2022MathorCup赛题B
以下所有文字均基于作者的实际经验,并不具有完全的合理性,请谨慎参考
目录
一、问题分析
(一)问题一
(二)问题二
二、预处理
(一)训练集预处理
(二)测试集预处理
三、相关性分析
(一)线性相关性
(二)非线性相关性
四、结果预测
五、材料源码
一、问题分析
首先要明白要解决一个什么问题,在原本的文档中,有六个数据集,分别是附件一语音业务满意度、附件二上网业务满意度、附件三语音业务满意度预测、附件四上网业务满意度预测、附件五字段说明、result预测集。
对于语音业务来说,里面有语音通话整体满意度、网络覆盖与信号强度、语音通话清晰度、语音通话稳定性四个标签属性,且这四个属性的取值都是0-10的离散取值。这就说明,这可能是一个典型的十分类问题,且需要对这四个属性分别建立分类器,也就是单单一个语音业务就是四个十分类。
同样,对于上网业务来说,里面有手机上网整体满意度、网络覆盖与信号强度、手机上网速度、手机上网稳定性四个标签属性,且这四个属性的取值都是0-10的离散取值。同样,这可能是典型的四个十分类。
以上为我们观察数据结构的基本判断,然后我们再关注文档中的要求。
(一)问题一
问题一需要我们找到语音业务和上网业务中对这八个评分影响最大的因素,那其实就是相关性的分析,也就是找到两种业务中剩余属性中对上面提到的八个标签属性影响最大的属性,因为显而易见,出题方希望找到影响他们业务最大的相关因素,从而对该服务进行重点关注。(本质是相关性分析,可能可以使用关联规则挖掘的相关工具)
(二)问题二
问题二需要我们根据自己建立的模型和预测集得出预测结果,然后填入result表格,那就根据建模情况进行预测即可。
二、预处理
结果的预测好坏跟数据的前期处理非常相关
首先需要关注训练集和预测集属性的异同,从中分析实际有用的属性。结合到本赛题的实际情况,需要关注附件五字段说明中对各属性的描述。
这里发现训练集中存在预测集中没有的属性,这种情况基本很少发生,但是本赛题出现,就可以直接删除。这里比如语音业务中的“重定向次数”,这个属性在预测集中并没有存在。
第二种发现预测集中存在训练集中没有的属性,这种情况基本也不会发生,所以建议仔细比对各属性的实际含义,然后考虑对训练集的属性进行删除或者合并或者其它操作。比如语音业务中,训练集中存在“家宽投诉”和“资费投诉”两个属性,但是预测集中是“是否投诉”属性,那么可以把家宽投诉和资费投诉合并为是否投诉,这里就需要对每个样本的两个属性取并集。
(一)训练集预处理
1、删除预测集中不存在的属性
2、删除无关属性。例如本题中的用户id
3、按照题目要求填充空缺值。这里是按照附件五字段说明填充空缺值,比如语音业务中的“是否关怀用户”
4、空缺值、异常值填充。某些属性下样本的值与其它样本与众不同,比如其它都是float类型,然后异常显示为string类型,这种一般用值填充。
连续值的话一般用均值填充,离散值的话可以用众值或“其它”填充,前提是有“其他”这个值,很多时候,离散值都是string类型(可能表格有“其他选项”,生活中调研问卷也会给出这样的选项)。或者可以选择直接把该样本删除,这样做的好处是可以提高拟合度,但是相反就丢失了一些可能重要的信息。(意思就是取舍,看你是愿意为了提高拟合度舍弃部分信息,还是为了模型考虑更加周全而降低你的准确率)
这里建议单独查看这些异常值样本的情况,如果数量相对于整体样本特别少,或者此样本还存在其他属性上的问题(比如好几个属性值异常,好几个属性值缺失),都建议删除。
5、列索引重整化。为了后面属性编码方便,建议进行这个操作,这个操作可以重新把属性的索引下标进行排列。
6、离散属性编码。某些属性可能是string类型,不利于模型训练,这里可以使用一些编码方式,比如one-hot编码、映射编码等多种编码方式。
7、归一化、标准化。这一步的操作就是让特征向量变得更加趋近中心化,更呈现出某种分布,某些模型空间性要求比较高,这一步就非却不可,比如SVM。但是对于一些通过离散方式训练的模型就显得比较多余,甚至会因此影响模型,比如决策树,但是Cart树和C4.5克服了连续属性的影响,这里需要仔细斟酌。
注意:数据属性取值要么是连续的,要么是离散的,某些模型需要连续属性,某些模型需要离散属性,但连续属性能适应大部分模型,所以不存在连续属性或离散属性的好坏,对属性进行连续或离散的变换能够更好拟合模型,但同时也会让属性失去一些信息,所以需要抉择和判断。数据连续化比较容易处理,数据离散化通常需要用到分箱方法,而且很需要能力和经验,如何进行分箱也是一门学问。
(二)测试集预处理
基本操作同训练集预处理相同,可能由于某些属性不同需要进行个别调整。
以下为语音业务训练集的预处理部分代码
# coding=utf-8
import os
import numpy as np
from sklearn.preprocessing import StandardScaler
import pandas as pd
# 填充空缺值
def my_fill(data):# print(data.isnull().sum()) #查看空值# 测试集中没有相关属性data.drop(['重定向次数', '重定向驻留时长','语音方式','是否去过营业厅','ARPU(家庭宽带)','是否实名登记用户'],axis=1,inplace=True)# 删除无关属性data.drop(['用户描述', '用户id', '用户描述.1'], axis=1,inplace=True)# 按照表格要求填充空缺值data['是否关怀用户'].fillna('否',inplace=True)# 该属性下的样本缺失值较多,且样本量较少直接删除(其它属性也缺失)drop1 = data[data["是否4G网络客户(本地剔除物联网)"].isnull()].index.tolist()data.drop(labels=drop1,axis=0,inplace=True)# 该属性下的样本格式错误,无法读取,导致变为0,由于是连续值,用均值代替drop2 = data[data["外省流量占比"].isnull()].index.tolist()temp_data = data.drop(labels=drop2,axis=0,inplace=False)fill = temp_data["外省流量占比"].unique()data["外省流量占比"].fillna(np.mean(fill),inplace=True)# 替换异常值0变为其他,这些特征其他属性没问题,在这里全是string类型的值里是0,可能是异常data['终端品牌'].replace(0, '其他', inplace=True)# 