Elasticsearch使用篇 - 指标聚合
指标聚合
指标聚合从聚合文档中提取出指标进行计算。可以从文档的字段或者使用脚本方式进行提取。
聚合统计可以同时返回明细数据,可以分页查询,可以返回总数量。
可以结合查询条件,限制数据范围,结合倒排索引+列式存储。
指标聚合的资料可以参考 Elasticsearch Metrics aggregation。
语法格式:
GET <index>/_search
{"aggs": {"<aggs_name>": {"<aggs_type>": {"field": "<field_name>"}}}
}
min、max、sum、avg
分别是最小值、最大值、求和、求平均值。它们四个都是单值指标聚合。可以从聚合文档中指定数值字段或者脚本中提取数值来计算统计信息。
-
field:对指定字段进行聚合。
-
missing:当指定字段的值不存在时,指定一个缺省值。默认会忽略。
GET kibana_sample_data_ecommerce/_search
{"size": 0, "aggs": {"sum_taxful_total_price": {"sum": {"field": "taxful_total_price"}},"avg_taxful_total_price": {"avg": {"field": "taxful_total_price"}},"max_taxful_total_price": {"max": {"field": "taxful_total_price"}},"min_taxful_total_price": {"min": {"field": "taxful_total_price"}}}
}
结果输出如下:
{"took" : 16,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4675,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"max_taxful_total_price" : {"value" : 2250.0},"sum_taxful_total_price" : {"value" : 350884.12890625},"avg_taxful_total_price" : {"value" : 75.05542864304813},"min_taxful_total_price" : {"value" : 6.98828125}}
}
以上四种聚合可以从脚本中提取数值来统计相关信息。
GET kibana_sample_data_ecommerce/_search
{"size": 0,"runtime_mappings": {"unit_price": {"type": "double","script": """emit(doc['taxful_total_price'].value / doc['total_quantity'].value)"""}}, "aggs": {"avg_unit_price": {"avg": {"field": "unit_price"}}}
}
stats
统计聚合。一种多值指标聚合,可以从聚合文档中指定数值字段或者脚本中提取数值来计算统计信息,统计信息包括 count、min、max、sum、avg。
-
field:对指定字段进行聚合。
-
missing:当指定字段的值不存在时,指定一个缺省值。默认会忽略。
GET kibana_sample_data_ecommerce/_search
{"size": 0, "aggs": {"stats_taxful_total_price": {"stats": {"field": "taxful_total_price"}}}
}
输出结果如下:
{"took" : 22,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4675,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"stats_taxful_total_price" : {"count" : 4675,"min" : 6.98828125,"max" : 2250.0,"avg" : 75.05542864304813,"sum" : 350884.12890625}}
}
stat 聚合可以从脚本中提取数值来统计相关信息。
GET kibana_sample_data_ecommerce/_search
{"size": 0,"runtime_mappings": {"unit_price": {"type": "double","script": """emit(doc['taxful_total_price'].value / doc['total_quantity'].value)"""}}, "aggs": {"stat_price": {"stats": {"field": "unit_price"}}}
}
extended_stats
拓展统计聚合。一种多值指标聚合,可以从聚合文档中指定数值字段或者脚本中提取数值来计算统计信息。
- field:对指定字段进行聚合。
- sigma:控制应该显示离均值的标准偏差的数量。
- missing:当指定字段的值不存在时,指定一个缺省值。默认会忽略。
GET kibana_sample_data_ecommerce/_search
{"size": 0, "aggs": {"extend_stats_total_price": {"extended_stats": {"field": "taxful_total_price"}}}
}
输出结果如下:
{"took" : 4,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4675,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"extend_stats_total_price" : {"count" : 4675,"min" : 6.98828125,"max" : 2250.0,"avg" : 75.05542864304813,"sum" : 350884.12890625,"sum_of_squares" : 3.9367749294174194E7, // 平方和"variance" : 2787.59157113862, // 方差"variance_population" : 2787.59157113862,"variance_sampling" : 2788.187974983536,"std_deviation" : 52.79764740155209, // 标准差"std_deviation_population" : 52.79764740155209,"std_deviation_sampling" : 52.80329511482722,"std_deviation_bounds" : {"upper" : 180.6507234461523,"lower" : -30.53986616005605,"upper_population" : 180.6507234461523,"lower_population" : -30.53986616005605,"upper_sampling" : 180.66201887270256,"lower_sampling" : -30.551161586606312}}}
}
extended_stats 聚合同样支持从脚本中提取数值来统计相关信息。
GET kibana_sample_data_ecommerce/_search
{"size": 0,"runtime_mappings": {"unit_price": {"type": "double","script": """emit(doc['taxful_total_price'].value / doc['total_quantity'].value)"""}}, "aggs": {"extended_stat_unit_price": {"extended_stats": {"field": "unit_price"}}}
}
percentiles
[pə’sentaɪlz] ,百分位数聚合。
它属于多值指标聚合,从聚合文档中的数值字段、直方图字段或者脚本中提取出一个或者多个百分位数。
百分位表示观测值的某个百分比出现的点。例如,第 95 个百分位数是大于观测值 95% 的值。
百分位数通常用于寻找异常值。在正态分布中,第 0.13 和 第 99.87 个百分位代表与平均值的三个标准差。任何超出三个标准差的数据通常都被认为是异常。
当检索到一个百分比范围时,可以使用它们来估计数据分布,并确定数据是否倾斜、双峰等。
-
field:对指定字段进行聚合。
-
keyed:默认 true,即使用键值对格式返回数据;如果设置为 false,则使用数组格式返回数据。
-
percents:指定百分位等级。
-
tdigest:百分位计算选择的算法。TDigest 算法用来平衡内存使用率和估算精度。该算法使用一些节点来估算百分位数 - 可用的节点越多,数据的精度越高,但是内存使用率也越高。节点个数限制为 compression * 20。一个节点大约占用 32 字节的内存,按照默认配置的最差情况将产生一个大约 64 KB 大小的 TDigest。
-
compression:压缩参数。默认100。
-
hdr:使用 HDR 直方图(High Dynamic Range Histogram,即高动态范围直方图)计算百分位数。它比 TDigest 算法更快,但是占用更大的内存。内部维护一个固定的最坏情况百分比错误(指定为有效数字的数量)。这意味着,如果在直方图中记录从 1 微秒到 1 小时(3,600,000,000 微秒)的值,并将其设置为 3 个有效数字,则对于 1 毫秒以内的值将保持 1 微秒的值分辨率,对于最大跟踪值(1 小时)将保持 3.6 秒(或更好)的值分辨率。
-
number_of_significant_value_digits:有效数字的数量。不能为负数。
-
missing:当指定字段的值不存在时,指定一个缺省值。默认会忽略。
-
script:使用脚本方式。
统计商品价格的百分位数(使用 TDigest 算法)
GET kibana_sample_data_ecommerce/_search
{"size": 0, "aggs": {"percentiles_taxful_total_price": {"percentiles": {"field": "taxful_total_price","percents": [1,5,25,50,75,95,99],"tdigest": {"compression": 200}}}}
}
输出如下:
{"took" : 58,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4675,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"percentiles_taxful_total_price" : {"values" : {"1.0" : 21.984375,"5.0" : 27.984375,"25.0" : 44.96875,"50.0" : 63.96875,"75.0" : 93.0,"95.0" : 156.0,"99.0" : 222.0}}}
}
使用 HDR 直方图的方式。
GET kibana_sample_data_ecommerce/_search
{"size": 0, "aggs": {"percentiles_taxful_total_price": {"percentiles": {"field": "taxful_total_price","percents": [1,5,25,50,75,95,99],"hdr": {"number_of_significant_value_digits": 3}}}}
}
百分位数聚合支持脚本方式。
GET kibana_sample_data_ecommerce/_search
{"size": 0,"aggs": {"percentiles_taxful_total_price": {"percentiles": {"script": {"lang": "painless","source": "doc['taxful_total_price'].value / params.timeUnit","params": {"timeUnit": 1000}}}}}
}
percentile_ranks
[pərˈsentaɪl],百分位数排名聚合。
