大型语言模型训练的三个阶段:Pre-Train、Instruction Fine-tuning、RLHF (PPO / DPO / GRPO)
前言
如果你对这篇文章可感兴趣,可以点击「【访客必读 - 指引页】一文囊括主页内所有高质量博客」,查看完整博客分类与对应链接。
当前的大型语言模型训练大致可以分为如下三个阶段:
- Pre-train:根据大量可获得的文本资料,采用自监督学习-预测 next token 的方式,训练得到预训练模型;
- Instruction Fine-tuning:根据大量任务上的指令标记数据,采用监督学习的方式微调模型,使得模型可以理解人类指令;
- RLHF:基于人类的反馈,采用强化学习的方式,使模型可以产出符合人类偏好的回答。
GPT Pre-train 系列历史
- GPT-1 (2018):模型参数量为 117M,使用了大约 7000 本书的数据量;
- GPT-2 (2019):模型参数量为 1542M(扩大了十倍),使用了大约 40GB 的资料;
- GPT-3 (2020):模型参数量为 175B(再次扩大一百倍),使用了大约 580GB 的资料,包含 300B 的 token,类似于哈利波特全集的 30 万遍。
- 下图来自 GPT-3 论文,可以看到随模型参数量扩大,模型性能逐步提高,但仍然没有发生质变,模型的使用体验也与当前的 GPT-4 等其它模型相差甚远。
- GPT-1、2、3 系列均采用自监督学习 (Self-Supervised Learning) 训练得到,即使用 predict next token 的方式,将句子中的下一个 token 作为 label 进行训练,无需人工标注数据。

Instruction Fine-tuning
通过自监督学习出来的模型,虽然已展现了一定程度的语言理解能力,但其性能依然有较大的提升空间。
因此在后续的 GPT 系列中,自监督学习只是模型训练的第一阶段。该阶段作为预训练 (Pre-train),无需人工标注,有大量的可训练数据,其训练得到的模型,将作为后续训练阶段的初始参数。
下述例子来自于开源指令微调数据集,要求模型输出的内容尽可能与 Target 一致:
Input: 对联,要求对仗工整:上联:桃李争春齐献媚
Output:下联:鹏鹄比翼各称雄Input:说话时面带惯常的微笑。翻译成英文:
Output:His face with the usual smile.
在指令微调的过程中,可以发现大模型表现出的一些「举一反三」的能力,即在多种语言上做预训练后,只要在某一个语言的某一个任务上做微调,就可以自动学会其他语言上同样的任务。如下图所示, 在 104 种语言上做 Pre-train,English QA 上做 Fine-tune,在 Chinese QA 上做 Testing,也可以取得 78.8% 的 F1 score。

先前 Fine-tuning 的思路通常是给定一个大型预训练模型,然后在各下游任务的数据集上各自训练,打造一堆专才,且微调的数据集规模通常不大。
不同于上述打造专才的思路,Instruct GPT 在大范围的任务集上进行了 Fine-tuning,并且在仅依赖 1.3B 模型参数量和上万条标注数据的情况下打败了拥有 175B 参数量的 GPT-3.

