Greenplum数据库执行器——PartitionSelector执行节点
为了能够对分区表有优异的处理能力,对于查询优化系统来说一个最基本的能力就是做分区裁剪partition pruning,将query中并不涉及的分区提前排除掉。如下执行计划所示,由于单表谓词在parititon key上,在优化期间即可确定哪些可以分区可以避免访问,即静态pruning。
explain select * from test where collecttime > '2023-02-22 00:00:00' and collecttime < '2023-02-28 00:00:00';QUERY PLAN
-------------------------------------------------------------------------------------------------------------
Gather Motion 12:1 (slice1; segments: 12) (cost=0.00..431.18 rows=39 width=1626)-> Sequence (cost=0.00..431.02 rows=4 width=1626)-> Partition Selector for test (dynamic scan id: 1) (cost=10.00...100.00 rows=9 width=4)Partition selected: 6 (out of 33)-> Dynamic Seq Scan on test (dynamic scan id: 1) (cost=0.00...431.02 rows=4 width=1626)Filter: ((collecttime > '2023-02-22 00:00:00'::timestamp without time zone) AND (collecttime < '2023-02-28 00:00:00'::timestamp without time zone))
Optimizer: Pivotal Optimizer (GPORCA) explain select * from test where collecttime > '2023-02-22 00:00:00' and collecttime < '2023-02-28 00:00:00'; QUERY PLAN
-------------------------------------------------------------------------------------------------------------
Gather Motion 12:1 (slice1; segments: 12) (cost=0.00..431.18 rows=6 width=3748)-> Append (cost=0.00...0.00 rows=1 width=3748)-> Seq Scan on test_1_prt_p20230222_1 (cost=0.00..0.00 rows=1 width=3748)Filter: ((collecttime > '2023-02-22 00:00:00'::timestamp without time zone) AND (collecttime < '2023-02-28 00:00:00'::timestamp without time zone))...-> Seq Scan on test_1_prt_p20230227_1 (cost=0.00..0.00 rows=1 width=3748)Filter: ((collecttime > '2023-02-22 00:00:00'::timestamp without time zone) AND (collecttime < '2023-02-28 00:00:00'::timestamp without time zone))
Optimizer: Postgres query optimizer
如下语句date_id的值将需要根据date_dim表的动态输出决定,因此对orders表的partition pruning只能在执行期完成,类似的例子还有动态绑定变量,称为动态pruning。
SELECT avg(amount) FROM ordersWHERE date_id IN (SELECT date_id FROM date_dim WHERE year = 2013 AND month BETWEEN 10 AND 12);
引入了3个新的算子来做pruning(PartitionSelector、DynamicScan、Sequence):Sequence用于描述PartitionSelector->DynamicScan的生产消费关系,确定谁先执行;PartitionSelector根据谓词生成相关partition ids,主要实现了做partition选择的功能,并将筛选后的ids传递给DynamicScan;DynamicSeqScan物理scan算子,基于PartitionSelector传递的ids,在做table scan时跳过不需要的partition。上一节已经描述过DynamicScan的执行流程了,该节主要介绍Partition Selector。
Partition Selector
Partition Selector用于计算和传播(Compute and propagate)使用Dynamic table scan的分区表oid。执行PartitionSelector有两种途径:Constant partition elimination和Join partition elimination,如下图:
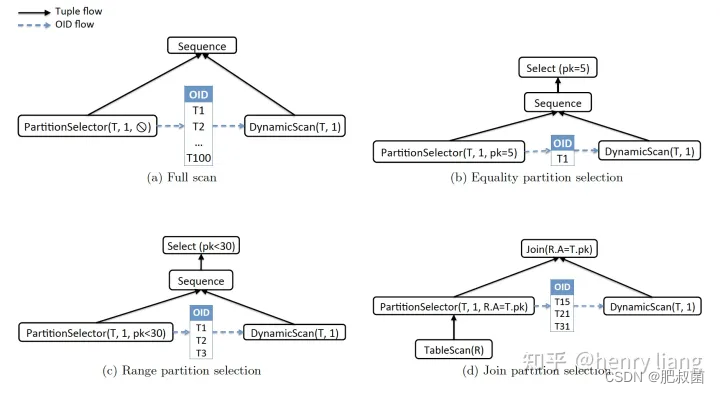
(a) 表示做full table scan,这时是没有filter的,PartitionSelector直接生成全量partition T1 -> T100给DynamicScan。
(b/c) 表示在partition key(PK)上有单表条件(PK=5/PK<30),这时可以只选出目标分区给DynamicScan。
(d) 表示了两表 R join T on R.A = T.PK,由于T表是partition table,其scan算子是DynamicScan。这里有所不同的是,对T的过滤需要基于R.A列的值,因此PartitionSelector要加在R的scan上方,用来获取R.A列的value用于过滤分区,并传递给右侧T的DynamicScan。另外可以看到这里不再有Sequence算子了,由于这里Join算子已经保障了R和T执行的先后顺序(先R后T),也就保证了PartitionSelector->DynamicScan的顺序,Sequence不再必要。
Constant partition elimination
PartitionSelector评估常量分区约束(constant partition constraints)来计算和传播(Compute and propagate)分区表oid。It only need to be called once.
1. Constant partition eliminationPlan structure:Sequence # 是一个同步的概念,用于描述PartitionSelector->DynamicScan的生产消费关系,确定谁先执行|--PartitionSelector # PartitionSelector根据谓词生成相关partition ids,主要实现了做partition选择的功能,并将筛选后的ids传递给DynamicScan|--DynamicSeqScan # 物理scan算子,基于PartitionSelector传递的ids,在做table scan时跳过不需要的partition
Join partition elimination
PartitionSelector与DynamicSeqScan、DynamicIndexScan或DynamicBitmapHeapScan位于同一切片slice中。它是为来自其子节点的每个元组执行的。它使用输入元组评估分区约束,并传播匹配的分区表Oids。
2. Join partition eliminationPlan structure:...:|--DynamicSeqScan|--...|--PartitionSelector|--...
可以有其他节点使用PartSelected qual来过滤行,而不是动态表扫描,根据选择的分区来过滤行。目前,ORCA使用动态表扫描,而非ORCA计划器生成的计划可以使用具有PartSelected quals的门控Result节点来排除不需要的分区。Instead of a Dynamic Table Scan, there can be other nodes that use a PartSelected qual to filter rows, based on which partitions are selected. Currently, ORCA uses Dynamic Table Scans, while plans produced by the non-ORCA planner use gating Result nodes with PartSelected quals, to exclude unwanted partitions.
src/backend/gpopt/translate/CTranslatorDXLToPlStmt.cpp文件中的Plan *CTranslatorDXLToPlStmt::TranslateDXLPartSelector(const CDXLNode *partition_selector_dxlnode, CDXLTranslateContext *output_context, CDXLTranslationContextArray *ctxt_translation_prev_siblings)函数将DXL PartitionSelector转化为GPDB PartitionSelector节点。