多值指标聚合,从聚合文档中的指定数值字段、直方图字段或者脚本中提取出一个或者多个百分位排名。
百分位数排名表示观测值低于某一数值的百分比。例如,如果一个值大于或等于观测值的 95%,则它位于第 95 百分位。
-
field:对指定字段进行聚合。
-
values:指定观测值。
-
keyed:默认 true,即使用键值对格式返回数据;如果设置为 false,则使用数组格式返回数据。
-
hdr:使用 HDR 直方图(High Dynamic Range Histogram,即高动态范围直方图)计算百分位数。它比 TDigest 算法更快,但是占用更大的内存。内部维护一个固定的最坏情况百分比错误(指定为有效数字的数量)。这意味着,如果在直方图中记录从 1 微秒到 1 小时(3,600,000,000 微秒)的值,并将其设置为 3 位有效数字,则对于 1 毫秒以内的值将保持 1 微秒的值分辨率,对于最大跟踪值(1 小时)将保持 3.6 秒(或更好)的值分辨率。
-
number_of_significant_value_digits:有效数字的数量。不能为负数。
-
missing:当指定字段的值不存在时,指定一个缺省值。默认会忽略。
GET kibana_sample_data_ecommerce/_search
{"size": 0, "aggs": {"percentile_ranks_total_price": {"percentile_ranks": {"field": "taxful_total_price","values": [100,200]}}}
}
结果输出如下:
{"took" : 22,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4675,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"percentile_ranks_total_price" : {"values" : {"100.0" : 79.31550802139039,"200.0" : 98.43850267379679}}}
}
percentile_ranks 聚合同样支持脚本方式。
GET kibana_sample_data_ecommerce/_search
{"size": 0,"aggs": {"percentile_ranks_taxful_total_price": {"percentile_ranks": {"values": [90, 100],"script": {"lang": "painless","source": "doc['taxful_total_price'].value / params.timeUnit","params": {"timeUnit": 10}}}}}
}
cardinality
[kɑːdɪ’nælɪtɪ],基数聚合。
一种单值指标聚合,统计不同值的近似计数。底层使用 Hyperloglog++ 算法。
-
field:对指定字段进行聚合。
-
precision_threshold:精度控制参数,默认 3000, 最大值 40000,在这个范围内,统计出来的数据去重是准确的,超过之后存在一定的误差。
-
missing:当指定字段的值不存在时,指定一个缺省值。默认会忽略。
统计客户数量
GET kibana_sample_data_ecommerce/_search
{"size": 0, "aggs": {"cardinality_customer_id": {"cardinality": {"field": "customer_id","precision_threshold": 3000}}}
}
结果输出如下:
{"took" : 9,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4675,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"cardinality_customer_id" : {"value" : 46}}
}
value_count
值计数聚合。用于计算从聚合文档中提取的值的数量。它是一种单值指标聚合。
- field:指定聚合的字段
统计客户购买了多少商品
GET kibana_sample_data_ecommerce/_search
{"size": 0, "aggs": {"value_count_products_id": {"value_count": {"field": "products._id.keyword"}}}
}
对于 histogram 类型的字段,value_count 聚合会统计 counts 数组元素之和。
PUT metrics_index
{"mappings": {"properties": {"network.name": {"type": "keyword"},"latency_histo": {"type": "histogram"}}}
}
PUT metrics_index/_doc/1
{"network.name" : "net-1","latency_histo" : {"values" : [0.1, 0.2, 0.3, 0.4, 0.5],"counts" : [3, 7, 23, 12, 6] }
}PUT metrics_index/_doc/2
{"network.name" : "net-2","latency_histo" : {"values" : [0.1, 0.2, 0.3, 0.4, 0.5],"counts" : [8, 17, 8, 7, 6] }
}
GET /metrics_index/_search?size=0
{"aggs": {"total_requests": {"value_count": { "field": "latency_histo" }}}
}
输出结果如下:
{"took" : 6,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"total_requests" : {"value" : 97}}
}
string_stats
字符串统计聚合,仅用于 keyword 类型的数据。它是一种多值指标聚合。
统计客户的名字
GET kibana_sample_data_ecommerce/_search
{"size": 0, "aggs": {"string_stats_customer_name": {"string_stats": {"field": "customer_full_name.keyword"}}}
}
结果输出如下:
{"took" : 81,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4675,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"string_stats_customer_name" : {"count" : 4675,"min_length" : 7,"max_length" : 25,"avg_length" : 13.309304812834224,"entropy" : 4.773147238719484}}
}
count:非空值的数量。
min_length:最小长度。
max_length:最大长度。
avg_length:平均长度。
entropy:信息熵。对于测量数据集的广泛属性,如多样性、相似性、随机性等,这是一个非常有用的度量标准。
top_hits
即热门聚合。热门聚合关注关联性最强的文档。通常作为子聚合使用,聚合每个桶中匹配程度最高的文档。简言之,分桶聚合时,热门聚合作为子聚合,用来返回每组头部明细数据。
- size:限制明细数据返回数量。
- sort:指定明细数据的排序字段以及排序方式。
- _source:指定明细数据返回的字段。
GET kibana_sample_data_ecommerce/_search
{"size": 0,"aggs": {"aggs_customer_id": {"terms": {"field": "customer_id","size": 10},"aggs": {"top_hits": {"top_hits": {"size": 2, "_source": {"includes": ["customer_id", "order_date", "products"]},"sort": [{"order_date": {"order": "desc"}} ]}}}}}
}
PUT sales
{"mappings": {"properties": {"tags": { "type": "keyword" },"comments": { "type": "nested","properties": {"username": { "type": "keyword" },"comment": { "type": "text" }}}}}
}
PUT sales/_doc/1?refresh
{"tags": ["car","auto"],"comments": [{"username": "baddriver007","comment": "This car could have better brakes"},{"username": "dr_who","comment": "Where's the autopilot? Can't find it"},{"username": "ilovemotorbikes","comment": "This car has two extra wheels"}]
}
GET sales/_search
{"query": {"term": {"tags": "car"}},"aggs": {"by_sale": {"nested": {"path": "comments"},"aggs": {"by_user": {"terms": {"field": "comments.username","size": 1},"aggs": {"by_nested": {"top_hits": {}}}}}}}
}
top_metrics
即头部指标聚合。可以指定自定义字段与排序规则,按照排序字段的头部数据统计。
- metrics:获取头部指标字段的数值。
- sort:指定头部指标字段的排序规则
- size:限制头部指标返沪的数据条数。默认1,索引限制最多为10,可以修改 index.top_metrics_max_size
e.g. 按照客户分桶统计,在每个桶中按照客户下单日期顺序排序,返回订单中第一条购买的总金额。
GET kibana_sample_data_ecommerce/_search
{"size": 0, "aggs": {"aggs_customer_id": {"terms": {"field": "customer_id","size": 2},"aggs": {"top_metrics_total_price": {"top_metrics": {"metrics": {"field": "taxful_total_price"},"sort": {"order_date": "desc"},"size": 1}}}}}
}
结果输出如下:
{"took" : 14,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4675,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"aggs_customer_id" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 4139,"buckets" : [{"key" : "27","doc_count" : 348,"top_metrics_total_price" : {"top" : [{"sort" : ["2022-08-13T18:38:53.000Z"],"metrics" : {"taxful_total_price" : 79.0}}]}},{"key" : "52","doc_count" : 188,"top_metrics_total_price" : {"top" : [{"sort" : ["2022-08-13T21:41:46.000Z"],"metrics" : {"taxful_total_price" : 75.0}}]}}]}}
}
修改 top metrics 限制
PUT kibana_sample_data_ecommerce/_settings
{"top_metrics_max_size": 100
}
相关文章:

