深度学习PyTorch之13种模型精度评估公式及调用方法
深度学习pytorch之22种损失函数数学公式和代码定义
深度学习pytorch之19种优化算法(optimizer)解析
深度学习pytorch之4种归一化方法(Normalization)原理公式解析和参数使用
深度学习pytorch之简单方法自定义9类卷积即插即用
实时语义分割之BiSeNetv2(2020)结构原理解析及建筑物提取实践
文章目录
- 摘要
- 1. Accuracy Score
- 2. Balanced Accuracy
- 3. Brier Score Loss
- 4. Cohen's Kappa
- 5. F1/F-beta Score
- 6. Hamming Loss
- 7. Hinge Loss
- 8. Jaccard Score
- 9. Log Loss
- 10. Matthews Correlation
- 11. Precision
- 12. Recall
- 13. Zero-One Loss
- 关键参数说明
- 可执行代码示例
摘要
模型训练后需要评估模型性能,因此需要了解各种评估指标的具体用法和背后的数学原理,本博客以清晰的格式呈现分类任务评估指标的名称、调用示例、公式说明。
1. Accuracy Score
调用方式:
from sklearn.metrics import accuracy_score
acc = accuracy_score(y_true, y_pred, normalize=True, sample_weight=None)
公式:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
2. Balanced Accuracy
调用方式:
from sklearn.metrics import balanced_accuracy_score
bal_acc = balanced_accuracy_score(y_true, y_pred, sample_weight=None, adjusted=False)
公式:
Balanced Accuracy = (Recall_Class1 + Recall_Class2 + … +Recall_ClassN) / N
调整后版本:BalancedAcc_adj = (BalancedAcc - 1/N) / (1 -1/N)
3. Brier Score Loss
调用方式:
from sklearn.metrics import brier_score_loss
brier = brier_score_loss(y_true, y_prob, sample_weight=None, pos_label=1)
公式:
Brier Score = 1/N * Σ(y_true_i - y_prob_i)^2
(适用于概率预测的校准度评估)
4. Cohen’s Kappa
调用方式:
from sklearn.metrics import cohen_kappa_score
kappa = cohen_kappa_score(y1, y2, labels=None, weights=None, sample_weight=None)
公式:
κ = (p_o - p_e) / (1 - p_e) 其中 p_o 为观察一致率,p_e 为期望一致率
5. F1/F-beta Score
调用方式:
from sklearn.metrics import f1_score, fbeta_score
f1 = f1_score(y_true, y_pred, average='weighted', zero_division=0)
fbeta = fbeta_score(y_true, y_pred, beta=0.5, average='macro')
公式:
Fβ = (1 + β²) * (precision * recall) / (β² * precision + recall) 当 β=1
时为 F1 Score
6. Hamming Loss
调用方式:
from sklearn.metrics import hamming_loss
hamming = hamming_loss(y_true, y_pred, sample_weight=None)
公式:
Hamming Loss = 1/N * Σ(预测错误的标签数 / 总标签数) (多标签任务专用)
7. Hinge Loss
调用方式:
from sklearn.metrics import hinge_loss
hinge = hinge_loss(y_true, pred_decision, labels=None, sample_weight=None)
公式:
Hinge Loss = max(0, 1 - y_true * pred_decision) 的平均值 (SVM模型常用)
8. Jaccard Score
调用方式:
from sklearn.metrics import jaccard_score
jaccard = jaccard_score(y_true, y_pred, average='samples')
公式:
Jaccard = TP / (TP + FP + FN)
即IOU,多用于图像分割评估
9. Log Loss
调用方式:
from sklearn.metrics import log_loss
logloss = log_loss(y_true, y_pred, eps=1e-15, normalize=True, labels=None)
公式:
Log Loss = -1/N * Σ[y_true_i * log(y_pred_i) + (1-y_true_i) *log(1-y_pred_i)]
交叉熵损失,需概率预测输入
10. Matthews Correlation
调用方式:
from sklearn.metrics import matthews_corrcoef
mcc = matthews_corrcoef(y_true, y_pred, sample_weight=None)
公式:
MCC = (TPTN - FPFN) / √((TP+FP)(TP+FN)(TN+FP)(TN+FN))
适用于类别不平衡的二分类
11. Precision
调用方式:
from sklearn.metrics import precision_score
