深度学习模型组件之优化器--自适应学习率优化方法(Adadelta、Adam、AdamW)
深度学习模型组件之优化器–自适应学习率优化方法(Adadelta、Adam、AdamW)
文章目录
- 深度学习模型组件之优化器--自适应学习率优化方法(Adadelta、Adam、AdamW)
- 1. Adadelta
- 1.1 公式
- 1.2 优点
- 1.3 缺点
- 1.4 应用场景
- 2. Adam (Adaptive Moment Estimation)
- 2.1 公式
- 2.2 优点
- 2.3 缺点
- 2.4 应用场景
- 3. AdamW
- 3.1 公式
- 3.2 优点
- 3.3 缺点
- 3.4 应用场景
- 4.总结
在深度学习中,优化器是训练过程中不可或缺的一部分。不同的优化器通过调整学习率和更新规则来帮助模型收敛得更快、更好。本文将详细介绍三种常用的优化器: Adadelta、 Adam 和 AdamW,并展示它们的核心公式、工作原理、优缺点以及应用场景。
1. Adadelta
1.1 公式
Adadelta 的核心公式如下:
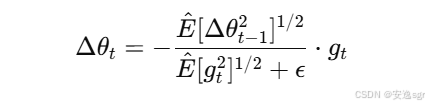
其中:
Δθt是参数更新;gt是当前时间步的梯度;E^[Δθt−12]是之前梯度的累积平方;E^[gt2]是当前梯度的平方的累积;ϵ是一个小常数,用于避免除零错误。
1.2 优点
- 自适应学习率:
Adadelta不需要预定义学习率,通过梯度的变化动态调整学习率。 - 避免学习率衰减: 与其他优化器不同,
Adadelta没有显式的学习率衰减机制,这使得优化过程更加稳定。
1.3 缺点
- 参数更新较慢: 在一些任务中,
Adadelta的更新速度可能较慢,尤其是在复杂的深度神经网络中。 - 内存消耗较大:
Adadelta存储了梯度的平方和参数的更新历史,因此需要更多的内存资源。
1.4 应用场景
- 动态调整学习率: 适用于那些无法手动调整学习率的任务,特别是对于一些不容易设定初始学习率的情况。
- 不需要手动调整学习率: 对于一些快速原型设计的任务,
Adadelta是一个不错的选择。
1.5 代码示例
import torch
import torch.optim as optim# 假设我们有一个模型和数据
model = torch.nn.Linear(10, 1)
optimizer = optim.Adadelta(model.parameters(), lr=1.0)# 假设损失函数
criterion = torch.nn.MSELoss()# 假设输入和目标
input = torch.randn(32, 10)
target = torch.randn(32, 1)# 训练过程
optimizer.zero_grad()
output = model(input)
loss = criterion(output, target)
loss.backward()
optimizer.step()
2. Adam (Adaptive Moment Estimation)
2.1 公式
Adam 优化器的核心公式如下:
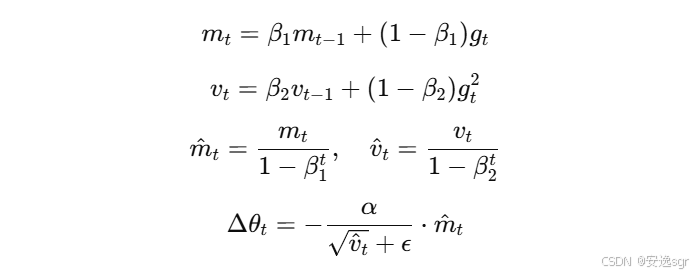
其中:
mt是梯度的一阶矩(均值);vt是梯度的二阶矩(方差);m^t是对mt和vt进行偏差修正后的估计;gt是当前时间步的梯度;β1和β2是一阶矩和二阶矩的衰减率;ϵ是一个小常数,用于避免除零错误;α是学习率。
2.2 优点
- 动态调整学习率:
Adam通过一阶矩和二阶矩的自适应调整,使得每个参数的学习率是动态的。 - 适应稀疏梯度: 对于一些稀疏梯度问题,
Adam展现出较好的性能。 - 偏差修正: 通过修正一阶和二阶矩的偏差,
Adam在初期训练阶段表现更加稳定。
2.3 缺点
- 过拟合: 在一些正则化要求较强的模型中,
Adam可能导致过拟合,特别是对于大型模型。 - 内存消耗:
Adam需要存储一阶和二阶矩的估计,因此需要更多的内存资源。
2.4 应用场景
- 大多数深度学习任务:
Adam适用于各种深度学习任务,尤其是在处理大规模数据集和深层神经网络时表现优异。 - 稀疏数据和参数: 在处理稀疏梯度或稀疏参数的任务时,
Adam是非常合适的选择。
2.5 代码示例:
import torch
