Go分布式爬虫笔记(二十二)
文章目录
- 22 辅助任务管理:任务优先级、去重与失败处理
- 设置爬虫最大深度
- 避免请求重复
- 设置优先队列
- 设置随机User-Agent
- 失败处理
22 辅助任务管理:任务优先级、去重与失败处理
设置爬虫最大深度
目的:
- 防止访问陷入到死循环
- 控制爬取的有效链接的数量
最大爬取深度是和任务有关的,因此我们要在 Request 中加上 MaxDepth 这个字段,它可以标识到爬取的最大深度。Depth 则表示任务的当前深度,最初始的深度为 0。
type Request struct {Url stringCookie stringWaitTime time.DurationDepth intMaxDepth intParseFunc func([]byte, *Request) ParseResult
}
那在异步爬取的情况下,我们怎么知道当前网站的深度呢?最好的时机是在采集引擎采集并解析爬虫数据,并将下一层的请求放到队列中的时候。以我们之前写好的 ParseURL 函数为例,在添加下一层的 URL 时,我们将 Depth 加 1,这样就标识了下一层的深度。
func ParseURL(contents []byte, req *collect.Request) collect.ParseResult {re := regexp.MustCompile(urlListRe)matches := re.FindAllSubmatch(contents, -1)result := collect.ParseResult{}for _, m := range matches {u := string(m[1])result.Requesrts = append(result.Requesrts, &collect.Request{Url: u,WaitTime: req.WaitTime,Cookie: req.Cookie,Depth: req.Depth + 1,MaxDepth: req.MaxDepth,ParseFunc: func(c []byte, request *collect.Request) collect.ParseResult {return GetContent(c, u)},})}return result
}
最后一步,我们在爬取新的网页之前,判断最大深度。如果当前深度超过了最大深度,那就不再进行爬取。
func (r *Request) Check() error {if r.Depth > r.MaxDepth {return errors.New("Max depth limit reached")}return nil
}func (s *Schedule) CreateWork() {for {r := <-s.workerChif err := r.Check(); err != nil {s.Logger.Error("check failed",zap.Error(err),)continue}...}
}
避免请求重复
目的:
- 避免死循环
- 无效爬取
考虑点:
- 用什么数据结构来存储数据才能保证快速地查找到请求的记录?
哈希表 - 如何保证并发查找与写入时,不出现并发冲突问题?
锁, sync.Map - 在什么条件下,我们才能确认请求是重复的,从而停止爬取?
任务进行前检查
在解决上面的三个问题之前,我们先优化一下代码。我们之前的 Request 结构体会在每一次请求时发生变化,但是我们希望有一个字段能够表示一整个网站的爬取任务,因此我们需要抽离出一个新的结构 Task 作为一个爬虫任务,而 Request 则作为单独的请求存在。有些参数是整个任务共有的,例如 Task 中的 Cookie、MaxDepth(最大深度)、WaitTime(默认等待时间)和 RootReq(任务中的第一个请求)。
type Task struct {Url stringCookie stringWaitTime time.DurationMaxDepth intRootReq *RequestFetcher Fetcher
}// 单个请求
type Request struct {Task *TaskUrl stringDepth intParseFunc func([]byte, *Request) ParseResult
}
由于抽象出了 Task,代码需要做对应的修改,例如我们需要把初始的 Seed 种子任务替换为 Task 结构。
for i := 0; i <= 0; i += 25 {str := fmt.Sprintf("<https://www.douban.com/group/szsh/discussion?start=%d>", i)seeds = append(seeds, &collect.Task{...Url: str,RootReq: &collect.Request{ParseFunc: doubangroup.ParseURL,},})}
同时,在深度检查时,每一个请求的最大深度需要从 Task 字段中获取。
func (r *Request) Check() error {if r.Depth > r.Task.MaxDepth {return errors.New("Max depth limit reached")}return nil
}
接下来,我们继续用一个哈希表结构来存储历史请求。
由于我们希望随时访问哈希表中的历史请求,所以把它放在 Request、Task 中都不合适。 放在调度引擎中也不合适,因为调度引擎从功能上讲,应该只负责调度才对。所以,我们还需要完成一轮抽象,将调度引擎抽离出来作为一个接口,让它只做调度的工作,不用负责存储全局变量等任务。
type Crawler struct {out chan collect.ParseResult //负责处理爬取后的数据,完成下一步的存储操作。schedule 函数会创建调度程序,负责的是调度的核心逻辑。Visited map[string]bool //存储请求访问信息VisitedLock sync.Mutexoptions