Self-Instruct
Instruction Fine-tuning 效果非常显著,其所需的训练数据通常无需太多,但要求是高质量的标注数据。由于标注数据有一定的获取门槛,因此有人提出对 ChatGPT 进行逆向工程,即 Self-Instruct,生成大量标注数据。
具体流程如下:
- 先让 ChatGPT 想大量的任务(例如撰写邮件、修改文章、撰写报告摘要等);
- 再让 ChatGPT 根据任务产生大量可能的输入;
- 最后让 ChatGPT 根据产生的大量输入,输出具体的答案,组成一组标注数据。
Reinforcement Learning from Human Feedback (RLHF)
RLHF 即根据人类的反馈(例如判断某两个回答哪个更好),采用强化学习的方式,进一步提升模型的性能。
在先前的两个训练阶段,模型不断地在判断 next token 的输出是否正确,缺乏对整个文本内容全面的考量。在第三阶段,RLHF 通过人类反馈的 response 间的优劣关系,站在更全局性的视角,进一步地对模型进行优化。换句话说,前两个阶段更加关注 response 输出的过程,而 RLHF 这个阶段则更关注最终的结果,即整个 response 的质量。
在 RLHF 的过程中,首先需要训练一个 Reward Model,其输入为一个 response,输出为这个 response 的得分,可以根据人类给出的两个 response 之间的排序,训练这个奖励模型。
得到 Reward Model 后,最直接的用法是:让 LLM 对于特定的输入,输出多个回答,再根据 Reward Model 选择得分最高的回答。
进一步地,也可以使用 Reward Model 继续微调 LLM,即对于所有的输入,让 LLM 输出的得分低的 response 出现的概率更低,让 LLM 输出的得分高的 response 出现的概率更高。
Proximal Policy Optimization (PPO)
PPO 就是一种在 Reward Model 基础上,进一步优化模型参数的强化学习优化方法。
在强化学习流程中, t t t 时刻环境的状态为 s t s_t st,采取动作 a t a_t at 后,得到奖励 r t r_t rt,环境变成 s t + 1 s_{t+1} st+1。整个学习过程的目的是找到一个最佳策略,使得其能够根据环境状态选择最佳的动作。
上述的 r t r_t rt 仅为即时收益,为在决策过程中考虑未来多步的收益,强化学习中引入了状态价值函数 V t V_t Vt,其表示从当前状态开始,未来所有时刻所能累积的收益,通常表达为:
V t = r t + γ ⋅ V t + 1 , V_t=r_{t}+\gamma \cdot V_{t+1}, Vt=rt+γ⋅Vt+1,
其中 γ \gamma γ 作为折扣因子,使决策在短期奖励和长期收益间取得平衡,并且确保无限时间下累计的奖励和使有限的,避免累积奖励发散。
在 LLM 语境下,模型会在 t t t 时刻根据上文,产出一个 token o t o_t ot(对应动作 a t a_t at),对应即时奖励 r t r_{t} rt 和未来总收益 V t V_{t} Vt;由于 r t r_{t} rt 和 V t V_{t} Vt 都无法直接获取,整个 RLHF-PPO 阶段一共包含四个主要模型,分别是:
- Actor Model:输出每个时刻的 token,即我们想要继续优化的 LLM(通常采用指令微调后的模型初始化);
- Critic Model:根据 s t s_t st 估计时刻 t t t 的总收益 V t V_{t} Vt;
- Reward Model:即前文根据人类反馈数据训练得到的奖励模型;
- Reference Model:参考模型,避免语言模型在 RLHF 阶段训歪(同样通常采用指令微调后的模型初始化)。
不难发现 Reward Model 和 Reference Model 在 PPO 阶段都是参数冻结的,因此主要关键在于如何训练 Actor Model 和 Critic Model。
在介绍具体 loss 函数前,我们首先探究一下如何表示 r t r_{t} rt?由于前文训练得到的 Reward Model 仅能根据最终的 response 输出最终的奖励 r φ ( q , o ≤ T ) r_\varphi(q,o_{\leq T}) rφ(q,o≤T)(假设输入为 q q q,输出共 T T T 个 token),中间过程的奖励 r t r_{t} rt 无法通过 Reward Model 直接得到,因此在 deepspeed-chat 的 RLHF 实践中,采用 Actor Model 和 Reference Model 输出的差异(可以理解为动作分布的差异)来表示中间过程的奖励( β \beta β 为超参数):
r t = { − β ∗ ( log P ( o t ∣ q , o < t ) P r e f ( o t ∣ q , o < t ) ) , t ≠ T r φ ( q , o ≤ T ) − β ∗ ( log P ( o t ∣ q , o < t ) P r e f ( o t ∣ q , o < t ) ) , t = T r_{t}=\left\{\begin{array}{l} -\beta *\left(\log \frac{P\left(o_t \mid q,o_{<t}\right)}{P_{r e f}\left(o_t \mid q,o_{<t}\right)}\right), \quad t \neq T \\ r_\varphi(q,o_{\leq T})-\beta *\left(\log \frac{P\left(o_t \mid q,o_{<t}\right)}{P_{r e f}\left(o_t \mid q,o_{<t}\right)}\right), \quad t=T \end{array}\right. rt=⎩ ⎨ ⎧−β∗(logPref(ot∣q,o<t)P(ot∣q,o<t)),t=Trφ(q,o≤T)−β∗(logPref(ot∣q,o<t)P(ot∣q,o<t)),t=T
即 P ( o t ∣ q , o < t ) P(o_t\mid q,o_{<t}) P(ot∣q,o<t) 越大(和参考模型的输出越相似),即时奖励 r t r_{t} rt 越大。需要注意的是,上述仅是 r t r_{t} rt 的某一种设计。在 PPO 中,我们希望最大化如下目标( π θ \pi_{\theta} πθ 为具体的策略,代表 Actor 模型参数; τ \tau τ 代表一条轨迹,对应一个 response):
J ( θ ) = E τ ∼ π θ [ R ( τ ) ] = ∑ τ R ( τ ) P ( τ ∣ π θ ) . \mathcal{J}\left(\theta\right)=E_{\tau \sim \pi_\theta}[R(\tau)]=\sum_\tau R(\tau) P\left(\tau \mid \pi_\theta\right). J(θ)=Eτ∼πθ[R(τ)]=τ∑R(τ)P(τ∣πθ).
其相应梯度如下:
∇ J ( θ ) = ∑ τ R ( τ ) ∇ P ( τ ∣ π θ ) = ∑ τ R ( τ ) P ( τ ∣ π θ ) ∇ P ( τ ∣ π θ ) P ( τ ∣ π θ ) = ∑ τ R ( τ ) P ( τ ∣ π θ ) ∇ log ( P ( τ ∣ π θ ) ) = E τ ∼ π θ [ R ( τ ) ∇ log ( P ( τ ∣ π θ ) ) ] \begin{aligned} \nabla \mathcal{J}\left(\theta\right) & =\sum_\tau R(\tau) \nabla P\left(\tau \mid \pi_\theta\right) \\ & =\sum_\tau R(\tau) P\left(\tau \mid \pi_\theta\right) \frac{\nabla P\left(\tau \mid \pi_\theta\right)}{P\left(\tau \mid \pi_\theta\right)} \\ & =\sum_\tau R(\tau) P\left(\tau \mid \pi_\theta\right) \nabla \log \left(P\left(\tau \mid \pi_\theta\right)\right) \\ & =E_{\tau \sim \pi_\theta}\left[R(\tau) \nabla \log \left(P\left(\tau \mid \pi_\theta\right)\right)\right] \end{aligned} ∇J(θ)=τ∑R(τ)∇P(τ∣πθ)=τ∑R(τ)P(τ∣πθ)P(τ∣πθ)∇P(τ∣πθ)=τ∑R(τ)P(τ∣πθ)∇log(P(τ∣πθ))=Eτ∼πθ[R(τ)∇log(P(τ∣πθ))]
假设每条轨迹共有 T T T 个节点,则 P ( τ ∣ π θ ) = ρ 0 ( s 0 ) ∏ t = 1 T P ( s t + 1 ∣ s t , a t ) π θ ( a t ∣ s t ) P\left(\tau \mid \pi_\theta\right)=\rho_0\left(s_0\right) \prod_{t=1}^{T} P\left(s_{t+1} \mid s_t, a_t\right) \pi_\theta\left(a_t \mid s_t\right) P(τ∣πθ)=ρ0(s0)∏t=1TP(st+1∣st,at)πθ(at∣st),代入 ∇ J ( θ ) \nabla \mathcal{J}\left(\theta\right) ∇J(θ) 得到:
∇ J ( θ ) = E τ ∼ π θ [ R ( τ ) ∇ log ( P ( τ ∣ π θ ) ) ] = E τ ∼ π θ [ R ( τ ) ∑ t = 1 T ∇ log π θ ( a t ∣ s t ) ] \begin{aligned} \nabla \mathcal{J}\left(\theta\right) & =E_{\tau \sim \pi_\theta}\left[R(\tau) \nabla \log \left(P\left(\tau \mid \pi_\theta\right)\right)\right] \\ & =E_{\tau \sim \pi_\theta}\left[R(\tau) \sum_{t=1}^{T} \nabla \log \pi_\theta\left(a_t \mid s_t\right)\right] \end{aligned} ∇J(θ)=Eτ∼πθ[R(τ)∇log(P(τ∣πθ))]=Eτ∼πθ[R(τ)t=1∑T∇logπθ(at∣st)]
