大数据框架之Hadoop:HDFS(三)HDFS客户端操作(开发重点)
3.1 HDFS客户端环境准备
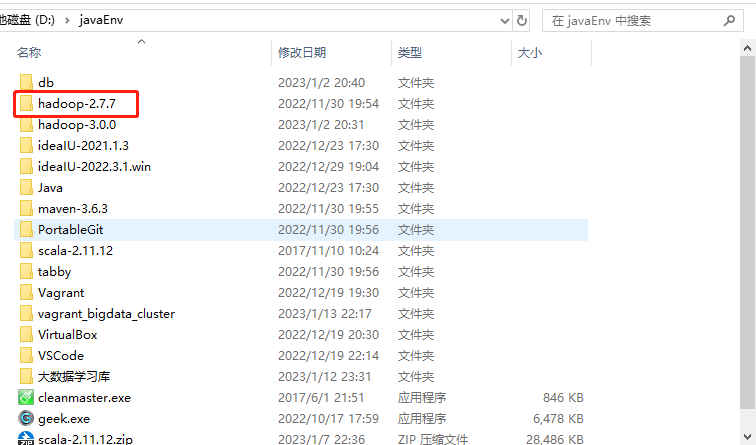
1.根据自己电脑的操作系统拷贝对应的编译后的hadoop jar包到非中文路径(例如:D:\javaEnv\hadoop-2.77),如下图所示。
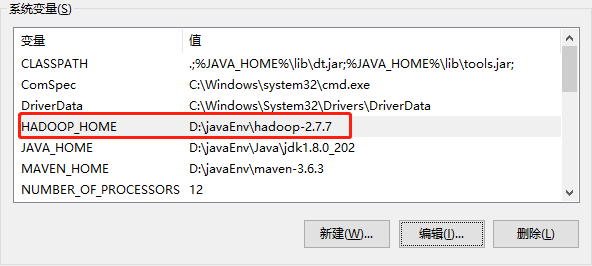
2.配置HADOOP_HOME环境变量,如下图所示。
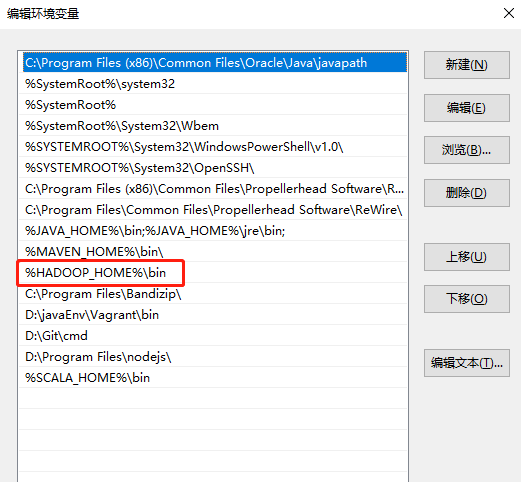
3.配置Path环境变量,如下图所示。
4.创建一个Maven工程HdfsClientDemo
5.导入相应的依赖坐标+日志添加
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>RELEASE</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.8.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.7</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.7</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.7.7</version></dependency><dependency><groupId>jdk.tools</groupId><artifactId>jdk.tools</artifactId><version>1.8</version><scope>system</scope><systemPath>${JAVA_HOME}/lib/tools.jar</systemPath></dependency>
</dependencies>
注意:如果Eclipse/Idea打印不出日志,在控制台上只显示
1.log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
2.log4j:WARN Please initialize the log4j system properly.
