机器学习-问答题准备(英文)-更新中
第一章 入门
-
How would you define Machine Learning?
Machine Learning is about building systems that can learn from data. Learning means getting better at some task, given some performance measure. -
Can you name four types of problems where it shines?
To replace long lists of hand-tuned rules, like filtering spam emails; to make better recommendations for customers; to build systems that adapt to fluctuating environments; to recognize voice and pictures. -
What is a labeled training set?
It contains desired solution (a.k.a. a label) for each instance. -
What are the two most common supervised tasks?
Regression and classification. -
Can you name four common unsupervised tasks?
Clustering, dimensionality reduction, visualization and association rule learning. -
What type of Machine Learning algorithm would you use to allow a robot to walk in various unknown terrains?
Reinforcement learning. -
What type of algorithm would you use to segment your customers into multiple groups?
If you don’t know what groups you would like to have, then you can use clustering, otherwise use classification instead. -
Would you frame the problem of spam detection as a supervised learning problem or an unsupervised learning problem?
It’s a supercised learning problem. -
What is an online learning system?
It can learn incrementally. This makes it capable of adapting rapidly ro both changing data and autonomous systems, and of training on very large quantities of data. -
What is out-of-core learning?
Out-of-core algorithms can handle vast quantities of data that cannot fit in a computer’s main memory. An out-of-core learning algorithm chops the data into mini-batches and uses online learning techniques to learn from these minibatches. -
What type of learning algorithm relies on a similarity measure to make predictions?
Instance-based learning. -
What is the difference between a model parameter and a learning algorithm’s hyperparameter?
A model has one or more model parameters that determine what it will predict given a new instance, for example, the slope of a linear model. A hyperparameter is a parameter of the learning algorithm itself, not of the model, for example, the amount of regularization to apply. -
What do model-based learning algorithms search for? What is the most common strategy they use to succeed? How do they make predictions?
They search for an optimal value for the model parameters such that the model will generalize well to new instances. We usually train such systems by minimizing a cost function that measures how bad the system is at making predictions on training data, plus a penalty for model complexity if the model is regularized. To make predictions, we feed the new instance’s features into the model’s prediction function, using the parameter values found by the learning system. -
Can you name four of the main challenges in Machine Learning?
Lack of data, poor data quality, nonrepresentative data, excessively complex models that overfit the data. -
If your model performs great on the training data but generalizes poorly to new instances, what is happening? Can you name three possible solutions?
It seems that the model is likely overfitting the training data. Possible solutions such as getting more data, simplifying the model, and reducing the noise in the training data. -
What is a test set, and why would you want to use it?
A test set is used to estimate the generalization error that a model will make on new instances, before the model is launched in production. -
What is the purpose of a validation set?
A validation set is used to compare models. It helps to select the best model and tune the hyperparameters. -
What is the train-dev set, when do you need it, and how do you use it?
The train-dev set is a part of the training set that’s held out(the model is not trained on it).
It’s used when there is a risk of mismatch between the training data the validation plus test data.
The model is trained on the rest of the training set, and evaluated on both the train-dev set and the validation set.If the model performs well on the traing set but not on the train-dev set, then the model is overfitting the traing set. If the model performs well on train-dev set, but not on the validation set, then there is probably a significant data mismatch between the traing data and the validation + test data. -
What can go wrong if you tune hyperparameters using the test set?
If you do so, you risk overfitting the test set and the generalization error will be optimistic.
相关文章:
-更新中)
机器学习-问答题准备(英文)-更新中
第一章 入门 How would you define Machine Learning? Machine Learning is about building systems that can learn from data. Learning means getting better at some task, given some performance measure. Can you name four types of problems where it shines? To r…...

展示演示软件设计制作(C语言)
展示演示软件设计制作 所谓展示演示软件就像是PPT那样的东西。PPT是幻灯片式的展示,而我设计的软件是多媒体的,多样展示方法的,多种功能的。可以扩展为产品展示,项目介绍,景点导游,多媒体授课,…...
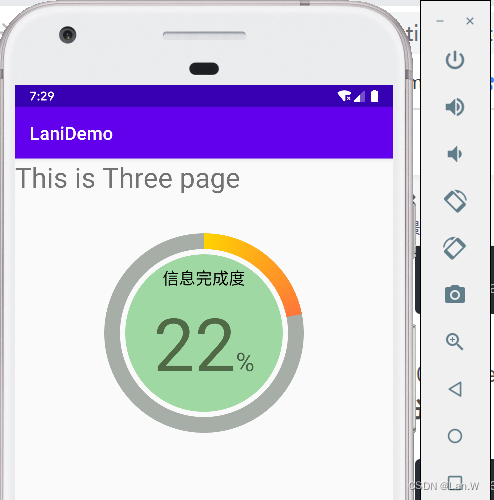
Android 自定义view 入门 案例
自定义一个圆环进度条: 1.首页Android Studio创建一个项目 2.在项目src/xxx/目录下右键选择创建一个自定义view页面:new->UICompoent->customer view 3.输入自定义名称,选择开发语言 4.确定之后,自动生成3个文件一个是&…...

