[linux kernel]slub内存管理分析(7) MEMCG的影响与绕过
文章目录
- 背景
- 前情回顾
- 描述方法约定
- MEMCG总览
- 省流总结
- 简介
- slub 相关 memcg机制
- kernel 5.9 版本之前
- 结构体
- 初始化
- 具体实现
- kernel 5.9-5.14
- kernel 5.14 之后
- 突破slab限制方法
- cross cache attack
- page 堆风水
- 总结
背景
前情回顾
关于slab几个结构体的关系和初始化和内存分配和释放的逻辑请见:
[linux kernel]slub内存管理分析(0) 导读
[linux kernel]slub内存管理分析(1) 结构体
[linux kernel]slub内存管理分析(2) 初始化
[linux kernel]slub内存管理分析(2.5) slab重用
[linux kernel]slub内存管理分析(3) kmalloc
[linux kernel]slub内存管理分析(4) 细节操作以及安全加固
[linux kernel]slub内存管理分析(5) kfree
[linux kernel]slub内存管理分析(6) 销毁slab
描述方法约定
PS:为了方便描述,这里我们将一个用来切割分配内存的page 称为一个slab page,而struct kmem_cache我们这里称为slab管理结构,它管理的真个slab 体系成为slab cache,struct kmem_cache_node这里就叫node。单个堆块称为object或者堆块或内存对象。
MEMCG总览
省流总结
- 如果开启了memcg,那么kmalloc 申请相同大小的附带ACCOUNT关键字的flag的内存和不带ACCOUNT 关键字的内存可能是从不同slab 中申请的:
- 在kernel 版本小于5.9(不包括5.9) 的情况下,两者申请的内存属于不同slab
- 在kernel 版本属于5.9-5.14(包括5.9,不包括5.14)的情况下,两者申请的内存属于相同slab
- 在kernel 版本大于5.14(包括5.14)的情况下,两者申请的内存属于不同slab,但和第一种情况的实现不同
- 对于跨slab 的漏洞利用,可以考虑使用cross cache attack 或页面级堆风水来做。
其实memcg 本质上来说是一个统计功能,用于统计在cgroup 场景下申请内存的多少什么的,但它的实现方式可能会对我们的漏洞利用带来麻烦,下面简单从源码角度分析一下。
简介
memcg 全称memory cgroup,是cgroup 的一种,其实现了内存资源的隔离与限制功能。在内核中的整体实现是一个包括cgroup模块、内存管理模块等跨模块的实现。而为什么要在这里提到MEMCG呢,是因为我们分析slub 算法源码的主要目的还是为了做内核的漏洞利用。而memcg 的一个在内存管理模块的"记账(统计)"机制会给我们的漏洞利用带来一些麻烦,需要我们注意。
内核编译选项CONFIG_MEMCG 决定是否开启memcg 功能,但这个是默认开启的。
slub 相关 memcg机制
kernel 5.9 版本之前
结构体
struct kmem_cache {··· ···
#ifdef CONFIG_MEMCGstruct memcg_cache_params memcg_params;///* For propagation, maximum size of a stored attr */unsigned int max_attr_size;
#ifdef CONFIG_SYSFSstruct kset *memcg_kset;
#endif
#endif
··· ···
};
开启CONFIG_MEMCG 的情况下在slab 管理结构kmem_cache中会多出一个比较重要的成员memcg_params,属于memcg_cache_params 结构体,memcg_cache_params 用于记录memcg 在slab 相关的一些参数:
struct memcg_cache_params {struct kmem_cache *root_cache;//指向根slabunion {struct {struct memcg_cache_array __rcu *memcg_caches;//存放若干子memcg slab 管理结构struct list_head __root_caches_node;struct list_head children;bool dying;};··· ···};
};
root_cache 指向根slab,也就是说可以通过根slab的memcg_params 找到子slab,也可以通过子slab 的root_cache 找到所属的跟slab。
memcg_caches 是一个memcg_cache_array 结构的成员,存放子memcg slab 的数组:
struct memcg_cache_array {struct rcu_head rcu;struct kmem_cache *entries[0];//子memcg slab 的数组
};
entries 是子memcg slab 的数组,通过memcg id 进行下标寻找。
所以可以理解为每一个根slab 管理结构(根slab 管理结构根据大小分类)都有一个对应的子memcg slab 列表。
初始化
主要的初始化函数是init_memcg_params:
mm\slab_common.c : init_memcg_params
static int init_memcg_params(struct kmem_cache *s,struct kmem_cache *root_cache)