将 R ( τ ) R(\tau) R(τ) 拆分到每一步中,可以得到:
∇ J ( θ ) = E τ ∼ π θ [ ∑ t = 1 T Ψ t ∇ log π θ ( a t ∣ s t ) ] \begin{aligned} \nabla \mathcal{J}\left(\theta\right) & =E_{\tau \sim \pi_\theta}\left[\sum_{t=1}^{T} \Psi_t \nabla \log \pi_\theta\left(a_t \mid s_t\right)\right] \end{aligned} ∇J(θ)=Eτ∼πθ[t=1∑TΨt∇logπθ(at∣st)]
此处的 Ψ t \Psi_t Ψt 代表了当前的价值度量,其最好能同时表示「单步即时奖励」和「未来轨迹的整体收益」,在 PPO 中采用广义优势估计 (GAE) 中的优势函数 A t A_t At 表示,其定义为:
A t = ∑ l = 0 ∞ ( γ λ ) l δ t + l , A_t=\sum_{l=0}^{\infty}(\gamma \lambda)^l \delta_{t+l}, At=l=0∑∞(γλ)lδt+l,
其中 λ ∈ [ 0 , 1 ] \lambda\in [0,1] λ∈[0,1], δ t \delta_t δt 为 TD error,其代表采取行动 a t a_t at 后实际价值与预估价值之间的差距,即 δ t = r t + γ ⋅ V t + 1 − V t \delta_t=r_t+\gamma\cdot V_{t+1}-V_t δt=rt+γ⋅Vt+1−Vt,即此处的 A t A_t At 表示未来多步 TD error 的加权和,其可以表示为如下递归形式:
A t = δ t + γ λ A t + 1 . A_t=\delta_t+\gamma\lambda A_{t+1}. At=δt+γλAt+1.
由于轨迹结束时 A T = 0 A_T=0 AT=0,因此 A t A_t At 可在轨迹确定后,从后往前递归求解。由此我们可以得到下述大模型语境下,PPO 对应优化目标的梯度:
∇ J P P O ( θ ) = E [ q ∼ P ( Q ) , o ∼ π θ ( O ∣ q ) ] ∑ t = 1 ∣ o ∣ A t ∇ log π θ ( o t ∣ q , o < t ) . \nabla \mathcal{J}_{P P O}(\theta)=\mathbb{E}\left[q \sim P(Q), o \sim \pi_{\theta}(O \mid q)\right] \sum_{t=1}^{|o|}A_t \nabla \log \pi_\theta\left(o_t \mid q, o_{<t}\right) . ∇JPPO(θ)=E[q∼P(Q),o∼πθ(O∣q)]t=1∑∣o∣At∇logπθ(ot∣q,o<t).
在实际优化过程中,为提高样本利用率, π θ \pi_{\theta} πθ 采样得到的轨迹 o o o 会被重复使用来优化 π θ \pi_\theta πθ,即采样轨迹 o o o 的 π θ o l d \pi_{\theta_{old}} πθold 和要优化的 π θ \pi_{\theta} πθ 不一样(off-policy),因此可以采用 Importance Sampling 的方式修正上述梯度:
∇ J P P O ( θ ) = E [ q ∼ P ( Q ) , o ∼ π θ o l d ( O ∣ q ) ] ∑ t = 1 ∣ o ∣ π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) A t ∇ log π θ ( o t ∣ q , o < t ) . \nabla \mathcal{J}_{P P O}(\theta)=\mathbb{E}\left[q \sim P(Q), o \sim \pi_{\theta_{old}}(O \mid q)\right] \sum_{t=1}^{|o|} \frac{\pi_\theta\left(o_t \mid q, o_{<t}\right)}{\pi_{\theta_{o l d}}(o_t \mid q, o_{<t})} A_t \nabla \log \pi_\theta\left(o_t \mid q, o_{<t}\right) . ∇JPPO(θ)=E[q∼P(Q),o∼πθold(O∣q)]t=1∑∣o∣πθold(ot∣q,o<t)πθ(ot∣q,o<t)At∇logπθ(ot∣q,o<t).
由于 ∇ log f ( θ ) = ∇ f ( θ ) f ( θ ) \nabla \log f(\theta)=\frac{\nabla f(\theta)}{f(\theta)} ∇logf(θ)=f(θ)∇f(θ),上述梯度对应的优化目标如下:
J P P O ( θ ) = E [ q ∼ P ( Q ) , o ∼ π θ o l d ( O ∣ q ) ] ∑ t = 1 ∣ o ∣ π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) A t . \mathcal{J}_{P P O}(\theta)=\mathbb{E}\left[q \sim P(Q), o \sim \pi_{\theta_{old}}(O \mid q)\right] \sum_{t=1}^{|o|} \frac{\pi_\theta\left(o_t \mid q, o_{<t}\right)}{\pi_{\theta_{o l d}}(o_t \mid q, o_{<t})} A_t. JPPO(θ)=E[q∼P(Q),o∼πθold(O∣q)]t=1∑∣o∣πθold(ot∣q,o<t)πθ(ot∣q,o<t)At.
为了使整体训练更稳定,最终的优化目标会对 π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) \frac{\pi_\theta\left(o_t \mid q, o_{<t}\right)}{\pi_{\theta_{o l d}}(o_t \mid q, o_{<t})} πθold(ot∣q,o<t)πθ(ot∣q,o<t) 进行裁剪,避免该值过大或者过小;并且由于不同轨迹可能长度差异很大,优化目标会对轨迹长度进行归一化;最终 PPO 所要最大化的目标如下所示:
J P P O ( θ ) = E [ q ∼ P ( Q ) , o ∼ π θ o l d ( O ∣ q ) ] 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ min [ π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) A t , clip ( π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) , 1 − ε , 1 + ε ) A t ] . \mathcal{J}_{P P O}(\theta)=\mathbb{E}\left[q \sim P(Q), o \sim \pi_{\theta_{o l d}}(O \mid q)\right] \frac{1}{|o|} \sum_{t=1}^{|o|} \min \left[\frac{\pi_\theta\left(o_t \mid q, o_{<t}\right)}{\pi_{\theta_{o l d}}\left(o_t \mid q, o_{<t}\right)} A_t, \operatorname{clip}\left(\frac{\pi_\theta\left(o_t \mid q, o_{<t}\right)}{\pi_{\theta_{o l d}}\left(o_t \mid q, o_{<t}\right)}, 1-\varepsilon, 1+\varepsilon\right) A_t\right]. JPPO(θ)=E[q∼P(Q),o∼πθold(O∣q)]∣o∣1t=1∑∣o∣min[πθold(ot∣q,o<t)πθ(ot∣q,o<t)At,clip(πθold(ot∣q,o<t)πθ(ot∣q,o<t),1−ε,1+ε)At].
相对应地,Critic 模型的优化目标可以理解为最小化优势 A t A_t At,即让 V t V_t Vt 对局面的评估更加精准,具体目标可写作如下形式:
arg min V ϕ E t [ max [ ( V t − ( A t + V t o l d ) ) 2 , ( V t c l i p − ( A t + V t o l d ) ) 2 ] ] , \arg \min _{V_\phi} \mathbb{E}_t\left[\max\left[(V_t-(A_t+V_t^{old}))^2,(V_t^{clip}-(A_t+V_t^{old}))^2\right]\right], argVϕminEt[max[(Vt−(At+Vtold))2,(Vtclip−(At+Vtold))2]],
其中 V t c l i p = clip ( V t , V t o l d − ϵ , V t o l d + ϵ ) V_t^{clip}=\text{clip}(V_t,V_t^{old}-\epsilon,V_t^{old}+\epsilon) Vtclip=clip(Vt,Vtold−ϵ,Vtold+ϵ).
Direct Preference Optimization (DPO)
在上述 RLHF-PPO 的训练中,存在「显存占用大」、「超参多」以及「模型训练不稳定」等一系列问题,为简化整体训练过程,DPO 应运而生,其对 PPO 的改进主要为如下两点(如下图所示):
- 不再训练 Reward Model,而是直接基于人类反馈的数据,一步到位训练最终的模型;
- 简化原始训练目标,不再使用强化学习的方法,而是通过类似于监督微调的方式进行训练。