src/backend/optimizer/plan/planpartition.c文件中的Plan *create_partition_selector_plan(PlannerInfo *root, PartitionSelectorPath *best_path)函数从PartitionSelectorPath结构体创建一个PartitionSelector plan。
ExecInitPartitionSelector
首先介绍PartitionSelector node,其通过给定的root表OID找到叶子子分区表的集合和可选选择谓词。它隐藏了分区选择和传播的逻辑,而不是用它来污染计划,使计划看起来一致且易于理解。很容易找到分区选择在计划中发生的位置。(It hides the logic of partition selection and propagation instead of polluting the plan with it to make a plan look consistent and easy to understand. It will be easy to locate where partition selection happens in a plan.)
PartitionSelection可以以如下三种方式运行,A PartitionSelection can work in three different ways:
- Dynamic selection, based on tuples that pass through it.
- Dynamic selection, with a projected tuple.
- Static selection, performed at beginning of execution.
PartitionSelector结构体除了包含DynamicScan算子唯一编号和PartitionSelector算子唯一编号、root表oid和该分区表的层级外。还包含了如上三种运行方式的变量。比如对于Dynamic selection, based on tuples that pass through it来说,levelExpressions就是保存了每个分区层级使用的谓词表达式、levelEqExpressions就是保存了每个分区层级使用的等值表达式、最后应用的剩余谓词residualPredicate、传播表达式propagationExpression。对于Dynamic selection, with a projected tuple,partTabTargetlist是用于动态选择的字段,通过将输入元组投影到具有与分区表中相同位置的分区键值的元组。对于Static selection, performed at beginning of execution,staticPartOids是静态选择的分区子表oid和staticScanIds用于传播静态选择的分区子表oid的扫描id。
typedef struct PartitionSelector{Plan plan;Oid relid; /* OID of target relation */int nLevels; /* number of partition levels */int32 scanId; /* id of the corresponding dynamic scan */ // 每个DynamicScan算子有其唯一编号int32 selectorId; /* id of this partition selector */ // 每个PartitionSelector算子有其唯一编号/* Fields for dynamic selection */List *levelEqExpressions; /* list of list of equality expressions used for individual levels */List *levelExpressions; /* predicates used for individual levels */Node *residualPredicate; /* residual predicate (to be applied at the end) */Node *propagationExpression; /* propagation expression */Node *printablePredicate; /* printable predicate (for explain purposes) *//* Fields for dynamic selection, by projecting input tuples to a tuple that has the partitioning key values in the same positions as in the partitioned table. */List *partTabTargetlist;/* Fields for static selection */bool staticSelection; /* static selection performed? */List *staticPartOids; /* list of statically selected parts */List *staticScanIds; /* scan ids used to propagate statically selected part oids */
} PartitionSelector;
ExecInitPartitionSelector函数为Orca生成的PartitionSelector节点创建运行时状态信息,并初始化外部子节点(如果存在)。Create the run-time state information for PartitionSelector node produced by Orca and initializes outer child if exists. 其主要执行的步骤如下:
- 调用initPartitonSelection创建PartitionSelectorState,其levelPartRules中的每个元素都是每层子分区的PartitionRule信息(我们知道分区表除了root表之外的inheritor和leaf分区在pg_partition_rule中都有一个条目,其信息就是PartitionRule);为levelEqExpressions、levelExpressions、residualPredicate、propagationExpression初始化表达式执行ExprState列表。
- 对于ParitionSelector来说,其没有Inner plan也就是没有右子树,这里仅仅需要调用ExecInitNode初始化psstate->lefttree即可,也就是Join partition elimination这种情况。
- 如果PartitionSeletor.partTabTargetlist不为NIL,partTabTargetlist是用于动态选择的字段,通过将输入元组投影到具有与分区表中相同位置的分区键值的元组。初始化投影,以生成一个元组,该元组的分区键列位于与分区表中相同的位置。
PartitionSelectorState *ExecInitPartitionSelector(PartitionSelector *node, EState *estate, int eflags){PartitionSelectorState *psstate = initPartitionSelection(node, estate); ExecInitResultTupleSlot(estate, &psstate->ps); /* tuple table initialization */ExecAssignResultTypeFromTL(&psstate->ps);ExecAssignProjectionInfo(&psstate->ps, NULL);/* initialize child nodes */if (NULL != outerPlan(node)){ outerPlanState(psstate) = ExecInitNode(outerPlan(node), estate, eflags); }/* Initialize projection, to produce a tuple that has the partitioning key columns at the same positions as in the partitioned table. */if (node->partTabTargetlist){ // partition key target listList *exprStates = (List *) ExecInitExpr((Expr *) node->partTabTargetlist, (PlanState *) psstate);psstate->partTabDesc = ExecTypeFromTL(node->partTabTargetlist, false);psstate->partTabSlot = MakeSingleTupleTableSlot(psstate->partTabDesc);psstate->partTabProj = ExecBuildProjectionInfo(exprStates, psstate->ps.ps_ExprContext, psstate->partTabSlot, ExecGetResultType(&psstate->ps));}return psstate;
}

