qwen-0.5b小模型的用处和显存要求
详细分析一下 Qwen-0.5B (5亿参数) 这个模型在不同训练阶段的显存需求以及它的用途。(根据网页反馈:1、0.5b做蒸馏,特定领域轻松超越sft的7b;2、大部分实时要求高的业务需要用小模型初筛降量,比如意图识别;3、取倒数第一层的hidden vector拿来做text embedding,相当于是一个可以接受prompt的bert,再对比学习调一下就是embedding模型;4、给无显卡的人调参数做实验;5、边缘计算、端侧应用;6、rag差不多够用;)
一、训练阶段显存需求估算 (估算值,受多种因素影响)
显存需求是一个动态值,受到以下关键因素显著影响:
- 训练方式: 全参数微调 vs. 参数高效微调 (PEFT, 如 LoRA, Prefix-Tuning)。
- 优化器: AdamW 比 SGD 占用更多显存(需要存储动量和方差)。
- 精度: FP32 (单精度) vs. FP16/BF16 (半精度) vs. FP8 (8位精度,较少支持)。半精度训练是当前主流,能显著节省显存和加速训练,以下估算主要基于 BF16/FP16。
- Batch Size: 批次大小直接影响激活值和梯度的显存占用。
- 序列长度: 输入文本的最大长度,直接影响激活值显存。
- 梯度累积: 是否使用梯度累积来模拟更大的 Batch Size。
- 激活检查点: 是否开启梯度检查点技术(用计算时间换显存)。
- 并行策略: 是否使用数据并行、模型并行、流水线并行、Zero Redundancy Optimizer (ZeRO) 等技术。
- 其他开销: 框架开销、通信开销(在多卡训练时)、数据加载等。
核心估算逻辑:
- 模型参数: 5亿参数,在 BF16/FP16 下,每个参数占 2 字节。模型参数本身占用约
0.5B * 2 bytes = 1 GB。 - 优化器状态 (AdamW): 对于每个参数,AdamW 需要存储其 FP32 格式的参数副本、动量、方差。通常每个参数需要
4 bytes (FP32 param) + 4 bytes (momentum) + 4 bytes (variance) = 12 bytes。在 BF16/FP16 训练下,模型参数是半精度的,但优化器状态通常是 FP32 的。优化器状态占用约0.5B * 12 bytes = 6 GB。 - 梯度: 在 BF16/FP16 下,每个参数的梯度占 2 字节。梯度占用约
0.5B * 2 bytes = 1 GB。 - 激活值: 这是最难精确估算的部分,它高度依赖于 Batch Size、序列长度、模型结构(层数、隐藏层大小)、是否使用激活检查点。对于 0.5B 模型,在合理配置下,激活值占用通常在模型参数大小的数倍到十倍左右(尤其在序列较长、Batch Size 较大时)。
以下是不同训练阶段的大致显存需求范围 (单卡,BF16/FP16):
-
Pretraining (预训练):
- 需求最高。 需要处理海量原始数据,通常使用大 Batch Size 和长序列。
- 需要存储完整的模型参数、优化器状态、梯度、大量激活值。
- 估算范围: 15 GB - 40+ GB
- 典型场景: 需要至少一张 24GB 显存的卡 (如 NVIDIA RTX 3090/4090, Tesla A10) 才能进行小规模预训练(Batch Size 较小,序列长度适中,可能开启激活检查点)。进行有意义的预训练通常需要 多张 A100 (40/80GB) 或 H100 卡,利用数据并行或 ZeRO 等技术。
-
Supervised Fine-Tuning (SFT,监督微调):
