自然语言处理:高斯混合模型
介绍
大家好,博主又来给大家分享知识了,今天给大家分享的内容是自然语言处理中的高斯混合模型。
在自然语言处理这个充满挑战与机遇的领域,我们常常面临海量且复杂的文本数据。如何从这些数据中挖掘出有价值的信息,对文本进行有效的分类、聚类等操作,一直是研究人员和从业者努力攻克的难题。而高斯混合模型,就像是一把神奇的钥匙,为我们打开了一扇深入理解和处理文本数据的新大门。
高斯混合模型,英文简称为GMM(Gaussian Mixture Model)。它并不是一个单一的模型,而是多个高斯分布的巧妙组合。好了,话不多说,我们直接进入正题。
高斯混合模型
在自然语言处理(NLP)的复杂领域中,对文本数据进行精准建模和有效分析是实现诸多任务的关键,如文本分类、情感分析、主题模型构建等。高斯混合模型(Gaussian Mixture Model,GMM)作为一种强大的概率模型,在自然语言处理中发挥着独特且重要的作用。它能够通过对数据分布的拟合,挖掘文本数据中的潜在结构和特征。
基础概念
高斯分布
又叫正态分布,高斯分布是一种常见的概率分布,在自然界和许多领域都有广泛应用。其概率密度函数为:
其中,是均值,决定了分布的中心位置;
是方差,控制了分布的离散程度。例如,在学生考试成绩的分布中,成绩往往呈现出以平均成绩为中心,向两侧逐渐分散的趋势,这就近似符合高斯分布。在自然语言处理中,我们可以将文本的某些特征(如词频分布等)看作是符合高斯分布的变量。
高斯混合模型
高斯混合模型是由多个高斯分布组合而成的概率模型。假设存在 个高斯分布,每个高斯分布都有自己的均值
、方差
和权重
。那么,高斯混合模型的概率密度函数可以表示为:
直观地理解,高斯混合模型可以看作是多个高斯分布的“混合体”,每个高斯分布代表了数据中的一种潜在模式。在文本处理中,不同的高斯分布可以对应不同主题的文本,比如一个高斯分布代表科技类文本,另一个代表娱乐类文本等。通过对文本特征的建模,高斯混合模型能够将文本按照不同的潜在主题进行聚类。
期望最大化算法
期望最大化(Expectation - Maximization,EM)算法用于训练高斯混合模型(Gaussian Mixture Model,GMM),是借助EM算法来确定GMM中的参数,使得模型能够尽可能准确地拟合给定的数据。
期望最大化(EM)算法是训练高斯混合模型的常用方法。它是一个迭代的过程,主要包含两个步骤:
E步(期望步骤):根据当前模型参数(均值、方差和权重),计算每个数据点属于每个高斯分布的概率,即后验概率。这里
表示数据点属于第
个高斯分布,
是第
个数据点。通过贝叶斯公式计算:
M步(最大化步骤):利用E步计算得到的后验概率,更新模型的参数(均值、方差和权重)。
- 权重更新公式:
- 均值更新公式:
- 方差更新公式:
通过不断迭代E步和M步,直到模型参数收敛(即参数的变化小于某个预设的阈值),就可以得到一组相对较优的模型参数,从而完成高斯混合模型的训练。
代码实现
我们实现一个基于Python的高斯混合模型(Gaussian Mixture Model, GMM)的测试代码。高斯混合模型是一种用于对数据进行概率密度估计和聚类的强大工具,它假设数据是由多个高斯分布混合而成的。
完整代码
# 导入os模块,用于与操作系统进行交互,比如设置环境变量等操作
import os
# 导入numpy库,别名np,用于进行高效的数值计算和数组操作
import numpy as np
# 导入matplotlib库,用于绘制图形和可视化数据
import matplotlib# 设置matplotlib的后端为tkAgg,这是一种图形用户界面后端,用于显示图形窗口
matplotlib.use('tkAgg')
