爬虫之数据库存储
在对于爬取数量数量较少时,我们可以将爬虫数据保存于CSV文件或者其他格式的文件中,既简单又方便,但是如果需要存储的数据量大,又要频繁访问这些数据时,就应该考虑将数据保存到数据库中了。目前主流的数据库有关系性数据库MySQL,以及非关系性数据库MongoDB和Redis等。这里我先来讲讲MySQL。
1、MySQL数据库
MySQl数据库是一个中小型关系型数据库,应用及其广泛,开源,高效,免费,可移植性好,现在有很多大厂还是在广泛使用MySQL数据库。
1.关系型数据库概述
关系型数据库,是建立在关系模型基础上的数据库,简单的讲,它由多张互相联结的二位表格组成,每一行是一条记录,每一列是一个字段,而表就是某个实体的集合,它展现的形式类似于EXCEL中常见的表格。
像SQLite,MySQL,Oracle,SQL Server DB2等都属于关系型数据库。
2.下载和安装MySQL数据库
这里常规的安装方法我不再赘述,如果后续有要求,我会补上。安装本地测试集成环境
3、数据库管理工具Navicat
MySQL安装好之后,下面就可以建立保存爬虫数据的数据库了。如果对MySQL数据库不是很精通,甚至连SQL语句都不会怎么写,那么Navicat绝对可以帮上忙。这是一个强大的数据库管理和设计工具,支持Windows,Mac OS,Linux系统。通过直观的GUI(图形用户界面),可以让用户方便的管理MySQL,Oracle,SQL Server,Mongo DB等数据库。
3.1 Navicat下载和安装
进入Navicat官网下载Navicat for MySQL,下载地址为:Navicat下载地址
3.2 连接MySQL数据库服务器
Navicat安装完成后,运行 Navicat。首先完成与MySQL数据库服务器的连接。单机“连接”按钮,在弹出的“新建连接”对话框中输入MySQL配置信息,如连接名为mysql(名称自定义),密码为安装MySQL时设置的密码,其余配置默认设置,单击“连接测试”按钮,确保连接成功,最后单机“确定”按钮,完成与MySQl服务器的连接。
3.3 新建数据库
与MySQL数据库服务器建立连接后,就可以操作MySQL数据库了。新建一个数据库,用于存储爬取的信息。右击连接名mysql,在弹出的快捷菜单中,选择“新建数据库”命令,输入数据库名,设置字符集和排序规则,单机“确定”。
3.4 新建表
在新建的数据库crawler中新建一个用于存储爬取测试的表test。字段这里根据爬取的内容设置,比如:id的设置为int型,主键,不是null,自动递增,其余字段均为varchar型。
Python爬虫之数据写入
#写入到Excel
import xlsxwriter#创建文件,并添加一个工作表
workbook=xlsxwriter.Workbook('demo.xlsx')
worksheet=workbook.add_worksheet()#在指定位置写入数据
worksheet.write("A1","这是A1的数据")
worksheet.write("A2","这是A2的数据")#关闭表格文件
workbook.close()
#爬取便民查询网常用账号,并写入到Excel
import re
import requests
import xlsxwriterheaders = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Ap\
pleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Sa\
fari/537.36"
}response=requests.get("http://changyongdianhuahaoma.51240.com/",headers=headers).textpat1=r'<tr bgcolor="#EFF7F0">[\s\S]*?<td>(.*?)</td>[\s\S]*?<td>[\s\S]*?</td>[\s\S]*?</tr>'
pat2=r'<tr bgcolor="#EFF7F0">[\s\S]*?<td>[\s\S]*?</td>[\s\S]*?<td>(.*?)</td>[\s\S]*?</tr>'pattern1=re.compile(pat1)
pattern2=re.compile(pat2)data1=pattern1.findall(response)
data2=pattern2.findall(response)resultlist=[]#创建表格
workbook=xlsxwriter.Workbook("demo2.xlsx")
worksheet=workbook.add_worksheet()for i in range(0,len(data1)):resultlist.append(data1[i]+data2[i])#写入数据worksheet.write("A"+str(i+1),data1[i])worksheet.write("B"+str(i+1),data2[i])print(resultlist)
# 关闭表格资源,这样才会完成创建
workbook.close()
#爬取便民查询网常用账号,并写入到Mysql
#注意:需要提前创建对应字段的数据库
import re
import requests
import pymysql#建立数据库连接
db=pymysql.Connect(host="localhost",port=3306,user="root",passwd="AA123456",db="spider_test",charset="utf8")
cursor=db.cursor()#爬取数据
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Ap\
pleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Sa\
fari/537.36"
}response=requests.get("http://changyongdianhuahaoma.51240.com/",headers=headers).text#处理数据
pat1=r'<tr bgcolor="#EFF7F0">[\s\S]*?<td>(.*?)</td>[\s\S]*?<td>[\s\S]*?</td>[\s\S]*?</tr>'
pat2=r'<tr bgcolor="#EFF7F0">[\s\S]*?<td>[\s\S]*?</td>[\s\S]*?<td>(.*?)</td>[\s\S]*?</tr>'pattern1=re.compile(pat1)
pattern2=re.compile(pat2)data1=pattern1.findall(response)
data2=pattern2.findall(response)#清空数据库原来的内容
sqll="delete from tel"
cursor.execute(sqll)
db.commit()resultlist=[]
for i in range(0,len(data1)):resultlist.append(data1[i]+data2[i])sql="insert into tel(name,phone) values('"+data1[i]+"','"+data2[i]+"')"cursor.execute(sql)print(resultlist)db.commit()
db.close()
相关文章:

爬虫之数据库存储
在对于爬取数量数量较少时,我们可以将爬虫数据保存于CSV文件或者其他格式的文件中,既简单又方便,但是如果需要存储的数据量大,又要频繁访问这些数据时,就应该考虑将数据保存到数据库中了。目前主流的数据库有关系性数据…...
面试官:你可以用 for of 遍历 Object 吗?
本文以 用 for of遍历 Object 为引 来聊聊 迭代器模式。 什么是迭代器模式 迭代器模式提供一种方法顺序访问一个聚合对象中的各个元素,而又不暴露该对象的内部表示。 ——《设计模式:可复用面向对象软件的基础》 可以说迭代器模式就是为了遍历存在的。提…...

蓝桥杯基础12:BASIC-3试题 字母图形
资源限制 内存限制:256.0MB C/C时间限制:1.0s Java时间限制:3.0s Python时间限制:5.0s 问题描述 利用字母可以组成一些美丽的图形,下面给出了一个例子: ABCDEFG BABCDEF CBABCDE DCBABCD EDC…...
基于PaddleOCR开发懒人精灵文字识别插件
目的 懒人精灵是 Android 平台上的一款自动化工具,它通过编写 lua 脚本,结合系统的「 无障碍服务 」对 App 进行自动化操作。在文字识别方面它提供的有一款OCR识别插件,但是其中有识别速度慢,插件大的缺点,所以这里将讲…...

PyTorch 深度学习实战 | DIEN 模拟兴趣演化的序列网络
01、实例:DIEN 模拟兴趣演化的序列网络深度兴趣演化网络(Deep Interest Evolution Network,DIEN)是阿里巴巴团队在2018年推出的另一力作,比DIN 多了一个Evolution,即演化的概念。在DIEN 模型结构上比DIN 复杂许多,但大家丝毫不用担心,我们将DIEN 拆解开来详细地说明…...

