elasticsearch 常用数据类型详解和范例
主要内容
-
elasticsearch 中的字符串(keyword)类型 的详解和范例
-
elasticsearch 中的字符串/文本(text)类型 的详解和范例
-
elasticsearch 中的数字(数值)类型 的详解和范例
-
elasticsearch 中的布尔(boolean)类型 的详解和范例
-
elasticsearch 中的日期(date)类型 的详解和范例
-
elasticsearch 中的地理(geo_point、geo_shape)类型 的详解和范例
-
elasticsearch 中的对象类型 的详解和范例
-
elasticsearch 中的数组类型 的详解和范例
概要
本篇文章主要讲解elasticsearch在业务中经常用到的字段类型,通过大量的范例来学习和理解不同字段类型的应用场景。范例elasticsearch使用的版本为7.17.5。
简述
在Elasticsearch的映射关系中,每个字段都对应一个数据类型或者字段类型,这些类型规范了字段存储的值和用途。例如,可以将字符串索引到text和keyword字段。text字段的值用于全文搜索;keyword字段的值存储时不会被分词建立索引,主要用于统计计算等操作。
内容
字符串(keyword)类型 详解
-
keyword类型用于存储结构化的内容
-
keyword类型是不进行切分的字符串类型
-
不进行切分
-
在索引时,对keyword类型的数据不进行切分,直接构建倒排索引
-
在搜索时,对该类型的查询字符串不进行切分后的部分匹配
-
keyword类型数据一般用于对文档的过滤、排序和聚合
-
在现实场景中,keyword经常用于描述ID、电子邮件、主机名、邮政编码、标签、姓名、产品类型、用户ID、URL和状态码等
-
keyword类型数据一般用于比较字符串是否相等,不对数据进行部分匹配,因此一般查询这种类型的数据时使用term查询
字符串(keyword)类型 范例
1.创建user索引库并插入一条数据
#建立一个人名索引,设定姓名字段为keyword字段
PUT /user
{"mappings": {"properties": {"user_name": {"type": "keyword"}}}
}#插入数据
PUT /user/_doc/001
{"user_name": "张三"
}2.使用term查询刚刚写入的数据
#使用term查询刚刚写入的数据
GET /user/_search
{"query": {"term": {"user_name": {"value": "张三"}}}
}#返回的结果如下
{"took": 0,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 0.2876821,"hits": [{"_index": "user","_type": "_doc","_id": "001","_score": 0.2876821,"_source": {"user_name": "张三"}}]}
}- 由搜索结果可以看出,使用term进行全字符串匹配"张三"可以搜索到命中文档。
3.使用match查询刚刚写入的数据中带有"张"的记录
#使用match查询刚刚写入的数据中带有"张"的记录
GET /user/_search
{"query": {"match": {"user_name": "张"}}
}#返回的结果如下
{"took": 0,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 0,"relation": "eq"},"max_score": null,"hits": []}
}- 由搜索结果可以看出,对keyword类型使用match搜索进行匹配是不会命中文档的。
字符串/文本(text)类型 的详解
-
text类型是可进行切分的字符串类型。
-
可切分
-
在索引时,可按照相应的切词算法对文本内容进行切分,然后构建倒排索引
-
在搜索时,对该类型的查询字符串按照用户的切词算法进行切分,然后对切分后的部分匹配打分
-
-
-
text类型用于进行全文搜索(也称为全文检索),text类型允许用户在每个全文字段中搜索单个单词
-
在现实场景中,text经常用于电子邮箱正文或产品描述的全文等
-
text不适合进行排序,也不适合进行聚合计算。如果字段需要聚合计算或者排序,推荐使用keyword类型
字符串/文本(text)类型 的范例(一)
1.创建一个hotel索引库,并插入一条数据
#建立一个hotel索引,可以设定title字段为text字段
PUT /hotel
{"mappings": {"properties": {"title": {"type": "text"}}}
}#插入数据
POST /hotel/_doc/001
{"title":"文雅酒店"
}2.使用term查询刚刚写入的数据
#按照普通的term进行搜索
GET /hotel/_search
{"query": {"term": {"title": {"value": "文雅酒店"}}}
}#返回的结果如下
{"took" : 570,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]}
}-
根据返回的结果可知,上面的请求并没有搜索到文档。
-
term搜索用于搜索值和文档对应的字段是否完全相等,而对于text类型的数据,在建立索引时ES已经进行了切分并建立了倒排索引,因此使用term没有查询到数据。一般情况下,搜索text类型的数据时应使用match搜索。
3.使用match查询刚刚写入的数据中带有"文雅"的记录
#按照普通的match进行搜索
GET /hotel/_search
{"query": {"match": {"title": "文雅"}}
}#返回结果如下
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.5753642,"hits" : [{"_index" : "hotel","_type" : "_doc","_id" : "001","_score" : 0.5753642,"_source" : {"title" : "文雅酒店"}}]}
}字符串/文本(text)类型 的范例(二)
1.创建myindex-2_13索引库,并插入数据
#创建索引映射并指定tagname字段的字段类型为text类型
PUT myindex-2_13
{"mappings": {"properties": {"tagname": {"type": "text"}}}
}#插入文档数据
PUT myindex-2_13/_doc/1
{"tagname":"江苏省"
}#插入文档数据
PUT myindex-2_13/_doc/2
{"tagname":"河北省"
}2.根据tagname字段内容分词,然后对所有分词进行匹配搜索
#根据tagname字段内容分词,然后对所有分词进行匹配搜索
GET myindex-2_13/_doc/_search
{"query": {"match": {"tagname": "河南省"}}
}#返回的结果如下
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 0.8754687,"hits" : [{"_index" : "myindex-2_13","_type" : "_doc","_id" : "2","_score" : 0.8754687,"_source" : {"tagname" : "河北省"}},{"_index" : "myindex-2_13","_type" : "_doc","_id" : "1","_score" : 0.18232156,"_source" : {"tagname" : "江苏省"}}]}
}-
以上搜索结果中把"江苏省"和"河北省"这两行数据都返回了,这是因为目前默认的分词器把"河南省"分了"河"、"南"、"省"三个词,而"河北省"和"江苏省"分别分成"河"、"北"、"省"和"江"、"苏"、"省",这两个词被分词后都有一个"省"字,所以搜索时被全文匹配到了。在实际业务中,如果我们要对字段的内容进行全文搜索,可以使用text类型;如果要聚合查询或者精准匹配,则尽量使用keyword类型。
字符串/文本(text)类型 的范例(三)
-
对于大多数想要对文本字段执行更过操作的用户,也可以使用多字段映射,其中既有text类型可以用于全文检索,又有keyword类型可以用于聚合分析,语法如下:
PUT 索引库名称 {"mappings": {"properties": {"my_field": {"type": "text","fields": {"keyword": {"type": "keyword"}}}}} } -
由以上语句可知,my_field字段的映射关系是:父字段类型是text类型,子字段类型是keyword类型。
1.创建myindex-2_14索引库,并插入数据
#创建索引映射
PUT myindex-2_14
{"mappings": {"properties": {"tagname": {"type": "text","fields": {"keyword": {"type": "keyword"}}}}}
}#插入文档数据
PUT myindex-2_14/_doc/1
{"tagname":"江苏省"
}#插入文档数据
PUT myindex-2_14/_doc/2
{"tagname":"河北省"
}2.根据父字段(text类型)搜索符合要求的文档数据
#根据父字段(text类型)搜索符合要求的文档数据
GET myindex-2_14/_doc/_search
