Hadoop MapReduce各阶段执行过程以及Python代码实现简单的WordCount程序
视频资料:黑马程序员大数据Hadoop入门视频教程,适合零基础自学的大数据Hadoop教程
文章目录
- Map阶段执行过程
- Reduce阶段执行过程
- Python代码实现MapReduce的WordCount实例
- mapper.py
- reducer.py
- 在Hadoop HDFS文件系统中运行
Map阶段执行过程
- 把输入目录下文件按照一定的标准逐个进行
逻辑切片,每个块的默认大小为Split size = Block size(128M),不足128M的为一个块,每一个切片由一个MapTask处理。 - 对切片中的数据按照一定的规则读取解析返回
<key, value>对。 - 调用Mapper类中的map方法处理数据。每读取解析出一个<key, value>,调用一次map方法。
- 按照一定的规则对Map输出的键值对进行
分区partition。默认不分区,因为只有一个reducetask。分区的数量就是reducetask运行的数量。 - Map输出数据写入
内存缓冲区Memory Buffer,达到比例溢出到磁盘上。溢出spill的时候根据key进行排序sort。默认根据key字典序排序。 - 对所有溢出文件进行最终的
合并merge,成为一个文件。

Reduce阶段执行过程
- ReduceTask会主动从MapTask
复制拉取属于需要自己处理的数据。 - 把拉取来的数据全部进行合并
merge,即把分散的数据合并成一个大的数据。再对合并后的数据排序。 - 对排序后的键值对调用reduce方法。
键相同的键值对调用一次reduce方法。最后把这些输出的键值对写入到HDFS文件中。
Python代码实现MapReduce的WordCount实例
首先介绍一个叫做Hadoop Streaming的工具,它能够帮助用户创建一类特殊的map/reduce作业,这些特殊的作业是由一些可执行文件或脚本文件充当mapper或者reducer。例如:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar \-input myInputDirs \-output myOutputDir \-mapper mapper.py \-reducer reducer.py
Mapper任务运行时,它把输入切分成行并把每一行提供给可执行文件进程的标准输入STDIN。 同时,mapper收集可执行文件进程标准输出STDOUT的内容,并把收到的每一行内容转化成key/value对,作为mapper的输出。
Reducer任务运行时,它把输入切分成行并把每一行提供给可执行文件进程的标准输入。 同时,reducer收集可执行文件进程标准输出的内容,并把每一行内容转化成key/value对,作为reducer的输出。
以下内容是代码示例:
新建文件夹WordCountTask,并在该文件夹下新建文本文档word.txt,输入以下内容:
Hello World
Hello Hadoop
Hello MapReduce
在WordCountTask文件夹下分别创建mapper.py和reducer.py两个文件:
mapper.py
#!/usr/bin/python3import sysfor line in sys.stdin:# 去除输入内容首位的空白字符line = line.strip()# 将输入内容分割为单词words = line.split()for word in words:# 将结果写到标准输出STDOUT,作为Reduce阶段代码的输入print("%s\t%s" % (word, 1))
输入命令cat word.txt | ./mapper.py,运行结果如下:
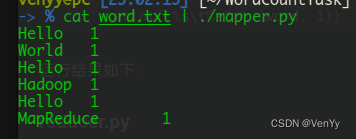
reducer.py
#!/usr/bin/python3import syscurrent_word = None
current_count = 0
word = Nonefor line in sys.stdin:line = line.strip()word, count = line.split("\t", 1)try:count = int(count)except ValueError:continueif current_word == word:current_count += countelse:if current_word:print("%s\t%s" % (current_word, current_count))current_count = countcurrent_word = wordif word == current_word:print("%s\t%s" % (current_word, current_count))输入命令cat word.txt | ./mapper.py | sort | ./reducer.py,运行结果如下:
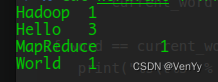
- 解释一下,符号
|是Linux系统中的管道符,管道符主要用于多重命令处理,前面命令的打印结果作为后面命令的输入。 sort命令用于将文本文件内容加以排序。
在Hadoop HDFS文件系统中运行
在三台虚拟机搭建的Hadoop伪分布式系统上运行刚刚写的mapper和reducer
- 首先需要启动Hadoop及所需组件:
- 在HDFS文件系统根目录下新建文件夹WordCountTask,并将word.txt上传到该目录下:
[root@master ~]# hadoop fs -mkdir /WordCountTask
[root@master ~]# hadoop fs -put WordCountTask/word.txt /WordCountTask
- 运行命令:
[root@master ~]# hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.7.1.jar \
-input /WordCountTask/ \
-output /WordCountTask/out \
-file /root/WordCountTask/mapper.py \
-mapper /root/WordCountTask/mapper.py \
-file /root/WordCountTask/reducer.py \
-reducer /root/WordCountTask/reducer.py
- 最终程序的结果在
-output参数指定的路径中,此路径为程序自动生成,程序执行前不能有该路径。Hadoop Streaming是Hadoop自带的流处理包。程序的流程是原文本以流式方式传到Map函数,Map函数处理之后把结果传到Reduce函数,最终结果会保存在HDFS上。
相关文章:
Hadoop MapReduce各阶段执行过程以及Python代码实现简单的WordCount程序
视频资料:黑马程序员大数据Hadoop入门视频教程,适合零基础自学的大数据Hadoop教程 文章目录Map阶段执行过程Reduce阶段执行过程Python代码实现MapReduce的WordCount实例mapper.pyreducer.py在Hadoop HDFS文件系统中运行Map阶段执行过程 把输入目录下文件…...

