Elasticsearch:配置选项
Elasticsearch 带有大量的设置和配置,甚至可能让专家工程师感到困惑。 尽管它使用约定优于配置范例并且大部分时间使用默认值,但在将应用程序投入生产之前自定义配置是必不可少的。
在这里,我们将介绍属于不同类别的一些属性,并讨论它们的重要性以及如何调整它们。 我们可以调整三个配置文件:
- elasticsearch.yml - 这个配置文件是最常编辑的,我们可以在其中设置集群名称、节点信息、数据和日志路径,以及网络和安全设置。
- log4j2.properties - 让我们设置 Elasticsearch 节点的日志记录级别。
- jvm.options - 这里我们可以设置运行节点的堆内存。
这些文件位于 Elasticsearch 安装的如下目录中:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.6.1
$ tree config/ -L 2
config/
├── certs
│ ├── http.p12
│ ├── http_ca.crt
│ └── transport.p12
├── elasticsearch-plugins.example.yml
├── elasticsearch.keystore
├── elasticsearch.yml
├── jvm.options
├── jvm.options.d
├── log4j2.properties
├── role_mapping.yml
├── roles.yml
├── users
└── users_roles
这些文件由 Elasticsearch 节点从 config 目录中读取,该目录基本上是 Elasticsearch 安装目录下的一个文件夹。 对于二进制(zip 或 tar.gz)安装,此目录默认为 $ES_HOME/config(ES_HOME 变量指向 Elasticsearch 的安装目录)。 如果你使用 Debian 或 RPM 发行版等包管理器进行安装,则情况会有所不同,默认为 /etc/elasticsearch/config。
如果你希望从不同的目录访问你的配置文件,你可以设置并导出一个名为 ES_PATH_CONF 的路径变量,它指向新的配置文件位置。 在接下来的几个小节中,我们将介绍一些需要理解的重要设置,不仅对管理员如此,对开发人员也是如此。
主配置文件
尽管 Elastic 的人们开发了 Elasticsearch 以使用默认值(约定优于配置)运行,但我们在将节点投入生产时不太可能依赖默认值。 我们应该调整属性以设置特定的网络信息、数据或日志路径、安全方面等。 为此,我们可以修改 elasticserch.yml 文件以设置我们正在运行的应用程序所需的大部分属性。
Elasticsearch 将网络属性公开为 network.* 属性。 我们可以使用此属性设置主机名和端口号。 例如,我们可以将 Elasticsearch 的端口号更改为 9900 而不是保留默认端口 9200:http.port :9900。 如果要更改节点内部通信的端口,也可以设置 transport.port。
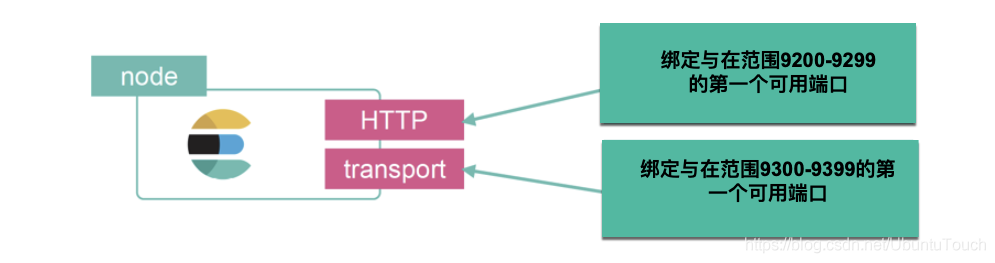
根据你的要求,你可能需要更改许多属性。 如果你想详细了解这些属性,请参阅官方文档:Networking | Elasticsearch Guide [8.6] | Elastic
如果你想设置自己的 Elasticsearch 能被外部访问而不是以 localhost 的方式访问,你可以更改如下的设置:
network.host: 192.168.0.1在上面,我们设置为电脑的私有地址,这样它可以被所在的局域网所访问。我们也可以这样设置:
network.host: 0.0.0.0这样 Elasticsearh 会绑定于所有的 IP 接口上。我们通常可以使用如下的方式来得到所有的 IP:
ifconfig | grep inet$ ifconfig | grep inetinet 127.0.0.1 netmask 0xff000000 inet6 ::1 prefixlen 128 inet6 fe80::1%lo0 prefixlen 64 scopeid 0x1 inet6 fe80::acbc:f2ff:fe5e:d6e9%anpi0 prefixlen 64 scopeid 0x4 inet6 fe80::acbc:f2ff:fe5e:d6eb%anpi2 prefixlen 64 scopeid 0x5 inet6 fe80::acbc:f2ff:fe5e:d6ea%anpi1 prefixlen 64 scopeid 0x6 inet6 fe80::f4d4:88ff:fe6a:c36d%ap1 prefixlen 64 scopeid 0xe inet6 fe80::c6b:334b:459e:a8fb%en0 prefixlen 64 secured scopeid 0xf inet 192.168.0.101 netmask 0xffffff00 broadcast 192.168.0.255inet6 