Elasticsearch使用篇 - 指标聚合
指标聚合 指标聚合从聚合文档中提取出指标进行计算。可以从文档的字段或者使用脚本方式进行提取。 聚合统计可以同时返回明细数据,可以分页查询,可以返回总数量。 可以结合查询条件,限制数据范围,结合倒排索引列式存储。 指标…...

Python生命周期及内存管理
文章目录 一、Python的生命周期 1、概念2、如何监听生命周期二、内存管理 1.存储2.垃圾回收3.引用计数一、生命周期: 1、概念:一个对象从创建到消亡的过程 当一个对象呗创建是,会在内存中分配响应的内存空间进行存储 当这个对象不再使…...
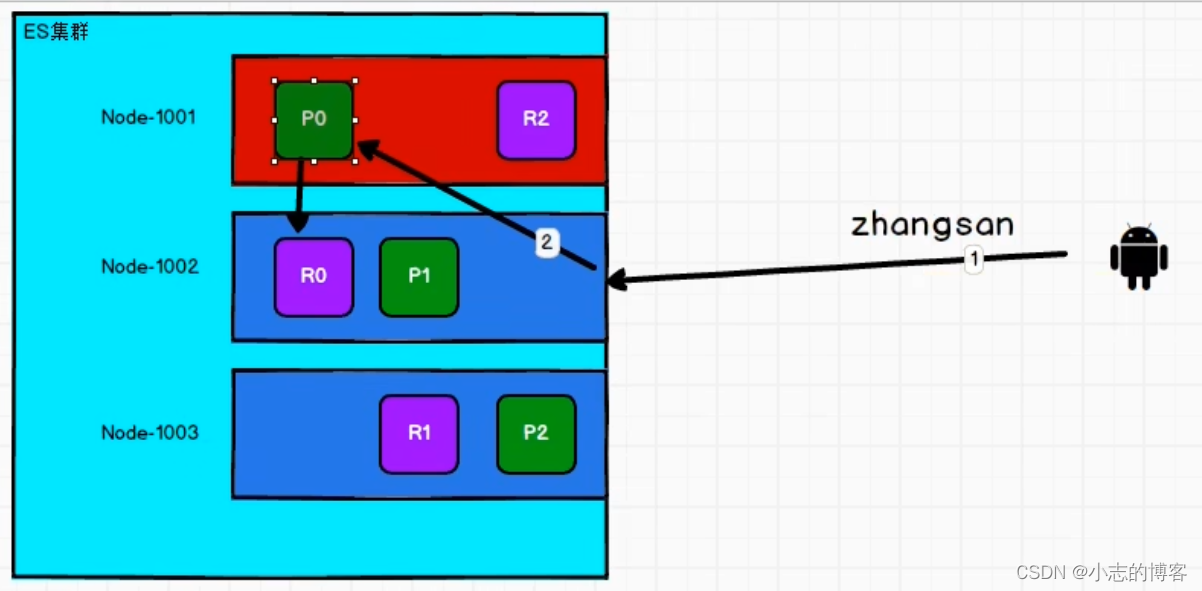
Elasticsearch7.8.0版本进阶——数据写流程
目录一、数据写流程概述二、数据写流程步骤2.1、数据写流程图2.2、数据写流程步骤(新建索引和删除文档所需要的步骤顺序)2.3、数据写流程的请求参数一、数据写流程概述 新建、删除索引和新建、删除文档的请求都是写操作, 必须在主分片上面完…...
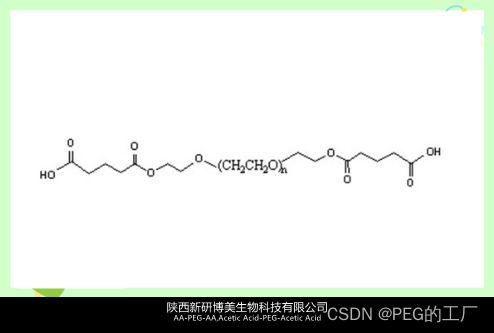
化学试剂Glutaric Acid-PEG-Glutaric Acid,GA-PEG-GA,戊二酸-聚乙二醇-戊二酸
一:产品描述 1、名称 英文:Glutaric Acid-PEG-Glutaric Acid,GA-PEG-GA 中文:戊二酸-聚乙二醇-戊二酸 2、CAS编号:N/A 3、所属分类:Carboxylic acid PEG 4、分子量:可定制, 戊…...