# 定义一个字典config,用于设置matplotlib的字体和符号显示配置
config = {"font.family": 'serif', # 设置字体族为衬线字体"mathtext.fontset": 'stix', # 设置数学文本的字体集为stix"font.serif": 'SimSun', # 设置衬线字体为宋体'axes.unicode_minus': False # 解决负号显示问题
}
# 使用update方法将配置字典应用到matplotlib的全局参数中
matplotlib.rcParams.update(config)
# 从matplotlib中导入pyplot子模块,别名plt,用于绘制各种图形
import matplotlib.pyplot as plt
# 从sklearn库的mixture模块中导入GaussianMixture类,用于实现高斯混合模型
from sklearn.mixture import GaussianMixture# 定义一个名为GaussianMixtureClustering的类,用于实现高斯混合模型聚类
class GaussianMixtureClustering:# 类的初始化方法,用于设置类的属性初始值def __init__(self, random_seed=50, n_components=2, figsize=(10, 6)):# 初始化随机数种子,保证每次运行代码时生成的随机数相同,便于结果复现self.random_seed = random_seed# 初始化高斯分布的数量,即高斯混合模型中包含的高斯分量的个数self.n_components = n_components# 初始化图形窗口的大小,单位为英寸self.figsize = figsize# 初始化数据集,用于存储生成的样本数据self.X = None# 初始化高斯混合模型对象,后续用于模型训练和预测self.gmm = None# 初始化预测的类别标签,用于存储模型对数据的分类结果self.labels = None# 定义生成数据的方法,用于创建符合特定分布的数据集def generate_data(self):# 设置随机数种子,确保每次运行生成的数据相同np.random.seed(self.random_seed)# 生成100个符合二维多元正态分布的数据点,均值为 [0, 0],协方差矩阵为 [[1, 0], [0, 1]]X1 = np.random.multivariate_normal(mean=[0, 0], cov=[[1, 0], [0, 1]], size=100)# 生成100个符合二维多元正态分布的数据点,均值为 [5, 5],协方差矩阵为 [[1, 0], [0, 1]]X2 = np.random.multivariate_normal(mean=[5, 5], cov=[[1, 0], [0, 1]], size=100)# 将X1和X2这两个数组在垂直方向上堆叠,形成一个新的数据集Xself.X = np.vstack([X1, X2])# 定义训练模型的方法,使用生成的数据集对高斯混合模型进行训练def train_model(self):# 创建一个GaussianMixture模型对象,设置高斯分布的数量为初始化时指定的值self.gmm = GaussianMixture(n_components=self.n_components)# 使用数据集X对高斯混合模型进行训练,让模型学习数据的分布特征self.gmm.fit(self.X)# 定义预测标签的方法,使用训练好的模型对数据集进行预测def predict_labels(self):# 使用训练好的高斯混合模型对数据集X进行预测,得到每个数据点所属的类别标签self.labels = self.gmm.predict(self.X)# 