20250306-笔记-精读class CVRPEnv:step(self, selected)
文章目录
- 前言
- 一、时间步小于 4
- 1.1 控制时间步的递增
- 1.2 判断是否在配送中心
- 1.3 特定时间步的操作
- 1.4更新
- 1.4.1 更新当前节点和已选择节点列表
- 1.4.2 更新需求和负载
- 1.4.3 更新访问标记
- 1.4.4 更新负无穷掩码
- 1.4.5 更新步骤状态,将更新后的状态同步到 self.step_state
- 二、时间步大于等于 4
- 2.1 动作模式分类 (action classification):
- 2.2 动作索引与选择计数更新:
- 2.3 节点更新:
- 2.4 负载更新:
- 2.5 访问标记更新:
- 2.6 负无穷掩码更新:
- 2.7 完成状态更新:
- 2.8 模式更新与掩码调整:
- 2.9 步骤状态更新:
- 附录
前言
class CVRPEnv:step(self, selected)函数是强化学习代码实现中的核心。
精读该代码的目标:
- 熟悉每一个参数的shape。
- 熟悉每个参数之间的关系(剪切,扩展,等)。
一、时间步小于 4
1.1 控制时间步的递增
# 控制时间步的递增self.time_step=self.time_step+1self.selectex_count = self.selected_count+1
| 参数 | Shape | 含义 |
|---|---|---|
| self.time_step | 标量 | 用来控制时间步数 |
| self.selectex_count | (batch, pomo) | 表示每个批次、每个智能体已选择的节点数量。 |
self.time_step=self.time_step+1
增加 self.time_step 的值,用来控制时间步数。
self.time_step是一个标量(单个整数),表示当前的时间步数。
self.selected_count = self.selected_count + 1
这一行代码的目的是增加 self.selected_count 的值,表示在当前时间步中,智能体已经选择的节点数量增加了。
self.selected_count是一个形状为(batch_size, pomo_size)的张量,表示每个批次、每个智能体已选择的节点数量。
1.2 判断是否在配送中心
#判断是否在配送中心self.at_the_depot = (selected == 0)
| 参数 | Shape | 含义 |
|---|---|---|
| self.at_the_depot | (batch, pomo) | 布尔张量,表示每个智能体是否位于配送中心 |
| selected | (batch, pomo) | 表示每个批次和每个智能体选择的节点编号 |
这行代码的目的是更新 self.at_the_depot 张量,用来表示每个智能体是否位于配送中心(通常是节点 0)。如果智能体选择的节点编号是 0(配送中心节点),则 self.at_the_depot 对应的位置为True,否则为 False。
1.3 特定时间步的操作
if self.time_step==3:self.last_current_node = self.current_node.clone()self.last_load = self.load.clone()if self.time_step == 4:self.last_current_node = self.current_node.clone()self.last_load = self.load.clone()self.visited_ninf_flag[:, :, self.problem_size+1][(~self.at_the_depot)&(self.last_current_node!=0)] = 0
| 参数 | Shape | 含义 |
|---|---|---|
| self.time_step | 标量 | 用来控制时间步数 |
| self.current_node | (batch, pomo) | 示每个批次、每个智能体当前访问的节点。 |
| self.last_current_node | (batch, pomo) | self.current_node.clone() |
| self.load | (batch, pomo) | 表示每个智能体当前的负载状态。 |
| self.last_load | (batch, pomo) | self.load.clone() |
| self.visited_ninf_flag | (batch, pomo, problem + 1) | 记录每个智能体对每个节点的访问标志。 |
| self.at_the_depot | (batch, pomo) | 布尔张量,表示每个智能体是否位于配送中心 |
if self.time_step == 3:
self.last_current_node = self.current_node.clone()
self.last_load = self.load.clone()
在时间步为 3 时,保存当前节点(self.current_node)和负载(self.load)的状态。
self.current_node和self.load在时间步 3 时被保存为self.last_current_node和self.last_load。它们的形状仍然是(batch_size, pomo_size)
if self.time_step == 4:
self.last_current_node = self.current_node.clone()
self.last_load = self.load.clone()
在时间步为 4 时,再次保存当前节点和负载状态,并更新 self.visited_ninf_flag,修改智能体在配送中心以外的访问状态。
self.current_node和self.load在时间步 4 时被保存为self.last_current_node和self.last_load。它们的形状仍然是(batch_size, pomo_size)
self.visited_ninf_flag[:, :, self.problem_size + 1][(~self.at_the_depot) & (self.last_current_node != 0)] = 0
-
self.visited_ninf_flag:这是一个形状为(batch_size, pomo_size, problem_size + 1)的张量,记录每个智能体对每个节点的访问标志。 -
self.visited_ninf_flag[:, :, self.problem_size + 1]:表示对visited_ninf_flag张量的切片操作,选取所有批次、所有智能体,并指定第problem_size + 1个节点的位置。self.problem_size + 1指定的是配送中心。
-
(~self.at_the_depot) & (self.last_current_node != 0):这部分是一个布尔索引,用来筛选符合特定条件的位置。self.at_the_depot是一个布尔张量,表示每个智能体是否在配送中心(True表示在配送中心,False表示不在)。~self.at_the_depot对self.at_the_depot进行布尔取反,表示哪些智能体不在配送中心。self.last_current_node != 0判断哪些智能体在时间步 3 时没有选择配送中心(节点 0)。(~self.at_the_depot) & (self.last_current_node != 0)综合起来表示,选择那些不在配送中心并且在时间步 3 时没有选择配送中心的智能体。
1.4更新
1.4.1 更新当前节点和已选择节点列表
#更新当前节点和已选择节点列表self.current_node = selectedself.selected_node_list = torch.cat((self.selected_node_list, self.current_node[:, :, None]), dim=2)
| 参数 | Shape | 含义 |
|---|---|---|
| self.current_node | (batch, pomo) | |
| self.selected_node_list | (batch, pomo,0~) |
注:0~表示第三维度逐渐增加
self.selected_node_list的shape:

self.current_node的shape:

self.selected_node_list = torch.cat((self.selected_node_list, self.current_node[:, :, None]), dim=2),表示先将self.current_node扩展为三维数据,再将self.current_node沿着self.selected_node_list 的第三维度(dim=2)进行依次剪切进去。
1.4.2 更新需求和负载
#更新需求和负载demand_list = self.depot_node_demand[:, None, :].expand(self.batch_size, self.pomo_size, -1)gathering_index = selected[:, :, None]selected_demand = demand_list.gather(dim=2, index=gathering_index).squeeze(dim=2)self.load -= selected_demandself.load[self.at_the_depot] = 1 # refill loaded at the depot
| 参数 | Shape | 含义g |
|---|---|---|
| self.depot_node_demand | (batch, problem + 1) | 表示每个批次中,每个问题(包括配送中心)对应的节点需求 |
| demand_list | (batch, pomo, problem + 1) | 包含每个节点需求的张量 |
| selected | (batch, pomo) | 表示每个批次中的每个智能体所选择的节点编号(这些节点是从节点集合中选择的) |
| selected_demand | (batch, pomo) | 示每个智能体所选择节点的需求。 |
demand_list = self.depot_node_demand[:, None,:].expand(self.batch_size, self.pomo_size, -1)
[:, None, :]:先在self.depot_node_demand的第二维(即问题维度)上增加一个新的维度,使其变为(batch_size, 1, problem_size + 1)。.expand(self.batch_size, self.pomo_size, -1):将数据self.depot_node_demand扩展为(batch_size, pomo_size, problem_size + 1),表示每个批次中的每个 POMO 智能体都有一份相同的需求数据。

gathering_index = selected[:, :, None]
- 将
selected进行维度扩展

selected_demand = demand_list.gather(dim=2,index=gathering_index).squeeze(dim=2)
demand_list的 shape 是(batch_size, pomo_size, problem_size + 1),包含了所有节点的需求数据。gather(dim=2, index=gathering_index)会按照gathering_index(即selected中存储的节点编号)从demand_list中选择出对应的节点需求。dim=2表示沿着第三维(即问题维度)进行选择。gather的结果是一个 shape 为(batch_size, pomo_size, 1)的张量。.squeeze(dim=2)去掉了多余的第三维,最终得到selected_demand,其 shape 是(batch_size, pomo_size),表示每个智能体所选择节点的需求。

