数据规整:聚合、合并和重塑
目录
- 一、层次化索引
- 重排与分级排序
- 根据级别汇总统计
- 二、合并数据集
- 数据库风格的DataFrame合并
- 索引上的合并
- 轴向连接
- 合并重叠数据
- 三、重塑和轴向旋转
- 重塑层次化索引
- 将“长格式”旋转为“宽格式”
- 将“宽格式”旋转为“长格式”
一、层次化索引
层次化索引(hierarchical indexing)是pandas的一项重要功能,它使你能在一个轴上拥有多个(两个以上)索引级别。抽象点说,它使你能以低维度形式处理高维度数据。我们先来看一个简单的例子:创建一个Series,并用一个由列表或数组组成的列表作为索引:
In [9]: data = pd.Series(np.random.randn(9),...: index=[['a', 'a', 'a', 'b', 'b', 'c', 'c', 'd', 'd'],...: [1, 2, 3, 1, 3, 1, 2, 2, 3]])In [10]: data
Out[10]:
a 1 -0.2047082 0.4789433 -0.519439
b 1 -0.5557303 1.965781
c 1 1.3934062 0.092908
d 2 0.2817463 0.769023
dtype: float64
看到的结果是经过美化的带有MultiIndex索引的Series的格式。索引之间的“间隔”表示“直接使用上面的标签”:
In [11]: data.index
Out[11]:
MultiIndex(levels=[['a', 'b', 'c', 'd'], [1, 2, 3]],labels=[[0, 0, 0, 1, 1, 2, 2, 3, 3], [0, 1, 2, 0, 2, 0, 1, 1, 2]])
对于一个层次化索引的对象,可以使用所谓的部分索引,使用它选取数据子集的操作更简单:
In [12]: data['b']
Out[12]:
1 -0.555730
3 1.965781
dtype: float64In [13]: data['b':'c']
Out[13]:
b 1 -0.5557303 1.965781
c 1 1.3934062 0.092908
dtype: float64In [14]: data.loc[['b', 'd']]
Out[14]:
b 1 -0.5557303 1.965781
d 2 0.2817463 0.769023
dtype: float64
有时甚至还可以在“内层”中进行选取
In [15]: data.loc[:, 2]
Out[15]:
a 0.478943
c 0.092908
d 0.281746
dtype: float64
对于一个DataFrame,每条轴都可以有分层索引:
In [18]: frame = pd.DataFrame(np.arange(12).reshape((4, 3)),....: index=[['a', 'a', 'b', 'b'], [1, 2, 1, 2]],....: columns=[['Ohio', 'Ohio', 'Colorado'],....: ['Green', 'Red', 'Green']])In [19]: frame
Out[19]: Ohio ColoradoGreen Red Green
a 1 0 1 22 3 4 5
b 1 6 7 82 9 10 11
各层都可以有名字(可以是字符串,也可以是别的Python对象)。如果指定了名称,它们就会显示在控制台输出中:
In [20]: frame.index.names = ['key1', 'key2']In [21]: frame.columns.names = ['state', 'color']In [22]: frame
Out[22]:
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 22 3 4 5
b 1 6 7 82 9 10 11
重排与分级排序
有时,你需要重新调整某条轴上各级别的顺序,或根据指定级别上的值对数据进行排序。swaplevel接受两个级别编号或名称,并返回一个互换了级别的新对象(但数据不会发生变化):
In [24]: frame.swaplevel('key1', 'key2')
Out[24]:
state Ohio Colorado
color Green Red Green
key2 key1
1 a 0 1 2
2 a 3 4 5
1 b 6 7 8
2 b 9 10 11
而sort_index则根据单个级别中的值对数据进行排序。交换级别时,常常也会用到sort_index,这样最终结果就是按照指定顺序进行字母排序了:
In [25]: frame.sort_index(level=1)
Out[25]:
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 2
b 1 6 7 8
a 2 3 4 5
b 2 9 10 11In [26]: frame.swaplevel(0, 1).sort_index(level=0)
Out[26]:
state Ohio Colorado
color Green Red Green
key2 key1
1 a 0 1 2b 6 7 8
2 a 3 4 5b 9 10 11
根据级别汇总统计
许多对DataFrame和Series的描述和汇总统计都有一个level选项,它用于指定在某条轴上求和的级别。再以上面那个DataFrame为例,我们可以根据行或列上的级别来进行求和:
In [27]: frame.sum(level='key2')
Out[27]:
state Ohio Colorado
color Green Red Green
key2
1 6 8 10
2 12 14 16In [28]: frame.sum(level='color', axis=1)
Out[28]:
color Green Red
key1 key2
a 1 2 12 8 4
b 1 14 72 20 10
DataFrame的set_index函数会将其一个或多个列转换为行索引,并创建一个新的DataFrame:
In [29]: frame = pd.DataFrame({'a': range(7), 'b': range(7, 0, -1),....: 'c': ['one', 'one', 'one', 'two', 'two',....: 'two', 'two'],....: 'd': [0, 1, 2, 0, 1, 2, 3]})In [30]: frame
Out[30]: a b c d
0 0 7 one 0
1 1 6 one 1
2 2 5 one 2
3 3 4 two 0
4 4 3 two 1
5 5 2 two 2
6 6 1 two 3
默认情况下,那些列会从DataFrame中移除,但也可以将其保留下来:
In [33]: frame.set_index(['c', 'd'], drop=False)
Out[33]: a b c d
c d
one 0 0 7 one 01 1 6 one 12 2 5 one 2
two 0 3 4 two 01 4 3 two 12 5 2 two 23 6 1 two 3
reset_index的功能跟set_index刚好相反,层次化索引的级别会被转移到列里面:
In [34]: frame2.reset_index()
Out[34]:
c d a b
0 one 0 0 7
1 one 1 1 6
2 one 2 2 5
3 two 0 3 4
4 two 1 4 3
5 two 2 5 2
6 two 3 6 1
二、合并数据集
pandas对象中的数据可以通过一些方式进行合并:
- pandas.merge可根据一个或多个键将不同DataFrame中的行连接起来。SQL或其他关系型数据库的用户对此应该会比较熟悉,因为它实现的就是数据库的join操作。
- pandas.concat可以沿着一条轴将多个对象堆叠到一起。
- 实例方法combine_first可以将重复数据拼接在一起,用一个对象中的值填充另一个对象中的缺失值。
我将分别对它们进行讲解,并给出一些例子。本书剩余部分的示例中将经常用到它们。
数据库风格的DataFrame合并
数据集的合并(merge)或连接(join)运算是通过一个或多个键将行连接起来的。这些运算是关系型数据库(基于SQL)的核心。pandas的merge函数是对数据应用这些算法的主要切入点。
以一个简单的例子开始:
In [35]: df1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],....: 'data1': range(7)})In [36]: df2 = pd.DataFrame({'key': ['a', 'b', 'd'],....: 'data2': range(3)})In [37]: df1
Out[37]: data1 key
0 0 b
1 1 b
2 2 a
3 3 c
4 4 a
5 5 a
6 6 bIn [38]: df2
Out[38]: data2 key
0 0 a
1 1 b
2 2 d
这是一种多对一的合并。df1中的数据有多个被标记为a和b的行,而df2中key列的每个值则仅对应一行。对这些对象调用merge即可得到:
In [39]: pd.merge(df1, df2)
Out[39]: data1 key data2
0 0 b 1
1 1 b 1
2 6 b 1
3 2 a 0
4 4 a 0
5 5 a 0
注意,我并没有指明要用哪个列进行连接。如果没有指定,merge就会将重叠列的列名当做键。不过,最好明确指定一下:
In [40]: pd.merge(df1, df2, on='key')
Out[40]: data1 key data2
0 0 b 1
1 1 b 1
2 6 b 1
3 2 a 0
4 4 a 0
5 5 a 0
如果两个对象的列名不同,也可以分别进行指定:
In [41]: df3 = pd.DataFrame({'lkey': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],....: 'data1': range(7)})In [42]: df4 = pd.DataFrame({'rkey': ['a', 'b', 'd'],....: 'data2': range(3)})In [43]: pd.merge(df3, df4, left_on='lkey', right_on='rkey')
Out[43]: data1 lkey data2 rkey
0 0 b 1 b
1 1 b 1 b
2 6 b 1 b
3 2 a 0 a
4 4 a 0 a
5 5 a 0 a
可能你已经注意到了,结果里面c和d以及与之相关的数据消失了。默认情况下,merge做的是“内连接”;结果中的键是交集。其他方式还有"left"、“right"以及"outer”。外连接求取的是键的并集,组合了左连接和右连接的效果:
In [44]: pd.merge(df1, df2, how='outer')
Out[44]: data1 key data2
0 0.0 b 1.0
1 1.0 b 1.0
2 6.0 b 1.0
3 2.0 a 0.0
4 4.0 a 0.0
5 5.0 a 0.0
6 3.0 c NaN
7 NaN d 2.0