}type Scheduler interface {Schedule() //启动调度器Push(...*collect.Request) //将请求放入到调度器中Pull() *collect.Request //从调度器中获取请求
}type Schedule struct {requestCh chan *collect.Request //负责接收请求workerCh chan *collect.Request //负责分配任务给 workerreqQueue []*collect.RequestLogger *zap.Logger
}
Visited 中的 Key 是请求的唯一标识,我们现在先将唯一标识设置为 URL + method 方法,并使用 MD5 生成唯一键。后面我们还会为唯一标识加上当前请求的规则条件。
// 请求的唯一识别码
func (r *Request) Unique() string {block := md5.Sum([]byte(r.Url + r.Method))return hex.EncodeToString(block[:])
}
接着,编写 HasVisited 方法,判断当前请求是否已经被访问过。StoreVisited 方法用于将请求存储到 Visited 哈希表中。
func (e *Crawler) HasVisited(r *collect.Request) bool {e.VisitedLock.Lock()defer e.VisitedLock.Unlock()unique := r.Unique()return e.Visited[unique]
}func (e *Crawler) StoreVisited(reqs ...*collect.Request) {e.VisitedLock.Lock()defer e.VisitedLock.Unlock()for _, r := range reqs {unique := r.Unique()e.Visited[unique] = true}
}
最后在 Worker 中,在执行 request 前,判断当前请求是否已被访问。如果请求没有被访问过,将 request 放入 Visited 哈希表中。
func (s *Crawler) CreateWork() {for {r := s.scheduler.Pull()if err := r.Check(); err != nil {s.Logger.Error("check failed",zap.Error(err),)continue}// 判断当前请求是否已被访问if s.HasVisited(r) {s.Logger.Debug("request has visited",zap.String("url:", r.Url),)continue}// 设置当前请求已被访问s.StoreVisited(r)...}
}
设置优先队列
爬虫任务的优先级有时并不是相同的,一些任务需要优先处理。因此,接下来我们就来设置一个任务的优先队列。优先队列还可以分成多个等级,在这里将它简单地分为了两个等级,即优先队列和普通队列。优先级更高的请求会存储到 priReqQueue 优先队列中。
type Schedule struct {requestCh chan *collect.RequestworkerCh chan *collect.RequestpriReqQueue []*collect.RequestreqQueue []*collect.RequestLogger *zap.Logger
}
设置随机User-Agent
避免服务器检测到我们使用了同一个 User-Agent,继而判断出是同一个客户端在发出请求,我们可以为发送的 User-Agent 加入随机性。
这个操作的本质就是将浏览器的不同型号与不同版本拼接起来,组成一个新的 User-Agent。
随机生成 User-Agent 的逻辑位于 extensions/randomua.go 中,里面枚举了不同型号的浏览器和不同型号的版本,并且通过排列组合产生了不同的 User-Agent。
最后一步,我们要在采集引擎中调用 GenerateRandomUA 函数,将请求头设置为随机的 User-Agent,如下所示:
func (b BrowserFetch) Get(request *spider.Request) ([]byte, error) {...req.Header.Set("User-Agent", extensions.GenerateRandomUA())resp, err := client.Do(req)
失败处理
我们在爬取网站时,网络超时等诸多潜在风险都可能导致爬取失败。这时,我们可以对失败的任务进行重试。但是如果网站多次失败,那就没有必要反复重试了,我们可以将它们放入单独的队列中。为了防止失败请求日积月久导致的内存泄露,同时也为了在程序崩溃后能够再次加载这些失败网站,我们最后还需要将这些失败网站持久化到数据库或文件中。
我们先完成前半部分,即失败重试。我们要在全局 Crawler 中存储 failures 哈希表,设置 Key 为请求的唯一键,用于快速查找。failureLock 互斥锁用于并发安全。
type Crawler struct {...failures map[string]*collect.Request // 失败请求id -> 失败请求failureLock sync.Mutex
}
当请求失败之后,调用 SetFailure 方法将请求加入到 failures 哈希表中,并且把它重新交由调度引擎进行调度。这里我们为任务 Task 引入了一个新的字段 Reload,标识当前任务的网页是否可以重复爬取。如果不可以重复爬取,我们需要在失败重试前删除 Visited 中的历史记录。
「此文章为4月Day6学习笔记,内容来源于极客时间《Go分布式爬虫实战》,强烈推荐该课程!/推荐该课程」
相关文章:
)
Go分布式爬虫笔记(二十二)
文章目录22 辅助任务管理:任务优先级、去重与失败处理设置爬虫最大深度避免请求重复设置优先队列设置随机User-Agent失败处理22 辅助任务管理:任务优先级、去重与失败处理 设置爬虫最大深度 目的: 防止访问陷入到死循环控制爬取的有效链接的数量 最大…...