1.4.3 更新访问标记
#更新访问标记(防止重复选择已访问的节点)self.visited_ninf_flag[self.BATCH_IDX, self.POMO_IDX, selected] = float('-inf')self.visited_ninf_flag[:, :, 0][~self.at_the_depot] = 0 # depot is considered unvisited, unless you are AT the depot
| 参数 | Shape | 含义 |
|---|---|---|
| self.visited_ninf_flag | (batch, pomo, problem+ 1) | 记录了每 个智能体(POMO)在每个批次中已访问的节点的信息,标记某些节点是否已经被访问(用负无穷表示)。 |
| self.BATCH_IDX | (batch, pomo) | 批次索引的张量 |
| self.POMO_IDX | (batch, pomo) | 智能体(POMO)索引的张量 |
| selected | (batch, pomo) | 表示每个批次中的每个智能体所选择的节点编号(这些节点是从节点集合中选择的) |
| self.at_the_depot | (batch, pomo) | 一个布尔型张量,表示每个智能体是否处于配送中心(即该智能体是否在节点 0,通常是配送中心)。 |

self.visited_ninf_flag[self.BATCH_IDX, self.POMO_IDX, selected] =float(‘-inf’)
self.visited_ninf_flag[self.BATCH_IDX, self.POMO_IDX, selected] 表示从 visited_ninf_flag 张量中选择出对应批次和智能体的对应位置,并设置为 float('-inf'),表示这些节点已经被访问过。
举例:
假设我们有以下参数:
- batch_size = 2,即有 2 个批次。
- pomo_size = 3,即每个批次有 3 个智能体(POMO)。
- problem_size = 4,即有 4 个节点(包含配送中心)。
self.visited_ninf_flag = [[[ 0., 0., 0., 0., 0.], # 第一个批次(batch 0)[ 0., 0., 0., 0., 0.], # POMO 0, POMO 1, POMO 2 各自对节点的访问标志[ 0., 0., 0., 0., 0.]],[[ 0., 0., 0., 0., 0.], # 第二个批次(batch 1)[ 0., 0., 0., 0., 0.],[ 0., 0., 0., 0., 0.]]
]
self.BATCH_IDX(批次索引):
self.BATCH_IDX = [[0, 0, 0], # 第一个批次[1, 1, 1] # 第二个批次
]
self.POMO_IDX(POMO 索引):
self.POMO_IDX = [[0, 1, 2], # 每个批次中三个智能体的索引[0, 1, 2]
]
selected(每个智能体选择的节点):
selected = [[1, 2, 0], # 第一个批次中,智能体选择的节点:POMO 0 选择节点 1,POMO 1 选择节点 2,POMO 2 选择节点 0[3, 1, 2] # 第二个批次中,智能体选择的节点:POMO 0 选择节点 3,POMO 1 选择节点 1,POMO 2 选择节点 2
]
执行这一行代码 self.visited_ninf_flag[self.BATCH_IDX, self.POMO_IDX, selected] = float('-inf')。
对于第一个批次(BATCH_IDX[0]),我们有三个智能体(POMO_IDX[0]),选择了节点 [1, 2, 0],分别是:
selected[0][0] = 1表示 POMO 0 选择了节点 1。selected[0][1] = 2表示 POMO 1 选择了节点 2。selected[0][2] = 0表示 POMO 2 选择了节点 0。
对于第二个批次(BATCH_IDX[1]),我们同样有三个智能体(POMO_IDX[1]),选择了节点[3, 1, 2],分别是:selected[1][0] = 3表示 POMO 0 选择了节点 3。selected[1][1] = 1表示 POMO 1 选择了节点 1。selected[1][2] = 2表示 POMO 2 选择了节点 2。
更新 visited_ninf_flag: 根据批次索引和 POMO 索引,我们更新了对应位置的值为负无穷 -inf:
- 对于
BATCH_IDX[0]和POMO_IDX[0, 1, 2],我们将selected[0][0] = 1,selected[0][1] = 2,selected[0][2] = 0位置标记为-inf。 - 对于
BATCH_IDX[1]和POMO_IDX[0, 1, 2],我们将selected[1][0] = 3,selected[1][1] = 1,selected[1][2] = 2位置标记为-inf。
self.visited_ninf_flag[:, :, 0][~self.at_the_depot] = 0
self.visited_ninf_flag[:, :, 0][~self.at_the_depot] = 0,我们将所有不在配送中心的智能体的配送中心访问标志设置为 0。
-[:, :, 0] 是一个切片操作,表示我们提取张量中的第一个节点(通常是配送中心节点)。
~self.at_the_depot是对self.at_the_depot张量的布尔取反操作,将True变为False,将False变为True。
1.4.4 更新负无穷掩码
#更新负无穷掩码(屏蔽需求量超过当前负载的节点)self.ninf_mask = self.visited_ninf_flag.clone()round_error_epsilon = 0.00001demand_too_large = self.load[:, :, None] + round_error_epsilon < demand_list_2=torch.full((demand_too_large.shape[0],demand_too_large.shape[1],1),False)demand_too_large = torch.cat((demand_too_large, _2), dim=2)self.ninf_mask[demand_too_large] = float('-inf')
| 参数 | Shape | 含义 |
|---|---|---|
| self.visited_ninf_flag | (batch, pomo, problem+ 1) | 记录了每 个智能体(POMO)在每个批次中已访问的节点的信息,标记某些节点是否已经被访问(用负无穷表示)。 |
| self.ninf_mask | (batch, pomo, problem+ 1) | self.visited_ninf_flag.clone() |
| demand_too_large | (batch, pomo, problem + 1) | 每个智能体负载与节点需求的比较结果 |
| _2 | (batch, pomo, 1) | 张量 _2 用于扩展 demand_too_large 张量的形状。 |
self.ninf_mask = self.visited_ninf_flag.clone()
复制 visited_ninf_flag 张量的内容,初始化 ninf_mask。self.visited_ninf_flag 是一个形状为 (batch_size, pomo_size, problem_size + 1) 的张量,记录了每个智能体对每个节点的访问状态。
round_error_epsilon = 0.00001
demand_too_large = self.load[:, :, None]+ round_error_epsilon < demand_list
定义一个小的数值误差 round_error_epsilon,用来避免浮点数运算时的小数误差。
检查每个智能体的负载是否小于当前节点的需求量。
self.load[:, :, None]的形状为(batch_size, pomo_size, 1),是每个批次中每个智能体的负载。通过[:, :, None]进行扩展,将其转换为三维张量,第三维用于后续与demand_list对比。demand_list是一个形状为(batch_size, pomo_size, problem_size + 1)的张量,表示每个智能体选择的节点的需求量。round_error_epsilon是用于避免计算中的浮动误差。demand_too_large是一个布尔张量,形状为(batch_size, pomo_size, problem_size + 1),其值为True表示该节点的需求量大于当前负载(包括误差修正),为False表示需求量不大于负载。
注:demand_too_large的形状继承于demand_list

