小白学Agent技术[4](Agent设计模式)
文章目录
- Agent设计模式
- Zero shot
- Few shot
- 应用场景
- 技术特性对比
- ReAct模式
- ReAct模式简介
- ReAct模式举例
- ReAct模式实现
- Plan and Solve模式
- 实现原理
- Reason without Observation模式
- LLMCompiler模式
- 实现原理
- Basic Reflection
- Basic Reflection原理
- Reflexion 模式
- Reflexion 模式原理
- Reflexion框架
- Language Agent TreeSearch模式
- Language Agent TreeSearch原理
- 框架对比
- Self-Discover模式
- Self-Discover推理结构
- 第一阶段-发现推理结构
- 第二阶段-应用推理结构
Agent设计模式

Zero shot
- 最接近C端大多数人初次体验ChatGPT时的交互模式。在这种Agent模式之下,用户的输入问题不增加任何prompt template处理,直接被传入了大模型中,并将大模型返回结果直接返回给了终端用户。
- 在大多数的终端应用开发场景中,这种Agent开发模式都是无法满足需求的
Few shot
-
Few shot模式和PlainPrompt最大的区别在于,它开始有prompt template逻辑,因为prompt template的存在,开发者得以调用大模型的context-learning(上下文学习)能力。
-
Few-Shot模式应该是B端开发场景中使用频率最高的一种Agent范式。这种范式中有几个核心组成部分:
- 角色描述:一句话描述清楚你希望大模型扮演什么样的角色,以及需要具备的能力和技能
- 指令任务描述:可以是一句话,也可以通过提示词引导大模型按照一定的步骤逐步解决问题
- 样例:一个完整的"任务-解决方案"示例,或者是入参/出参的格式
-
工程师可以通过大模型的指令遵循能力,将原本需要通过复杂规则定义和处理的环节,都通过大模型重做一遍,提升工作效率。
-
以客服工单分类场景为例,Prompt模板设计如下:
示例1:
用户描述:"付款后订单未显示"
分类标签:支付问题示例2:
用户描述:"APP闪退无法登录"
分类标签:技术故障待分类问题:
用户描述:"商品页面图片加载失败"
分类标签:
应用场景
- 低资源任务:标注数据不足时快速构建分类/生成系统
- 动态场景适配:电商促销期间新增"限时折扣咨询"分类
- 多语言支持:通过添加不同语言示例实现跨语种意图识别
- 复杂规则传递:金融场景中合规性审查规则的示例化表达
技术特性对比
| 维度 | Few-shot模式 | Zero-shot模式 | Fine-tuning模式 |
|---|---|---|---|
| 数据需求 | 5-20样本 | 无样本 | 千级以上标注 |
| 迭代成本 | 修改Prompt即时生效 | 需调整Prompt逻辑 | 需重新训练模型 |
| 可解释性 | 通过示例可追溯推理路径 | 依赖模型内部知识 | 黑箱参数更新 |
ReAct模式
ReAct模式简介

- ReAct针对给出的问题,先进行思考,再根据思考的结果行动,然后观察行动的结果,如果不满足要求,再进行思考、行动,直至得到满意的结果为止。
- 采用few-shotin-context学习来生成解决问题的action和thought序列。每个in-context样例是由action、thought、observation构成的行为轨迹
- 在推理占主导地位的应用中,我们交替生成thought和action,这样完整的行为轨迹就是多个thought-action-observation步骤
- 相反在决策生成任务中(涉及大量action),thought只会在行为轨迹中最相关的位置稀疏出现
ReAct模式举例
举个例子,让孩子帮忙去厨房里拿一瓶酱油,告诉ta一步步来(COT提示词策略):
- 先看看台面上有没有
- 再拉开灶台底下抽屉里看看
- 再打开油烟机左边吊柜里看看
在没有ReAct的情况就是:不管在第几步找到酱油,孩子都会把这几个地方都看看(Action)
有ReAct的情况是:
- Action1:先看看台面上有没有
- Observation1:台面上没有酱油,执行下一步
- Action2:再拉开灶台底下抽屉里看看
- Observation2:抽屉里有酱油
- Action3:把酱油拿出来
在论文的开头作者也提到人类智能的一项能力,即每次执行行动后都有一个"自言自语的反思(Observation:现在做了什么,是否已达目的),这相当于让Agent能够维持短期记忆。
ReAct模式实现

