分布式ID生成方案:数据库号段、Redis与第三方开源实现
分布式ID生成方案:数据库号段、Redis与第三方开源实现
引言
在分布式系统中,全局唯一ID生成是核心基础能力之一。本文针对三种主流分布式ID生成方案(数据库号段模式、Redis方案、第三方开源框架)进行解析,从实现原理到实战优劣势全面对比,为技术选型提供可靠依据。
一、基于数据库的号段模式
1.1 核心原理
通过数据库自增特性批量分配ID区间,应用层缓存号段本地消费,实现数据库访问频次大幅降低。
技术实现步骤:
- 创建ID管理表
CREATE TABLE id_generator (biz_tag VARCHAR(64) PRIMARY KEY, -- 业务标识max_id BIGINT NOT NULL, -- 当前最大IDstep INT NOT NULL, -- 号段长度version BIGINT NOT NULL -- 乐观锁版本号
);
- 号段获取流程
public synchronized List<Long> getNextSegment(String bizTag) {// 1. 查询当前号段IdRecord record = selectForUpdate(bizTag);// 2. 计算新号段范围long newMaxId = record.maxId + record.step;// 3. 原子更新数据库updateMaxId(bizTag, newMaxId, record.version);// 4. 返回可用区间return Arrays.asList(record.maxId+1, newMaxId);
}
1.2 关键优化策略
- 双Buffer机制:预加载下一号段,实现无感切换
- 动态步长调整:根据业务压力自动扩容号段大小
- 多实例隔离:通过biz_tag字段支持多业务线
1.3 优劣势对比
| 优势 | 劣势 |
|---|---|
| ✅ 简单易实现 | ❌ 强依赖数据库可用性 |
| ✅ 天然ID趋势递增 | ❌ 号段耗尽可能引发短暂延迟 |
| ✅ 容灾能力强(可重建) | ❌ 需要处理并发更新问题 |
二、基于Redis的ID生成方案
2.1 典型实现方式
方式一:原子计数器
# 生成连续ID
INCR order:id# 集群模式分段
HINCRBY id_pool order 1000
方式二:Snowflake改进版
-- 获取秒级时间戳(支持到2038年)
local ts = redis.call('TIME')[1] -- 获取节点标识(预分配的静态ID)
local node_id = 1001 -- 获取自增序列(自动归零)
local seq = redis.call('INCR', 'global:seq')
if seq > 65535 thenredis.call('SET', 'global:seq', 0)seq = 0
end-- 组合ID
2.2 核心挑战与解决方案
-
持久化问题:
- AOF持久化保证数据不丢失
- 定期快照+最大序列号持久化
-
时钟回拨处理:
- 维护最近时间戳到Redis
- 检测到回拨时自动等待
-
集群扩展方案:
- 基于Hash Slot划分业务区间
- 多节点分段预生成策略
2.3 优劣势对比
| 优势 | 劣势 |
|---|---|
| ✅ 单机10w+ TPS | ❌ 持久化策略影响性能 |
| ✅ 支持灵活数据结构 | ❌ 集群配置复杂度高 |
| ✅ 支持多种ID格式 | ❌ 网络抖动可能引发雪崩 |
三、第三方开源方案解析
3.1 美团Leaf方案
架构组成:
- Leaf-Segment:增强型号段模式
- Leaf-Snowflake:优化雪花算法
核心创新点:
- ZooKeeper协调节点分配
- 时钟回拨解决方案:
if (currentTime < lastTimestamp) {long offset = lastTimestamp - currentTime;if (offset <= 5) {wait(offset << 1);} else {throw new ClockMovedBackwardsException();} }
3.2 百度UidGenerator
核心算法改进:
- 自定义比特分配策略:
| sign | delta seconds | worker node | sequence | | 1bit | 28bits | 22bits | 13bits | - RingBuffer预取机制:
- 双指针无锁化设计
- 填充阈值动态调整策略
3.3 开源方案对比
| 维度 | Leaf | UidGenerator |
|---|---|---|
| 吞吐量 | 10w+/s(号段模式) | 60w+/s |
| 时钟依赖 | 强依赖NTP | 自带时间累积方案 |
| 部署复杂度 | 需ZooKeeper | 纯Java实现 |
| 数据倾斜处理 | 自动rebalance | 固定worker分配 |
四、综合对比与选型建议
4.1 多维度对比矩阵
| 评估维度 | 数据库号段 | Redis方案 | 开源方案 |
|---|---|---|---|
| 性能上限 | 中等 | 高 | 极高 |
| 运维复杂度 | 低 | 中 | 高 |
| 数据可靠性 | 高 | 依赖配置 | 高 |
| 扩展灵活性 | 低 | 中 | 高 |
| 时钟敏感性 | 无 | 无 | 高 |
4.2 场景化选型指南
- 中小型系统:数据库号段模式(日均百万级)
- 高并发场景:Redis集群方案(千万级日订单)
- 金融级系统:Leaf方案(强一致性要求)
- 物联网场景:UidGenerator(海量设备接入)
五、未来演进方向
- 混合模式架构:号段+雪花算法的动态切换
- Serverless化服务:基于云函数的弹性ID服务
实际选型需结合团队技术栈、业务增长预期和运维能力综合评估。建议在预生产环境进行压力测试,重点关注ID服务在网络分区、节点故障等异常场景的表现。
相关文章:

分布式ID生成方案:数据库号段、Redis与第三方开源实现
分布式ID生成方案:数据库号段、Redis与第三方开源实现 引言 在分布式系统中,全局唯一ID生成是核心基础能力之一。本文针对三种主流分布式ID生成方案(数据库号段模式、Redis方案、第三方开源框架)进行解析,从实现原理…...
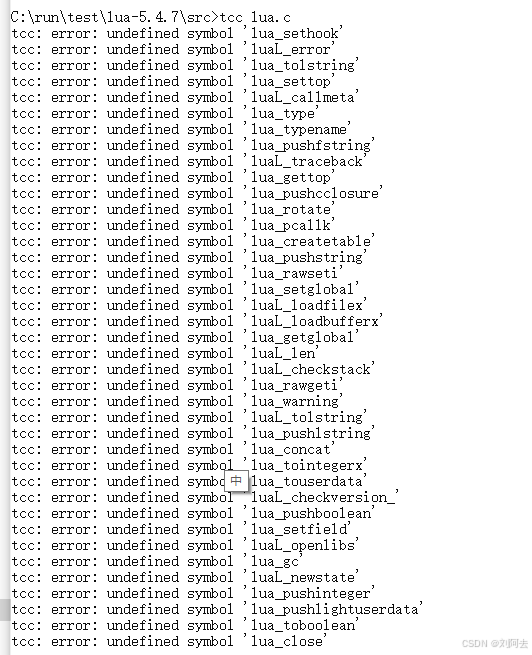
tcc编译器教程2 编译lua解释器
本文主要介绍了使用tcc编译器编译lua解释器源码。 1 介绍 lua是一门编程语言,开源且源码很容易编译,我平时用来测试C语言编程环境时经常使用。