{"query": {"match": {"tagname": "河南省"}}
}#返回的结果为
{"took" : 1029,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 0.8754687,"hits" : [{"_index" : "myindex-2_14","_type" : "_doc","_id" : "2","_score" : 0.8754687,"_source" : {"tagname" : "河北省"}},{"_index" : "myindex-2_14","_type" : "_doc","_id" : "1","_score" : 0.18232156,"_source" : {"tagname" : "江苏省"}}]}
}-
其中,使用tagname字段的父字段(text类型)进行搜索,因为父类型是text类型。所以搜索时会进行分词。结果返回了包含"河北省"和"江苏省"的文档信息
3.利用tagname字段的子字段(keyword类型)进行匹配查询
#利用tagname字段的子字段(keyword类型)进行匹配查询
GET myindex-2_14/_search
{"query": {"match": {"tagname.keyword": "江苏省"}}
}#返回结果为
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.6931471,"hits" : [{"_index" : "myindex-2_14","_type" : "_doc","_id" : "1","_score" : 0.6931471,"_source" : {"tagname" : "江苏省"}}]}
}-
其中,tagname.keyword代表使用了tagname字段的子字段(keyword类型)进行了不分词搜索,需要保证搜索的内容和字段存储的内容完全匹配,所以从当前索引库中匹配到了数据。
elasticsearch 中的数字(数值)类型 的详解
-
elasticsearch支持的数据类型有long、integer、short、byte、double、float、scaled_float、half_float和unsigned_long等。各类型所表达的数值范围可以参考官方文档,网址为Numeric field types | Elasticsearch Guide [8.7] | Elastic。
-
为节约存储空间并提升搜索和索引的效率,在实际应用中,在满足需求的情况下应尽可能选择范围小的数据类型。比如,年龄字段的取值最大值不会超过200,因此选择byte类型即可
-
数值类型的数据也可用于对进行过滤、排序和聚合
-
对于数值型数据,一般使用term搜索或者范围搜索
elasticsearch 中的数字(数值)类型 的范例(一)
1.更新hotel索引库的mapping,并为hotel索引库定义价格、星级和评论数等字段;更新后再插入数据。
#一个酒店搜索项目,酒店的索引除了包含酒店名称和城市之外,还需要定义价格、星级和评论数等。
PUT /hotel/_mapping
{"properties": {"city": {"type": "keyword"},"price": {"type": "double"},"start": {"type": "byte"},"comment_count": {"type": "integer"}}
}#插入数据
POST /hotel/_doc/001
{"title":"文雅酒店","city":"上海","price":270,"start":10,"comment_count":2
}2.搜索价格为200~300(包含200和300)的酒店
#搜索价格为200~300(包含200和300)的酒店
GET /hotel/_search
{"query": {"range": {"price": {"gte": 200,"lte": 300}}}
}#返回结果如下
{"took" : 596,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "hotel","_type" : "_doc","_id" : "001","_score" : 1.0,"_source" : {"title" : "文雅酒店","city" : "上海","price" : 270,"start" : 10,"comment_count" : 2}}]}
}elasticsearch 中的数字(数值)类型 的范例(二)
1.创建索引并创建字段映射关系
#创建索引并创建字段映射关系
PUT myindex-2_09
{"mappings": {"properties": {"number": {"type": "integer"},"time_in_secondes": {"type": "float"},"price": {"type": "scaled_float","scaling_factor": 100}}}
}#插入文档数据
PUT myindex-2_09/_doc/1?refresh
{"number":1,"time_in_secondes":1.001,"price":1.11
}-
在以上语句创建的索引映射中,"scaling_factor"参数表示数值在存储时使用了缩放因子,该值在存储时乘以缩放因子并四舍五入到最接近long类型的值(比如1.11实际存储的数据是111).注意,这个参数是必不可少的。
-
就上面范例中的数字类型而言,他们可以存储任何数字,但是我们在使用时尽量选择可以满足需求的最小数值类型,这样可以更有效地编制索引和进行搜索,同时也可以节省一部分的存储空间。
2.精确查询price为1.11的数据
#精确查询price为1.11的数据
GET myindex-2_09/_search
{"query": {"term": {"price": {"value": "1.11"}}}
}elasticsearch 中的布尔(boolean)类型 的详解
-
布尔字段接受JSON格式的true和false,但也可以接受解释为真或假的字符串,false,"false",true,"true"
-
布尔类型使用boolean定义,用于业务中的二值表示,如商品是否售罄,房屋是否已租,酒店房间是否满房等。
elasticsearch 中的布尔(boolean)类型 的范例(一)
1.一个酒店搜索项目,酒店的索引除了包含酒店名称、城市、价格、星级、评论数之外,还需要定义是否 满房等。其次插入数据
#一个酒店搜索项目,酒店的索引除了包含酒店名称、城市、价格、星级、评论数之外,还需要定义是否
满房等。
PUT /hotel/_mapping
{"properties": {"full_room": {"type": "boolean"}}
}#插入数据
POST /hotel/_doc/001
{"title":"文雅酒店","city":"上海","price":270,"start":10,"comment_count":2,"full_room":true
}2.查询满房的酒店
#查询满房的酒店
GET hotel/_search
{"query": {"term": {"full_room": {"value": "true"}}}
}#返回结果如下
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.2876821,"hits" : [{"_index" : "hotel","_type" : "_doc","_id" : "001","_score" : 0.2876821,"_source" : {"title" : "文雅酒店","city" : "上海","price" : 270,"start" : 10,"comment_count" : 2,"full_room" : true}}]}
}elasticsearch 中的布尔(boolean)类型 的范例(二)
1.创建索引myindex-2_03映射并指定is_published字段类型为布尔类型
#创建索引映射并指定is_published字段类型为布尔类型
PUT myindex-2_03
{"mappings": {"properties": {"is_published": {"type": "boolean"}}}
}#新增数据,字段值必须和映射类型匹配
POST myindex-2_03/_doc/1?pretty
{"is_published": "true"
}POST myindex-2_03/_doc/2?pretty
{"is_published": true
}2.查询索引库中is_publish字段的值是true的数据
#查询索引库中is_publish字段的值是true的数据
GET myindex-2_03/_search
{"query": {"term": {"is_published": {"value": "true"}}}
}
#返回结果如下
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.6931471,"hits" : [{"_index" : "myindex-2_03","_type" : "_doc","_id" : "1","_score" : 0.6931471,"_source" : {"is_published" : "true"}}]}
}3.在使用布尔类型字段时需要注意的是,布尔类型的查询不能使用0或者1代替,否则会抛出异常
#在使用布尔类型字段时需要注意的是,布尔类型的查询不能使用0或者1代替,否则会抛出异常
POST myindex-2_03/_doc/3?pretty
{"is_published": 1
}#返回结果如下