precision = precision_score(y_true, y_pred, average='weighted', zero_division=0)
公式:
Precision = TP / (TP + FP)
12. Recall
调用方式:
from sklearn.metrics import recall_score
recall = recall_score(y_true, y_pred, average='macro', zero_division=0)
公式:
Recall = TP / (TP + FN)
13. Zero-One Loss
调用方式:
from sklearn.metrics import zero_one_loss
zero_one = zero_one_loss(y_true, y_pred, normalize=True)
公式:
Zero-One Loss = 1 - Accuracy
直接统计错误预测比例
关键参数说明
| 参数 | 说明 |
|---|---|
| average | 计算方式:None(各类单独计算)、‘micro’(全局统计)、‘macro’(各类平均)、‘weighted’(按支持数加权) |
| zero_division | 处理除零情况:0(返回0)、1(返回1)或’warn’(返回0并警告) |
| sample_weight | 样本权重数组 |
| pos_label | 指定正类标签(仅二分类有效) |
| labels | 指定要评估的类别列表 |
| beta | F-beta中召回率的权重(>1侧重召回率,<1侧重精确率) |
可执行代码示例
以下程序采用常用的accuracy, precision, recall, f1对分类结果进行评估,注意替换下列文件夹,两个文件夹内均为8位单波段影像,采用相同命名。
- label_dir = ‘label’ # 替换为实际路径
- pred_dir = ‘pred’ # 替换为实际路径
import os
import numpy as np
from PIL import Image
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
import matplotlib.pyplot as pltdef load_images_and_labels(label_dir, pred_dir):"""读取标签图像和预测图像,假设它们的像素值代表类别标签。:param label_dir: 实际标签图像的文件夹路径:param pred_dir: 预测标签图像的文件夹路径:return: 实际标签和预测标签的列表"""labels = []preds = []# 获取文件列表label_files = sorted(os.listdir(label_dir))pred_files = sorted(os.listdir(pred_dir))# 遍历每个图像文件加载标签和预测for label_file, pred_file in zip(label_files, pred_files):label_path = os.path.join(label_dir, label_file)pred_path = os.path.join(pred_dir, pred_file)# 加载图像并转换为灰度label_img = Image.open(label_path).convert('L') # 灰度图pred_img = Image.open(pred_path).convert('L') # 灰度图# 假设灰度值代表类标签label = np.array(label_img)pred = np.array(pred_img)# 扁平化数组,以便计算评估指标labels.extend(label.flatten())preds.extend(pred.flatten())return np.array(labels), np.array(preds)def evaluate_model(labels, preds):"""计算模型的评估指标:param labels: 实际标签:param preds: 预测标签"""# 计算评估指标accuracy = accuracy_score(labels, preds)precision = precision_score(labels, preds, average='weighted', zero_division=0)recall = recall_score(labels, preds, average='weighted', zero_division=0)f1 = f1_score(labels, preds, average='weighted', zero_division=0)# 打印评估指标print(f"Accuracy: {accuracy:.4f}")print(f"Precision: {precision:.4f}")print(f"Recall: {recall:.4f}")print(f"F1 Score: {f1:.4f}")# 可选:绘制混淆矩阵from sklearn.metrics import confusion_matriximport seaborn as snscm = confusion_matrix(labels, preds)sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=np.unique(labels), yticklabels=np.unique(labels))plt.title('Confusion Matrix')plt.xlabel('Predicted')plt.ylabel('True')plt.show()if __name__ == "__main__":# 设置实际标签和预测标签的文件夹路径label_dir = 'label' # 替换为实际路径pred_dir = 'pred' # 替换为实际路径# 加载标签和预测数据labels, preds = load_images_and_labels(label_dir, pred_dir)# 评估模型evaluate_model(labels, preds)输出结果:
Accuracy: 0.9681
Precision: 0.9686
Recall: 0.9681
F1 Score: 0.9683
绘制混淆矩阵:

相关文章:
深度学习PyTorch之13种模型精度评估公式及调用方法
深度学习pytorch之22种损失函数数学公式和代码定义 深度学习pytorch之19种优化算法(optimizer)解析 深度学习pytorch之4种归一化方法(Normalization)原理公式解析和参数使用 深度学习pytorch之简单方法自定义9类卷积即插即用 实时…...

《云原生监控体系构建实录:从Prometheus到Grafana的观测革命》
PrometheusGrafana部署配置 Prometheus安装 下载Prometheus服务端 Download | PrometheusAn open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.https://prometheus.io/…...

GHCTF2025--Web
upload?SSTI! import os import refrom flask import Flask, request, jsonify,render_template_string,send_from_directory, abort,redirect from werkzeug.utils import secure_filename import os from werkzeug.utils import secure_filenameapp Flask(__name__)# 配置…...

NO.32十六届蓝桥杯备战|函数|库函数|自定义函数|实参|形参|传参(C++)
函数是什么 数学中我们其实就⻅过函数的概念,⽐如:⼀次函数 y kx b ,k和b都是常数,给⼀个任意的x ,就得到⼀个 y 值。其实在C/C语⾔中就引⼊了函数(function)的概念,有些翻译为&a…...

计算机视觉算法实战——老虎个体识别(主页有源码)
✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连✨ 1. 领域介绍 老虎个体识别是计算机视觉中的一个重要应用领域,旨在通过分析老虎的独特条纹图案,自动识别和区…...

【移动WEB开发】rem适配布局
目录 1. rem基础 2.媒体查询 2.1 语法规范 2.2 媒体查询rem 2.3 引入资源(理解) 3. less基础 3.1 维护css的弊端 3.2 less介绍 3.3 less变量 3.4 less编译 3.5 less嵌套 3.6 less运算 4. rem适配方案 4.1 rem实际开发 4.2 技术使用 4.3 …...

25年携程校招社招求职能力北森测评材料计算部分:备考要点与误区解析
在求职过程中,能力测评是筛选候选人的重要环节之一。对于携程这样的知名企业,其能力测评中的材料计算部分尤为关键。许多求职者在备考时容易陷入误区,导致在考试中表现不佳。本文将深入解析材料计算部分的实际考察方向,并提供针对…...

【Elasticsearch入门到落地】9、hotel数据结构分析
接上篇《8、RestClient操作索引库-基础介绍及导入demo》 上一篇我们介绍了RestClient的基础,并导入了使用Java语言编写的RestClient程序Demo以及将要分析的数据库。本篇我们就要分析导入的宾馆数据库tb_hotel表结构的具体含义,并分析如何建立其索引库。 …...

现代互联网网络安全与操作系统安全防御概要
现阶段国与国之间不用对方路由器,其实是有道理的,路由器破了,内网非常好攻击,内网共享开放端口也非常多,更容易攻击。还有些内存系统与pe系统自带浏览器都没有javascript脚本功能,也是有道理的,…...

轻量级TCC框架的实现
现有seata、tcc-transaction等tcc框架实现都较为重量级,今天主要带来一种轻量级的实现,大概只用了1200行代码实现。不依赖具体框架grpc、http、dubbo等,只需要业务系统按照标准化实现Try、Commit、Cancel实现接口即可。 已解决悬挂、幂等、空…...

共绘智慧升级,看永洪科技助力由由集团起航智慧征途
在数字化洪流汹涌澎湃的当下,企业如何乘风破浪,把握转型升级的黄金机遇,已成为所有企业必须直面的时代命题。由由集团,作为房地产的领航者,始终以前瞻视野引领变革,坚决拥抱数字化浪潮,携手数字…...

小程序开发总结
今年第一次帮别人做小程序。 从开始动手到完成上线,一共耗时两天。AI 让写代码变得简单、高效。 不过,小程序和 Flutter 等大厂开发框架差距实在太大,导致我一开始根本找不到感觉。 第一,IDE 不好用,各种功能杂糅在…...

