Scala 中生成一个RDD的方法
在 Scala 中,生成 RDD(弹性分布式数据集)的主要方法是通过 SparkContext(或 SparkSession)提供的 API。以下是生成 RDD 的常见方法:
1. 从本地集合创建 RDD
使用 parallelize 方法将本地集合(如 Seq、List、Array 等)转换为 RDD。
val spark = SparkSession.builder.appName("RDD Example").getOrCreate()
val sc = spark.sparkContext// 从本地集合创建 RDD
val data = Seq(1, 2, 3, 4, 5)
val rdd = sc.parallelize(data)// 查看 RDD 内容
rdd.collect().foreach(println)2. 从外部数据源创建 RDD
使用 textFile 方法从外部文件(如 HDFS、本地文件系统等)加载数据生成 RDD。
// 从文本文件创建 RDD
val rdd = sc.textFile("path/to/file.txt")// 从目录中的所有文件创建 RDD
val rdd = sc.textFile("path/to/directory/*")// 从 HDFS 文件创建 RDD
val rdd = sc.textFile("hdfs://path/to/file.txt")3. 从其他 RDD 转换生成新的 RDD
通过对现有 RDD 进行转换操作(如 map、filter、flatMap 等)生成新的 RDD。
val rdd1 = sc.parallelize(Seq(1, 2, 3, 4, 5))// 使用 map 转换生成新的 RDD
val rdd2 = rdd1.map(x => x * 2)// 使用 filter 转换生成新的 RDD
val rdd3 = rdd1.filter(x => x % 2 == 0)// 使用 flatMap 转换生成新的 RDD
val rdd4 = rdd1.flatMap(x => Seq(x, x * 10))4. 从 Hadoop 输入格式创建 RDD
使用 newAPIHadoopFile 或 hadoopFile 方法从 Hadoop 支持的文件格式(如 SequenceFile、Avro 等)创建 RDD。
import org.apache.hadoop.io.{Text, LongWritable}
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat// 从 Hadoop 文件创建 RDD
val rdd = sc.newAPIHadoopFile[LongWritable, Text, TextInputFormat]("path/to/hadoop/file"
)5. 从 DataFrame 或 Dataset 转换为 RDD
通过调用 .rdd 方法将 DataFrame 或 Dataset 转换为 RDD。
import spark.implicits._val df = Seq(("Alice", 25), ("Bob", 30)).toDF("name", "age")// 将 DataFrame 转换为 RDD
val rdd = df.rdd// 将 Dataset 转换为 RDD
val ds = df.as[(String, Int)]
val rdd = ds.rdd6. 使用 range 方法生成数值序列 RDD
使用 range 方法生成一个包含连续数值的 RDD。
// 生成一个包含 1 到 10 的 RDD
val rdd = sc.range(1, 10)7. 从空集合创建 RDD
使用 emptyRDD 方法创建一个空的 RDD。
// 创建一个空的 RDD
val rdd = sc.emptyRDD[Int]8. 从键值对数据创建 RDD
使用 parallelize 方法创建包含键值对的 RDD。
val data = Seq(("a", 1), ("b", 2), ("c", 3))
val rdd = sc.parallelize(data)9. 从分区函数创建 RDD
使用 makeRDD 方法通过指定分区函数创建 RDD。
val rdd = sc.makeRDD(Seq(1, 2, 3, 4, 5), numSlices = 2)10. 从数据库或其他数据源创建 RDD
通过自定义逻辑从数据库、API 或其他数据源读取数据并生成 RDD。
val data = // 从数据库或其他数据源读取数据
val rdd = sc.parallelize(data)总结
生成 RDD 的主要方法包括:
-
从本地集合创建(
parallelize) -
从外部文件创建(
textFile) -
从现有 RDD 转换生成
-
从 Hadoop 文件格式创建
-
从 DataFrame/Dataset 转换
-
使用
range生成数值序列 -
创建空 RDD(
emptyRDD) -
从键值对数据创建
-
使用分区函数创建(
makeRDD) -
从数据库或其他数据源创建
根据具体需求选择合适的方法生成 RDD。
相关文章:

Scala 中生成一个RDD的方法
在 Scala 中,生成 RDD(弹性分布式数据集)的主要方法是通过 SparkContext(或 SparkSession)提供的 API。以下是生成 RDD 的常见方法: 1. 从本地集合创建 RDD 使用 parallelize 方法将本地集合(如…...
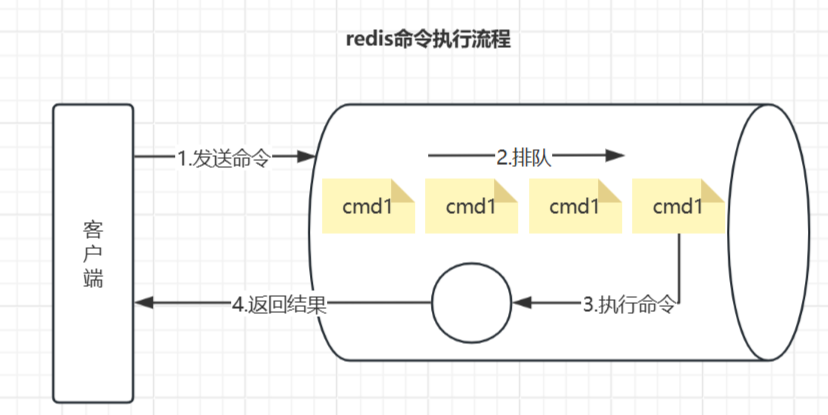
【redis】慢查询分析与优化
慢查询指在Redis中执行时间超过预设阈值的命令,其日志记录是排查性能瓶颈的核心工具。Redis采用单线程模型,任何耗时操作都可能阻塞后续请求,导致整体性能下降。 命令的执行流程 根据Redis的核心机制,命令执行流程可分为以下步骤…...

P8925 「GMOI R1-T2」Light 题解
P8925 「GMOI R1-T2」Light 让我们好好观察样例解释的这一张图: 左边第 1 1 1 个像到 O O O 点的距离 : L 2 2 L L\times22L L22L 右边第 1 1 1 个像到 O O O 点的距离 : R 2 2 R R\times22R R22R 左边第 2 2 2 个像到 O O O 点…...

Spring Boot + MyBatis + MySQL:快速搭建CRUD应用
一、引言 1. 项目背景与目标 在现代Web开发中,CRUD(创建、读取、更新、删除)操作是几乎所有应用程序的核心功能。本项目旨在通过Spring Boot、MyBatis和MySQL技术栈,快速搭建一个高效、简洁的CRUD应用。我们将从零开始ÿ…...

python中os库的常用举例
os 库是Python中用于与操作系统进行交互的标准库,以下是一些 os 库的常用示例: 获取当前工作目录 python import os current_dir os.getcwd() print(current_dir) os.getcwd() 函数用于获取当前工作目录的路径。 列出目录内容 python import os …...

Unity 通用UI界面逻辑总结
概述 在游戏开发中,常常会遇到一些通用的界面逻辑,它不论在什么类型的游戏中都会出现。为了避免重复造轮子,本文总结并提供了一些常用UI界面的实现逻辑。希望可以帮助大家快速开发通用界面模块,也可以在次基础上进行扩展修改&…...

Python3 与 VSCode:深度对比分析
Python3 与 VSCode:深度对比分析 引言 Python3 和 Visual Studio Code(VSCode)在软件开发领域扮演着举足轻重的角色。Python3 作为一门强大的编程语言,拥有丰富的库和框架,广泛应用于数据科学、人工智能、网络开发等多个领域。而 VSCode 作为一款轻量级且功能强大的代码…...

