LSTM方法实践——基于LSTM的汽车销量时序建模与预测分析
Hi,大家好,我是半亩花海。本实验基于汽车销量时序数据,使用LSTM网络(长短期记忆网络)构建时间序列预测模型。通过数据预处理、模型训练与评估等完整流程,验证LSTM在短期时序预测中的有效性。
目录
一、实验目标
二、实验原理
三、实验环境
四、实验步骤
1. 数据预处理
2. 构建时间序列数据集
3. 模型构建与训练
4. 预测与反归一化
5. 结果可视化
6. 模型评估
五、实验分析
1. 评估指标解读
2. 可能的原因分析
3. 改进方法
六、完整代码
一、实验目标
本实验基于汽车销量时序数据,构建LSTM神经网络模型,实现对时间序列数据的预测,并通过可视化和评估指标验证模型性能。实验目标包括:
- 掌握时间序列数据的预处理方法
- 理解LSTM网络的工作原理
- 构建端到端的时序预测模型
- 评估模型预测性能
二、实验原理
1. 核心算法:LSTM网络
长短期记忆 (Long Short-Term Memory, LSTM) 是一种时间递归神经网络(RNN),它是一种基于机器学习理论的循环网络时间序列预测方法。该模型可有效处理并解决RNN中人为很难实现的延长时间任务的问题,并预测时间序列中间隔和延迟非常长的重要事件,同时削减了RNN中梯度消失问题对预测研究的影响,总的来说LSTM模型是一种特殊的RNN循环神经网络。
RNN循环神经网络结构如图所示。