定义可视化结果的方法,将聚类结果以图形的形式展示出来def visualize_results(self):# 创建一个新的图形窗口,设置窗口的大小为初始化时指定的值plt.figure(figsize=self.figsize)# 绘制散点图,将数据集X的第一列作为x轴坐标,第二列作为y轴坐标# 用标签labels来确定每个点的颜色,使用viridis颜色映射,点的大小为50,边缘颜色为黑色plt.scatter(self.X[:, 0], self.X[:, 1], c=self.labels, cmap='viridis', s=50, edgecolor='k')# 获取高斯混合模型中每个高斯分布的均值means = self.gmm.means_# 绘制每个高斯分布的均值点,颜色为红色,大小为200,标记形状为Xplt.scatter(means[:, 0], means[:, 1], c='red', s=200, marker='X')# 设置图形的标题为'高斯混合模型聚类'plt.title('高斯混合模型聚类')# 设置x轴的标签为'特征 1'plt.xlabel('特征1')# 设置y轴的标签为'特征 2'plt.ylabel('特征2')# 显示绘制好的图形plt.show()# 定义运行方法,依次调用生成数据、训练模型、预测标签和可视化结果的方法def run(self):# 调用generate_data方法生成数据集self.generate_data()# 调用train_model方法对模型进行训练self.train_model()# 调用predict_labels方法进行标签预测self.predict_labels()# 调用visualize_results方法可视化聚类结果self.visualize_results()# 主程序入口,确保代码作为脚本直接运行时才会执行以下代码
if __name__ == "__main__":# 设置环境变量LOKY_MAX_CPU_COUNT为4,用于限制并行计算时使用的CPU核心数os.environ['LOKY_MAX_CPU_COUNT'] = '4'# 创建GaussianMixtureClustering类的实例,使用默认参数clustering = GaussianMixtureClustering()# 调用实例的run方法,执行整个聚类流程clustering.run()运行结果
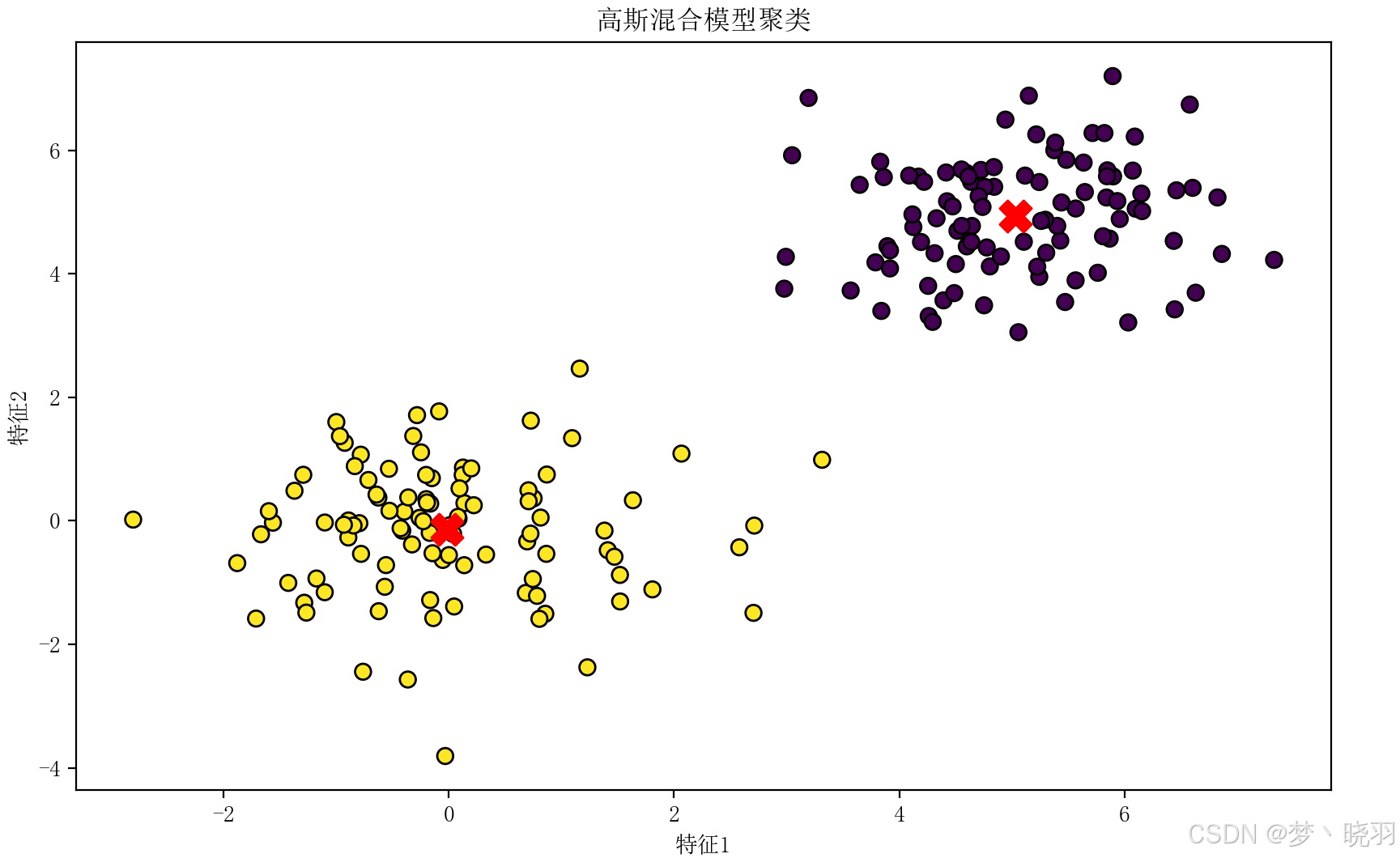
代码使用Python中的sklearn库实现高斯混合模型,并对生成的模拟数据进行聚类分析。通过这个代码,我们可以直观地看到高斯混合模型是如何对数据进行建模和聚类的,同时也能了解如何使用 sklearn库中的GaussianMixture类来完成这一任务。
通过运行这个代码,我们可以看到高斯混合模型是如何对数据进行聚类的,并且可以直观地看到每个高斯分布的中心位置。在实际项目中,高斯混合模型可用于数据聚类、异常检测、密度估计等任务。通过这个代码示例,我们可以将其作为一个基础模板,应用到更复杂的实际问题中。
模型优点
- 强大的建模能力:高斯混合模型能够灵活地拟合各种复杂的数据分布。由于它是多个高斯分布的组合,对于具有多模态分布的数据(如包含多种主题的文本数据),可以很好地捕捉不同模式之间的差异,相比单一的高斯分布模型,具有更强的表达能力。
- 无监督学习优势:作为一种无监督学习模型,高斯混合模型不需要预先标记的数据,能够自动从数据中发现潜在的结构和模式。在自然语言处理中,这一特性非常适合用于文本聚类任务,帮助我们在没有人工标注的情况下,将文本按照主题等特征进行分类,节省了大量的人力成本。