ReAct流程的三个关键概念:
- Thought:由LLM模型生成,是LLM产生行为和依据。可根据LLM的思考,来衡量他要采取的行为是否合理。这是一个可用来判断本次决策是否合理的关键依据。相较于人类,thought的存在可以让LLM的决策变得更加有可解释性和可信度。
- Act:Act是指LLM判断本次需要执行的具体行为。Act一般由两部分组成:行为和对象。编程角度来看就是API名称和对应的入参。LLM模型最大的优势是,可以根据Thought的判断,选择需要使用的API并生成需要填入API的参数。从而保证了ReAct框架在执行层面的可行性。
- obs:LLM框架对于外界输入的获取。就像LLM的五官,将外界的反馈信息同步给LLM模型,协助LLM模型进一步的做分析或者决策。
一个完整的ReAct的行为,包涵以下几个流程:
- 输入目标:任务的起点。可以是用户的手动输入,也可以是依靠触发器(比如系统故障报警)。
- LOOP:LLM模型开始分析问题需要的步骤(Thought),按步骤执行Act,根据观察到的信息(Obs),循环执行这个过程。直到判断任务目标达成。
- Finish:任务最终执行成功,返回最终结果。
Plan and Solve模式
- 为了解决多步推理的步骤缺失问题,提出了Plan-and-Solve(PS)prompting方法,它由两部分组成,首先设计计划,计划的目标是将整个任务划分为多个更小的子任务,然后根据计划执行子任务。
实现原理
- Plan and Solve模式更适合先有计划再执行。如果ReAct更适合完成厨房拿酱油的任务,那么 Plan and Solve更适合完成“西红柿炒鸡蛋”的任务。
- Plan and Solve中先计划,如果执行过程中,不满足条件,那么计划可以根据情况进行变化。

- 规划器:负责让LLM生成一个多步计划来完成一个大任务。代码中有Planner和和Replanner,Planner负责第一次生成计划;
Replanner是指在完成单个任务后,根据目前任务的完成情况进行Replan,所以Replanner提示词中除了Zeroshot,还会包含:目标,原有计划,和已完成步骤的情况。 - 执行器:接受用户查询和规划中的步骤,并调用一个或多个工具来完成该任务。
Reason without Observation模式
-
核心思想是将推理(Reasoning)过程与外部观察(Observation)分离,以此来提高模型的效率和性能。
-
在传统的LLM增强系统中,如ReAct模式中。模型的推理过程是与外部工具的调用和观察结果紧密交织在一起的。这种模式虽然简单易用,但往往会导致计算复杂性高,因为需要多次调用语言模型(LLM)并重复执行操作,这不仅增加了计算成本,也增加了执行时间。
-
REWOO模式通过以下几个步骤来优化这一过程:
- Planner(规划器):首先,规划接收用户输入的任务,并将其分解为一系列的计划((Pns)。每个计划都详细说明了需要使用哪些外部工具以及如何使用这些工具来获取证据或执行特定的动作,负责生成一个相互依赖的“链式计划”,定义每一步所依赖的上一步的输出。
- Worker(执行器):接下来,执行器根据规划器提供的计划,调用相应的外部工具来执行任务,并获取必要的信息或证据,循环遍历每个任务,并将任务输出分配给相应的变量。当调用后续调用时,它还会用变量的结果替换变量。
- Solver(合并器):最后,合并器将所有计划的执行结果整合起来,形成对原始任务的最终解决方案。这种模块化的设计显著减少了令牌消耗和执行时间,因为它允许一次性生成完整的工具链,而不是在每次迭代中都重复调用LLM
- 此外,由于规划数据不依赖于工具的输出,因此可以在不实际调用工具的情况下对模型进行微调,进一步简化微调过程。

LLMCompiler模式
论文An LLMCompiler for Parallel FunctionCalling
github项目
实现原理
- 简单来说,就是通过并行Function callng来提高效率,比如用户提问Scott Derrickson和Ed Wood是否是同一个国家的国民?planner搜索ScottDerrickson国籍和搜索EdWood国籍同时进行,最后合并即可。