元脑服务器:浪潮信息引领AI基础设施的创新与发展
根据国际著名研究机构GlobalData于2月19日发布的最新报告,浪潮信息在全球数据中心领域的竞争力评估中表现出色,凭借其在算力算法、开放加速计算和液冷技术等方面的创新,获得了“Leader”评级。在创新、增长力与稳健性两个主要维度上ÿ…...

uniapp+node+mysql接入deepseek实现流式输出
node import express from express; import mysql from mysql2; import cors from cors; import bodyParser from body-parser; import axios from axios; import { WebSocketServer } from ws; // 正确导入 WebSocketServerconst app express();// Middlewares app.use(cors…...

PHP MySQL 创建数据库
PHP MySQL 创建数据库 引言 在网站开发中,数据库是存储和管理数据的核心部分。PHP 和 MySQL 是最常用的网页开发语言和数据库管理系统之一。本文将详细介绍如何在 PHP 中使用 MySQL 创建数据库,并对其操作进行详细讲解。 前提条件 在开始创建数据库之…...

UE4 World, Level, LevelStreaming从入门到深入
前言 在《塞尔达传说:旷野之息》中,玩家攀上初始高塔的瞬间,目光所及的山川湖泊皆可抵达;在《艾尔登法环》中,黄金树的辉光始终悬于地平线之上,指引玩家穿越无缝衔接的史诗战场。这些现代游戏杰作背后的核…...
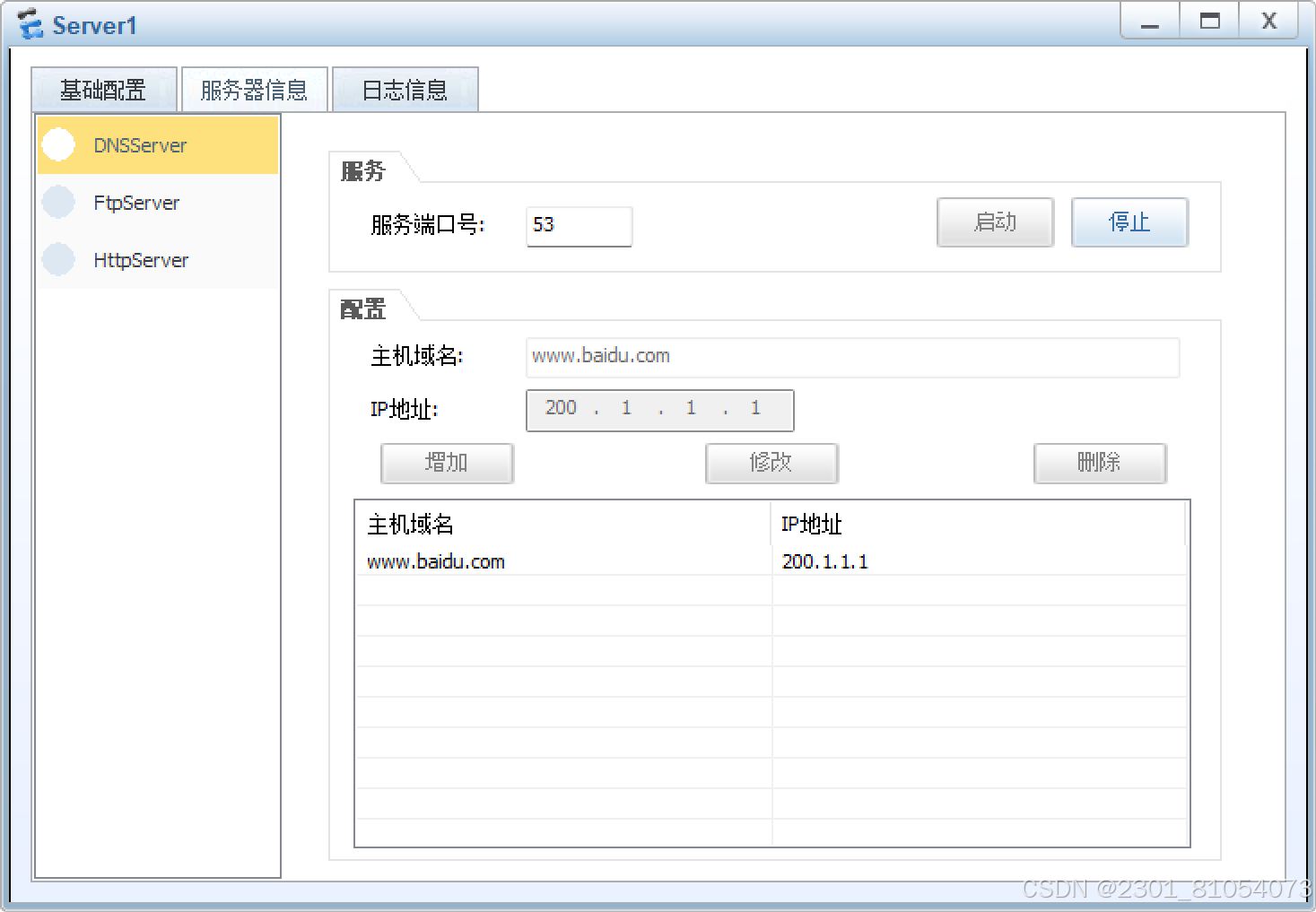
3月8日实验
拓扑: 需求: 1.学校内部的HTTP客户端可以正常通过域名www.baidu.com访问到白度网络中的HTTP服务器 2.学校网络内部网段基于192.168.1.0/24划分,PC1可以正常访问3.3.3.0/24网段,但是PC2不允许 3.学校内部路由使用静态路由&#…...