多键合并
In [51]: left = pd.DataFrame({'key1': ['foo', 'foo', 'bar'],....: 'key2': ['one', 'two', 'one'],....: 'lval': [1, 2, 3]})In [52]: right = pd.DataFrame({'key1': ['foo', 'foo', 'bar', 'bar'],....: 'key2': ['one', 'one', 'one', 'two'],....: 'rval': [4, 5, 6, 7]})In [53]: pd.merge(left, right, on=['key1', 'key2'], how='outer')
Out[53]: key1 key2 lval rval
0 foo one 1.0 4.0
1 foo one 1.0 5.0
2 foo two 2.0 NaN
3 bar one 3.0 6.0
4 bar two NaN 7.0
对于合并运算需要考虑的最后一个问题是对重复列名的处理。虽然你可以手工处理列名重叠的问题(查看前面介绍的重命名轴标签),但merge有一个更实用的suffixes选项,用于指定附加到左右两个DataFrame对象的重叠列名上的字符串:
In [54]: pd.merge(left, right, on='key1')
Out[54]: key1 key2_x lval key2_y rval
0 foo one 1 one 4
1 foo one 1 one 5
2 foo two 2 one 4
3 foo two 2 one 5
4 bar one 3 one 6
5 bar one 3 two 7In [55]: pd.merge(left, right, on='key1', suffixes=('_left', '_right'))
Out[55]: key1 key2_left lval key2_right rval
0 foo one 1 one 4
1 foo one 1 one 5
2 foo two 2 one 4
3 foo two 2 one 5
4 bar one 3 one 6
5 bar one 3 two 7