3.log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
需要在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
6.创建包名:com.atguigu.hdfs
7.创建HdfsClient类
public class HdfsClient{@Testpublic void testMkdirs() throws IOException, InterruptedException, URISyntaxException {// 1 获取文件系统Configuration configuration = new Configuration();// 配置在集群上运行// configuration.set("fs.defaultFS", "hdfs://hdp101:9000");// FileSystem fs = FileSystem.get(configuration);FileSystem fs = FileSystem.get(new URI("hdfs://hdp101:9000"), configuration, "root");// 2 创建目录fs.mkdirs(new Path("/1108/daxian/banzhang"));// 3 关闭资源fs.close();}
}
8.执行程序
运行时需要配置用户名称,如图3-7所示
客户端去操作HDFS时,是有一个用户身份的。默认情况下,HDFS客户端API会从JVM中获取一个参数来作为自己的用户身份:-DHADOOP_USER_NAME=root,root为用户名称。
3.2HDFS的API操作
3.2.1HDFS文件上传(测试参数优先级)
1.编写源代码
@Test
public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {// 1 获取文件系统Configuration configuration = new Configuration();configuration.set("dfs.replication", "2");FileSystem fs = FileSystem.get(new URI("hdfs://hdp101:9000"), configuration, "root");// 2 上传文件fs.copyFromLocalFile(new Path("e:/banzhang.txt"), new Path("/banzhang.txt"));// 3 关闭资源fs.close();System.out.println("over");
}
2.将hdfs-site.xml拷贝到项目的根目录下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>dfs.replication</name><value>1</value></property>
</configuration>
3.参数优先级
参数优先级排序:(1)客户端代码中设置的值 >(2)ClassPath下的用户自定义配置文件 >(3)然后是服务器的默认配置
3.2.2HDFS文件下载
@Test
public void testCopyToLocalFile() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hdp101:9000"), configuration, "root");// 2 执行下载操作// boolean delSrc 指是否将原文件删除// Path src 指要下载的文件路径// Path dst 指将文件下载到的路径// boolean useRawLocalFileSystem 是否开启文件校验fs.copyToLocalFile(false, new Path("/banzhang.txt"), new Path("e:/banhua.txt"), true);// 3 关闭资源fs.close();
}
3.2.3HDFS文件夹删除
@Test
public void testDelete() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hdp101:9000"), configuration, "root");// 2 执行删除fs.delete(new Path("/1108/"), true);// 3 关闭资源fs.close();
}
3.2.4 HDFS文件名更改
@Test
public void testRename() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hdp101:9000"), configuration, "root");// 2 修改文件名称fs.rename(new Path("/banzhang.txt"), new Path("/banhua.txt"));// 3 关闭资源fs.close();
}
3.2.5HDFS文件详情查看
@Test
public void testListFiles() throws IOException, InterruptedException, URISyntaxException{// 1获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hdp101:9000"), configuration, "root");// 2 获取文件详情RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);while(listFiles.hasNext()){LocatedFileStatus status = listFiles.next();// 输出详情// 文件名称System.out.println(status.getPath().getName());// 长度System.out.println(status.getLen());// 权限System.out.println(status.getPermission());// 分组System.out.println(status.getGroup());// 获取存储的块信息BlockLocation[] blockLocations = status.getBlockLocations();for (BlockLocation blockLocation : blockLocations) {// 获取块存储的主机节点String[] hosts = blockLocation.getHosts();for (String host : hosts) {System.out.println(host);}}System.out.println("-----------班长的分割线----------");}// 3 关闭资源fs.close();
}
3.2.6HDFS文件和文件夹判断
@Test
public void testListStatus() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件配置信息Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hdp101:9000"), configuration, "root");// 2 判断是文件还是文件夹FileStatus[] listStatus = fs.listStatus(new Path("/"));for (FileStatus fileStatus : listStatus) {// 如果是文件if (fileStatus.isFile()) {System.out.println("f:"+fileStatus.getPath().getName());}else {System.out.println("d:"+fileStatus.getPath().getName());}}// 3 关闭资源fs.close();
}
3.3 HDFS的I/O流操作
上面我们学的API操作HDFS系统都是框架封装好的。那么如果我们想自己实现上述API的操作该怎么实现呢?