import torch.optim as optim# 假设我们有一个模型和数据
model = torch.nn.Linear(10, 1)
optimizer = optim.Adam(model.parameters(), lr=0.001)# 假设损失函数
criterion = torch.nn.MSELoss()# 假设输入和目标
input = torch.randn(32, 10)
target = torch.randn(32, 1)# 训练过程
optimizer.zero_grad()
output = model(input)
loss = criterion(output, target)
loss.backward()
optimizer.step()
3. AdamW
3.1 公式
AdamW 的核心公式与 Adam 非常相似,不同之处在于它将权重衰减与梯度更新过程分开。AdamW 的参数更新公式如下:
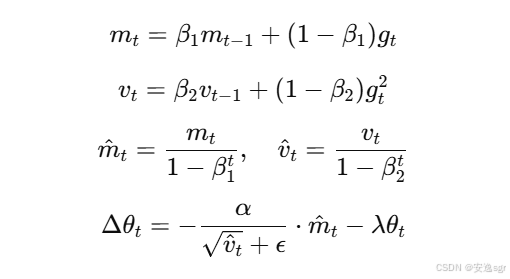
其中:
λ是权重衰减系数;- 其他符号与
Adam中相同。
3.2 优点
- 更好的正则化: 通过将权重衰减项从梯度更新中分离出来,
AdamW在正则化方面比 Adam 更加有效。 - 更高的泛化能力: 由于权重衰减对模型权重的约束,
AdamW能有效减少过拟合,尤其适用于大规模模型。
3.3 缺点
- 超参数调整: 相比于
Adam,AdamW需要额外调整权重衰减系数,可能增加调参的复杂度。 - 计算成本: 虽然与 Adam 相似,但添加了权重衰减项,可能在计算和内存上稍有增加。
3.4 应用场景
- 大型模型训练:
AdamW在需要正则化的大型模型(如Transformer、BERT)中有显著优势。 - 需要强正则化的任务: 对于需要避免过拟合的任务,特别是在复杂模型中,
AdamW是更好的选择。
3.5 代码示例:
import torch
import torch.optim as optim# 假设我们有一个模型和数据
model = torch.nn.Linear(10, 1)
optimizer = optim.AdamW(model.parameters(), lr=0.001, weight_decay=0.01)# 假设损失函数
criterion = torch.nn.MSELoss()# 假设输入和目标
input = torch.randn(32, 10)
target = torch.randn(32, 1)# 训练过程
optimizer.zero_grad()
output = model(input)
loss = criterion(output, target)
loss.backward()
optimizer.step()
4.总结
| 优化器 | 核心思想 | 公式 | 优缺点 | 适用场景 |
|---|---|---|---|---|
| Adadelta | 基于 RMSprop 的改进版本,自适应调整学习率 | 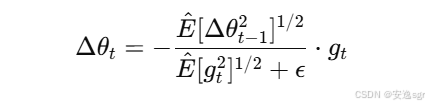 | 优点:动态调整学习率,不需要手动设置;缺点:更新较慢,内存消耗大 | 需要动态调整学习率的任务,快速原型设计 |
| Adam | 结合动量和 RMSprop 的优点,通过一阶和二阶矩自适应调整 | 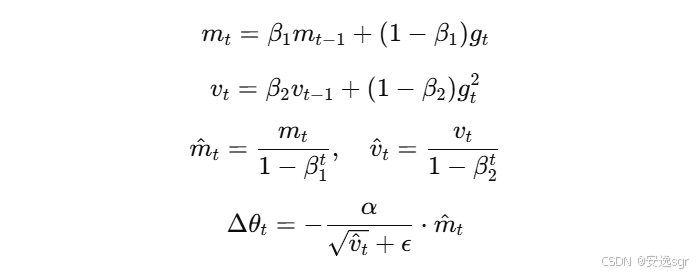 | 优点:动态调整学习率,适应稀疏梯度,偏差修正;缺点:可能导致过拟合,内存消耗大 | 大多数深度学习任务,稀疏数据处理 |
| AdamW | 在 Adam 基础上添加权重衰减,适合大模型正则化 | 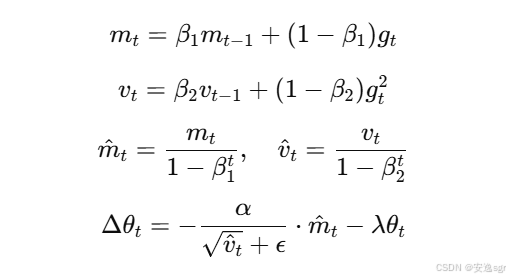 | 优点:更好的正则化,减少过拟合;缺点:需要额外调整权重衰减系数 | 大型模型训练,需要正则化的任务 |
相关文章:
深度学习模型组件之优化器--自适应学习率优化方法(Adadelta、Adam、AdamW)
深度学习模型组件之优化器–自适应学习率优化方法(Adadelta、Adam、AdamW) 文章目录 深度学习模型组件之优化器--自适应学习率优化方法(Adadelta、Adam、AdamW)1. Adadelta1.1 公式1.2 优点1.3 缺点1.4 应用场景 2. Adam (Adaptiv…...