{"error" : {"root_cause" : [{"type" : "mapper_parsing_exception","reason" : "failed to parse field [is_published] of type [boolean] in
document with id '3'. Preview of field's value: '1'"}],"type" : "mapper_parsing_exception","reason" : "failed to parse field [is_published] of type [boolean] in document
with id '3'. Preview of field's value: '1'","caused_by" : {"type" : "json_parse_exception","reason" : "Current token (VALUE_NUMBER_INT) not of boolean type\n at [Source:
(ByteArrayInputStream); line: 2, column: 20]"}},"status" : 400
}#可以看到,使用1作为筛选值进行查询时不能正确地转换为布尔类型的值。如果需要对布尔值进行转换,可以使用
"运行时"脚本来处理
GET myindex-2_03/_search
{"fields": [{"field": "weight"}],"runtime_mappings": {"weight": {"type": "long","script": "emit(doc['is_published'].value?1:0)"}}
}
#返回结果如下
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "myindex-2_03","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"is_published" : false},"fields" : {"weight" : [0]}},{"_index" : "myindex-2_03","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"is_published" : "true"},"fields" : {"weight" : [1]}}]}
}elasticsearch 中的日期(date)类型 的详解
-
JSON格式规范中没有对日期数据类型进行定义。
-
elasticsearch一般使用如下形式表示日期类型数据
-
格式化的日期字符串,例如 2015-01-01 或 2015/01/01 12:10:30
-
毫秒级的长整型(一个表示自纪元以来毫秒数的长整形数字),表示从1970年1月1日0点到现在的毫秒数
-
秒级别的整形(表示从纪元开始的秒数的整数),表示从1970年1月1日0点到现在的秒数
-
-
在Elasticsearch内部,日期转换为UTC(如果指定了时区),并存储为毫秒数时间戳。
-
日期类型的默认格式为strict_date_optional_time||epoch_millis。其中,strict_date_optional_time的含义是严格的时间类型,支持yyyy-MM-dd、yyyyMMdd、yyyyMMddHHmmss、yyyy-MM-ddTHH:mm:ss、yyyy-MM-ddTHH:mm:ss.SSS和yyyy-MM-ddTHH:mm:ss:SSSZ等格式;epoch_millis的含义是从1970年1月1日0点到现在的毫秒数。
-
Elasticsearch中的日期类型可以时包含日期格式的字符串,例如"2021-01-01"或"2021/01/01 12:10:30"等格式,也可以使用自纪元以来的毫秒数来表示(注:在Unix中,纪元是指UTC时间1970年1月1日00:00:00)。
-
对日期的查询在内部转换为范围查询,聚合和存储字段的结果将根据与字段关联的日期格式转换回字符串。
-
日期类型默认不支持yyyy-MM-dd HH:mm:ss格式,如果经常使用这种格式,可以在索引的mapping中设置日期字段的 format属性为自定义格式。
-
搜索日期数据时,一般使用范围查询。
elasticsearch 中的日期(date)类型 的范例(一)
1.一个酒店搜索项目,酒店的索引除了包含酒店名称、城市、价格、星级、评论数、是否满房之外,还需要定义日期等。
#一个酒店搜索项目,酒店的索引除了包含酒店名称、城市、价格、星级、评论数、是否满房之外,还需要定义日期等。
PUT /hotel/_mapping
{"properties": {"create_time": {"type": "date"}}
}#插入数据
POST /hotel/_doc/001
{"title":"文雅酒店","city":"上海","price":270,"start":10,"comment_count":2,"full_room":true,"create_time":"20210115"
}2.搜索创建日期为2015年的酒店
#搜索创建日期为2015年的酒店
GET hotel/_search
{"query": {"range": {"create_time": {"gte": "20150101","lt": "20220112"}}}
}#返回结果如下
{"took" : 14,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "hotel","_type" : "_doc","_id" : "001","_score" : 1.0,"_source" : {"title" : "文雅酒店","city" : "上海","price" : 270,"start" : 10,"comment_count" : 2,"full_room" : true,"create_time" : "20210115"}}]}
}3.删除原来的hotel索引库,构建新的hotel索引库,并设置create_time字段的格式为yyyy-MM-dd HH:mm:ss
#设置create_time字段的格式为yyyy-MM-dd HH:mm:ss
PUT /hotel
{"mappings": {"properties": {"title": {"type": "text"},"city": {"type": "keyword"},"price": {"type": "double"},"start": {"type": "byte"},"comment_count": {"type": "integer"},"full_room": {"type": "boolean"},"create_time": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"}}}
}#插入数据
POST /hotel/_doc/001
{"title":"文雅酒店","city":"上海","price":270,"start":10,"comment_count":2,"full_room":true,"create_time":"20210115"
}#返回结果如下
{"error" : {"root_cause" : [{"type" : "mapper_parsing_exception","reason" : "failed to parse field [create_time] of type [date] in document
with id '001'. Preview of field's value: '20210115'"}],"type" : "mapper_parsing_exception","reason" : "failed to parse field [create_time] of type [date] in document
with id '001'. Preview of field's value: '20210115'","caused_by" : {"type" : "illegal_argument_exception","reason" : "failed to parse date field [20210115] with format [yyyy-MM-dd
HH:mm:ss]","caused_by" : {"type" : "date_time_parse_exception","reason" : "Text '20210115' could not be parsed at index 0"}}},"status" : 400
}-
根据错误信息可知,错误的原因是写入的数据格式和定义的数据格式不同
3.插入create_time的格式为yyyy-MM-dd HH:mm:ss数据
#插入create_time的格式为yyyy-MM-dd HH:mm:ss数据
POST /hotel/_doc/001
{"title":"文雅酒店","city":"上海","price":270,"start":10,"comment_count":2,"full_room":true,"create_time":"2021-01-15 01:23:30"
}elasticsearch 中的日期(date)类型 的范例(二)
#创建索引映射并指定date字段的字段类型为日期类型
PUT myindex-2_04
{"mappings": {"properties": {"date":{"type": "date"}}}
}#插入文档数据
PUT myindex-2_04/_doc/1
{"date":"2015-01-01"
}#插入文档数据