{struct memcg_cache_array *arr;if (root_cache) {int ret = percpu_ref_init(&s->memcg_params.refcnt,kmemcg_cache_shutdown,0, GFP_KERNEL);if (ret)return ret;s->memcg_params.root_cache = root_cache;INIT_LIST_HEAD(&s->memcg_params.children_node);INIT_LIST_HEAD(&s->memcg_params.kmem_caches_node);return 0;}slab_init_memcg_params(s);if (!memcg_nr_cache_ids)return 0;arr = kvzalloc(sizeof(struct memcg_cache_array) + //最多含有memcg_nr_cache_ids 个子slabmemcg_nr_cache_ids * sizeof(void *),GFP_KERNEL);if (!arr)return -ENOMEM;RCU_INIT_POINTER(s->memcg_params.memcg_caches, arr);return 0;
}
除此之外,memcg 在slab 相关的初始化可以关注调用栈中多出的memcg 相关函数:
kmem_cache_init
- create_boot_cache
- slab_init_memcg_params //初始化memcg
- __kmem_cache_create
- ··· ···
- memcg_propagate_slab_attrs //初始化memcg
- bootstrap
- ··· ···
- slab_init_memcg_params//初始化memcg
- memcg_link_cache //初始化memcg
- create_kmalloc_caches
- new_kmalloc_cache
- create_kmalloc_cache
- ··· ···
- memcg_link_cache //初始化memcg
- create_kmalloc_cache
- new_kmalloc_cache
具体实现
我们这里以kernel 5.4 版本的源码为例,首先看关键的部分,经过之前的分析,我们知道,在kmalloc 的调用栈中有slab_alloc_node 函数,在其中调用的slab_pre_alloc_hook 函数我们没有分析,现在看slab_pre_alloc_hook 函数的实现:
static __always_inline void *slab_alloc_node(struct kmem_cache *s,gfp_t gfpflags, int node, unsigned long addr)
{void *object;struct kmem_cache_cpu *c;struct page *page;unsigned long tid;s = slab_pre_alloc_hook(s, gfpflags);//调用slab_pre_alloc_hook,memcg相关,可能会替换slab 管理结构sif (!s)return NULL;
redo:··· ······ ···
}
分析slab_pre_alloc_hook 函数:
mm\slab.h : slab_pre_alloc_hook
static inline struct kmem_cache *slab_pre_alloc_hook(struct kmem_cache *s,gfp_t flags)
{flags &= gfp_allowed_mask;fs_reclaim_acquire(flags);fs_reclaim_release(flags);might_sleep_if(gfpflags_allow_blocking(flags));if (should_failslab(s, flags))return NULL;if (memcg_kmem_enabled() &&//开启memcg,并且flag中含有__GFP_ACCOUNT 或SLAB_ACCOUNT((flags & __GFP_ACCOUNT) || (s->flags & SLAB_ACCOUNT)))return memcg_kmem_get_cache(s);return s;
}
前文提到过,如果调用kmalloc 时的flag 中有ACCOUNT关键字的话,可能会从不同slab 申请内存,这里进行判断,如果开启了memcg并且flag 中为__GFP_ACCOUNT 与SLAB_ACCOUNT的话,则会调用memcg_kmem_get_cache 并返回。
在memcg_kmem_get_cache 函数中会将cgroup 对应的slab 管理结构找到并返回,如果尚未初始化该slab结构,则在这里现创建:
mm\memcontrol.c : memcg_kmem_get_cache
struct kmem_cache *memcg_kmem_get_cache(struct kmem_cache *cachep)
{struct mem_cgroup *memcg;struct kmem_cache *memcg_cachep;struct memcg_cache_array *arr;int kmemcg_id;VM_BUG_ON(!is_root_cache(cachep));//[1]传入的一定要是root 所属的if (memcg_kmem_bypass())//中断或内核进程不需要统计操作,直接返回return cachep;rcu_read_lock();if (unlikely(current->active_memcg))memcg = current->active_memcg; //[2]获取当前进程cgroup 的mem_cgroupelsememcg = mem_cgroup_from_task(current);//获取当前进程cgroup 的mem_cgroupif (!memcg || memcg == root_mem_cgroup) //如果是根cgroup 则直接返回,不需要统计操作goto out_unlock;kmemcg_id = READ_ONCE(memcg->kmemcg_id); //获取memcg idif (kmemcg_id < 0)goto out_unlock;arr = rcu_dereference(cachep->memcg_params.memcg_caches);···memcg_cachep = READ_ONCE(arr->entries[kmemcg_id]);···if (unlikely(!memcg_cachep))//如果还没有memcg_cachepmemcg_schedule_kmem_cache_create(memcg, cachep);//分配并初始化该cgroup 的slab 管理结构else if (percpu_ref_tryget(&memcg_cachep->memcg_params.refcnt))cachep = memcg_cachep;//存在memcg_cachep,则直接返回