_2=torch.full((demand_too_large.shape[0],demand_too_large.shape[1],1),False)
demand_too_large = torch.cat((demand_too_large, _2), dim=2)
创建一个形状为 (batch_size, pomo_size, 1) 的张量 _2,其值为 False。
torch.full()创建一个所有元素都为False的张量,形状为(batch_size, pomo_size, 1),确保将其连接到demand_too_large上时,可以对其进行扩展。
将 _2 连接到 demand_too_large 张量的最后一维。
demand_too_large的形状为(batch_size, pomo_size, problem_size + 1),表示每个智能体负载与节点需求的比较结果。_2的形状为(batch_size, pomo_size, 1),用于将布尔值False填充到demand_too_large的最后一维。- 通过
torch.cat()将_2拼接到demand_too_large后面,得到新的形状(batch_size, pomo_size, problem_size + 2),扩展了一个额外的维度。

self.ninf_mask[demand_too_large] = float(‘-inf’)
将 demand_too_large 为 True 的位置,更新 ninf_mask 为负无穷 -inf,表示这些节点的需求量超过当前负载。
1.4.5 更新步骤状态,将更新后的状态同步到 self.step_state
#更新步骤状态,将更新后的状态同步到 self.step_stateself.step_state.selected_count = self.time_stepself.step_state.load = self.loadself.step_state.current_node = self.current_nodeself.step_state.ninf_mask = self.ninf_mask
| 参数 | Shape | 含义 |
|---|---|---|
| self.time_step | 一个整数 | 时间步数 |
| self.load | (batch, pomo) | 每个批次所有POMO智能体的负载 |
| self.current_node | (batch, pomo) | 每个批次所有POMO智能体选择的节点 |
| self.ninf_mask | (batch, pomo, problem+ 1) | 记录了每 个智能体(POMO)在每个批次中已访问的节点的信息,标记某些节点是否已经被访问(用负无穷表示)。 |
二、时间步大于等于 4
2.1 动作模式分类 (action classification):
# 动作模式分类
action0_bool_index = ((self.mode == 0) & (selected != self.problem_size + 1))
action1_bool_index = ((self.mode == 0) & (selected == self.problem_size + 1)) # regret
action2_bool_index = self.mode == 1
action3_bool_index = self.mode == 2
| 参数 | Shape | 含义 |
|---|---|---|
| self.mode | (batch_size, pomo_size) | 表示每个批次中每个智能体的当前状态模式(mode)。 |
| selected | (batch_size, pomo_size) | 表示每个批次中每个智能体选择的节点编号。 |
| action0_bool_index | (batch_size, pomo_size) | 表示哪些智能体当前处于模式 0 且选择的节点不是 self.problem_size + 1。 |
| action1_bool_index | (batch_size, pomo_size) | 表示哪些智能体当前处于模式 0 且选择了 self.problem_size + 1(即“后悔”模式)。 |
| action2_bool_index | (batch_size, pomo_size) | 表示哪些智能体当前处于模式 1。 |
| action3_bool_index | (batch_size, pomo_size) | 表示哪些智能体当前处于模式 2。 |
action0_bool_index = ((self.mode == 0) & (selected != self.problem_size + 1))
selected是一个形状为(batch_size, pomo_size)的张量,表示每个批次中每个智能体选择的节点编号。selected != self.problem_size + 1会生成一个布尔张量,表示哪些智能体没有选择self.problem_size + 1这个特殊的节点(假设self.problem_size + 1是表示一个特定的节点,如“后悔”节点)。
2.2 动作索引与选择计数更新:
action1_index = torch.nonzero(action1_bool_index)
action2_index = torch.nonzero(action2_bool_index)action4_index = torch.nonzero((action3_bool_index & (self.current_node != 0)))# 更新选择计数
self.selected_count = self.selected_count + 1
# 后悔模式
self.selected_count[action1_bool_index] = self.selected_count[action1_bool_index] - 2
| 参数 | Shape | 含义 |
|---|---|---|
| action1_bool_index | (N, 2),其中 N 是符合条件的元素个数,2 表示 [batch_idx, pomo_idx] 两个维度 | 所有满足“后悔模式”条件的智能体的批次和智能体索引 |
| action1_bool_index | (batch_size, pomo_size) | 表示每个批次、每个智能体是否符合 action1 条件 |
| action2_index | (N, 2),其中 N 是符合条件的元素个数,2 表示 [batch_idx, pomo_idx] 两个维度 | 所有处于模式 1 的智能体的批次和智能体索引 |
| action2_bool_index | (batch_size, pomo_size) | 表示每个批次、每个智能体是否符合 action2 条件 |
| action4_index | (N, 2),其中 N 是符合条件的元素个数,2 表示 [batch_idx, pomo_idx] 两个维度 | 所有处于模式 2 且当前节点不为配送中心的智能体的批次和智能体索引 |
| action3_bool_index | (batch_size, pomo_size) | 表示每个批次、每个智能体是否符合 action3 条件 |
| self.selected_count | (batch_size, pomo_size) | 表示每个批次、每个智能体选择的节点数量。 |
action1_index = torch.nonzero(action1_bool_index)
这行代码通过 torch.nonzero 获取所有满足 action1_bool_index 条件的位置索引,表示那些处于模式 0 且选择了 self.problem_size + 1(可能是“后悔模式”)的智能体。
torch.nonzero(action1_bool_index)会返回一个张量,包含所有为True的位置的索引。返回的索引张量的形状为(N, 2),其中N是True的数量,第一列是批次索引,第二列是智能体索引。
action4_index = torch.nonzero((action3_bool_index & (self.current_node != 0)))
action3_bool_index是一个布尔张量,形状为(batch_size, pomo_size),表示每个批次、每个智能体是否符合action3条件(即处于模式 2)。self.current_node != 0生成一个布尔张量,表示当前选择的节点不为配送中心(节点编号 0)。
self.selected_count[action1_bool_index] = self.selected_count[action1_bool_index] - 2
这行代码针对处于后悔模式(action1_bool_index)的智能体,将它们的选择计数减去 2。
action1_bool_index是一个形状为(batch_size, pomo_size)的布尔张量,表示哪些智能体处于后悔模式。self.selected_count[action1_bool_index]会提取所有处于后悔模式的智能体的选择计数。- 将这些智能体的选择计数减去 2,表示它们在当前步骤的选择无效,可能需要补偿或调整。
2.3 节点更新:
# 节点更新
self.last_is_depot = (self.last_current_node == 0)_ = self.last_current_node[action1_index[:, 0], action1_index[:, 1]].clone()
temp_last_current_node_action2 = self.last_current_node[action2_index[:, 0], action2_index[:, 1]].clone()
self.last_current_node = self.current_node.clone()
self.current_node = selected.clone()
self.current_node[action1_index[:, 0], action1_index[:, 1]] = _.clone()# 更新已选择节点列表
self.selected_node_list = torch.cat((self.selected_node_list, selected[:, :, None]), dim=2)
| 参数 | Shape | 含义 |
|---|---|---|
| self.last_current_node | (batch_size, pomo_size) | 表示每个批次中每个智能体在上一个时间步选择的节点。 |
| self.last_is_depot | (batch_size, pomo_size) | 表示每个智能体是否选择了节点 0(配送中心)。 |
| action1_index | (N, 2) | 表示处于“后悔模式”(mode == 0 且选择了特殊节点 self.problem_size + 1)的智能体的索引。 |
| _ | (N,),其中 N 是处于“后悔模式”下的智能体数量 | 每个位置的值是上一个时间步智能体选择的节点编号。 |
| temp_last_current_node_action2 | (N,),其中 N 是处于模式 1 下的智能体数量 | 每个位置的值是上一个时间步智能体选择的节点编号。 |
| selected | (batch_size, pomo_size) | 表示当前时间步每个智能体选择的节点。 |
| self.current_node | (batch_size, pomo_size) | 表示当前时间步每个智能体选择的节点。 |
| self.selected_node_list | (batch_size, pomo_size, num_selected_nodes) | 表示每个批次中每个智能体已经选择的节点列表。 |
_ = self.last_current_node[action1_index[:, 0], action1_index[:, 1]].clone()
self.last_current_node[action1_index[:, 0], action1_index[:, 1]]提取了那些处于“后悔模式”下的智能体在上一个时间步选择的节点。_的形状是(N,),其中N是处于“后悔模式”下的智能体数量。每个位置的值是上一个时间步智能体选择的节点编号。