GitLab CI/CD 新书发布,助企业降本增效
前言 大家好,我是CSDN的拿我格子衫来, 昨天我的第一本书《GitLab CI/CD 从入门到实战》上架啦,这是业内第一本详细讲解GitLab CI/CD的书籍。 历经无数个日夜,最终开花结果。感触良多,今天就借这篇文章来谈一谈这本书的…...
【分享】如何写出整洁的代码?
文章目录前言1.为什么要保持代码整洁?1.1 所以从一开始就要保持整洁1.2 如何写出整洁的代码?2.命名3.类3.1单一职责3.2 开闭原则3.3 内聚4.函数4.1 只做一件事4.2 函数命名4.3 参数4.4 返回值4.5 怎样写出这样的函数?4.6 代码质量扫描工具5.测试5.1 TDD5.2 FIRST原则5.3 测试…...
视频剪辑:教你如何调整视频画面的大小。
大家应该都会调整图片的大小吧,那你们会调整视频画面的大小吗?我想,应该会有人不还不知道要调整的吧,今天就让小编来教大家一个方法怎样去调整视频画面的大小尺寸。 首先,我们要有以下材料: 一台电脑 【…...

操作系统概述
Overview Q1(Why):为什么要学操作系统?Q2(What):到底什么是操作系统?Q3(How):怎么学操作系统? 一.为什么要学操作系统? 学习操作系统…...
记录重启csdn
有太多收藏的链接落灰了,在此重启~ 1、社会 https://mp.weixin.qq.com/s/Uq0koAbMUk8OFZg2nCg_fg https://mp.weixin.qq.com/s/yCtLdEWSKVVAKhvLHxjeig https://zhuanlan.zhihu.com/p/569162335?utm_mediumsocial&utm_oi938179755602853888&ut…...

蓝牙耳机哪个品牌质量最好最耐用?蓝牙耳机排行榜10强推荐
现今,外出佩戴蓝牙耳机的人越来越多,各大品牌厂商对于蓝牙耳机各种性能的设计也愈发用心。那么,无线耳机哪个品牌音质好?下面,我来给大家推荐几款质量好的无线蓝牙耳机,可以当个参考。 一.南卡…...