使用jcodec库,访问网络视频提取封面图片上传至oss
注释部分为FFmpeg(确实方便但依赖太大,不想用) package com.zuodou.upload;import com.aliyun.oss.OSS; import com.aliyun.oss.model.ObjectMetadata; import com.aliyun.oss.model.PutObjectRequest; import com.zuodou.oss.OssProperties;…...

新品速递 | 多通道可编程衰减器+矩阵系统,如何破解复杂通信测试难题?
在无线通信技术快速迭代的今天,多通道可编程数字射频衰减器和衰减矩阵已成为测试领域不可或缺的核心工具。它们凭借高精度、灵活配置和强大的多通道协同能力,为5G、物联网、卫星通信等前沿技术的研发与验证提供了关键支持。从基站性能测试到终端设备校准…...

扩展------项目中集成阿里云短信服务
引言 在当今数字化时代,短信服务在各种项目中扮演着重要角色,如用户注册验证、订单通知、营销推广等。阿里云短信服务凭借其稳定、高效和丰富的功能,成为众多开发者和企业的首选。本文将详细介绍如何在项目中集成阿里云短信服务,帮…...

MySQL面试篇——性能优化
MySQL性能优化 在MySQL中,如何定位慢查询 慢查询表象:页面加载过慢、接口压测响应时间过长(超过1s)。造成慢查询的原因通常有:聚合查询、多表查询、表数据量过大查询、深度分页查询 方案一:开源工具 调试工…...

Java EE 进阶:Spring MVC(2)
cookie和session的关系 两者都是在客户端和服务器中进行存储数据和传递信息的工具 cookie和session的区别 Cookie是客⼾端保存⽤⼾信息的⼀种机制. Session是服务器端保存⽤⼾信息的⼀种机制. Cookie和Session之间主要是通过SessionId关联起来的,SessionId是Co…...