将两个投诉变为合并为一个投诉cnt1 = data['家宽投诉']+data['资费投诉']data['家宽投诉'] = cnt1data.drop(['资费投诉'],axis=1,inplace=True)data.rename(columns={'家宽投诉':'是否投诉'},inplace=True)data['是否投诉'] = data['是否投诉'].apply(lambda x: '否' if x == 0 else '是')# 将两个欠费变为合并为一个欠费cnt2 = data['当月欠费金额'] + data['前第3个月欠费金额']data['当月欠费金额'] = cnt2data.drop(['前第3个月欠费金额'], axis=1, inplace=True)data.rename(columns={'当月欠费金额': '是否不限量套餐到达用户'}, inplace=True)data['是否不限量套餐到达用户'] = data['是否不限量套餐到达用户'].apply(lambda x: '否' if x == 0 else '是')#重整行索引,为后面编码提供方便data.reset_index(drop=True,inplace=True)return data# 属性编码
def my_encode(data):# 映射(层次)编码,对字符串属性进行特征编码code4 = {'2G':0,'4G':1,'5G':2}data['4\\5G用户'] = data['4\\5G用户'].map(code4)# 映射编码code6 = {'否':0,'是':1}data['是否关怀用户'] = data['是否关怀用户'].map(code6)data['是否4G网络客户(本地剔除物联网)'] = data['是否4G网络客户(本地剔除物联网)'].map(code6)data['是否5G网络客户'] = data['是否5G网络客户'].map(code6)data['是否投诉'] = data['是否投诉'].map(code6)data['是否不限量套餐到达用户'] = data['是否不限量套餐到达用户'].map(code6)# 映射编码val = data['终端品牌'].unique()labels = [i for i in range(0,len(val))]code14 = dict(zip(val,labels))data['终端品牌'] = data['终端品牌'].map(code14)#映射编码val = data['终端品牌类型'].unique()labels = [i for i in range(0, len(val))]code15 = dict(zip(val, labels))data['终端品牌类型'] = data['终端品牌类型'].map(code15)# 映射编码val = data['客户星级标识'].unique()labels = [i for i in range(0, len(val))]code18 = dict(zip(val, labels))data['客户星级标识'] = data['客户星级标识'].map(code18)return data
def scalelize(data):scal = StandardScaler()new_data = scal.fit_transform(data)return new_datadata = pd.read_excel('../附件1语音业务用户满意度数据.xlsx')
data_fill = my_fill(data) #填充后的数据
data_encode = my_encode(data_fill) #编码后的数据y1 = data_encode['语音通话整体满意度'] #总标签1
y2 = data_encode['网络覆盖与信号强度'] #标签2
y3 = data_encode['语音通话清晰度'] #标签3
y4 = data_encode['语音通话稳定性'] #标签4
y_all = pd.concat([y1,y2],axis=1)
y_all = pd.concat([y_all,y3],axis=1)
y_all = pd.concat([y_all,y4],axis=1)# 去除标签的特征
x_dataframe = data_encode.drop(['语音通话整体满意度', '网络覆盖与信号强度','语音通话清晰度','语音通话稳定性'], axis=1)
x = pd.DataFrame(scalelize(x_dataframe))
x.columns = ['是否遇到过网络问题', '居民小区', '办公室', '高校', '商业街', '地铁', '农村', '高铁', '其他,请注明', '手机没有信号', '有信号无法拨通', '通话过程中突然中断', '通话中有杂音、听不清、断断续续', '串线', '通话过程中一方听不见', '其他,请注明.1', '脱网次数', 'mos质差次数', '未接通掉话次数', '是否投诉', '4\\5G用户', '是否关怀用户', '套外流量(MB)', '是否4G网络客户(本地剔除物联网)', '套外流量费(元)', '外省语音占比', '语音通话-时长(分钟)', '省际漫游-时长(分钟)', '终端品牌', '终端品牌类型', '当月ARPU', '当月MOU', '前3月ARPU', '前3月MOU', '外省流量占比', 'GPRS总流量(KB)', 'GPRS-国内漫游-流量(KB)', '是否5G网络客户', '客户星级标识', '是否不限量套餐到达用户']# 导出
writer = pd.ExcelWriter("./1_train.xlsx")
x.to_excel(writer,index=False)
writer.save()writer1 = pd.ExcelWriter("./1_train_label.xlsx")
y_all.to_excel(writer1,index=False)
writer1.save()三、相关性分析
相关性分析可以理解为找多个属性之间的相似度,一些书本上记录了许多相关系数可以进行参考,这里仅给出部分
(一)线性相关性
最典型的就是皮尔逊相关系数,也就是通过协方差的方式得出每个属性之间的相关度,然后可以用协方差矩阵和热力图直观看出属性之间的相关影响。例如下图