索引上的合并
有时候,DataFrame中的连接键位于其索引中。在这种情况下,你可以传入left_index=True或right_index=True(或两个都传)以说明索引应该被用作连接键:
In [56]: left1 = pd.DataFrame({'key': ['a', 'b', 'a', 'a', 'b', 'c'],....: 'value': range(6)})In [57]: right1 = pd.DataFrame({'group_val': [3.5, 7]}, index=['a', 'b'])In [58]: left1
Out[58]:key value
0 a 0
1 b 1
2 a 2
3 a 3
4 b 4
5 c 5In [59]: right1
Out[59]: group_val
a 3.5
b 7.0In [60]: pd.merge(left1, right1, left_on='key', right_index=True)
Out[60]: key value group_val
0 a 0 3.5
2 a 2 3.5
3 a 3 3.5
1 b 1 7.0
4 b 4 7.0
由于默认的merge方法是求取连接键的交集,因此你可以通过外连接的方式得到它们的并集:
In [61]: pd.merge(left1, right1, left_on='key', right_index=True, how='outer')
Out[61]: key value group_val
0 a 0 3.5
2 a 2 3.5
3 a 3 3.5
1 b 1 7.0
4 b 4 7.0
5 c 5 NaN
DataFrame还有一个便捷的join实例方法,它能更为方便地实现按索引合并。它还可用于合并多个带有相同或相似索引的DataFrame对象,但要求没有重叠的列。在上面那个例子中,我们可以编写:
In [73]: left2.join(right2, how='outer')
Out[73]: Ohio Nevada Missouri Alabama
a 1.0 2.0 NaN NaN
b NaN NaN 7.0 8.0
c 3.0 4.0 9.0 10.0
d NaN NaN 11.0 12.0
e 5.0 6.0 13.0 14.0
轴向连接
另一种数据合并运算也被称作连接(concatenation)、绑定(binding)或堆叠(stacking)。NumPy的concatenation函数可以用NumPy数组来做:
In [79]: arr = np.arange(12).reshape((3, 4))In [80]: arr
Out[80]:
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])In [81]: np.concatenate([arr, arr], axis=1)
Out[81]:
array([[ 0, 1, 2, 3, 0, 1, 2, 3],[ 4, 5, 6, 7, 4, 5, 6, 7],[ 8, 9, 10, 11, 8, 9, 10, 11]])
对于pandas对象(如Series和DataFrame),带有标签的轴使你能够进一步推广数组的连接运算。具体点说,你还需要考虑以下这些东西:
- 如果对象在其它轴上的索引不同,我们应该合并这些轴的不同元素还是只使用交集?
- 连接的数据集是否需要在结果对象中可识别?
- 连接轴中保存的数据是否需要保留?许多情况下,DataFrame默认的整数标签最好在连接时删掉。
pandas的concat函数提供了一种能够解决这些问题的可靠方式。我将给出一些例子来讲解其使用方式。假设有三个没有重叠索引的Series:
In [82]: s1 = pd.Series([0, 1], index=['a', 'b'])In [83]: s2 = pd.Series([2, 3, 4], index=['c', 'd', 'e'])In [84]: s3 = pd.Series([5, 6], index=['f', 'g'])
对这些对象调用concat可以将值和索引粘合在一起:
In [85]: pd.concat([s1, s2, s3])
Out[85]:
a 0
b 1
c 2
d 3
e 4
f 5
g 6
dtype: int64
默认情况下,concat是在axis=0上工作的,最终产生一个新的Series。如果传入axis=1,则结果就会变成一个DataFrame(axis=1是列):
In [86]: pd.concat([s1, s2, s3], axis=1)
Out[86]: 0 1 2
a 0.0 NaN NaN
b 1.0 NaN NaN
c NaN 2.0 NaN
d NaN 3.0 NaN
e NaN 4.0 NaN
f NaN NaN 5.0
g NaN NaN 6.0
你可以通过join_axes指定要在其它轴上使用的索引:
In [91]: pd.concat([s1, s4], axis=1, join_axes=[['a', 'c', 'b', 'e']])
Out[91]: 0 1
a 0.0 0.0
c NaN NaN
b 1.0 1.0
e NaN NaN
不过有个问题,参与连接的片段在结果中区分不开。假设你想要在连接轴上创建一个层次化索引。使用keys参数即可达到这个目的:
In [92]: result = pd.concat([s1, s1, s3], keys=['one','two', 'three'])In [93]: result
Out[93]:
one a 0b 1
two a 0b 1
three f 5g 6
dtype: int64In [94]: result.unstack()
Out[94]: a b f g
one 0.0 1.0 NaN NaN
two 0.0 1.0 NaN NaN
three NaN NaN 5.0 6.0
如果沿着axis=1对Series进行合并,则keys就会成为DataFrame的列头:
In [95]: pd.concat([s1, s2, s3], axis=1, keys=['one','two', 'three'])
Out[95]: one two three
a 0.0 NaN NaN
b 1.0 NaN NaN
c NaN 2.0 NaN
d NaN 3.0 NaN
e NaN 4.0 NaN
f NaN NaN 5.0
g NaN NaN 6.0
合并重叠数据
还有一种数据组合问题不能用简单的合并(merge)或连接(concatenation)运算来处理。比如说,你可能有索引全部或部分重叠的两个数据集。举个有启发性的例子,我们使用NumPy的where函数,它表示一种等价于面向数组的if-else:
In [108]: a = pd.Series([np.nan, 2.5, np.nan, 3.5, 4.5, np.nan],.....: index=['f', 'e', 'd', 'c', 'b', 'a'])In [109]: b = pd.Series(np.arange(len(a), dtype=np.float64),.....: index=['f', 'e', 'd', 'c', 'b', 'a'])In [110]: b[-1] = np.nanIn [111]: a
Out[111]:
f NaN
e 2.5
d NaN
c 3.5
b 4.5
a NaN
dtype: float64In [112]: b
Out[112]:
f 0.0
e 1.0
d 2.0
c 3.0
b 4.0
a NaN
dtype: float64In [113]: np.where(pd.isnull(a), b, a)
Out[113]: array([ 0. , 2.5, 2. , 3.5, 4.5, nan])
Series有一个combine_first方法,实现的也是一样的功能,还带有pandas的数据对齐:
In [114]: b[:-2].combine_first(a[2:])
Out[114]:
a NaN
b 4.5
c 3.0
d 2.0
e 1.0
f 0.0
dtype: float64对于DataFrame,combine_first自然也会在列上做同样的事情,因此你可以将其看做:用传递对象中的数据为调用对象的缺失数据“打补丁”:
In [115]: df1 = pd.DataFrame({'a': [1., np.nan, 5., np.nan],.....: 'b': [np.nan, 2., np.nan, 6.],.....: 'c': range(2, 18, 4)})In [116]: df2 = pd.DataFrame({'a': [5., 4., np.nan, 3., 7.],.....: 'b': [np.nan, 3., 4., 6., 8.]})In [117]: df1
Out[117]: a b c
0 1.0 NaN 2
1 NaN 2.0 6
2 5.0 NaN 10
3 NaN 6.0 14In [118]: df2
Out[118]: a b
0 5.0 NaN
1 4.0 3.0
2 NaN 4.0
3 3.0 6.0
4 7.0 8.0In [119]: df1.combine_first(df2)
Out[119]: a b c
0 1.0 NaN 2.0
1 4.0 2.0 6.0
2 5.0 4.0 10.0
3 3.0 6.0 14.0
4 7.0 8.0 NaN
三、重塑和轴向旋转
有许多用于重新排列表格型数据的基础运算。这些函数也称作重塑(reshape)或轴向旋转(pivot)运算。
重塑层次化索引
层次化索引为DataFrame数据的重排任务提供了一种具有良好一致性的方式。主要功能有二:
- stack:将数据的列“旋转”为行。
- unstack:将数据的行“旋转”为列。
我将通过一系列的范例来讲解这些操作。接下来看一个简单的DataFrame,其中的行列索引均为字符串数组:
In [120]: data = pd.DataFrame(np.arange(6).reshape((2, 3)),.....: index=pd.Index(['Ohio','Colorado'], name='state'),.....: columns=pd.Index(['one', 'two', 'three'],.....: name='number'))In [121]: data
Out[121]:
number one two three
state
Ohio 0 1 2
Colorado 3 4 5
# 对该数据使用stack方法即可将列转换为行,得到一个Series:
In [122]: result = data.stack()In [123]: result
Out[123]:
state number
Ohio one 0two 1three 2
Colorado one 3two 4three 5
dtype: int64
#对于一个层次化索引的Series,你可以用unstack将其重排为一个DataFrame:
In [124]: result.unstack()
Out[124]:
number one two three
state
Ohio 0 1 2
Colorado 3 4 5
将“长格式”旋转为“宽格式”
多个时间序列数据通常是以所谓的“长格式”(long)或“堆叠格式”(stacked)存储在数据库和CSV中的。我们先加载一些示例数据,做一些时间序列规整和数据清洗:
In [139]: data = pd.read_csv('examples/macrodata.csv')In [140]: data.head()
Out[140]: year quarter realgdp realcons realinv realgovt realdpi cpi \
0 1959.0 1.0 2710.349 1707.4 286.898 470.045 1886.9 28.98
1 1959.0 2.0 2778.801 1733.7 310.859 481.301 1919.7 29.15
2 1959.0 3.0 2775.488 1751.8 289.226 491.260 1916.4 29.35
3 1959.0 4.0 2785.204 1753.7 299.356 484.052 1931.3 29.37
4 1960.0 1.0 2847.699 1770.5 331.722 462.199 1955.5 29.54 m1 tbilrate unemp pop infl realint
0 139.7 2.82 5.8 177.146 0.00 0.00
1 141.7 3.08 5.1 177.830 2.34 0.74
2 140.5 3.82 5.3 178.657 2.74 1.09
3 140.0 4.33 5.6 179.386 0.27 4.06
4 139.6 3.50 5.2 180.007 2.31 1.19 In [141]: periods = pd.PeriodIndex(year=data.year, quarter=data.quarter,.....: name='date')In [142]: columns = pd.Index(['realgdp', 'infl', 'unemp'], name='item')In [143]: data = data.reindex(columns=columns)In [144]: data.index = periods.to_timestamp('D', 'end')In [145]: ldata = data.stack().reset_index().rename(columns={0: 'value'})
这就是多个时间序列(或者其它带有两个或多个键的可观察数据,这里,我们的键是date和item)的长格式。表中的每行代表一次观察。
关系型数据库(如MySQL)中的数据经常都是这样存储的,因为固定架构(即列名和数据类型)有一个好处:随着表中数据的添加,item列中的值的种类能够增加。在前面的例子中,date和item通常就是主键(用关系型数据库的说法),不仅提供了关系完整性,而且提供了更为简单的查询支持。有的情况下,使用这样的数据会很麻烦,你可能会更喜欢DataFrame,不同的item值分别形成一列,date列中的时间戳则用作索引。DataFrame的pivot方法完全可以实现这个转换:
In [147]: pivoted = ldata.pivot('date', 'item', 'value')In [148]: pivoted
Out[148]:
item infl realgdp unemp
date
1959-03-31 0.00 2710.349 5.8
1959-06-30 2.34 2778.801 5.1
1959-09-30 2.74 2775.488 5.3
1959-12-31 0.27 2785.204 5.6
1960-03-31 2.31 2847.699 5.2
1960-06-30 0.14 2834.390 5.2
1960-09-30 2.70 2839.022 5.6
1960-12-31 1.21 2802.616 6.3
1961-03-31 -0.40 2819.264 6.8
1961-06-30 1.47 2872.005 7.0
... ... ... ...
2007-06-30 2.75 13203.977 4.5
2007-09-30 3.45 13321.109 4.7
2007-12-31 6.38 13391.249 4.8
2008-03-31 2.82 13366.865 4.9
2008-06-30 8.53 13415.266 5.4
2008-09-30 -3.16 13324.600 6.0