[imangazaliev/didom]一个简单又快速的DOM操作库
DiDOM是一个功能齐全、易于使用和高性能的解析器和操作库,可以帮助PHP开发者更加高效地处理HTML文档。 为了更好地了解这个项目,我们先来看看下面的介绍。 安装 你可以使用composer来安装DiDOM,只需要在你的项目目录下执行下面的命令&…...
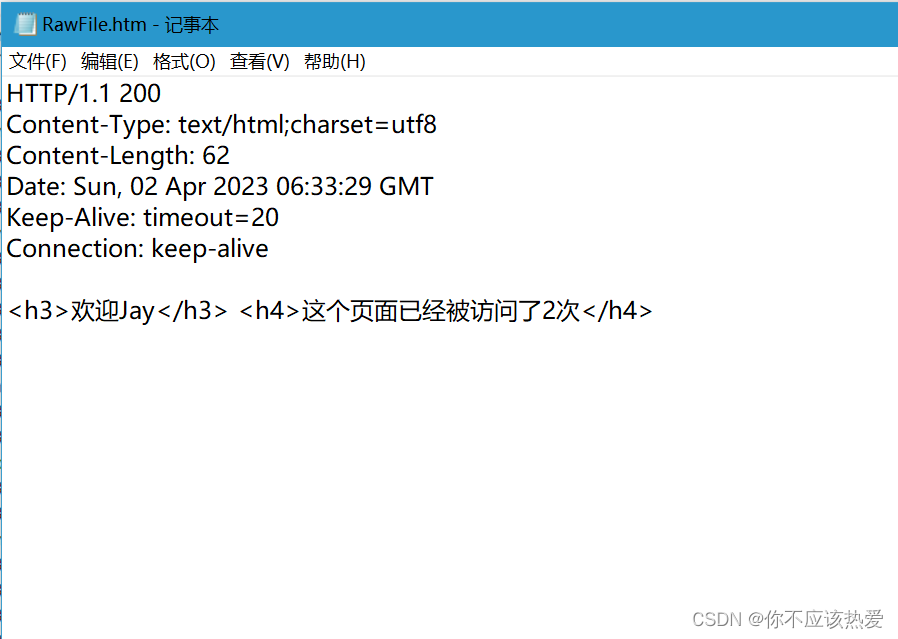
Cookie和Session的工作流程及区别(附代码案例)
目录 一、 HTTP协议 1.1 为什么HTTP协议是无状态的? 1.2 在HTTP协议中流式传输和分块传输编码的区别 二、Cookie和Session 2.1 Cookie 2.2 Session 2.3 Cookie和Session的区别 三、servlet中与Cookie和Session相关的API 3.1 HttpServletRequest 类中的相关方…...