- 需求中等。 数据量通常远小于预训练,任务更聚焦,可以使用较小的 Batch Size 和序列长度。强烈推荐使用 PEFT (如 LoRA)!
- 全参数微调: 显存占用结构与预训练类似,但激活值压力通常小一些(因为 Batch Size 和序列长度可能更小)。估算范围: 10 GB - 30+ GB。一张 24GB 卡 (如 3090/4090) 在精心配置(小 Batch Size, 激活检查点)下通常可以进行。
- PEFT 微调 (强烈推荐): 只微调少量额外参数(如 LoRA 的秩矩阵),冻结原始模型的大部分参数。优化器状态和梯度只存在于这些少量参数上,显存需求大幅降低。
- 估算范围: 2 GB - 8 GB (取决于基础模型加载方式、LoRA 配置、Batch Size)。
- 典型场景: 可以在 消费级显卡 (如 RTX 3060 12GB, RTX 4060 16GB) 甚至更低显存的卡上轻松进行。
-
RLHF / DPO Training (人类反馈强化学习 / 直接偏好优化):
- 需求高 (尤其 RLHF) / 中等偏高 (DPO)。 需要同时处理多个模型。
- RLHF (传统 PPO):
- 需要同时加载和运行:
- Policy Model (策略模型): 正在训练的模型 (SFT 后的模型)。
- Reference Model (参考模型): 通常是 SFT 后的模型(冻结)。
- Reward Model (奖励模型): 另一个训练好的模型(冻结)。
- PPO 过程本身还需要存储经验回放缓存、优势函数估计等额外信息。
- 估算范围 (Policy + Ref + RM): 2.5 - 3 倍于单个 SFT 模型全参微调的显存。对于 0.5B 模型,通常在 30 GB - 80+ GB 范围。通常需要多张高显存卡 (如 A100/H100) 和复杂的并行策略 (ZeRO Stage 3, 模型并行)。
- 需要同时加载和运行:
- DPO:
- 需要同时加载:
- Policy Model (策略模型): 正在训练的模型。
- Reference Model (参考模型): 冻结的 SFT 模型。
- 优化过程相对 PPO 更简单直接,不需要奖励模型和复杂的 PPO 更新步骤。
- 估算范围 (Policy + Ref): 约 2 倍于单个 SFT 模型全参微调的显存。对于 0.5B 模型,通常在 20 GB - 60+ GB 范围。比 RLHF (PPO) 显存需求低,但对单卡压力仍然很大。使用 PEFT (如 LoRA) 进行 DPO 可以显著降低显存需求,可能降到 5 GB - 15 GB 左右,使得在 单张 24GB 卡 上运行成为可能(仍需仔细配置)。
- 需要同时加载:
总结显存需求表 (单卡 BF16/FP16, 粗略估算):
| 训练阶段 | 主要特点 | 显存需求范围 (GB) | 典型可行硬件 (单卡) | 关键节省技术 |
|---|---|---|---|---|
| Pretraining | 海量数据,大Batch,长序列 | 15 - 40+ | A100/H100 (多卡常见) | 激活检查点, ZeRO, 低精度 |
| SFT (全参) | 任务数据,中等配置 | 10 - 30+ | RTX 3090/4090 (24GB) | 激活检查点, 小Batch |
| SFT (PEFT) | 仅微调少量参数 | 2 - 8 | RTX 3060 (12GB) / 4060 (16GB) 或更高 | LoRA 等 PEFT 方法 |
