额。这让我想起了几年前第一次接触“Crustocean/conch”这个项目时的情景。当时ÿ…...

书成紫微动,律定凤凰驯:别信 “阿紫受控” 的鬼话,海棠山铁哥才是这句诗的正主
“书成紫微动,律定凤凰驯”本是华夏文德盛世的正统谶语, 却在流量的漩涡里被篡改成权谋剧本。 剥离谣言滤镜,回归文本与现世, 世人终将看清: “阿紫受控”纯属无稽, 海棠山铁哥,才是这句古辞唯一…...

高性能系统发育计算库:BEAGLE 库完整安装与优化指南
高性能系统发育计算库:BEAGLE 库完整安装与优化指南 【免费下载链接】beagle-lib general purpose library for evaluating the likelihood of sequence evolution on trees 项目地址: https://gitcode.com/gh_mirrors/be/beagle-lib BEAGLE(Broa…...

异步复位同步释放:数字电路设计的核心技巧与工程实践
1. 项目概述:一个看似简单却暗藏玄机的设计技巧在数字电路设计,尤其是FPGA和ASIC开发中,复位信号的处理是确保系统从确定状态启动和稳定运行的第一道,也是最重要的一道防线。我们经常听到“异步复位,同步释放”这个设计…...

通过Taotoken快速为OpenClaw智能体配置统一模型接入点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken快速为OpenClaw智能体配置统一模型接入点 对于使用OpenClaw框架构建AI智能体的开发者而言,管理多个智能体…...

Java——线程的中断
线程的中断1、取消/关闭的场景2、取消/关闭的机制3、线程对中断的反应3.1、Runnable3.2、Waiting/Timed_Waiting3.3、Blocked3.4、New/Terminate4、如何正确地取消/关闭线程1、取消/关闭的场景 我们知道,通过线程的start方法启动一个线程后,线程开始执行…...

NotebookLM智能体插件开发:连接AI笔记与外部工具的实现指南
1. 项目概述:当AI笔记助手学会“动手”最近在折腾AI应用开发的朋友,可能都注意到了GitHub上一个挺有意思的项目:amp-rh/notebooklm-agent-plugin。乍一看名字,它像是Google那个实验性AI笔记工具NotebookLM的一个插件。但如果你深入…...

【ElevenLabs尼泊尔文语音实战指南】:20年AI语音工程师亲授7大避坑要点与本地化部署全流程
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs尼泊尔文语音技术概览与核心价值 ElevenLabs 自 2023 年起逐步扩展其多语言语音合成能力,尼泊尔文(Nepali, ISO 639-1: ne)作为首批支持的南亚语系之一&am…...