适用于高级别自动驾驶的驾驶员可预见误用仿真测试
摘要 借助高级别自动驾驶(HAD),驾驶员可以从事与驾驶无关的任务。在系统出现失效的情况下,驾驶员应该合理地重新获得对自动驾驶车辆(AV)的控制。不正确的系统理解可能会引起驾驶员的误操作,并可能导致车辆级的危害。ISO 21448预期功能安全标…...
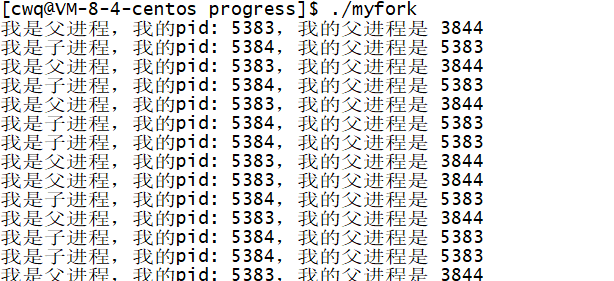
Linux之进程知识点
一、什么是进程 进程是一个运行起来的程序。 问题思考: ❓ 思考:程序是文件吗? 是!都读到这一章了,这种问题都无需思考!文件在磁盘哈。 本章一开始讲的冯诺依曼,磁盘就是外设,和内…...
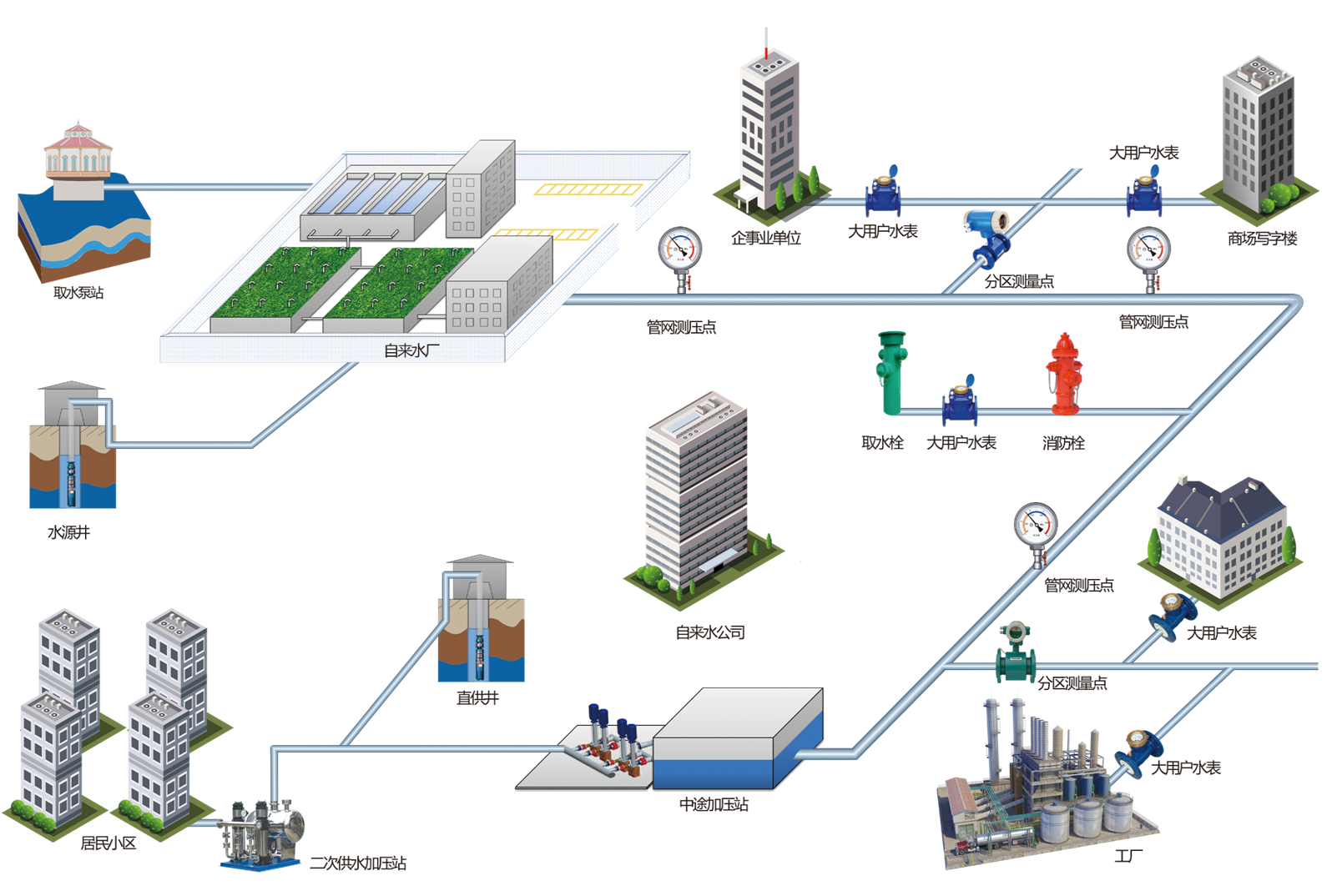
一种供水系统物联网监测系统
1.1供水系统 1.1.1监测范围选择依据 (1)管网老化区域管网 管网建设年代久远,通常管网发生破损问题较大,根据管网本身属性和历史发生事件的统计分析,结合数理统计,优先选择管网老化区域的管段所在区域进行…...