out_unlock:rcu_read_unlock();return cachep;
}
调用memcg_schedule_kmem_cache_create 来进行memcg 特定slab 的申请与初始化:
mm\memcontrol.c : memcg_schedule_kmem_cache_create
static void memcg_schedule_kmem_cache_create(struct mem_cgroup *memcg,struct kmem_cache *cachep)
{··· ···INIT_WORK(&cw->work, memcg_kmem_cache_create_func);//启动了一个内核任务去初始化queue_work(memcg_kmem_cache_wq, &cw->work);
}
static void memcg_kmem_cache_create_func(struct work_struct *w)
{··· ··memcg_create_kmem_cache(memcg, cachep);··· ···
}
这里启动了一个内核任务,具体任务执行memcg_kmem_cache_create_func 函数,在其中直接调用了memcg_create_kmem_cache 函数来实现slab 申请与初始化:
mm\slab_common.c : memcg_create_kmem_cache
void memcg_create_kmem_cache(struct mem_cgroup *memcg,struct kmem_cache *root_cache)
{static char memcg_name_buf[NAME_MAX + 1];··· ···idx = memcg_cache_id(memcg);//获取memcg idarr = rcu_dereference_protected(root_cache->memcg_params.memcg_caches,lockdep_is_held(&slab_mutex));//rcu解锁···if (arr->entries[idx])//如果其他任务先完成了申请,则这里直接退出goto out_unlock;cgroup_name(css->cgroup, memcg_name_buf, sizeof(memcg_name_buf));//初始化name字符串cache_name = kasprintf(GFP_KERNEL, "%s(%llu:%s)", root_cache->name,css->serial_nr, memcg_name_buf);//组合slab 的名字字符串if (!cache_name)goto out_unlock;s = create_cache(cache_name, root_cache->object_size,//调用create_cache 申请与初始化slabroot_cache->align,root_cache->flags & CACHE_CREATE_MASK,root_cache->useroffset, root_cache->usersize,root_cache->ctor, memcg, root_cache);··· ······ ···
}
kernel 5.9-5.14
在该commit: 10befea91b61c4e2c2d1df06a2e978d182fcf792 之后,memcg 简化了实现方式,将所有的分配都试用同一组slab(可能是由于内存泄露等原因)。删除了大量代码(包括初始化阶段、分配、释放阶段等),我们直接看关键改动,以5.13代码为例,还是slab_pre_alloc_hook函数:
mm\slab.h : slab_pre_alloc_hook
static inline struct kmem_cache *slab_pre_alloc_hook(struct kmem_cache *s,struct obj_cgroup **objcgp,size_t size, gfp_t flags)
{flags &= gfp_allowed_mask;might_alloc(flags);if (should_failslab(s, flags))return NULL;if (!memcg_slab_pre_alloc_hook(s, objcgp, size, flags))return NULL;return s;//无论如何返回的都是s本身
}
可以看出,经过修改之后,使用memcg_slab_pre_alloc_hook 函数进行统计操作,具体操作我们不管,但最后返回的就是传入的slab 管理结构s,也就是说slab 没有因为存在ACCOUNT而被替换。
在memcg_slab_pre_alloc_hook 函数中,根据是否含有ACCOUNT关键字而进行是否统计的处理:
mm\slab.h : memcg_slab_pre_alloc_hook
static inline bool memcg_slab_pre_alloc_hook(struct kmem_cache *s,struct obj_cgroup **objcgp,size_t objects, gfp_t flags)
{struct obj_cgroup *objcg;if (!memcg_kmem_enabled())return true;if (!(flags & __GFP_ACCOUNT) && !(s->flags & SLAB_ACCOUNT))//不需要统计就直接返回return true;objcg = get_obj_cgroup_from_current();if (!objcg)return true;if (obj_cgroup_charge(objcg, flags, objects * obj_full_size(s))) {//统计obj_cgroup_put(objcg);return false;}*objcgp = objcg;return true;
