关于Dataset和DataLoader的概念
关于Dataset和DataLoader的概念
在机器学习中,Dataset和DataLoader是两个很重要的概念,它们通常用于训练和测试模型时的数据处理。
Dataset是指用于存储和管理数据的类。在深度学习中,通常将数据存储在Dataset中,并使用Dataset提供的方法读取和处理数据。Dataset可以是各种类型的数据,例如图像、文本、音频、视频等。在PyTorch中,torch.utils.data.Dataset是一个抽象类,可以用于创建自定义的Dataset类。在自定义Dataset类中,我们需要实现__len__方法和__getitem__方法,用于返回数据集的大小和每个数据样本。例如,我们可以创建一个图像分类的Dataset类,其中每个数据样本是一张图像及其对应的标签。
DataLoader是指用于从Dataset中读取数据的类。在深度学习中,通常将Dataset传递给DataLoader,然后使用DataLoader提供的方法对数据进行批量读取和处理。DataLoader可以实现多线程读取数据、数据打乱、数据增强等功能。在PyTorch中,torch.utils.data.DataLoader是一个类,可以用于创建DataLoader对象。在创建DataLoader对象时,我们可以指定批量大小、是否打乱数据、是否使用多线程读取数据等参数。例如,我们可以创建一个DataLoader对象,用于从图像分类的Dataset中读取数据,并每次读取32个数据样本。
通过使用Dataset和DataLoader,我们可以方便地读取和处理数据,并将其传递给模型进行训练和测试。这种数据处理方式可以大大简化代码,提高代码的可读性和可维护性
如何创建自定义的Dataset类?
在PyTorch中,我们可以通过创建自定义的Dataset类来处理自己的数据。下面是一个示例,说明如何创建自定义的Dataset类:
import torch
from torch.utils.data import Datasetclass MyDataset(Dataset):def __init__(self, data, labels):self.data = dataself.labels = labelsdef __len__(self):return len(self.labels)def __getitem__(self, index):x = self.data[index]y = self.labels[index]return x, y
在上述代码中,我们创建了一个名为MyDataset的自定义Dataset类。该类接受两个参数:data和labels,分别表示数据和标签。在类的初始化方法__init__中,我们将传入的数据和标签存储为类的成员变量,以便在后续的方法中使用。
该类实现了__len__方法和__getitem__方法,用于返回数据集的大小和每个数据样本。__len__方法返回数据集的大小,即数据的数量。__getitem__方法接受一个索引index作为参数,并返回该索引对应的数据样本。在该方法中,我们首先获取数据和标签的索引,然后将它们打包成一个元组返回。在实际使用时,我们可以通过调用该类的实例对象的__getitem__方法,以便获取数据集中的数据。
例如,我们可以使用以下代码创建MyDataset的实例对象,然后通过调用该实例对象的__getitem__方法来获取数据集中的数据:
data = torch.randn(100, 3, 32, 32)
labels = torch.randint(0, 10, (100,))
dataset = MyDataset(data, labels)
x, y = dataset[0]
print(x.shape, y)
在上述代码中,我们首先创建了一个随机的数据张量data和标签张量labels,然后使用它们创建了一个MyDataset的实例对象dataset。最后,我们通过调用dataset的__getitem__方法来获取数据集中的第一个数据样本,并输出该数据样本的形状和标签。
通过创建自定义的Dataset类,我们可以方便地处理各种类型的数据,并将其传递给DataLoader对象进行批量读取和处理。
如何使用 DataLoader 从我的自定义数据集中加载数据?
在PyTorch中,我们可以使用DataLoader从自定义的数据集中加载数据。下面是一个示例,说明如何使用DataLoader从自定义的数据集中加载数据:
import torch
from torch.utils.data import DataLoader# 假设我们创建了一个名为MyDataset的自定义数据集
dataset = MyDataset(data, labels)# 创建一个批量大小为32且打乱数据的DataLoader对象
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)# 使用for循环遍历DataLoader对象,以批量的形式加载数据
for batch in dataloader:# batch是一个元组,包含一批数据和标签x, y = batch# 对一批数据和标签进行操作...
在上述代码中,我们首先创建了一个自定义的数据集MyDataset,并将数据和标签作为参数传递进去。然后,我们使用DataLoader创建了一个批量大小为32且打乱数据的DataLoader对象。在使用for循环遍历DataLoader对象时,每个batch返回一个元组,其中包含一批数据和标签。我们可以对每个batch进行操作,例如将其传递给模型进行训练或评估。
需要注意的是,批量大小应该根据可用内存和数据大小进行选择。较大的批量大小可以加速训练,但可能需要更多的内存。打乱数据的参数应该在训练数据中设置为True,在验证和测试数据中设置为False。