知识图谱业务落地技术推荐之国内知识图谱平台汇总(竞品)[阿里、腾讯、华为等】
各位可以参考国内知识图谱平台产品进行对技术链路搭建和产品参考提供借鉴。...
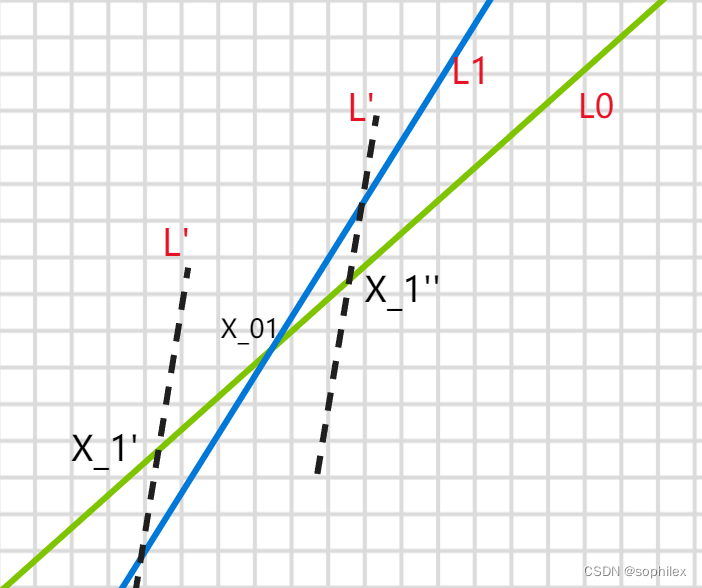
ABC 289 G - Shopping in AtCoder store 数学推导+凸包
大意: n个顾客,每个人有一个购买的欲望bi,m件物品,每一件物品有一个价值ci,每一个顾客会买商品当且仅当bici>定价. 现在要求对每一个商品定价,求出它的最大销售值(数量*定价) n,m<2e5 思路&#x…...