pyspark null类型 在 json.dumps(null) 之后,会变为字符串‘null‘
在将 hive 数仓数据写入 MySQL 时候,有时我们需将数据转为 json 字符串,然后再存入 MySQL。但 hive 数仓中的 null 类型遇到 json 函数之后会变为 ‘null’ 字符串,这时我们只需在使用 json 函数之前对值进行判断即可,当值为 null…...
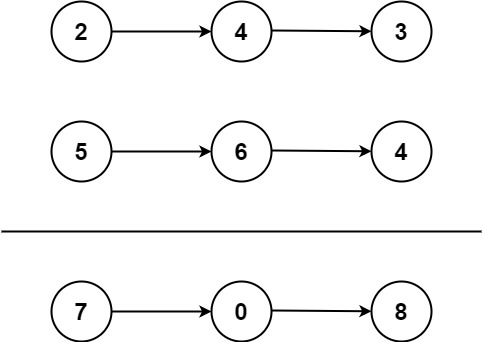
LeetCode - 两数相加
题目信息 源地址:两数相加 给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。 请你将两个数相加,并以相同形式返回一个表示和的链表。 你可以假设除了数字…...
Office 2021专业版安装包及激活教程
[软件名称]: Office 2021 [软件大小]: 4.33GB [安装环境]: Win11/Win 10 [软件安装包下载]:https://pan.quark.cn/s/169ed49988b2 “Microsoft Office 2021是Microsoft推出的办公软件。2021年10月5日,Office 2021 for Mac发布,其中包含许多新功能 Micro…...
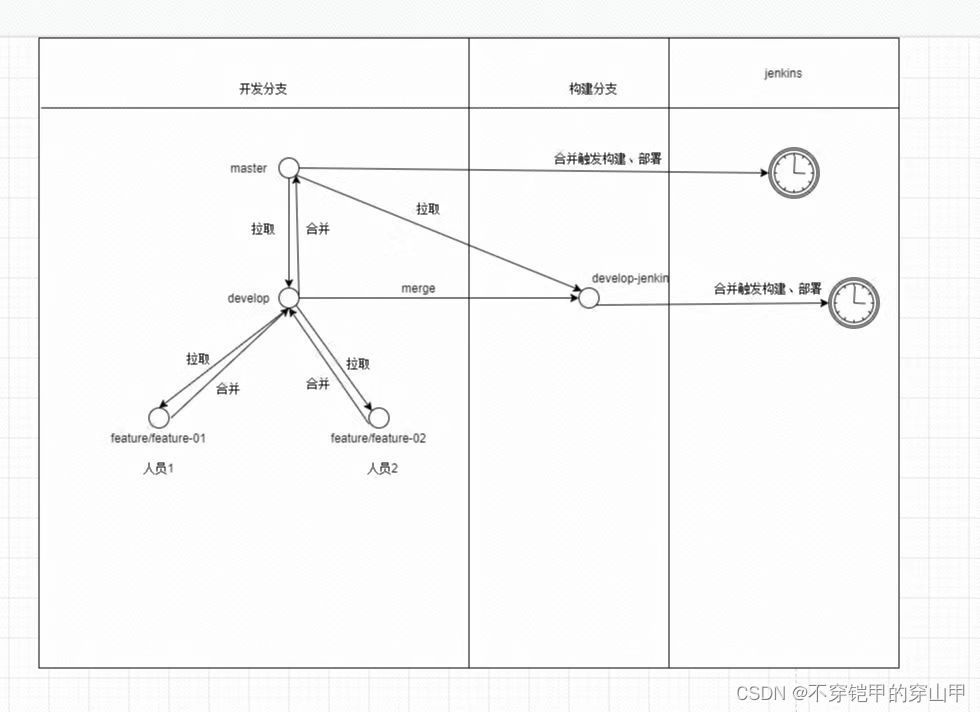
git版本规范-前端
前言 本文档适用于前端的小伙伴。针对目前前端只有测试环境和生产环境,为更好管理前端代码和适用于自动化部署,编写次文档,有不同意见的小伙伴可以进行讨论。 分支 由于没有目前没有预发环境,简化开发、测试、部署和发布流程&a…...
: 重新认识Device Path)
UEFI Device Path (1): 重新认识Device Path
从事UEFI开发的人员,对UEFI Device Path的概念都有一定了解,但未必都建立了比较系统而深刻的认识。UEFI Device Path的认知仅限于: 1)它是用来表示系统中设备的路径;2) 在UEFI SPEC中定义了它的数据结构和若干操作它的UEFI Protocol。除此以外…...
合成孔径成像的应用及发展
一、引言 合成孔径成像自20世纪50年代提出,应用于雷达成像,历经70年的研发,已经日趋成熟,成功地用于环境资源监测、灾害监测、海事管理及军事等领域。受物理环境制约,合成孔径在声呐成像中的研发与应用起步稍迟&#…...

MyBatis-Plus的基本操作
目录 1、配置文件 1、添加依赖 2、启动类 3、实体类 4、添加Mapper类 5、测试Mapper接口 2、CRUD测试 1、insert添加 2、修改操作 3、删除操作 3、MyBatis-Plus条件构造器 4、knife4j 1、Swagger介绍 2、集成knife4j 3.添加依赖 4 添加knife4j配置类 5、 Cont…...