PUT myindex-2_04/_doc/2
{"date": "2015-01-01T12:10:30Z"
}#插入文档数据
PUT myindex-2_04/_doc/3
{"date":1420070400001
}
#以上3种不同格式的日期数据都被插入到索引库中。#创建索引并为日期类型的字段指定具体的日期格式
PUT myindex-2_05
{"mappings": {"properties": {"date": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"}}}
}
#以下语句插入文档数据时将会抛出异常,因为日期内容不符合映射格式
PUT myindex-2_05/_doc/1
{"date":"2015-01-01"
}#以下语句插入文档数据时将会抛出异常,因为日期内容不符合映射格式
PUT myindex-2_05/_doc/2
{"date":"2015-01-01T12:10:30Z"
}#以下语句插入文档数据时将会抛出异常,因为日期内容不符合映射格式
PUT myindex-2_05/_doc/3
{"date":1420070400001
}
#以下语句文档数据正常插入,因为日期内容符合字段指定的日期格式
PUT myindex-2_05/_doc/4
{"date":"2015-01-01 12:02:56"
}elasticsearch 中的地理(geo_point、geo_shape)类型 的详解
-
地理位置(geo)是用于存储经纬度的字段类型。
-
用例场景如下
-
在边界框内、中心点的特定距离内或多边形内查找地理点
-
按地理位置或距中心点的距离聚合文档
-
将距离整合到文档的相关性得分中
-
按距离对文档排序
-
-
在生活中,我们可能会遇到根据当前所在的位置找到离自己最近的符合条件的一些商店、酒店之类的情况。在elasticsearch中也支持这种业务的查询,它主要支持两种类型的地理查询:一种是地理点(geo_point)查询,即经纬度查询;另一种是地理形状(geo_shape)查询,支持点、线、圈、多边形查询等。
geo_shape
-
geo_shape(空间位置)类型支持地理形状的搜索,即点、线、圈、多边形搜索等。比如我们想要找到最接近给定位置的路线,就可以使用此类型。语法如下
PUT /索引库名称
{"mappings": {"properties": {"location": {"type": "geo_shape"}}}
}geo_point
-
在移动互联网时代,用户借助移动设备产生的消费越来越多。例如:用户要根据某个地理位置来搜索酒店,此时可以把酒店的经纬度数据设置为地理数据类型。该类型的定义需要在mapping中指定目标字段的数据类型为geo_point类型
-
elasticseach也提供了地理点查询的类型,即geo_point类型。使用语法如下
PUT 索引库名称
{"mappings": {"properties": {"location": {"type": "geo_point"}}}
}elasticsearch 中的地理(geo_point)类型 范例
#一个酒店搜索项目,酒店的索引除了包含酒店名称、城市、价格、星级、评论数、是否满房、日期之外,还需要定义位
置等。
PUT /hotel/_mapping
{"properties": {"location": {"type": "geo_point"}}
}#插入数据
POST /hotel/_doc/001
{"title":"文雅酒店","city":"上海","price":270,"start":10,"comment_count":2,"full_room":true,"create_time":"2021-01-15 01:23:30","location":{"lat":40.012134,"lon":116.497553}
}#搜索指定的两个地理位置形成的矩形范围中包含的酒店信息
GET hotel/_search
{"query": {"bool": {"must": [{"match_all": {}}],"filter": {"geo_bounding_box": {"location": {"top_left": {"lat": 40.73,"lon": -74.1},"bottom_right": {"lat": 40.01,"lon": -71.12}}}}}}
}#搜索指定的多个地理位置形成的多边形范围中包含酒店信息
GET /hotel/_search
{"query": {"bool": {"must": [{"match_all": {}}],"filter": {"geo_polygon": {"location": {"points": [{"lat": 40.73,"lon": -74.1},{"lat": 40.83,"lon": -75.1},{"lat": 40.93,"lon": -76.1}]}}}}}
}#搜索指定位置1000km范围内的酒店数据
GET /hotel/_search
{"query": {"bool": {"must": [{"match_all": {}}],"filter":{"geo_distance": {"distance": "1000km","location": {"lat": 40.73,"lon": -74.1}}}}}
}#搜索距离指定位置一定范围内有多少个酒店
GET /hotel/_search
{"size": 0,"aggs": {"count_by_distinct": {"geo_distance": {"field": "location","origin": {"lat": 52.376,"lon": 4.894},"ranges": [{"from": 100,"to": 300}],"unit": "mi","distance_type": "arc"}}}
}elasticsearch 中的地理(geo_shape)类型 范例
1.创建索引映射并指定location字段的字段类型为geo_shape类型
#创建索引映射并指定location字段的字段类型为geo_shape类型
PUT myindex-geo_shape
{"mappings": {"properties": {"location": {"type": "geo_shape"}}}
}#插入地点相关信息
POST /myindex-geo_shape/_doc?refresh
{"name": "Wind & Wetter,Berlin,Germany","location": {"type": "point","coordinates": [13.400544,52.530286]}
}2.搜索指定的两个位置范围内的地点
#搜索指定的两个位置范围内的地点
GET /myindex-geo_shape/_search
{"query": {"bool": {"must": [{"match_all": {}}],"filter": {"geo_shape": {"location": {"shape": {"type": "envelope","coordinates": [[13,53],[14,52]]},"relation": "within"}}}}}
}#返回的结果
{"took" : 3,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "myindex-geo_shape","_type" : "_doc","_id" : "oKSWWYcB7w4YX5_iGU4l","_score" : 1.0,"_source" : {"name" : "Wind & Wetter,Berlin,Germany","location" : {"type" : "point","coordinates" : [13.400544,52.530286]}}}]}
}-
由以上语句可知,根据需求返回了两个地理位置范围内符合条件的地点。
elasticsearch 中的对象类型 的详解
-
elasticsearch中的object类型实际就是JSON数据格式
-
在实际业务中,一个文档需要包含其他内部对象。例如,在酒店搜索需求中,用户希望酒店信息中包含评论数据。评论数据分为好评数量和差评数量。为了支持这种业务,在ES中可以使用对象类型。
-
对象类型和数组类型一样,对象类型也不用事先定义,在写入文档的时候ES会自动识别并转换为对象类型。
elasticsearch 中的对象类型 的范例(一)
#向hotel中添加一条数据
PUT /hotel/_doc/002
{"title": "好再来酒店","city": "青岛","price": 578.23,"comment_info": {"properties": {"favourable_comment": 199,"negative_comment": 68}}
}
#执行以上DSL后,索引hotel增加了一个字段comment_info,它有两个属性,分别是favourable_comment
和negative_comment,二者的类型都是long。#查看hotel的mapping
GET /hotel/_mapping
#hotel 的mapping 响应结果为:
{"hotel" : {"mappings" : {"properties" : {"city" : {"type" : "keyword"},"comment_count" : {"type" : "integer"},"comment_info" : {"properties" : {"properties" : {"properties" : {"favourable_comment" : {"type" : "long"},"negative_comment" : {"type" : "long"}}}}},"create_time" : {"type" : "date","format" : "yyyy-MM-dd HH:mm:ss"},"full_room" : {"type" : "boolean"},"location" : {"type" : "geo_point"},"price" : {"type" : "double"},"start" : {"type" : "byte"},"title" : {"type" : "text"}}}}
}
#根据对象类型的属性进行搜索,可以直接用"."操作符进行指向。
#例如搜索hotel索引中好评数大于200的文档
GET /hotel/_search
{"query": {"range": {"comment_info.properties.favourable_comment": {"gte": 36}}}
}
#当然,对象内部还可以包含对象
#评论信息字段comment_info可以增加前3条好评数据
POST /hotel/_doc/002
{"title": "好再来酒店","city": "青岛","price": 578.23,"comment_info": {"properties": {"favourable_comment": 199,"negative_comment": 68,"top3_favourable_comment": {"top1": {"content": "干净整洁的一家酒店","score":87},"top2": {"content": "服务周到,停车方便","score":89},"top3": {"content": "闹中取静,环境优美","score":90}}}}
}elasticsearch 中的对象类型 的范例(二)
#创建索引映射
PUT myindex-object
{"mappings": {"properties": {"region": {"type": "keyword"},"manager": {"properties": {"age": {"type": "integer"},"name": {"properties": {"first": {"type": "text"},"last": {"type": "text"}}}}}}}
}#对于_id等于1的文档而言,manager是一个对象,该对象中又包含一个name对象,而name对象中有两个键值对。如果需
要向这个索引映射中插入文档,可以使用下面任何一种方式写入#范例一:使用嵌套的JSON数据格式进行写入
#使用嵌套的JSON数据格式进行写入
PUT myindex-object/_doc/1
{"region":"China","manager":{"age":30,"name":{"first":"clay","last":"zhagng"}}
}#范例二:使用简单的JSON数据格式进行写入
#使用简单的JSON数据格式进行写入
PUT myindex-object/_doc/2
{"region": "US","manager.age": 30,"manager.name.first": "John","manager.name.last": "Smith"
}#使用以上两种方式写入数据不会影响数据的存储,但是会影响查询返回的结果。
#查询数据
GET myindex-object/_doc/_search#返回的结果为
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "myindex-object","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"region" : "China","manager" : {"age" : 30,"name" : {"first" : "clay","last" : "zhagng"}}}},{"_index" : "myindex-object","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"region" : "US","manager.age" : 30,"manager.name.first" : "John","manager.name.last" : "Smith"}}]}
}
#以上返回信息的写入格式与查询返回的格式一致。elasticsearch 中的数组类型 的详解
-
ES数组没有定义方式,其使用方式是开箱即用的,即无须事先声明,在写入时把数据用中括号[]括起来,由ES对该字段完成定义。当然,如果事先已经定义了字段类型,在写数据时以数组形式写入,ES也会将该类型转为数组。
elasticsearch 中的数组类型 的范例
#为hotel索引增加一个标签字段,名称为tag
PUT /hotel/_mapping
{"properties": {"tag": {"type": "keyword"}}
}
#查看一下索引hotel的mapping
GET /hotel/_mapping
#返回的结果如下
{"hotel" : {"mappings" : {"properties" : {"city" : {"type" : "keyword"},"comment_count" : {"type" : "integer"},"comment_info" : {"properties" : {"properties" : {"properties" : {"favourable_comment" : {"type" : "long"},"negative_comment" : {"type" : "long"},"top3_favourable_comment" : {"properties" : {"top1" : {"properties" : {"content" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"score" : {"type" : "long"}}},"top2" : {"properties" : {"content" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"score" : {"type" : "long"}}},"top3" : {"properties" : {"content" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"score" : {"type" : "long"}}}}}}}}},"create_time" : {"type" : "date","format" : "yyyy-MM-dd HH:mm:ss"},"full_room" : {"type" : "boolean"},"location" : {"type" : "geo_point"},"price" : {"type" : "double"},"start" : {"type" : "byte"},"tag" : {"type" : "keyword"},"title" : {"type" : "text"}}}}
}
#通过返回的mapping信息来看,新增的tag字段与普通的keyword类型字段没什么区别,现在写入一条数据
PUT /hotel/_doc/004
{"title":"好再来酒店","city":"青岛","price":"578.23","tags":["有车位","免费WIFI"]
}#查询一下写入的数据
GET /hotel/_search#返回的数据为
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "hotel","_type" : "_doc","_id" : "001","_score" : 1.0,"_source" : {"title" : "文雅酒店","city" : "上海","price" : 270,"start" : 10,"comment_count" : 2,"full_room" : true,"create_time" : "2021-01-15 01:23:30","location" : {"lat" : 40.012134,"lon" : 116.497553}}},{"_index" : "hotel","_type" : "_doc","_id" : "002","_score" : 1.0,"_source" : {"title" : "好再来酒店","city" : "青岛","price" : 578.23,"comment_info" : {"properties" : {"favourable_comment" : 199,"negative_comment" : 68,"top3_favourable_comment" : {"top1" : {"content" : "干净整洁的一家酒店","score" : 87},"top2" : {"content" : "服务周到,停车方便","score" : 89},"top3" : {"content" : "闹中取静,环境优美","score" : 90}}}}}},{"_index" : "hotel","_type" : "_doc","_id" : "004","_score" : 1.0,"_source" : {"title" : "好再来酒店","city" : "青岛","price" : "578.23","tags" : ["有车位","免费WIFI"]}}]}
}
#通过以上信息可以看到,写入的数据的tag字段已经是数组类型了。那么,数组类型的数据如何搜索呢?