temp_last_current_node_action2 = self.last_current_node[action2_index[:, 0], action2_index[:, 1]].clone()
self.last_current_node[action2_index[:, 0], action2_index[:, 1]]提取了那些处于模式 1 下的智能体在上一个时间步选择的节点。
self.current_node = selected.clone()
self.current_node[action1_index[:, 0], action1_index[:, 1]] = _.clone()
self.current_node[action1_index[:, 0], action1_index[:, 1]]获取这些智能体在当前时间步的节点位置。_.clone()将之前保存的智能体在上一个时间步选择的节点(即_)赋值给这些智能体在当前时间步的节点。
self.selected_node_list = torch.cat((self.selected_node_list, selected[:, :, None]), dim=2)
- 更新
self.selected_node_list,将当前时间步的节点选择添加到已选择的节点列表中。 torch.cat((self.selected_node_list, selected[:, :, None]), dim=2)将当前时间步选择的节点添加到self.selected_node_list中,使得selected_node_list更新为包含当前时间步节点的列表。
2.4 负载更新:
# 更新负载
self.at_the_depot = (selected == 0)
demand_list = self.depot_node_demand[:, None, :].expand(self.batch_size, self.pomo_size, -1)
_3 = torch.full((demand_list.shape[0], demand_list.shape[1], 1), 0)
demand_list = torch.cat((demand_list, _3), dim=2)
gathering_index = selected[:, :, None]
selected_demand = demand_list.gather(dim=2, index=gathering_index).squeeze(dim=2)
_1 = self.last_load[action1_index[:, 0], action1_index[:, 1]].clone()
self.last_load = self.load.clone()
self.load -= selected_demand
self.load[action1_index[:, 0], action1_index[:, 1]] = _1.clone()
self.load[self.at_the_depot] = 1 # refill loaded at the depot
| 参数 | Shape | 含义 |
|---|---|---|
| self.at_the_depot | (batch, pomo) | 标记每个智能体是否在配送中心。 |
| depot_node_demand | (batch, problem + 1) | 表示每个节点的需求,包括配送中心。 |
| demand_list | (batch, pomo_size, problem+1) | 每个智能体所对应的所有节点的需求。 |
| selected | (batch, pomo) | 表示当前批次和 POMO(多智能体)中选择的节点。 |
| _3 | (batch, pomo_size, 1) | 一个临时张量,用于后续扩展 demand_list。 |
| gathering_index | (batch, pomo_size, 1) | 用于指定要从 demand_list 中收集哪些需求。 |
| selected_demand | (batch, pomo_size) | 表示每个智能体选择的节点的需求。 |
| action1_index | (N, 2) | 表示处于“后悔模式”(mode == 0 且选择了特殊节点 self.problem_size + 1)的智能体的索引。 |
| self.load | (batch, pomo_size) | 表示每个智能体的负载。 |
self.at_the_depot = (selected == 0)
该行代码根据 selected 来判断是否选择了配送中心。
- 如果选择的节点是配送中心(节点编号为 0),则
self.at_the_depot为True,否则为False。
demand_list = self.depot_node_demand[:, None, :].expand(self.batch_size, self.pomo_size, -1)
这行代码扩展了 self.depot_node_demand,使其能够适应批量和多个智能体的需求。
self.depot_node_demand[:, None, :]将self.depot_node_demand的维度从(batch, problem+1)扩展到(batch, 1, problem+1),在第二维上添加一个新维度。.expand(self.batch_size, self.pomo_size, -1)将该 tensor 扩展到(batch, pomo_size, problem+1),复制需求数据,使每个智能体都能访问这些数据。
_3 = torch.full((demand_list.shape[0], demand_list.shape[1], 1), 0)
创建一个全为 0 的张量 _3,它的形状与 demand_list 相同,但在最后一维有一个额外的维度。
demand_list = torch.cat((demand_list, _3), dim=2)
这行代码将 _3 张量连接到 demand_list 的最后一维(dim=2)。
demand_list的原始形状是(batch, pomo_size, problem+1),它表示每个智能体的需求。_3的形状是(batch, pomo_size, 1),它会被附加到demand_list的最后一维,使其形状变为(batch, pomo_size, problem+2)。
gathering_index = selected[:, :, None]
gathering_index 用于指定要从 demand_list 中收集哪些需求。
selected的形状为(batch, pomo_size),表示每个智能体选择的节点。[:, :, None]会将selected的形状从(batch, pomo_size)转换为(batch, pomo_size, 1),增加一个新的维度,使其可以用作gather的索引。
selected_demand = demand_list.gather(dim=2, index=gathering_index).squeeze(dim=2)
该行代码根据 gathering_index 从 demand_list 中提取所选节点的需求,并移除不必要的维度。
demand_list.gather(dim=2, index=gathering_index)会根据gathering_index提取每个智能体选择节点的需求。dim=2表示从最后一维(需求)中选取。.squeeze(dim=2)去除 gather 后产生的单一维度,使selected_demand的形状从(batch, pomo_size, 1)转变为(batch, pomo_size)。