我们可以采用IO流的方式实现数据的上传和下载。
3.3.1HDFS文件上传
1.需求:把本地e盘上的banhua.txt文件上传到HDFS根目录
2.编写代码
@Test
public void putFileToHDFS() throws IOException, InterruptedException, URISyntaxException {// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hdp101:9000"), configuration, "root");// 2 创建输入流FileInputStream fis = new FileInputStream(new File("e:/banzhang.txt"));// 3 获取输出流FSDataOutputStream fos = fs.create(new Path("/banhua.txt"));// 4 流对拷IOUtils.copyBytes(fis, fos, configuration);// 5 关闭资源IOUtils.closeStream(fos);IOUtils.closeStream(fis);fs.close();
}
3.3.2HDFS文件下载
1.需求:从HDFS上下载banhua.txt文件到本地e盘上
2.编写代码
// 文件下载
@Test
public void getFileFromHDFS() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hdp101:9000"), configuration, "root");// 2 获取输入流FSDataInputStream fis = fs.open(new Path("/banhua.txt"));// 3 获取输出流FileOutputStream fos = new FileOutputStream(new File("e:/banhua.txt"));// 4 流的对拷IOUtils.copyBytes(fis, fos, configuration);// 5 关闭资源IOUtils.closeStream(fos);IOUtils.closeStream(fis);fs.close();
}
3.3.3定位文件读取
1.需求:分块读取HDFS上的大文件,比如根目录下的/hadoop-2.7.2.tar.gz
2.编写代码
(1)下载第一块
@Test
public void readFileSeek1() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hdp101:9000"), configuration, "root");// 2 获取输入流FSDataInputStream fis = fs.open(new Path("/hadoop-2.7.7.tar.gz"));// 3 创建输出流FileOutputStream fos = new FileOutputStream(new File("e:/hadoop-2.7.7.tar.gz.part1"));// 4 流的拷贝byte[] buf = new byte[1024];for(int i =0 ; i < 1024 * 128; i++){fis.read(buf);fos.write(buf);}// 5关闭资源IOUtils.closeStream(fis);IOUtils.closeStream(fos);fs.close();
}
(2)下载第二块
@Test
public void readFileSeek2() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hdp101:9000"), configuration, "root");// 2 打开输入流FSDataInputStream fis = fs.open(new Path("/hadoop-2.7.7.tar.gz"));// 3 定位输入数据位置fis.seek(1024*1024*128);// 4 创建输出流FileOutputStream fos = new FileOutputStream(new File("e:/hadoop-2.7.7.tar.gz.part2"));// 5 流的对拷IOUtils.copyBytes(fis, fos, configuration);// 6 关闭资源IOUtils.closeStream(fis);IOUtils.closeStream(fos);
}
(3)合并文件
在Window命令窗口中进入到目录E:\,然后执行如下命令,对数据进行合并
type hadoop-2.7.2.tar.gz.part2 >> hadoop-2.7.2.tar.gz.part1
合并完成后,将hadoop-2.7.2.tar.gz.part1重新命名为hadoop-2.7.2.tar.gz。解压发现该tar包非常完整。
相关文章:
大数据框架之Hadoop:HDFS(三)HDFS客户端操作(开发重点)
3.1 HDFS客户端环境准备 1.根据自己电脑的操作系统拷贝对应的编译后的hadoop jar包到非中文路径(例如:D:\javaEnv\hadoop-2.77),如下图所示。 2.配置HADOOP_HOME环境变量,如下图所示。 3&#…...
多模式支持无线监控技术:主动式定位、被动式定位
物联网空间信息与数字技术发展至今,已经催生了一大批优秀的践行者。在日常与商业应用中,室内外定位领域依托于这一技术的发展,更是在近几年风光无限。但是并不是说室内定位与室外定位都已经相当成熟,相对来说,室内定位…...