#数组类型的字段适用于元素类型的搜索方式,也就是说,数组元素适用于什么搜索,数组字段就适用于什么搜索。
#在上面的示例中,数组元素类型是keyword,该类型可以适用于term搜索,则tag字段也可以适用于term搜索
GET /hotel/_search
{"query": {"term": {"tags": {"value": "有车位"}}}
}#ES中的空数组可以作为missing field,即没有值的字段,下面的DSL将插入一条tag为空的数组
POST /hotel/_doc/003
{"title":"环球酒店","city":"青岛","price":"530.00","tags":[]
}相关文章:

elasticsearch 常用数据类型详解和范例
主要内容 elasticsearch 中的字符串(keyword)类型 的详解和范例 elasticsearch 中的字符串/文本(text)类型 的详解和范例 elasticsearch 中的数字(数值)类型 的详解和范例 elasticsearch 中的布尔&#…...
力扣119杨辉三角 II:代码实现 + 方法总结(数学规律法 记忆法/备忘录)
文章目录第一部分:题目第二部分:解法①-数学规律法2.1 规律分析2.2 代码实现2.3 需要思考第三部分:解法②-记忆法(备忘录)第四部分:对比总结第一部分:题目 🏠 链接:119.…...

安装pandas遇到No module named ‘_bz2’ 的解决方案
出现这个问题我们可以按照这篇博客去解决: https://blog.csdn.net/bf96163/article/details/128654915 如果解决不了,可以这样去做: 1.确保安装了 对应的库 // ubuntu安装命令 sudo apt-get install bzip2-devel // centos安装命令 sudo y…...
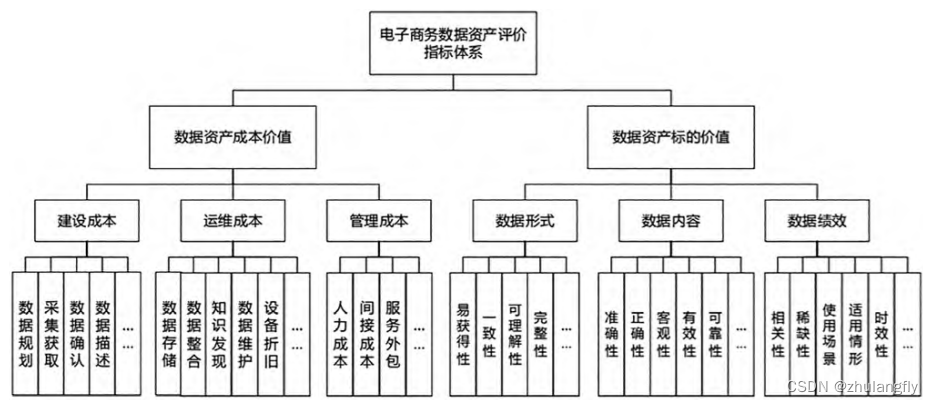
【数据治理-05】什么数据才是货真价实的数据资产,一起聊聊数据资产
在国家层面一些列文件、纲要、政策、办法等政府力量的推动下,数据资产这个词越来越频繁的出现在我们寻常工作当中,现在越来越觉得这个词被滥用,大有“一切数据皆是资产”的感觉,业务数据是资产、技术数据是资产,不能共…...

第三章 ARM处理器体系结构【嵌入式系统】