架构上它由三个组件组成: - Planner(规划器):streama DAGof tasks,即将原始问题分解为一个DAG(DirectAcyclicGraph,有向无环图)的任务列表。
- Task Fetching Unit(并行执行器):根据任务的依赖,调度任务并行执行
- Joiner(合并器):综合DAG执行结果反馈给用户,如果没达预期可以重新规划任务
Basic Reflection
- Basic Reflection可以类比于学生(Generator)写作业,老师(Reflector)来批改建议,学生根据批改建议来修改,如此反Basic Reflection可以类比于左右互博。
- 左手是Generator,负责根据用户指令生成结果;右手是Reflector,来审查Generator的生成结果并给出建议。在左右互搏的情况下,Generator生成的结果越来越好,Reflector的检查越来越严格,输出的结果也越来越有效。
Basic Reflection原理
- Generator接收来自用户的输入,输出initialresponse
- Reflector接收来自Generator的response,根据开发者设置的要求,给出Reflections,即评语、特征、建议
- Generator再根据Reflector给出的反馈进行修改和优化,输出下一轮response
- 循环往复,直到循环次数

Reflexion 模式
- 论文RelexionLanguage Agents with Verbal Rinforcement Leaming
- github项目
Reflexion 模式原理
- 由于传统强化学习需要大量的训练样本和昂贵的模型微调,大模型很难快速有效地从错误经验中学习。ReAct,HuggingGPT等基于大模型的任务决策框架,它们利用In-contextlearning的方式快速地指导模型执行任务,避免了传统微调方式带来的计算成本和时间成本。相当于Basic Reflection模式的升级版,使用语言反馈信号来帮助agent从先前的失败经验中学习。
- Reflexion将传统梯度更新中的参数信号转变为添加在大模型上下文中的语言总结。使得agent在下一个episode中能参考上次执行失败的失败经验,从而提高agent的执行效果。

Reflexion框架
- Actor:Actor由LLM担任,主要工作是基于当前环境生成下一步的动作。
- Evaluator:Evlauator主要工作是衡量Actor生成结果的质量。就像强化学习中的Reward函数对Actor的执行结果进行打分。
- Self-reflexion:Self-reflexion一般由LLM担任,是Reflexion框架中最重要的部分。它能结合离散的reward信号(如success/fail)、trajectory(轨迹,也就是推理上下文)等生成具体且详细语言反馈信号,这种反馈信号会储存在Memory中,启发下一次实验的Actor执行动作。相比reward分数,这种语言反馈信号储存更丰富的信息,例如在代码生成任务中,Reward只会告诉你任务是失败还是成功,但是Self-reflexion会告诉你哪一步错了,错误的原因是什么等。
- Memory:分为短期记忆(short-term)和长期记忆(long-term)。在一次实验中的上下文称为短期记忆,多次试验中Self-reflexion的结果称为长期记忆。类比人类思考过程,在推理阶段Actor会不仅会利用短期记忆,还会结合长期记忆中存储的重要细节,这是Reflexion框架能取得效果的关键。
- Reflexion是一个迭代过程,Actor产生行动,Evaluator对Actor的行动做出评价,Self-Rflexion基于行动和评价形成反思,并将反思结果存储到长期记忆中,直到Actor执行的结果达到目标效果。

Language Agent TreeSearch模式
论文Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
- LATS提供了一种灵活、高效且可扩展的方式来处理自然语言任务中的推理和决策问题。主要解决了自然语言任务中的推理和决策问题。具体来说,它可以用于以下场景:
- 推理问题:当输入一个问题时,可以通过LATS生成一系列中间想法(思考序列),最终得到答案。
- 决策问题:当需要在多个选项之间做出选择时,LATS可以根据不同的情况生成不同的决策路径,并从中选择最优解
Language Agent TreeSearch原理
- LATS简单来说:是Treesearch+ReAct+Plan&solve的融合体