首先,RLHF 阶段整体目标如下( π θ , π ref , r ϕ \pi_{\theta},\pi_{\text{ref}},r_{\phi} πθ,πref,rϕ 分别对应上述的 Actor、参考模型以及 Reward Model):
- 最大化奖励的同时,避免训练后得到的 π θ \pi_{\theta} πθ 与参考模型 π ref \pi_{\text{ref}} πref 差异过大.
max π θ E x ∼ D , y ∼ π θ ( y ∣ x ) [ r ϕ ( x , y ) ] − β D K L [ π θ ( y ∣ x ) ∥ π r e f ( y ∣ x ) ] . \max _{\pi_\theta} \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_\theta(y \mid x)}\left[r_\phi(x, y)\right]-\beta \mathbb{D}_{\mathrm{KL}}\left[\pi_\theta(y \mid x) \| \pi_{\mathrm{ref}}(y \mid x)\right]. πθmaxEx∼D,y∼πθ(y∣x)[rϕ(x,y)]−βDKL[πθ(y∣x)∥πref(y∣x)].
为了绕过 Reward Model,上述式子可以进行如下推导:
max π E x ∼ D , y ∼ π ( y ∣ x ) [ r ( x , y ) ] − β D K L [ π ( y ∣ x ) ∥ π r e f ( y ∣ x ) ] = max π E x ∼ D E y ∼ π ( y ∣ x ) [ r ( x , y ) − β log π ( y ∣ x ) π r e f ( y ∣ x ) ] = min π E x ∼ D E y ∼ π ( y ∣ x ) [ log π ( y ∣ x ) π r e f ( y ∣ x ) − 1 β r ( x , y ) ] = min π E x ∼ D E y ∼ π ( y ∣ x ) [ log π ( y ∣ x ) 1 Z ( x ) π r e f ( y ∣ x ) exp ( 1 β r ( x , y ) ) − log Z ( x ) ] . \begin{aligned} & \ \ \ \ \max _\pi \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi(y \mid x)} {[r(x, y)]-\beta \mathbb{D}_{\mathrm{KL}}\left[\pi(y \mid x) \| \pi_{\mathrm{ref}}(y \mid x)\right] } \\ & =\max _\pi \mathbb{E}_{x \sim \mathcal{D}} \mathbb{E}_{y \sim \pi(y \mid x)}\left[r(x, y)-\beta \log \frac{\pi(y \mid x)}{\pi_{\mathrm{ref}}(y \mid x)}\right] \\ & =\min _\pi \mathbb{E}_{x \sim \mathcal{D}} \mathbb{E}_{y \sim \pi(y \mid x)}\left[\log \frac{\pi(y \mid x)}{\pi_{\mathrm{ref}}(y \mid x)}-\frac{1}{\beta} r(x, y)\right] \\ & =\min _\pi \mathbb{E}_{x \sim \mathcal{D}} \mathbb{E}_{y \sim \pi(y \mid x)}\left[\log \frac{\pi(y\mid x)}{\frac{1}{Z(x)} \pi_{\mathrm{ref}}(y \mid x) \exp \left(\frac{1}{\beta} r(x, y)\right)}-\log Z(x)\right]. \end{aligned} πmaxEx∼D,y∼π(y∣x)[r(x,y)]−βDKL[π(y∣x)∥πref(y∣x)]=πmaxEx∼DEy∼π(y∣x)[r(x,y)−βlogπref(y∣x)π(y∣x)]=πminEx∼DEy∼π(y∣x)[logπref(y∣x)π(y∣x)−β1r(x,y)]=πminEx∼DEy∼π(y∣x) logZ(x)1πref(y∣x)exp(β1r(x,y))π(y∣x)−logZ(x) .
令 Z ( x ) = ∑ y π r e f ( y ∣ x ) exp ( 1 β r ( x , y ) ) Z(x)=\sum_y \pi_{\mathrm{ref}}(y \mid x) \exp \left(\frac{1}{\beta} r(x, y)\right) Z(x)=∑yπref(y∣x)exp(β1r(x,y)),可以将上述式子中 log \log log 项分母部分转化为一个概率分布,整体优化目标可以视作最小化 π ( y ∣ x ) \pi(y\mid x) π(y∣x) 和 1 Z ( x ) π r e f ( y ∣ x ) exp ( 1 β r ( x , y ) ) \frac{1}{Z(x)} \pi_{\mathrm{ref}}(y \mid x) \exp \left(\frac{1}{\beta} r(x, y)\right) Z(x)1πref(y∣x)exp(β1r(x,y)) 之间的 KL 散度。由于 Z ( x ) Z(x) Z(x) 与 π \pi π 无关,因此上述式子的最优解 π ∗ \pi^* π∗ 可以表示为:
π ∗ ( y ∣ x ) = 1 Z ( x ) π ref ( y ∣ x ) exp ( 1 β r ( x , y ) ) . \pi^*(y \mid x)=\frac{1}{Z(x)} \pi_{\text {ref }}(y \mid x) \exp \left(\frac{1}{\beta} r(x, y)\right). π∗(y∣x)=Z(x)1πref (y∣x)exp(β1r(x,y)).
相对应地,奖励模型 r r r 也可以表示为如下形式:
r ∗ ( x , y ) = β log π ∗ ( y ∣ x ) π r e f ( y ∣ x ) + β log Z ( x ) . r^*(x, y)=\beta \log \frac{\pi^*(y \mid x)}{\pi_{\mathrm{ref}}(y \mid x)}+\beta \log Z(x). r∗(x,y)=βlogπref(y∣x)π∗(y∣x)+βlogZ(x).
接下来,只要我们在奖励模型的训练目标中代入上式,即可实现直接对最终策略 π ∗ \pi^* π∗ 的优化。在奖励模型的训练中,通常有如下 2 种偏好排序方法:
- 只对两个回答进行排序,即对于 prompt x x x,回答 y 1 y_1 y1 优于 y 2 y_2 y2,对应的优化目标采用 Bradley-Terry 模型进行建模;
- 对 K K K 个回答进行排序,即对于 prompt x x x,排序顺序为 y 1 > y 2 > . . . > y K y_1>y_2>...>y_K y1>y2>...>yK,对应的优化目标采用 Plackett-Luce 模型进行建模。
DPO Objective Under the Bradley-Terry Model
在 BT 模型下,回答 y 1 y_1 y1 优于 y 2 y_2 y2 的概率建模如下:
p ∗ ( y 1 ≻ y 2 ∣ x ) = exp ( r ∗ ( x , y 1 ) ) exp ( r ∗ ( x , y 1 ) ) + exp ( r ∗ ( x , y 2 ) ) . p^*\left(y_1 \succ y_2 \mid x\right)=\frac{\exp \left(r^*\left(x, y_1\right)\right)}{\exp \left(r^*\left(x, y_1\right)\right)+\exp \left(r^*\left(x, y_2\right)\right)}. p∗(y1≻y2∣x)=exp(r∗(x,y1))+exp(r∗(x,y2))exp(r∗(x,y1)).
代入 π ∗ \pi^* π∗,可以将上述式子进行如下转换:
p ∗ ( y 1 ≻ y 2 ∣ x ) = exp ( β log π ∗ ( y 1 ∣ x ) π ref ( y 1 ∣ x ) + β log Z ( x ) ) exp ( β log π ∗ ( y 1 ∣ x ) π ref ( y 1 ∣ x ) + β log Z ( x ) ) + exp ( β log π ∗ ( y 2 ∣ x ) π ref ( y 2 ∣ x ) + β log Z ( x ) ) = 1 1 + exp ( β log π ∗ ( y 2 ∣ x ) π ref ( y 2 ∣ x ) − β log π ∗ ( y 1 ∣ x ) π ref ( y 1 ∣ x ) ) = σ ( β log π ∗ ( y 1 ∣ x ) π ref ( y 1 ∣ x ) − β log π ∗ ( y 2 ∣ x ) π ref ( y 2 ∣ x ) ) . \begin{aligned} p^*\left(y_1 \succ y_2 \mid x\right) & =\frac{\exp \left(\beta \log \frac{\pi^*\left(y_1 \mid x\right)}{\pi_{\text {ref }}\left(y_1 \mid x\right)}+\beta \log Z(x)\right)}{\exp \left(\beta \log \frac{\pi^*\left(y_1 \mid x\right)}{\pi_{\text {ref }}\left(y_1 \mid x\right)}+\beta \log Z(x)\right)+\exp \left(\beta \log \frac{\pi^*\left(y_2 \mid x\right)}{\pi_{\text {ref }}\left(y_2 \mid x\right)}+\beta \log Z(x)\right)} \\ & =\frac{1}{1+\exp \left(\beta \log \frac{\pi^*\left(y_2 \mid x\right)}{\pi_{\text {ref }}\left(y_2 \mid x\right)}-\beta \log \frac{\pi^*\left(y_1 \mid x\right)}{\pi_{\text {ref }}\left(y_1 \mid x\right)}\right)} \\ & =\sigma\left(\beta \log \frac{\pi^*\left(y_1 \mid x\right)}{\pi_{\text {ref }}\left(y_1 \mid x\right)}-\beta \log \frac{\pi^*\left(y_2 \mid x\right)}{\pi_{\text {ref }}\left(y_2 \mid x\right)}\right) . \end{aligned} p∗(y1≻y2∣x)=exp(βlogπref (y1∣x)π∗(y1∣x)+βlogZ(x))+exp(βlogπref (y2∣x)π∗(y2∣x)+βlogZ(x))exp(βlogπref (y1∣x)π∗(y1∣x)+βlogZ(x))=1+exp(βlogπref (y2∣x)π∗(y2∣x)−βlogπref (y1∣x)π∗(y1∣x))1=σ(βlogπref (y1∣x)π∗(y1∣x)−βlogπref (y2∣x)π∗(y2∣x)).
由于我们希望 y w y_w yw (更符合人类偏好的回答) 的概率尽可能大于 y l y_l yl (未被选中的回答),因此整体优化目标可以写作如下形式:
L D P O ( π θ ; π r e f ) = − E ( x , y w , y l ) ∼ D [ log p ( y w ≻ y l ∣ x ) ] = − E ( x , y w , y l ) ∼ D [ log σ ( β log π θ ( y w ∣ x ) π r e f ( y w ∣ x ) − β log π θ ( y l ∣ x ) π r e f ( y l ∣ x ) ) ] . \begin{aligned} \mathcal{L}_{\mathrm{DPO}}\left(\pi_\theta ; \pi_{\mathrm{ref}}\right)&= -\mathbb{E}_{\left(x, y_w, y_l\right) \sim \mathcal{D}}[\log p(y_w \succ y_l \mid x)]\\ &=- \mathbb{E}_{\left(x, y_w, y_l\right) \sim \mathcal{D}}\left[\log \sigma\left(\beta \log \frac{\pi_\theta\left(y_w \mid x\right)}{\pi_{\mathrm{ref}}\left(y_w \mid x\right)}-\beta \log \frac{\pi_\theta\left(y_l \mid x\right)}{\pi_{\mathrm{ref}}\left(y_l \mid x\right)}\right)\right]. \end{aligned} LDPO(πθ;πref)=−E(x,yw,yl)∼D[logp(yw≻yl∣x)]=−E(x,yw,yl)∼D[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))].