- 理论基础完善:高斯混合模型基于概率论和数理统计的理论,具有坚实的数学基础。其训练过程使用的期望最大化算法有严格的数学推导和收敛性证明,使得模型的训练和优化过程更加可靠和可解释。
模型缺点
- 对超参数敏感:高斯混合模型的性能很大程度上依赖于超参数的选择,如高斯分布的数量 K、协方差类型等。在实际应用中,选择合适的超参数并不容易,不同的超参数设置可能会导致截然不同的聚类结果。如果 K 设置不当,可能会出现聚类不足或过度聚类的问题。
- 计算复杂度较高:在训练过程中,尤其是当数据量较大或者高斯分布数量较多时,期望最大化算法的计算量会显著增加。每次迭代都需要计算每个数据点属于每个高斯分布的后验概率,以及更新模型的参数,这对于大规模文本数据处理来说,计算成本较高,可能会影响算法的效率。
- 模型可解释性受限:虽然高斯混合模型有一定的数学理论基础,但当高斯分布数量较多时,模型的结构会变得复杂,难以直观地解释每个高斯分布所代表的实际意义。在文本聚类中,可能难以清晰地阐述每个聚类所对应的主题,不利于对结果的深入理解和分析。
结论赋能
高斯混合模型作为自然语言处理中的一种重要模型,凭借其强大的建模能力和无监督学习的优势,在文本聚类等任务中发挥着重要作用。它能够自动挖掘文本数据中的潜在结构,为文本分析提供有价值的信息。
然而,其对超参数的敏感性、较高的计算复杂度以及可解释性受限等问题,也限制了它在某些场景下的应用。在实际使用中,需要根据具体的文本数据特点和任务需求,谨慎选择高斯混合模型,并结合其他技术(如特征选择、模型融合等)来弥补其不足,以实现更高效、更准确的自然语言处理任务。
结束
好了,以上就是本次分享的全部内容了,希望大家通过这次分享,对高斯混合模型在自然语言处理中的应用有了更多的理解。
我们知道了高斯分布在生活中随处可见,而高斯混合模型巧妙地将多个高斯分布组合起来,为我们处理复杂的文本数据提供了有力工具。通过期望最大化算法训练模型,不断调整参数,让模型能够更好地拟合数据,实现文本的聚类等任务。
所以在今后的学习和实践中,如果遇到自然语言处理的相关任务,比如文本聚类、情感分析等,大家可以考虑使用高斯混合模型,但要根据实际情况合理选择超参数,并结合其他技术来提升模型性能。如果在应用过程中遇到超参数选择的难题,可以尝试不同的取值进行实验,观察模型的表现;面对计算复杂度高的问题,可以优化数据处理流程,或者采用分布式计算的方式。而对于模型可解释性差的情况,可借助可视化工具或者结合领域知识来辅助理解。
那么本次分享就到这里了。最后,博主还是那句话:请大家多去大胆的尝试和使用,成功总是在不断的失败中试验出来的,敢于尝试就已经成功了一半。如果大家对博主分享的内容感兴趣或有帮助,请点赞和关注。大家的点赞和关注是博主持续分享的动力🤭,博主也希望让更多的人学习到新的知识。
相关文章:
自然语言处理:高斯混合模型
介绍 大家好,博主又来给大家分享知识了,今天给大家分享的内容是自然语言处理中的高斯混合模型。 在自然语言处理这个充满挑战与机遇的领域,我们常常面临海量且复杂的文本数据。如何从这些数据中挖掘出有价值的信息,对文本进行有…...
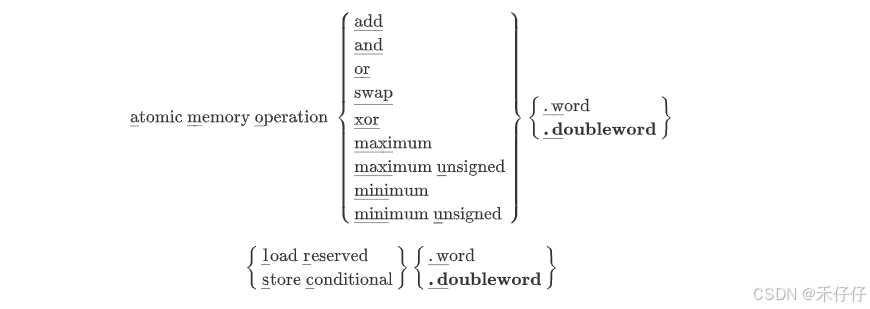
RISC-V汇编学习(三)—— RV指令集
有了前两节对于RISC-V汇编、寄存器、汇编语法等的认识,本节开始介绍RISC-V指令集和伪指令。 前面说了RISC-V的模块化特点,是以RV32I为作为ISA的核心模块,其他都是要基于此为基础,可以这样认为:RISC-V ISA 基本整数指…...
OpenCV连续数字识别—可运行验证
前言 文章开始,瞎说一点其他的东西,真的是很离谱,找了至少两三个小时,就一个简单的需求: 1、利用OpenCV 在Windows进行抓图 2、利用OpenCV 进行连续数字的检测。 3、使用C,Qt 3、将检测的结果显示出来 …...