ExecPartitionSelector
从root表获取PartitionNode和access method。首先看一下DynamicTableScanInfo的List *partsMetadata,其存放了所有相关分区表的分区元数据。getPartitionNodeAndAccessMethod从root表获取PartitionNode和accessMethod,其实就是调用findPartitionMetadataEntry函数,该函数从partsMetadata列表中查找到相应partition oid的PartitionMetadata对象(输入参数为partsMetadata: list of PartitionMetadata、partOid: Part Oid;输出参数为partsAndRules: output parameter for matched PartitionNode;accessMethods: output parameter for PartitionAccessMethods)。PartitionMetadata结构体其实就包含了PartitionNode *partsAndRules和PartitionAccessMethods *accessMethods两个成员
if (NULL == node->rootPartitionNode){getPartitionNodeAndAccessMethod(ps->relid,estate->dynamicTableScanInfo->partsMetadata,estate->es_query_cxt,&node->rootPartitionNode,&node->accessMethods);
}
/* ----------------------------------------------------------------* getPartitionNodeAndAccessMethod Retrieve PartitionNode and access method from root table* ---------------------------------------------------------------- */
void getPartitionNodeAndAccessMethod(Oid rootOid, List *partsMetadata, MemoryContext memoryContext, PartitionNode **partsAndRules, PartitionAccessMethods **accessMethods){findPartitionMetadataEntry(partsMetadata, rootOid, partsAndRules, accessMethods);(*accessMethods)->part_cxt = memoryContext;
}
void findPartitionMetadataEntry(List *partsMetadata, Oid partOid, PartitionNode **partsAndRules, PartitionAccessMethods **accessMethods){ListCell *lc = NULL;foreach(lc, partsMetadata){PartitionMetadata *metadata = (PartitionMetadata *) lfirst(lc);*partsAndRules = findPartitionNodeEntry(metadata->partsAndRules, partOid);if (NULL != *partsAndRules){/* accessMethods define the lookup access methods for partitions, one for each level */*accessMethods = metadata->accessMethods;return;}}
}
描述findPartitionNodeEntry函数之前,需要了解一下pg_partition和pg_partition_rule系统表,每个分区父表(root table和intermediate table)在其中都有一个条目,且该条目有标识自己的oid,也就是Partition结构体中的partid;而parrelid字段就是该表的oid;parkind指明分区类型list或range;level是分区树的层级。PartitionRule结构体则代表pg_partition_rule系统表中的条目,除了root table,intermediate table和leaf table都应该有对应的条目,同样每个条目都有标识自己的oid(parruleid),paroid则代表该分区表的oid,通过parparentrule可以关联父表的rule条目,从而组成自下而上的父子链。
struct PartitionNode{NodeTag type;Partition *part; List *rules; /* rules for this level */ struct PartitionRule *default_part;
};
typedef struct Partition{NodeTag type;Oid partid; /* OID of row in pg_partition. */Oid parrelid; /* OID in pg_class of top-level partitioned relation */char parkind; /* 'r', 'l', or (unsupported) 'h' */int16 parlevel; /* depth below parent partitioned table */bool paristemplate; /* just a template, or really a part? */int16 parnatts; /* number of partitioning attributes */AttrNumber *paratts;/* attribute number vector */ Oid *parclass; /* operator class vector */
} Partition;
typedef struct PartitionRule{NodeTag type;Oid parruleid; Oid paroid; Oid parchildrelid; Oid parparentrule;bool parisdefault; char *parname; Node *parrangestart; bool parrangestartincl;Node *parrangeend; bool parrangeendincl; Node *parrangeevery; List *parlistvalues;int16 parruleord; List *parreloptions; Oid partemplatespaceId; /* the tablespace id for the template (or InvalidOid for non-template rules */struct PartitionNode *children; /* sub partition */
} PartitionRule;
findPartitionNodeEntry函数用于通过给定分区表oid查找到PartitonNode,如果partitionNode代表的是给定partOid,则返回该partitonNode;如果不是,有可能partOid是PartitionNode的子分区,通过递归子分区,获取到以partOid对应的PartitionNode并返回。
static PartitionNode *findPartitionNodeEntry(PartitionNode *partitionNode, Oid partOid){if (NULL == partitionNode){ return NULL; }if (partitionNode->part->parrelid == partOid){ return partitionNode; } ListCell *lcChild = NULL; /* check recursively in child parts in case we have the oid of an intermediate node */foreach(lcChild, partitionNode->rules){PartitionRule *childRule = (PartitionRule *) lfirst(lcChild);PartitionNode *childNode = findPartitionNodeEntry(childRule->children, partOid);if (NULL != childNode){ return childNode; }} if (NULL != partitionNode->default_part){ /* check recursively in the default part, if any */childNode = findPartitionNodeEntry(partitionNode->default_part->children, partOid);}return childNode;
}
Static selection
如果PartitionSelector.staticSelection为true,需要执行Static selection, performed at beginning of execution。staticPartOids是静态选择的分区子表oid和staticScanIds用于传播静态选择的分区子表oid的扫描id。
TupleTableSlot *ExecPartitionSelector(PartitionSelectorState *node){PartitionSelector *ps = (PartitionSelector *) node->ps.plan; EState *estate = node->ps.state;if (ps->staticSelection){/* propagate the part oids obtained via static partition selection */partition_propagation(estate, ps->staticPartOids, ps->staticScanIds, ps->selectorId);return NULL;}