与传统的基于MCTS的推理决策框架相比,LATS的主要改进在于: - 使用了蒙特卡罗树搜索算法,可以有效地探索可能的解决方案
- 利用了预训练的语言模型来评估节点的价值,从而更好地指导搜索过程
- 引入了自我反思机制,可以从失败的轨迹中学习并提高决策能力

- LATS主要内容,包含了节点选择、拓展、评分、执行、反向传播、反思。选择节点后进行拓展子节点,每个子节点通过LLM评分。任务不断执行直到达到设定的指定步数或获取最优质的结果,再将结果反向传播给各父节点进行更新。而输出内容经过LM进行反思更新结果。
- LATS中通过树搜索的方式进行Reward(强化学习的思路),同时还会融入Reflection,从而拿到最佳结果。所以:LATS=Tree search+ ReAct+Plan&solve+Reflection+强化学习
- 提示词模板方面和之前的reflection,plan&solve,ReAct差别不大,只是上下文中多了对树搜索结果的评估和返回结果。
- 架构上,由多轮的BasicReflection,多个Generator和Reflector组成。

主要有四个主要步骤:
- 选择:根据下面步骤(2)中的总奖励选择最佳的下一步行动。要么做出响应(如果找到解决方案或达到最大搜索深度),要么继续搜索。
- 扩展和执行:生成N(例子中为5个Act节点)个潜在操作以并行执行并执行它们。
- 反思+评估:观察这些行动的结果并根据反思(以及可能的外部反馈)对决策进行评分。
- 反向传播:根据结果更新根轨迹的分数
- 总结一下,选择当前节点,行动、反思、评分,并将结果反向传播给父节点,同时根据节点数量是否达到上限以及结果情况决定是否继续向下延伸或输出结果。
框架对比
- LATS通过融合计划、思考、行动、反思与记忆,便用蒙特卡罗树搜索算法,相较ReAct、ToT、CoT、Reflection等框架具有显著优势。

Self-Discover模式
-
论文SELF-DISCOVER: Large Language Models Self-Compose Reasoning Structures
-
github项目
-
SELF-DISCOVER旨在使模型能够自动发现用于解决复杂推理问题的任务内在推理结构。-
-
SELF-DISCOVER的核心是一个自我发现过程,LLMS在这一过程中选择多个原子推理模块(如批判性思维和逐步思考)并将它们组合成一个明确的推理结构,供LLMs在解码时遵循。
优点
- SELF-DISCOVER增强LLM处理复杂推理问题的能力,尤其是那些传统提示方法难以应对的问题
- 基于理论的代理推理和MATH等具有挑战性的推理基准测试上的表现,相比链式推理(CoT)提高了32%
- SELF-DISCOVER在效率上也超过了推理密集型方法,如CoT-Self-Consistency,同时所需的推理计算量减少了10到40倍
- 展示了自我发现的推理结构在不同的模型家族之间具有普适性,可以从PaLM2-L迁移到GPT-4,以及从GPT-4迁移到Lama2

Self-Discover推理结构
- SELF-DISCOVER是一个的两阶段方法,旨在利用大型LLM来自动构建和应用解决特定理结构,再通过生成的推理结构解决复杂的问题。