(二)非线性相关性
这里最典型的就是信息增益,通过决策树模型得出每个属性对标签属性的信息增益。例如下图
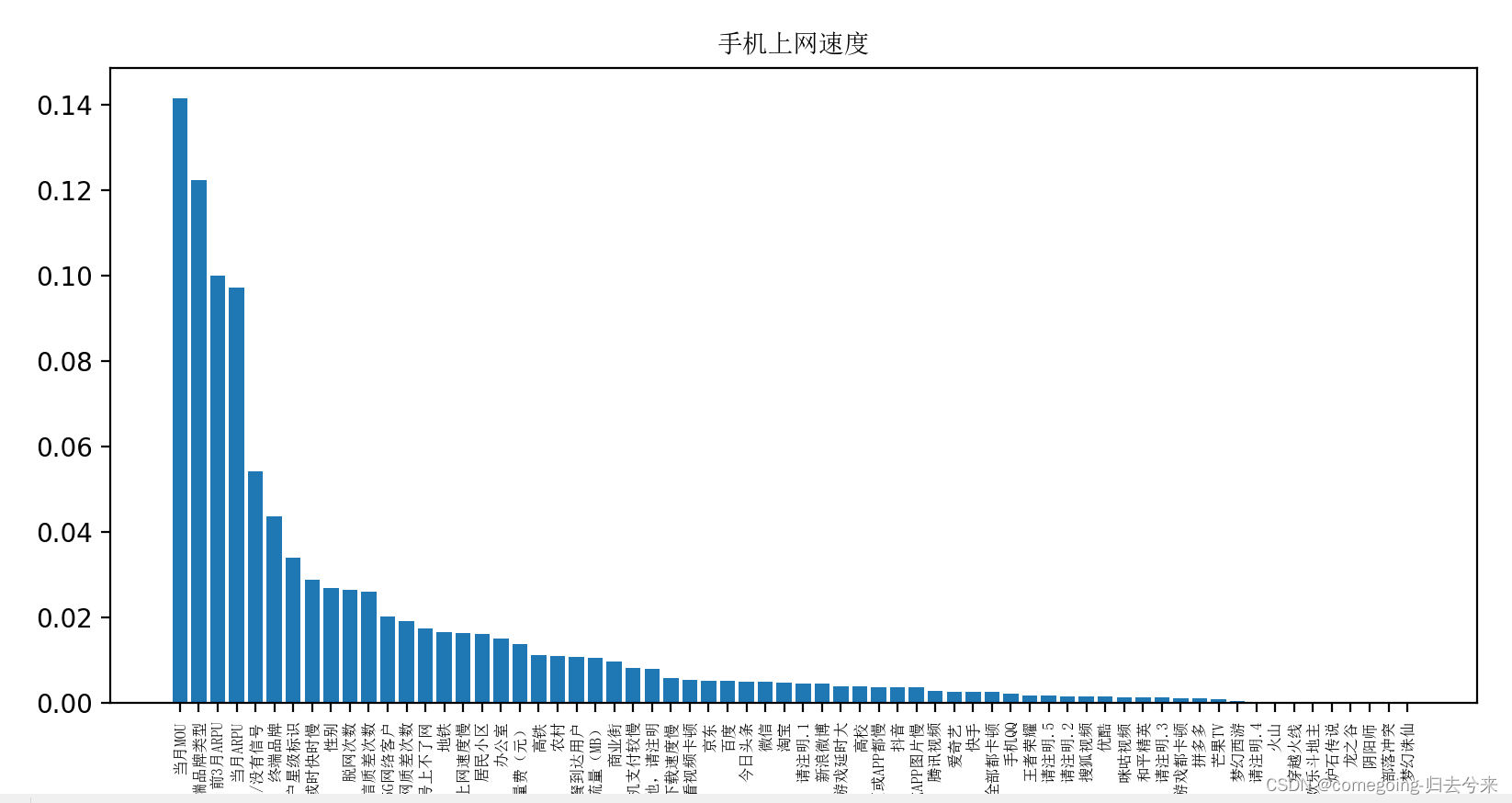
四、结果预测
针对这个赛题,其实我们通过皮尔逊相关系数发现其线性相关度较小,那么通过决策树既可以得到相关度同时也可以对结果进行预测
五、材料源码
github(仅代码):
GitHub - comegoing/2022mathorcup
百度网盘(完整):
链接:https://pan.baidu.com/s/1efuzvLE7RTV_U4TZA9KnKw?pwd=2023
提取码:2023
相关文章:
2022MathorCup赛题B
以下所有文字均基于作者的实际经验,并不具有完全的合理性,请谨慎参考 目录 一、问题分析 (一)问题一 (二)问题二 二、预处理 (一)训练集预处理 (二)测…...

