C语言【进阶篇】之结构体 —— 从基础声明到复杂应用的进阶之路
目录
- 🚀前言
- ✍️结构体类型的声明
- 💯结构体定义
- 💯结构的特殊声明
- 🦜结构的自引用
- 💻结构体内存对齐
- 💯对齐规则
- 💯为什么存在内存对齐
- 💯修改默认对齐数
- 🐍结构体传参
- 🐧结构体实现位段
- 🤔什么是位段
- 💯位段的内存分配
- 💯位段的跨平台问题
- 💯位段的应用
- 💯位段使用的注意事项
- 🌟总结
🚀前言
大家好!我是 EnigmaCoder。本文收录于我的专栏 C,感谢您的支持!
- 在C语言编程体系里,结构体是整合不同类型数据的重要工具,它能够将多个相关数据组合为一个有机整体,显著提升数据处理的效率与便捷性。无论是小型代码项目,还是大型复杂系统开发,结构体都占据着关键地位。深入掌握结构体知识,不仅有助于提升编程技能,还能优化代码质量,使其更高效、易维护。接下来,让我们全面且深入地探讨C语言结构体的各个方面,从基础声明到内存对齐、传参方式,再到特殊的位段实现。
✍️结构体类型的声明
💯结构体定义
结构体是不同类型数据的集合体,这些组成数据被称为成员变量,每个成员的类型可以各不相同。定义结构体时,需要明确结构体标签(tag)和成员列表。例如,定义一个描述学生信息的结构体:
// 定义名为Stu的结构体,用于存储学生相关信息
struct Stu {char name[20]; // 用于存储学生姓名,最多可容纳20个字符int age; // 存储学生年龄char sex[5]; // 存储学生性别,最多5个字符char id[20]; // 存储学生学号,最多20个字符
};
在这个结构体中,struct是定义结构体的关键字,Stu作为结构体标签方便后续引用,name、age、sex、id是不同类型的成员变量,分别描述学生的不同属性。
💯结构的特殊声明
匿名结构体在声明时不设置结构体标签,这种结构体若不重命名,通常仅能使用一次。因为编译器会将不同的匿名结构体声明视作不同类型,例如:
// 定义一个匿名结构体,并创建变量x
struct {int a; // 成员a,类型为intchar b; // 成员b,类型为charfloat c; // 成员c,类型为float
}x;// 定义另一个匿名结构体,创建数组a和指针p
struct {int a; // 成员a,类型为intchar b; // 成员b,类型为charfloat c; // 成员c,类型为float
}a[20], *p;
// p = &x; 该行代码非法,编译器将两个匿名结构体视为不同类型
上述代码中,虽然两个匿名结构体成员相同,但由于缺少标签,编译器将它们识别为不同类型,导致p = &x;赋值操作不被允许。
🦜结构的自引用
在结构体内部直接包含同类型结构体变量会导致结构体大小无限递归,这种做法不合理。正确的自引用方式是使用指针。以链表节点结构体定义为例:
// 定义链表节点结构体Node
struct Node {int data; // 存储节点数据struct Node* next; // 指向下一个节点的指针
};
在Node结构体中,next成员是指向struct Node类型的指针,通过它可构建链表结构。若使用typedef对匿名结构体重命名时,要避免在结构体内部提前使用重命名后的类型,如下代码是错误的:
// 错误示例:在匿名结构体内部提前使用未定义的Node类型
typedef struct {int data; // 成员data,类型为intNode* next; // 此处使用Node类型错误,因为Node还未定义
}Node;
正确的做法是:
// 正确定义结构体并使用typedef重命名
typedef struct Node {int data; // 成员data,类型为intstruct Node* next; // 指向下一个节点的指针
}Node;
先定义带标签的结构体,再使用typedef重命名,可避免上述错误。
💻结构体内存对齐
💯对齐规则
- 结构体的第一个成员在内存中的起始地址与结构体变量的起始地址重合,偏移量为
0。 - 后续成员变量需对齐到特定数字(对齐数)的整数倍地址处。对齐数是编译器默认对齐数和该成员变量大小两者中的较小值。在
VS编译器中,默认对齐数为8;而Linux的gcc编译器没有默认对齐数,对齐数就是成员自身大小。 - 结构体的总大小必须是所有成员对齐数中的最大值的
整数倍。 - 当结构体中嵌套其他结构体时,嵌套的结构体成员要对齐到其自身成员最大对齐数的整数倍位置,整个结构体的大小则是所有最大对齐数(包含嵌套结构体中成员的对齐数)的整数倍。
通过以下练习加深理解:
// 练习1:计算结构体S1的大小
struct S1 {char c1; // 第一个成员,占1字节int i; // 第二个成员,在VS中对齐数为4(默认8与4的较小值),需对齐到4的倍数地址char c2; // 第三个成员,对齐数为1,占1字节
};
// 在VS中,S1的大小为8字节(1 + 3(填充)+ 4 + 1)