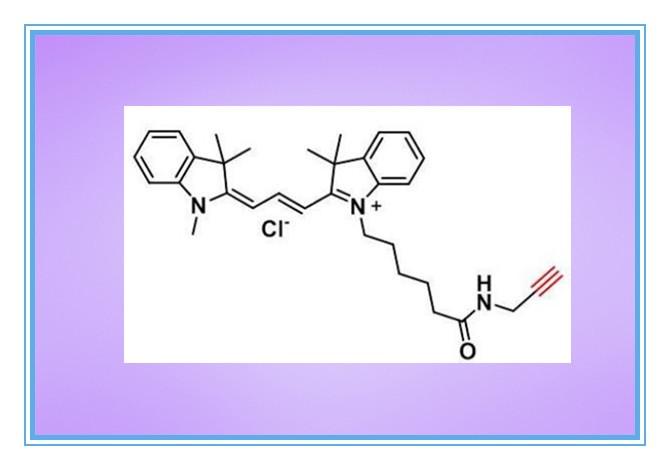
Cy5 Alkyne,1223357-57-0,花青素Cyanine5炔基,氰基5炔烃
CAS号:1223357-57-0 | 英文名: Cyanine5 alkyne,Cy5 Alkyne | 中文名:花青素CY5炔基CASNumber:1223357-57-0Molecular formula:C35H42ClN3OMolecular weight:556.19Purity:95%Appear…...
【MySQL】MySQL 中 WITH 子句详解:从基础到实战示例
文章目录一、什么是 WITH 子句1. 定义2.用途二、WITH 子句的语法和用法1.语法2.使用示例3.优点三、总结"梦想不会碎,只有被放弃了才会破灭。" "Dreams wont break, only abandoned will shatter."一、什么是 WITH 子句 1. 定义 WITH 子句是 M…...
c/c++开发,无可避免的模板编程实践(篇一)
一、c模板 c开发中,在声明变量、函数、类时,c都会要求使用指定的类型。在实际项目过程中,会发现很多代码除了类型不同之外,其他代码看起来都是相同的,为了实现这些相同功能,我们可能会进行如下设计…...

mulesoft MCIA 破釜沉舟备考 2023.02.13.04
mulesoft MCIA 破釜沉舟备考 2023.02.13.03 1. An integration Mule application consumes and processes a list of rows from a CSV file.2. One of the backend systems involved by the API implementation enforces rate limits on the number of request a particle clie…...
Camtasia2023最新版本新功能及快捷键教程
使用Camtasia,您可以毫不费力地在计算机的显示器上录制专业的活动视频。除了录制视频外,Camtasia还允许您从外部源将高清视频导入到录制中。Camtasia的独特之处在于它可以创建包含可单击链接的交互式视频,以生成适用于教室或工作场所的动态视…...