2008-12-31 -8.79 13141.920 6.9
2009-03-31 0.94 12925.410 8.1
2009-06-30 3.37 12901.504 9.2
2009-09-30 3.56 12990.341 9.6
[203 rows x 3 columns]
前两个传递的值分别用作行和列索引,最后一个可选值则是用于填充DataFrame的数据列。假设有两个需要同时重塑的数据列:
In [149]: ldata['value2'] = np.random.randn(len(ldata))In [150]: ldata[:10]
Out[150]: date item value value2
0 1959-03-31 realgdp 2710.349 0.523772
1 1959-03-31 infl 0.000 0.000940
2 1959-03-31 unemp 5.800 1.343810
3 1959-06-30 realgdp 2778.801 -0.713544
4 1959-06-30 infl 2.340 -0.831154
5 1959-06-30 unemp 5.100 -2.370232
6 1959-09-30 realgdp 2775.488 -1.860761
7 1959-09-30 infl 2.740 -0.860757
8 1959-09-30 unemp 5.300 0.560145
9 1959-12-31 realgdp 2785.204 -1.265934
如果忽略最后一个参数,得到的DataFrame就会带有层次化的列:
In [151]: pivoted = ldata.pivot('date', 'item')In [152]: pivoted[:5]
Out[152]: value value2
item infl realgdp unemp infl realgdp unemp
date
1959-03-31 0.00 2710.349 5.8 0.000940 0.523772 1.343810
1959-06-30 2.34 2778.801 5.1 -0.831154 -0.713544 -2.370232
1959-09-30 2.74 2775.488 5.3 -0.860757 -1.860761 0.560145
1959-12-31 0.27 2785.204 5.6 0.119827 -1.265934 -1.063512
1960-03-31 2.31 2847.699 5.2 -2.359419 0.332883 -0.199543In [153]: pivoted['value'][:5]
Out[153]:
item infl realgdp unemp
date
1959-03-31 0.00 2710.349 5.8
1959-06-30 2.34 2778.801 5.1
1959-09-30 2.74 2775.488 5.3
1959-12-31 0.27 2785.204 5.6
1960-03-31 2.31 2847.699 5.2
注意,pivot其实就是用set_index创建层次化索引,再用unstack重塑:
In [154]: unstacked = ldata.set_index(['date', 'item']).unstack('item')In [155]: unstacked[:7]
Out[155]: value value2
item infl realgdp unemp infl realgdp unemp
date
1959-03-31 0.00 2710.349 5.8 0.000940 0.523772 1.343810
1959-06-30 2.34 2778.801 5.1 -0.831154 -0.713544 -2.370232
1959-09-30 2.74 2775.488 5.3 -0.860757 -1.860761 0.560145
1959-12-31 0.27 2785.204 5.6 0.119827 -1.265934 -1.063512
1960-03-31 2.31 2847.699 5.2 -2.359419 0.332883 -0.199543
1960-06-30 0.14 2834.390 5.2 -0.970736 -1.541996 -1.307030
1960-09-30 2.70 2839.022 5.6 0.377984 0.286350 -0.753887
将“宽格式”旋转为“长格式”
旋转DataFrame的逆运算是pandas.melt。它不是将一列转换到多个新的DataFrame,而是合并多个列成为一个,产生一个比输入长的DataFrame。看一个例子:
In [157]: df = pd.DataFrame({'key': ['foo', 'bar', 'baz'],.....: 'A': [1, 2, 3],.....: 'B': [4, 5, 6],.....: 'C': [7, 8, 9]})In [158]: df
Out[158]: A B C key
0 1 4 7 foo
1 2 5 8 bar
2 3 6 9 baz
key列可能是分组指标,其它的列是数据值。当使用pandas.melt,我们必须指明哪些列是分组指标。下面使用key作为唯一的分组指标:
In [159]: melted = pd.melt(df, ['key'])In [160]: melted
Out[160]: key variable value
0 foo A 1
1 bar A 2
2 baz A 3
3 foo B 4
4 bar B 5
5 baz B 6
6 foo C 7
7 bar C 8
8 baz C 9
使用pivot,可以重塑回原来的样子:
In [161]: reshaped = melted.pivot('key', 'variable', 'value')In [162]: reshaped
Out[162]:
variable A B C
key
bar 2 5 8
baz 3 6 9
foo 1 4 7
因为pivot的结果从列创建了一个索引,用作行标签,我们可以使用reset_index将数据移回列:
In [163]: reshaped.reset_index()
Out[163]:
variable key A B C
0 bar 2 5 8
1 baz 3 6 9
2 foo 1 4 7
你还可以指定列的子集,作为值的列:
In [164]: pd.melt(df, id_vars=['key'], value_vars=['A', 'B'])
Out[164]: key variable value
0 foo A 1
1 bar A 2
2 baz A 3
3 foo B 4
4 bar B 5
5 baz B 6
pandas.melt也可以不用分组指标:
In [165]: pd.melt(df, value_vars=['A', 'B', 'C'])
Out[165]: variable value
0 A 1
1 A 2
2 A 3
3 B 4
4 B 5
5 B 6
6 C 7
7 C 8
8 C 9In [166]: pd.melt(df, value_vars=['key', 'A', 'B'])
Out[166]: variable value
0 key foo
1 key bar
2 key baz
3 A 1
4 A 2
5 A 3
6 B 4
7 B 5
8 B 6
相关文章:
数据规整:聚合、合并和重塑
目录一、层次化索引重排与分级排序根据级别汇总统计二、合并数据集数据库风格的DataFrame合并索引上的合并轴向连接合并重叠数据三、重塑和轴向旋转重塑层次化索引将“长格式”旋转为“宽格式”将“宽格式”旋转为“长格式”一、层次化索引 层次化索引(hierarchica…...