printf("%d\n", sizeof(struct S1)); // 练习2:计算结构体S2的大小
struct S2 {char c1; // 第一个成员,占1字节char c2; // 第二个成员,对齐数为1,占1字节int i; // 第三个成员,对齐数为4,需对齐到4的倍数地址
};
// 在VS中,S2的大小为8字节(1 + 1 + 2(填充)+ 4)
printf("%d\n", sizeof(struct S2)); // 练习3:计算结构体S3的大小
struct S3 {double d; // 第一个成员,占8字节,对齐数为8char c; // 第二个成员,对齐数为1,占1字节int i; // 第三个成员,对齐数为4,需对齐到4的倍数地址
};
// 在VS中,S3的大小为16字节(8 + 1 + 3(填充)+ 4)
printf("%d\n", sizeof(struct S3)); // 练习4:结构体嵌套问题,计算结构体S4的大小
struct S4 {char c1; // 第一个成员,占1字节struct S3 s3; // 嵌套结构体成员,S3中最大对齐数为8,s3需对齐到8的倍数地址double d; // 第三个成员,对齐数为8
};
// 在VS中,S4的大小为32字节(1 + 7(填充)+ 16 + 8)
printf("%d\n", sizeof(struct S4));
在这些练习中,根据对齐规则分析每个结构体成员的存储位置和填充字节情况,从而准确计算出结构体的大小。
💯为什么存在内存对齐
内存对齐主要基于平台和性能两方面考虑:
- 平台原因:并非所有硬件平台都能访问任意内存地址上的任意数据。部分硬件平台对数据的访问地址有限制,若访问未对齐的数据,可能引发硬件异常。例如,某些硬件要求特定类型数据必须存储在特定地址边界上,否则无法正常读取或写入数据。
- 性能原因:数据结构(尤其是栈)在自然边界上对齐,能提升访问效率。访问未对齐内存时,处理器可能需要进行多次内存访问操作;而对齐的内存访问仅需一次。例如,若处理器每次从内存读取8个字节数据,数据地址必须是8的倍数,才能一次完成读写操作。若数据未对齐,可能需分两次访问不同的8字节内存块,降低了系统性能。
结构体内存对齐本质上是用空间换取时间的策略。在设计结构体时,将占用空间小的成员集中放置,有助于节省内存空间。例如:
// 对比S1和S2结构体,成员相同但顺序不同
struct S1 {char c1; // 占1字节int i; // 对齐数为4,需对齐到4的倍数地址char c2; // 占1字节
};struct S2 {char c1; // 占1字节char c2; // 占1字节int i; // 对齐数为4,需对齐到4的倍数地址
};
// S1在VS中大小为8字节,S2在VS中大小为8字节,但S2布局更节省空间
在这个例子中,S1和S2结构体成员相同,但S2将两个char类型成员放在一起,使int成员对齐时无需额外填充字节,从而在一定程度上节省了内存。
💯修改默认对齐数
使用#pragma pack()预处理指令可改变编译器的默认对齐数。例如,#pragma pack(1)将默认对齐数设为1,之后使用#pragma pack()可取消设置,恢复默认对齐数。示例如下:
#include <stdio.h>
// 将默认对齐数设置为1
#pragma pack(1)
struct S {char c1; // 占1字节int i; // 占4字节char c2; // 占1字节
};
// 取消设置的对齐数,还原为默认
#pragma pack() int main() {// 输出结果为6,因为设置对齐数为1后,不再有填充字节printf("%d\n", sizeof(struct S)); return 0;
}
在上述代码中,通过#pragma pack(1)设置对齐数为1,结构体成员紧密排列,无填充字节,所以struct S的大小为1 + 4 + 1 = 6字节。取消设置后,后续结构体定义将恢复默认对齐规则。
🐍结构体传参
传递结构体对象时,如果结构体规模较大,参数压栈会带来较大的系统开销,进而降低性能。因此,结构体传参时优先选择传递结构体地址。例如:
// 定义结构体S
struct S {int data[1000]; // 包含1000个int类型元素的数组int num; // 一个int类型的成员
};// 定义函数print1,参数为结构体S的对象
void print1(struct S s) {// 输出结构体成员num的值printf("%d\n", s.num);
}// 定义函数print2,参数为结构体S的指针
void print2(struct S* ps) {// 通过指针访问结构体成员num并输出其值printf("%d\n", ps->num);
}int main() {// 初始化结构体S的对象sstruct S s = {{1,2,3,4}, 1000}; // 调用print1函数,传递结构体对象print1(s); // 调用print2函数,传递结构体地址print2(&s); return 0;