首先学习一下InsertPidIntoDynamicTableScanInfo函数用于将分区oid插入dynamicTableScanInfo的pidIndexes[scanId],如果partOid分区oid为非法oid,该函数将不会插入该oid,但是会确保dynamicTableScanInfo的pidIndexes[scanId]的HTAB(该HTAB的key为partition table oid,entry为partition table oid和selectorId列表的组合)存在。从DynamicSeqScan的逻辑可知,需要扫描的分区oid就存在于dynamicTableScanInfo的pidIndexes[scanId]中。partition_propagation函数就是将该selector为不同DynamicScan裁剪的分区oid放入dynamicTableScanInfo->pidIndexes缓冲中,供DynamicScan扫描。
static void partition_propagation(EState *estate, List *partOids, List *scanIds, int32 selectorId){ListCell *lcOid = NULL; ListCell *lcScanId = NULL;forboth (lcOid, partOids, lcScanId, scanIds) {Oid partOid = lfirst_oid(lcOid); int scanId = lfirst_int(lcScanId);InsertPidIntoDynamicTableScanInfo(estate, scanId, partOid, selectorId);}
}
void InsertPidIntoDynamicTableScanInfo(EState *estate, int32 index, Oid partOid, int32 selectorId){DynamicTableScanInfo *dynamicTableScanInfo = estate->dynamicTableScanInfo;MemoryContext oldCxt = MemoryContextSwitchTo(estate->es_query_cxt);if (index > dynamicTableScanInfo->numScans){ increaseScanArraySize(estate, index); } // 对array扩容if ((dynamicTableScanInfo->pidIndexes)[index - 1] == NULL){ dynamicTableScanInfo->pidIndexes[index - 1] = createPidIndex(estate, index); } // 为该index创建HTABif (partOid != InvalidOid){bool found = false;PartOidEntry *hashEntry = hash_search(dynamicTableScanInfo->pidIndexes[index - 1], &partOid, HASH_ENTER, &found);if (found){hashEntry->selectorList = list_append_unique_int(hashEntry->selectorList, selectorId);}else{hashEntry->partOid = partOid; hashEntry->selectorList = list_make1_int(selectorId);}}MemoryContextSwitchTo(oldCxt);
}
Dynamic selection
如果NULL != outerPlanState(node),则需要处理Join partition elimination。调用ExecProcNode(outerPlan)执行partitionselector的左子树的执行计划。如果inputSlot为null,其实就是说明outerPlan没有匹配的tuple了,也就是说明不需要继续判定哪些分区需要扫描了。
PlanState *outerPlan = outerPlanState(node);TupleTableSlot *inputSlot = ExecProcNode(outerPlan);if (TupIsNull(inputSlot)){ /* no more tuples from outerPlan *//* Make sure we have an entry for this scan id in dynamicTableScanInfo. Normally, this would've been done the first time a partition is selected, but we must ensure that there is an entry even if no partitions were selected. (The traditional Postgres planner uses this method.) */if (ps->partTabTargetlist) InsertPidIntoDynamicTableScanInfo(estate, ps->scanId, InvalidOid, ps->selectorId);else LogPartitionSelection(estate, ps->selectorId);return NULL;}
如果有partitioning投影(Dynamic selection, with a projected tuple),将输入tuple投影成看上去来自partitioned table的tuple,然后使用selectPartitionMulti函数选择分区。(Postgres planner使用这种方式)
ListCell *lc;TupleTableSlot *slot = ExecProject(node->partTabProj, NULL); slot_getallattrs(slot);List *oids = selectPartitionMulti(node->rootPartitionNode,slot_get_values(slot),slot_get_isnull(slot),slot->tts_tupleDescriptor,node->accessMethods);foreach (lc, oids){InsertPidIntoDynamicTableScanInfo(estate, ps->scanId, lfirst_oid(lc), ps->selectorId);}list_free(oids);
selectPartitionMulti函数通过提供的partition node、tuple values nullness和partition state,找到匹配的叶子分区。该函数和selectPartition相似,但是对于nulls的处理不同。该函数的处理方式是,如果有partitioning key的值为null,则所有子分区都被认为是匹配的;如果没有partitioning key的值为null,调用selectPartition1获取对应partitioning key值下的子分区。The input values/isnull should match the layout of tuples in the partitioned table.
List *selectPartitionMulti(PartitionNode *partnode, Datum *values, bool *isnull, TupleDesc tupdesc, PartitionAccessMethods *accessMethods){List *leafPartitionOids = NIL;List *inputList = list_make1(partnode);while (list_length(inputList) > 0){ // 按层处理,这里的InputList是每层分区表的PartitionNode列表List *levelOutput = NIL; ListCell *lc = NULL; foreach(lc, inputList){ // 遍历所有PartitionNodePartitionNode *candidatePartNode = (PartitionNode *) lfirst(lc);bool foundNull = false;for (int i = 0; i < candidatePartNode->part->parnatts; i++){ // 遍历该partition node的所有分区键AttrNumber attno = candidatePartNode->part->paratts[i]; if (isnull[attno - 1]){ /* If corresponding value is null, then we should pick all of its children (or itself if it is a leaf partition) */foundNull = true;if (IsLeafPartitionNode(candidatePartNode)){ /* Extract out Oids of all children */leafPartitionOids = list_concat(leafPartitionOids, all_partition_relids(candidatePartNode));}else {levelOutput = list_concat(levelOutput, PartitionChildren(candidatePartNode));}}}/* If null was not found on the attribute, and if this is a leaf partition, then there will be an exact match. If it is not a leaf partition, then we have to find the right child to investigate. */if (!foundNull) {if (IsLeafPartitionNode(candidatePartNode)){Oid matchOid = selectPartition1(candidatePartNode, values, isnull, tupdesc, accessMethods, NULL, NULL);if (matchOid != InvalidOid){ leafPartitionOids = lappend_oid(leafPartitionOids, matchOid); }}else{PartitionNode *childPartitionNode = NULL;selectPartition1(candidatePartNode, values, isnull, tupdesc, accessMethods, NULL, &childPartitionNode);if (childPartitionNode){ levelOutput = lappend(levelOutput, childPartitionNode); }}}}list_free(inputList); inputList = levelOutput; /* Start new level */}return leafPartitionOids;