开心档之C++ 信号处理
C 信号处理 目录 C 信号处理 signal() 函数 实例 raise() 函数 实例 信号是由操作系统传给进程的中断,会提早终止一个程序。在 UNIX、LINUX、Mac OS X 或 Windows 系统上,可以通过按 CtrlC 产生中断。 有些信号不能被程序捕获,但是下表…...

ChatGPT惨遭围剿?多国封杀、近万人联名抵制……
最近,全世界燃起一股围剿ChatGPT的势头。由马斯克、图灵奖得主Bengio等千人联名的“暂停高级AI研发”的公开信,目前签名数量已上升至9000多人。除了业内大佬,欧盟各国和白宫也纷纷出手。 最早“动手”的是意大利,直接在全国上下封…...
SpringBoot监听器
1.寻找spring.factories配置文件对应的监听器,主要要写监听器的全路径名,不然反射会报错 SpringBoot底层是如何读取META-INF/spring.factories的配置的? 1.遍历所有jar下的META-INF/spring.factories配置文件 2.读取配置文件下的所有属性&a…...

【网络安全】SQL注入--报错注入
报错注入报错注入定义代码展示常用的报错语句1.获取数据库名称2.获取mysql账号密码3.获取表名4.获取字段名5.获取账号密码报错注入定义 报错注入:利用sql语句的不规范,获取相关sql提示信息 代码展示 常用的报错语句 select first_name, last_name FROM…...

APP隐私整改建议
1、违规收集个人信息 情形一: APP首次启动时,未有以弹窗形式明示个人信息保护政策。 改进建议: APP首次启动时,以弹窗等形式向用户明示个人信息保护政策。 情形二: 个人信息保护政策未有说明个人信息处理的目的、方…...
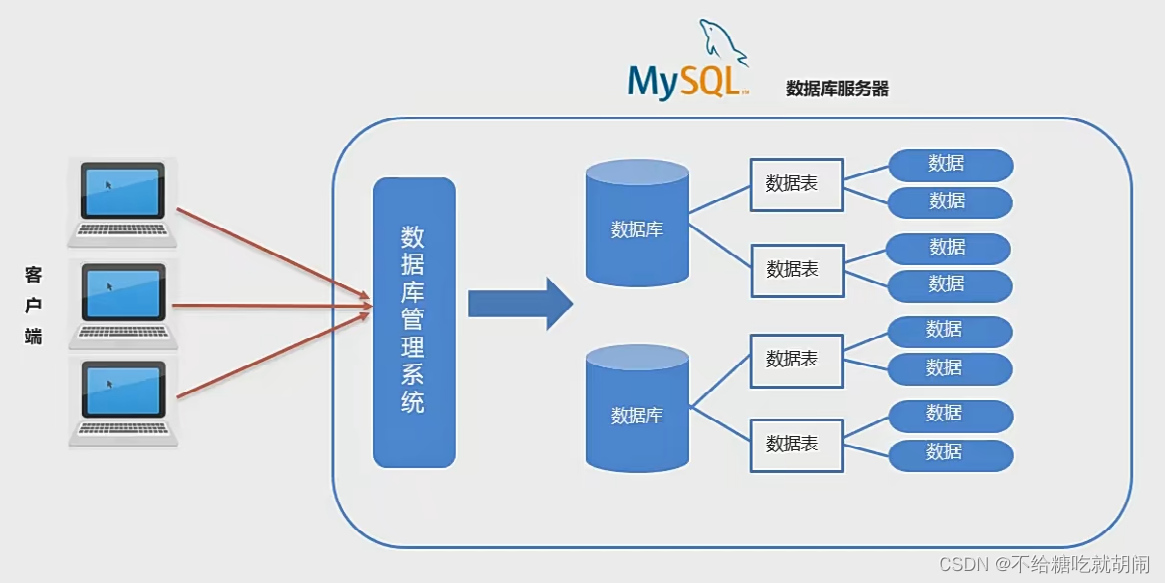
MySQL数据模型 and 通用语法 and 分类
关系型数据库 关系型数据库是由多张能互相连接的二维表组成的数据库。 优点: 1.都是使用表结构,格式一致,易于维护。 2.使用通用的SQL语言操作,使用方便,可用于复杂查询。 3.数据存储在磁盘中,安全。 …...

一款识别域名是否使用cdn的工具cdnChecker
cdnChecker 一款识别域名是否使用cdn的工具 https://github.com/alwaystest18/cdnChecker 背景 红队打点时经常会有收集子域名然后转成ip进而扩展ip段进行脆弱点寻找的需求,如果域名使用cdn,会导致收集错误的ip段,因此我们需要排除cdn来收…...

Ant Design Vue的汉化
Ant Design Vue的汉化 1. 引入依赖 import zhCN from "ant-design-vue/lib/locale-provider/zh_CN"; // 汉化 export default {data () {zhCN,} }2. 标签包裹需要汉化的组件 <a-config-provider :locale"zhCN"><a-table :row-selection"ro…...
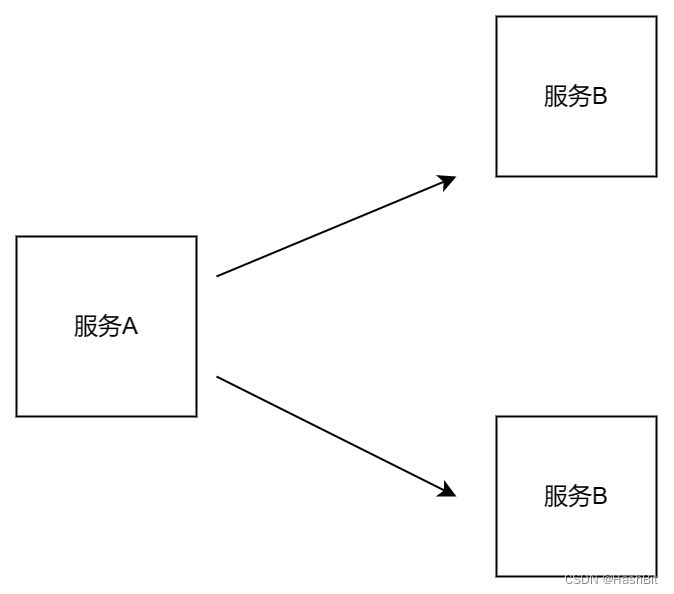
spring cloud中实现接口广播请求到服务提供者
一、背景 假如现在有一台服务A,两台服务B,可以简化为如下图模型: 需求:一次请求服务A需要同时将请求广播打到两台服务B上。 二、实现方案 2.1 需要应用到两个类: 2.1.1:LoadBalancerClient package org…...