mysql 双主架构详解
文章目录 一、背景二、MySQL双主(主主)架构方案三、MySQL双主架构图四、MySQL双主架构的优缺点五、MySQL双主架构,会存在什么问题?总结一、背景 MySQL 主从模式优缺点 容灾:主数据库宕机后,启动从数据库,用于故障切换 备份:防止数据丢失 读写分离:主数据库可以只负责…...
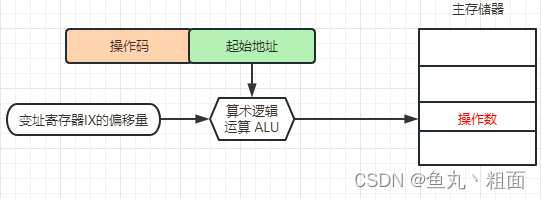
计算机指令系统基础 - 寻址方式详解
文章目录1 概述2 常见寻址方式2.1 立即寻址2.2 直接寻址2.3 间接寻址2.4 寄存器寻址2.5 寄存器间接寻址2.6 相对寻址2.7 变址寻址3 扩展3.1 操作码3.2 常见寄存器1 概述 计算机指令:指挥计算机工作的 指示 和 命令内容:通常一条 指令 包括两方面的内容 …...
React Three Fiber动画入门
使用静态对象和形状构建 3D 场景非常酷,但是当你可以使用动画使场景栩栩如生时,它会更酷。 在 3D 世界中,有一个称为角色装配的过程,它允许你创建称为骨架的特殊对象,其作用类似于骨骼和关节系统。 这些骨架连接到一块…...