fe80::a082:13ff:fe68:d82f%awdl0 prefixlen 64 scopeid 0x10 inet6 fe80::a082:13ff:fe68:d82f%llw0 prefixlen 64 scopeid 0x11 inet6 fe80::1699:5325:c1de:b41%utun0 prefixlen 64 scopeid 0x12 inet6 fe80::ce81:b1c:bd2c:69e%utun1 prefixlen 64 scopeid 0x13 inet6 fe80::c22c:882d:15c7:d083%utun2 prefixlen 64 scopeid 0x14 inet6 fe80::10cf:86ce:6771:979%en4 prefixlen 64 secured scopeid 0x1a inet 192.168.0.3 netmask 0xffffff00 broadcast 192.168.0.255如上所示,当我们设置 network.host 为 0.0.0.0 时,它绑定于上面所示的 127.0.0.1 及 192.168.0.3 及 192.168.0.101 上。除上面的配置之前,我们也可以使用如下的定义:
| 定义 | 描述 |
|---|---|
| _local_ | 系统上的任何 loopback 地址,例如 127.0.0.1。 |
| _site_ | 系统上的任何站点本地地址,例如 192.168.0.1。这样我们就不用硬编码私有地址 |
| _global_ | 系统上任何全局范围的地址,例如 8.8.8.8。 |
配置文件格式
配置格式为 YAML。 以下是更改数据和日志目录路径的示例:
path:data: /var/lib/elasticsearchlogs: /var/log/elasticsearch设置也可以展平如下:
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch在 YAML 中,你可以将非标量值格式化为序列:
discovery.seed_hosts:- 192.168.1.10:9300- 192.168.1.11- seeds.mydomain.com虽然不太常见,但你也可以将非标量值格式化为数组:
discovery.seed_hosts: ["192.168.1.10:9300", "192.168.1.11", "seeds.mydomain.com"]环境变量替换
配置文件中用 ${...} 表示法引用的环境变量将替换为环境变量的值。 例如:
node.name: ${HOSTNAME}
network.host: ${ES_NETWORK_HOST}环境变量的值必须是简单的字符串。 使用逗号分隔的字符串提供 Elasticsearch 将解析为列表的值。 例如,Elasticsearch 会将以下字符串拆分为 ${HOSTNAME} 环境变量的值列表:
export HOSTNAME="host1,host2"日志记录选项
Elasticsearch 是用 Java 开发的,与大多数 Java 应用程序一样,Elasticsearch 使用 Log4j 2 作为其日志记录库。 一个正在运行的节点将 INFO 级别的日志信息输出到控制台和文件(分别使用 Kibana 控制台和 RollingFile Appenders)。
Log4j 属性文件 (log4j2.properties) 包含一些系统变量(sys:es.logs.base_path、sys:es.logs.cluster_name 等),这些变量在应用程序运行时解析。 因为这些属性由 Elasticsearch 公开,所以它们可供 Log4j 使用,这让 Log4j 可以设置其日志文件目录位置、日志文件模式和其他属性。 例如 sys:es.logs.base_path 指向 Elasticsearch 写入日志的路径,解析为 $ES_HOME/logs 目录。
默认情况下,大部分 Elasticsearch 运行在 INFO 级别,但我们可以根据单个包自定义设置。 例如,我们可以编辑 log4j2.properties 文件并为索引包添加一个记录器,如下面的清单所示。
设置特定包的日志记录级别:
logger.index.name = org.elasticsearch.index
logger.index.level = DEBUG通过这样做,我们允许 index package 在 DEBUG 级别输出日志。 我们可以在集群级别设置 DEBUG 日志级别,而不是在特定节点上编辑此文件并重新启动该节点(如果你在创建群之前没有设法这样做,则可能需要为每个节点执行此操作) 对于这个包。 下一个清单演示了此设置:
全局设置临时日志级别:
PUT _cluster/settings
{"transient": { #A"logger.org.elasticsearch.index":"DEBUG" #B}
}如查询所示,我们在 transient 块中将 index 包的记录器级别属性设置为 DEBUG。 transient block 表示该属性不持久(仅在集群启动并运行时可用)。 如果我们重启集群或者它崩溃了,设置就会丢失,因为它没有永久存储在磁盘上。