my_dataset.py
# import random
# list1 = [1,2,3,4,5,6,7] # 所有的数据 , dataset
#
#
# batch_size = 2 #
# epoch = 2 # 轮次
# shuffle = True
#
# for e in range(epoch):
# if shuffle:
# random.shuffle(list1)
# for i in range(0,len(list1),batch_size): # 数据加载的过程, dataloader
# batch_data = list1[i:i+batch_size]
# print(batch_data)import random
class MyDataset:def __init__(self,all_datas,batch_size,shuffle=True):self.all_datas = all_datasself.batch_size = batch_sizeself.shuffle = shuffleself.cursor = 0# python魔术方法:某种场景自动触发的方法#def __iter__(self): # 返回一个具有__next__的对象if self.shuffle:random.shuffle(self.all_datas)self.cursor = 0return selfdef __next__(self):if self.cursor >= len(self.all_datas):raise StopIterationbatch_data = self.all_datas[self.cursor:self.cursor+self.batch_size]self.cursor += self.batch_sizereturn batch_dataif __name__ == "__main__":all_datas = [1,2,3,4,5,6,7]batch_size = 2shuffle = Trueepoch = 2dataset = MyDataset(all_datas,batch_size,shuffle)for e in range(epoch):for batch_data in dataset: # 把一个对象放在for上时, 会自动调用这个对象的__iter__,print(batch_data)
[3, 1]
[5, 7]
[6, 4]
[2]
[5, 3]
[2, 7]
[4, 1]
[6]
my_dataset_dataloader.py
import random
import numpy as np
class MyDataset:def __init__(self,all_datas,batch_size,shuffle=True):self.all_datas = all_datasself.batch_size = batch_sizeself.shuffle = shuffle# python魔术方法:某种场景自动触发的方法#def __iter__(self): # 返回一个具有__next__的对象# if self.shuffle:# random.shuffle(self.all_datas)# self.cursor = 0# return selfreturn DataLoader(self)def __len__(self):return len(self.all_datas)# def __next__(self):# if self.cursor >= len(self.all_datas):# raise StopIteration## batch_data = self.all_datas[self.cursor:self.cursor+self.batch_size]# self.cursor += self.batch_size# return batch_dataclass DataLoader:def __init__(self,dataset):self.dataset = datasetself.indexs = [i for i in range(len(self.dataset))]if self.dataset.shuffle == True:np.random.shuffle(self.indexs)self.cursor = 0def __next__(self):if self.cursor >= len(self.dataset.all_datas):raise StopIterationindex = self.indexs[self.cursor:self.cursor + self.dataset.batch_size]batch_data = self.dataset.all_datas[index]self.cursor += self.dataset.batch_sizereturn batch_dataif __name__ == "__main__":all_datas = np.array([1,2,3,4,5,6,7])batch_size = 2shuffle = Trueepoch = 2dataset = MyDataset(all_datas,batch_size,shuffle)for e in range(epoch):for batch_data in dataset: # 把一个对象放在for上时, 会自动调用这个对象的__iter__,print(batch_data)
[7 1]
[5 2]
[4 3]
[6]
[3 1]
[2 5]
[6 7]
[4]
相关文章:

关于Dataset和DataLoader的概念
关于Dataset和DataLoader的概念 在机器学习中,Dataset和DataLoader是两个很重要的概念,它们通常用于训练和测试模型时的数据处理。 Dataset是指用于存储和管理数据的类。在深度学习中,通常将数据存储在Dataset中,并使用Dataset提…...

前端与JS变量
前端开发是当今互联网发展的重要组成部分,而JavaScript变量则是前端开发中不可或缺的一部分。在前端开发中,变量的作用不仅仅是存储数据,还可以用来控制程序流程、实现动态效果等。因此,学习前端与JavaScript变量是非常必要的。 …...
初始SpringBoot
初始SpringBoot1. SpringBoot创建和运行1.1. SpringBoot的概念1.2. SpringBoot的优点1.3. SpringBoot的创建1.3.0. 前置工作:安装插件(这是社区版需要做的工作, 专业版可以忽略)1.3.1. 社区版创建方式1.3.2. 专业版创建方式1.3.3. 网页版创建方式1.4. 项目目录介绍1.5. SpringB…...
vue+springboot 上传文件、图片、视频,回显到前端。
效果图 预览: 视频: 设计逻辑 数据库表 前端vue html <div class"right-pannel"><div class"data-box"><!--上传的作业--><div style"display: block" id""><div class"tit…...
)
java入门-W3(K81-K143)
一. 什么是对象 什么是对象?之前我们讲过,对象就是计算机中的虚拟物体。例如 System.out,System.in 等等。然而,要开发自己的应用程序,只有这些现成的对象还远远不够。需要我们自己来创建新的对象。 例如,…...

English Learning - L2 语音作业打卡 复习元音 [ɜː] [æ] 辅元连读技巧 Day42 2023.4.3 周一
English Learning - L2 语音作业打卡 复习元音 [ɜː] [] 辅元连读技巧 Day42 2023.4.3 周一💌发音小贴士:💌当日目标音发音规则/技巧:中元音 [ɜː]前元音 []辅元连读技巧🍭 Part 1【热身练习】🍭 Part2【练习内容】&…...

Thinkphp 6.0图像处理功能
本节课我们来学习一下图像处理功能,这功能是外置的,并非系统内置。 一.图像处理功能 1. 图像处理功能不是系统内置的功能了,需要通过 composer 引入进来; composer require topthink/think-image 2. 引入进来之后&…...

表格软件界的卷王,Excel、access、foxpro全靠边,WPS:真荣幸
Excel和Access就是表格软件的选择? 现在,铺天盖地的Excel的技能教程可谓是满天飞,有网上的教程,也有视频直播课程。 很多办公人员用Excel这种表格软件与VBA结合,甚至用不遗余力去学习Python编程语法,但Exce…...
Node.js -- http模块
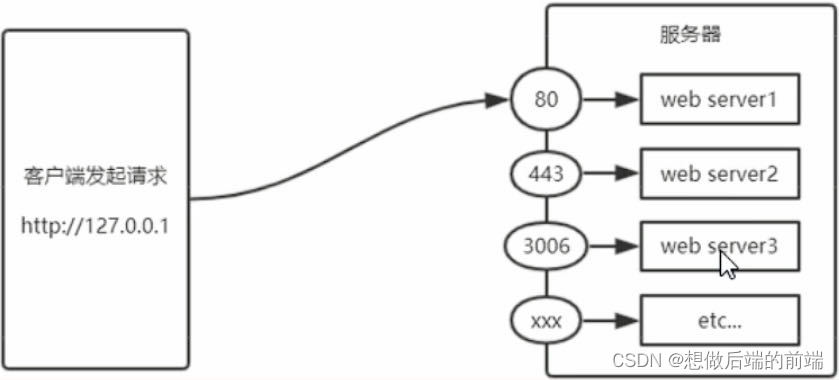
1. 什么是http模块 在网络节点中,负责消费资源的电脑,叫客户端;负责对外提供网络资源的电脑,叫做服务器。 http模块是Node.js官方提供的,用来创建web服务器的模块。通过http模块提供的http.createServer()方法&#…...
静态库与动态库
库是已经写好的、成熟的、可复用的代码。在我们的开发的应用中经常有一些公共代码是需要反复使用的,就把这些代码编译为库文件。库可以简单看成一组目标文件的集合,将这些目标文件经过压缩打包之后形成的一个可执行代码的二进制文件。库有两种࿱…...

问题 A: C语言11.1
题目描述: 完成一个对候选人得票的统计程序。假设有3个候选人,名字分别为Li,Zhang和Fun。使用结构体存储每一个候选人的名字和得票数。记录每一张选票的得票人名,输出每个候选人最终的得票数。结构体可以定义成如下的格式&#x…...
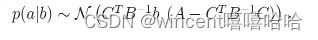
SLAM中后端优化的技术细节总结与回答
SLAM中后端优化的技术细节 本文档主要收集总结了一些SLAM大佬们讲解后端优化中偏理论的技术细节的博客和回答以及一些学习教材。 Written by wincent 位姿估计以及李群相关的概述 Lie theory is by no means simple ———— 谎言理论绝不简单doge 《A micro Lie theory for st…...
小白快速学习Markdown
这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注…...