| RLHF (PPO) | Policy + Ref + RM + PPO 机制 | 30 - 80+ | 多张 A100/H100 + ZeRO Stage 3 / 模型并行 | 极其依赖并行和优化 |
| DPO (全参) | Policy + Ref | 20 - 60+ | 高显存单卡或多卡 (A100/H100) | 激活检查点 |
| DPO (PEFT) | Policy (LoRA) + Ref | 5 - 15 | RTX 3090/4090 (24GB) | LoRA + 激活检查点 |
二、Qwen-0.5B (5亿参数) 模型的用途
虽然 5亿参数在当今大模型(百亿、千亿级)面前显得很小,但 Qwen-0.5B 这样的模型在特定场景下依然非常有价值:
-
边缘计算与端侧部署:
- 核心优势: 模型体积小(通常几百MB),计算量和内存占用低。
- 应用场景: 可以在手机、平板、嵌入式设备、物联网设备上本地运行,实现离线智能功能,保护用户隐私,降低延迟。
- 具体任务: 设备本地的简单对话助手、文本摘要、关键词提取、基础问答、情感分析、翻译(短语或句子级别)、写作辅助(短文本生成、润色)。
-
对延迟敏感的应用:
- 核心优势: 推理速度快,响应时间短。
- 应用场景: 实时交互系统(如聊天机器人需要快速回复)、高频API服务(处理大量并发请求时,小模型成本更低、速度更快)、游戏NPC对话。
-
轻量级任务自动化:
- 应用场景: 自动生成简单的报告模板、邮件草稿、社交媒体帖子;进行基础的文本分类(如垃圾邮件过滤、主题分类);信息抽取(如从固定格式文本中提取关键字段)。
-
教育、研究与原型开发:
- 学习工具: 学生和研究人员可以更轻松地在个人电脑上理解和实验大语言模型的基本原理、训练/微调流程、评估方法,学习成本低。
- 快速原型验证: 在产品开发早期,可以用小模型快速搭建功能原型,验证想法和用户交互流程,然后再考虑是否需要更大模型提升效果。
- 算法研究平台: 研究新的训练方法(如更高效的 RLHF/DPO)、模型压缩技术、PEFT 方法等,在小模型上迭代速度更快,成本更低。
-
成本敏感型业务:
- 核心优势: 训练和推理的硬件成本、云服务费用、电力消耗都远低于大模型。
- 应用场景: 初创公司、预算有限的项目、需要大规模部署的简单智能功能(如客服系统中的关键词触发回复、工单自动分类)。
-
特定领域垂直应用的基石:
- 虽然通用能力不如大模型,但在某个狭窄、定义清晰的任务领域(例如:根据特定模板生成产品描述、分析特定类型的客服日志情绪、回答某个知识库内的常见问题),经过高质量的领域数据微调后,Qwen-0.5B 可以表现得非常高效和实用。
总结
- 显存: Qwen-0.5B 的预训练 (Pretrain) 需要高显存卡或多卡并行(15-40+ GB)。SFT 微调在消费级显卡上可行(全参10-30+ GB,PEFT 2-8 GB)。RLHF (PPO) 训练显存需求极高(30-80+ GB),通常需要专业级多卡集群。DPO 训练需求低于 PPO(全参20-60+ GB,PEFT 5-15 GB),在高端消费卡上使用 PEFT 是可能的。PEFT (尤其是 LoRA) 是大幅降低 SFT 和 DPO 显存需求的关键。
- 用途: Qwen-0.5B 的核心价值在于其小巧、快速、低成本。它非常适合端侧/边缘部署、实时应用、轻量级任务自动化、教育研究、快速原型开发、成本敏感型业务以及在特定垂直领域经过精调后提供高效的解决方案。它是轻量化和实用性的代表,虽然能力上无法与数百亿参数的大模型匹敌,但在其适用场景下性价比极高。
选择是否使用 Qwen-0.5B,取决于你的具体应用场景对模型能力、响应速度、部署成本、隐私要求和硬件限制的权衡。
相关文章:

qwen-0.5b小模型的用处和显存要求
详细分析一下 Qwen-0.5B (5亿参数) 这个模型在不同训练阶段的显存需求以及它的用途。(根据网页反馈:1、0.5b做蒸馏,特定领域轻松超越sft的7b;2、大部分实时要求高的业务需要用小模型初筛降量,比如意图识别;…...

防范DDoS攻击,服务器稳定性崩溃的根源与高效防御对策
DDoS攻击(分布式拒绝服务攻击)已成为危害服务器稳定性和业务连续性的主要因素之一。本文将深入探讨为什么服务器一遇到DDoS攻击就崩溃,以及如何从根本上实现有效防御和应对这一威胁,帮助企业提升网络安全水平。 具体内容如下&…...
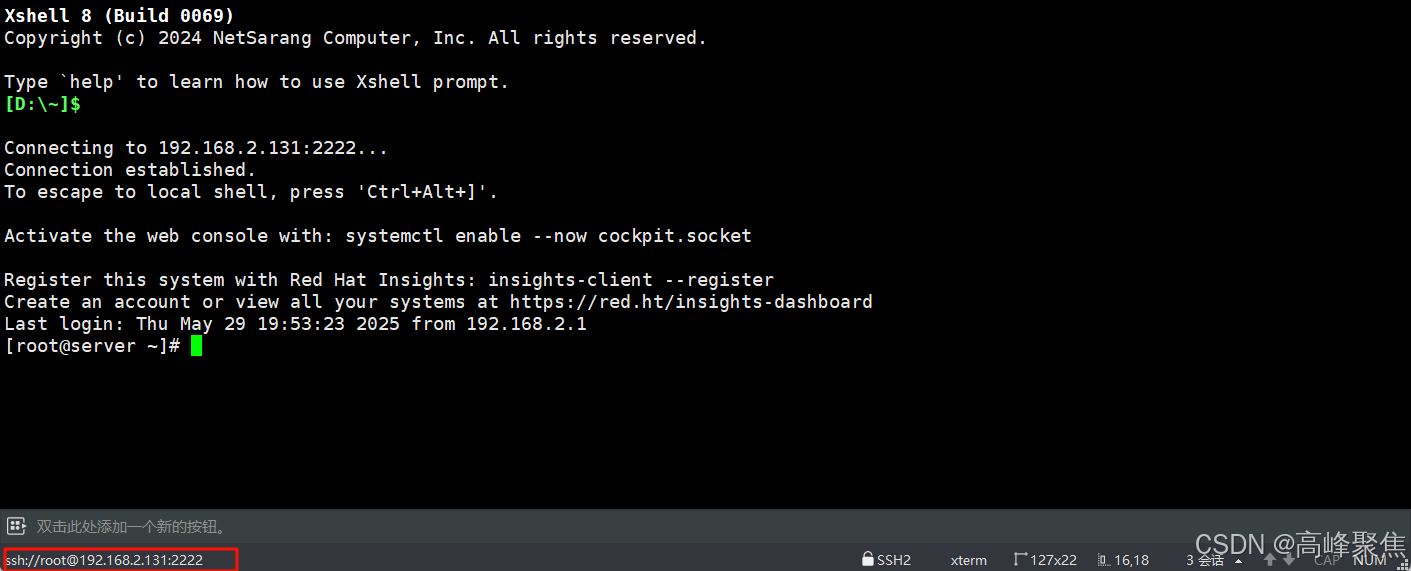
深入理解 SELinux:通过 Nginx 和 SSH 服务配置实践安全上下文与端口策略
目录 一、引言 二、实验环境说明 三、实验 1:Nginx 服务安全上下文配置 3.1 实验目标 3.2 操作步骤 1. 开启 SELinux 并重启系统 2. 安装 Nginx 并创建自定义目录 3. 配置 Nginx 指向自定义目录 4. 分析 SELinux 上下文冲突 5. 修改上下文为合法类型 6. 验…...
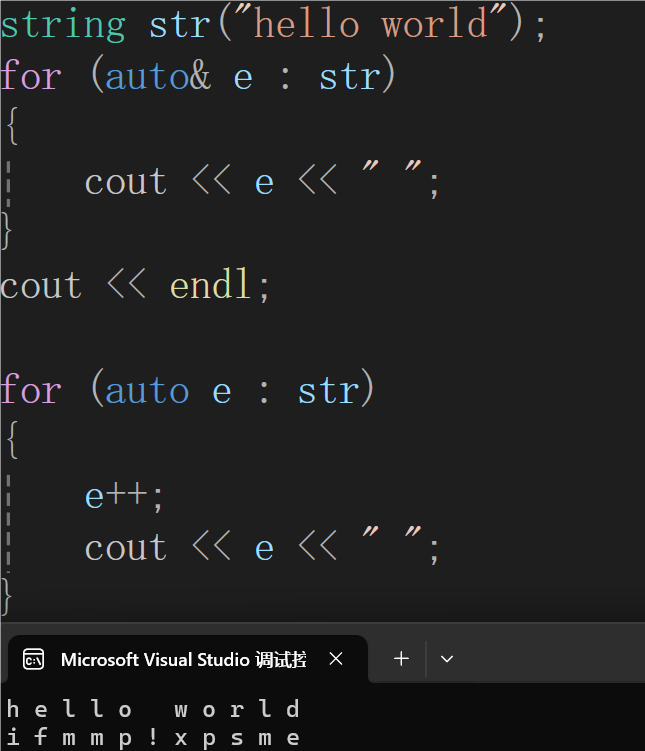
C++ —— STL容器——string类
1. 前言 本篇博客将会介绍 string 中的一些常用的函数,在使用 string 中的函数时,需要加上头文件 string。 2. string 中的常见成员函数 2.1 初始化函数 string 类中的常用的初始化函数有以下几种: 1. string() …...