我们可以通过调用集群设置 API (_cluster/settings) 来设置此属性,如清单中的代码所示。 设置此属性后,将在 DEBUG 级别输出与 org.elasticsearch.index 源包中的索引相关的任何进一步日志记录信息。
Elasticsearch 也提供了一种持久存储集群属性的方法。 如果我们需要永久存储属性,我们可以使用 persistent 块。 以下清单用持久块替换了 transient 块。
永久设置日志级别:
PUT _cluster/settings
{"persistent": {"logger.org.elasticsearch.index":"DEBUG","logger.org.elasticsearch.http":"TRACE"}
}此代码在 org.elasticsearch.index 包上设置 DEBUG 级别,在 org.elasticsearch.http 包上设置 TRACE 级别。 因为两者都是持久属性,所以记录器会按照包上设置的这些级别写入详细的日志,这些级别也会在集群重新启动后继续存在。
请注意使用 persistent 属性永久设置的此类属性。 我的建议是在故障排除或调试期间启用日志记录级别 DEBUG 或 TRACE。 当你完成生产中的 “救火” 情节时,将其重置回 INFO 以避免将大量请求写入磁盘。
更多阅读,请参考文章 “Elastic:配置 Elasticsearch 服务器 logs”。
JVM 选项
因为 Elasticsearch 使用 Java 编程语言,所以可以在 JVM 级别进行大量优化调整。 出于显而易见的原因,在本文中讨论如此庞大的话题是不够公正的。 但是,如果你很好奇并想了解 JVM 的本质或想在较低级别微调性能,请参阅 Optimizing Java(Ben Evan 和 Jame Gough)或 Java Performance(Scott Oaks)等书籍。 我强烈推荐它们,因为它们不仅提供基础知识,还提供操作提示和技巧。
Elasticsearch 在 /config 目录中提供了一个 jvm.options 文件,其中包含 JVM 设置。 但是,此文件仅供参考(例如,检查节点的内存设置),不得编辑。 根据节点的可用内存,为 Elasticsearch 服务器自动设置堆内存。
警告:在任何情况下我们都不应该编辑 jvm.options 文件。 这样做可能会破坏 Elasticsearch 的内部运作。
如果我们想要升级内存或更改任何 JVM 设置,我们必须创建一个以 .options 作为文件扩展名的新文件,提供适当的调整参数,并将该文件放在 config 下一个名为 jvm.options.d 的目录中以便以存档形式进行安装(tar 或 zip)。 我们可以为我们的自定义文件指定任何名称,但我们需要在其文件名中包含固定的 .options 扩展名。
对于 RPM/Debian 软件包安装,此文件应位于 /etc/elasticsearch/jvm.options.d/ 目录下。 同样,将选项文件挂载在 /usr/share/elasticsearch/config 文件夹下以进行 Docker 安装。
我们可以编辑这个自定义 JVM 选项文件中的设置。 例如,要升级名为 jvm_custom.options 的文件中的堆内存,我们可以使用以下清单中的代码。
升级堆内存:
# Setting the JVM heap memory in jvm_custom.options file
-Xms4g
-Xmx4g_Xms 标志设置初始堆内存,而 _Xmx 调整最大堆内存。 不成文的规则是不要让 _Xms 和 _Xmx 设置超过节点总 RAM 的 50% 以上。 在引擎盖下运行的 Apache Lucene 将内存的后半部分用于其分段、缓存和其他进程。
相关文章:
Elasticsearch:配置选项
Elasticsearch 带有大量的设置和配置,甚至可能让专家工程师感到困惑。 尽管它使用约定优于配置范例并且大部分时间使用默认值,但在将应用程序投入生产之前自定义配置是必不可少的。 在这里,我们将介绍属于不同类别的一些属性,并讨…...
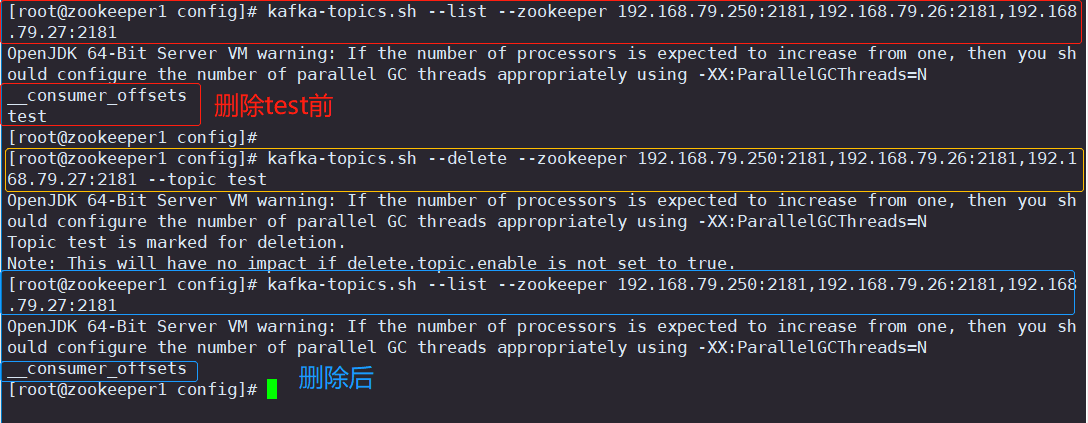
消息中间件Kafka分布式数据处理平台+ZooKeeper
目录 一.消息队列基本介绍 1.为什么需要消息队列(MQ) 2.使用消息队列的好处 2.1 解耦 2.2 可恢复性 2.3 缓冲 2.4 灵活性 & 峰值处理能力 2.5 异步通信 3.消息队列的两种模式 3.1 点对点模式 3.2 发布/订阅模式 二.Kafka基本介绍 1.Kaf…...
Linux 用户文件磁盘网络进程指令
用户相关指令 useradd 用户名添加用户useradd -g 组名 用户名 向组添加用户passwd 用户名 设置密码id 用户名 查看用户名的具体信息cat /etc/passwd 查看创建了哪些用户su 用户名 切换用户名(不能获得环境变量)su - 用户名获得环境变量以及执行权…...