LSTM的网络结构大概为:单层LSTM(5个神经元)+ 全连接层,输入形状为(时间步长=1, 特征数=1)。LSTM网络结构如图所示。


(1)输入门(Input gate)的计算:
![]()
(2)遗忘门(Forget gate)的计算:
![]()
(3)候选记忆单元的计算:
![]()
(4)记忆单元状态更新的计算:
![]()
(5)输出门的计算:
![]()
(6)隐藏状态(output)的计算:
![]()
2. 关键技术实现
- 数据归一化:使用
MinMaxScaler将数据缩放到[0,1]区间,加速模型收敛。 - 时间序列建模:通过滑动窗口法(
look_back=1)将数据转换为监督学习格式,每个样本包含1个时间步的历史数据。 - 模型训练:采用Adam优化器和均方误差损失函数,训练150轮,批量大小为2。
三、实验环境
| 项目 | 配置/版本 |
|---|---|
| Python | 3.8+(3.8.20) |
| TensorFlow | 2.10.0 |
| 主要库 | numpy(1.21.6), matplotlib(3.6.3), pandas(1.4.4), scikit-learn(1.1.3), pillow(10.4.0) |
| 硬件环境 | CPU/GPU |
四、实验步骤
1. 数据预处理
(1)数据加载与清洗
# 加载数据(取第2列,跳过末尾3行)
dataframe = pd.read_csv("D:\Python_demo\Time Series\LSTM\car.csv", usecols=[1], skipfooter=3)- 选取CSV文件第2列数据(销量数据)
- 跳过末尾3行异常数据
- 转换为float32类型保证数值精度
(2)数据归一化
dataset = scaler.fit_transform(dataframe.values.astype('float32'))- 使用MinMaxScaler进行0-1归一化
- 消除量纲影响,加速模型收敛
- 公式:
(3)数据集划分
# 划分训练集与测试集(8:2)
train_size = int(len(dataset) * 0.80)
trainlist, testlist = dataset[:train_size], dataset[train_size:]- 按8:2比例划分训练/测试集
- 保持时序连续性,避免随机划分
2. 构建时间序列数据集
def create_dataset(dataset, look_back):dataX, dataY = [], []for i in range(len(dataset) - look_back - 1):a = dataset[i:(i + look_back)] # 取look_back长度的历史数据dataX.append(a)dataY.append(dataset[i + look_back]) # 预测下一个时间点的值return np.array(dataX), np.array(dataY)# 设置时间步长(这里使用1步预测)
look_back = 1
trainX, trainY = create_dataset(trainlist, look_back)
testX, testY = create_dataset(testlist, look_back)# 调整输入格式(LSTM需要[样本数, 时间步, 特征数]的3D张量)
trainX = np.reshape(trainX, (trainX.shape[0], look_back, 1))
testX = np.reshape(testX, (testX.shape[0], look_back, 1))
- 滑动窗口法 :
look_back=1表示用当前时刻数据预测下一时刻值。 - 输入维度 :LSTM要求输入为3D张量,此处形状为
(样本数, 1, 1)。
3. 模型构建与训练
# 构建LSTM模型
model = Sequential() # 创建序列模型
model.add(LSTM(5, input_shape=(look_back, 1))) # 添加LSTM层(5个神经元,输入形状为(时间步=1, 特征数=1))
model.add(Dense(1)) # 添加全连接输出层
model.compile(loss='mean_squared_error', optimizer='adam') # 编译模型(均方误差损失,Adam优化器)
model.fit(trainX, trainY, epochs=150, batch_size=2, verbose=2) # 训练模型(100轮,批量大小2)
- 损失函数 :均方误差(MSE)适用于回归任务。
- 优化器 :Adam动态调整学习率,平衡收敛速度与精度。
- 超参数选择 :小批量(batch_size=2)训练适合小数据集。
4. 预测与反归一化
# 对训练集和测试集进行预测
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)# 反归一化(将预测结果还原到原始数据范围)
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform(trainY)
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform(testY)- 反归一化 :将预测结果还原到原始数据范围,便于计算真实误差。
5. 结果可视化
# 绘制训练集结果
plt.figure(figsize=(10, 6))
plt.plot(trainY, label="训练实际数据", color="#FF3B1D", marker='*', linestyle="--")
plt.plot(trainPredict[1:], label="训练预测数据", color="#F9A602", marker='*', linestyle="--")
plt.title("训练集预测效果")
plt.xlabel('时间步')
plt.ylabel('数值')
plt.legend()
plt.show()# 绘制测试集结果
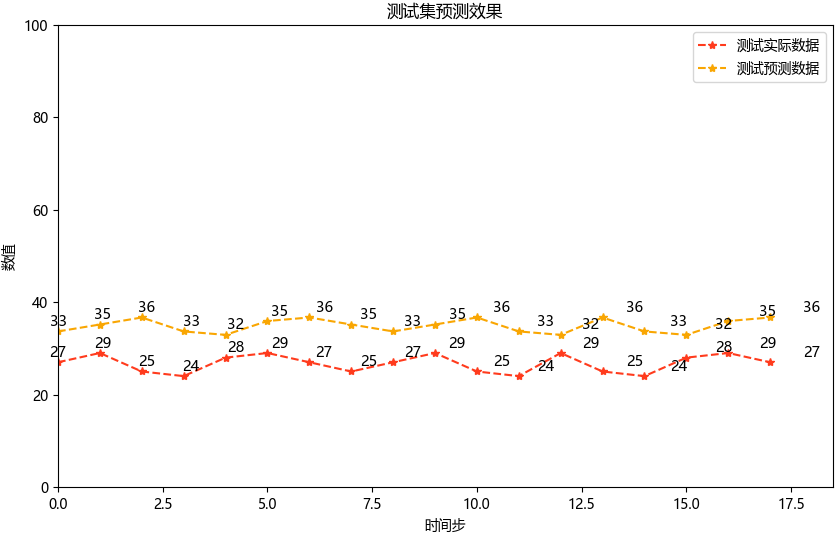
plt.figure(figsize=(10, 6))
xx = np.linspace(0, len(testY), len(testY))
plt.plot(testY, label="测试实际数据", color="#FF3B1D", marker='*', linestyle="--")
plt.plot(testPredict, label="测试预测数据", color="#F9A602", marker='*', linestyle="--")
plt.title("测试集预测效果")
plt.xlabel('时间步')
plt.ylabel('数值')
plt.xlim(0, 18.5)
plt.ylim(0, 100)
plt.legend()# 添加数据标签
for x, y in zip(xx, testY):plt.text(x, y + 0.3, int(y), ha='center', va='bottom', fontsize=10.5)
for x, y in zip(xx, testPredict):plt.text(x, y + 0.3, int(y), ha='center', va='bottom', fontsize=10.5)plt.show()
- 坐标轴限制 :根据测试集数据范围手动设置,避免自动缩放失真。
- 数据标签 :通过
plt.text()标注具体数值,增强可读性。