用JS实现植物大战僵尸(前端作业)
1. 先搭架子 整体效果: 点击开始后进入主场景 左侧是植物卡片 右上角是游戏的开始和暂停键 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevic…...

Rust Mock 工具
Rust Mock 工具 Mock(模拟)是测试中不可或缺的工具,用来替代复杂或不可控的依赖,比如数据库、网络服务等,帮助我们写出高质量、健壮的测试代码。Rust 社区中,mockall 和 mockito 是两款主流且强大的 Mock …...

C++读写锁以及实现方式
文章目录 【C专题】读写锁(Reader-Writer Lock)原理与实现方式(含C11/20实践)一、读写锁核心概念1. **什么是读写锁?**2. **读写锁 vs 互斥锁** 二、C中的读写锁实现方式 方案一:POSIX 读写锁(p…...
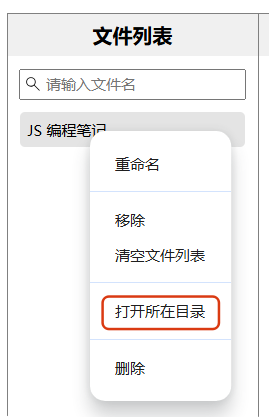
Electron-vite【实战】MD 编辑器 -- 文件列表(含右键快捷菜单,重命名文件,删除本地文件,打开本地目录等)
最终效果 页面 src/renderer/src/App.vue <div class"dirPanel"><div class"panelTitle">文件列表</div><div class"searchFileBox"><Icon class"searchFileInputIcon" icon"material-symbols-light:…...
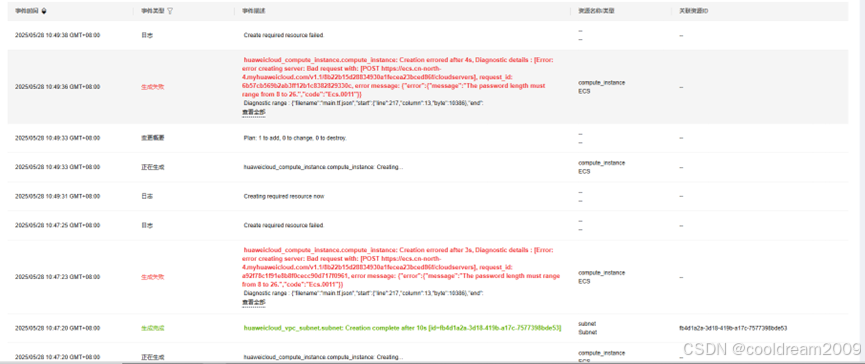
华为云Flexus+DeepSeek征文|华为云Flexus云服务器X实例上部署Dify:打造高效的开源大语言模型应用开发平台
目录 前言 1 Dify与华为云部署概述 1.1 什么是 Dify 1.2 华为云与 Flexus 云服务器的优势 2 云服务器部署 Dify 的步骤详解 2.1 模板选择 2.2 参数配置 2.3 资源栈设置 2.4 确认部署信息并执行 3 部署成功后的操作与平台使用指南 3.1 访问平台 3.2 设置管理员账号 …...

[git每日一句]Your branch is up to date with ‘origin/master‘
这句话是 Git 版本控制系统的提示信息,意思是: "你当前所在的分支已经与远程仓库(origin)的 master 分支同步,没有需要推送的提交。" 详细解释: Your branch - 指你当前所在的本地分支 is up …...