如何使用Socks5代理IP提高网络安全性
随着网络的快速发展,网络安全问题变得越来越重要。为了保障网络安全,人们普遍使用代理IP,其中Socks5代理IP是一种常用的选择。本文将介绍什么是Socks5代理IP,以及如何使用它提高网络安全性。 一、什么是Socks5代理IP Socks5代…...
《Java8实战》第3章 Lambda 表达式
利用行为参数化来传递代码有助于应对不断变化的需求。它允许你定义一段代码块来表示一个行为,然后传递它。采用匿名类来表示多种行为并不令人满意:代码十分啰唆,这会影响程序员在实践中使用行为参数化的积极性。 3.1 Lambda 管中窥豹 可以…...

开放式耳机的颠覆之作!南卡OE Pro新皇降临!佩戴和音质双重突破
千呼万唤的南卡OE Pro终于要在最近正式官宣上线,此消息一经放出,蓝牙耳机市场就已经沸腾。NANK南卡品牌作为国内的音频大牌,发展和潜力一直备受业内关注,这次要上线的南卡OE Pro更是南卡十余年来积累的声学技术结晶之一。 据透露…...
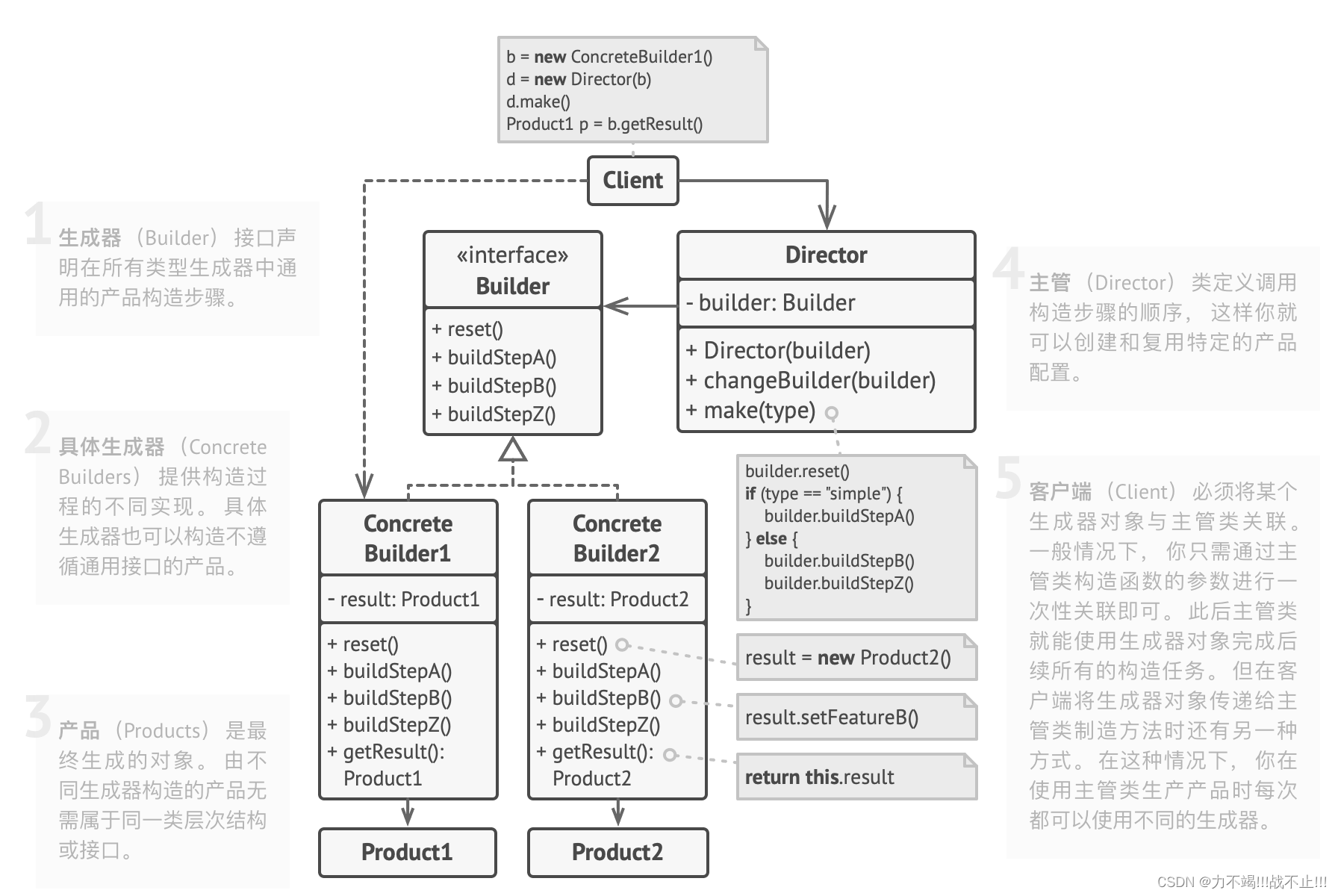
生成器设计模式(Builder Design Pattern)[论点:概念、图示、示例、框架中的应用、场景]
文章目录概念相关图示代码示例框架中的应用场景多个生成器(Concrete Builder):单个生成器概念 生成器设计模式(Builder Design Pattern)是一种创建型设计模式,用于处理具有多个属性和复杂构造过程的对象。生…...