6. 模型评估
| 指标 | 公式 |
|---|---|
| MAE(Mean Absolute Error,平均绝对误差) | |
| RMSE(Root Mean Squared Error,均方根误差) | |
| R²(Coefficient of Determination,决定系数) | |
# 计算评估指标
mae = mean_absolute_error(testPredict, testY)
rmse = np.sqrt(mean_squared_error(testPredict, testY))
r2 = r2_score(testPredict, testY)print('测试集评估指标:')
print('MAE: %.3f' % mae)
print('RMSE: %.3f' % rmse)
print('R²: %.3f' % r2)
| 指标 | 计算结果 | 意义 |
|---|---|---|
| MAE | 6.397 | 预测值与真实值的平均绝对误差,表明平均预测误差约4.85个单位 |
| RMSE | 6.818 | 对较大误差更敏感的均方根误差 |
| R² | -25.777 | 模型解释了一定的数据方差,说明模型的解释力 |
五、实验分析
1. 评估指标解读
(1)MAE(Mean Absolute Error,平均绝对误差)
- 值:6.397
- 解释:平均绝对误差表示预测值与真实值之间的平均差距为6.397。
- 评价:MAE值本身并不算特别大,但需要结合数据的实际范围来判断。如果汽车销量数据的范围是几十到几百,则6.397的误差可能偏高。
(2)RMSE(Root Mean Squared Error,均方根误差)
- 值:6.818
- 解释:均方根误差对较大的误差更敏感,其值比MAE稍高,说明可能存在一些较大的预测偏差。
- 评价:RMSE略高于MAE,说明误差分布中存在一些较大的异常值。
(3)R²(Coefficient of Determination,决定系数)
- 值:-25.777
- 解释:R²衡量模型对数据方差的解释能力,理想值为1,负值表示模型的预测效果比直接用均值预测还要差。
- 评价 :R²为负数是一个严重的警告信号,说明模型几乎完全无法捕捉数据的趋势,甚至可能在某些情况下“反向预测”。
2. 可能的原因分析
(1)数据质量问题
①数据量不足:如果训练数据太少,模型可能无法学习到有效的模式。
②数据噪声过多:汽车销量数据可能存在大量随机波动或异常值,导致模型难以拟合。
③非平稳性:时间序列数据可能存在趋势或季节性成分,而模型未对其进行处理。
(2)模型设计问题
①LSTM结构过于简单
- 单层LSTM(仅5个神经元)可能不足以捕捉复杂的时序关系。
- 时间步长
look_back=1限制了模型利用历史信息的能力。
②超参数设置不当
- 训练轮次(epochs=150)可能过多或过少。
- 批量大小(batch_size=2)可能导致梯度更新不稳定。
(3)数据预处理问题
①归一化范围不合适:虽然使用了MinMaxScaler,但如果数据分布不均匀,归一化可能放大噪声。
②滑动窗口法不足:look_back=1仅使用最近一个时间点的数据进行预测,可能忽略长期依赖关系。
(4)测试集划分问题
①训练集和测试集分布不一致:如果测试集包含了训练集中未见过的模式(如突然的销量激增或下降),模型可能表现不佳。
②数据泄露:确保测试集数据没有被意外用于训练。
3. 改进方法
(1)数据质量优化
①检查数据完整性 :确认数据无缺失值或异常值,并剔除明显的噪声点。
②平滑处理 :对原始数据进行移动平均或其他平滑操作,减少短期波动的影响。
③分解时间序列 :使用STL分解等方法提取趋势和季节性成分,分别建模。
(2)模型结构调整
①增加LSTM层数和神经元数量
model.add(LSTM(50, return_sequences=True, input_shape=(look_back, 1))) # 第一层LSTM
model.add(LSTM(50)) # 第二层LSTM
model.add(Dense(1)) # 输出层我后续只修改了这一项,得出结果如下,感觉只有训练集效果稍微好了一些。