上述优化目标中不包含 Reward Model,由此可以绕过训练 Reward Model 的环节,直接用成对的偏好数据,采用类似 SFT 的方式训练对齐模型。
DPO Objective Under the Plackett-Luce Model
类似地,在 PL 模型下,偏好排序 τ \tau τ( y 1 > y 2 > . . . > y K y_1>y_2>...>y_K y1>y2>...>yK)的概率建模如下:
p ∗ ( τ ∣ y 1 , … , y K , x ) = ∏ k = 1 K exp ( r ∗ ( x , y τ ( k ) ) ) ∑ j = k K exp ( r ∗ ( x , y τ ( j ) ) ) . p^*\left(\tau \mid y_1, \ldots, y_K, x\right)=\prod_{k=1}^K \frac{\exp \left(r^*\left(x, y_{\tau(k)}\right)\right)}{\sum_{j=k}^K \exp \left(r^*\left(x, y_{\tau(j)}\right)\right)}. p∗(τ∣y1,…,yK,x)=k=1∏K∑j=kKexp(r∗(x,yτ(j)))exp(r∗(x,yτ(k))).
代入 π ∗ \pi^* π∗,可以得到如下优化目标(由于 Z ( x ) Z(x) Z(x) 与 π θ \pi_{\theta} πθ 无关,因此下式中省去了 Z ( x ) Z(x) Z(x)):
L D P O ( π θ ; π r e f ) = − E τ , y 1 , … , y K , x ∼ D [ log p ( τ ∣ y 1 , … , y K , x ) ] = − E τ , y 1 , … , y K , x ∼ D [ log ∏ k = 1 K exp ( β log π θ ( y τ ( k ) ∣ x ) π r e f ( y τ ( k ) ∣ x ) ) ∑ j = k K exp ( β log π θ ( y τ ( j ) ∣ x ) π r e f ( y τ ( j ) ∣ x ) ) ] . \begin{aligned} \mathcal{L}_{\mathrm{DPO}}\left(\pi_\theta ; \pi_{\mathrm{ref}}\right)&= -\mathbb{E}_{\tau, y_1, \ldots, y_K, x \sim \mathcal{D}}[\log p(\tau \mid y_1, \ldots, y_K, x)]\\ &=-\mathbb{E}_{\tau, y_1, \ldots, y_K, x \sim \mathcal{D}}\left[\log \prod_{k=1}^K \frac{\exp \left(\beta \log \frac{\pi_\theta\left(y_{\tau(k)} \mid x\right)}{\pi_{\mathrm{ref}}\left(y_{\tau(k)} \mid x\right)}\right)}{\sum_{j=k}^K \exp \left(\beta \log \frac{\pi_\theta\left(y_{\tau(j)} \mid x\right)}{\pi_{\mathrm{ref}}\left(y_{\tau(j)} \mid x\right)}\right)}\right]. \end{aligned} LDPO(πθ;πref)=−Eτ,y1,…,yK,x∼D[logp(τ∣y1,…,yK,x)]=−Eτ,y1,…,yK,x∼D logk=1∏K∑j=kKexp(βlogπref(yτ(j)∣x)πθ(yτ(j)∣x))exp(βlogπref(yτ(k)∣x)πθ(yτ(k)∣x)) .
Group Relative Policy Optimization (GRPO)
GRPO 是在 PPO 上的进一步变化,其省略了 PPO 过程中对 Critic Model (Value Model) 的建模,并且不再对中间过程的 reward 进行建模,而是直接优化整个回答的 reward,其 Policy Model 最大化的目标函数如下:
J G R P O ( θ ) = E [ q ∼ P ( Q ) , { o i } i = 1 G ∼ π θ o l d ( O ∣ q ) ] 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ { min [ π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) A ^ i , t , clip ( π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) , 1 − ε , 1 + ε ) A ^ i , t ] − β D K L [ π θ ∣ ∣ π r e f ] } . \begin{aligned} \mathcal{J}_{G R P O}(\theta) & =\mathbb{E}\left[q \sim P(Q),\left\{o_i\right\}_{i=1}^G \sim \pi_{\theta_{o l d}}(O \mid q)\right] \\ & \frac{1}{G} \sum_{i=1}^G \frac{1}{\left|o_i\right|} \sum_{t=1}^{\left|o_i\right|}\left\{\min \left[\frac{\pi_\theta\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta_{o l d}}\left(o_{i, t} \mid q, o_{i,<t}\right)} \hat{A}_{i, t}, \operatorname{clip}\left(\frac{\pi_\theta\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta_{o l d}}\left(o_{i, t} \mid q, o_{i,<t}\right)}, 1-\varepsilon, 1+\varepsilon\right) \hat{A}_{i, t}\right]-\beta \mathbb{D}_{K L}\left[\pi_\theta| | \pi_{r e f}\right]\right\}. \end{aligned} JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G∣oi∣1t=1∑∣oi∣{min[πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ε,1+ε)A^i,t]−βDKL[πθ∣∣πref]}.
不同于 PPO 的优化目标,GRPO 一次性采样一组输出 { o i } i = 1 G \{o_i\}_{i=1}^G {oi}i=1G,其对应的整体 reward 为 r = { r i } i = 1 G \boldsymbol{r}=\{r_i\}_{i=1}^G r={ri}i=1G(由 Reward Model 得到),随后 A ^ i , t \hat{A}_{i,t} A^i,t 被定义为 o i o_i oi 所对应的标准化后的 reward,即:
A ^ i , t = r ^ i = r i − mean ( r ) std ( r ) . \hat{A}_{i,t}=\hat{r}_i=\frac{r_i-\text{mean}(\boldsymbol{r})}{\text{std}(\boldsymbol{r})}. A^i,t=r^i=std(r)ri−mean(r).
在复杂数学任务场景下,每个 reasoning step 也有其对应的 reward,即:
R = { { r 1 index ( 1 ) , ⋯ , r 1 index ( K 1 ) } , ⋯ , { r G index ( 1 ) , ⋯ , r G index ( K G ) } } , \mathbf{R}=\left\{\left\{r_1^{\text {index }(1)}, \cdots, r_1^{\operatorname{index}\left(K_1\right)}\right\}, \cdots,\left\{r_G^{\operatorname{index}(1)}, \cdots, r_G^{\operatorname{index}\left(K_G\right)}\right\}\right\}, R={{r1index (1),⋯,r1index(K1)},⋯,{rGindex(1),⋯,rGindex(KG)}},
其中 index ( j ) \text{index}(j) index(j) 为第 j j j 步推理结束时的 token index,此时的 A ^ i , t \hat{A}_{i,t} A^i,t 可以进行如下定义:
A ^ i , t = ∑ index ( j ) ≥ t r ^ i index ( j ) , r ^ i index ( j ) = r i index ( j ) − mean ( R ) std ( R ) . \hat{A}_{i, t}=\sum_{\text {index }(j) \geq t} \hat{r}_i^{\text {index }(j)}, \hat{r}_i^{\text {index }(j)}=\frac{r_i^{\text {index }(j)}-\operatorname{mean}(\mathbf{R})}{\operatorname{std}(\mathbf{R})}. A^i,t=index (j)≥t∑r^iindex (j),r^iindex (j)=std(R)riindex (j)−mean(R).
另外由于上述 reward 定义中不再包含与 π r e f \pi_{ref} πref 的 KL 散度约束,因此直接将 D K L [ π θ ∣ ∣ π r e f ] \mathbb{D}_{K L}\left[\pi_\theta| | \pi_{r e f}\right] DKL[πθ∣∣πref] 显式建模在了 J G R P O ( θ ) \mathcal{J}_{G R P O}(\theta) JGRPO(θ) 之中,其具体式子如下:
D K L [ π θ ∣ ∣ π r e f ] = π r e f ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − log π r e f ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − 1 , \mathbb{D}_{K L}\left[\pi_\theta| | \pi_{r e f}\right]=\frac{\pi_{r e f}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_\theta\left(o_{i, t} \mid q, o_{i,<t}\right)}-\log \frac{\pi_{r e f}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_\theta\left(o_{i, t} \mid q, o_{i,<t}\right)}-1, DKL[πθ∣∣πref]=πθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−logπθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−1,
上述式子为对 D K L [ π θ ∣ ∣ π r e f ] \mathbb{D}_{K L}\left[\pi_\theta| | \pi_{r e f}\right] DKL[πθ∣∣πref] 的无偏估计,即期望相同。整体优化算法的伪代码如下所示:

GRPO 与 PPO 的方法对比图如下,可以看到 GRPO 中不再需要训练 Value Model:

Other Discussion
除了 RLHF,也可以使用 RLAIF,即让 LLM 自己来判断哪个回答更好,根据 LLM 判断的结果再来微调具体的模型,判断回答好的 LLM 既可以使用类似 GPT-4 等已有模型,甚至也可以使用正在训练的这个模型。
此外,RLHF 仍然面临一个困难,即 “好” 这件事并没有一个固定的标准,例如对于一个不太安全的问题,一个回答更考虑 Safety,而另一个回答与问题关系更密切,此时应该选择哪一个答案呢?另外,许多回答,即使人类来判断,也难以辨别哪个更好,此时 RLHF 又该如何继续提升呢?
参考资料
- Hung-yi Lee: 生成式 AI 导论 2024 - 第 6 讲
- Hung-yi Lee: 生成式 AI 导论 2024 - 第 7 讲
- Hung-yi Lee: 生成式 AI 导论 2024 - 第 8 讲
- arXiv20 GPT3 - Language Models are Few-Shot Learners
- arXiv22 Instruct GPT - Training language models to follow instructions with human feedback
- arXiv22 Self-Instruct: Aligning Language Models with Self-Generated Instructions
- arXiv23 DPO: Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- arXiv24 Self-Rewarding Language Models
- arXiv24 GRPO: DeepSeekMath - Pushing the Limits of Mathematical Reasoning in Open Language Models
- 知乎 - PPO 原理与源码解读 / RL-PPO理论知识 / DPO 数学原理 / 如何理解 PPO 和 GRPO
相关文章:
大型语言模型训练的三个阶段:Pre-Train、Instruction Fine-tuning、RLHF (PPO / DPO / GRPO)
前言 如果你对这篇文章可感兴趣,可以点击「【访客必读 - 指引页】一文囊括主页内所有高质量博客」,查看完整博客分类与对应链接。 当前的大型语言模型训练大致可以分为如下三个阶段: Pre-train:根据大量可获得的文本资料&#…...