第一阶段-发现推理结构
第一阶段包括三个操作如下:
- 选择(Select):在这一操作下,模型需要从39个预定义的推理模块中选择几个关键模块,这些模块可以帮助解决特定的任务。
提供了所有可用推理模块的描述,例如“批判性思维”、“步骤分解“和“提出并验证“等。同时也给出了一些带答案的任务示例。模型需要根据这些信息选择最合适的推理模块组合。 - 适应(Adapt):选择完关键推理模块后,模型需要调整和细化每个模块的描述,使其更好地适应待解决的具体任务。在这个阶段,会显示之前SELECT阶段选择的模块描述,以及一些无答案的任务示例。模型需要根据这些信息,改写每个推理模块的描述,使其更贴合实际任务。
- 实施(lmplement):模型需要将调整后的推理模块组合成一个SON格式的分步推理计划。为了展示如何实现这一计划,会给出一个人工编写的示例推理结构。该结构展示了如何将推理模块按顺序实施,以逐步解决问题并得到正确答案。模型的目标是生成一个类似的推理计划,但应用于当前的任务和调整后的推理模块描述。
第二阶段-应用推理结构
- 完成阶段一之后,模型将拥有一个专门为当前任务定制的推理结构。在解决问题的实例时,模型只需遵循这个结构,逐步填充JSON中的值,直到得出最终答案
相关文章:
小白学Agent技术[4](Agent设计模式)
文章目录 Agent设计模式Zero shotFew shot应用场景 技术特性对比ReAct模式ReAct模式简介ReAct模式举例ReAct模式实现 Plan and Solve模式实现原理 Reason without Observation模式LLMCompiler模式实现原理 Basic ReflectionBasic Reflection原理 Reflexion 模式Reflexion 模式原…...
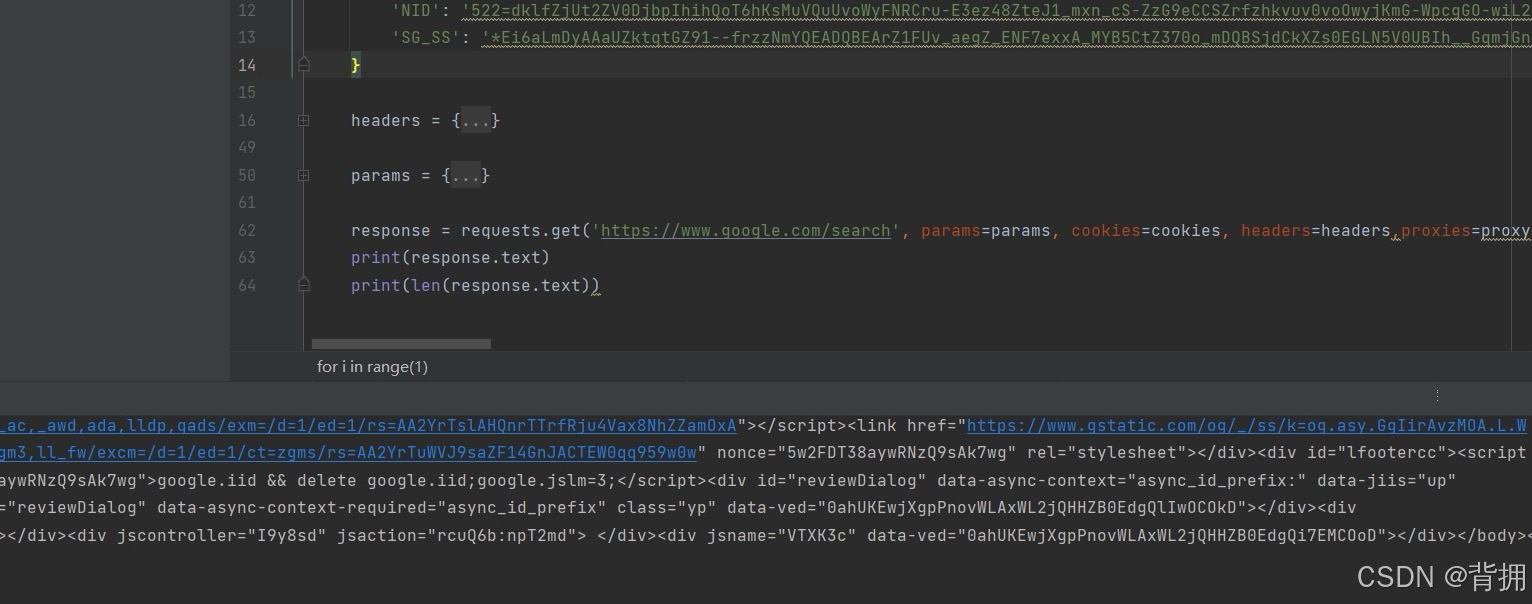
Google参数逆向 谷歌搜索
背景 从2025年1月15日开始,Google强制用户开启JavaScript才能使用Google搜索功能。 由于此前业务需要调用Google搜索功能去寻找目标资源进行下载,Google的改版导致整条产线全部瘫痪,急需解决方案。 业务每日需要Google搜索数百万次 临时解决方…...