}
如果没有partitioning投影,则利用levelEqExpressions和levelExpressions来选择分区。(ORCA使用这种方式)
typedef struct SelectedParts{ /* SelectedParts node: This is the result of partition selection. It has a list of leaf part oids and the corresponding ScanIds to which they should be propagated */List *partOids;List *scanIds;
} SelectedParts;SelectedParts *selparts = processLevel(node, 0 /* level */, inputSlot); if (NULL != ps->propagationExpression){ /* partition propagation */partition_propagation(estate, selparts->partOids, selparts->scanIds, ps->selectorId);}list_free(selparts->partOids); list_free(selparts->scanIds); pfree(selparts);
processLevel函数返回符合predicates处于指定分区层级的分区表oid。如果处理intermediate层级,存储符合要求的分区oid,继续下一个层级分区;如果处于叶子层级,获取满足要求的分区oid。其执行流程如下所示:
- 首先获取指定层级的谓词表达式equalityPredicate和generalPredicate,定位到root PartitionNode,如果level为0,则parentNode为node->rootPartitionNode;否则为node->levelPartRules[level - 1]->children。
- 调用partition_rules_for_equality_predicate和partition_rules_for_general_predicate获取匹配equalityPredicate和generalPredicate谓词的PartitionRule列表。如果没有上述谓词,则需要把下一个层级的PartitionRule全部返回。
- 遍历satisfied PartitionRules,如果当前层级为叶子层级,调用eval_part_qual函数处理residual predicate,调用eval_propagation_expression函数propagationExpression获取scanId,将partoid和scanId设置到selparts;否则需要递归调用
processLevel(node, level + 1, inputTuple)到next level’s partition elimination
SelectedParts *processLevel(PartitionSelectorState *node, int level, TupleTableSlot *inputTuple){SelectedParts *selparts = makeNode(SelectedParts); selparts->partOids = NIL; selparts->scanIds = NIL;PartitionSelector *ps = (PartitionSelector *) node->ps.plan;/* get equality and general predicate for the current level */ // 获取指定层级的谓词表达式List *equalityPredicate = (List *) lfirst(list_nth_cell(ps->levelEqExpressions, level));Expr *generalPredicate = (Expr *) lfirst(list_nth_cell(ps->levelExpressions, level));/* get parent PartitionNode if in level 0, it's the root PartitionNode */PartitionNode *parentNode = node->rootPartitionNode;if (0 != level){parentNode = node->levelPartRules[level - 1]->children;}/* list of PartitionRule that satisfied the predicates */List *satisfiedRules = NIL; if (NULL != equalityPredicate){ /* If equalityPredicate exists */List *chosenRules = partition_rules_for_equality_predicate(node, level, inputTuple, parentNode);satisfiedRules = list_concat(satisfiedRules, chosenRules);}else if (NULL != generalPredicate) /* If generalPredicate exists */{List *chosenRules = partition_rules_for_general_predicate(node, level, inputTuple, parentNode);satisfiedRules = list_concat(satisfiedRules, chosenRules);}else { /* None of the predicate exists *//** Neither equality predicate nor general predicate exists. Return all the next level PartitionRule.* WARNING: Do NOT use list_concat with satisfiedRules and parentNode->rules. list_concat will destructively modify satisfiedRules to point to parentNode->rules, which will then be freed when we free satisfiedRules. This does not apply when we execute partition_rules_for_general_predicate as it creates its own list. */ListCell *lc = NULL; foreach(lc, parentNode->rules){PartitionRule *rule = (PartitionRule *) lfirst(lc); satisfiedRules = lappend(satisfiedRules, rule);}if (NULL != parentNode->default_part){satisfiedRules = lappend(satisfiedRules, parentNode->default_part);}}/* Based on the satisfied PartitionRules, go to next level or propagate PartOids if we are in the leaf level */ListCell *lc = NULL;foreach(lc, satisfiedRules){PartitionRule *rule = (PartitionRule *) lfirst(lc);node->levelPartRules[level] = rule; if (level == ps->nLevels - 1){ /* If we already in the leaf level */bool shouldPropagate = true; if (NULL != ps->residualPredicate){ /* if residual predicate exists */ shouldPropagate = eval_part_qual(node->ps.ps_ExprContext, inputTuple, node->residualPredicateExprStateList); /* evaluate residualPredicate */}if (shouldPropagate){if (NULL != ps->propagationExpression){if (!list_member_oid(selparts->partOids, rule->parchildrelid)){selparts->partOids = lappend_oid(selparts->partOids, rule->parchildrelid);int scanId = eval_propagation_expression(node, rule->parchildrelid);selparts->scanIds = lappend_int(selparts->scanIds, scanId);}}}}else{ /* Recursively call this function for next level's partition elimination */SelectedParts *selpartsChild = processLevel(node, level + 1, inputTuple);selparts->partOids = list_concat(selparts->partOids, selpartsChild->partOids);selparts->scanIds = list_concat(selparts->scanIds, selpartsChild->scanIds);pfree(selpartsChild);}}list_free(satisfiedRules); node->levelPartRules[level] = NULL; /* After finish iteration, reset this level's PartitionRule */return selparts;
}