②调整时间步长 :尝试look_back=3或更高值,以利用更多历史信息。
③添加Dropout层 :防止过拟合,例如:
from tensorflow.keras.layers import Dropout
model.add(Dropout(0.2))(3)超参数调优
①学习率调整 :尝试不同的学习率(如0.001或0.01)。
②批量大小优化 :将batch_size调整为更大的值(如16或32)。
③早停机制 :避免过拟合,使用EarlyStopping回调函数:
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(monitor='val_loss', patience=10)
model.fit(trainX, trainY, epochs=200, batch_size=16, validation_split=0.2, callbacks=[early_stopping])(4)数据预处理改进
①标准化代替归一化 :如果数据分布较广,可以尝试StandardScaler(均值为0,标准差为1)。
②特征工程 :引入额外特征(如节假日、促销活动等)增强模型输入。
(5)测试集验证
①交叉验证 :使用时间序列交叉验证(TimeSeriesSplit)评估模型性能。
②重新划分数据集 :确保训练集和测试集分布一致,避免数据泄露。
六、完整代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@Project : Time Series/LSTM/LSTM_car
@File : LSTM_car.py
@IDE : PyCharm
@Author : 半亩花海
@Date : 2025/03/10 17:36
"""
# ===================================
# 导入必要库
# ===================================
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.layers import Dense, LSTM
from tensorflow.keras.models import Sequential, load_model
import tensorflow as tf# 禁用eager模式(兼容旧版本TensorFlow)
tf.compat.v1.disable_eager_execution()# 设置中文字体显示
matplotlib.rcParams['font.sans-serif'] = ['Microsoft YaHei']
matplotlib.rcParams['font.serif'] = ['Microsoft YaHei']
matplotlib.rcParams['axes.unicode_minus'] = False# ===================================
# 数据预处理
# ===================================
# 加载数据(取第2列数据,跳过末尾3行)
dataframe = pd.read_csv(r"D:\Python_demo\Time Series\LSTM\car.csv", usecols=[1], engine='python', skipfooter=3)
dataset = dataframe.values# 数据类型转换
dataset = dataset.astype('float32')# 数据归一化(0-1范围)
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)# 划分训练集和测试集(8:2比例)
train_size = int(len(dataset) * 0.80)
trainlist = dataset[:train_size]
testlist = dataset[train_size:]# ===================================
# 构建时间序列数据集
# ===================================
def create_dataset(dataset, look_back):"""将时间序列数据转换为监督学习格式:param dataset: 原始数据集:param look_back: 时间步长(使用多少历史数据预测):return: 输入特征X和目标值Y"""dataX, dataY = [], []for i in range(len(dataset) - look_back - 1):a = dataset[i:(i + look_back)] # 取look_back长度的历史数据dataX.append(a)dataY.append(dataset[i + look_back]) # 预测下一个时间点的值return np.array(dataX), np.array(dataY)# 设置时间步长(这里使用1步预测)
look_back = 1
trainX, trainY = create_dataset(trainlist, look_back)
testX, testY = create_dataset(testlist, look_back)# 调整输入格式(LSTM需要[样本数, 时间步, 特征数]的3D张量)
trainX = np.reshape(trainX, (trainX.shape[0], look_back, 1))
testX = np.reshape(testX, (testX.shape[0], look_back, 1))# ===================================
# 构建和训练LSTM模型
# ===================================
# 构建LSTM模型
model = Sequential() # 创建序列模型
model.add(LSTM(5, input_shape=(look_back, 1))) # 添加LSTM层(5个神经元,输入形状为(时间步=1, 特征数=1))
model.add(Dense(1)) # 添加全连接输出层
model.compile(loss='mean_squared_error', optimizer='adam') # 编译模型(均方误差损失,Adam优化器)
model.fit(trainX, trainY, epochs=150, batch_size=2, verbose=2) # 训练模型(100轮,批量大小2)# 保存并加载模型
model_path = r"D:\Python_demo\Time Series\LSTM\lstm_model.h5"
model.save(model_path)
model = load_model(model_path)# ===================================
# 预测与反归一化
# ===================================
# 对训练集和测试集进行预测
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)# 反归一化(将预测结果还原到原始数据范围)
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform(trainY)
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform(testY)# ===================================
# 可视化结果
# ===================================
# 绘制训练集结果
plt.figure(figsize=(10, 6))
plt.plot(trainY, label="训练实际数据", color="#FF3B1D", marker='*', linestyle="--")
plt.plot(trainPredict[1:], label="训练预测数据", color="#F9A602", marker='*', linestyle="--")
plt.title("训练集预测效果")
plt.xlabel('时间步')
plt.ylabel('数值')
plt.legend()
plt.show()# 绘制测试集结果
plt.figure(figsize=(10, 6))
xx = np.linspace(0, len(testY), len(testY))
plt.plot(testY, label="测试实际数据", color="#FF3B1D", marker='*', linestyle="--")
plt.plot(testPredict, label="测试预测数据", color="#F9A602", marker='*', linestyle="--")
plt.title("测试集预测效果")
plt.xlabel('时间步')
plt.ylabel('数值')
plt.xlim(0, 18.5)
plt.ylim(0, 100)
plt.legend()# 添加数据标签
for x, y in zip(xx, testY):plt.text(x, y + 0.3, int(y), ha='center', va='bottom', fontsize=10.5)
for x, y in zip(xx, testPredict):plt.text(x, y + 0.3, int(y), ha='center', va='bottom', fontsize=10.5)plt.show()# ===================================
# 模型评估
# ===================================
# 计算评估指标
mae = mean_absolute_error(testPredict, testY)
rmse = np.sqrt(mean_squared_error(testPredict, testY))
r2 = r2_score(testPredict, testY)print('测试集评估指标:')
print('MAE: %.3f' % mae)
print('RMSE: %.3f' % rmse)
print('R²: %.3f' % r2)
相关文章:
LSTM方法实践——基于LSTM的汽车销量时序建模与预测分析
Hi,大家好,我是半亩花海。本实验基于汽车销量时序数据,使用LSTM网络(长短期记忆网络)构建时间序列预测模型。通过数据预处理、模型训练与评估等完整流程,验证LSTM在短期时序预测中的有效性。 目录 一、实验…...
微服务——网关、网关登录校验、OpenFeign传递共享信息、Nacos共享配置以及热更新、动态路由
之前学习了Nacos,用于发现并注册、管理项目里所有的微服务,而OpenFeign简化微服务之间的通信,而为了使得前端可以使用微服务项目里的每一个微服务的接口,就应该将所有微服务的接口管理起来方便前端调用,所以有了网关。…...
【数据结构】二叉搜索树、平衡搜索树、红黑树
二叉搜索树(Binary Search Tree) 二叉搜索树是一种特殊的二叉树,它用来快速搜索某个值,对于每个节点都应该满足以下条件: 若该节点有左子树,那么左子树中所有节点的值都应该小于该节点的值。若该节点有右…...