ARM Linux 如何在sysfs用户态命令行中控制 GPIO 引脚?
ARM Linux 如何在sysfs用户态命令行中控制 GPIO 引脚?我们在开发工作中,经常需要确定内核gpio驱动,是否有异常,或者在没有应用的情况下,像控制某个外设,这时我们就可以在控制台命令行中,用命令导…...
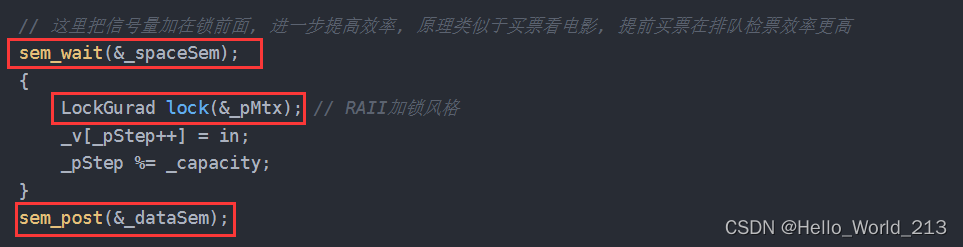
【Linux】生产者消费者模型 - 详解
目录 一.生产者消费者模型概念 1.为何要使用生产者消费者模型 2.生产者消费者之间的关系 3.生产者消费者模型的优点 二.基于阻塞队列的生产消费模型 1.在阻塞队列中的三种关系 2.BlockingQueue.hpp - 阻塞队列类 3.LockGurad.hpp - RAII互斥锁类 4.Task.hpp - 在阻塞队…...