https://zhuanlan.zhihu.com/p/367068030
相关文章:
Greenplum数据库执行器——PartitionSelector执行节点
为了能够对分区表有优异的处理能力,对于查询优化系统来说一个最基本的能力就是做分区裁剪partition pruning,将query中并不涉及的分区提前排除掉。如下执行计划所示,由于单表谓词在parititon key上,在优化期间即可确定哪些可以分区…...

POJ 2311 Cutting Game
POJ 2311 Cutting Game 题目大意 有一张有whw\times hwh个格子的长方形纸张,两个人轮流将当前的纸张中选一张,并沿着格子的边界将这张纸剪成两部分。最先切出只有一个格子的纸张(111\times 111的纸张)的玩家获胜。当双方都采用最…...

CTF-PHP反序列化漏洞1-基础知识
作者:Eason_LYC 悲观者预言失败,十言九中。 乐观者创造奇迹,一次即可。 一个人的价值,在于他所拥有的。可以不学无术,但不能一无所有! 技术领域:WEB安全、网络攻防 关注WEB安全、网络攻防。我的…...
【面试】记一次安恒面试及总结
文章目录SQL 注入sql注入的原理?如何通过SQL注入判断对方数据库类型?补充一下其他方法判断数据库类型时间盲注的函数XPath注入抓不到http/https包,怎么办?app无自己的ssl证书app有自己的ssl证书-证书绑定(SSL pinning)逻辑漏洞有哪…...