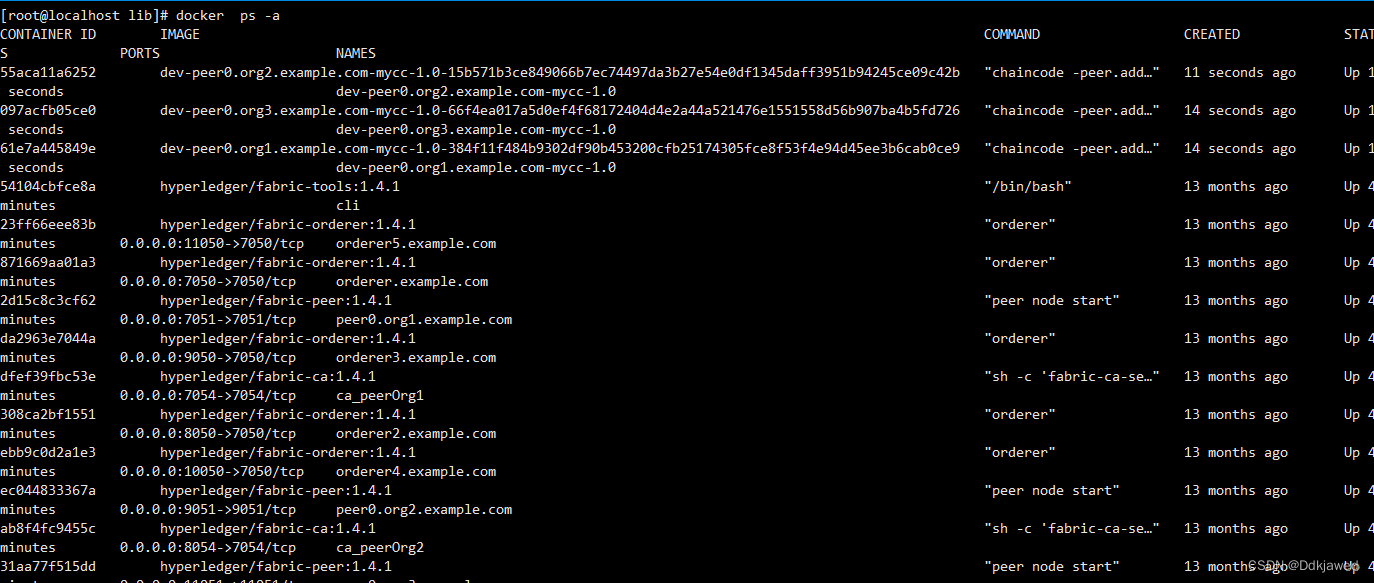
Fabric磁盘扩容后数据迁移
线上环境原来的磁盘比较小,随着业务数据的增多,磁盘需要扩容,因此需要把原来docker数据转移至新的数据盘。 数据迁移 操作系统: centOS 7 docker默认的数据目录为/var/lib/docker 创建一个新的目录/opt/dockerdata&…...

大厂光环下的功能测试,出去面试自动化一问三不知
在一家公司待久了技术能力反而变弱了,原来的许多知识都会慢慢遗忘,这种情况并不少见。一个京东员工发帖吐槽:感觉在大厂快待废了,出去面试问自己接口环境搭建、pytest测试框架,自己做点工太久都忘记了。平时用的时候搜…...
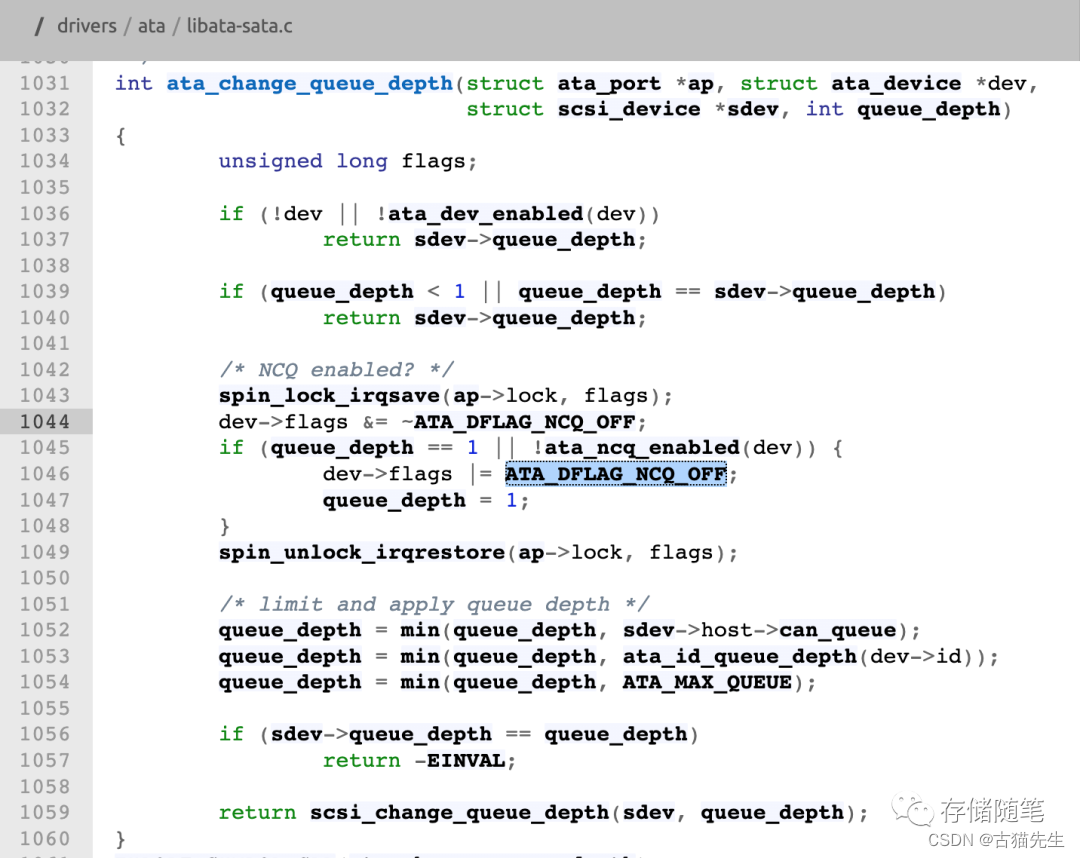
SATA SSD需要NCQ开启吗?
一、故事开篇最近有同学在咨询,SATA SSD是否需要NCQ功能?借此机会,今天我们来聊聊这个比较古老的话题,关于SATA协议的NCQ的故事。首先我们先回顾下SATA与NCQ的历史:2003年,SATA协议1.0问世,传输…...

知识图谱业务落地技术推荐之图神经网络算法库图计算框架汇总
1.PyTorch Geometric: https://pytorch-geometric.readthedocs.io/en/latest/notes/introduction.html PyG是一个基于PyTorch的用于处理不规则数据(比如图)的库,或者说是一个用于在图等数据上快速实现表征学习的框架。它的运行速度很快,训练模型速度可以达到DGL(Deep Gra…...
的区别)
==与equals()的区别
与equals()的区别 对于 比较的是值是否相等如果作用于基本数据类型的变量,则直接比较其存储的 “值”是否相等;如果作用于引用类型的变量,则比较的是所指向的对象的地址 对于equals方法 equals方法不能作用于基本数据类型的变量ÿ…...