Python中与字符串操作相关的30个常用函数及其示例
以下是Python中与字符串操作相关的30个常用函数及其示例: 1. str.capitalize() 将字符串的第一个字符大写,其余字符小写。 s "hello world" print(s.capitalize()) # 输出: Hello world2. str.lower() 将字符串中的所有字符转换为小写。…...
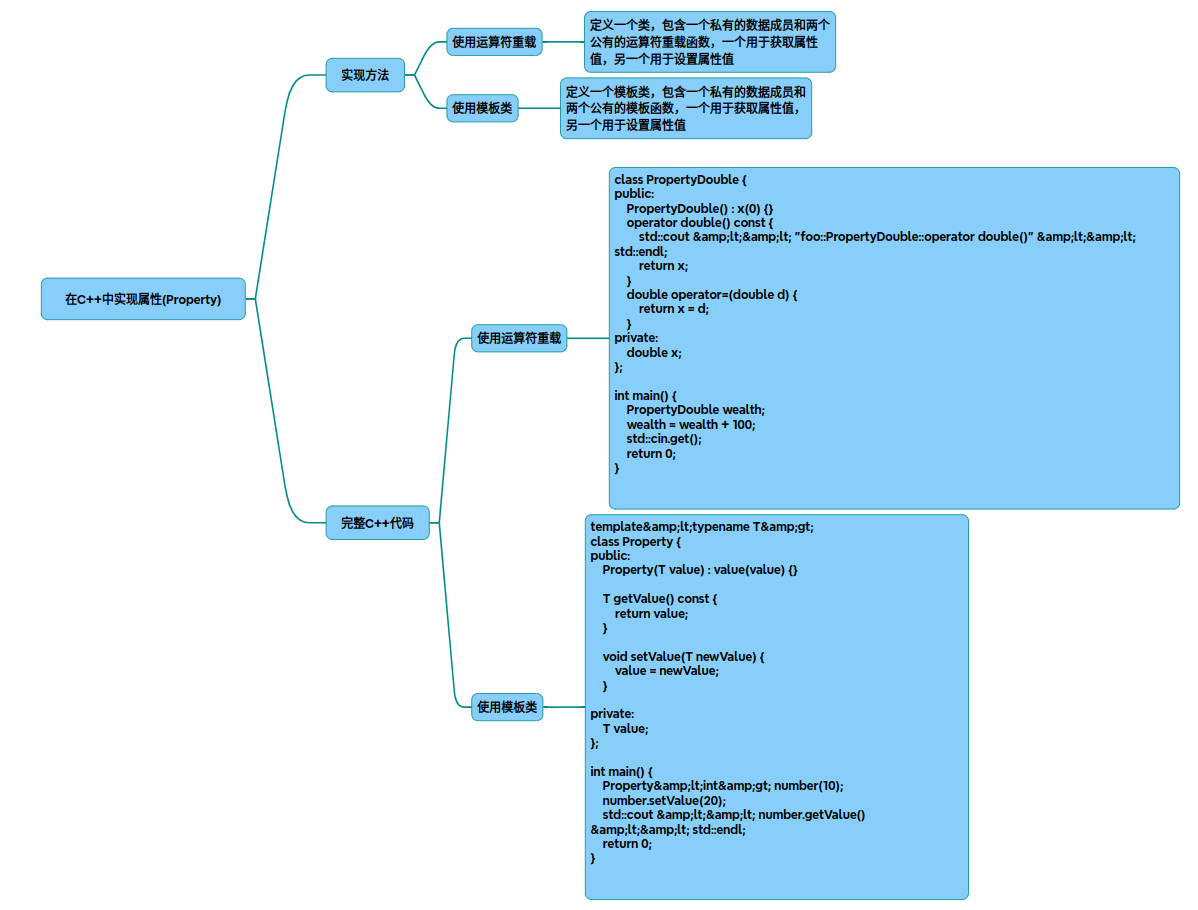
007-Property在C++中的实现与应用
Property在C中的实现与应用 以下是在C中实现属性(Property)的完整实现方案,结合模板技术和运算符重载实现类型安全的属性访问,支持独立模块化封装: #include <iostream> #include <functional>template<typename HostType, t…...