刹车制动(卡钳)TOP3供应商份额超50%,哪些本土供应商突围
作为中国本土底盘系统供应商最早切入的细分市场之一,乘用车(液压)刹车制动器(含卡钳)由连接到车轮的制动盘和位于制动盘边缘的卡钳组成。制动时,高压刹车油推动刹车片夹紧刹车盘,从而产生制动效…...
)
Go分布式爬虫笔记(二十二)
文章目录22 辅助任务管理:任务优先级、去重与失败处理设置爬虫最大深度避免请求重复设置优先队列设置随机User-Agent失败处理22 辅助任务管理:任务优先级、去重与失败处理 设置爬虫最大深度 目的: 防止访问陷入到死循环控制爬取的有效链接的数量 最大…...

跨线程修改主界面
winform 方式: public delegate void MyInvoke(string str1); private void check_Click(object sender, RoutedEventArgs e) { //跨现场调度1 delete委托 WIMFORM Task.Run(() > { …...
国内ChatGPt研发-中国chatGPT
人工智能软件chatGPT Chat GPT是一种自然语言处理算法,采用了深度学习技术,用于实现文本生成和自然语言处理任务。它可以实现自然而然的人机交互,在自然语言生成和问答领域应用广泛。 值得注意的是,Chat GPT本身并不是一款具体的…...
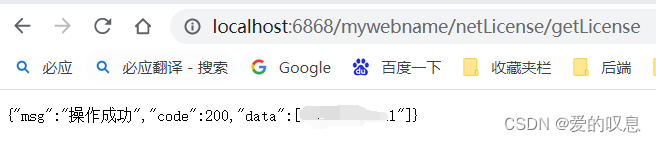
springboot的rest服务配置服务的根路径
如果不配置默认为空,如下是application.yml文件只配置了端口号 server:port: 6868 那么访问时直接访问服务即可 如果配置了rest服务 RestController RequestMapping("/netLicense") public class NetLicenseController {RequestMapping("/getLice…...

MySQL B+Tree 索引优化技巧
文章目录前言一、BTree索引的基本原理二、BTree索引的性能优化技巧1.索引列的选择2.索引列的顺序3.索引长度4.索引的覆盖性5. 索引的唯一性总结前言 MySQL是一种开源关系型数据库管理系统,被广泛应用于各种应用程序中。作为一种关系型数据库,MySQL使用B…...

100种思维模型之逆向思维模型-46
芒格思考问题总是从逆向开始!正如他经常提到的一句谚语:如果我能够知道我将死在哪里,那么我将永远不去那个地方。 马云有句口头禅:倒立看世界,一切皆有可能! 遇到难题时,不妨回头看看࿰…...

C/C++每日一练(20230413)
目录 1. 与浮点数A最接近的分数B/C 🌟 2. 比较版本号 🌟🌟 3. 无重复字符的最长子串 🌟🌟 🌟 每日一练刷题专栏 🌟 Golang每日一练 专栏 Python每日一练 专栏 C/C每日一练 专栏 Java每…...

volatile和synchronized的区别
volatile和synchronized的区别并发编程三个特性:原子性有序性可见性ViolatedSynchronized区别对比并发编程三个特性: 原子性、有序性、可见性 原子性 volatile无法保证原子性。 synchronized是排它锁,被synchronzied修饰的代码不能被打断…...

Cadence Allegro 导出Unplaced Component Report报告详解
⏪《上一篇》 🏡《上级目录》 ⏩《下一篇》 目录 1,概述2,Unplaced Component Report作用3,Unplaced Component Report示例4,Unplaced Component Report导出方法4.1,方法14.2,方法2B站关注“硬小二”浏览更多演示视频...
面试了上百位性能测试后,我发现了一个令人不安的事实...
在企业中负责技术招聘的同学,肯定都有一个苦恼,那就是招一个合适的测试太难了!若要问起招哪种类型的测试最难时,相信很多人都会说出“性能测试”这个答案。 每当发布一个性能测试岗位,不一会就能收到上百份简历&#…...
天气预报查询 API + AI 等于王炸(一大波你未曾设想的天气预报查询 API 应用场景更新了)
前言 近年来,随着信息化进程的不断深入,人们对于信息的获取和处理需求越来越高。而其中,天气查询API是一个非常重要的服务,它能够帮助人们快速获取所在位置的天气情况,同时也为各类应用提供了必要的气象数据支持。 本…...

跨境电商的行业现状与发展趋势分析
随着互联网的不断发展,跨境电商作为一种全新的商业模式已经逐渐崭露头角。跨境电商的出现,让越来越多的商家看到了扩大市场的机会,也为消费者提供了更加便利、更加优质的购物体验。本文将从跨境电商的定义、行业现状、发展趋势等方面进行探讨…...

适配器设计模式
目录 前言: 适配器原理与实现 适配器模式的应用场景 1.封装有缺陷的接口 2.统一多个类的接口设计 3.替换依赖的外部系统 4.兼容老版本接口 5.适配不同格式的数据 代理、桥接、装饰器、适配器 4 种设计模式的区别 参考资料 前言: 适配器模式这个模…...