为什么我推荐你使用 systemd timer 替代 cronjob?
概述 前几天在使用 Terraform cloud-init 批量初始化我的实验室 Linux 机器。正好发现有一些定时场景需要使用到 cronjob, 进一步了解到 systemd timer 完全可以替换 cronjob, 并且 systemd timer 有一些非常有趣的功能。 回归话题:为什么我推荐你使用 systemd t…...
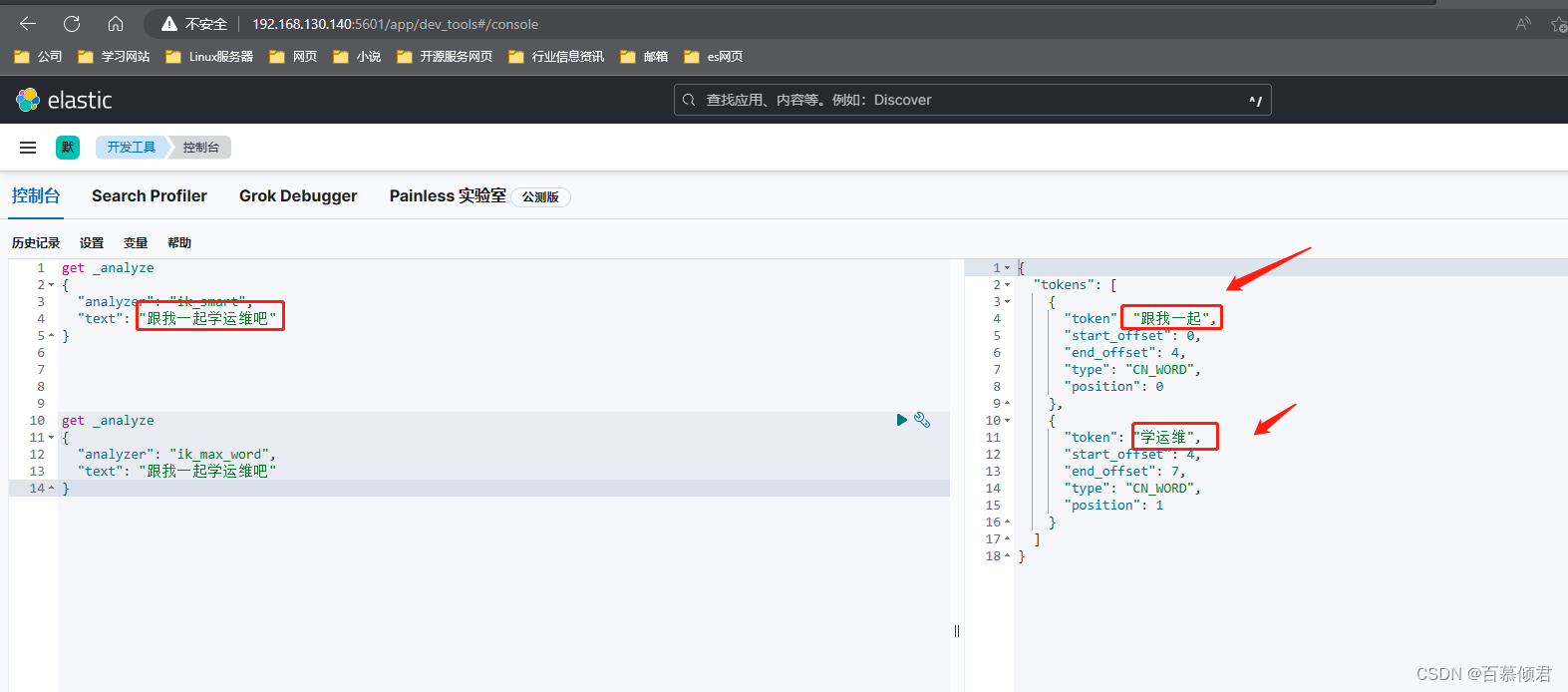
elasticsearch基础6——head插件安装和web页面查询操作使用、ik分词器
文章目录一、基本了解1.1 插件分类1.2 插件管理命令二、分析插件2.1 es中的分析插件2.1.1 官方核心分析插件2.1.2 社区提供分析插件2.2 API扩展插件三、Head 插件3.1 安装3.2 web页面使用3.2.1 概览页3.2.1.1 unassigned问题解决3.2.2 索引页3.2.3 数据浏览页3.2.4 基本查询页3…...
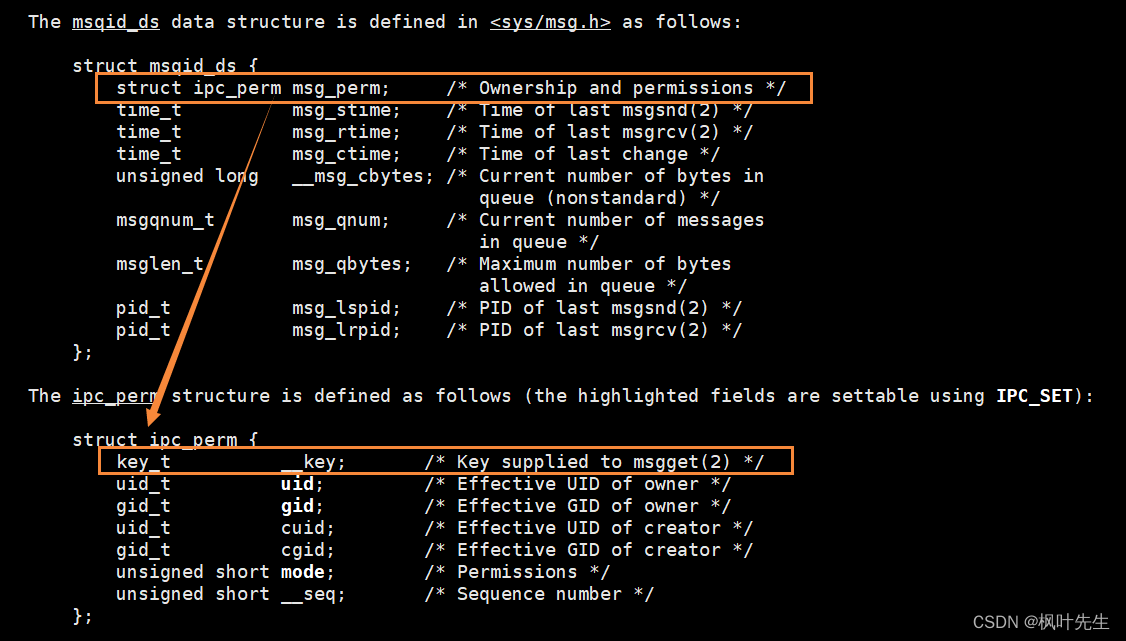
【Linux】七、进程间通信(二)
目录 三、system V(IPC) 3.1 system V共享内存 3.1.1 共享内存的概念 3.1.2 共享内存的原理 3.1.3 创建共享内存(shmget ) 3.1.4 ftok函数 3.1.5 查看共享内存资源 3.1.6 创建共享内存测试代码 3.1.7 再次理解共享内存 3.1.8 释放共享内存(shm…...