}
在这段代码中,print1函数传递结构体对象,函数调用时会将整个结构体内容复制到函数栈帧,对于大型结构体,复制操作耗时耗空间。而print2函数传递结构体地址,仅需将一个指针值压栈,系统开销小,性能更优。
🐧结构体实现位段
🤔什么是位段
位段的声明与结构体类似,但有两个显著区别:一是位段成员类型通常为int、unsigned int、signed int(C99标准支持更多类型);二是成员名后会紧跟一个冒号和一个数字,用于指定该成员占用的二进制位数。例如:
// 定义一个名为A的位段类型
struct A {int _a:2; // 成员_a,占用2位int _b:5; // 成员_b,占用5位int _c:10; // 成员_c,占用10位int _d:30; // 成员_d,占用30位
};
在struct A中,_a、_b、_c、_d是位段成员,冒号后的数字表示它们各自占用的位数,通过这种方式可在有限的内存空间内紧凑存储多个小数据。
💯位段的内存分配
位段成员类型多样,内存空间按4字节(int类型)或1字节(char类型)的方式开辟。不过,位段存在诸多不确定因素,不具备良好的跨平台性。示例如下:
// 定义一个位段结构体S
struct S {char a:3; // 成员a,占用3位char b:4; // 成员b,占用4位char c:5; // 成员c,占用5位char d:4; // 成员d,占用4位
};
// 初始化位段结构体S的对象s
struct S s = {0};
// 给位段成员赋值
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
在上述代码中,struct S是位段结构体,s是其对象。初始化时所有位段成员为0,后续分别赋值。由于位段按位存储,赋值时需注意数值范围不能超出位段允许的最大值。
💯位段的跨平台问题
位段在跨平台使用时存在诸多问题,主要体现在以下方面:
int位段在不同平台上可能被解释为有符号数或无符号数,缺乏一致性,导致程序行为不可预测。- 不同平台支持的位段最大位数不同,
16位机器和32位机器的最大位数限制不同,若代码中指定的位数超出目标平台限制,会引发错误。 - 位段成员在内存中的分配方向(从左向右或从右向左)没有统一标准,不同平台实现方式不同,增加了程序的不确定性。
- 当结构体包含多个位段,且后一个位段成员无法完全容纳在前一个位段剩余空间时,是舍弃剩余位还是利用,不同平台处理方式不同。
鉴于这些跨平台问题,注重可移植性的程序应谨慎使用位段。
💯位段的应用
在网络协议的IP数据报格式中,许多属性仅需几个二进制位就能描述,此时使用位段既能实现功能需求,又能节省内存空间,减少网络传输的数据量,提高网络传输效率。例如:
// 模拟IP数据报部分位段
struct IPHeader {unsigned int version:4; // 4位版本号unsigned int tos:8; // 8位服务类型unsigned int total_length:16; // 16位总长度// 其他位段成员可继续添加
};
在IPHeader结构体中,利用位段定义IP数据报的部分属性,version用4位表示版本号,tos用8位表示服务类型,total_length用16位表示总长度,有效节省内存,方便网络数据处理。
💯位段使用的注意事项
位段的部分成员起始位置可能并非字节的起始位置,这部分位置没有内存地址。由于内存按字节分配地址,字节内部的二进制位没有独立地址,因此不能对位段成员使用取地址操作符&,也就无法使用scanf直接给位段成员输入值。正确做法是先将输入值存储到普通变量中,再赋值给位段成员。例如:
// 定义位段结构体A
struct A {int _a:2; // 成员_a,占用2位int _b:5; // 成员_b,占用5位int _c:10; // 成员_c,占用10位int _d:30; // 成员_d,占用30位
};int main() {// 初始化位段结构体A的对象sastruct A sa = {0}; // scanf("%d", &sa._b); 该行代码错误,不能对位段成员使用&操作符// 正确的示范int b = 0; // 先将输入值存储到变量bscanf("%d", &b); // 再将b的值赋给位段成员_bsa._b = b; return 0;
}
🌟总结
C语言结构体涵盖了丰富的知识,从基础的类型声明、变量初始化,到内存对齐优化、传参方式选择,再到特殊的位段应用,每个环节都有其独特要点和应用场景。在实际编程中,应根据具体需求合理运用这些特性。比如在处理大量数据时,精心设计结构体布局,利用内存对齐提高性能;在频繁调用函数传递结构体时,选择传地址方式减少开销。同时,要充分考虑位段的跨平台问题,在对可移植性要求高的项目中谨慎使用。通过深入理解和灵活运用结构体知识,能编写出更高效、可靠的代码,在C语言编程道路上不断进阶。
相关文章:

C语言【进阶篇】之结构体 —— 从基础声明到复杂应用的进阶之路
目录 🚀前言✍️结构体类型的声明💯结构体定义💯结构的特殊声明 🦜结构的自引用💻结构体内存对齐💯对齐规则💯为什么存在内存对齐💯修改默认对齐数 🐍结构体传参…...

Python-列表和元组
列表 列表是什么, 元组是什么 编程中, 经常需要使用变量, 来保存/表示数据. 如果代码中需要表示的数据个数比较少, 我们直接创建多个变量即可. 但是有的时候, 代码中需要表示的数据特别多, 甚至也不知道要表示多少个数据. 这个时候, 就需要用到列表. 列表是一种让程序猿在代…...

PyTorch 中的混合精度训练方法,从 autocast 到 GradScalar
PyTorch 的混合精度训练主要由两个方法实现:amp.autocast 和 amp.GradScalar。在这两个工具的帮助下,可以实现以 torch.float16 的混合精度训练。当然,这两个方法都是模块化并且通常都会一起调用,但并不一定总是需要一起使用。 参…...

分享能在线运行C语言的网站
https://www.onlinegdb.com/# 我用vscode运行c语言总是报错,后面找到这个网站,可以在线调试和保存代码。 如下图,程序的效果是给变量x,y,z赋值,并打印出来。代码输入以后,右上角选择C语言&…...

AI-Deepseek + PPT
01--Deepseek提问 首先去Deepseek问一个问题: Deepseek的回答: 在汽车CAN总线通信中,DBC文件里的信号处理(如初始值、系数、偏移)主要是为了 将原始二进制数据转换为实际物理值,确保不同电子控制单元&…...

MacOS Big Sur 11 新机安装brew wget python3.12 exo
MacOS Big Sur 11,算是很老的系统了,所以装起来有点费劲。 首先安装brew 按照官网的方法,直接执行下面语句即可安装: export HOMEBREW_BREW_GIT_REMOTE"https://githubfast.com" # put your Git mirror of Homebrew/brew here …...

十大经典排序算法简介
一 概述 本文对十大经典排序算法做简要的总结(按常用分类方式排列),包含核心思想、时间/空间复杂度及特点。 二、比较类排序 1. 冒泡排序 (BUBBLE SORT) 思想:重复交换相邻逆序元素,像气泡上浮 复杂度: 时间:O(n^2)(最好情况O(n)) 空间:O(1) 特点:简单但效率低,稳…...

不小心更改了/etc权限为777导致sudo,ssh等软件都无法使用
修复流程 一、进入恢复模式(无网络或无法登录时必选) 1.重启系统,在 GRUB 启动菜单选择 Recovery Mode(按 Shift 或 Esc 呼出菜单)。2.以 root 身份挂载为可读写: bash 复制 mount -o remount,rw /确保文…...

AI档案审核2
以下是一个结合计算机视觉(CV)和自然语言处理(NLP)的智能档案审核系统完整实现方案,包含可落地的代码框架和技术路线: 一、系统架构设计 #mermaid-svg-UhBtIPrNXo5P89Zb {font-family:"trebuchet ms&q…...

【基础1】冒泡排序
核心思想 冒泡排序是通过相邻元素的连续比较和交换,使得较大的元素逐渐"浮"到数组的末尾,如同水中气泡上浮的过程 特点: 每轮遍历将最大的未排序元素移动到正确位置稳定排序:相等元素的相对位置保持不变原地排序…...