跨线程修改主界面
winform 方式: public delegate void MyInvoke(string str1); private void check_Click(object sender, RoutedEventArgs e) { //跨现场调度1 delete委托 WIMFORM Task.Run(() > { …...
国内ChatGPt研发-中国chatGPT
人工智能软件chatGPT Chat GPT是一种自然语言处理算法,采用了深度学习技术,用于实现文本生成和自然语言处理任务。它可以实现自然而然的人机交互,在自然语言生成和问答领域应用广泛。 值得注意的是,Chat GPT本身并不是一款具体的…...
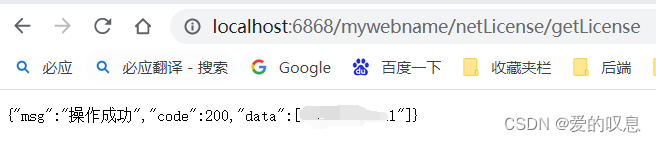
springboot的rest服务配置服务的根路径
如果不配置默认为空,如下是application.yml文件只配置了端口号 server:port: 6868 那么访问时直接访问服务即可 如果配置了rest服务 RestController RequestMapping("/netLicense") public class NetLicenseController {RequestMapping("/getLice…...

MySQL B+Tree 索引优化技巧
文章目录前言一、BTree索引的基本原理二、BTree索引的性能优化技巧1.索引列的选择2.索引列的顺序3.索引长度4.索引的覆盖性5. 索引的唯一性总结前言 MySQL是一种开源关系型数据库管理系统,被广泛应用于各种应用程序中。作为一种关系型数据库,MySQL使用B…...

100种思维模型之逆向思维模型-46
芒格思考问题总是从逆向开始!正如他经常提到的一句谚语:如果我能够知道我将死在哪里,那么我将永远不去那个地方。 马云有句口头禅:倒立看世界,一切皆有可能! 遇到难题时,不妨回头看看࿰…...

C/C++每日一练(20230413)
目录 1. 与浮点数A最接近的分数B/C 🌟 2. 比较版本号 🌟🌟 3. 无重复字符的最长子串 🌟🌟 🌟 每日一练刷题专栏 🌟 Golang每日一练 专栏 Python每日一练 专栏 C/C每日一练 专栏 Java每…...

volatile和synchronized的区别
volatile和synchronized的区别并发编程三个特性:原子性有序性可见性ViolatedSynchronized区别对比并发编程三个特性: 原子性、有序性、可见性 原子性 volatile无法保证原子性。 synchronized是排它锁,被synchronzied修饰的代码不能被打断…...