_1 = self.last_load[action1_index[:, 0], action1_index[:, 1]].clone()
self.last_load = self.load.clone()
self.load -= selected_demand
- 该段代码先将
_1更新为之前的self.last_load,在此之后self.last_load已更新为当前的self.load- 将
self.last_load中,指定位置的负载克隆到_1。action1_index是一个包含批次和 POMO 索引的 tensor。self.last_load是一个形状为(batch, pomo_size)的 tensor,表示每个智能体的负载。action1_index提供了批次和智能体的索引,所以通过这些索引来获取self.last_load中的值。
- 将当前负载
self.load的值克隆到self.last_load中,以便后续使用。 - 根据
selected_demand更新负载。selected_demand是每个智能体选择的节点需求,形状为(batch, pomo_size)。
- 将
self.load[action1_index[:, 0], action1_index[:, 1]] = _1.clone()
这行代码将 action1_index 索引位置的负载值恢复为 _1(即之前的负载值)。
action1_index是一个 tensor,表示在某些情况下需要恢复负载的智能体的索引。- 通过该索引,将
self.load中的负载恢复为之前保存的_1。
self.load[self.at_the_depot] = 1
这行代码将位于配送中心的智能体的负载设置为 1,表示它们已被重新加载。
self.at_the_depot是一个形状为(batch, pomo_size)的布尔值 tensor,表示哪些智能体在配送中心。self.load[self.at_the_depot] = 1将这些智能体的负载恢复为1,表示它们重新装载。
2.5 访问标记更新:
# 更新访问标记
self.visited_ninf_flag[:, :, self.problem_size + 1][self.last_is_depot] = 0
self.visited_ninf_flag[self.BATCH_IDX, self.POMO_IDX, selected] = float('-inf')
self.visited_ninf_flag[action2_index[:, 0], action2_index[:, 1], temp_last_current_node_action2] = float(0)
self.visited_ninf_flag[action4_index[:, 0], action4_index[:, 1], self.problem_size + 1] = float(0)
self.visited_ninf_flag[:, :, self.problem_size + 1][self.at_the_depot] = float('-inf')
self.visited_ninf_flag[:, :, 0][~self.at_the_depot] = 0
| 参数 | Shape | 含义 |
|---|---|---|
| self.visited_ninf_flag | (batch, pomo_size, problem+2) | 用于存储每个节点的访问状态。 |
| self.last_is_depot | (batch, pomo_size) | 表示上一步的节点是否是配送中心(True 表示在配送中心,False 表示不在)。 |
| self.BATCH_IDX | (batch, pomo_size) | 批次的索引。 |
| self.POMO_IDX | (batch, pomo_size) | POMO智能体的索引。 |
| selected | (batch, pomo_size) | 表示当前每个智能体选择的节点编号。 |
| action2_index | (N, 2) | 其中 N 是符合 mode=1 条件的智能体数量,每一行 (batch_idx, pomo_idx) 指定了具体的智能体索引。 |
| temp_last_current_node_action2 | (N,) | 表示 action2_index 对应的智能体在上一步访问的节点编号。 |
| action4_index | (M, 2) | 其中 M 是满足 mode=2(表示特定的选择模式)并且 current_node ≠ 0 的智能体数量,每一行 (batch_idx, pomo_idx) 指定了具体的智能体索引。 |
| self.at_the_depot | (batch, pomo_size) | 表示哪些智能体位于配送中心。 |
self.visited_ninf_flag[:, :, self.problem_size + 1][self.last_is_depot] = 0
- 将
self.visited_ninf_flag的 倒数第二个索引self.problem_size + 1位置的值设为0,但仅限于上一步在配送中心的智能体(self.last_is_depot)。 self.problem_size + 1这个索引通常用于表示一个特殊状态(例如 “后悔” 或 “未选择” 状态)。
self.visited_ninf_flag[self.BATCH_IDX, self.POMO_IDX, selected] = float(‘-inf’)
将 当前选择的节点 的访问标记设为 -inf,表示这些节点已经被访问,防止它们被重复选择。
self.visited_ninf_flag[action2_index[:, 0], action2_index[:, 1], temp_last_current_node_action2] = float(0)
恢复某些节点的访问权限,即:对于 mode=1(表示后悔操作)的智能体,重新允许访问它们上次的节点。
action2_index的形状是(N, 2),其中N是符合mode=1条件的智能体数量,每一行(batch_idx, pomo_idx)指定了具体的智能体索引。temp_last_current_node_action2的形状是(N,),表示action2_index对应的智能体在上一步访问的节点编号。self.visited_ninf_flag的形状是(batch, pomo_size, problem+2)。
self.visited_ninf_flag[action4_index[:, 0], action4_index[:, 1], self.problem_size + 1] = float(0)
针对 action3_bool_index & (self.current_node != 0) 的情况,重新启用 self.problem_size + 1 位置的访问权限。
action4_index的形状是(M, 2),其中M是满足mode=2(表示特定的选择模式)并且current_node ≠ 0的智能体数量,每一行(batch_idx, pomo_idx)指定了具体的智能体索引。
self.visited_ninf_flag[:, :, self.problem_size + 1][self.at_the_depot] = float(‘-inf’)
在配送中心的智能体,不允许选择 problem_size + 1 这个特殊状态。
self.visited_ninf_flag[:, :, self.problem_size + 1]选取visited_ninf_flag的problem_size + 1位置,得到形状(batch, pomo_size)。[self.at_the_depot]选择所有位于配送中心的智能体,并把它们的problem_size+1位置设置为-inf,防止它们选择这个状态。
self.visited_ninf_flag[:, :, 0][~self.at_the_depot] = 0
如果不在配送中心,则允许访问配送中心(节点 0)。
self.visited_ninf_flag[:, :, 0]选取visited_ninf_flag的第 0 个索引(即配送中心的访问状态),形状为(batch, pomo_size)。[~self.at_the_depot]选取所有不在配送中心的智能体,并将它们的visited_ninf_flag设为0,允许它们重新访问配送中心。
2.6 负无穷掩码更新:
# 更新负无穷掩码
self.ninf_mask = self.visited_ninf_flag.clone()
round_error_epsilon = 0.00001
demand_too_large = self.load[:, :, None] + round_error_epsilon < demand_list
self.ninf_mask[demand_too_large] = float('-inf')
| 参数 | Shape | 含义 |
|---|---|---|
| self.ninf_mask | (batch, pomo_size, problem+2) | visited_ninf_flag 包含已访问节点的屏蔽信息和需求超过当前负载的节点的屏蔽信息。 |
| self.visited_ninf_flag | (batch, pomo_size, problem+2) | 存储每个智能体对每个节点的访问状态。 |
| demand_too_large | (batch, pomo_size, problem+2) | 标记哪些节点的需求大于当前负载。 |
| demand_list | (batch, pomo_size, problem+2) | 表示每个智能体对每个节点的需求。 |
| self.load | (batch, pomo_size) | 表示当前每个智能体的负载。 |
self.ninf_mask = self.visited_ninf_flag.clone()
self.visited_ninf_flag的形状是(batch, pomo_size, problem+2),用于存储每个智能体对每个节点的访问状态。
round_error_epsilon = 0.00001
demand_too_large = self.load[:, :, None] + round_error_epsilon < demand_list
- 定义一个极小的正数
round_error_epsilon,用于浮点数计算中的舍入误差处理。避免 load 与 demand_list 直接比较时因为精度问题导致错误。 - 计算一个布尔掩码
demand_too_large,标记哪些节点的需求大于当前负载,这些节点应该被屏蔽。self.load[:, :, None]通过 None扩展维度,这样就可以与demand_list进行逐元素比较。demand_list.shape == (batch, pomo_size, problem+2),表示每个智能体对每个节点的需求。- 生成
demand_too_large,形状为(batch, pomo_size, problem+2):True表示该节点的需求大于当前负载(不能被选择)。False表示该节点的需求在当前负载允许范围内。
self.ninf_mask[demand_too_large] = float(‘-inf’)
屏蔽负载不足的节点,确保它们不会被智能体选择。
self.ninf_mask[demand_too_large] = float('-inf')- 找到
demand_too_large为True的位置(即负载不足的节点)。 - 在
self.ninf_mask中,将这些位置的值设为-inf,防止它们被选中。
- 找到
2.7 完成状态更新:
# 更新完成状态
newly_finished = (self.visited_ninf_flag == float('-inf'))[:,:,:self.problem_size+1].all(dim=2)
self.finished = self.finished + newly_finished
| 参数 | Shape | 含义 |
|---|---|---|
| newly_finished | (batch, pomo_size) | 标记哪些智能体已经访问了所有节点,即它们的路径已经完成。 |
| self.visited_ninf_flag | (batch, pomo_size, problem+2) | 记录每个智能体对各个节点的访问状态 (-inf 代表已访问) |
| self.finished | (batch, pomo_size) | 表示智能体是否完成任务 |
newly_finished = (self.visited_ninf_flag == float(‘-inf’))[:,:,:self.problem_size+1].all(dim=2)
计算一个布尔掩码 newly_finished,标记哪些智能体已经访问了所有节点,即它们的路径已经完成。
newly_finished形状为(batch, pomo_size),其中:True表示该智能体已经访问了所有任务点,旅行完成。
-False表示该智能体仍有未访问的节点。
逻辑
self.visited_ninf_flag == float('-inf')- 生成一个布尔张量,表示每个节点是否已访问:
True(已访问)False(未访问)
- 生成一个布尔张量,表示每个节点是否已访问:
[:, :, :self.problem_size+1]- 仅保留任务节点部分,不包括
problem+2的特殊状态。 - 形状变为
(batch, pomo_size, problem+1)。
- 仅保留任务节点部分,不包括
.all(dim=2)- 在
dim=2(节点维度)上执行 all():- 若智能体已访问所有
problem+1个节点,则返回True。 - 若有未访问的节点,则返回
False。
- 若智能体已访问所有
- 形状变为
(batch, pomo_size),每个智能体对应一个布尔值。
- 在
self.finished = self.finished + newly_finished
更新 self.finished,标记哪些智能体已经完成任务。
2.8 模式更新与掩码调整:
# 更新模式
self.mode[action1_bool_index] = 1
self.mode[action2_bool_index] = 2
self.mode[action3_bool_index] = 0
self.mode[self.finished] = 4# 更新完成后的掩码调整
self.ninf_mask[:, :, 0][self.finished] = 0
self.ninf_mask[:, :, self.problem_size + 1][self.finished] = float('-inf')
| 参数 | Shape | 含义 |
|---|---|---|
| self.mode | (batch, pomo_size) | 智能体的行为模式 |
| action1_bool_index | (batch, pomo_size) | 选中的智能体执行模式 1 |
| action2_bool_index | (batch, pomo_size) | 选中的智能体执行模式 2 |
| action3_bool_index | (batch, pomo_size) | 选中的智能体执行模式 0 |
| self.finished | (batch, pomo_size) | 选中的智能体进入模式 4 |
| self.ninf_mask | (batch, pomo_size, problem+2) | 用于屏蔽不可选择的节点 |