JUC并发工具
JUC并发工具 一、CountDownLatch应用&源码分析 1.1 CountDownLatch介绍 CountDownLatch就是JUC包下的一个工具,整个工具最核心的功能就是计数器。 如果有三个业务需要并行处理,并且需要知道三个业务全部都处理完毕了。 需要一个并发安全的计数器来操作。 CountDown…...

java面试题-基础问题-如何理解Java中的多态?
如何理解Java中的多态?如何理解Java中的多态?典型回答扩展知识方法的重载与重写重载和重写的区别如何理解Java中的多态? 典型回答 多态的概念比较简单,就是同一操作作用于不同的对象,可以有不同的解释,产…...
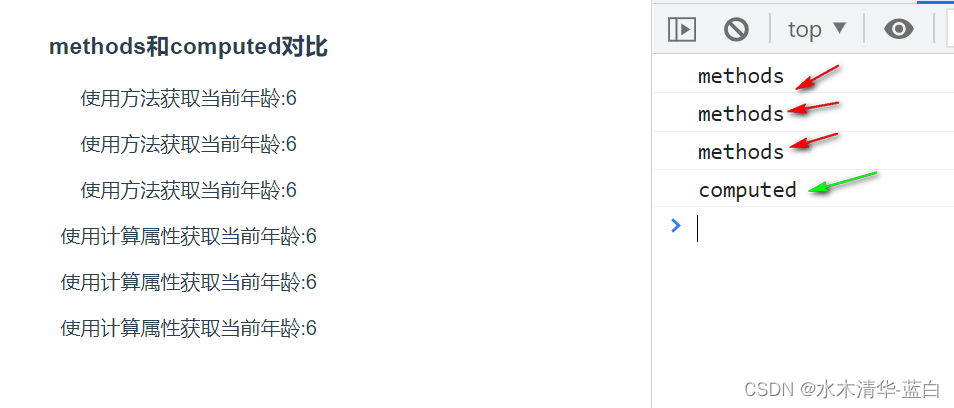
03.vue3的计算属性
文章目录1.计算属性1.get()和set()2.computed的简写3.computed和methods对比2.相关demo1.全选和反选2.todos列表1.计算属性 模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的。在模板中放入太多的逻辑会让模板过重且难以维护。所以,对于任何…...