Cadence Allegro 导出Unplaced Component Report报告详解
⏪《上一篇》 🏡《上级目录》 ⏩《下一篇》 目录 1,概述2,Unplaced Component Report作用3,Unplaced Component Report示例4,Unplaced Component Report导出方法4.1,方法14.2,方法2B站关注“硬小二”浏览更多演示视频...
面试了上百位性能测试后,我发现了一个令人不安的事实...
在企业中负责技术招聘的同学,肯定都有一个苦恼,那就是招一个合适的测试太难了!若要问起招哪种类型的测试最难时,相信很多人都会说出“性能测试”这个答案。 每当发布一个性能测试岗位,不一会就能收到上百份简历&#…...
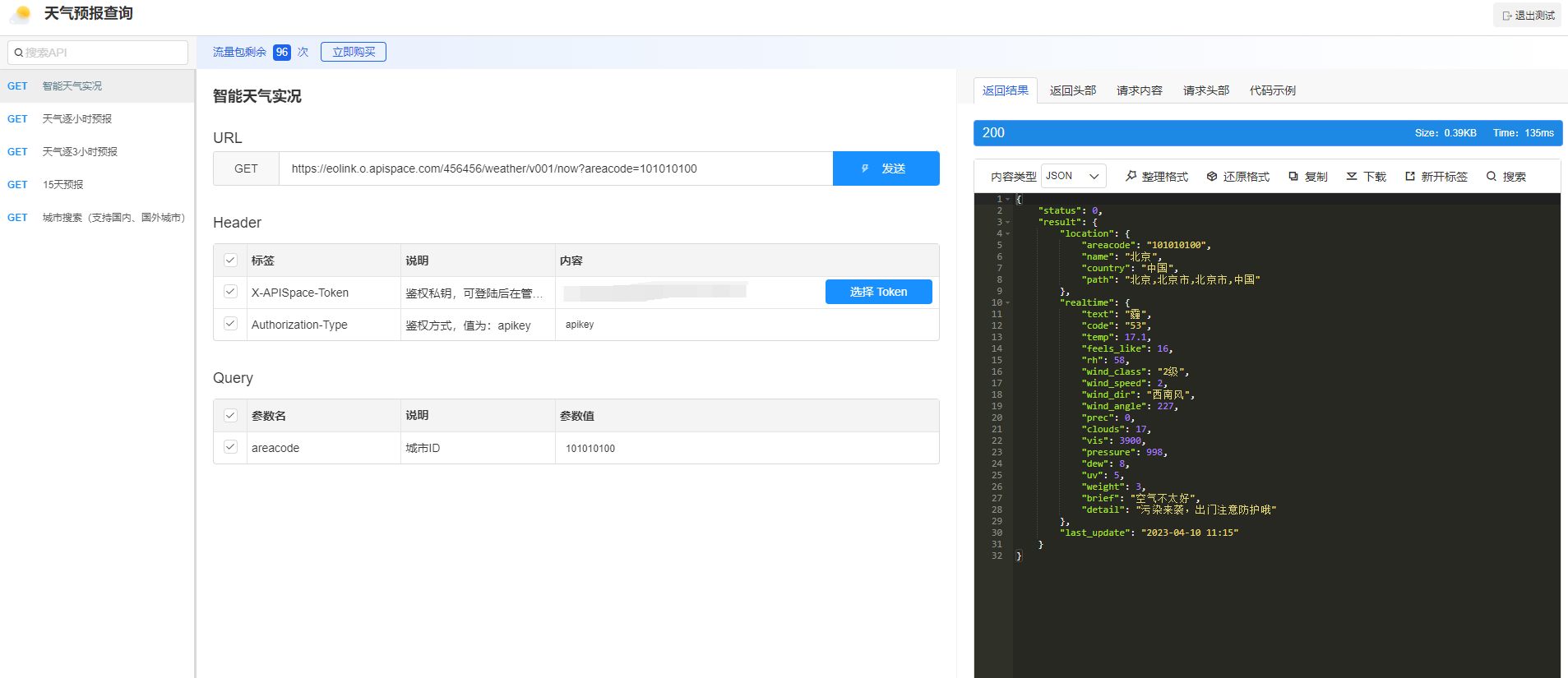
天气预报查询 API + AI 等于王炸(一大波你未曾设想的天气预报查询 API 应用场景更新了)
前言 近年来,随着信息化进程的不断深入,人们对于信息的获取和处理需求越来越高。而其中,天气查询API是一个非常重要的服务,它能够帮助人们快速获取所在位置的天气情况,同时也为各类应用提供了必要的气象数据支持。 本…...