电机PID参数调节笔记
规则1 1)降低比例增益P,可以获得较小的振动2)有可能不需要调节I环和D环3)提升比例增益P环可以增加灵敏度,但可能会出现不稳定的情况(如振动)4)可以设定电机速度最大幅值,…...
【深度学习】基于华为MindSpore的手写体图像识别实验
1 实验介绍 1.1 简介 Mnist手写体图像识别实验是深度学习入门经典实验。Mnist数据集包含60,000个用于训练的示例和10,000个用于测试的示例。这些数字已经过尺寸标准化并位于图像中心,图像是固定大小(28x28像素),其值为0到255。为简单起见,每…...
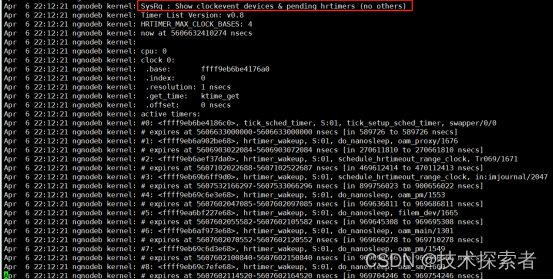
Linux:内核调试之内核魔术键sysrq
在linux系统下,我们可能会遇到系统某个命令hang住的情况,通常情况下,我们会查看/proc/pid/wchan文件,看看进程处于什么状况,然后进一步查看系统日志或者使用strace跟踪命令执行时的系统调用等等方法来分析问题。我们知…...

Python import导包快速入门
import 和 from import 在 Python 中,使用 import 语句可以将其他 Python 模块或包中的代码引入到当前模块中,以供使用。通常情况下,我们可以使用以下语法将整个模块导入到当前命名空间中: import module_name其中,m…...
ChatGPT这么火,我们能怎么办?
今天打开百度,看到这样一条热搜高居榜二:B站UP主发起停更潮,然后点进去了解一看,大体是因为最近AI创作太火,对高质量原创形成了巨大冲击!记得之前看过一位UP主的分享,说B站UP主的年收入大体约等…...
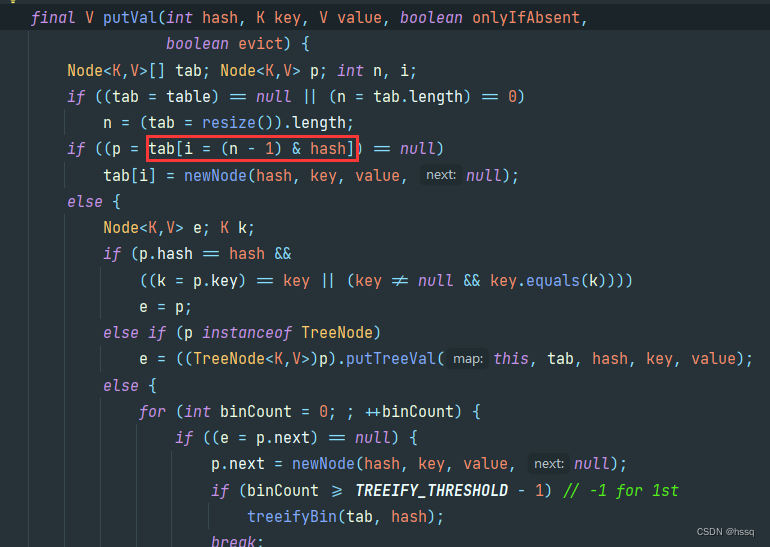
HashMap底层原理
文章目录1. 基本概念2. HashMap 的底层数据结构3. HashMap 的 put 方法流程4. 怎么计算节点存储的下标5. Hash 冲突1)概念2)解决 hash 冲突的办法开放地址法再哈希法链地址法建立公共溢出区6. HashMap 的扩容机制1)扩容时涉及到的几个属性2&a…...