【实战篇】【DeepSeek 全攻略:从入门到进阶,再到高级应用】
凌晨三点,某程序员在Stack Overflow上发出灵魂拷问:“为什么我的DeepSeek会把财务报表生成成修仙小说?” 这个魔性的AI工具,今天我们就来场从开机键到改造人类文明的硬核教学。(文末含高危操作集锦,未成年人请在师父陪同下观看) 一、萌新村任务:把你的电脑变成炼丹炉 …...

clickhouse属于国产吗
《ClickHouse:探索其背景与国内的应用实例》 当我们谈论数据库技术时,ClickHouse是一个绕不开的话题。很多人可能会好奇,ClickHouse是否属于国产软件呢?答案是,虽然ClickHouse最初并非在中国开发,但这款列…...
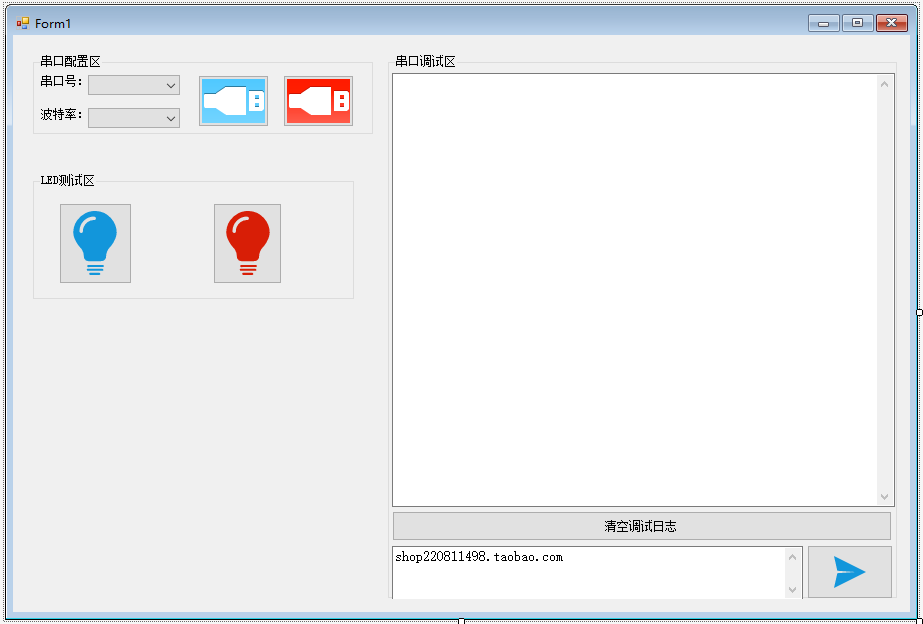
ESP32 UART select解析json数据,上位机控制LED灯实验
前言: 本实验的目的主要是通过上位机通过UART来控制ESP32端的LED的点亮以及熄灭,整个项目逻辑比较简单,整体架构如下: 上位机(PC)主要是跑在PC端的一个软件,主要作用包含: 1)串口相关配置&…...