跨境电商的行业现状与发展趋势分析
随着互联网的不断发展,跨境电商作为一种全新的商业模式已经逐渐崭露头角。跨境电商的出现,让越来越多的商家看到了扩大市场的机会,也为消费者提供了更加便利、更加优质的购物体验。本文将从跨境电商的定义、行业现状、发展趋势等方面进行探讨…...

适配器设计模式
目录 前言: 适配器原理与实现 适配器模式的应用场景 1.封装有缺陷的接口 2.统一多个类的接口设计 3.替换依赖的外部系统 4.兼容老版本接口 5.适配不同格式的数据 代理、桥接、装饰器、适配器 4 种设计模式的区别 参考资料 前言: 适配器模式这个模…...

代码随想录算法训练营第三十五天-贪心算法4| ● 860.柠檬水找零 ● 406.根据身高重建队列 ● 452. 用最少数量的箭引爆气球
860.柠檬水找零 参考视频:贪心算法,看上去复杂,其实逻辑都是固定的!LeetCode:860.柠檬水找零_哔哩哔哩_bilibili 解题思路: 只需要维护三种金额的数量,5,10和20。 有如下三种情…...

2023MathorcupC题电商物流网络包裹应急调运与结构优化问题建模详解+模型代码(一)
电商物流网络包裹应急调运与结构优化问题 第三次继续写数模文章和思路代码了,不知道上次美赛和国赛大家有没有认识我,没关系今年只要有数模比赛艾特我私信我,要是我有时间我一定免费出文章代码好吧!博主参与过十余次数学建模大赛…...
)
软件测试技术之跨平台的移动端UI自动化测试(上)
摘要:本文提出一种跨平台的UI自动化测试方案,一方面使用像素级的截图对比技术,解决传统UI自动化测试难以验证页面样式的问题;另一方面用统一部署在服务器端的JavaScript测试代码代替Android和iOS测试代码,大大提高编写…...

【MySQL--02】库的操作
文章目录1.库的操作1.1创建数据库1.2创建数据库的案例1.3字符集和校验规则1.3.1查看系统默认字符集以及校验规则1.3.2查看数据库支持的字符集1.3.3查看数据库支持的字符集校验规则1.3.4 校验规则对数据库的影响1.4操纵数据库1.4.1查看数据库1.4.2 删除数据库1.4.3显示创建语句1…...

人民链Baas服务平台上线,中创助力人民数据共建数据服务应用场景
人民链2.0是数据要素大发展时代下的可信联盟链 作为区块链分布式存储领域行业先驱与让人民放心的国家级数据云平台,中创算力与人民数据的合作从未间断。为了推动人民链2.0高质量发展,中创算力与人民数据开展了多方面合作,助力人民数据共建数据…...

说说如何借助webpack来优化前端性能?
通过webpack优化前端的手段有: ① JS代码压缩 ② CSS代码压缩 ③ HTML文件代码压缩 ④ 文件大小压缩 ⑤ 图片压缩 ⑥ Tree Shaking ⑦ 代码分离 ⑧ 内联 chunk 1、JS代码压缩 terser是一个JavaScript的解释、绞肉机、压…...