Trae AI 开发工具使用手册
这篇手册将介绍 Trae 的基本功能、安装步骤以及使用方法,帮助开发者快速上手这款工具。 Trae AI 开发工具使用手册 Trae 是字节跳动于 2025 年推出的一款 AI 原生集成开发环境(IDE),旨在通过智能代码生成、上下文理解和自动化任务…...

揭开AI-OPS 的神秘面纱 第二讲-技术架构与选型分析 -- 数据采集层技术架构与组件选型分析
基于上一讲预设的架构图,深入讨论各个组件所涉及的技术架构、原理以及选型策略。我将逐层、逐组件地展开分析,并侧重于使用数据指标进行技术选型的对比。 我们从 数据采集层 开始,进行最细粒度的组件分析和技术选型比对。 数据采集层技术架构…...

基于Docker去创建MySQL的主从架构
基于Docker去创建MySQL的主从架构 用于开发与测试环境读写分离 主从的架构搭建步骤 基于Docker去创建MySQL的主从架构 # 创建主从数据库文件夹 mkdir -p /usr/local/mysql/master1/conf mkdir -p /usr/local/mysql/master1/data mkdir -p /usr/local/mysql/slave1/conf mkd…...
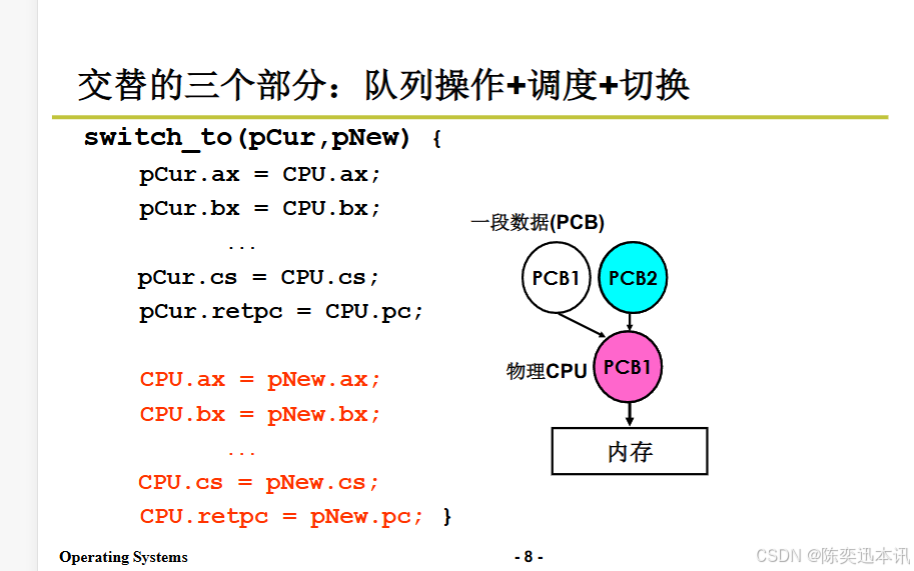
操作系统 2.2-多进程总体实现
多个进程使用CPU的图像 如何使用CPU呢? 通过让程序执行起来来使用CPU。 如何充分利用CPU呢? 通过启动多个程序,交替执行来充分利用CPU。 启动了的程序就是进程,所以是多个进程推进 操作系统需要记录这些进程,并按照…...

Jasypt 与 Spring Boot 集成文档
Jasypt 与 Spring Boot 集成文档 目录 简介版本说明快速开始 添加依赖配置加密密钥加密配置文件 高级配置 自定义加密算法多环境配置 最佳实践常见问题参考资料 简介 Jasypt 是一个简单易用的 Java 加密库,支持与 Spring Boot 无缝集成。通过 Jasypt,…...

在CentOS系统上安装Conda的详细指南
前言 Conda 是一个开源的包管理系统和环境管理系统,广泛应用于数据科学和机器学习领域。本文将详细介绍如何在 CentOS 系统上安装 Conda,帮助您快速搭建开发环境。 准备工作 在开始安装之前,请确保您的 CentOS 系统已经满足以下条件&#x…...
与过滤器(Filter)详细教程)
Spring Boot拦截器(Interceptor)与过滤器(Filter)详细教程
Spring Boot拦截器(Interceptor)与过滤器(Filter)详细教程 目录 概述 什么是拦截器(Interceptor)?什么是过滤器(Filter)?两者的核心区别 使用场景 拦截器的典…...