Ceph性能调优
1. 最佳实践 1.1 基本 监控节点对于集群的正确运行非常重要,应当为其分配独立的硬件资源。如果跨数据中心部署,监控节点应该分散在不同数据中心或者可用性区域日志可能会让集群的吞吐量减半。理想情况下,应该在不同磁盘上运行操作系统、OSD…...
-更新中)
机器学习-问答题准备(英文)-更新中
第一章 入门 How would you define Machine Learning? Machine Learning is about building systems that can learn from data. Learning means getting better at some task, given some performance measure. Can you name four types of problems where it shines? To r…...

展示演示软件设计制作(C语言)
展示演示软件设计制作 所谓展示演示软件就像是PPT那样的东西。PPT是幻灯片式的展示,而我设计的软件是多媒体的,多样展示方法的,多种功能的。可以扩展为产品展示,项目介绍,景点导游,多媒体授课,…...
Android 自定义view 入门 案例
自定义一个圆环进度条: 1.首页Android Studio创建一个项目 2.在项目src/xxx/目录下右键选择创建一个自定义view页面:new->UICompoent->customer view 3.输入自定义名称,选择开发语言 4.确定之后,自动生成3个文件一个是&…...

[imangazaliev/didom]一个简单又快速的DOM操作库
DiDOM是一个功能齐全、易于使用和高性能的解析器和操作库,可以帮助PHP开发者更加高效地处理HTML文档。 为了更好地了解这个项目,我们先来看看下面的介绍。 安装 你可以使用composer来安装DiDOM,只需要在你的项目目录下执行下面的命令&…...
Cookie和Session的工作流程及区别(附代码案例)
目录 一、 HTTP协议 1.1 为什么HTTP协议是无状态的? 1.2 在HTTP协议中流式传输和分块传输编码的区别 二、Cookie和Session 2.1 Cookie 2.2 Session 2.3 Cookie和Session的区别 三、servlet中与Cookie和Session相关的API 3.1 HttpServletRequest 类中的相关方…...