AiDD AI+软件研发数字峰会开启编程新纪元
随着OpenAI 推出全新的对话式通用人工智能工具——ChatGPT火爆出圈后,人工智能再次受到了工业界、学术界的广泛关注,并被认为向通用人工智能迈出了坚实的一步,在众多行业、领域有着广泛的应用潜力,甚至会颠覆很多领域和行业&#…...

探索下一代命令行界面:OpenCLI 架构设计与插件化实践
1. 项目概述:一个面向未来的命令行界面原型最近在开源社区里,我注意到一个名为sys-fairy-eve/nightly-mvp-2026-03-19-opencli的项目。这个标题信息量不小,它不像一个成熟的产品,更像是一个开发过程中的里程碑快照。sys-fairy-eve…...

从零构建专属大语言模型:Self-LLM开源项目全流程实践指南
1. 项目概述与核心价值最近在开源社区里,一个名为datawhalechina/self-llm的项目引起了我的注意。乍一看,这像是一个关于大语言模型(LLM)的仓库,但“self”这个前缀又让人浮想联翩。经过一段时间的深入研究和实践&…...

MCP服务器自动发现与管理工具mcpfinder详解
1. 项目概述:一个用于发现与管理MCP服务器的工具如果你正在构建或使用基于模型上下文协议(Model Context Protocol, 简称MCP)的应用,那么你很可能遇到过这样的困扰:手头有几个不同功能的MCP服务器ÿ…...

基于Arduino与加速度传感器的可穿戴智能徽章制作全解析
1. 项目概述:一个会“走路”的智能徽章几年前,当《Pokemon Go》风靡全球时,我注意到一个有趣的现象:深夜的公园里,总有一群玩家低头盯着手机屏幕,在昏暗的光线下穿梭。这固然是游戏的乐趣,但也带…...

AI赋能安全分析:hexstrike-ai项目实战与提示词工程详解
1. 项目概述:一个为安全研究而生的AI助手如果你是一名安全研究员、逆向工程师或者渗透测试人员,那么你肯定对“工具链”这个词深有体会。我们的工作台就像是一个复杂的车间,摆满了IDA Pro、Ghidra、x64dbg、Burp Suite、Wireshark……这些工具…...

2026 私域救命玩法!90% 的老板赚不到钱,根本不是产品不行
我在杭州做电商、做私域、做投资这么多年,见过各行各业的起起伏伏。这些年接触过的实体老板,没有一百也有八十。手里握着工厂的、拿着自主知识产权的、有正规生产资质的,比比皆是。但 90% 的人都在亏钱。他们天天抱怨流量太贵、同行乱价、客户…...

DIY LED眼妆:从电路原理到穿戴制作的完整指南
1. 项目概述:打造你的专属发光眼妆想为下一次Cosplay活动或万圣节派对增添一抹赛博朋克般的未来感吗?厌倦了千篇一律的商店货,渴望一件真正独一无二、能让你在人群中脱颖而出的发光装饰?这个DIY LED眼妆项目,正是为你准…...
)
PyTorch实战:手把手教你实现DCNv2可变形卷积(附完整代码与避坑指南)
PyTorch实战:手把手教你实现DCNv2可变形卷积(附完整代码与避坑指南) 当你在处理计算机视觉任务时,是否遇到过这样的困扰:传统卷积神经网络对物体几何变换的适应性有限,导致模型在复杂场景下的表现不尽如人意…...

gifuct-js:高性能JavaScript GIF解码器的架构设计与性能优化策略
gifuct-js:高性能JavaScript GIF解码器的架构设计与性能优化策略 【免费下载链接】gifuct-js Fastest javascript .GIF decoder/parser 项目地址: https://gitcode.com/gh_mirrors/gi/gifuct-js gifuct-js是一个专注于高效GIF文件解析与解码的JavaScript库&a…...
)
【负荷预测】基于LSTM-KAN的负荷预测研究(Python代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...