Linux驱动开发——字符设备(2)
目录 虚拟串口设备驱动 一个驱动支持多个设备 习题 虚拟串口设备驱动 字符设备驱动除了前面搭建好代码的框架外,接下来最重要的就是要实现特定于设备的操作方法,这是驱动的核心和关键所在,是一个驱动区别于其他驱动的本质所在,…...
【MySQL数据库原理】MySQL Community安装与配置
目录 安装成功之后查看版本验证1、介绍、安装与配置数据库2、操作MySQL数据库3、MySQL数据库原理安装成功之后查看版本验证 SELECT VERSION();查看mysql版本号 1、介绍、安装与配置数据库 下载安装包:https://download.csdn.net/download/weixin_41194129/87672588 MySQL…...

【ROS参数服务器增删改c++操作1】
需求:实现参数服务器参数的增删改查操作。 在C中实现参数服务器数据的增删改查,可以通过两套API实现:. ros::NodeHandle ros::param下面为具体操作演示: 在src下面的自己定义的作用包下面新建文件。 比如我的是一直存在的demo03_ws文件下的src里面&…...

elasticsearch 常用数据类型详解和范例
主要内容 elasticsearch 中的字符串(keyword)类型 的详解和范例 elasticsearch 中的字符串/文本(text)类型 的详解和范例 elasticsearch 中的数字(数值)类型 的详解和范例 elasticsearch 中的布尔&#…...
力扣119杨辉三角 II:代码实现 + 方法总结(数学规律法 记忆法/备忘录)
文章目录第一部分:题目第二部分:解法①-数学规律法2.1 规律分析2.2 代码实现2.3 需要思考第三部分:解法②-记忆法(备忘录)第四部分:对比总结第一部分:题目 🏠 链接:119.…...

安装pandas遇到No module named ‘_bz2’ 的解决方案
出现这个问题我们可以按照这篇博客去解决: https://blog.csdn.net/bf96163/article/details/128654915 如果解决不了,可以这样去做: 1.确保安装了 对应的库 // ubuntu安装命令 sudo apt-get install bzip2-devel // centos安装命令 sudo y…...
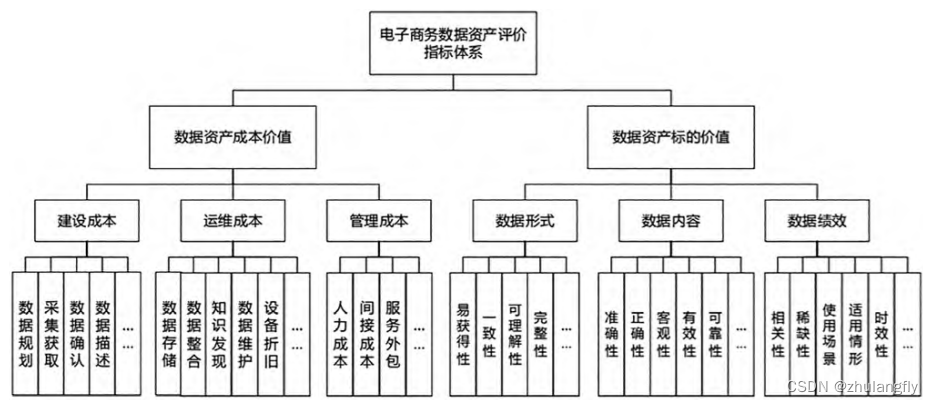
【数据治理-05】什么数据才是货真价实的数据资产,一起聊聊数据资产
在国家层面一些列文件、纲要、政策、办法等政府力量的推动下,数据资产这个词越来越频繁的出现在我们寻常工作当中,现在越来越觉得这个词被滥用,大有“一切数据皆是资产”的感觉,业务数据是资产、技术数据是资产,不能共…...

第三章 ARM处理器体系结构【嵌入式系统】
第三章 ARM处理器体系结构【嵌入式系统】前言推荐第三章 ARM处理器体系结构3.1 概述3.2 ARM处理器的结构3.7 ARM的异常中断处理最后前言 以下内容源自《【嵌入式系统】》 仅供学习交流使用 推荐 无 第三章 ARM处理器体系结构 留着占位 敬请期待 3.1 概述 3.2 ARM处理器的…...