高密爆炸警钟长鸣:AI为化工安全戴上“智能护盾”
一、高密爆炸:一声巨响,撕开化工安全“伤疤” 2025年5月27日,山东高密友道化学有限公司的车间爆炸声,像一把利刃划破了化工行业的平静。剧烈的冲击波将车间夷为平地,黑色蘑菇云腾空而起,刺鼻的化学气味弥漫…...
机器人学基础——正运动学(理论推导及c++实现)
机器人正运动学 机器人正运动学一般是指从机器人的关节位置到基于参考坐标系下末端执行器的位置。 平移变换和旋转变换 平移变换 假设我们有两个坐标系A和B,坐标系A与B的方位相同,xyz轴的指向都是一致的,即没有旋转变换。有一点p…...
[网页五子棋][对战模块]处理连接成功,通知玩家就绪,逻辑问题(线程安全,先手判定错误)
文章目录 处理连接成功通知玩家就绪逻辑图问题 1:线程安全问题 2:先手判定错误两边都是提示:轮到对方落子 处理连接成功 实现 GameAPI 的 afterC…...
 生产环境模型版本控制与回滚实战指南)
TensorFlow Extended (TFX) 生产环境模型版本控制与回滚实战指南
TFX 版本控制核心架构 TFX 通过以下组件构建完整的模型生命周期管理系统: ML Metadata (MLMD):记录所有实验和管道的元数据Pusher 组件:负责模型部署与版本标记Model Registry:集中式模型存储库&#x…...
【Web应用】若依框架:基础篇11功能详解-系统接口
文章目录 ⭐前言⭐一、课程讲解⭐二、自己动手实操⭐总结 标题详情作者JosieBook头衔CSDN博客专家资格、阿里云社区专家博主、软件设计工程师博客内容开源、框架、软件工程、全栈(,NET/Java/Python/C)、数据库、操作系统、大数据、人工智能、工控、网络、…...

【Docker项目实战篇】Docker部署PDF查看器PdfDing
【Docker项目实战篇】Docker部署PDD查看器PdfDing 一、PdfDing介绍1.1 PdfDing简介1.2 PdfDing主要特点1.3 主要使用场景 二、本次实践规划2.1 本地环境规划2.2 本次实践介绍 三、本地环境检查3.1 检查Docker服务状态3.2 检查Docker版本3.3 检查docker compose 版本 四、下载Pd…...

Redis 常用数据类型和命令使用
目录 1 string 2 hash 3 list 4 set集合 5 zset有序集合 1 string 值可以是字符串、数字和二进制的value,值最大不能超过512MB 应用场景: 应用程序缓存 计数器 web共享session 限速 1.1 设置单个键值 set <key> value [EX seconds|PX…...

【Linux系统】第八节—进程概念(上)—冯诺依曼体系结构+操作系统+进程及进程状态+僵尸进程—详解!
hi,我是云边有个稻草人 偶尔中二的博主^(* ̄(oo) ̄)^,与你分享专业知识,祝博主们端午节快乐! Linux—本节博客所属专栏—持续更新中—欢迎订阅! 目录 一、冯诺依曼体系结构 二、操作系统(Opera…...

WPF 全局加载界面、多界面实现渐变过渡效果
WPF 全局加载界面与渐变过渡效果 完整实现方案 MainWindow.xaml <Window x:Class"LoadingScreenDemo.MainWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.com/winfx/2006/xaml&quo…...

WebSocket与实时对话式AI服务的集成
WebSocket与实时对话式AI服务的集成 在现代对话式AI系统中,传统的HTTP请求-响应模型已难以满足实时交互的体验需求。特别是用户对响应速度、逐字输出、会话上下文保持等方面提出更高要求时,需要一种能够建立持久连接并支持双向通信的协议。WebSocket正是在这一背景下,成为A…...

【xmb】】内部文档148344599
这里写自定义目录标题 CyberDog 2 仿真智能物流配送系统 – 初赛设计报告摘要目录1 引言2 任务与需求分析3 系统总体设计4 核心算法与模块实现5 仿真测试与结果分析6 结论与展望 CyberDog 2 仿真智能物流配送系统 – 初赛设计报告 团队名称: (晚点写&am…...