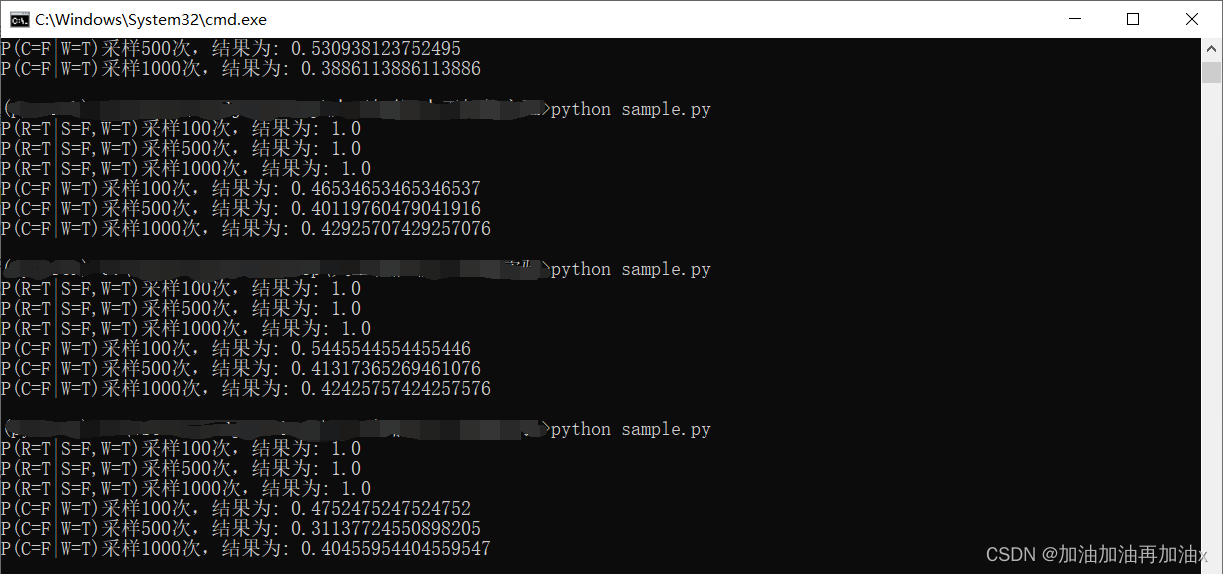
【人工智能】对贝叶斯网络进行吉布斯采样
问题 现要求通过吉布斯采样方法,利用该网络进行概率推理(计算 P(RT|SF, WT)、P2(CF|WT)的概率值)。 原理 吉布斯采样的核心思想为一维一维地进行采样,采某一个维度的时候固定其他的维度,在本次实验中,假…...
Java 面向对象基础
文章目录一、类和对象1. 类的定义2. 对象的使用二、对象内存图三、成员变量和局部变量四、封装1. private 关键字2. this 关键字五、构造方法六、标准类制作一、类和对象 在此之前,我们先了解两个概念,对象和类。 万物皆对象,客观存在的事物…...
—ConsumeMessageConcurrentlyService并发消费消息源码)
RocketMQ源码(21)—ConsumeMessageConcurrentlyService并发消费消息源码
基于RocketMQ release-4.9.3,深入的介绍了ConsumeMessageConcurrentlyService并发消费消息源码。 此前我们学习了consumer消息的拉取流程源码: RocketMQ源码(18)—DefaultMQPushConsumer消费者发起拉取消息请求源码RocketMQ源码(19)—Broker处理Default…...

基于 STM32+FPGA 的多轴运动控制器的设计
运动控制器是数控机床、高端机器人等自动化设备控制系统的核心。为保证控制器的实用性、实时性和稳定 性,提出一种以 STM32 为主控制器、FPGA 为辅助控制器的多轴运动控制器设计方案。给出了运动控制器的硬件电路设计, 将 S 形加减速算法融入运动控制器&…...