Spring Boot 解析 LocalDateTime 失败?Uniapp 传输时间变 1970 的原因与解决方案
目录 前言1. 问题分析2. 时间戳(推荐,可尝试)3. 使用 JsonDeserialize & JsonSerialize(中立)4. 前端传 ISO-8601 格式(不推荐,可尝试)5. 用 String(中立)…...
)
Xilinx ZYNQ FSBL解读:LoadBootImage()
篇首 最近突发奇想,Xilinx 的集成开发环境已经很好了,很多必要的代码都直接生成了,这给开发者带来了巨大便利的同时,也让人错过了很多代码的精彩,可能有很多人用了很多年了,都还无法清楚的理解其中过程。博…...

mysql中in和exists的区别?
大家好,我是锋哥。今天分享关于【mysql中in和exists的区别?】面试题。希望对大家有帮助; mysql中in和exists的区别? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在 MySQL 中,IN 和 EXISTS 都用于进行子查询,但它…...

oracle 数据导出方案
工作中有遇到需要将oracle 数据库表全部导出,还需要去除表数据中的换行符。 方案 shell 设计 封装函数 1 function con_oracle() 用于连接oracle 2 function send_file() 用于发送文件 3 主程序 使用循环将所有表导出并发送到数据服务器 主程序 程序代码 #!…...