一般能编译成功就说明编程环境设置正常。下面用之前设置好的tcc编程环境进行测试。 2 获取源码 我一般有保留多个版本的lua源码进…...
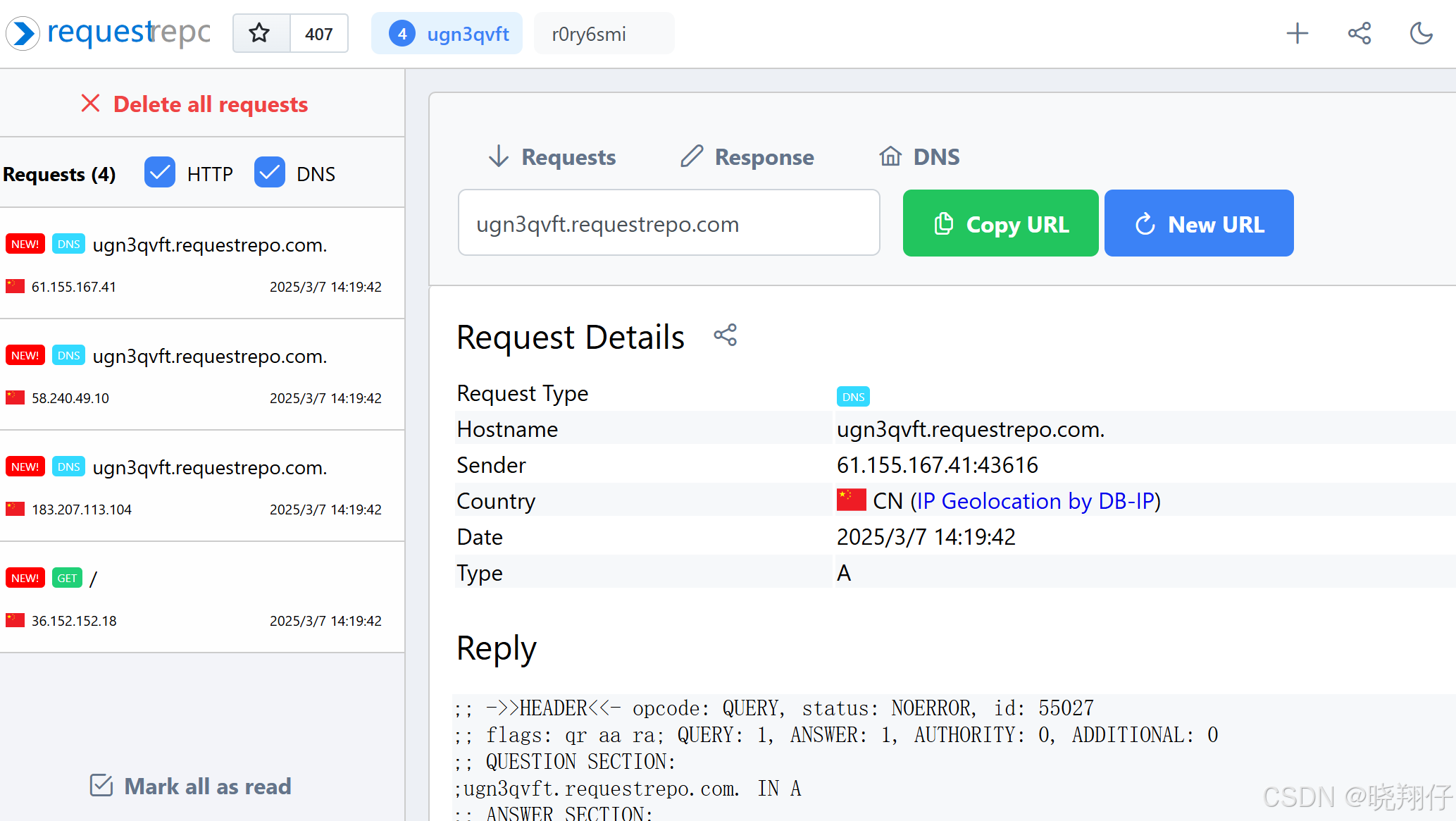
利用 requestrepo 工具验证 XML外部实体注入漏洞
1. 前言 在数字化浪潮席卷的当下,网络安全的重要性愈发凸显。应用程序在便捷生活与工作的同时,也可能暗藏安全风险。XXE(XML外部实体)漏洞作为其中的典型代表,攻击者一旦利用它,便能窃取敏感信息、掌控服务…...