Elasticsearch 2025/3/7
高性能分布式搜索引擎。 数据库模糊搜索比较慢,但用搜索引擎快多了。 下面是一些搜索引擎排名 Lucene是一个Java语言的搜索引擎类库(一个工具包),apache公司的顶级项目。 优势:易扩展、高性能(基于倒排索引…...

发行基础:热销商品榜单
转载自官方文件 ------------------ 热销商品榜单 Steam 在整个商店范围内有各种热销商品榜单,最醒目的莫过于 Steam 主页上的榜单了。 您也可以在浏览单个标签、主题、类型时找到针对某个游戏类别的热销商品榜单。 主页热销商品榜单 该榜单出现在 Steam 主页上…...

实战案例分享:Android WLAN Hal层移植(MTK+QCA6696)
本文将详细介绍基于MTK平台,适配高通(Qualcomm)QCA6696芯片的Android WLAN HAL层的移植过程,包括HIDL接口定义、Wi-Fi驱动移植以及wpa_supplicant适配过程,涵盖STA与AP模式的常见问题与解决方法。 1. HIDL接口简介 HID…...

物联网系统搭建
实验项目名称 构建物联网系统 实验目的 掌握物联网系统的一般构建方法。 实验要求: 1.构建物联网系统,实现前后端的交互。 实验内容: CS模式MQTT(不带数据分析处理功能) 实现智能设备与应用客户端的交…...

微前端框架 Qiankun 的应用及问题分析
一、Qiankun 的核心应用场景与优势 多技术栈共存与灵活集成 Qiankun 支持主应用与子应用使用不同技术栈(如 Vue、React、Angular 等),通过 HTML Entry 方式接入子应用,无需深度改造子应用即可实现集成,降低了技术迁移成…...

设计模式-结构型模式-适配器模式
概述 适配器模式 : Adapter Pattern 是一种结构型设计模式. 作用 : 使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。 实现思路 : 适配器模式通过将一个类的接口转换成客户希望的另外一个接口来实现这一点。 这里的“接口”指的是类所提供的…...
)
6. 机器人实现远程遥控(具身智能机器人套件)
1. 启动控制脚本 远程作到 Raspberry Pi 中,并运行以下脚本: conda activate lerobotpython lerobot/scripts/control_robot.py \--robot.typelekiwi \--control.typeremote_robot登录笔记本电脑上,同时运行以下脚本: conda ac…...

多模态知识图谱融合
1.Knowledge Graphs Meet Multi-Modal Learning: A Comprehensive Survey 1.1多模态实体对齐 1.2多模态实体链接 研究进展&#...

windows 平台如何点击网页上的url ,会打开远程桌面连接服务器
你可以使用自定义协议方案(Protocol Scheme)实现网页上点击URL后自动启动远程桌面连接(mstsc),参考你提供的C代码思路,如下实现: 第一步:注册自定义协议 使用类似openmstsc://协议…...

基于Spark的热门动漫推荐数据分析与可视化系统的设计与实现(采用Python语言Django框架,Hadoop,spider爬虫等技术实现)
基于Hadoop的热门动漫推荐数据分析与可视化系统 基于Django的热门动漫推荐数据分析与可视化系统 1. 开发工具和实现技术 Pycharm, Python3.7,Django框架,Hadoop,Spark,Hive,spider爬虫(爬取动漫之家的动…...
)
8. 机器人模型训练与评估(具身智能机器人套件)
1. 训练 使用python lerobot/scripts/train.py可以进行机器人控制模型训练,一般需要几个小时,可以在outputs/train/act_lekiwi_test/checkpoints查看锚点数据,下面为一组示例参数: python lerobot/scripts/train.py \--dataset.…...

计算机网络-服务器模型
一.服务器模型 1.支持多客户端访问 //单循环服务器 socket bind listen while(1) { accept while(1) { recv/send } } close 注:该模式remvform为阻塞态,服务器将等待接收数据 2..支持多客户端同时访问 (并发能力) socket…...

DeepSeek大模型 —— 全维度技术解析
DeepSeek大模型 —— 全维度技术解析 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,可以分享一下给大家。点击跳转到网站。 https://www.captainbed.cn/ccc 文章目录 DeepSeek大模型 —— 全维度技术解析一、模型架构全景解析1…...

OSPF网络类型:NBMA与P2MP
一、NBMA网络 NBMA网络的特点 连接方式: 支持多台设备连接到同一个网络段,但网络本身不支持广播或组播。典型例子:帧中继、ATM。 DR/BDR选举: 由于网络不支持广播,OSPF需要手动配置邻居。 仍然会选举DR(…...
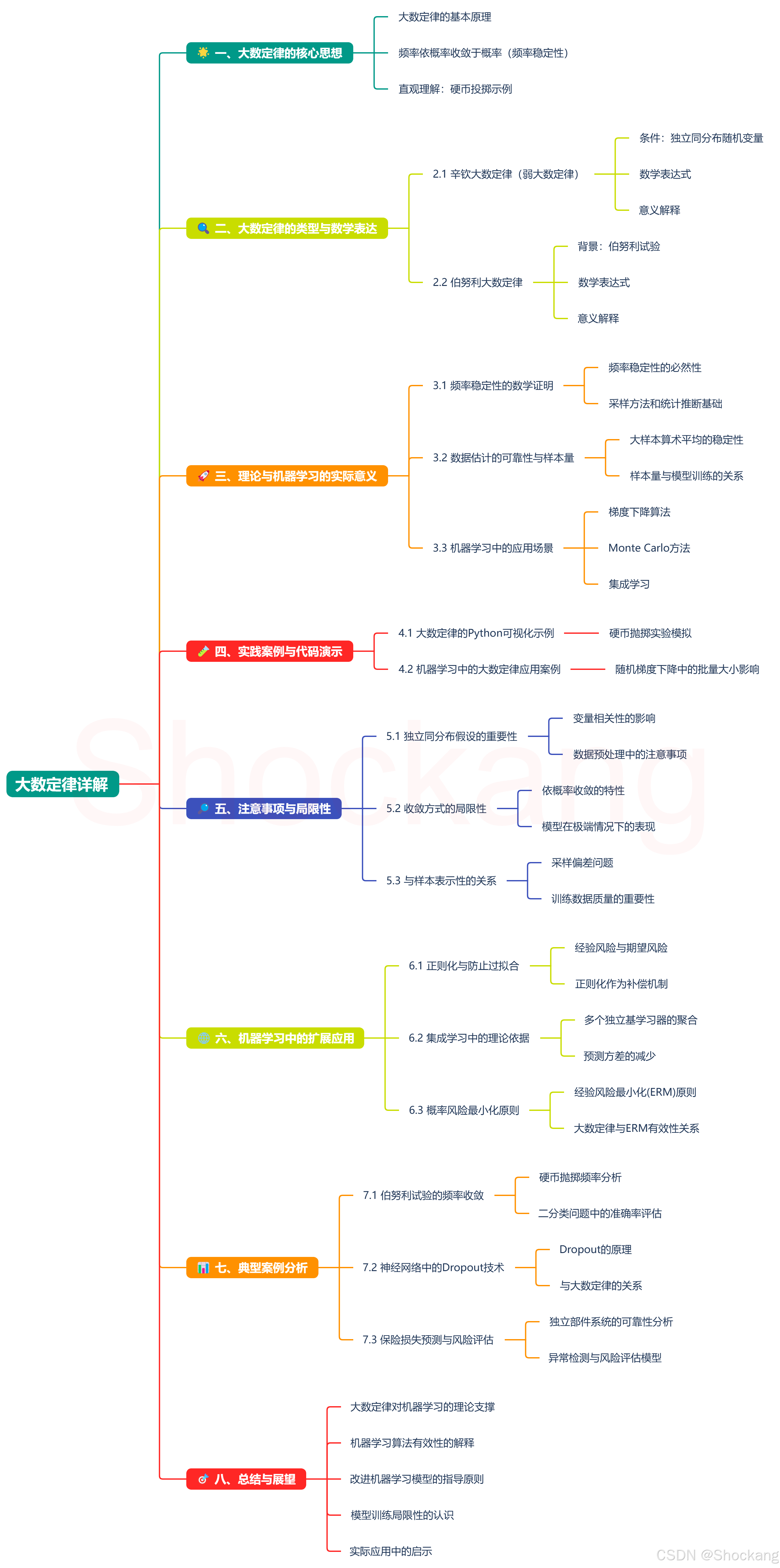
大数定律详解
前言 本文隶属于专栏《机器学习数学通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见《机器学习数学通关指南》 正文 🌟 一、大数定律的…...