适合销售使用的CRM系统特点
销售人员抱怨CRM系统太复杂,这是一个很重要的问题。毕竟,如果系统太难使用,会导致CRM实用率和效率下降,最终影响公司的运作。在这篇文章中,我们来探讨当销售抱怨crm客户系统太复杂了,企业该如何解决。 缺少…...

项目中获取resource下文件路径的方法
String filepathrequest.getServletContext().getRealPath("/")"files\\"; 获取的当前文件在实际运行的tomcat地址目录 String path ClassUtils.getDefaultClassLoader().getResource("").getPath()"tmp/files/"; 获取的是当前文件…...
Air32F103CBT6|CCT6|KEIL-uVsion5|本地编译|STClink|(6)、Air32F103编译下载
目录 一、环境搭建 准备工作 安装支持包 二、新建工程 添加外设库支持 测试代码 三、下载烧录 一、环境搭建 准备工作 安装MDK5,具体方法请百度,安装后需要激活才能编译大文件 下载安装AIR32F103的SDK:luatos-soc-air32f103: Air32f…...
)
结构(c的数据类型)
我们知道数组是相同类型元素的集合,那么结构就是不同类型的元素的集合,这些不同元素叫结构中的成员。是因为这些集合都有一定的联系才会归为一类的。 形式:我们知道,平时学习的int,double都叫类型,而结构是…...