第五课:Express框架与RESTful API设计:技术实践与探索
在使用Node.js进行企业应用开发,常用的开发框架Express,其中的中间件、路由配置与参数解析、RESTful API核心技术尤为重要,本文将深入探讨它们在应用开发中的具体使用方法,最后通过Postman来对开发的接口进行测试。 一、Express中…...

Linux 内核自定义协议族开发:从 “No buffer space available“ 错误到解决方案
引言 在 Linux 内核网络协议栈开发中,自定义协议族(Address Family, AF)是实现新型通信协议或扩展内核功能的关键步骤。然而,开发者常因对内核地址族管理机制理解不足,遇到如 insmod: No buffer space available 的错误。本文将以实际案例为基础,深入分析错误根源,并提…...

html-列表标签和表单标签
一、列表标签 表格是用来显示数据的,那么列表就是用来布局的 列表最大的特点就是整齐、整洁、有序,它作为布局会更加自由和方便。 根据使用情景不同,列表可以分为三大类:无序列表、有序列表和自定义列表。 1.无序列表(重…...

HTML-网页介绍
一、网页 1.什么是网页: 网站是指在因特网上根据一定的规则,使用 HTML 等制作的用于展示特定内容相关的网页集合。 网页是网站中的一“页”,通常是 HTML 格式的文件,它要通过浏览器来阅读。 网页是构成网站的基本元素…...

动态ip和静态ip适用于哪个场景?有何区别
在数字化浪潮席卷全球的今天,IP地址作为网络世界的“门牌号”,其重要性不言而喻。然而,面对动态IP与静态IP这两种截然不同的IP分配方式,许多用户往往感到困惑:它们究竟有何区别?又分别适用于哪些场景呢&…...

android13打基础: 保存用户免得下次重新登录逻辑
使用SP来做 创建LoginUser.kt // 登录用户需要Email data class LoginUser(val email: String,val password: String, )创建假数据FakeLoginUser.kt object FakeLoginUser {val fake_login_user_items arrayListOf(LoginUser(email "1690544550qq.com",password …...

Linux 4.4 内核源码的目录结构及其主要内容的介绍
以下是 Linux 4.4 内核源码的目录结构及其主要内容的介绍,适用于理解内核模块和驱动开发的基本框架: Linux 4.4 内核源码目录结构 目录作用与内容arch/平台架构相关代码每个子目录对应一种 CPU 架构(如 x86/、arm/、arm64/),包含硬件相关的启动逻辑、中断处理、内存管理等…...

手脑革命:拆解Manus AI如何用“执行智能体”重构生产力——中国团队突破硅谷未竟的技术深水区
第一章:Manus AI 的技术演进与行业背景 1.1 从工具到智能体:AI 技术的范式跃迁 人工智能的发展经历了从规则驱动(Rule-based)到统计学习(Statistical Learning),再到深度学习(Deep…...

Android 调用c++报错 exception of type std::bad_alloc: std::bad_alloc
一、报错信息 terminating with uncaught exception of type std::bad_alloc: std::bad_alloc 查了那部分报错c++代码 szGridSize因为文件太大,初始化溢出了 pEGM->pData = new float[szGridSize]; 解决办法 直接抛出异常,文件太大就失败吧 最后还增加一个日志输出,给…...

匿名GitHub链接使用教程(Anonymous GitHub)2025
Anonymous GitHub 1. 引言2. 准备3. 进入Anonymous GitHub官网4. 用GitHub登录匿名GitHub并授权5. 进入个人中心,然后点击• Anonymize Repo实例化6. 输入你的GitHub链接7. 填写匿名链接的基础信息8. 提交9. 实例化对应匿名GitHub链接10. 进入个人中心管理项目11. 查…...

【0基础跟AI学软考高项】成本管理
💰「成本管理」是什么? 一句话解释:像家庭装修控制预算,既要买得起好材料,又要避免超支吃泡面——成本管理就是精准算钱、合理花钱、动态盯钱,保证项目不破产! 🌋 真实案例…...