《爆肝整理》保姆级系列教程python接口自动化(十三)--cookie绕过验证码登录(详解
python接口自动化(十三)--cookie绕过验证码登录(详解 简介 有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接)。获取…...
soapui + groovy 接口自动化测试
1.操作excel的groovy脚本 package pubimport jxl.* import jxl.write.Label import jxl.write.WritableWorkbookclass ExcelOperation {def xlsFiledef workbookdef writableWorkbookdef ExcelOperation(){}//设置xlsFile文件路径def ExcelOperation(xlsFile){this.xlsFile x…...
:内存规整简介)
Linux内存管理(三十五):内存规整简介
源码基于:Linux5.4 0. 前言 伙伴系统以页面为单位来管理内存,内存碎片也是基于页面的,即由大量离散且不连续的页面组成的。从内核角度来看,出现内存碎片不是好事情,有些情况下物理设备需要大段的连续的物理内存,如果内核无法满足,则会发生内核错误。内存规整就是为了解…...
Java连接Redis
Jedis是Redis官方推荐的Java连接开发工具。api:https://tool.oschina.net/apidocs/apidoc?apijedis-2.1.0一、 导入包<!-- https://mvnrepository.com/artifact/redis.clients/jedis --> <dependency><groupId>redis.clients</groupId><…...