前端常用的开工具库
常用的开发工具库 打包工具webpack webpack是现在最流行的打包工具之一,是javaScript的静态模块的打包器。会根据业务逻辑构建一个依赖的关系图,每一个依赖的单元都是一个模块,模块可以是js文件 可以图片资源或者css资源。在使用webpack的时…...

爬虫之数据库存储
在对于爬取数量数量较少时,我们可以将爬虫数据保存于CSV文件或者其他格式的文件中,既简单又方便,但是如果需要存储的数据量大,又要频繁访问这些数据时,就应该考虑将数据保存到数据库中了。目前主流的数据库有关系性数据…...
面试官:你可以用 for of 遍历 Object 吗?
本文以 用 for of遍历 Object 为引 来聊聊 迭代器模式。 什么是迭代器模式 迭代器模式提供一种方法顺序访问一个聚合对象中的各个元素,而又不暴露该对象的内部表示。 ——《设计模式:可复用面向对象软件的基础》 可以说迭代器模式就是为了遍历存在的。提…...

蓝桥杯基础12:BASIC-3试题 字母图形
资源限制 内存限制:256.0MB C/C时间限制:1.0s Java时间限制:3.0s Python时间限制:5.0s 问题描述 利用字母可以组成一些美丽的图形,下面给出了一个例子: ABCDEFG BABCDEF CBABCDE DCBABCD EDC…...
基于PaddleOCR开发懒人精灵文字识别插件
目的 懒人精灵是 Android 平台上的一款自动化工具,它通过编写 lua 脚本,结合系统的「 无障碍服务 」对 App 进行自动化操作。在文字识别方面它提供的有一款OCR识别插件,但是其中有识别速度慢,插件大的缺点,所以这里将讲…...

PyTorch 深度学习实战 | DIEN 模拟兴趣演化的序列网络
01、实例:DIEN 模拟兴趣演化的序列网络深度兴趣演化网络(Deep Interest Evolution Network,DIEN)是阿里巴巴团队在2018年推出的另一力作,比DIN 多了一个Evolution,即演化的概念。在DIEN 模型结构上比DIN 复杂许多,但大家丝毫不用担心,我们将DIEN 拆解开来详细地说明…...