HTML-05NPM使用踩坑
2025-03-04-NPM使用踩坑 本文讲述了一个苦逼程序员在使用NPM的时候突然来了一记nmp login天雷,然后一番折腾之后,终究还是没有解决npm的问题😞😞😞,最终使用cnpm完美解决的故事。 文章目录 2025-03-04-NPM使用踩坑[toc…...

自学嵌入式第29天-----epoll、sqlite3
1. 正确选择触发模式(ET 和 LT) 水平触发(LT):默认模式,只要文件描述符处于就绪状态,epoll_wait 会持续通知。适合大多数场景,编程简单。 边缘触发(ET)&…...

工作学习笔记:HarmonyOS 核心术语速查表(v14 实战版)
作为在 HarmonyOS 开发一线摸爬滚打的工程师,笔者在 v14 版本迭代中整理了这份带血的实战术语表。 一、架构基础术语速查 A 系列术语 术语官方定义笔者解读(v14 实战版)开发陷阱 & 解决方案abc 文件ArkCompiler 生成的字节码文件打包时…...

腾讯 Marvis 操作系统层 AI 助手内测:多场景显身手,“AI 打工人”雏形初现但仍待打磨
多场景显身手近日,腾讯开始内测一款名为 Marvis(马维斯)的操作系统层个人 AI 助手。这一 AI 助手通过多个 Agent 的协作完成 App 操作、EXE 操作、电脑操作、文件管理、文档生成以及各种复杂任务,24 小时持续在线,并支…...

为什么Delorean是Python时间处理的最佳选择?
为什么Delorean是Python时间处理的最佳选择? 【免费下载链接】delorean Delorean: Time Travel Made Easy 项目地址: https://gitcode.com/gh_mirrors/de/delorean 在Python开发中,时间处理常常是一个令人头疼的问题,尤其是涉及到时区…...

爱普生SG-8201CJ石英可编程振荡器:精准频率控制,高效能工业级应用首选
引言在电子设计中,晶振是不可或缺的元器件,它为整个系统提供精准的时间基准。然而,面对市场上琳琅满目的晶振产品,工程师们常常感到选型困难,特别是在需要高精度、高稳定性和快速交付的情况下。今天,我们就…...

深入解析vsync:基于版本化状态流的高并发同步原语
1. 项目概述:一个被低估的同步利器如果你在开发中经常需要处理跨进程、跨线程的数据同步,或者为状态管理中的竞态条件头疼,那么nicepkg/vsync这个项目很可能就是你一直在寻找的“瑞士军刀”。乍一看这个标题,它像是一个普通的版本…...

科技与科学新闻摘要-2026年5月16日
科技与科学新闻摘要 日期: 2026年5月16日 科技领域重点新闻 1. 中国2025年度十大科学进展揭晓 核心要点: 中国科学技术部发布了2025年度十大科学进展,覆盖深空探测、人工智能、生命科学、能源技术等多个领域,集中展示了中国基础研究和应用研究的突破性…...

2026届学术党必备的AI辅助写作网站实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于学术研究范畴之内,撰写上一篇具备高质量水平的论文,乃是每一位学者…...

Mybatis-Plus条件构造器实战:QueryWrapper与UpdateWrapper的进阶应用与避坑指南
1. 为什么需要条件构造器? 在日常开发中,数据库操作是绕不开的话题。记得我刚入行时,每次写SQL都要手动拼接字符串,不仅容易出错,还经常被SQL注入漏洞困扰。后来接触到MyBatis,虽然解决了安全问题…...

PostgreSQL日期时间格式化终极指南:to_char、to_timestamp、extract epoch实战详解
PostgreSQL日期时间格式化终极指南:to_char、to_timestamp、extract epoch实战详解 在处理数据库时,日期和时间操作几乎是每个开发者都会遇到的挑战。PostgreSQL作为功能强大的开源关系型数据库,提供了丰富的日期时间处理函数,能够…...

Linly中文大模型本地部署指南:从选型到实战优化
1. 项目概述:一个面向中文场景的“小而美”语言模型最近在折腾本地部署大语言模型的朋友,可能都绕不开一个名字:Linly。这个由深圳大学计算机视觉研究所(CVI-SZU)开源的项目,在中文社区里热度一直不低。它不…...

基于CircuitPython与蓝牙BLE的交互式电子糖果心制作指南
1. 项目概述:一个可交互的蓝牙电子糖果心 情人节期间,那些印着“BE MINE”、“HUG ME”等短句的糖果心(Conversation Hearts)总是能传递简单而直接的情感。你有没有想过,如果能亲手制作一个可以随时改变文字和颜色的电…...