ToBeWritten之物联网WI-FI协议
也许每个人出生的时候都以为这世界都是为他一个人而存在的,当他发现自己错的时候,他便开始长大 少走了弯路,也就错过了风景,无论如何,感谢经历 转移发布平台通知:将不再在CSDN博客发布新文章,敬…...

C++模板元编程深度解析:探索编译时计算的神奇之旅
C模板元编程深度解析:探索编译时计算的神奇之旅引言C模板元编程的概念与作用模板元编程在现代C编程中的应用模板元编程基础类型萃取(Type Traits)编译时条件(静态if)模板元编程中的递归与终止条件模板元编程技巧与工具…...

姿态变换及坐标变换
目录0. 空见间变换&基变换0.0 空间变换0.1 基变换1.缩放、旋转、平移机器人齐次变换坐标系变换0. 空见间变换&基变换 这是矩阵分析的相关知识,有兴趣的参考第一篇知乎文章[1]. 0.0 空间变换 空间变换是指在同一组绝对基下的变换,可以想象为世…...

从命令行管理文件
目录标题文件命名规则创建、删除普通文件创建普通文件格式创建多个普通文件删除普通文件目录操作命令创建目录--mkdir命令统计目录及文件的空间占用情况--du命令删除目录文件复制、移动文件复制(copy)文件或目录--cp命令移动(mv)文…...
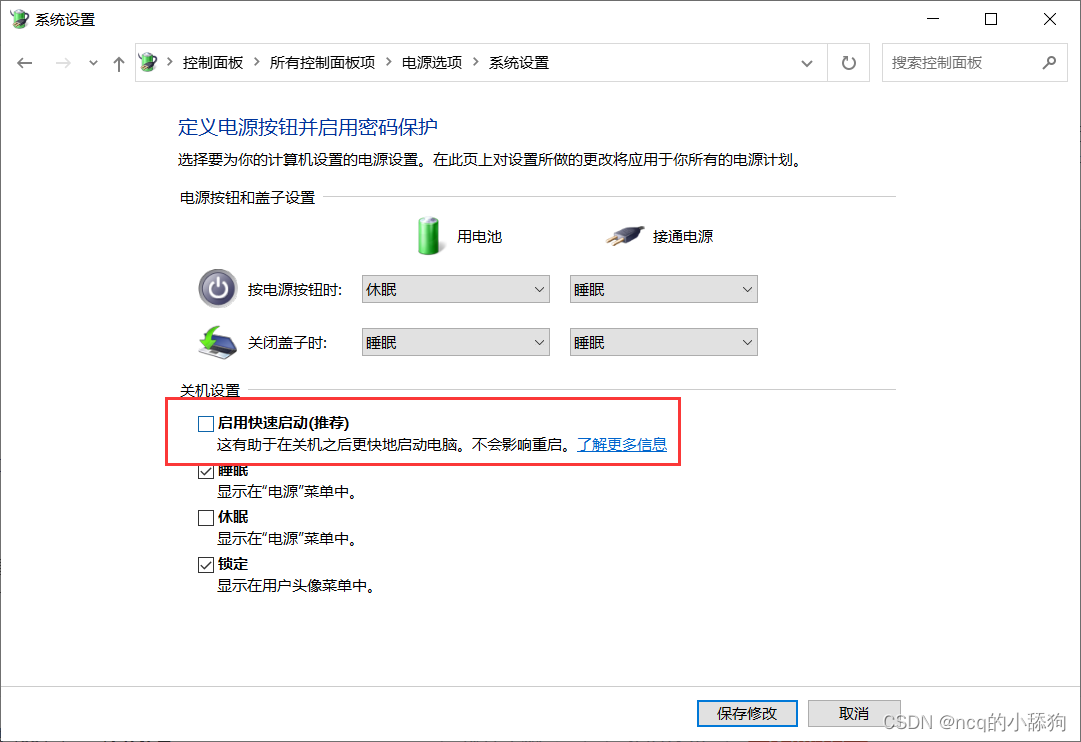
电脑无法正常关机?点了关机又会自动重启
“真木马”相信不少朋友遇到过电脑关机自动重启现象,一点关机,但随后电脑有会进入重启状态,就是一直不会停,属实是很难崩。 目录 一、问题症状 二、问题原因 三、解决方案 方法一: 1.关闭系统发生错误时电脑自动…...