HTTPAPI使用
1、使用浏览器 1.1、获取当前IP(限制 1200次 /小时) 用浏览器访问 http://ip.hahado.cn/current-ip 输入用户名和密码 [{"ip": "180.102.181.64","ttl": 262.87515091896057} ] "ip": 字段是当前的外网IP ("ip&qu…...
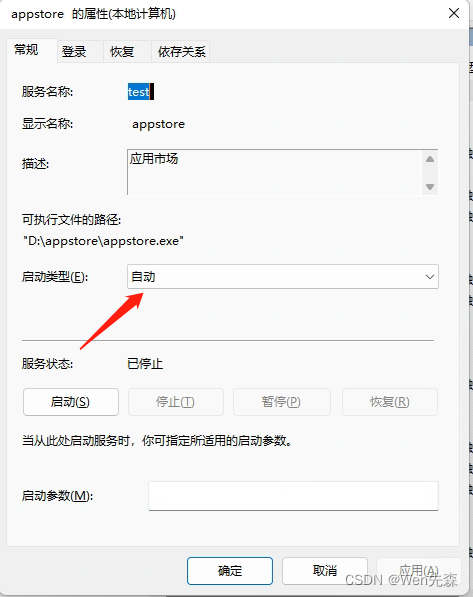
Windos下设置java项目开机自启动
这里是将java项目注册为Windows服务实现开机自启动。 查看.NET framework版本 因为使用winsw工具运行时需要使用.NET framework,基本上现在的win10系统带自带有.NET framework4.0,为了选择合适的版本,我们可以查看本机.NET Framework版本,根…...
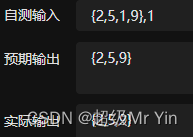
(链表)移除链表元素(双指针法)
文章目录前言:问题描述:解题思路(双指针法):代码实现:总结:前言: 此篇是针对链表的经典练习题。 问题描述: 给你一个链表的头节点 head 和一个整数 val ,请…...

Raft协议
文章目录一、目的(与Paxos相同)二、名字来源三、服务器状态四、基本实现1、任期2、RPC调用3、领导者选举4、日志复制5.领导者更替三、Raft与Paxos的区别1.表现形式2.简单性3.领导选举算法一、目的(与Paxos相同) 保证日志完全相同…...
动态规划概述
动态规划概述动态规划的两个要求: 1.最优子结构 例:现有一座10级台阶的楼梯,我们要从下往上走,每次只能跨一步,一步可以往上走1级或者2级台阶,请问一共有多少种解法呢? 台阶数12345678910走法数…...

CPU缓存架构+Disruptor内存队列
文章目录CPU缓存架构Disruptor内存队列CPU缓存架构介绍缓存一致性问题缓存一致性协议MESI协议伪共享问题高性能内存队列DisruptorCPU缓存架构Disruptor内存队列 CPU缓存架构 介绍 cpu与内存的交互数据之间,有一个高速缓存层。有些处理器有3层缓冲,有些…...
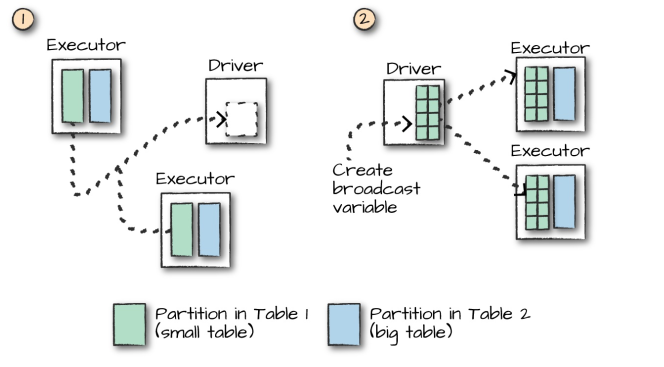
Spark SQL join操作详解
一、 数据准备 本文主要介绍 Spark SQL 的多表连接,需要预先准备测试数据。分别创建员工和部门的 Datafame,并注册为临时视图,代码如下: val spark SparkSession.builder().appName("aggregations").master("lo…...
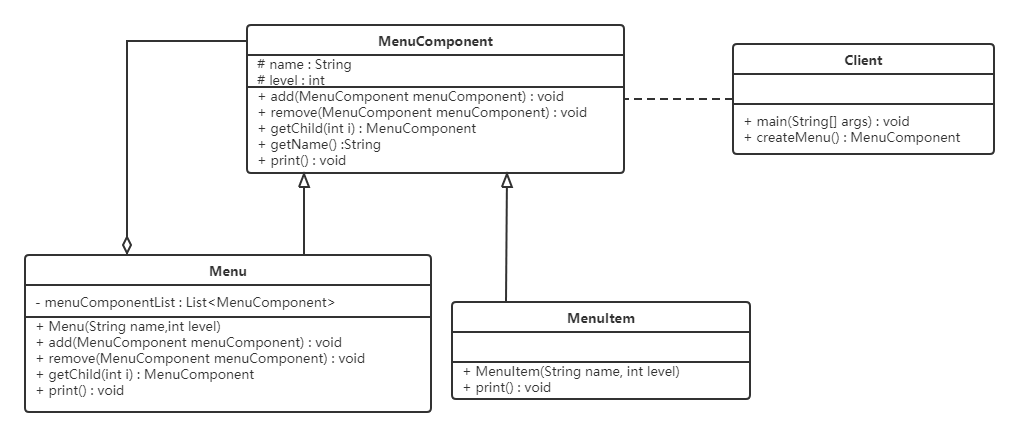
设计模式-day04
5,结构型模式 5.6 组合模式 5.6.1 概述 对于这个图片肯定会非常熟悉,上图我们可以看做是一个文件系统,对于这样的结构我们称之为树形结构。在树形结构中可以通过调用某个方法来遍历整个树,当我们找到某个叶子节点后,…...