OneM2M:全球性的物联网标准-可应用于物联网中
OneM2M 是一个全球性的物联网(IoT)标准,旨在为物联网设备和服务提供统一的框架和接口,以实现设备之间的互操作性、数据共享和服务集成。OneM2M 由多个国际标准化组织(如 ETSI、TIA、TTC、ARIB 等)共同制定,目标是解决物联网领域的碎片化问题,提供一个通用的标准,支持跨…...

MySQL环境搭建和基本操作
前言 MySQL是现在最为流行的数据库,而且是开源的,任何人都可以在Internet下载,进行安装。 MySQL环境搭建 一、软件包安装 MySQL是目前最为流行的开放源码的数据库,是完全网络化的跨平台的关系型数据库系统,它是由瑞典MySQLAB公司…...

【GIT】non-fast-forward错误
遇到 non-fast-forward 错误时,通常是因为远程仓库有本地尚未包含的提交(如远程仓库初始化时自动生成的 README.md 等文件)。以下是分步解决方案: 1. 拉取远程更改并合并历史 git pull origin master --allow-unrelated-historie…...

深入了解Linux —— 调试程序
前言 我们已经学习了linux下许多的工具,vim、gcc、make/makefile等; 已经能够在linux写代码,并且进行编译运行,让程序在linux下跑起来。 但是,如果我们在写代码的时候遇见了错误;但是我们并不知道错误在哪&…...

JVM - 3.垃圾回收
1.垃圾收集的经典问题 1.哪些内存需要回收2.什么时候回收3.如何回收1.你知道哪几种垃圾回收器,各自的优缺点,重点讲一下cms和g12.JVM GC算法有哪些,目前的JDK版本采用什么回收算法3.G1回收器的回收过程 1.Java中垃圾的定义(Garbag…...

vs code 设置字体颜色
修改setting.json文件 {"remote.SSH.remotePlatform": {"ubuntu": "linux"},// "workbench.colorTheme": "One Dark Pro",// "editor.semanticTokenColorCustomizations": {// },"editor.semanticTokenColo…...

MoonSharp 文档一
目录 1.Getting Started(入门手册) 步骤1:在 IDE 中引入 MoonSharp 步骤2:引入命名空间 步骤3:调用脚本 步骤4:运行代码 2.Keeping a Script around(保留一个脚本) 步骤1:复现前教程所有操作 步骤2:改为创建Script对象 步骤3:访问全局环境 步骤4:直接调用…...
详解)
Unity3D 图形渲染(Graphics Rendering)详解
前言 Unity3D 是一款广泛使用的游戏引擎,其图形渲染系统是开发者创建高质量视觉效果的核心。本文将深入探讨 Unity3D 的图形渲染管线、渲染技术、以及如何通过代码实现自定义渲染效果。 对惹,这里有一个游戏开发交流小组,大家可以点击进来一…...
计算机视觉图像点运算【灰度直方图均衡化图形界面实操理解 +开源代码】
对一个数字图像处理系统来说,一般的处理过程为三个步骤:图像预处理、特征抽取、图像识别和分析。图像的点运算就是预处理过程中的重要一步,点运算是对图像的灰度级进行变换。 图像点运算概念 点运算是指对图像的每个像素依次进行相同的灰度变…...

在Windows 7操作系统,基于llama.cpp本地化部署 deepseek-r1模型的方法 2025-02-08
一、概述 现在已经是大模型时代。 个人认为,deepseek效果惊艳,大模型已进入实用阶段。 有些电脑,由于种种原因,还在用 Windows 7, Windows XP 等操作系统。 为了让这些电脑用上大模型,本教程在 llama.c…...

力扣146 - LRU缓存
视频讲解 哈希 双向链表 为什么要用双向链表? 快速删除节点(O(1)) 如果是单链表的话,删除一个节点时,需要从头遍历,找到前驱节点,才能修改 prev->next,导致 O(n)…...

C++ 算法竞赛STL以及常见模板
目录 STL /*═══════════════ Vector ═══════════════*/ /*════════════════ Pair ════════════════*/ /*══════════════ String ════════════════*/ /*══════════…...