源码深度解析Spring Bean的加载
在应用spring 的过程中,就会涉及到bean的加载,bean的加载经历一个相当复杂的过程,bean的加载入口如下: 使用getBean()方法进行加载Bean,最终调用的是AbstractBeanFactory.doGetBean() 进行Bean的…...
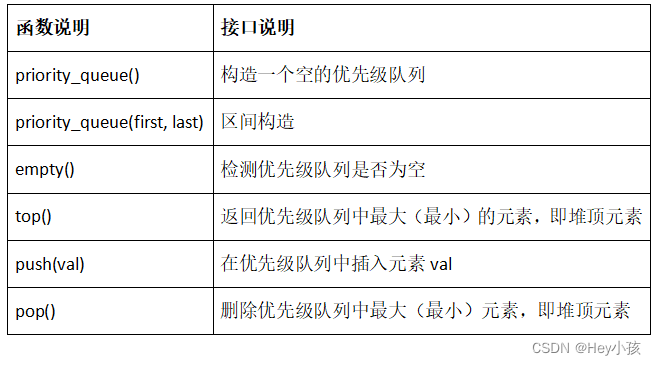
STL——priority_queue
一、priority_queue介绍及使用 1.priority_queue文档介绍 (1)优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的。 (2)此上下文类似与堆,在堆中可以…...
Springboot集成工作流Activity
介绍 官网:https://www.activiti.org/ 一 、工作流介绍 1.工作流(workflow) 就是通过计算机对业务流程自动化执行管理,它主要解决的是“使在多个参与这之间按照某种预定义规则自动化进行传递文档、信息或任务的过程,…...