ShardingSphere 和 Spring 的动态数据源切换机制的对比以及原理
ShardingSphere 与 Spring 动态数据源切换机制的对比及原理 一、核心定位对比 维度ShardingSphereSpring动态数据源(如 AbstractRoutingDataSource)定位分布式数据库中间件轻量级多数据源路由工具核心目标分库分表、读写分离、分布式事务多数据源动态切…...

基于Django的协同过滤算法养老新闻推荐系统的设计与实现
基于Django的协同过滤算法养老新闻推荐系统(可改成普通新闻推荐系统使用) 开发工具和实现技术 Pycharm,Python,Django框架,mysql8,navicat数据库管理工具,vue,spider爬虫࿰…...
)
AI视频生成工具清单(附网址与免费说明)
以下是一份详细的AI视频制作网站总结清单,包含免费/付费信息及核心功能说明: AI视频生成工具清单(附网址与免费说明) 1. Synthesia 网址:https://www.synthesia.io是否免费:免费试用(生成视频…...

JavaWeb学习——HTTP协议
HTTP 协议 什么是 HTTP 协议 HTTP(超文本传输协议,HyperText Transfer Protocol)是用于在客户端(如浏览器)和服务器之间传输超文本(如网页、图片、视频等)的应用层协议。它是现代互联网数据通…...
)
QP 问题(Quadratic Programming, 二次规划)
QP 问题(Quadratic Programming, 二次规划)是什么? QP(Quadratic Programming,二次规划)是一类优化问题,其中目标函数是二次型函数,约束条件可以是线性等式或不等式。 QP 问题是线…...

VSTO(C#)Excel开发2:Excel对象模型和基本操作
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C的,可以在任何平台上使用。 源码指引:github源…...

MySQL索引数据结构
目录 1 索引常用的数据结构 1.1 二叉树 1.2 平衡二叉树 1.3 红黑树 1.3 Hash表 1.4 B树 1.4 B树 2 MySQL索引的数据结构 2.1 MyISAM存储引擎索引 2.2 InnoDB存储引擎索引 2.2.1 聚集索引 2.2.2 非聚集索引 2.2.3 联合索引数 2.2.4 hash索引 1 索引常用的数据结构 1.1 二叉树 二…...

C 语 言 --- 数 组 (1)
C 语 言 --- 数 组1 数 组定义一维数组语 法 格 式初始化完 全 初 始 化不 完 全 初 始 化省 略 数 组 大 小不 初 始 化使 用 memset 初 始 化 类 型访 问 元 素一 维 数 组 在 内 存 中 的 存 储 总结 💻作 者 简 介:曾 与 你 一 样 迷 茫,…...

[视频编码]rkmpp 实现硬件编码
mpi_enc_test的命令参数描述说明 命令参数的描述说明如下: 命令参数 描述说明 -i 输入的图像文件。 -o 输出的码流文件。 -w 图像宽度,单位为像素。 -h 图像高度,单位为像素。 -hstride 垂直方向相邻两行之间的距离,单…...

3D数字化:家居行业转型升级的关键驱动力
在科技日新月异的今天,家居行业正经历着一场前所未有的变革。从传统的线下实体店铺到线上电商平台的兴起,再到如今3D数字化营销的广泛应用,消费者的购物体验正在发生翻天覆地的变化。3D数字化营销不仅让购物变得更加智能和便捷,还…...

网安知识点
1.SQL注入漏洞产生的原因是? 前端传到后端的数据,没有经过任何处理,直接当作sql语句的一部分来执行 2.讲一下sql注入,写入webshell需要哪些前提条件 开启导入导出权限secure-file-priv 站点根目录位置/路径 mysql用户对站点根目…...

天津大学02-深度解读DeepSeek:部署、使用、安全【文末附下载链接】
大模型风险与不当用例——价值观错位 大模型与人类价值观、期望之间的不一致而导致的安全问题,包含:• 社会偏见(Social Bias)LLM在生成文本时强化对特定社会群体的刻板印象,例如将穆斯林与恐怖主义关联,或…...