K8S 集群搭建——cri-dockerd版
目录 一、工作准备 1.配置主机名 2.配置hosts解析 3.配置免密登录(只需要在master上操作) 4.时间同步(每台节点都要做,必做,否则可能会因为时间不同步导致集群初始化失败) 5.关闭系统防火墙 6.配置…...

基于Python的电商销售数据分析与可视化系统实
一、系统架构设计 1.1系统流程图 #mermaid-svg-Pdo9oZWrVHNuOoTT {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-Pdo9oZWrVHNuOoTT .error-icon{fill:#552222;}#mermaid-svg-Pdo9oZWrVHNuOoTT .error-text{fill:#5…...

学习笔记:Python网络编程初探之基本概念(一)
一、网络目的 让你设备上的数据和其他设备上进行共享,使用网络能够把多方链接在一起,然后可以进行数据传递。 网络编程就是,让在不同的电脑上的软件能够进行数据传递,即进程之间的通信。 二、IP地址的作用 用来标记唯一一台电脑…...

高效处理 List<T> 集合:更新、查找与优化技巧
引言 在日常开发中,List<T> 是我们最常用的数据结构之一。无论是批量更新数据、查找特定项还是进行复杂的集合操作,掌握 List<T> 的高级用法可以显著提高代码的效率和可读性。本文将详细介绍如何使用 List<T> 进行批量更新、查找匹配项以及优化性能的方法…...

HTML5(Web前端开发笔记第一期)
p.s.这是萌新自己自学总结的笔记,如果想学习得更透彻的话还是请去看大佬的讲解 目录 三件套标签标题标签段落标签文本格式化标签图像标签超链接标签锚点链接默认链接地址 音频标签视频标签 HTML基本骨架综合案例->个人简介列表表格表单input标签单选框radio上传…...
)
Windows控制台函数:标准输入输出流交互函数GetStdHandle()
目录 什么是 GetStdHandle? 它长什么样? 怎么用它? 它跟 std::cout 有什么不一样? GetStdHandle 是一个 Windows API 函数,用于获取标准输入、标准输出或标准错误设备的句柄。它定义在 Windows 的核心头文件 <…...