在 Maven 中使用 <scope> 元素:全面指南
目录 前言 在 Maven 中, 元素用于定义依赖项的作用范围,即依赖项在项目生命周期中的使用方式。正确使用 可以帮助我们优化项目的构建过程,减少不必要的依赖冲突,并提高构建效率。本文将详细介绍 的使用步骤、常见作用范围、代码…...

uni_app实现下拉刷新
1. 在页面配置中启用下拉刷新 首先,你需要在页面的 pages.json 文件中启用下拉刷新功能。 {"pages": [{"path": "pages/index/index","style": {"navigationBarTitleText": "首页","enablePull…...

PCIe协议之RCB、MPS、MRRS详解
✨前言: PCIe总线的存储器写请求、存储器读完成等TLP中含有数据负载,即Data Payload。Data Payload的长度和MPS(Max Payload Size)、MRRS(Max Read Request Size)和RCB(Read Completion Bounda…...
达梦数据库在Linux,信创云 安装,备份,还原
(一)系统环境检查 1操作系统:确认使用的是国产麒麟操作系统,检查系统版本是否兼容达梦数据库 V8。可以通过以下命令查看系统版本: cat /etc/os-release 2硬件资源:确保服务器具备足够的硬件资源࿰…...
使用Dockerfile打包java项目生成镜像部署到Linux_java项目打docker镜像的dockerfile
比起容器、镜像来说,Dockerfile 非常普通,它就是一个纯文本,里面记录了一系列的构建指令,比如选择基础镜像、拷贝文件、运行脚本等等,每个指令都会生成一个 Layer,而 Docker 顺序执行这个文件里的所有步骤&…...

爬虫案例九js逆向爬取CBA中国篮球网
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、CBA网站分析二、代码 前言 提示:这里可以添加本文要记录的大概内容: 爬取CBA中国篮球网 提示:以下是本篇文章正文内容…...

【DeepSeek】Ubuntu快速部署DeepSeek(Ollama方式)
文章目录 人人都该学习的DeepSeekDeepSeek不同版本功能差异DeepSeek与硬件直接的关系DeepSeek系统兼容性部署方式选择部署步骤(Ollama方式)1.选定适合的deepseek版本2.环境准备3.安装Ollama4.部署deepseek5.测试使用 人人都该学习的DeepSeek DeepSeek 作…...

C++后端服务器开发技术栈有哪些?有哪些资源或开源库拿来用?
一、 C后台服务器开发是一个涉及多方面技术选择的复杂领域,特别是在高性能、高并发的场景下。以下是C后台服务器开发的一种常见技术路线,涵盖了从基础到高级的技术栈。 1. 基础技术栈 C标准库 C11/C14/C17/C20:使用现代C特性,如…...

基于SpringBoot的餐厅点餐管理系统设计与实现(源码+SQL脚本+LW+部署讲解等)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...
服务端和客户端通信(TCP)
服务端 using System; using System.Collections.Generic; using System.Linq; using System.Net; using System.Net.Sockets; using System.Text; using System.Threading.Tasks;namespace TeachTcpServer {class Program{static void Main(string[] args){#region 知识点一 …...

Java 大视界 -- Java 大数据在智能体育赛事运动员表现分析与训练优化中的应用(122)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

基于Spring Boot的多级缓存架构实现
基于Spring Boot的多级缓存架构实现 以下是一个基于Spring Boot的多级缓存架构实现示例 多级缓存架构实现方案 1. 依赖配置(pom.xml) <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-star…...

Git与GitHub:理解两者差异及其关系
目录 Git与GitHub:理解两者差异及其关系Git:分布式版本控制系统概述主要特点 GitHub:基于Web的托管服务概述主要特点 Git和GitHub如何互补关系现代开发工作流 结论 Git与GitHub:理解两者差异及其关系 Git:分布式版本控…...