Synchronized学习大总结
目录 1.synchronized特性 2.synchronized如何使用 3.synchronized的锁机制 1.synchronized特性 synchronized 是乐观锁,也是悲观锁,是轻量级锁(j基于自旋锁实现),也是重量级锁(基于挂起等待锁实现),它不是读写锁,是互斥锁,当一个线程抢到锁之后,其它线程阻塞等待,进入synchr…...
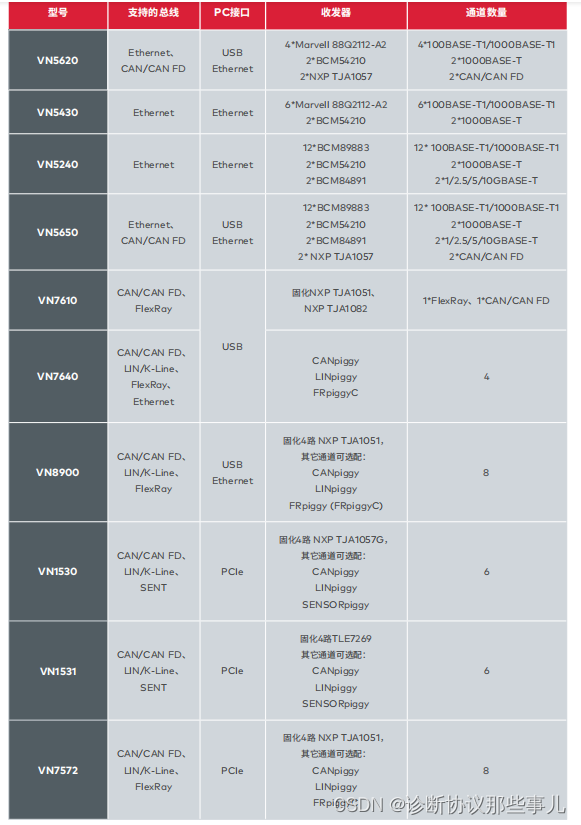
VN5620以太网测试——环境搭建篇
文章目录 前言一、新建以太网工程二、Port Configuration三、Link up四 Trace界面五、添加Ethernet Packet Builder六、添加ARP Packet七、添加Ethernet IG总结前言 CANoe(CAN open environment)VN5620 :是一个紧凑而强大的接口,用于以太网网络的分析、仿真、测试和验证。 …...
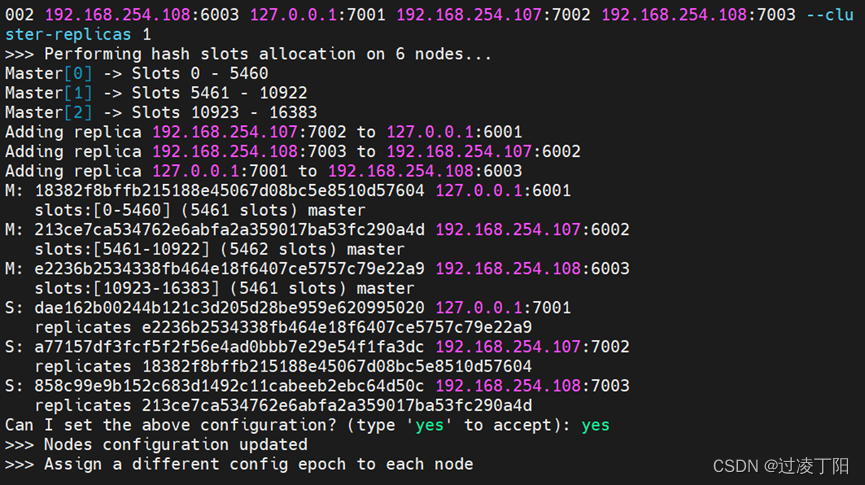
redis哨兵和集群部署手册
一、哨兵模式原理及作用 1.原理 哨兵(sentinel): 是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现 故障时,通过投票机制选择新的master并将所有slave连接到新的master。所以整个运行哨兵的集…...

ctfshow web入门 java 295 298-300
其他没啥好讲的,都是工具就通杀了 web295 漏洞地址 http://ip/S2-048/integration/saveGangster.action 这里我们可以看到他是解析了 尝试使用网上的payload %{(#dmognl.OgnlContextDEFAULT_MEMBER_ACCESS).(#_memberAccess?(#_memberAccess#dm):((#container#cont…...

SWIG包装器使用指南——(四)C#使用SWIG简介与实践
SWIG系列:http://t.csdn.cn/cIAcr 文章目录一、简介二、全局函数、变量、常量三、继承四、传递指针、引用、数组与值五、基本类型的指针与引用六、基本类型的数组七、基本类型的默认map规则八、常用的typemap方法九、代码插入十、实践10.1 如何映射Foo*&到ref F…...