}
具体使用obj_cgroup_charge 函数进行统计操作,具体就不分析了。
kernel 5.14 之后
在该commit: 494c1dfe855ec1f70f89552fce5eadf4a1717552后,又从"所有分配都在同一个slab"变回了ACCOUNT关键字在不同slab 分配,但具体实现有所不同。
我们知道,全局的通用slab 缓存数组 kmalloc_caches 是一个二维数组:
extern struct kmem_cache *
kmalloc_caches[NR_KMALLOC_TYPES][KMALLOC_SHIFT_HIGH + 1];
其中下标1代表slab 的类型,下标2代表slab 可以分配堆块的大小,通过kmalloc申请的时候的flag确定类型,通过大小确定大小。在5.14更新之后,在类型中新增如下类型:
enum kmalloc_cache_type {KMALLOC_NORMAL = 0,
#ifndef CONFIG_ZONE_DMAKMALLOC_DMA = KMALLOC_NORMAL,
#endif
#ifndef CONFIG_MEMCG_KMEMKMALLOC_CGROUP = KMALLOC_NORMAL,
#elseKMALLOC_CGROUP,//新增了KMALLOC_CGROUP类
#endifKMALLOC_RECLAIM,
#ifdef CONFIG_ZONE_DMAKMALLOC_DMA,
#endifNR_KMALLOC_TYPES
};这样用于MEMCG统计的slab 就变成了和通常slab "平级"的slab 了。然后在
#define KMALLOC_NOT_NORMAL_BITS \(__GFP_RECLAIMABLE | \(IS_ENABLED(CONFIG_ZONE_DMA) ? __GFP_DMA : 0) | \(IS_ENABLED(CONFIG_MEMCG_KMEM) ? __GFP_ACCOUNT : 0)) //如果携带了ACCOUNT 就会被标记为KMEMCGstatic __always_inline enum kmalloc_cache_type kmalloc_type(gfp_t flags)
{/** The most common case is KMALLOC_NORMAL, so test for it* with a single branch for all the relevant flags.*/if (likely((flags & KMALLOC_NOT_NORMAL_BITS) == 0))return KMALLOC_NORMAL;/** At least one of the flags has to be set. Their priorities in* decreasing order are:* 1) __GFP_DMA* 2) __GFP_RECLAIMABLE* 3) __GFP_ACCOUNT*/if (IS_ENABLED(CONFIG_ZONE_DMA) && (flags & __GFP_DMA))return KMALLOC_DMA;if (!IS_ENABLED(CONFIG_MEMCG_KMEM) || (flags & __GFP_RECLAIMABLE))return KMALLOC_RECLAIM;elsereturn KMALLOC_CGROUP;//增加堆KMEMCG类型的判断
}
这样就可以在kmalloc逻辑最开始确定slab 的环节就直接区分ACCOUNT 相关flag 和普通GFP_KERNEL flag 的分配所在的slab。
突破slab限制方法
那么我们已经确定了在一些版本下拥有ACCOUNT相关flag的内存分配和通常的内存分配不在一个slab之中。而且这两种分配方式在内核中非常常见,我们该如何解决呢?这里提供两种可以突破slab 隔离让两个不同slab 堆块申请到一起的方法,不只是可以突破GFP_KERNEL和GFP_ACCOUNT和之间的隔离,还可以突破特殊slab和普通slab的隔离,如通常slab 和文件slab filp_cachep之间的隔离。
适用场景是在一些漏洞比如UAF,Double Free,越界读写漏洞触发在某种不方便利用的slab上时,比如发生在struct file所在的sla:filp_cachep,而我们的漏洞利用原语都是普通的NORMAL类型,自然是无法让我们的堆块和目标堆块"连着"或者UAF的重用可以重申请到该堆块。那么就需要使用一些手段来打破这种隔离,目前有两种比较好的做法。
cross cache attack
我们利用slab page为空的时候会被系统回收的机制,让从slab A申请的堆块所在的page 为空后被系统回收,然后让slab B申请到该page,这样slab B后续的分配就可以从之前分配过slab A的堆块来分配了。适用于double free或UAF场景下,以double free为例简要操作逻辑如下:
首先我们假定发生double free 的slab 和凭证slab 的大小是一样的为kmalloc-x,该利用方法也是CVE-2022-2588中采用的:
- 喷射若干kmalloc-x 的堆块,其中构造一个洞,然后让可以double free 的结构落在洞中。或如果double free的目标允许喷射的话,则直接喷射若干目标结构即可。最后达到的一个效果就是,double free的目标指针所在slab page 的所有堆块我们都可以手动释放。
- 手动释放刚刚喷射的所有堆块,并且使用一次double free/非法free 操作,这样double free对象所在slab 页已经被释放空,那么该页就会被回收,但非法释放的指针还指向这个页中的内存块上。
- 喷射若干可控凭证结构,这时凭证slab 就会向系统申请内存页,刚被回收的页面就会被分配给凭证slab。这时之前非法释放的指针就指向了一个凭证结构体。
- 使用第二次free,将该凭证释放掉,然后喷射一堆高权限的/提权目标的凭证结构,就会申请到刚刚被非法释放的低权限凭证结构的内存块,就达到了替换低权限凭证为高权限凭证的目的。
如下方动图演示:

但事实是并不能保证我们double free发生的slab 大小和凭证slab 大小相同,如果大小不同,那么可以按照如下方式来构造凭证的替换:

-
同样是喷射若干double free 大小的堆块,达到释放的时候能让double free 目标所在page 全部释放空就行
-
然后使用两次double free构造一个"三个个可以释放的指针指向同一个内存块"的状态

-
把喷射的堆块全部释放,再释放一次目标堆块,让double free目标所在page释放空以至于页面被回收
-
喷射若干可控凭证结构,这时凭证slab 就会向系统申请内存页,刚被回收的页面就会被分配给凭证slab。这时之前非法释放的指针就指向了凭证slab页面中一个不和结构体对齐的位置:

-
虽然这里ptr 1’ 和ptr 2’ 并不整齐的指向凭证结构,但仍然可以通过以下方法完成置换:
- 释放ptr 1’ ,然后喷射若干低权限凭证,就会有一个落在ptr 1’的位置
- 释放ptr 2’ ,然后喷射若干高权限凭证,完成替换
这里主要利用了free 的这个机制,查看kfree源码:
linux\mm\slub.c : kfree
void kfree(const void *x)
{struct page *page;void *object = (void *)x;trace_kfree(_RET_IP_, x);if (unlikely(ZERO_OR_NULL_PTR(x)))return;page = virt_to_head_page(x);//根据地址找到对应的page结构体if (unlikely(!PageSlab(page))) {//如果该page 不是slab,那么就是大块内存了,调用free_page释放unsigned int order = compound_order(page);BUG_ON(!PageCompound(page));kfree_hook(object);mod_lruvec_page_state(page, NR_SLAB_UNRECLAIMABLE_B,-(PAGE_SIZE << order));__free_pages(page, order);return;}slab_free(page->slab_cache, page, object, NULL, 1, _RET_IP_);//释放slab 分配的内存块
}
首先会通过释放的堆块地址找到对应的struct page结构体(这个page肯定用于slab 分配),然后会调用slab_free 来进行实际分配,也就是说,第一步的操作是根据释放的堆内存,找到管理该内存page 的slab(struct kmem_cache)。
linux\mm\slub.c : slab_free
static __always_inline void slab_free(struct kmem_cache *s, struct page *page,void *head, void *tail, int cnt,unsigned long addr)
{if (slab_free_freelist_hook(s, &head, &tail))do_slab_free(s, page, head, tail, cnt, addr);//调用do_slab_free
}
static __always_inline void do_slab_free(struct kmem_cache *s,struct page *page, void *head, void *tail,int cnt, unsigned long addr)
{··· ···
redo:··· ······ ···if (likely(page == c->page)) {//释放的对象正好属于当前cpu_slab正在使用的slab则快速释放void **freelist = READ_ONCE(c->freelist);//获取freelistset_freepointer(s, tail_obj, freelist);//将新释放内存块插入freelist 开头if (unlikely(!this_cpu_cmpxchg_double(//this_cpu_cmpxchg_double()原子指令操作存放s->cpu_slab->freelist, s->cpu_slab->tid,freelist, tid,head, next_tid(tid)))) {note_cmpxchg_failure("slab_free", s, tid);//失败记录goto redo;}stat(s, FREE_FASTPATH);} else__slab_free(s, page, head, tail_obj, cnt, addr);//否则说明释放的内存不是当前cpu_slab立马能释放的}
这里可以看到,将释放的堆块直接放入freelist 的开头。那么下次申请该slab 的内存的时候,就会从freelist 开头直接取一个内存。可以看出这里并没有进行内存地址对齐的判断(后面的申请操作中也没有)。
具体做法可以参考CVE-2022-2588 和Dirty-Cred中的描述。
[漏洞分析] CVE-2022-2588 route4 double free内核提权
[kernel exploit] Dirty Cred: 一种新的无地址依赖漏洞利用方案
page 堆风水
上面的方法适用于UAF和Double Free这类需要漏洞堆块和利用堆块重合的场景,但如果我们是溢出类漏洞,需要漏洞堆块和利用堆块相邻,该如何操作呢。这里可以使用cve-2022-27666 中提到的页面级堆风水。
首先我们想要的是让溢出漏洞所在的堆块,和我们想要通过溢出覆盖的堆块相邻,但他们属于不同的slab(要么不同种类,要么不同大小,总之就是申请不到一起去)。但,我们虽然不能让堆块相邻,我们是可以让页面相邻的,我们可以构造如下的场景:

红色的小块代表漏洞所在的堆块,红色组成的大块代表所在的spab page,相对的蓝色代表目标(被越界操作)的堆块,我们可以构造两个slab page相邻,然后前一个slab page的最后一个堆块自然就和后一个slab page 的第一个堆块相邻了。那么如何让两个slab page准确的相邻呢,这就涉及到伙伴系统申请页面的逻辑了:
- 伙伴系统申请页面的时候需要提供一个order 值,这个order值代表申请
2^order个页面,例如order=3,则会申请到8页。我们的slab 每次去伙伴系统申请新的slab page都是申请order=3 的页面。 - 伙伴系统自身会根据order 不同维护若干个队列,每个队列中都是若干个对应order 大小的空白页,当有所属order 大小的页分配的时候直接从该队列返回一个空闲页。
- 若所属的order 分配光了,则会从order+1的队列中获取一个空白页,然后将其分一半给分配者,另一半留在order队列中,如下动图所示:

例如我们申请一个大尺寸页如order 4 0x10000,如果当前没有order 4 的空闲页的话,会实际会分配一个order 5 0x20000 的连续页并分成两半,把其中一半分配给申请者,另一半放在order 4队列里。然后order 小于这些的依次参照这个规则。
那么就可以肯定的一件事就是,从order 5分配的两个order 4 是地址相连的。那么以此类推,假如我们把所有的order 4以下的都消耗殆尽,那么申请order 0 0x1000(msg_msg) 的就会尝试将order 1分成两个,order 1 也没了那就尝试将order 2 分成两个… 那么以此类推就会分割刚刚分配order 4 剩下的另一半order 5。
所以如果想让两个不同slab 的堆块相连,可以先将小order 队列中的堆都消耗光,然后通过如rx_ring buffer这种可以申请超大内存页的结构体连续申请若干,这样可以确定的事连续两个rx_ring buffer一定是相邻的大页。那么隔一个释放一个rx_ring buffer然后堆喷第一种slab 的堆块,然后再将剩下的rx_ring buffer释放掉再堆喷另一种slab 的堆块,就可以构造出相连的场景了。这种场景两种参与的堆块的大小越大(最好是整页的倍数)越容易构造。
总结
总结就是,5.9 前和5.14 后,带有"ACCOUNT"flag 的kmalloc 申请是用的是单独slab。而5.9-5.14 简化为使用相同slab,利用的过程中要注意版本,有些版本能申请到一起去,有些是不行的。但如果漏洞允许使用上面你的一些绕过方法的话,还是可以的。
相关文章:
[linux kernel]slub内存管理分析(7) MEMCG的影响与绕过
文章目录背景前情回顾描述方法约定MEMCG总览省流总结简介slub 相关 memcg机制kernel 5.9 版本之前结构体初始化具体实现kernel 5.9-5.14kernel 5.14 之后突破slab限制方法cross cache attackpage 堆风水总结背景 前情回顾 关于slab几个结构体的关系和初始化和内存分配和释放的…...
)
MySQL创建数据库(CREATE DATABASE语句)
在 MySQL 中,可以使用 CREATE DATABASE 语句创建数据库,语法格式如下: CREATE DATABASE [IF NOT EXISTS] <数据库名> [[DEFAULT] CHARACTER SET <字符集名>] [[DEFAULT] COLLATE <校对规则名>]; [ ]中的内容是可选的。语…...

【JavaWeb】4—Tomcat
⭐⭐⭐⭐⭐⭐ Github主页👉https://github.com/A-BigTree 笔记链接👉https://github.com/A-BigTree/Code_Learning ⭐⭐⭐⭐⭐⭐ 如果可以,麻烦各位看官顺手点个star~😊 如果文章对你有所帮助,可以点赞👍…...
宝塔Linux面板部署Python flask项目
目录 👉1、前言 👉2、安装python项目管理器 👉3、上传项目文件及文件夹 👉4、配置项目 👉5、请求测试 学习记录: 👉1、前言 写在前面:前几天我们实现了外网内外登录正方教务系…...

spring中产生bean的几种方式
BeanImportMyImportSelector implements ImportSelectorMyImportBeanDefinitionRegistarimplements ImportBeanDefinitionRegistrarFactoryBean这里着重讲解FactoryBean如何判断当前bean是否是FactoryBeanorg.springframework.beans.factory.support.AbstractBeanFactory#isFac…...