第三章 ARM处理器体系结构【嵌入式系统】前言推荐第三章 ARM处理器体系结构3.1 概述3.2 ARM处理器的结构3.7 ARM的异常中断处理最后前言 以下内容源自《【嵌入式系统】》 仅供学习交流使用 推荐 无 第三章 ARM处理器体系结构 留着占位 敬请期待 3.1 概述 3.2 ARM处理器的…...

最速下降法
首先,计算函数f的梯度向量:∇f(x1,x2)[2x150x2]\nabla f(x_1,x_2) \begin{bmatrix}2x_1\\50x_2\end{bmatrix}∇f(x1,x2)[2x150x2] 然后,选择一个初始点(x10,x20)(x_1^0,x_2^0)(x10,x20),比如(0,0)(0,0)(0,0)。 接…...
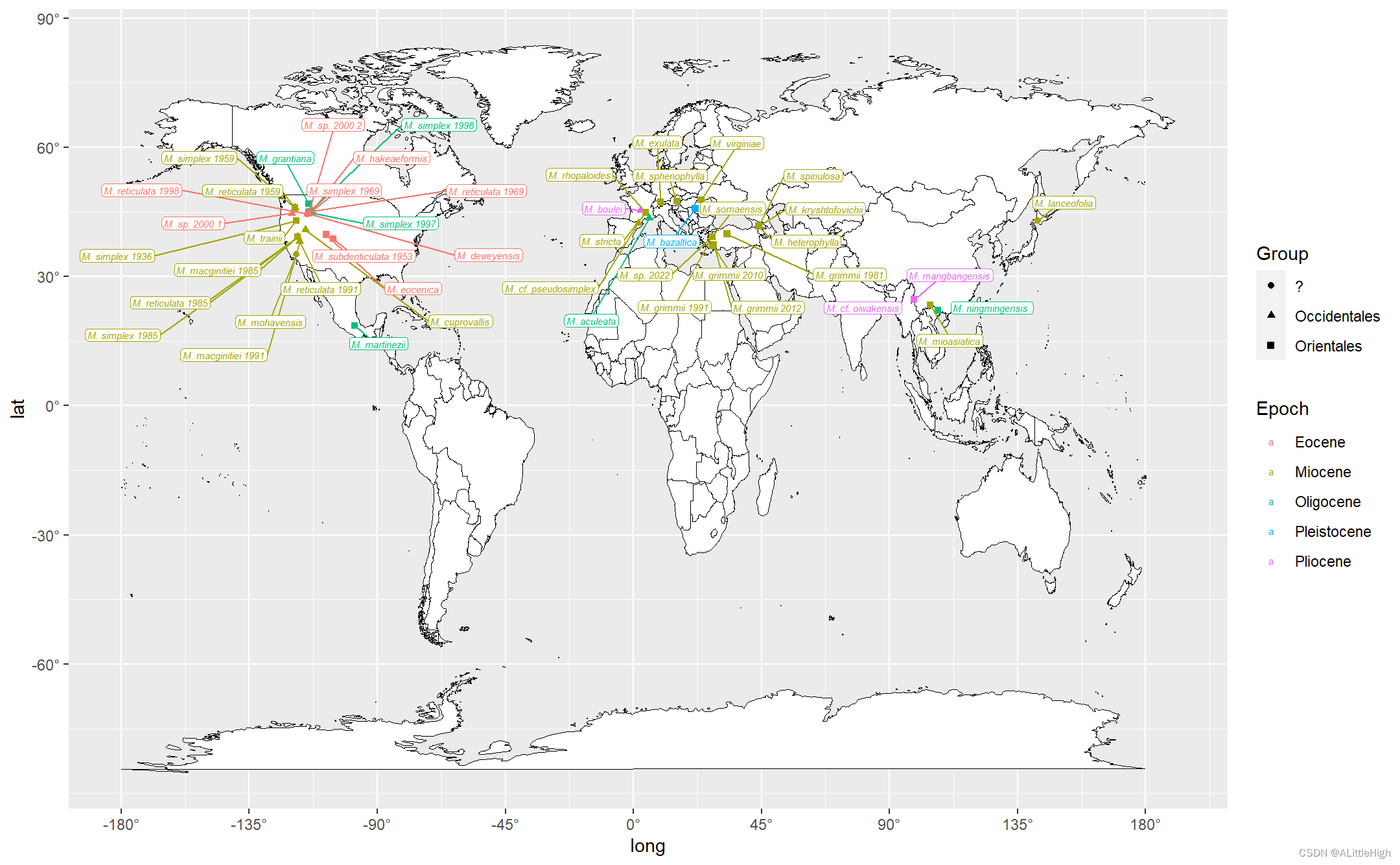
R语言实践——ggplot2+ggrepel绘制散点+优化注释文本位置
简介 书接adjustText实践——调整matplotlib散点图标签,避免重复 上文中,matplotlibadjustText对于我的实例来说并没有起到很好的效果。所以,博主决定在R中利用gglot2ggrepel绘制,期待效果。 操作过程 博主不常使用Rÿ…...
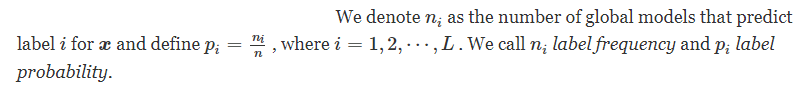
[TIFS 2022] FLCert:可证明安全的联邦学习免受中毒攻击
FLCert: Provably Secure Federated Learning Against Poisoning Attacks | IEEE Journals & Magazine | IEEE Xplore 摘要 由于其分布式性质,联邦学习容易受到中毒攻击,其中恶意客户端通过操纵其本地训练数据和/或发送到云服务器的本地模型更新来毒…...

css3关键帧动画
CSS3关键帧动画是一种在网页设计中常用的技术,通过使用CSS3的关键帧动画功能,可以实现网页上各种形式的动画效果,例如淡入淡出、滑动、旋转、缩放等,这些动画效果可以让网页更加生动有趣,吸引用户的注意力,…...
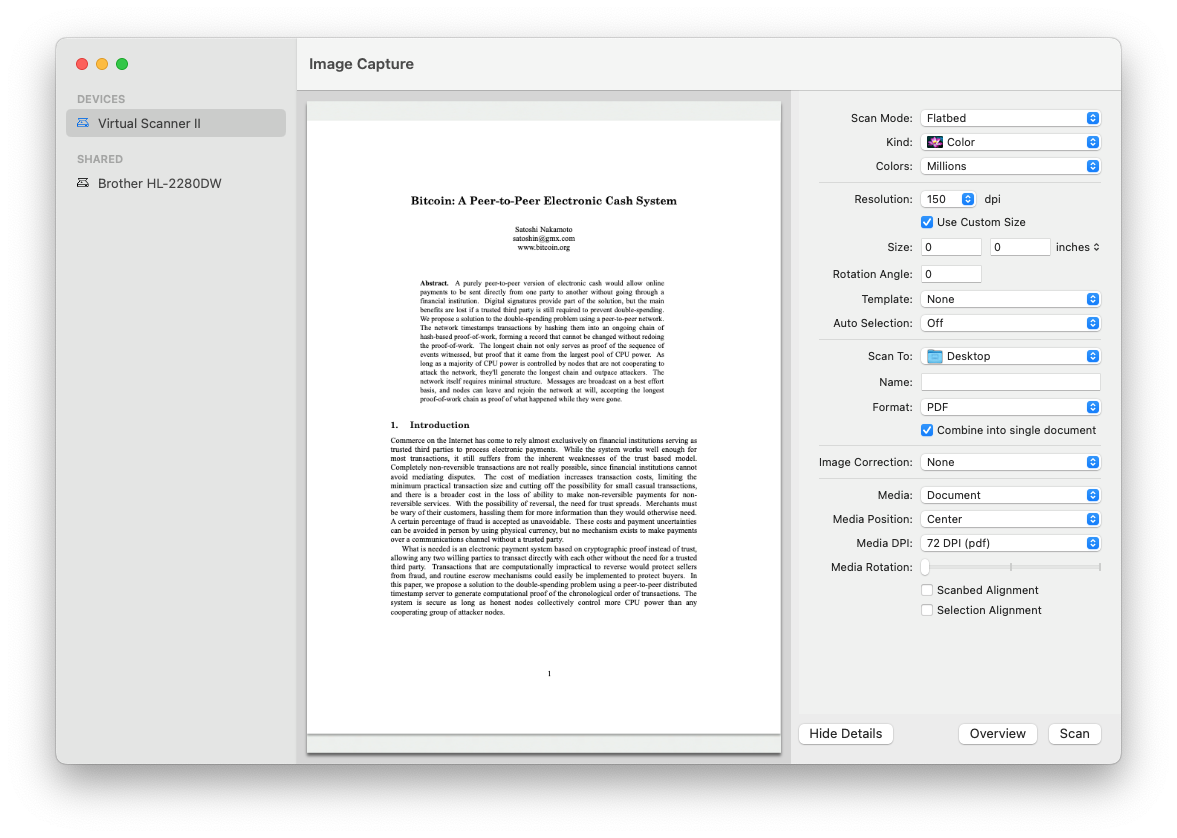
在 macOS Mojave 之后的每一个版本中都隐藏着比特币白皮书(Bitcoin Whitepaper)
今天我在尝试解决打印机故障问题时,发现了自2018年Mojave版本以来,macOS都附带了一份Satoshi Nakamoto(即中本聪)的比特币白皮书PDF副本[1]。 我已经询问了十几位使用Mac的朋友,他们都确认macOS里面有这个文件。这个文…...