微信小程序将markdown内容转为pdf并下载
要在微信小程序中将Markdown内容转换为PDF并下载,您可以使用以下方法: 方法一:使用第三方API服务 选择第三方API服务: 可以选择像 Pandoc、Markdown-PDF 或 PDFShift 这样的服务,将Markdown转换为PDF。例如,PDFShift 提供了一个API接口,可以将Markdown内容转换为PDF格式…...

AI绘画软件Stable Diffusion详解教程(7):图生图基础篇(改变图像风格)
我们在使用AI魔盒不停的绘制一幅幅图像时,会有这样的疑问:为什么生成的图像随机性这么强?我们如何按照自己的构图创作作品?为什么提示词生成的图像细节不够?如何把手绘的风格转换成另一种风格,或者说把自己…...

ES映射知识
映射 映射类似于关系型数据库的Schema(模式)。 映射来定义字段列和存储的类型等基础信息。 {"mappings": {"properties": {"username": {"type": "keyword","ignore_above": 256 // 忽略…...

蓝桥杯嵌入式组第七届省赛题目解析+STM32G431RBT6实现源码
文章目录 1.题目解析1.1 分而治之,藕断丝连1.2 模块化思维导图1.3 模块解析1.3.1 KEY模块1.3.2 ADC模块1.3.3 IIC模块1.3.4 UART模块1.3.5 LCD模块1.3.6 LED模块1.3.7 TIM模块 2.源码3.第七届题目 前言:STM32G431RBT6实现嵌入式组第七届题目解析源码&…...
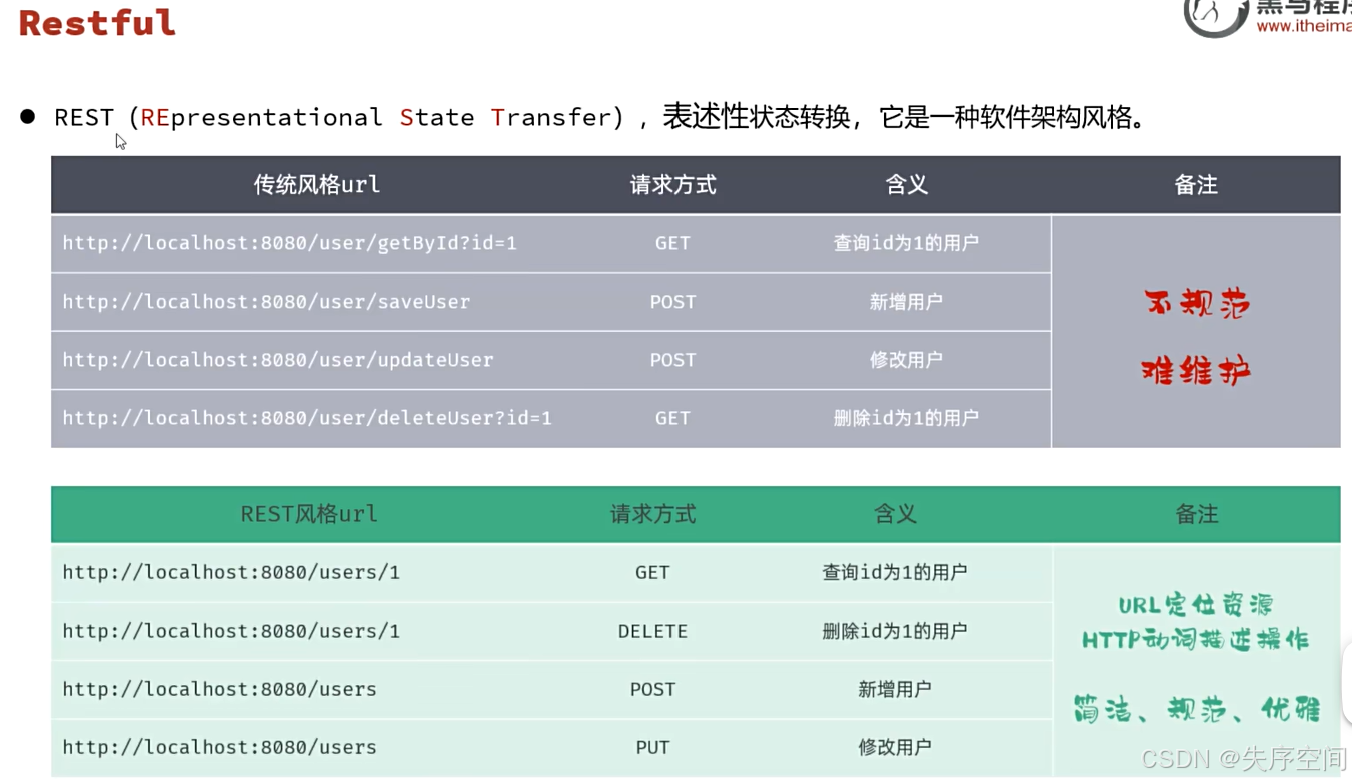
SpringBoot项目配置文件
SpringBoot项目提供了多种属性配置方式(properties、yaml、yml) yml配置文件 使用Apifox可以方便开发接口、前端测试等 工程搭建: 1.创建SpringBoot工程,并引入web开发起步依赖、mybatis、mysql驱动、lombok 2.创建数据库表&am…...