MobaXterm国内下载与安装使用教程
MobaXterm是一款为 Windows 用户量身打造的远程终端工具,它将多种网络功能集成在一个轻量级、便携式的界面中,尤其适合需要频繁与远程主机交互的开发者、系统运维工程师以及科研技术人员。无论是管理 Linux 服务器、远程执行命令,还是图形化运…...
数据结构——优先级队列(PriorityQueue)
1.优先级队列 优先级队列可以看作队列的另一个版本,队列的返回元素是由是由插入顺序决定的,先进先出嘛,但是有时我们可能想要返回优先级较高的元素,比如最大值?这种场景下就由优先级队列登场。 优先级队列底层是由堆实…...
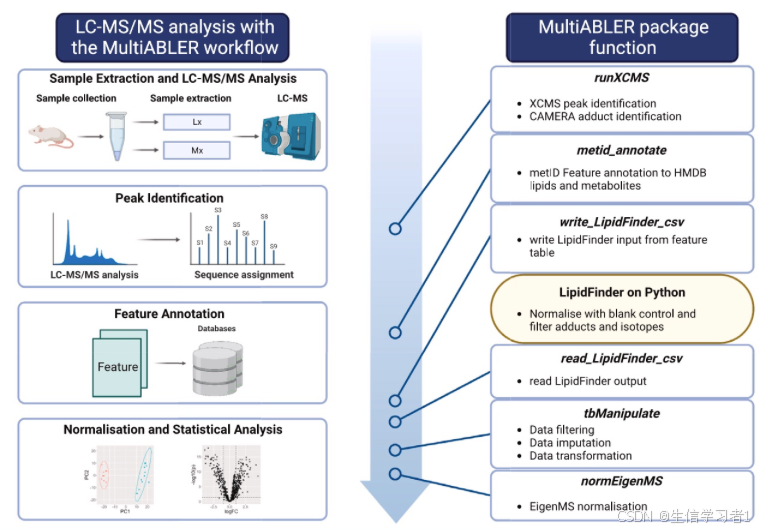
代谢组数据分析(二十六):LC-MS/MS代谢组学和脂质组学数据的分析流程
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍加载R包依赖包安装包加载需要的R包数据下载以及转换mzML数据预处理代谢物注释LipidFinder过滤MultiABLER数据预处理过滤补缺失值对数变换数据标准化下游数据分析总结系统信息参考介…...
)
服务器上用脚本跑python深度学习的注意事项(ubantu系统)
bash: $\r: command not found 问题原因: 出现 bash: $\r: command not found 以及路径中出现 \r 通常是因为脚本文件是在Windows系统下编辑,然后在Linux(如Ubuntu)系统中运行。在Windows系统中,文本文件的换行符是 \…...

【ARM】【FPGA】【硬件开发】Chapter.1 AXI4总线协议
Chapter.1 AXI4总线协议 作者:齐花Guyc(CAUC) 一、总线介绍 AXI4总线 AXI4总线就像是SoC内部的“高速公路”,负责在不同硬件模块之间高效传输数据。 AXI4协议通过 5个独立通道 传输数据和控制信号,每个通道都有自己的信号线,互…...