2025生物科技革命:AI驱动的基因编辑与合成生物学新纪元
一、基因编辑技术的精准化突破 第三代基因编辑工具CRISPR-Cas12f的研发成功,将编辑精度提升至0.1碱基对级别。中国科学院团队利用该技术在灵长类动物模型中修复遗传性视网膜病变基因,治愈率达到92%。对比传统CRISPR-Cas9技术,新型编辑器脱靶…...

百度SEO关键词布局从堆砌到场景化的转型指南
百度SEO关键词布局:从“堆砌”到“场景化”的转型指南 引言 在搜索引擎优化(SEO)领域,关键词布局一直是核心策略之一。然而,随着搜索引擎算法的不断升级和用户需求的多样化,传统的“关键词堆砌”策略已经…...

macOS常用网络管理配置命令
目录 **1. ifconfig:查看和配置网络接口****2. networksetup:管理系统网络配置****3. ping:测试网络连通性****4. traceroute:跟踪数据包路径****5. nslookup/dig:DNS 查询****6. netstat:查看网络连接和统…...

Selenium 中 ActionChains 支持的鼠标和键盘操作设置及最佳实践
Selenium 中 ActionChains 支持的鼠标和键盘操作设置及最佳实践 一、引言 在使用 Selenium 进行自动化测试时,ActionChains 类提供了强大的功能,用于模拟鼠标和键盘的各种操作。通过 ActionChains,可以实现复杂的用户交互,如鼠标…...

深入解析瑞芯微RK3399/RK3288平台ISP驱动:从V4L2框架到Camera Sensor联动
1. 项目概述 在嵌入式Linux开发,特别是涉及多媒体处理的项目中,图像信号处理器(ISP)驱动的理解往往是打通摄像头应用链路的关键一环,也是很多开发者感觉“黑盒”最多的地方。最近在调试基于瑞芯微RK3399和RK3288平台的…...

ISG系统三大电机结构深度解析:永磁同步、感应与开关磁阻电机对比
1. 项目概述:从“电机”到“ISG系统”的深度关联在混合动力与新能源车领域,ISG(Integrated Starter Generator,集成式启动发电一体机)系统是一个核心的动力单元。它不像传统汽车那样,启动电机和发电机是分开…...
GalTransl代码架构分析:理解多进程插件系统的设计原理
GalTransl代码架构分析:理解多进程插件系统的设计原理 【免费下载链接】GalTransl 支持GPT-4/Claude/Deepseek/Sakura等大语言模型的Galgame自动化翻译解决方案 Automated translation solution for visual novels supporting GPT-4/Claude/Deepseek/Sakura 项目地…...

【独家首发】ElevenLabs尚未官方支持的希伯来文增强模式:基于phoneme-level微调的48小时快速部署方案
更多请点击: https://intelliparadigm.com 第一章:希伯来文语音合成的技术挑战与ElevenLabs生态定位 希伯来文是一种自右向左(RTL)书写的辅音音素文字,其语音合成面临多重语言学与工程学挑战:元音符号&…...
)
保姆级教程:为Ultralytics YOLOv8 v8.0+ 添加mAP75和mAP90输出(附完整代码与验证方法)
深度优化YOLOv8评估体系:实战添加mAP75与mAP90指标全指南 当目标检测模型的mAP50达到80%以上时,研究者常陷入性能提升的瓶颈期。此时,引入mAP75和mAP90等更严格的评估指标,能有效区分"优秀"与"卓越"模型的边界…...

Steam库存管理革命:5分钟掌握批量操作终极指南
Steam库存管理革命:5分钟掌握批量操作终极指南 【免费下载链接】Steam-Economy-Enhancer 中文版:Enhances the Steam Inventory and Steam Market. 项目地址: https://gitcode.com/gh_mirrors/ste/Steam-Economy-Enhancer Steam Economy Enhancer…...

2026 电子招投标全流程操作指南:环境搭建→签章→上传→解密全避坑
据安华招标 2025 年度电子招投标技术白皮书显示,全国公共资源交易平台电子标覆盖率已达98.7%,但因纯技术操作失误导致的废标率仍高达22%。其中环境配置错误、签章失效、解密失败三大问题,占所有技术类废标的85% 以上。很多企业投入数月打磨标…...

Cursor AI破解工具技术深度解析:如何实现设备标识重置与Pro功能永久激活
Cursor AI破解工具技术深度解析:如何实现设备标识重置与Pro功能永久激活 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve…...

联想刃7000k BIOS深度解锁技术实现与性能优化指南
联想刃7000k BIOS深度解锁技术实现与性能优化指南 【免费下载链接】Lenovo-7000k-Unlock-BIOS Lenovo联想刃7000k2021-3060版解锁BIOS隐藏选项并提升为Admin权限 项目地址: https://gitcode.com/gh_mirrors/le/Lenovo-7000k-Unlock-BIOS 联想刃7000k作为一款高性能游戏主…...

AppleJuice与法律边界:如何在教育框架内负责任地使用
AppleJuice与法律边界:如何在教育框架内负责任地使用 【免费下载链接】AppleJuice Apple BLE proximity pairing message spoofing 项目地址: https://gitcode.com/gh_mirrors/ap/AppleJuice AppleJuice作为一款专注于Apple BLE近距离配对消息模拟的开源项目…...