OD-火星文计算(Python)
火星文计算 题目描述 已经火星人使用的运算符号为# $ 其与地球人的等价公式如下x#y2*x3*y4x$y3*xy2x y是无符号整数 地球人公式按照c语言规则进行计算 火星人公式中$符优先级高于#相同的运算符按从左到右的顺序运算 输入描述 火星人字符串表达式结尾不带回车换行 输入的字符…...

【vue3教程】初入了解vue3的基本结构
前言 Animatrix:黑客帝国 Blade Runner:银翼杀手 Cowboy Bebop:星际牛仔 Dragon Ball:龙珠 Evangelion:新世纪福音战士 Ghostin the Shell:攻壳机动队 Hunter X Hunter:全职猎人 Initial D&…...

智慧供水综合运营平台解决方案
一、概述 建设背景: 供水系统是城市生存、发展的基础,供水事业的发展与城市的社会经济发展息息相关,其服务质量的好坏不仅关系到供水企业自身的利益,也直接影响到社会的稳定和政府形象。住房城乡建设部于2012年12月5日正式发布了《…...
文件系统、描述符和缓冲区
目录 🏆一、文件系统 1、open ①对open接口的介绍 ②接口使用 2、write接口 3、read接口 🏆二、深入理解文件描述符fd 1、fd具体实质 2、文件fd的分配规则 3、fd重定向 ①输出重定向 ②追加重定向 ③输入重定向 ④文件的引用计数 🏆三…...
java微服务商城高并发秒杀项目--009.流控规则和降级规则
线程流控(只要线程数达到了指定数量,访问就会被流控):warm up流控效果(慢慢增加QPS的数量,之后最后达到阈值,这种情况下,一开始会容易限流,后期就不会限流了)…...

php编写的脚本,如何才能在windows系统运行呢?
咱们要在Windows系统上运行PHP脚本,需要安装PHP解释器和Web服务器。 以下是基本的步骤,很简单: 下载PHP解释器:可以从官方网站 https://windows.php.net/download/ 下载Windows版本的PHP解释器。根据你的操作系统和需要的版本选…...
政务综合服务平台建设项目方案书
本资料来源公开网络,仅供个人学习,请勿商用,如有侵权请联系删除 目 录 第一章 项目整体概述 1.1. 项目名称 1.2. 建设单位 1.3. 编写依据 1.3.1 相关政策 1.3.2 技术标准 1.4. 建设目标、规模、内容、建设期 1.4.1 建设目标 1.4.2 …...

python好玩的短代码
Python语言是一种流行的编程语言,在 Python语言中有很多有趣的特性,比如: 1.变量可以定义为字符串,也可以定义为字符串对象 2.变量可以用来初始化一个函数或模块,函数或者模块可以定义成一个类,这个类被称为…...

会Python如何学习C#的几个关键点
Python和C#都是常用的编程语言,但两者之间存在一些重要的区别。如果你已经掌握了Python并希望学习C#,以下是几个关键点: 面向对象编程(OOP):C#是一种严格的面向对象编程语言,而Python则具有更灵…...

索引失效原则与查询优化
数据库调优的维度: 索引建立SQL优化(本文重点)my.cnf的调整(线程数,缓存等)分库分表 SQL查询优化的技术从大方向上可以分为 物理查询优化,逻辑查询优化 物理查询优化:即通过建立索…...

读完这篇文章你就彻底了解了什么是AES算法
目录 导论 介绍加密算法的定义和基本概念 解释加密算法在现代通信和存储系统中的重要性...

ArrayDeque类常用方法
数据结构 ArrayDeque类是 双端队列的线性实现类。 具有以下特征: ArrayDeque是采用数组方式实现的双端队列。ArrayDeque的出队入队是通过头尾指针循环,利用数组实现的。ArrayDeque容量不足时是会扩容的,每次扩容容量增加一倍。ArrayDeque可…...
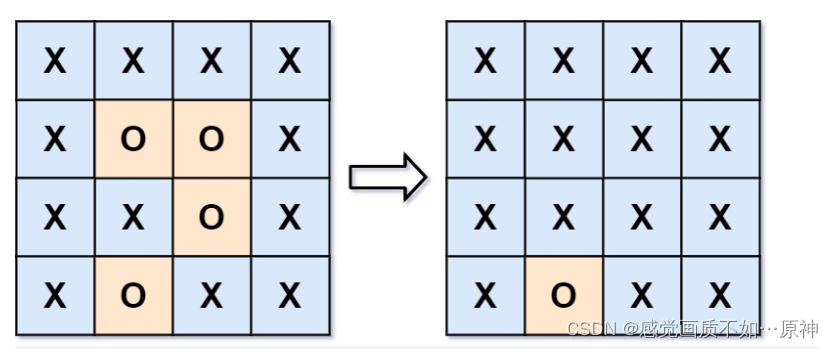
Leetcode.130 被围绕的区域
题目链接 Leetcode.130 被围绕的区域 mid 题目描述 给你一个 m x n的矩阵 board,由若干字符 X和 O,找到所有被 X围绕的区域,并将这些区域里所有的 O用 X填充。 示例 1: 输入:board [[“X”,“X”,“X”,“X”],[“X…...