pyspark null类型 在 json.dumps(null) 之后,会变为字符串‘null‘
在将 hive 数仓数据写入 MySQL 时候,有时我们需将数据转为 json 字符串,然后再存入 MySQL。但 hive 数仓中的 null 类型遇到 json 函数之后会变为 ‘null’ 字符串,这时我们只需在使用 json 函数之前对值进行判断即可,当值为 null…...
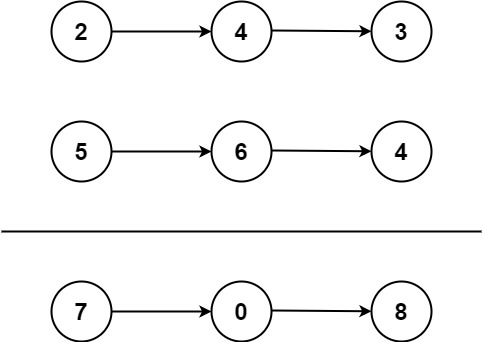
LeetCode - 两数相加
题目信息 源地址:两数相加 给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。 请你将两个数相加,并以相同形式返回一个表示和的链表。 你可以假设除了数字…...
Office 2021专业版安装包及激活教程
[软件名称]: Office 2021 [软件大小]: 4.33GB [安装环境]: Win11/Win 10 [软件安装包下载]:https://pan.quark.cn/s/169ed49988b2 “Microsoft Office 2021是Microsoft推出的办公软件。2021年10月5日,Office 2021 for Mac发布,其中包含许多新功能 Micro…...
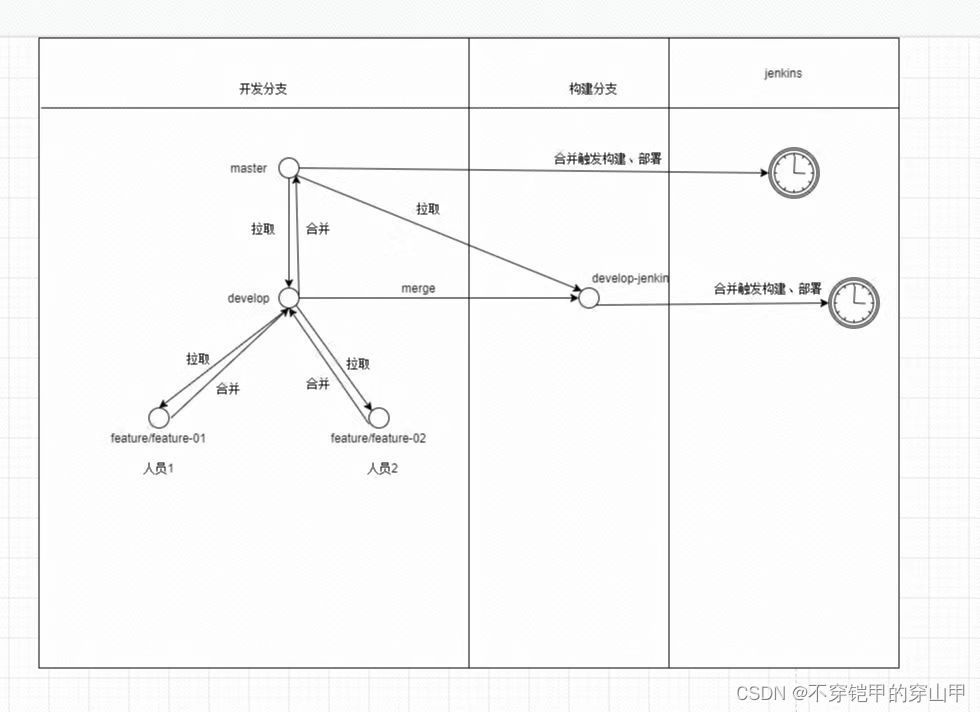
git版本规范-前端
前言 本文档适用于前端的小伙伴。针对目前前端只有测试环境和生产环境,为更好管理前端代码和适用于自动化部署,编写次文档,有不同意见的小伙伴可以进行讨论。 分支 由于没有目前没有预发环境,简化开发、测试、部署和发布流程&a…...
: 重新认识Device Path)
UEFI Device Path (1): 重新认识Device Path
从事UEFI开发的人员,对UEFI Device Path的概念都有一定了解,但未必都建立了比较系统而深刻的认识。UEFI Device Path的认知仅限于: 1)它是用来表示系统中设备的路径;2) 在UEFI SPEC中定义了它的数据结构和若干操作它的UEFI Protocol。除此以外…...
合成孔径成像的应用及发展
一、引言 合成孔径成像自20世纪50年代提出,应用于雷达成像,历经70年的研发,已经日趋成熟,成功地用于环境资源监测、灾害监测、海事管理及军事等领域。受物理环境制约,合成孔径在声呐成像中的研发与应用起步稍迟&#…...

MyBatis-Plus的基本操作
目录 1、配置文件 1、添加依赖 2、启动类 3、实体类 4、添加Mapper类 5、测试Mapper接口 2、CRUD测试 1、insert添加 2、修改操作 3、删除操作 3、MyBatis-Plus条件构造器 4、knife4j 1、Swagger介绍 2、集成knife4j 3.添加依赖 4 添加knife4j配置类 5、 Cont…...