最速下降法
首先,计算函数f的梯度向量:∇f(x1,x2)[2x150x2]\nabla f(x_1,x_2) \begin{bmatrix}2x_1\\50x_2\end{bmatrix}∇f(x1,x2)[2x150x2] 然后,选择一个初始点(x10,x20)(x_1^0,x_2^0)(x10,x20),比如(0,0)(0,0)(0,0)。 接…...
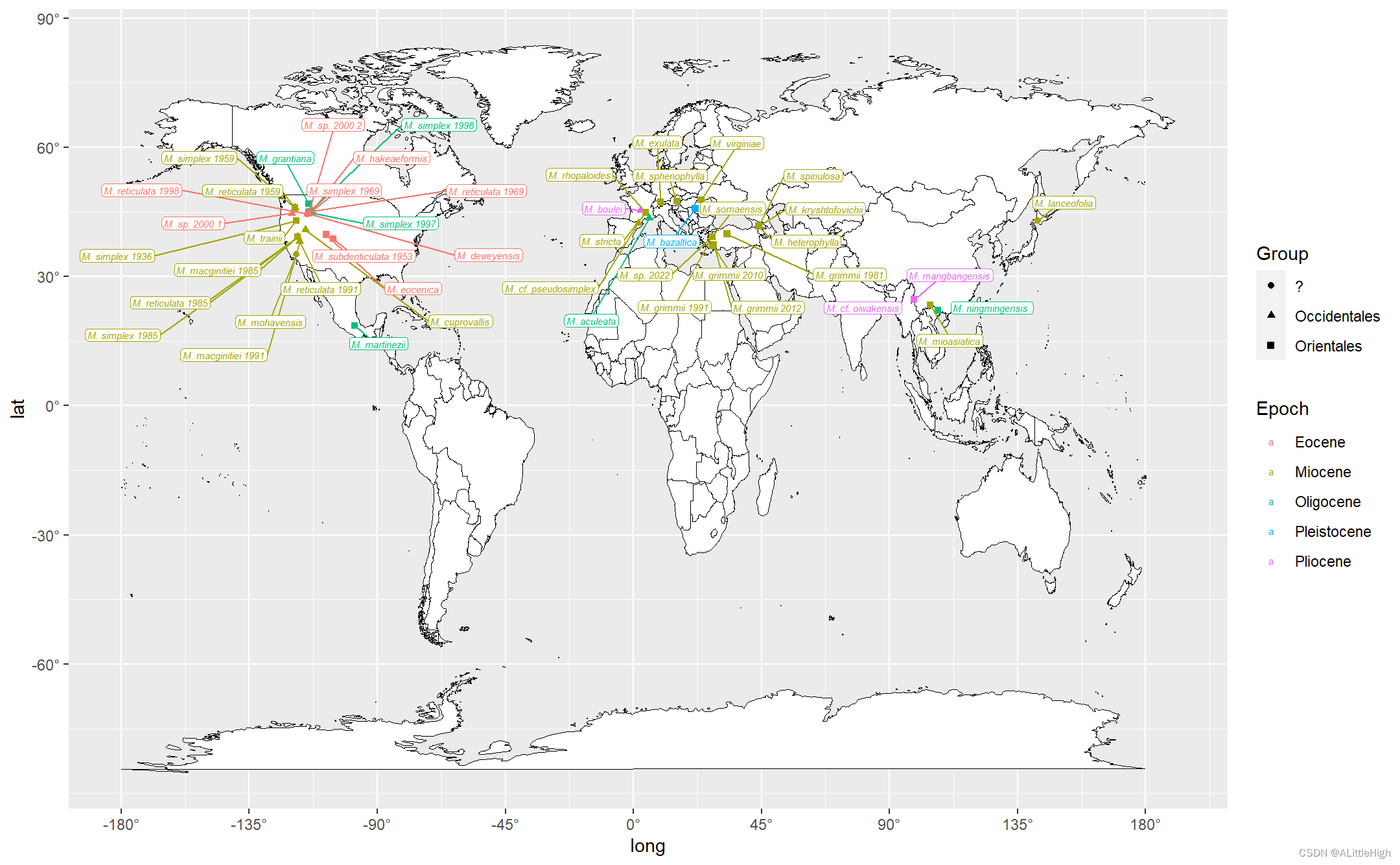
R语言实践——ggplot2+ggrepel绘制散点+优化注释文本位置
简介 书接adjustText实践——调整matplotlib散点图标签,避免重复 上文中,matplotlibadjustText对于我的实例来说并没有起到很好的效果。所以,博主决定在R中利用gglot2ggrepel绘制,期待效果。 操作过程 博主不常使用Rÿ…...
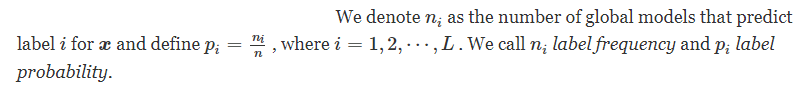
[TIFS 2022] FLCert:可证明安全的联邦学习免受中毒攻击
FLCert: Provably Secure Federated Learning Against Poisoning Attacks | IEEE Journals & Magazine | IEEE Xplore 摘要 由于其分布式性质,联邦学习容易受到中毒攻击,其中恶意客户端通过操纵其本地训练数据和/或发送到云服务器的本地模型更新来毒…...