IO多路复用实现并发服务器
一.select函数 select 的调用注意事项 在使用 select 函数时,需要注意以下几个关键点: 1. 参数的修改与拷贝 readfds 等参数是结果参数 : select 函数会直接修改传入的 fd_set(如 readfds、writefds 和 exceptfds…...
【漫话机器学习系列】122.相关系数(Correlation Coefficient)
深入理解相关系数(Correlation Coefficient) 1. 引言 在数据分析、统计学和机器学习领域,研究变量之间的关系是至关重要的任务。我们常常想知道:当一个变量变化时,另一个变量是否也会随之变化?如果会&…...

控制系统分类
文章目录 定义与特点1. 自治系统(Autonomous System)与非自治系统(Non-Autonomous System)自治系统非自治系统 2. 线性系统(Linear System)与非线性系统(Nonlinear System)线性系统非…...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...

Unity安卓构建72小时实战指南:从零到真机运行
1. 这不是“又一本Unity教程”,而是我带三个新人从零上线第一款安卓游戏的真实路径你点开这个标题,大概率正站在两个路口之间:一边是满屏“30天速成Unity”“零基础做爆款”的短视频封面,一边是你刚下载完Unity Hub、卡在Android …...

DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染
更多请点击: https://codechina.net 第一章:DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染 硬件配置偏差:GPU显存与计算精度的隐性干扰 在A100(8…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

美团外卖mtgsig与waimai_sign双层签名逆向解析
1. 这不是“爬虫教程”,而是一份反向工程现场笔记你搜到这篇内容,大概率正卡在某个调试窗口前:抓包看到mtgsig和waimai_sign两个参数像两堵墙,无论怎么改请求头、换UA、清缓存,返回永远是{"code":403,"…...

2026智慧校园规划必读:如何在预算吃紧下选到高性价比方案
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...

股票买卖最佳时机:LeetCode121题解
题目LeetCode121给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。返回你可以从这笔交易中获取…...
)
保姆级避坑指南:在Ubuntu 22.04上搞定ROS2 Humble、PX4与Gazebo的联合仿真(附Empy版本降级)
保姆级避坑指南:Ubuntu 22.04下ROS2 Humble与PX4联合仿真的21个关键陷阱当你在Ubuntu 22.04上第一次尝试搭建ROS2 Humble、PX4与Gazebo的联合仿真环境时,可能会遇到比预期更多的挑战。这不是一个简单的"复制粘贴命令就能完成"的任务——版本冲…...

yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案
yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器正是你寻找的完美答案。作为…...

如何快速定制Office界面:终极开源工具使用指南
如何快速定制Office界面:终极开源工具使用指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-editor O…...