self.mode[action1_bool_index] = 1
self.mode[action2_bool_index] = 2
self.mode[action3_bool_index] = 0
self.mode[self.finished] = 4
- 更新
self.mode,决定智能体在下一步的行为模式。 self.mode形状为(batch, pomo_size),每个智能体都有自己的模式。- 模式的作用:
0:正常选择下一步节点1:执行“后悔”操作(回溯上一步)2:某种特殊选择状态(如重新选择)4:表示智能体已完成任务,不再进行选择
self.ninf_mask[:, :, 0][self.finished] = 0
self.ninf_mask[:, :, self.problem_size + 1][self.finished] = float(‘-inf’)
- 调整
self.ninf_mask,确保已完成任务的智能体不会继续选择新节点。 self.ninf_mask用于屏蔽不可选择的节点,形状为(batch, pomo_size, problem+2):-inf:表示该节点不能被选择。0:表示该节点可以被选择。
逻辑
self.ninf_mask[:, :, 0][self.finished] = 0- 允许已完成的智能体访问配送中心(节点 0)。
self.finished为True的智能体,其ninf_mask对应的 0 号索引会被设为0,表示它们可以回到配送中心。
self.ninf_mask[:, :, self.problem_size + 1][self.finished] = float('-inf')- 禁止已完成的智能体选择
problem_size+1(特殊状态)。 self.finished为True的智能体,其ninf_mask对应的problem_size+1号索引会被设为-inf,表示它们不能选择该状态。
- 禁止已完成的智能体选择
2.9 步骤状态更新:
# 更新步骤状态
self.step_state.selected_count = self.time_step
self.step_state.load = self.load
self.step_state.current_node = self.current_node
self.step_state.ninf_mask = self.ninf_mask
| 参数 | Shape | 含义 |
|---|---|---|
| self.time_step | 标量(int) | 记录当前时间步(迭代次数) |
| self.step_state.selected_count | 标量(int) | 记录当前的时间步数 |
| self.load | (batch, pomo_size) | 当前智能体的负载 |
| self.step_state.load | (batch, pomo_size) | 存储当前负载状态 |
| self.current_node | (batch, pomo_size) | 记录当前每个智能体所处的节点 |
| self.step_state.current_node | (batch, pomo_size) | 存储当前智能体的位置信息 |
| self.ninf_mask | (batch, pomo_size, problem+2) | 记录哪些节点不能被选择 |
| self.step_state.ninf_mask | (batch, pomo_size, problem+2) | 存储当前的掩码信息 |
附录
代码:
def step(self, selected):# selected.shape: (batch, pomo)#时间步数控制if self.time_step<4:# 控制时间步的递增self.time_step=self.time_step+1self.selectex_count = self.selected_count+1#判断是否在配送中心self.at_the_depot = (selected == 0)#特定时间步的操作if self.time_step==3:self.last_current_node = self.current_node.clone()self.last_load = self.load.clone()if self.time_step == 4:self.last_current_node = self.current_node.clone()self.last_load = self.load.clone()self.visited_ninf_flag[:, :, self.problem_size+1][(~self.at_the_depot)&(self.last_current_node!=0)] = 0#更新当前节点和已选择节点列表self.current_node = selectedself.selected_node_list = torch.cat((self.selected_node_list, self.current_node[:, :, None]), dim=2)#更新需求和负载demand_list = self.depot_node_demand[:, None, :].expand(self.batch_size, self.pomo_size, -1)gathering_index = selected[:, :, None]selected_demand = demand_list.gather(dim=2, index=gathering_index).squeeze(dim=2)self.load -= selected_demandself.load[self.at_the_depot] = 1 # refill loaded at the depot#更新访问标记(防止重复选择已访问的节点)self.visited_ninf_flag[self.BATCH_IDX, self.POMO_IDX, selected] = float('-inf')self.visited_ninf_flag[:, :, 0][~self.at_the_depot] = 0 # depot is considered unvisited, unless you are AT the depot#更新负无穷掩码(屏蔽需求量超过当前负载的节点)self.ninf_mask = self.visited_ninf_flag.clone()round_error_epsilon = 0.00001demand_too_large = self.load[:, :, None] + round_error_epsilon < demand_list_2=torch.full((demand_too_large.shape[0],demand_too_large.shape[1],1),False)demand_too_large = torch.cat((demand_too_large, _2), dim=2)self.ninf_mask[demand_too_large] = float('-inf')#更新步骤状态,将更新后的状态同步到 self.step_stateself.step_state.selected_count = self.time_stepself.step_state.load = self.loadself.step_state.current_node = self.current_nodeself.step_state.ninf_mask = self.ninf_mask#时间步大于等于 4 的复杂操作else:#动作模式分类action0_bool_index = ((self.mode == 0) & (selected != self.problem_size + 1))action1_bool_index = ((self.mode == 0) & (selected == self.problem_size + 1)) # regretaction2_bool_index = self.mode == 1action3_bool_index = self.mode == 2action1_index = torch.nonzero(action1_bool_index)action2_index = torch.nonzero(action2_bool_index)action4_index = torch.nonzero((action3_bool_index & (self.current_node != 0)))#更新选择计数self.selected_count = self.selected_count+1#后悔模式self.selected_count[action1_bool_index] = self.selected_count[action1_bool_index] - 2#节点更新self.last_is_depot = (self.last_current_node == 0)_ = self.last_current_node[action1_index[:, 0], action1_index[:, 1]].clone()temp_last_current_node_action2 = self.last_current_node[action2_index[:, 0], action2_index[:, 1]].clone()self.last_current_node = self.current_node.clone()self.current_node = selected.clone()self.current_node[action1_index[:, 0], action1_index[:, 1]] = _.clone()#更新已选择节点列表self.selected_node_list = torch.cat((self.selected_node_list, selected[:, :, None]), dim=2)#更新负载self.at_the_depot = (selected == 0)demand_list = self.depot_node_demand[:, None, :].expand(self.batch_size, self.pomo_size, -1)# shape: (batch, pomo, problem+1)_3 = torch.full((demand_list.shape[0], demand_list.shape[1], 1), 0)#扩展需求列表 demand_list demand_list = torch.cat((demand_list, _3), dim=2)gathering_index = selected[:, :, None]# shape: (batch, pomo, 1)selected_demand = demand_list.gather(dim=2, index=gathering_index).squeeze(dim=2)_1 = self.last_load[action1_index[:, 0], action1_index[:, 1]].clone()self.last_load= self.load.clone()# shape: (batch, pomo)self.load -= selected_demandself.load[action1_index[:, 0], action1_index[:, 1]] = _1.clone()self.load[self.at_the_depot] = 1 # refill loaded at the depot#更新访问标记self.visited_ninf_flag[:, :, self.problem_size+1][self.last_is_depot] = 0self.visited_ninf_flag[self.BATCH_IDX, self.POMO_IDX, selected] = float('-inf')self.visited_ninf_flag[action2_index[:, 0], action2_index[:, 1], temp_last_current_node_action2] = float(0)self.visited_ninf_flag[action4_index[:, 0], action4_index[:, 1], self.problem_size + 1] = float(0)self.visited_ninf_flag[:, :, self.problem_size+1][self.at_the_depot] = float('-inf')self.visited_ninf_flag[:, :, 0][~self.at_the_depot] = 0# 更新负无穷掩码self.ninf_mask = self.visited_ninf_flag.clone()round_error_epsilon = 0.00001demand_too_large = self.load[:, :, None] + round_error_epsilon < demand_list# shape: (batch, pomo, problem+1)self.ninf_mask[demand_too_large] = float('-inf')# 更新完成状态# 检查哪些智能体已经完成所有节点的访问。# 更新完成标记 self.finished。newly_finished = (self.visited_ninf_flag == float('-inf'))[:,:,:self.problem_size+1].all(dim=2)# shape: (batch, pomo)self.finished = self.finished + newly_finished# shape: (batch, pomo)#更新模式self.mode[action1_bool_index] = 1self.mode[action2_bool_index] = 2self.mode[action3_bool_index] = 0self.mode[self.finished] = 4# 更新完成后的掩码调整self.ninf_mask[:, :, 0][self.finished] = 0self.ninf_mask[:, :, self.problem_size+1][self.finished] = float('-inf')# 更新步骤状态self.step_state.selected_count = self.time_stepself.step_state.load = self.loadself.step_state.current_node = self.current_nodeself.step_state.ninf_mask = self.ninf_mask# returning valuesadone = self.finished.all()if done:reward = -self._get_travel_distance() # note the minus sign!else:reward = Nonereturn self.step_state, reward, done相关文章:
20250306-笔记-精读class CVRPEnv:step(self, selected)
文章目录 前言一、时间步小于 41.1 控制时间步的递增1.2 判断是否在配送中心1.3 特定时间步的操作1.4更新1.4.1 更新当前节点和已选择节点列表1.4.2 更新需求和负载1.4.3 更新访问标记1.4.4 更新负无穷掩码1.4.5 更新步骤状态,将更新后的状态同步到 self.step_state…...