ALG(Alloy+Loki+Grafana)轻量级日志系统
ALG(AlloyLokiGrafana)轻量级日志系统 前提要求 GrafanaMinioNginxPrometheus Grafana日志收集系统旧版是PLG(ProtailLokiGrafana), Protail收集日志, Loki存储, Grafana展示, 后续的Protail不维护了, Grafana推出了Alloy代替Pritial, 除了收集日志外, 还集成管理Prometheus各种…...
【漫话机器学习系列】121.偏导数(Partial Derivative)
偏导数(Partial Derivative)详解 1. 引言 在数学分析、机器学习、物理学和工程学中,我们经常会遇到多个变量的函数。这些函数的输出不仅取决于一个变量,而是由多个变量共同决定的。那么,当其中某一个变量发生变化时&…...

Deepseek可以通过多种方式帮助CAD加速工作
自动化操作:通过Deepseek的AI能力,可以编写脚本来自动化重复性任务。例如,使用Python脚本调用Deepseek API,在CAD中实现自动化操作。 插件开发:结合Deepseek进行二次开发,可以创建自定义的CAD插件。例如&a…...
)
【工具使用】IDEA 社区版如何创建 Spring Boot 项目(详细教程)
IDEA 社区版如何创建 Spring Boot 项目(详细教程) Spring Boot 以其简洁、高效的特性,成为 Java 开发的主流框架之一。虽然 IntelliJ IDEA 专业版提供了Spring Boot 项目向导,但 社区版(Community Edition)…...
实战选型指南)
别再乱用分支了!Flowable四种网关(排他/并行/包容/事件)实战选型指南
Flowable四大网关实战选型:从混乱到精准的决策艺术当你在设计一个请假审批流程时,是否遇到过这样的困惑:部门经理审批后需要同时通知HR和财务,但某些特殊情况下又需要跳过财务直接归档?这种看似简单的业务需求…...

混合求解器:用神经网络增强传统微分方程数值方法
1. 项目概述:当数值方法遇到机器学习在科学计算和工程仿真领域,求解常微分方程(ODE)和偏微分方程(PDE)是绕不开的核心任务。无论是模拟电路中的电流变化、预测天气系统的演变,还是分析机械结构的…...

UE4动画蓝图实战:用双骨骼IK节点搞定手部穿模,附完整蓝图节点截图
UE4动画蓝图实战:双骨骼IK节点解决手部穿模的完整指南在角色动画开发中,手部穿模问题堪称"视觉杀手"。想象一下精心设计的角色挥拳时,拳头直接穿过墙壁或敌人身体——这种违和感足以毁掉整个场景的沉浸感。本文将彻底解决这个痛点&…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

极致精简,功能强大的PDF编辑工具
这是一款功能全面的PDF编辑工具 你只需要导入一份PDF格式文件 就可以快速的对它进行插入 批注编辑保护转换等各种操作 而且无需登录 也可以直接使用 在插入选项中可以进行插入文字图片 页面页眉页脚页码文档背景水印视频音频等 在批注选项中可以管理批注隐藏批注 高亮显示 文本…...

FeHelper前端助手:30+开发工具集,让你的浏览器变身效率神器
FeHelper前端助手:30开发工具集,让你的浏览器变身效率神器 【免费下载链接】FeHelper 😍FeHelper--Web前端助手(Awesome!Chrome & Firefox & MS-Edge Extension, All in one Toolbox!) 项目地址:…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...

如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗
如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗 【免费下载链接】react-native-bottom-sheet-behavior react-native wrapper for android BottomSheetBehavior 项目地址: https://gitcode.com/gh_mirrors/re/react-native-bottom…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...

真可用!美团数字人模型开源,MV、电商等统统拿下
美团开源的数字人视频生成框架 LongCat-Video-Avatar 刚刚更新到 1.5 版本。是真能用。这版更新把音频编码器换了,推理步数砍到8步,在770人、13240条主观评分的大规模评测里,雷达图面积全面领先。音频编码器换血,8步出图LongCat-V…...