English Learning - L2 语音作业打卡 复习双元音 [eɪ] [aɪ] r 谦让型爆破技巧 Day46 2023.4.7 周五
English Learning - L2 语音作业打卡 复习双元音 [eɪ] [aɪ] r 谦让型爆破技巧 Day46 2023.4.7 周五💌发音小贴士:💌当日目标音发音规则/技巧:[eɪ][aɪ]谦让型爆破🍭 Part 1【热身练习】🍭 Part2【练习内容】&#x…...

webgl-画任意多边形
注意: let canvas document.getElementById(webgl) canvas.width window.innerWidth canvas.height window.innerHeight let radio window.innerWidth/window.innerHeight; let ctx canvas.getContext(webgl) 由于屏幕长宽像素不一样,导致了长宽像素…...

终极指南:如何使用AppleRa1n工具安全绕过iOS 15-16激活锁
终极指南:如何使用AppleRa1n工具安全绕过iOS 15-16激活锁 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n iOS激活锁绕过是许多iPhone用户在设备所有权验证遇到困难时的迫切需求。AppleRa1n…...

编写程序统计职场上下级沟通频率,工作执行效果数据,搭建高效沟通模式,减少指令传达偏差工作失误。
构建一个职场上下级沟通频率与工作执行效果分析的商务智能示例项目,去营销化、中立化,仅用于学习与工程实践参考。一、实际应用场景描述在任何组织中,上下级沟通质量直接决定执行效率:- 上级布置任务 → 下级理解并执行 → 反馈结…...

通过curl命令快速测试Taotoken的API兼容性与连通性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken的API兼容性与连通性 在接入大模型服务时,开发者常常需要一个快速、轻量的方法来验证API…...

【NotebookLM企业级权限治理白皮书】:为什么87%的AI协作项目在上线30天内遭遇越权访问?
更多请点击: https://intelliparadigm.com 第一章:NotebookLM企业级权限治理的底层逻辑 NotebookLM 的企业级权限治理并非简单叠加 RBAC(基于角色的访问控制),而是构建在「数据主权可追溯、策略执行零信任、上下文感知…...

CNN在卷什么:五大组件详解,一文讲透卷积神经网络,从LeNet到ResNet,为什么这5个组件是CNN的标配
CNN在卷什么:五大组件详解,一文讲透卷积神经网络 副标题: 从LeNet到ResNet,为什么这5个组件是CNN的标配 痛点:CNN的五大组件是什么? 学CNN的时候,你是不是分不清这些概念? 卷积层 vs 池化层:都是"滑动",有什么区别? BatchNorm 到底在做什么?为什么需要它…...
)
【2026最新】应对维普算法升级,5大降AI工具横测,一次稳降至25%(附手改秘籍)
知网和维普的AIGC检测系统又更新了! 在当下的关口,如何在不牺牲质量的前提下,优化初稿表达,安全地降低AI痕迹,成了所有小伙伴们必须解决的一个问题。网络上各种“降AI神器”铺天盖地,这些工具到底靠不靠谱…...

openpilot自动驾驶系统深度解析:架构剖析与实战指南
openpilot自动驾驶系统深度解析:架构剖析与实战指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Trending/…...

技术解构:逆向工程视角下的百度网盘下载链接解析机制
技术解构:逆向工程视角下的百度网盘下载链接解析机制 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 想象一下,当你收到朋友分享的百度网盘链接时&…...

碳排放混合时间窗集装箱运输调度【附算法】
✨ 长期致力于集装箱运输VRP、混合时间窗、碳排放、多目标优化、NSGA-Ⅱ、蚁群算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)经济性与紧急性双目…...

Arm Neoverse CMN-700多芯片架构与一致性哈希解析
1. Arm Neoverse CMN-700多芯片架构解析在现代高性能计算领域,多芯片系统架构已成为突破单芯片性能瓶颈的关键技术路径。Arm Neoverse CMN-700作为第二代一致性网状网络控制器,其设计哲学体现在三个维度:首先是通过模块化设计实现计算单元的可…...