文档进行embedding,Faiss向量检索
这里采用Langchain的HuggingFaceEmbeddings 参照博主,改了一些东西,因为Langchain0.3在0.2的基础上进行了一定的修改 from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_huggingface import HuggingFaceEmbeddings …...

一周学会Flask3 Python Web开发-在模板中渲染WTForms表单视图函数里获取表单数据
锋哥原创的Flask3 Python Web开发 Flask3视频教程: 2025版 Flask3 Python web开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili 为了能够在模板中渲染表单,我们需要把表单类实例传入模板。首先在视图函数里实例化表单类LoginForm,然…...

Android AudioFlinger(五)—— 揭开AudioMixer面纱
前言: 在 Android 音频系统中,AudioMixer 是音频框架中一个关键的组件,用于处理多路音频流的混音操作。它主要存在于音频回放路径中,是 AudioFlinger 服务的一部分。 上一节我们讲threadloop的时候,提到了一个函数pr…...
)
分类学习(加入半监督学习)
#随机种子固定,随机结果也固定 def seed_everything(seed):torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)torch.backends.cudnn.benchmark Falsetorch.backends.cudnn.deterministic Truerandom.seed(seed)np.random.see…...

Serilog: 强大的 .NET 日志库
Serilog 是一个功能强大的日志记录库,专为 .NET 平台设计。它提供了丰富的 API 和可插拔的输出器及格式化器,使得开发者能够轻松定制和扩展日志记录功能。在本文中,我们将探索 Serilog 的基础知识、API 使用、配置和一些常见的示例。 1. 日志…...

Matlab——添加坐标轴虚线网格的方法
第一步:在显示绘制图的窗口,点击左上角 “编辑”,然后选“坐标区属性” 第二步:点 “网格”,可以看到添加网格的方框了...
π0及π0_fast的源码解析——一个模型控制7种机械臂:对开源VLA sota之π0源码的全面分析,含我司微调π0的部分实践
前言 ChatGPT出来后的两年多,也是我疯狂写博的两年多(年初deepseek更引爆了下),比如从创业起步时的15年到后来22年之间 每年2-6篇的,干到了23年30篇、24年65篇、25年前两月18篇,成了我在大模型和具身的原始技术积累 如今一转眼已…...

TCP7680端口是什么服务
WAF上看到有好多tcp7680端口的访问信息 于是上网搜索了一下,确认TCP7680端口是Windows系统更新“传递优化”功能的服务端口,个人理解应该是Windows利用这个TCP7680端口,直接从内网已经具备更新包的主机上共享下载该升级包,无需从微…...

服务器python项目部署
角色:root, 其他用户应该也可以 1. 安装python3环境 #如果是新机器,尽量执行,避免未知报错 yum -y update python -v yum install python3 python3 -v2. 使用virtualenvwrapper 创建虚拟环境,并使用workon切换不同的虚拟环境 # 安装virtua…...

Hive-优化(语法优化篇)
列裁剪与分区裁剪 在生产环境中,会面临列很多或者数据量很大时,如果使用select * 或者不指定分区进行全列或者全表扫描时效率很低。Hive在读取数据时,可以只读取查询中所需要的列,忽视其他的列,这样做可以节省读取开销…...

C语言100天练习题【记录本】
C语言经典100题(手把手 编程) 可以在哔哩哔哩找到(url:C语言经典100题(手把手 编程)_哔哩哔哩_bilibili) 已解决的天数:一,二,五,六,八…...

记录排查服务器CPU负载过高
1.top 命令查看cpu占比过高的进程id 这里是 6 2. 查看进程中占用CPU过高的线程 id 这里是9 top -H -p 6 ps -mp 6 -o THREAD,tid,time 使用jstack 工具 产看进程的日志 需要线程id转换成16进制 jstack 6 | grep “0x9” 4.jstack 6 可以看进程的详细日志 查看日志发现是 垃圾回…...

Spring Boot 项目中 Redis 常见问题及解决方案
目录 缓存穿透缓存雪崩缓存击穿Redis 连接池耗尽Redis 序列化问题总结 1. 缓存穿透 问题描述 缓存穿透是指查询一个不存在的数据,由于缓存中没有该数据,请求会直接打到数据库上,导致数据库压力过大。 解决方案 缓存空值:即使…...

基于Spring Boot的校园失物招领系统的设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

10 【HarmonyOS NEXT】 仿uv-ui组件开发之Avatar头像组件开发教程(一)
温馨提示:本篇博客的详细代码已发布到 git : https://gitcode.com/nutpi/HarmonyosNext 可以下载运行哦! 目录 第一篇:Avatar 组件基础概念与设计1. 组件概述2. 接口设计2.1 形状类型定义2.2 尺寸类型定义2.3 组件属性接口 3. 设计原则4. 使用…...

OpenHarmony 5.0.0 Release
OpenHarmony 5.0.0 Release 版本概述 OpenHarmony 5.0.0 Release版本标准系统能力持续完善。相比OpenHarmony 5.0 Beta1,Release版本做出了如下特性新增或增强: 应用框架新增更多生命周期管理能力、提供子进程相关能力,可以对应用运行时的…...

RSA的理解运用与Pycharm组装Cryptodome库
1、RSA的来源 RSA通常指基于RSA算法的密码系统,令我没想到的是,其名字的来源竟然不是某个含有特别意义的单词缩写而成(比如PHP:Hypertext Preprocessor(超文本预处理器)),而是由1977年提出该算法的三个歪果…...