css3关键帧动画
CSS3关键帧动画是一种在网页设计中常用的技术,通过使用CSS3的关键帧动画功能,可以实现网页上各种形式的动画效果,例如淡入淡出、滑动、旋转、缩放等,这些动画效果可以让网页更加生动有趣,吸引用户的注意力,…...

Node.js后端服务快速集成Taotoken,为应用注入大模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js后端服务快速集成Taotoken,为应用注入大模型能力 为Node.js后端服务添加大模型能力,可以显著提升应…...

等保2.0合规实战:Redis安全配置核查与加固指南
1. Redis安全配置入门:为什么等保2.0要求这么严格? 我第一次接触Redis安全配置是在一次等保2.0合规检查中。当时客户系统因为Redis默认配置导致数据泄露,整个项目组连夜加班整改。从那以后,我就养成了每次部署Redis必做安全检查的…...

Noto Emoji终极指南:3种策略彻底解决跨平台表情符号显示难题
Noto Emoji终极指南:3种策略彻底解决跨平台表情符号显示难题 【免费下载链接】noto-emoji Noto Emoji fonts 项目地址: https://gitcode.com/gh_mirrors/no/noto-emoji Noto Emoji是Google开发的开源表情符号字体库,旨在为全球用户提供完整、一致…...

STM32CubeMX生成代码后,Keil编译烧写的那些“隐藏”步骤与调试器避坑
STM32CubeMX生成代码后,Keil编译烧写的那些“隐藏”步骤与调试器避坑 当你用STM32CubeMX生成代码后,以为万事大吉,结果在Keil里编译烧写时却频频碰壁——这几乎是每个STM32开发者都会经历的“成人礼”。那些教程里一笔带过的“编译”、“烧写…...

番茄小说下载器:从网页到电子书的完整离线阅读解决方案
番茄小说下载器:从网页到电子书的完整离线阅读解决方案 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 番茄小说下载器是一款基于Rust语言开发的开源工具ÿ…...

C++ 如何在VS中“强制”链接?
如何在VS中“强制”链接? 打开你的game_mobile项目,按下图设置。 方法一:强制链接(最直接) 这是彻底忽略LNK1169及其引发的所有LNK2005错误,强制生成可执行文件的方法。 打开项目的“属性页”。导航到“配置…...
)
你还在手动调参?——用Python自动化脚本批量生成表现主义变体并智能评分(GitHub开源已验证)
更多请点击: https://intelliparadigm.com 第一章:你还在手动调参?——用Python自动化脚本批量生成表现主义变体并智能评分(GitHub开源已验证) 表现主义图像生成常依赖艺术家风格参数(如笔触强度、色域饱和…...

【ElevenLabs尼泊尔文语音实战指南】:20年AI语音工程师亲授7大避坑要点与本地化部署全流程
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs尼泊尔文语音技术概览与核心价值 ElevenLabs 自 2023 年起逐步扩展其多语言语音合成能力,尼泊尔文(Nepali, ISO 639-1: ne)作为首批支持的南亚语系之一&am…...

手把手教你为全志Tina Linux添加新SPI屏驱动:以GC9306和HX8357C为例
全志Tina Linux SPI屏驱动移植实战:从裸机到内核框架的完整指南 在嵌入式Linux开发中,LCD显示屏的驱动移植是一个常见但颇具挑战性的任务。不同于裸机环境下的直接寄存器操作,Linux内核要求驱动程序遵循特定的框架和规范。本文将深入探讨如何…...

基于MCP协议构建加密货币数据查询工具:coinpaprika-mcp详解
1. 项目概述:一个连接加密货币数据世界的桥梁 最近在折腾一个需要实时获取多种加密货币数据的项目,从价格、市值到社区动态,需求五花八门。市面上数据源不少,但要么API调用限制太死,要么数据维度不够全,要…...