代码随想录算法训练营第三十五天-贪心算法4| ● 860.柠檬水找零 ● 406.根据身高重建队列 ● 452. 用最少数量的箭引爆气球
860.柠檬水找零 参考视频:贪心算法,看上去复杂,其实逻辑都是固定的!LeetCode:860.柠檬水找零_哔哩哔哩_bilibili 解题思路: 只需要维护三种金额的数量,5,10和20。 有如下三种情…...

2023MathorcupC题电商物流网络包裹应急调运与结构优化问题建模详解+模型代码(一)
电商物流网络包裹应急调运与结构优化问题 第三次继续写数模文章和思路代码了,不知道上次美赛和国赛大家有没有认识我,没关系今年只要有数模比赛艾特我私信我,要是我有时间我一定免费出文章代码好吧!博主参与过十余次数学建模大赛…...

【仿真学习框架】MultiModalWBC 完全指南:从入门到精通的多模态全身控制框架
版本: v1.0 | 日期: 2026-05-15 目标读者: 具身智能研究者、机器人学习工程师、人形机器人开发者 前置知识: 基础强化学习(PPO)、PyTorch、刚体动力学概念 📑 目录 1. 初见 MultiModalWBC:我们到底在解决什么问题? 1.1 人形机器人控制的"碎片化"困境 1.2 多模态…...

Bun用Rust重写核心代码,百万行新增代码直接把GitHub干爆了!
Bun 项目刚刚完成了一次惊人的技术跨越。5月14日,Bun 正式宣布其核心运行时已从 Zig 重写为 Rust——这个版本包含 6755 个 commit,二进制文件体积缩小 3-8 MB,性能测试在各个平台上均达到或超越原有水平。Jarred Sumner(Bun 的创…...
)
藏文语音生成准确率从61.2%跃升至94.8%:ElevenLabs Fine-tuning私有数据集构建全流程(含217小时母语者录音标注规范)
更多请点击: https://intelliparadigm.com 第一章:藏文语音生成技术演进与ElevenLabs适配挑战 藏文作为具有复杂音节结构、声调隐含性及丰富上下文依赖的黏着语系文字,其语音合成长期受限于高质量标注语料稀缺、音素-音节映射不唯一、以及缺…...

Agent 一接分布式缓存就开始数据不一致:从 Cache Coherence 到 Write-Through Guard 的工程实战
一、缓存不一致的生产陷阱 在生产环境中部署 Agent 系统时,一个常见的诡异现象是:Agent 从 Redis 缓存读取的业务状态与数据库实际值不一致,导致后续决策出现偏差。这个问题在缓存 TTL 到期前难以察觉,高并发下却反复出现。⚠️ 某…...

Redis分布式锁进阶第二十二篇拆解
一、本篇前置衔接 第九十二篇我们完成Redisson源码拆解、手写复刻、底层内核穿透,彻底明白分布式锁代码层、脚本层、线程层原理。到此为止,代码、源码、坑点、运维、监控、面试全部讲透。但很多开发最大的困惑依旧存在:不同体量公司为什么锁架…...

PyTorch:torch.nonzero——从稀疏数据到精准索引的实战指南
1. 为什么你需要掌握torch.nonzero? 在处理数据时,我们经常会遇到这样的情况:一个大型张量中只有少数几个值是我们真正关心的。想象一下你在分析一张医学影像,可能只有几个像素点显示异常;或者在自然语言处理中&#x…...

扩展卡尔曼滤波锂电池SOC估算【附代码】
✨ 长期致力于锂离子电池、SOC估算、锂离子电池建模、EKF算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)二阶RC等效电路建模与温度自适应参数修正…...
)
不止于安装:在 Ubuntu 20.04 上为 GAMMA 配置完整的 InSAR 科研环境(含 Python 依赖)
不止于安装:在 Ubuntu 20.04 上为 GAMMA 配置完整的 InSAR 科研环境(含 Python 依赖) 当你在Ubuntu 20.04上成功安装GAMMA后,可能会发现这仅仅是开始。真正的挑战在于构建一个完整、稳定的科研环境,让InSAR数据处理流程…...
)
Word分栏排版进阶:如何实现左右栏独立编辑与中英文对照排版(解决内容错乱问题)
Word分栏排版进阶:左右栏独立编辑与中英文对照排版实战指南 在专业文档制作中,双语对照排版是教师、翻译人员和外语学习者经常遇到的挑战。传统分栏功能虽然简单易用,但当我们需要左边显示英文原文、右边显示对应中文翻译时,直接分…...

ITK-SNAP医学图像分割:从临床需求到精准分析的完整指南
ITK-SNAP医学图像分割:从临床需求到精准分析的完整指南 【免费下载链接】itksnap ITK-SNAP medical image segmentation tool 项目地址: https://gitcode.com/gh_mirrors/it/itksnap 面对复杂的医学影像数据,你是否曾为如何准确提取关键解剖结构而…...