MySQL-四大类日志
目录 🍁MySQL日志分为4大类 🍁错误日志 🍃修改系统配置 🍁二进制日志 🍃查看二进制日志 🍃删除二进制日志 🍃暂时停止二进制日志的功能 🍁事务日志(或称redo日志) 🍁慢查…...

新加坡量子软件公司Horizon完成1810万美元A轮融资
(图片来源:网络) 近期,Horizon宣布已完成来自印度红杉资本、腾讯、SGInnovate、Pappas Capital和Expeditions Fund的1810万美元A轮投资。 Horizon是一家开发新一代编程工具的公司,总部位于新加坡,它致力…...

Linux应用层直接操作硬件寄存器:原理、实现与安全实践
1. 项目概述:为什么要在应用层操作寄存器? 在嵌入式Linux开发或者驱动调试的日常工作中,我们常常会遇到一个看似“越界”的需求:在用户空间的应用层程序里,直接去读写某个硬件寄存器的值。这听起来有点“离经叛道”&am…...

对话式AI应用开发实战:基于Bolna框架的语音助手构建与优化指南
1. 项目概述:Bolna,一个面向对话式AI应用的开源编排框架如果你正在构建一个需要处理语音或文本对话的AI应用,比如一个智能客服、一个语音助手,或者一个能通过电话自动处理预约的机器人,你可能会立刻想到几个核心挑战&a…...

5分钟掌握全平台炫酷抽奖:Magpie-LuckyDraw开源项目深度解析
5分钟掌握全平台炫酷抽奖:Magpie-LuckyDraw开源项目深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https://gitcode.com/gh_mirrors/ma…...

为OpenClaw配置Taotoken作为其AI模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw配置Taotoken作为其AI模型供应商 基础教程类,指导使用OpenClaw这类Agent工具的开发者,如何将其后…...

基于LLM的智能网页自动化:从意图理解到工程实践
1. 项目概述:当AI学会“看”和“点”,自动化进入新阶段如果你还在为那些需要手动点击、填写表单、抓取数据的重复性网页任务感到头疼,那么browser-use这个项目可能会让你眼前一亮。简单来说,它不是一个普通的浏览器自动化工具&…...

Ansys Mechanical|远程点Behavior设置:刚性与柔性选择背后的工程考量
1. 远程点Behavior设置的核心逻辑 在Ansys Mechanical中,远程点(Remote Point)的Behavior设置看似只是一个简单的下拉选项,实则直接影响整个仿真结果的准确性。我见过太多工程师在这里踩坑,包括我自己早期也犯过错误。…...

WinRing0深度解析:Windows硬件访问的终极解决方案
WinRing0深度解析:Windows硬件访问的终极解决方案 【免费下载链接】WinRing0 WinRing0 is a hardware access library for Windows. 项目地址: https://gitcode.com/gh_mirrors/wi/WinRing0 WinRing0是一个功能强大的Windows硬件访问库,为开发者提…...

Cursor AI插件开发:从代码补全到智能动作执行的范式演进
1. 项目概述:当AI代码助手遇上插件生态最近在GitHub上看到一个挺有意思的项目,叫RightbrainAI/cursor-plugin。光看名字,可能很多用惯了Cursor的朋友会眼前一亮,以为这是Cursor编辑器官方或者某个社区大神出的插件。但点进去仔细一…...

SSD1306 OLED屏幕驱动全攻略:从Arduino到CircuitPython实战
1. 项目概述如果你玩过Arduino、ESP32或者树莓派Pico这类微控制器,肯定遇到过一个问题:怎么把程序运行的状态、传感器的数据或者一些简单的交互界面直观地展示出来?用串口监视器看数据流当然可以,但不够“酷”,也不够便…...

基于大语言模型构建智能思考伙伴:从原理到本地部署实践
1. 项目概述:一个“思考伙伴”的诞生最近在GitHub上看到一个挺有意思的项目,叫“thinking-partner”。光看这个名字,你可能会联想到一个聊天机器人,或者一个简单的问答工具。但当我深入去研究这个由 mortiebiennial49 开源的仓库时…...