3步解决下载难题:imFile下载管理器实战指南
3步解决下载难题:imFile下载管理器实战指南 【免费下载链接】imfile-desktop A full-featured download manager. 项目地址: https://gitcode.com/gh_mirrors/im/imfile-desktop 你是否经常遇到这些下载烦恼?浏览器下载速度慢如蜗牛,大…...

如何免费快速提取任天堂NDS游戏资源:终极Tinke工具完整指南
如何免费快速提取任天堂NDS游戏资源:终极Tinke工具完整指南 【免费下载链接】tinke Viewer and editor for files of NDS games 项目地址: https://gitcode.com/gh_mirrors/ti/tinke 想要探索NDS游戏内部的奥秘吗?Tinke作为一款免费开源的NDS游戏…...
)
Vivado里配置RFSoC数据转换器IP,这10个参数新手最容易搞错(附PG269避坑指南)
Vivado中RFSoC数据转换器IP配置的10个关键参数解析与实战避坑指南 第一次在Vivado中配置RFSoC的数据转换器IP核时,面对密密麻麻的参数选项,即使是经验丰富的FPGA工程师也可能感到无从下手。RFSoC作为集成了高速数据转换器的异构计算平台,其配…...

基于MCP架构构建营销数据管道:打通Google Ads、Meta Ads与GA4的数据孤岛
1. 项目概述:打通营销数据孤岛的“瑞士军刀” 如果你在数字营销领域摸爬滚打过几年,尤其是在同时操盘谷歌广告和Meta广告,并且数据后台用的是Google Analytics 4,那你一定对下面这个场景深恶痛绝:老板或客户要一份整体…...

从MWC 2016看5G与物联网:技术演进、产业博弈与生态构建
1. 从巴塞罗那看2016年移动通信的十字路口 时间回到2016年初,如果你身处通信行业,那么2月底的日程表上,巴塞罗那的“移动世界大会”绝对是一个绕不开的焦点。那不是一个普通的展会,更像是一个行业在技术迭代、市场转型和地缘政治多…...

品牌AI印相失效90%源于这7个参数误设,可口可乐级商业输出必须校准的4项色彩/构图硬指标
更多请点击: https://intelliparadigm.com 第一章:Midjourney Coca Cola印相失效的底层归因诊断 Midjourney v6 及后续版本中,针对品牌标识(如 Coca-Cola 经典红白波浪字体与动态弧线)的“印相”(prompt i…...

LED照明技术演进中的杰文斯悖论:从节能到光污染的双刃剑效应
1. 从“省电”到“光污染”:LED照明技术的双刃剑效应作为一名在电子工程和消费电子领域摸爬滚打了十几年的从业者,我见证了一波又一波的技术浪潮。从CRT到LCD,从机械硬盘到固态硬盘,每一次技术迭代都伴随着“更高效、更节能、更便…...

工作5年的PHP程序员,转智能体开发半年,薪资翻了2倍
文章目录前言一、PHP程序员的中年危机:不是你不行,是时代变了二、为什么智能体开发是PHP程序员的最优转型方向?1. 门槛最低,上手最快2. 竞争最小,薪资最高3. 前景最好,发展空间最大三、那个转智能体半年薪资…...

深度解析开源AI工具库:OpenAI API封装库的设计与实战应用
1. 项目概述:一个开源AI工具库的深度解构最近在GitHub上看到一个名为“anasfik/openai”的项目,这个标题乍一看有点意思。它不像官方SDK那样直接叫“openai”,而是带上了个人或组织的命名空间前缀“anasfik/”。这通常意味着这是一个第三方封…...

KouriChat + DeepSeek + 微信接入:本地 AI 角色聊天机器人搭建实录
🎁个人主页:User_芊芊君子 🎉欢迎大家点赞👍评论📝收藏⭐文章 🔍系列专栏:AI 文章目录: 前言1 KouriChat项目简介2 环境准备3 环境安装及项目部署3.1 Python3.11 安装3.2 启动KouriC…...