PythonWeb开发框架—Flask框架之flask-sqlalchemy、序列化和反序列化使用详解
1.安装依赖库 pip install flask-sqlalchemy pip install pymysql 2.连接数据库配置 from flask import Flask from flask_sqlalchemy import SQLAlchemyapp Flask(__name__) #创建 Flask 应用实例#配置数据库连接 app.config[SQLALCHEMY_DATABASE_URI]mysql://root:stud…...

告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略
告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略当开发者尝试在UniApp中实现沉浸式设计时,往往会遇到一个令人头疼的问题——默认的白色安全区和状态栏导致界面元素(如电池图标、信号强度)几乎不可见。…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...

为什么软件开发偏爱 Linux?深度剖析 Linux 相较于 Windows 的核心优势
引言 在软件开发的世界里,一个有趣的现象是:无论是大型互联网公司的服务器集群,还是资深程序员的个人开发机,Linux 操作系统的身影无处不在。与之形成鲜明对比的是,尽管 Windows 在个人消费市场占据绝对主导地位&…...
)
37家金融客户紧急启用的DeepSeek扫描辅助加固包(含未公开API调用密钥策略)
更多请点击: https://kaifayun.com 第一章:DeepSeek漏洞扫描辅助的背景与战略价值 近年来,大模型在安全领域的应用正从辅助问答向深度协同防御演进。DeepSeek系列模型凭借其开源、高推理精度及强代码理解能力,成为构建智能化漏洞…...

当 AI Coding 进入复杂企业系统,为什么提效远没有宣传里那么美好 ?
以 Claude Code、Codex 为代表的自主编码智能体(Coding Agents),正在以惊人的速度席卷软件开发者生态。与此同时,类似“10 倍开发效率”“普通人也能随手构建软件”“程序员即将失业”的说法,也随处可见。这种不分场景…...

交流电机驱动器的三种控制模式:前沿切相、后沿切相与同步模式详解
1. 项目概述:一个能玩出花的交流电机驱动器在汽车改装、工业控制或者一些创客项目里,驱动一个交流电机听起来简单,但想让它听话地变速、正反转,甚至实现软启动和精确同步,往往就得搬出笨重又昂贵的工业变频器。今天分享…...

Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南
Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款专为Adobe Creative Cloud系列软件…...

LeagueAkari:英雄联盟终极自动化助手革命性指南
LeagueAkari:英雄联盟终极自动化助手革命性指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否在英雄联盟游戏中反复经历这…...

告别手动预约:i茅台自动预约系统5分钟部署指南
告别手动预约:i茅台自动预约系统5分钟部署指南 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gitcode…...

基于ATmega328P与TFT屏的园艺环境监控系统:硬件选型与软件架构详解
1. 项目概述:打造你的家庭园艺数据监控中心如果你和我一样,是个喜欢在阳台或后院捣鼓花草的园艺爱好者,同时又对电子DIY有点兴趣,那么这个项目绝对会让你兴奋。我们不是在简单地种花,而是在用数据“聆听”植物的需求。…...