Apache Commons Lang3 和 Commons Net 详解
目录 1. Apache Commons Lang3 1.1 什么是 Apache Commons Lang3? 1.2 主要功能 1.3 示例代码 2. Commons Net 2.1 什么是 Commons Net? 2.2 主要功能 2.3 示例代码 3. 总结 3.1 Apache Commons Lang3 3.2 Commons Net 3.3 使用建议 4. 参考…...
从0开始的操作系统手搓教程33:挂载我们的文件系统
目录 代码实现 添加到初始化上 上电看现象 挂载分区可能是一些朋友不理解的——实际上挂载就是将我们的文件系统封装好了的设备(硬盘啊,SD卡啊,U盘啊等等),挂到我们的默认分区路径下。这样我们就能访问到了ÿ…...

【Linux】36.简单的TCP网络程序
文章目录 1. TCP socket API 详解1.1 socket():打开一个网络通讯端口1.2 bind():绑定一个固定的网络地址和端口号1.3 listen():声明sockfd处于监听状态1.4 accept():接受连接1.5 connect():连接服务器 2. 实现一个TCP网络服务器2.1 Log.hpp - "多级日志系统"2.2 Daem…...

时序分析
1、基本概念介绍 1.1、 建立时间 T(su) 建立时间:setup time,它是指有效的边沿信号到来之前,输入端口数据保持稳定的时间。 1.1.1、 建立时间要求: 建立时间要求指的是 想要寄存器如期的工作,在有效时…...

doris:ClickHouse
Doris JDBC Catalog 支持通过标准 JDBC 接口连接 ClickHouse 数据库。本文档介绍如何配置 ClickHouse 数据库连接。 使用须知 要连接到 ClickHouse 数据库,您需要 ClickHouse 23.x 或更高版本 (低于此版本未经充分测试)。 ClickHouse 数据库的 JDBC 驱动程序&a…...
-关系抽取(Relation Extraction, RE)任务训练模板)
NLP常见任务专题介绍(1)-关系抽取(Relation Extraction, RE)任务训练模板
📌 关系抽取(Relation Extraction, RE)任务训练示例 本示例展示如何训练一个关系抽取模型,以识别两个实体之间的关系。 1️⃣ 任务描述 目标:从文本中提取两个实体之间的语义关系,例如 “人物 - 组织”、“药物 - 疾病”、“公司 - 创始人” 等。输入:句子 + 标注的实…...

大模型Transformer的MOE架构介绍及方案整理
前言:DeepSeek模型最近引起了NLP领域的极大关注,也让大家进一步对MOE(混合专家网络)架构提起了信心,借此机会整理下MOE的简单知识和对应的大模型。本文的思路是MOE的起源介绍、原理解释、再到现有MOE大模型的整理。 一…...

零基础掌握Linux SCP命令:5分钟实现高效文件传输,小白必看!
引言 “为什么我传个文件到服务器要折腾半小时?” 如果你也曾在Linux系统中为文件传输抓狂,今天这篇保姆级教程就是你的救星!SCP命令——一个基于SSH协议的高效传输工具,只需5分钟,彻底告别FTP客户端和繁琐操作&#…...
分类评价指标
基础概念解释 TP、TN、FP、FN 这里T是True,F是False,P为Positive,N为Negative TP:被模型正确地预测为正样本(原本为正样本,预测为正样本) TN:被模型正确地预测为负样本࿰…...

Python项目-基于Django的在线教育平台开发
1. 项目概述 在线教育平台已成为现代教育的重要组成部分,特别是在后疫情时代,远程学习的需求显著增加。本文将详细介绍如何使用Python的Django框架开发一个功能完善的在线教育平台,包括系统设计、核心功能实现以及部署上线等关键环节。 本项…...

子数组问题——动态规划
个人主页:敲上瘾-CSDN博客 动态规划 基础dp:基础dp——动态规划-CSDN博客多状态dp:多状态dp——动态规划-CSDN博客 目录 一、解题技巧 二、最大子数组和 三、乘积最大子数组 四、最长湍流子数组 五、单词拆分 一、解题技巧 区分子数组&…...

linux设置pem免密登录和密码登录
其实现在chatgpt 上面很多东西问题都可以找到比较好答案了,最近换了一个服务器,记录一下。 如果设置root用户,就直接切换到cd .ssh目录下生成ssh key即可,不需要创建用户创建用户的ssh文件夹了 比如说我要让danny这个用户可以用p…...