模型的原始输出为什么叫 logits
模型的原始输出为什么叫 logits flyfish 一、Logarithm(对数 log) 定义:对数是指数运算的逆运算,表示某个数在某个底数下的指数。 公式:若 b x a b^x a bxa,则 log b ( a ) x \log_b(a) x logb…...

[SAP MM] 查看物料主数据的物料类型
创建物料主数据时,必须为物料分配物料类型,如原材料或半成品 在标准系统中,物料类型ROH(原材料)的所有物料都要从外部采购,而类型为NLAG(非库存物料)的物料则可从外部采购也可在内部生产 ① 特殊物料类型:NLAG 该物料…...

Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器
Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 还在为复杂的Steam游戏清单下载而头疼吗?想要备份游戏资源却不…...
上午题回忆与解析(非标答版))
2026上半年数据库系统工程师(软考)上午题回忆与解析(非标答版)
本文为考后回忆整理,非官方标准答案,旨在为考后对答案及下半年备考的同学提供参考。题目顺序和表述可能与原卷有出入,欢迎在评论区指正、补充。📊 整体考情分析 刚结束的2026年上半年数据库系统工程师考试,上午题的风格…...

CANoe诊断测试没CDD文件怎么办?手把手教你用Fault Memory窗口和CAPL脚本读取解析DTC故障码
CANoe诊断测试无CDD文件的实战解决方案:从Fault Memory到CAPL脚本全解析当CDD文件缺失或定义不清晰时,诊断测试工程师常常陷入困境。本文将深入探讨如何利用Fault Memory窗口的基础功能,并通过CAPL脚本实现更灵活、更强大的故障码读取与解析方…...

LizzieYzy:你的智能围棋教练,让AI分析变得简单有趣 [特殊字符]
LizzieYzy:你的智能围棋教练,让AI分析变得简单有趣 🎯 【免费下载链接】lizzieyzy LizzieYzy - GUI for Game of Go 项目地址: https://gitcode.com/gh_mirrors/li/lizzieyzy 还在为复盘找不到关键点而烦恼吗?想提升棋力却…...

通过用量看板分析团队大模型API消耗发现优化调用策略的机会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析团队大模型API消耗发现优化调用策略的机会 作为团队的技术负责人,确保大模型API调用在满足业务需求的…...
)
别再只用鼠标了!用Leap Motion手势控制Unity游戏,保姆级配置避坑指南(2024版)
2024年Unity手势交互开发实战:Leap Motion从配置到游戏逻辑全解析在游戏开发领域,交互方式的创新往往能带来全新的体验。想象一下,玩家不再需要键盘鼠标,仅凭自然的手部动作就能操控游戏角色——这正是Leap Motion手势识别技术为U…...

通过Taotoken实现Hermes Agent自定义模型供应商接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken实现Hermes Agent自定义模型供应商接入 Hermes Agent是一个流行的AI智能体开发框架,它支持通过配置自定义…...

应对Claude Code访问不稳定,快速切换至Taotoken的应急方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 应对Claude Code访问不稳定,快速切换至Taotoken的应急方案 对于依赖Claude Code进行日常开发或自动化任务的用户来说&a…...

Python到Android的魔法之旅:5步将你的代码变成移动应用
Python到Android的魔法之旅:5步将你的代码变成移动应用 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android 想象一下,你花了几个月时间精心…...

如何用嘎嘎降AI处理金融学论文:金融学毕业论文降AI4.8元完整操作教程
如何用嘎嘎降AI处理金融学论文:金融学毕业论文降AI4.8元完整操作教程 第一次用降AI工具有很多不确定——传什么格式、选哪个模式、怎么验收。 这篇教程把金融学论文降AI教程的常见问题都覆盖了,主要基于嘎嘎降AI(www.aigcleaner.com&#x…...