HTTPAPI使用
1、使用浏览器 1.1、获取当前IP(限制 1200次 /小时) 用浏览器访问 http://ip.hahado.cn/current-ip 输入用户名和密码 [{"ip": "180.102.181.64","ttl": 262.87515091896057} ] "ip": 字段是当前的外网IP ("ip&qu…...
Windos下设置java项目开机自启动
这里是将java项目注册为Windows服务实现开机自启动。 查看.NET framework版本 因为使用winsw工具运行时需要使用.NET framework,基本上现在的win10系统带自带有.NET framework4.0,为了选择合适的版本,我们可以查看本机.NET Framework版本,根…...

半导体测试数据可视化终极指南:STDF-Viewer从入门到精通
半导体测试数据可视化终极指南:STDF-Viewer从入门到精通 【免费下载链接】STDF-Viewer A free GUI tool to visualize STDF (semiconductor Standard Test Data Format) data files. 项目地址: https://gitcode.com/gh_mirrors/st/STDF-Viewer STDF-Viewer是…...

STM32与ADS1256的SPI通信实战:从寄存器配置到串口数据可视化
1. 硬件准备与电路连接 第一次接触ADS1256这块24位ADC芯片时,我被它的精度吓到了——理论上能分辨出0.000000119V的电压变化!不过要让STM32和它正常对话,硬件连接是第一个门槛。我用的STM32F103C8T6最小系统板,和ADS1256模块之间…...

如何用Cyber Engine Tweaks终极解锁赛博朋克2077的完整定制体验:新手快速入门指南
如何用Cyber Engine Tweaks终极解锁赛博朋克2077的完整定制体验:新手快速入门指南 【免费下载链接】CyberEngineTweaks Cyberpunk 2077 tweaks, hacks and scripting framework 项目地址: https://gitcode.com/gh_mirrors/cy/CyberEngineTweaks 你是否厌倦了…...

探索Windows HEIC缩略图:跨平台照片管理深度解析
探索Windows HEIC缩略图:跨平台照片管理深度解析 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails Windows HEIC缩略图…...
)
告别混乱信号!用CANdb++ Editor从零搭建汽车CAN网络DBC文件(保姆级图文教程)
告别混乱信号!用CANdb Editor从零搭建汽车CAN网络DBC文件(保姆级图文教程) 在汽车电子开发领域,CAN总线如同神经脉络般贯穿整车系统。我曾参与过一个新能源整车项目,由于早期缺乏规范的DBC文件,不同ECU厂商…...

Redis增强工具包:封装分布式锁、缓存模板与监控的最佳实践
1. 项目概述:一个Redis开发者的“瑞士军刀”在分布式系统和高并发场景下,Redis几乎成了标配。但用久了你会发现,官方客户端虽然稳定,但在日常开发、调试、运维中,总有些“不够顺手”的地方。比如,想批量按模…...

Gitclaw:封装复杂Git操作,提升开发效率的命令行工具
1. 项目概述:一个为Git操作注入“爪牙”的命令行工具如果你和我一样,日常开发工作重度依赖Git,那你肯定也经历过这样的时刻:面对一个需要多步操作才能完成的复杂Git任务,比如清理多个已合并的分支、批量重写提交历史中…...

终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能
终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专为NVIDIA显卡用户设计的免费优化工具&…...

Arm Morello平台模型与CHERI安全扩展开发指南
1. Arm Morello平台模型概述Morello是Arm公司推出的实验性处理器架构,基于CHERI(Capability Hardware Enhanced RISC Instructions)安全扩展技术。这个平台模型本质上是一个功能准确的虚拟硬件环境,允许开发者在物理芯片问世前18-…...

CircuitPython开发进阶:从库文档解读到内存优化与异步编程实战
1. 从“能用”到“精通”:为什么你需要深入理解CircuitPython库文档刚接触CircuitPython时,我们往往是从复制粘贴示例代码开始的。这没什么问题,快速让一个LED闪烁起来,或者让传感器读出数据,那种即时反馈的成就感是驱…...