青少年编程与数学 02-020 C#程序设计基础 10课题、桌面应用开发
青少年编程与数学 02-020 C#程序设计基础 10课题、桌面应用开发 一、桌面应用1. 主要特点2. 常见类型3. 优势4. 局限性 二、开发步骤1. 准备工作2. 创建项目3. 开发应用4. 运行调试5. 打包发布 三、Windows 窗体应用(一)定义(二)特…...
把 jar 打包成 exe
1. 把自己的项目先正常打成jar包 2. 使用exe4j工具将jar转换为exe 2.1 exe4j下载地址:https://www.ej-technologies.com/download/exe4j/files 2.2 下载完成之后激活 2.3 可以点击Change License,输入秘钥L-g782dn2d-1f1yqxx1rv1sqd 2.4 直接下一步…...
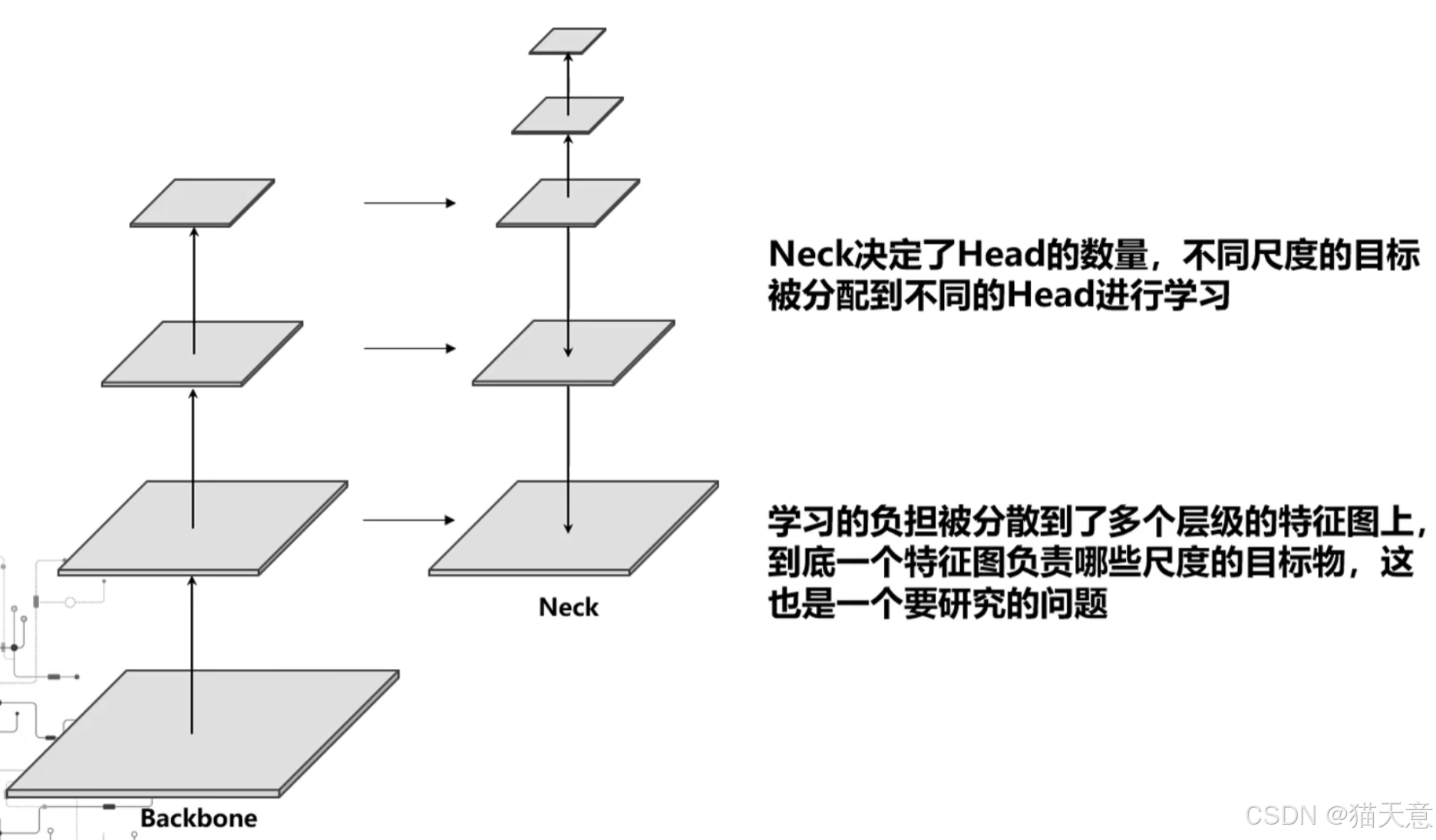
【目标检测】检测网络中neck的核心作用
1. neck最主要的作用就是特征融合,融合就是将具有不同大小感受野的特征图进行了耦合,从而增强了特征图的表达能力。 2. neck决定了head的数量,进而潜在决定了不同尺度样本如何分配到不同的head,这一点可以看做是将整个网络的多尺…...
【经验】Ubuntu中设置terminator的滚动行数、从Virtualbox复制到Windows时每行后多一空行
1、设置terminator的滚动行数 1.1 问题描述 在终端 terminator 中,调试程序时,只能查看有限行数的打印日志,大约是500行,怎么能增加行数 1.2 解决方法 1)安装terminator sudo apt install terminator和 terminato…...