卡顿优化小结
卡顿的本质 卡顿的本质是因为一次垂直同步信号来的时候,当前帧要显示的图像数据还没准备好,只能等待16ms下一次垂直同步信号来时才能更新画面,在这段时间里显示器只能一直停留在上一帧的画面,如果跳过的帧数过多,就会…...
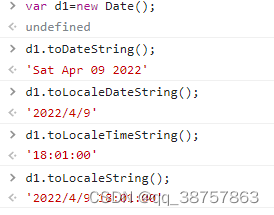
springboot前端ajax 04 关于后台传的时间和状态在前端的转换
修改状态及时间格式 在jsp中,时间显式: 只需要把json的时间部分改为用Date对象来显示就好了。 <td>new Date(jsonObj[i].startTime).toLocaleString()</td> <td>new Date(jsonObj[i].endTime).toLocaleString()</td> 状态对象…...
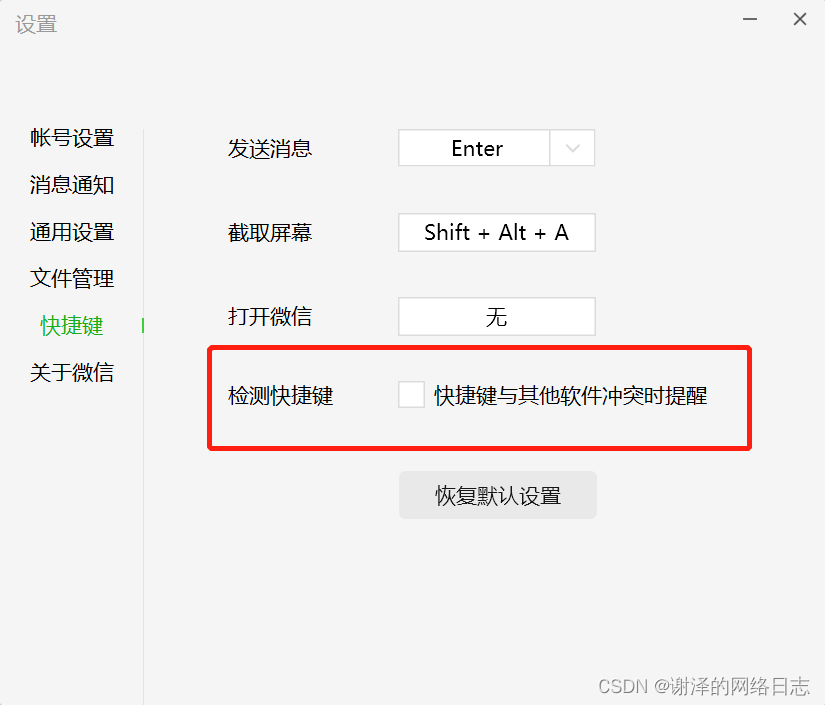
解决Windows微信和 PowerToys 的键盘管理器冲突
Windows开机之后PowerToys能正常使用, 但是打开微信之后设置好的快捷键映射就全部失效了 打开微信 -> 左下角三条杠 -> 设置 -> 快捷键 首先我把微信的快捷键全部清空了,发现还是没用 然后发现了设置里默认勾选了检测快捷键,我在想程序肯定是一直在后台检测,而powerTo…...

组会时间的工作
1. 党支部活动 看看组织生活记录本写完了没有 2. 论文翻译...
的自动化取证与图像重构实践)
从碎片到全景:基于RDP缓存文件(*.bmc)的自动化取证与图像重构实践
1. 揭开RDP缓存文件的神秘面纱 第一次接触*.bmc文件时,我完全没意识到这些看似普通的缓存文件里藏着这么多秘密。当时正在处理一个内部安全审计项目,需要确认某位离职员工是否通过远程桌面泄露了公司数据。在翻遍常规日志无果后,同事提醒我检…...

OpenFly实战:如何用无人机视觉语言导航工具链快速生成10万条训练数据
OpenFly实战:无人机视觉语言导航数据生成的10倍效率革命 当无人机开始理解人类语言指令时,一场人机交互的革命正在悄然发生。去年在深圳某科技园区,一组工程师仅用72小时就完成了过去需要三个月的数据采集工作——他们使用的秘密武器正是Open…...

TradingAgents-CN完整指南:5分钟搭建你的AI股票分析系统
TradingAgents-CN完整指南:5分钟搭建你的AI股票分析系统 【免费下载链接】TradingAgents-CN 基于多智能体LLM的中文金融交易框架 - TradingAgents中文增强版 项目地址: https://gitcode.com/GitHub_Trending/tr/TradingAgents-CN 还在为复杂的金融量化系统搭…...

聊天记录数据化生存:WeChatMsg从备份到分析的技术实践
聊天记录数据化生存:WeChatMsg从备份到分析的技术实践 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...

不只是 Copilot:一个完整 AI 软件交付团队的实践 - iforgeAI - 用更少的Tokens,办大事
在实际的软件开发过程中,一个完整的交付往往不是“写代码”这么简单。 从需求分析、架构设计、数据库建模,到 UI 设计、开发实现、测试与部署,每一个阶段都依赖不同角色的协作。 问题在于: 角色之间信息断层严重 文档不统一、不…...

2026年SCI论文AI率5%以下怎么做到?这3款降AI工具帮你稳过顶刊
投了三篇SCI,AI率问题折腾了快半年。 第一次投稿时完全不知道期刊有AI率要求,论文被直接拒稿,编辑在邮件里特别说明了AI生成内容的问题。从那以后就开始认真研究这个。先说结论:嘎嘎降AI(www.aigcleaner.comÿ…...
,搞定音频压缩和特征提取)
别再只用STFT了!用Python手把手实现短时DCT(STDCT),搞定音频压缩和特征提取
别再只用STFT了!用Python手把手实现短时DCT(STDCT),搞定音频压缩和特征提取 如果你处理过音频信号,大概率用过短时傅里叶变换(STFT)——这个在语音识别、音乐分析中无处不在的工具。但当你面对一…...
)
Python+Cartopy实战:用MODIS数据绘制全球气溶胶热力图(附完整代码)
PythonCartopy实战:用MODIS数据绘制全球气溶胶热力图(附完整代码) 当我们需要分析全球气溶胶分布时,卫星遥感数据提供了最全面的视角。MODIS(中分辨率成像光谱仪)作为NASA的重要观测工具,每天都…...

除了HDFS,DolphinScheduler资源中心还能怎么玩?聊聊S3与本地存储的配置差异
DolphinScheduler资源中心存储方案深度对比:从HDFS到S3的架构选型指南 在数据调度平台的实际部署中,存储后端的选型往往决定了系统整体的扩展性和运维成本。作为Apache DolphinScheduler的核心组件,资源中心支持多种存储类型配置,…...

Codesys实战排障手记:从证书过期到RTC时钟校准
1. 当Codesys突然弹出证书过期警告时 那天我正在客户现场调试禾川HCQ1系列PLC,刚打开Codesys V3.5开发环境,一个鲜红的证书过期警告就弹了出来。这种突如其来的报错让现场气氛瞬间紧张——产线等着调试,设备等着联调,而系统却在关…...