【kubernetes】service
目录 1. 说明2. 原理2.1 服务注册2.2 服务发现2.3 负载均衡 3. Service的类型3.1 ClusterIP3.2 NodePort3.3 LoadBalancer3.4 ExternalName 4. 使用场景 1. 说明 1.kubernetes中的service主要用于提供网络服务,并实现微服务架构中的几个核心功能:全自动…...

Python卷积神经网络(CNN)来识别和计数不同类型的工业零件
以下三种类型工业零件为例,使用卷积神经网络(CNN)来识别和计数不同类型的工业零件。以下是Python实现步骤: 数据准备:收集并标注包含不同形状(如方形、圆形、扇形)的工业零件图像数据集。 模型…...

Arm MPS3 FPGA开发板LED闪烁控制实战
1. 项目概述在嵌入式系统开发领域,FPGA(现场可编程门阵列)因其可重构特性成为硬件原型设计的首选平台。Arm MPS3 FPGA开发板作为一款功能强大的原型验证工具,为开发者提供了从算法验证到系统集成的完整解决方案。本次我们将通过经…...


接入Taotoken后感受到的API调用延迟降低与错误率改善
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 接入Taotoken后感受到的API调用延迟降低与错误率改善 1. 背景与切换契机 作为一名长期在项目中集成大模型能力的开发者࿰…...

你的群晖NAS性能过剩了吗?试试用它跑个万兆测速服务,榨干内网带宽
如何用群晖NAS搭建专业级内网测速平台:从硬件压榨到性能调优全指南 当你为家庭或工作室部署了万兆网络环境后,最令人抓狂的莫过于花了大价钱升级设备,却无法确认实际带宽是否达标。那些标榜"万兆兼容"的交换机、网卡和NASÿ…...

GitHub PR全流程实战:从创建、自动化测试到代码审查与合并
1. 项目概述与核心价值 如果你参与过开源项目,或者在公司内部使用GitHub进行团队协作,那么“Pull Request”(PR)这个流程你一定不陌生。它不仅仅是把代码从一个分支合并到另一个分支那么简单,而是一整套围绕代码质量、…...
基于CircuitPython与BLE的NeoPixel智能穿戴灯光项目实战
1. 项目概述:打造你的第一顶可编程发光帽 几年前,当我第一次在Maker Faire上看到有人戴着一顶能随着音乐节奏变换色彩的帽子时,我就被深深吸引了。那不仅仅是一个电子项目,更像是一件充满个性的可穿戴艺术品。从那时起࿰…...

为什么你的民族志写作总卡在“分析乏力”?NotebookLM三步穿透文本深层文化逻辑
更多请点击: https://intelliparadigm.com 第一章:为什么你的民族志写作总卡在“分析乏力”?NotebookLM三步穿透文本深层文化逻辑 民族志写作常陷入“描述丰富、解释单薄”的困境——田野笔记堆叠如山,却难以提炼出文化实践背后的…...

为防数据泄露!教你拆除2024款RAV4混动汽车调制解调器和GPS
拆除2024款RAV4混动汽车调制解调器和GPS,从源头上阻止数据传输!现代汽车就像装在轮子上的电脑,配备众多传感器,会回传位置、速度等遥测数据。其车内和车外摄像头、麦克风及调制解调器默认开启,且难关闭,数据…...

内容创作团队如何借助Taotoken聚合API管理多个模型的调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 内容创作团队如何借助Taotoken聚合API管理多个模型的调用成本 对于内容创作团队而言,大模型已成为提升写作效率、优化内…...

为什么OpenVSP是航空航天工程师的“参数化建模瑞士军刀“?5个实战场景深度解析
为什么OpenVSP是航空航天工程师的"参数化建模瑞士军刀"?5个实战场景深度解析 【免费下载链接】OpenVSP A parametric aircraft geometry tool 项目地址: https://gitcode.com/gh_mirrors/ope/OpenVSP 在飞机设计领域,传统CAD软件的复杂…...