适用于高级别自动驾驶的驾驶员可预见误用仿真测试
摘要 借助高级别自动驾驶(HAD),驾驶员可以从事与驾驶无关的任务。在系统出现失效的情况下,驾驶员应该合理地重新获得对自动驾驶车辆(AV)的控制。不正确的系统理解可能会引起驾驶员的误操作,并可能导致车辆级的危害。ISO 21448预期功能安全标…...
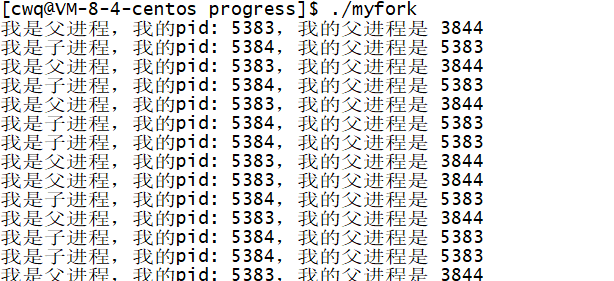
Linux之进程知识点
一、什么是进程 进程是一个运行起来的程序。 问题思考: ❓ 思考:程序是文件吗? 是!都读到这一章了,这种问题都无需思考!文件在磁盘哈。 本章一开始讲的冯诺依曼,磁盘就是外设,和内…...
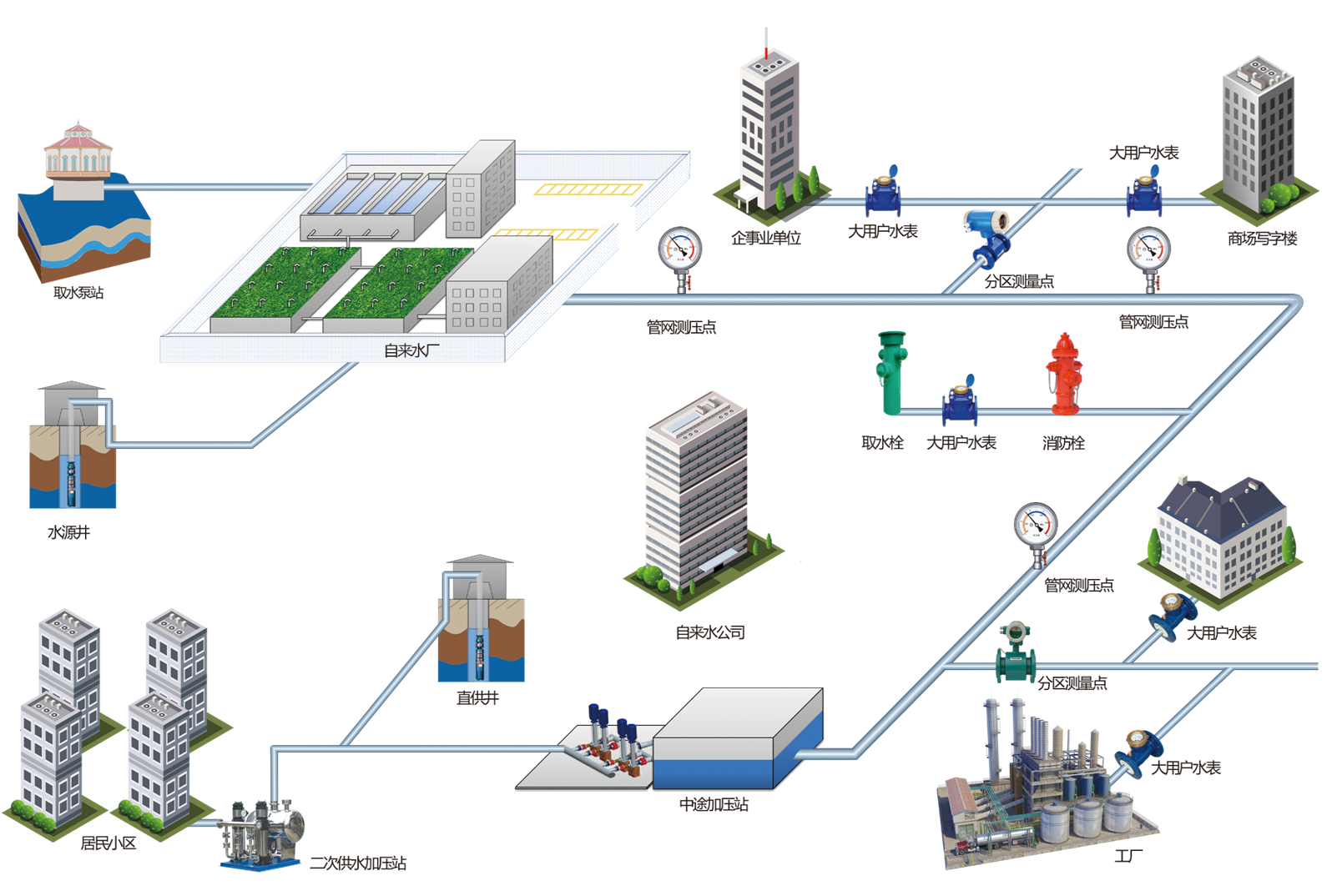
一种供水系统物联网监测系统
1.1供水系统 1.1.1监测范围选择依据 (1)管网老化区域管网 管网建设年代久远,通常管网发生破损问题较大,根据管网本身属性和历史发生事件的统计分析,结合数理统计,优先选择管网老化区域的管段所在区域进行…...