2023软件测试工程师涨薪攻略,3年如何达到月薪30K?
1.软件测试如何实现涨薪 首先涨薪并不是从8000涨到9000这种涨薪,而是从8000涨到15K加到25K的涨薪。基本上三年之内就可以实现。 如果我们只是普通的有应届毕业生或者是普通本科那我们就只能从小公司开始慢慢往上走。 有些同学想去做测试,是希望能够日…...
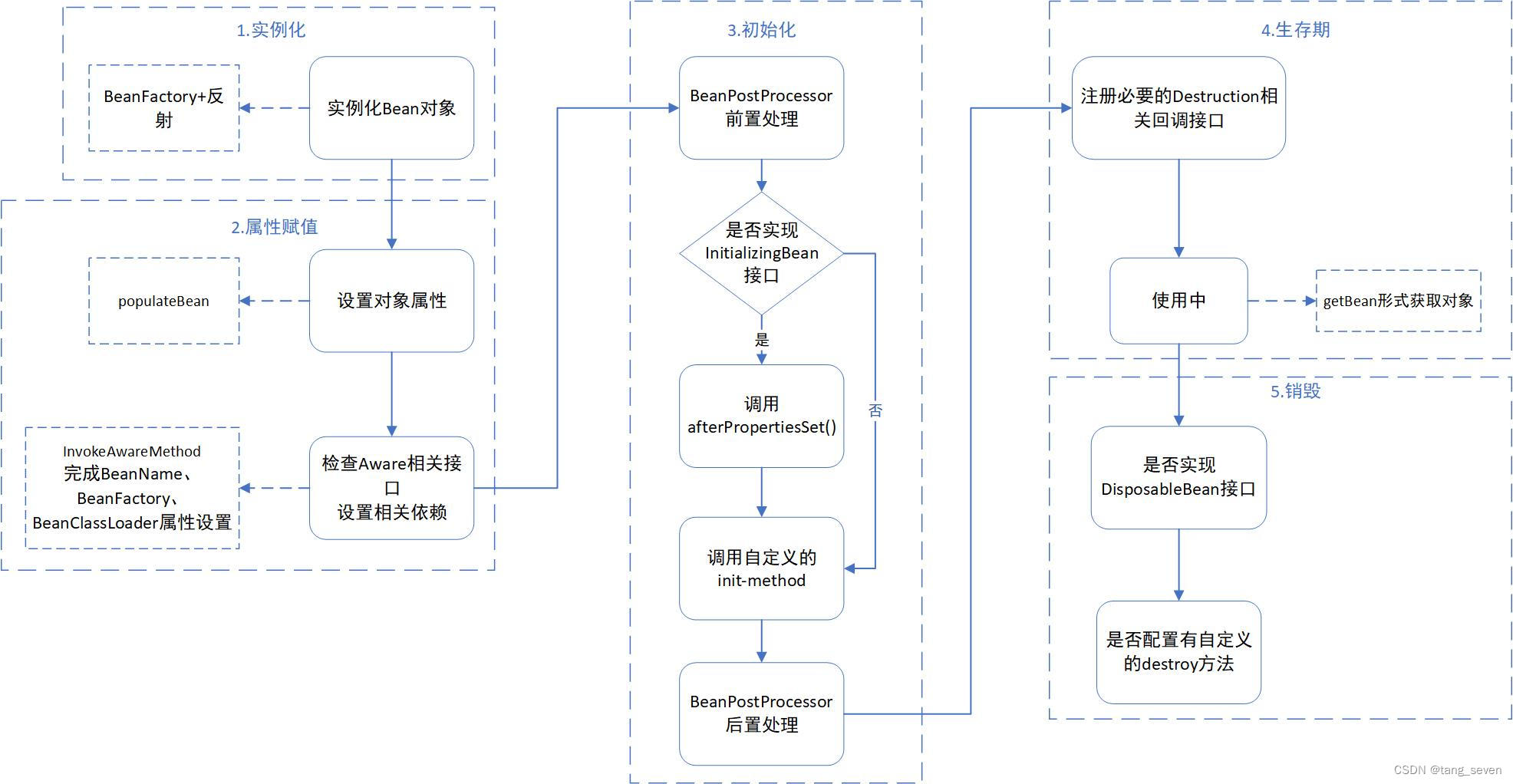
Java面试——Spring Bean相关知识
目录 1.Bean的定义 2.Bean的生命周期 3.BeanFactory及Factory Bean 4.Bean的作用域 5.Bean的线程安全问题 1.Bean的定义 JavaBean是描述Java的软件组件模型。在Java模型中,通过JavaBean可以无限扩充Java程序的功能,通过JavaBean的组合可以快速的生…...

上班在群里摸鱼,逮到一个字节8年测试开发,聊过之后羞愧难当...
老话说的好,这人呐,一旦在某个领域鲜有敌手了,就会闲得某疼。前几天我在上班摸鱼刷群的时候认识了一位字节测试开发大佬,在字节工作了8年,因为本人天赋比较高,平时工作也兢兢业业,现在企业内有一…...
HTTP、WebSocket和Socket.IO
一、HTTP协议 HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)。HTTP 协议和 TCP/IP 协议族内的其他众多的协议相同, 用于客户端和服务器之间的通信。请求访问文本或图像等资源的一端称为客户端, 而提供资源响应的一端称…...

Fluent Python 笔记 第 11 章 接口:从协议到抽象基类
本章讨论的话题是接口:从鸭子类型的代表特征动态协议,到使接口更明确、能验证实现是否符合规定的抽象基类(Abstract Base Class,ABC)。 11.1 Python 文化中的接口和协议 对 Python 程序员来说,“X 类对象”“X 协 议”和“X 接口”都是一个…...

【Spark分布式内存计算框架——Spark Core】11. Spark 内核调度(下)
8.5 Spark 基本概念 Spark Application运行时,涵盖很多概念,主要如下表格: 官方文档:http://spark.apache.org/docs/2.4.5/cluster-overview.html#glossary Application:指的是用户编写的Spark应用程序/代码&#x…...

Java中的函数
1.String.trim() : 主要有2个用法: 1、就是去掉字符串中前后的空白;这个方法的主要可以使用在判断用户输入的密码之类的。 2、它不仅可以去除空白,还可以去除字符串中的制表符,如 ‘\t’,\n等。 2.Integer.parseInt() : 字符串…...