什么是Flask
Flask是Python中一个简单、灵活和易用的Web框架,适合初学者使用。它提供了丰富的功能和扩展性,可以帮助开发者快速构建功能完善的Web应用程序。 以下是Python Flask框架的一些特点和功能: Flask 是一个使用 Python 编写的轻量级 WSGI 微 Web…...
)
从协议到代码:用Python仿真5G NR下行同步全流程(含PBCH解码与MIB解析)
从协议到代码:用Python仿真5G NR下行同步全流程(含PBCH解码与MIB解析) 在通信系统设计中,下行同步是终端接入网络的第一步关键操作。5G新空口(NR)技术引入了更复杂的同步信号结构,这对算法工程师和研究人员提出了更高要…...

5大优化技巧:让ComfyUI-Manager在低配置设备上流畅运行
5大优化技巧:让ComfyUI-Manager在低配置设备上流畅运行 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various cust…...

脉冲神经网络SAST训练方法:解决代理-硬件转换差距
1. 脉冲神经网络与传感器计算的挑战脉冲神经网络(SNNs)作为第三代神经网络模型,其核心特征是采用离散的脉冲信号进行信息传递和处理。这种事件驱动的计算方式与传统的连续激活神经网络(ANNs)有着本质区别。在传感器端计…...

为AI智能体构建持久化记忆系统:Shang Tsung项目实战解析
1. 项目概述:为AI智能体注入“灵魂”与“第二大脑”如果你和我一样,长期与各类AI智能体(Agent)打交道,无论是基于Claude Code、OpenClaw,还是其他本地化部署的LLM工具,你一定经历过那种令人沮丧…...

[具身智能-680]:ROS2 可视化与调试工具与示例
按日常开发必用分类,每条可直接复制运行,新手也能马上上手。一、3D 可视化工具1. rviz2(核心 3D 可视化)功能查看:机器人模型、激光雷达、点云、地图、TF 坐标、导航路径、相机图像、机械臂、代价地图等。启动bash运行…...
/瑞芯微刷机驱动(DriverAssitant)_多个版本下载及教程分享)
瑞芯微刷机工具(RKDevTool)/瑞芯微刷机驱动(DriverAssitant)_多个版本下载及教程分享
瑞芯微刷机工具(RKDevTool)/瑞芯微刷机驱动(DriverAssitant)_多个版本下载及教程分享 适合(处理器是RK字母开头的芯片),比如RK3128、RK3188、RK3229、RK3288、RK3368、RK3328、RK3399、RK3528、RK3568、RK3566、RK3588等等瑞芯微芯…...

技术决策的后悔药:选型错误后的补救策略
在软件测试的全生命周期中,技术选型是影响测试效率、质量与项目成败的关键环节。小到一款测试工具的挑选,大到整个测试框架的搭建,每一次决策都如同在迷雾中航行,稍有不慎便可能驶入“选型错误”的漩涡。当测试环境兼容性问题频发…...

从ADI收购LTC看电源管理趋势:软件定义电源与能量收集技术解析
1. 从一笔天价收购案,看电源管理技术的未来十年2016年,模拟芯片行业发生了一场地震级的并购:模拟巨头亚德诺半导体(Analog Devices Inc., ADI)以148亿美元的天价,收购了以高性能模拟芯片闻名的凌力尔特&…...

题目五:抽象类 + 接口 混合实现
编程要求:抽象类 Machine:抽象方法 work(),普通方法 start();接口 Clean:抽象方法 clean();类 Robot继承抽象类 Machine 实现接口 Clean;实现所有未实现的方法;测试创建机器人对象&…...

从零到一:手把手教你搭建MinGW-w64开发环境
1. 为什么需要MinGW-w64开发环境 第一次在Windows上写C代码时,我踩了个大坑:好不容易写完的代码,发现根本没法编译运行。这才意识到Windows不像Linux自带GCC编译器,需要额外搭建开发环境。MinGW-w64就是解决这个问题的神器&#x…...