Android 多用户相关
Android 多用户相关 本文主要记录下android 多用户相关的adb 命令操作. 1: 获取用户列表 命令: adb shell pm list users 输出如下: Users:UserInfo{0:机主:c13} running默认只有一个用户, id为0 ,用户状态为运行 2: 创建新用户 命令: adb shell …...
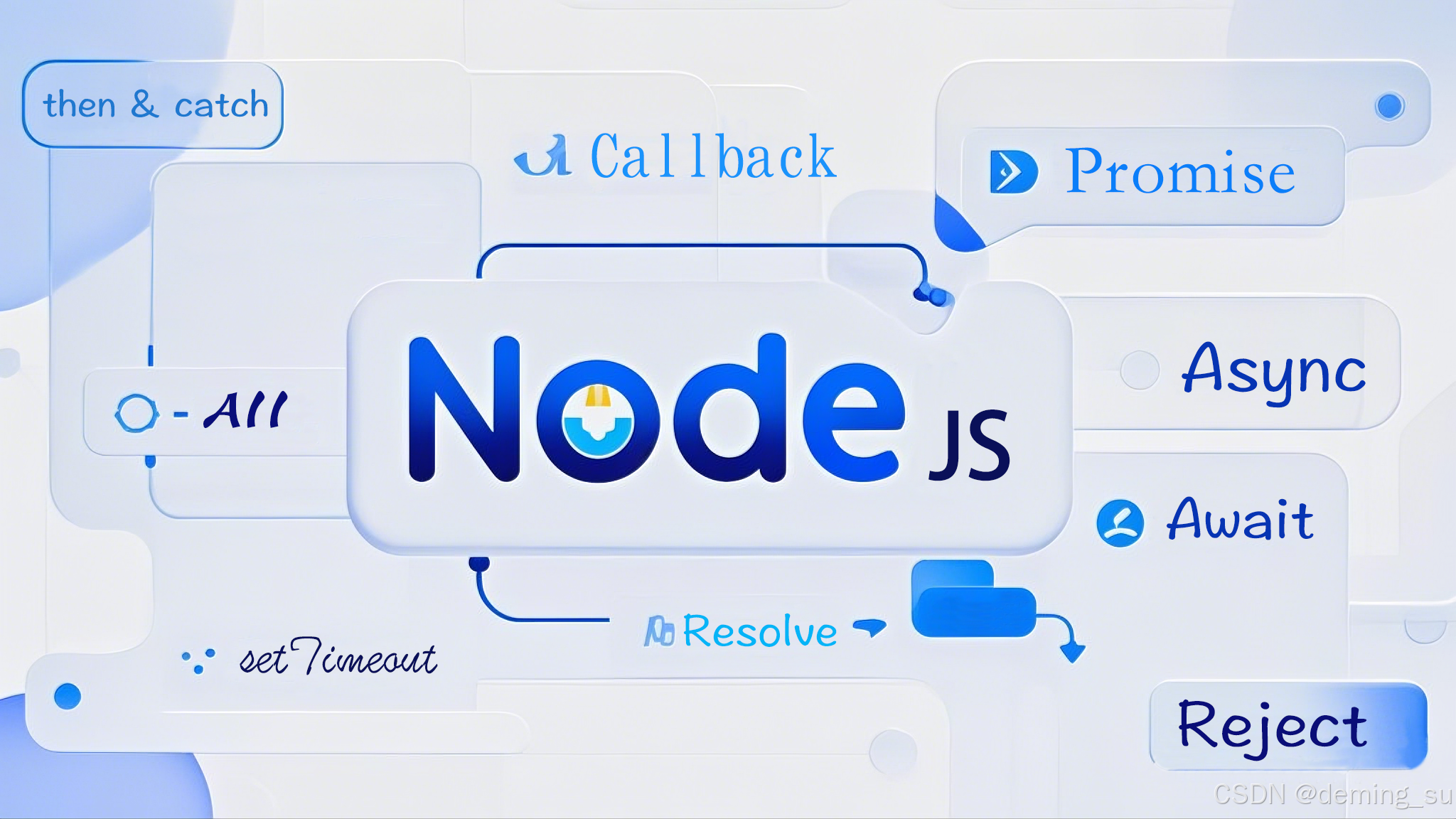
第三课:异步编程核心:Callback、Promise与Async/Await
Node.js 是一个基于事件驱动的非阻塞 I/O 模型,这使得它非常适合处理高并发的网络请求。在 Node.js 中,异步编程是一项非常重要的技能。理解和掌握异步编程的不同方式不仅能提高代码的效率,还能让你更好地应对复杂的开发任务。本文将深入探讨…...
怎么选,告别‘卖家秀’惨案)
从LED灯珠到手机屏幕:一文搞懂色温、显色指数(CRI)怎么选,告别‘卖家秀’惨案
从LED灯珠到手机屏幕:色温与显色指数的科学选购指南 深夜伏案工作时,你是否总觉得眼睛干涩疲劳?网购衣物到手后颜色总与屏幕显示相差甚远?餐厅美食拍出来总是暗淡无光?这些困扰的根源往往在于——光源质量。当我们面对…...

深入解析 magic-cli:基于模板的自动化代码生成工具设计与实践
1. 项目概述:一个能“变魔术”的命令行工具最近在折腾一些自动化脚本和项目脚手架时,发现了一个挺有意思的开源项目,叫magic-cli。乍一看这个名字,你可能会觉得有点玄乎,命令行工具还能玩出什么“魔法”来?…...

如何在Windows 11上完美运行经典游戏:DDrawCompat终极兼容性解决方案
如何在Windows 11上完美运行经典游戏:DDrawCompat终极兼容性解决方案 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mir…...

Windows系统信息里藏了多少宝?教你用systeminfo和wmic命令挖出BIOS等硬件详情
Windows命令行高手课:用systeminfo和wmic打造硬件信息查询工具箱 每次打开第三方硬件检测工具时,那些闪烁的广告弹窗是否让你不胜其烦?其实Windows早已内置了一套堪比专业软件的硬件信息查询系统。本文将带你解锁systeminfo和wmic这对黄金组合…...

ColorBrewer完整指南:如何为地图和数据可视化选择完美配色方案
ColorBrewer完整指南:如何为地图和数据可视化选择完美配色方案 【免费下载链接】colorbrewer 项目地址: https://gitcode.com/gh_mirrors/co/colorbrewer ColorBrewer是一个专为地图着色和数据可视化设计的开源配色工具,基于Cynthia Brewer博士的…...

SDEP协议与SPI-BLE数据传输:从理论到实战的深度解析
1. SDEP协议与SPI-BLE数据传输:从理论到实战的深度解析在物联网和嵌入式开发领域,如何让一个资源受限的微控制器(MCU)与一个复杂的无线模块稳定、高效地“对话”,一直是个既基础又关键的挑战。你可能遇到过这样的场景&…...

解放原神玩家生产力的开源工具箱:Snap.Hutao如何用本地化数据处理重塑游戏体验
解放原神玩家生产力的开源工具箱:Snap.Hutao如何用本地化数据处理重塑游戏体验 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitH…...

ESP32平台后量子密码学Kyber算法优化实践
1. ESP32平台上的后量子密码学实践 在物联网设备数量呈指数级增长的今天,设备间的安全通信面临着前所未有的挑战。传统公钥加密算法如RSA和ECC正面临着量子计算的威胁——Shor算法能在多项式时间内破解这些基于大整数分解和离散对数问题的加密体系。作为应对&#x…...

AI智能体协作命令行工具squads-cli:多智能体编排与自动化实战
1. 项目概述:一个面向AI智能体协作的命令行工具如果你最近在关注AI智能体(Agent)的开发,尤其是多智能体协作(Multi-Agent Collaboration)这个方向,那你很可能已经听说过或接触过一些相关的框架。…...

AI代码助手与Django全栈开发:人机协同编程新范式实践
1. 项目概述:当AI代码助手遇上Django全栈开发如果你是一名独立开发者、初创公司的技术负责人,或者正在学习全栈开发,那么“Cursor-Django”这个项目绝对值得你花时间研究。这不是一个简单的Django教程,而是一个由Coding for Entre…...