零代码构建离线环境数据记录器:基于WipperSnapper与BME280的实践指南
1. 项目概述:告别代码,用离线数据记录器抓住每一刻环境数据如果你曾经想搭建一个能默默在角落记录温度、湿度或气压的小设备,但又觉得写代码、调试硬件太麻烦,那今天这个项目就是为你准备的。数据记录,听起来很专业&am…...

AI视频自动化生产:从LLM到MoviePy的全栈技术解析
1. 项目概述:一个能自动“印钞”的AI内容工厂最近在GitHub上看到一个挺有意思的项目,叫“MoneyPrinterAICreate”。光看名字就挺吸引人,直译过来就是“印钞机AI创作”。这可不是什么物理印钞机,而是一个利用人工智能技术ÿ…...

实战解析:如何通过显卡频率优化解决CUDA/TensorRT推理速度骤降问题
1. 从异常现象到问题定位 最近在部署一个基于YOLOv5的工业检测系统时,遇到了一个让人头疼的问题:当系统从连续检测模式切换到条件触发模式后,原本飞快的CUDA推理速度突然下降了近5倍。更诡异的是,降低相机帧率后,推理…...

杰理701N可视化SDK:从stream.bin生成到工程导入的EQ调音闭环
1. 杰理701N可视化SDK与EQ调音基础 第一次接触杰理701N的开发者可能会好奇,这个可视化SDK到底能做什么?简单来说,它就像给声学工程师配了一把"声音雕刻刀"。通过图形化界面,你可以实时调整蓝牙耳机、音箱等设备的音效表…...

终极指南:在Windows上直接安装安卓APK文件的5个简单步骤
终极指南:在Windows上直接安装安卓APK文件的5个简单步骤 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上运行安卓应用,但又厌…...

mnestra:基于ESBuild的极简前端构建工具,速度与体验的完美平衡
1. 项目概述:一个被低估的现代前端构建工具如果你在前端开发领域摸爬滚打超过五年,大概率经历过从 Grunt、Gulp 到 Webpack 的构建工具变迁史。每次工具的迭代,都伴随着配置文件的日益复杂和构建速度的微妙下降。当 Vite 携 ES Module 原生支…...

Source Han Serif CN:企业级开源字体终极实战指南
Source Han Serif CN:企业级开源字体终极实战指南 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 在当今数字化时代,企业面临字体选择的两难困境:商…...

QMCFLAC2MP3终极指南:免费快速解锁QQ音乐格式限制
QMCFLAC2MP3终极指南:免费快速解锁QQ音乐格式限制 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾经在QQ音乐下载了心爱的歌曲࿰…...

手机号归属地查询系统:3步构建可视化定位工具
手机号归属地查询系统:3步构建可视化定位工具 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_mirrors/lo/l…...

虚实实景双向映射,升级高端楼宇精细化透明治理
虚实实景双向映射,升级高端楼宇精细化透明治理副标题:原生引擎驱动动态三维场景重构,结合无感化坐标解算、遮挡自适应跨镜接续、身体指纹无源身份匹配,构筑难以复刻、适配极强的楼宇透明化技术壁垒一、方案总览当下高端楼宇运营治…...