HashTable, HashMap 和 ConcurrentHashMap
HashTable, HashMap 和 ConcurrentHashMap 都是 Java 集合框架中的类,用于存储和操作键值对。它们之间存在一些关键区别,如下所示: 1.同步性: HashTable:线程安全,所有的方法都是同步的(synchr…...

ToBeWritten之IoT 技战法
也许每个人出生的时候都以为这世界都是为他一个人而存在的,当他发现自己错的时候,他便开始长大 少走了弯路,也就错过了风景,无论如何,感谢经历 转移发布平台通知:将不再在CSDN博客发布新文章,敬…...

Windows/Mac/Linux三平台实测:X-AnyLabeling自动标注YOLO数据集避坑指南
Windows/Mac/Linux三平台实测:X-AnyLabeling自动标注YOLO数据集避坑指南 在计算机视觉项目的开发流程中,数据标注往往是耗时最长的环节之一。传统手动标注不仅效率低下,还容易因疲劳导致标注质量下降。X-AnyLabeling作为一款新兴的开源标注工…...

从Word2Vec到BERT:前馈网络在NLP词嵌入进化史中扮演了什么角色?
从Word2Vec到BERT:前馈网络如何重塑NLP词嵌入的技术基因 在自然语言处理(NLP)的发展历程中,词嵌入技术的进化犹如一场静默的革命。当我们回溯这段历史时会发现,前馈神经网络(Feedforward Neural Network&am…...

BULLM_ExtendMotor:8通道I²C电机驱动Arduino HAL库
1. 项目概述BULLM_ExtendMotor 是专为牛明工作室(BULLM Studio)8通道电机驱动扩展板设计的嵌入式控制库。该扩展板采用 IC 总线通信,集成 8 路独立可逆直流电机驱动通道,每通道支持 PWM 调速与方向控制,适用于多轴运动…...

告别黑苹果配置噩梦:5大核心优势让开源工具OpCore-Simplify成为新手救星
告别黑苹果配置噩梦:5大核心优势让开源工具OpCore-Simplify成为新手救星 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 黑苹果配置一直是…...

设计师福音:Z-Image-Turbo_UI界面实现草图到成品的快速转化
设计师福音:Z-Image-Turbo_UI界面实现草图到成品的快速转化 你是不是也遇到过这样的场景?脑子里有一个绝妙的创意,手绘了一张草图,但要把这个草图变成一张精美的成品图,却需要花费数小时甚至数天的时间,在…...

Fluent Bit源码解析:KISS原则如何打造轻量级日志处理神器
Fluent Bit源码解析:KISS原则如何打造轻量级日志处理神器 【免费下载链接】fluent-bit Fast and Lightweight Logs and Metrics processor for Linux, BSD, OSX and Windows 项目地址: https://gitcode.com/GitHub_Trending/fl/fluent-bit 在当今云原生时代&…...

告别Keil:用VS Code + EIDE打造高效C51开发环境
1. 为什么我们要放弃Keil? 如果你接触过C51单片机开发,Keil μVision这个名字一定不会陌生。作为单片机开发领域的"老前辈",Keil几乎成了教学和入门的标准工具。但说实话,每次打开那个灰蒙蒙的界面,我都感觉…...

PvZ Toolkit 技术指南:从游戏修改到体验重塑
PvZ Toolkit 技术指南:从游戏修改到体验重塑 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 价值定位:为什么选择 PvZ Toolkit? 当你在《植物大战僵尸》无尽模式…...

网络工程师的日常:一次搞定eNSP中MSTP+VRRP的‘坑’与优化技巧
eNSP实战:MSTPVRRP组网中的典型故障排查与性能调优 凌晨两点,当我在eNSP模拟器中第三次看到"VRRP state transition to Backup"的日志时,咖啡杯已经见底。这个典型的双核心企业网架构本该在半小时内完成配置,却因为MSTP…...

dry容器管理实战:从创建、启动到停止删除的全流程操作
dry容器管理实战:从创建、启动到停止删除的全流程操作 【免费下载链接】dry moncho/dry: dry(Docker Run Commands)是一款命令行工具,旨在简化对Docker容器的操作管理,提供了一种简洁的方式创建、启动、停止和删除Dock…...