实验6-霍纳法则及变治技术
目录 1.霍纳法则(Horners rule) 2.堆排序 3.求a的n次幂 1.霍纳法则(Horners rule) 【问题描述】用霍纳法则求一个多项式在一个给定点的值 【输入形式】输入三行,第一行是一个整数n,表示的是多项式的最高次数;第二行多项式的系数组P[0...n](从低到高存储);第三行是…...
IP地址:揭晓安欣警官自证清白的黑科技
《狂飙》这部电视剧,此从播出以来可谓是火爆了,想必大家都是看过的。剧中,主人公“安欣”是一名警察。一直在与犯罪分子做斗争。 莽村的李顺案中,有匿名者这个案件在网上发帖恶意造谣,说安欣是黑恶势力的保护伞&#…...

如何快速掌握91160-cli:面向新手的医院全自动挂号完整指南
如何快速掌握91160-cli:面向新手的医院全自动挂号完整指南 【免费下载链接】91160-cli 健康160全自动挂号脚本,捡漏神器 项目地址: https://gitcode.com/gh_mirrors/91/91160-cli 还在为医院挂号难而烦恼吗?91160-cli是一款专为医疗预…...

告别手动下载!3步轻松批量获取网易云音乐FLAC无损音乐
告别手动下载!3步轻松批量获取网易云音乐FLAC无损音乐 【免费下载链接】NeteaseCloudMusicFlac 根据网易云音乐的歌单, 下载flac无损音乐到本地.。 项目地址: https://gitcode.com/gh_mirrors/nete/NeteaseCloudMusicFlac 你是不是也遇到过这样的烦恼&#x…...

终极指南:SpringAll安全框架实战——Shiro与Spring Security权限控制最佳实践
终极指南:SpringAll安全框架实战——Shiro与Spring Security权限控制最佳实践 【免费下载链接】SpringAll 循序渐进,学习Spring Boot、Spring Boot & Shiro、Spring Batch、Spring Cloud、Spring Cloud Alibaba、Spring Security & Spring Secur…...

德尔·考德威尔:从微波校准到计量标准,塑造现代精密测量的隐形基石
1. 一位计量学巨匠的遗产:从德尔考德威尔看精密测量的基石在电子工程与测试测量这个庞大而精密的领域里,我们常常关注的是最新的示波器带宽、最前沿的矢量网络分析技术,或是某个芯片的测试方案。然而,支撑起整个现代工业测量体系可…...

VirtualBox 6.1+ 搭配Win10:除了装系统,这些高效设置让你的虚拟机真正好用起来
VirtualBox 6.1 与Win10深度整合:解锁专业级虚拟化生产力的5个关键策略 当你已经成功在VirtualBox中安装好Windows 10虚拟机,这仅仅是虚拟化旅程的起点。真正的高手懂得如何将这个看似隔离的环境转变为无缝融入日常工作流的生产力引擎。本文将揭示那些鲜…...
)
实测46MB/s!基于FPGA与CY7C68013A的USB 2.0高速数据传输项目实战(附Streamer速率测试方法)
FPGA与CY7C68013A实现USB 2.0高速传输的工程实践 当我们需要在嵌入式系统中实现高速数据传输时,USB 2.0接口因其广泛兼容性和480Mbps的理论带宽成为首选。本文将详细介绍如何基于Siga-S16 FPGA开发板和CY7C68013A芯片构建一个实测传输速率可达46MB/s的高速数据通道…...

基于LangGraph与LLM的对话式BI工具OpenChatBI实战部署指南
1. 项目概述:当自然语言对话遇见数据分析 如果你和我一样,每天都要和数据仓库、BI报表打交道,那你肯定也经历过这样的场景:业务同事跑过来问,“帮我看看过去一周的CTR趋势”,或者“对比一下这两个渠道的转化…...

关于近期裁员潮的思考|AI让生产力爆炸,但也让平庸的公司战略原形毕露
周末闲着无事跟一个传统软件公司的老板聊天讨论,他问了一个非常尖锐的问题,AI时代会把程序员全部替代掉吗?现在各大公司貌似都在规划裁员节流...其实我觉着这轮裁员最扎心的地方,不是 AI 真的坐到了谁的工位上,而是它把…...

Unsloth框架解析:如何用4-bit量化与Triton内核加速大模型微调
1. 项目概述:为什么我们需要一个“不偷懒”的AI训练框架?如果你最近在尝试微调大语言模型,比如Llama、Mistral或者Qwen,大概率已经体会过什么叫“望眼欲穿”。动辄几个小时甚至几天的训练时间,对显存的贪婪吞噬&#x…...

浏览器高阶使用指南:从基础操作到效率系统构建
1. 项目概述:浏览器,远不止是“上网”那么简单“abczsl520/browser-use-skill”这个项目名,乍一看可能会觉得有点“标题党”——浏览器使用技巧?这谁不会啊?点开、输入网址、回车,不就完了吗?如…...