Linux驱动开发——字符设备(2)
目录 虚拟串口设备驱动 一个驱动支持多个设备 习题 虚拟串口设备驱动 字符设备驱动除了前面搭建好代码的框架外,接下来最重要的就是要实现特定于设备的操作方法,这是驱动的核心和关键所在,是一个驱动区别于其他驱动的本质所在,…...

YouMightNotNeedJS与响应式设计:打造完美适配所有设备的UI组件
YouMightNotNeedJS与响应式设计:打造完美适配所有设备的UI组件 【免费下载链接】YouMightNotNeedJS 项目地址: https://gitcode.com/gh_mirrors/yo/YouMightNotNeedJS 在现代网页开发中,实现跨设备兼容的响应式界面是提升用户体验的关键。YouMig…...

基于大语言模型的学术论文AI阅读助手:从PDF解析到智能问答全流程解析
1. 项目概述:一个为学术论文阅读而生的AI助手 如果你经常需要阅读海量的学术论文,尤其是计算机科学、人工智能领域的英文PDF文献,那你一定对那种“打开一篇新论文,面对几十页的陌生术语和复杂公式,不知从何读起”的无…...

对比直接采购使用Taotoken Token Plan套餐在长期开发中的成本优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接采购与使用Taotoken Token Plan套餐在长期开发中的成本优势 在长期的技术项目开发中,模型API调用成本是团队必…...

AI商品计划:中国鞋服零售如何用机器学习解决库存与周转难题
过去十年,中国鞋服零售经历了从线下到线上、从粗放铺货到精准运营的剧烈转变。但一个老问题始终没变:该备多少货,备在哪,备什么颜色尺码。备多了,资金压在仓库,季末折扣吞噬利润;备少了…...

解密Ryujinx:5个核心技术原理让你理解现代游戏模拟器的设计哲学
解密Ryujinx:5个核心技术原理让你理解现代游戏模拟器的设计哲学 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx Ryujinx作为一款基于C#开发的Nintendo Switch模拟器&#x…...

3分钟拯救你的B站视频:m4s-converter零转码转换完全指南
3分钟拯救你的B站视频:m4s-converter零转码转换完全指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 想象一下,你花了…...
怎么选,告别‘卖家秀’惨案)
从LED灯珠到手机屏幕:一文搞懂色温、显色指数(CRI)怎么选,告别‘卖家秀’惨案
从LED灯珠到手机屏幕:色温与显色指数的科学选购指南 深夜伏案工作时,你是否总觉得眼睛干涩疲劳?网购衣物到手后颜色总与屏幕显示相差甚远?餐厅美食拍出来总是暗淡无光?这些困扰的根源往往在于——光源质量。当我们面对…...
)
从‘点一下’到‘连一连’:Qt6中PushButton信号与槽的5种连接方式详解(含Lambda表达式实战)
从‘点一下’到‘连一连’:Qt6中PushButton信号与槽的5种连接方式详解(含Lambda表达式实战) 在Qt框架中,PushButton作为最基础的交互控件之一,其信号与槽机制是构建响应式用户界面的核心。随着Qt6的发布,信…...

通过curl命令直接测试Taotoken聊天补全接口的简易方法
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接测试Taotoken聊天补全接口的简易方法 在开发或调试过程中,有时我们希望在无需引入完整SDK的轻量级环境…...

ITK-SNAP医学图像分割:精准医疗影像分析的利器
ITK-SNAP医学图像分割:精准医疗影像分析的利器 【免费下载链接】itksnap ITK-SNAP medical image segmentation tool 项目地址: https://gitcode.com/gh_mirrors/it/itksnap 面对复杂的医学影像数据,如何快速准确地进行三维解剖结构分割ÿ…...