Vue3 中 Computed 用法
Computed 又被称作计算属性,用于动态的根据某个值或某些值的变化,来产生对应的变化,computed 具有缓存性,当无关值变化时,不会引起 computed 声明值的变化。 产生一个新的变量并挂载到 vue 实例上去。 vue3 中 的 com…...

常见的三种锁
一、互斥锁 互斥锁 Mutex 保证在任意时刻只有一个线程能够进入被保护的临界区。当一个线程获取到互斥锁后,其他线程若要进入临界区就会被阻塞,直到该线程释放锁。 互斥锁是一种阻塞锁,当线程无法获取到锁时,会进入阻塞状态。 应…...

离线文本转语音库pyttsx3(目前接触到的声音效果最好的,基本上拿来就能用)
在现代应用程序中,文本转语音(Text-to-Speech, TTS)技术越来越受到重视。无论是为视力障碍人士提供帮助,还是为教育和娱乐应用增添趣味,TTS 都能发挥重要作用。今天,我们将介绍一个简单易用的 Python 库——…...

LeetCode Hot100刷题——反转链表(迭代+递归)
206.反转链表 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。 示例 1: 输入:head [1,2,3,4,5] 输出:[5,4,3,2,1]示例 2: 输入:head [1,2] 输出:[2,1]示例 3&#…...

JJJ:linux sysfs相关
文章目录 1.sysfs(属性)文件的创建、读、写1.1 创建流程1.2 open流程1.3 read流程 2.补充2.1 sysfs下常见目录介绍2.2 属性相关2.2.1 简介2.2.2 attribute文件的创建 2.3 sysfs目录如何创建的 1.sysfs(属性)文件的创建、读、写 1…...

Leetcode 刷题记录 06 —— 矩阵
本系列为笔者的 Leetcode 刷题记录,顺序为 Hot 100 题官方顺序,根据标签命名,记录笔者总结的做题思路,附部分代码解释和疑问解答。 目录 01 矩阵置零 方法一:标记数组 方法二:两个标记变量 02 螺旋矩阵…...
)
从一次生产事故复盘:我们如何优雅地处理用户上传的‘异常’Excel文件(附Apache POI配置详解)
从生产事故到防御体系:构建Excel文件处理的工程化解决方案那天凌晨2点,我被一阵急促的告警声惊醒。监控系统显示,核心文件处理服务的错误率在10分钟内飙升到35%,大量用户上传的Excel文件无法正常解析。更糟糕的是,部分…...

ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题
ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vari…...
到底在‘看’什么?)
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?想象一下,你刚搬到一个新社区,想快速了解周围的邻居。最直接的方式是什么?不是挨家挨户敲门,而是通过社区活动认识几位关…...

Python合并Excel文档
有若干个Excel文档,每个文档格式一致,及第一行为文件标题,第二行为表格表头(表头不完全一致)。现需要将他们合并。合并规则为:去掉每个文档的第一行,以第二行为表头,将每个文档的第三…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

股票买卖最佳时机:LeetCode121题解
题目LeetCode121给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。返回你可以从这笔交易中获取…...
)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)第一次戴上Meta Quest 3时,那种虚拟与现实交织的震撼感至今难忘。但作为开发者,更让我着迷的是如何让虚拟物体在真实空间中"记住"…...

如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南
如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析
原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer 你是否曾想过拥有一个完全由自己掌控的提瓦特大陆&am…...

别再只会用--nogpgcheck了!手把手教你安全修复PostgreSQL yum源的GPG密钥问题
企业级PostgreSQL部署:安全解决GPG密钥验证的完整方案 当你在生产环境中部署PostgreSQL时,遇到GPG签名验证错误直接使用--nogpgcheck绕过检查,就像因为门锁打不开就直接把门拆掉一样危险。本文将带你深入理解GPG验证机制,并提供一…...