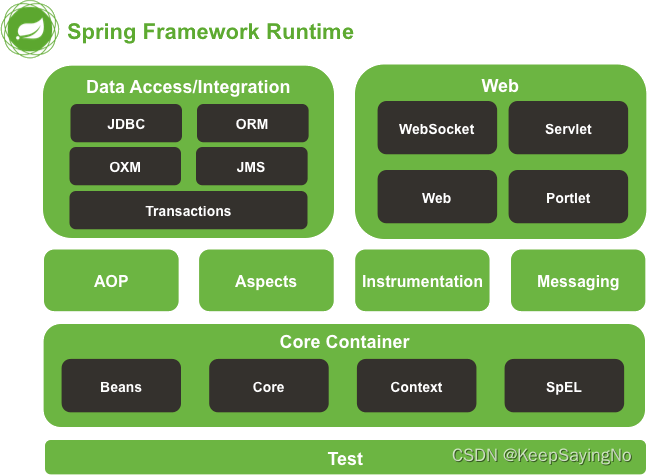
一文看懂SpringBoot操纵数据库
1.前言 很多同学进入公司就开始参与项目开发,大多数情况是对某个项目进行维护或者需求迭代,能够从0到1参与到项目中的机会很少,因此并没有多少机会了解某些技术的运行机制。换句话说,有的面试官在面试的时候就会探讨深层的技术问题…...

科普:java与C++的区别
Java与C是两种广泛使用的编程语言,它们在某些方面存在不同之处。本文将详细介绍Java与C的区别。 一、C与Java的历史 C语言是由Bjarne Stroustrup在20世纪80年代初期开发的一种面向对象编程语言,它是C语言的扩展。Java语言是由Sun Microsystems公司于20…...

突发!ChatGPT疯了!
数据智能产业创新服务媒体——聚焦数智 改变商业今天,笔者正常登录ChatGPT,试图调戏一下他。但是,突然震惊的发现,ChatGPT居然疯了。之所以说他是疯了,而不是崩溃了,是因为他还能回复我,但回…...
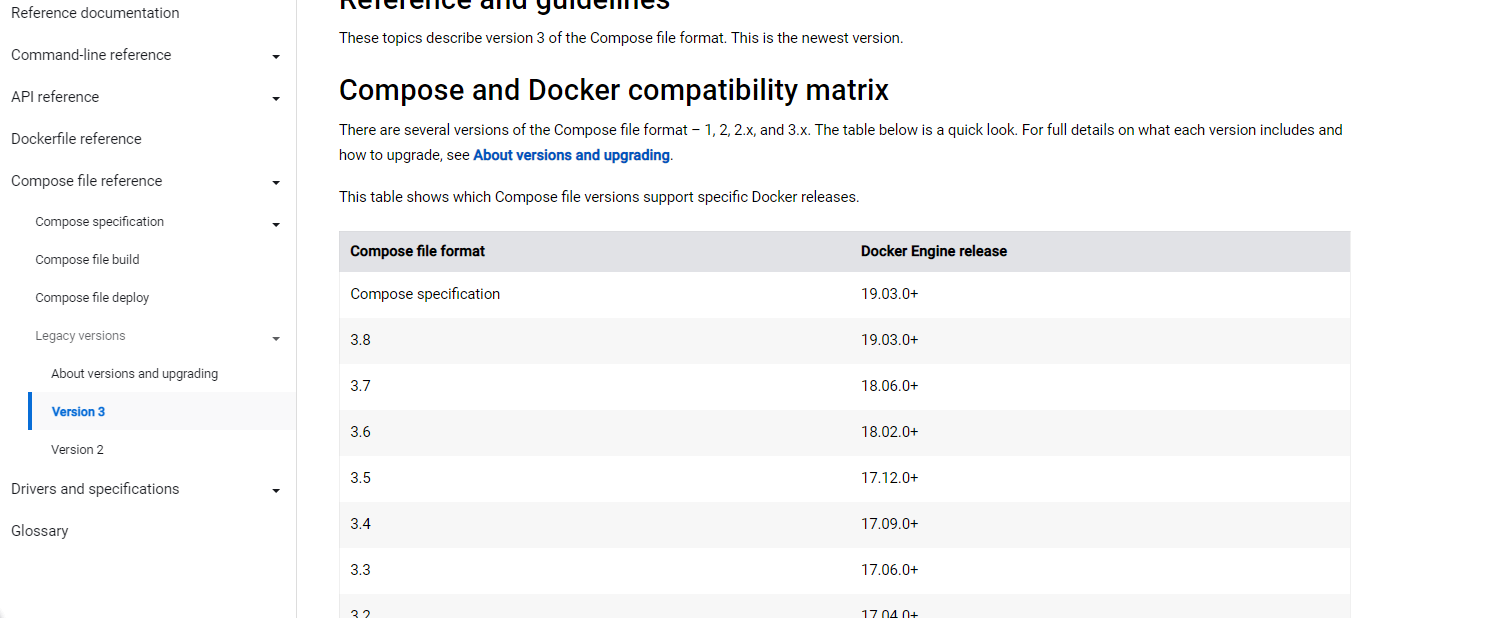
docker-compose容器编排使用详解+示例
文章目录一、docker-compose概述1、产生的背景2、核心概念3、使用的三个步骤4、常用命令二、下载安装1、官方文档2、下载3、卸载三、使用compose1、前置知识,将一个springboot项目打包为镜像2、编写docker-compose.yml文件3、启动docker-compose4、停止一、docker-c…...
可用的rtsp ,rtmp地址以及使用VLC和ffmpeg 播放视频流
可用的 rtmp地址: rtmp://ns8.indexforce.com/home/mystream 可用的 rtsp地址: rtsp://wowzaec2demo.streamlock.net/vod/mp4:BigBuckBunny_115k.mp4 可搭配VLC播放器使用,以及虚幻4 流媒体使用,实现直播效果 1.使用VLC 播放:https://www.vi…...
Python机器学习:朴素贝叶斯
前两天不知道把书放哪去了,就停更了一下,昨天晚上发现被我放在书包夹层里面了,所以今天继续开始学习。 首先明确一下啊,朴素贝叶斯是什么:朴素贝叶斯分类器是一种有监督的统计学过滤器,在垃圾邮件过滤、信…...

几个最基本软件的环境变量配置
在Windows中配置环境变量位置: 控制面板->系统和安全->系统。可以点击:“此电脑”->“属性”直接进入。 点击“高级系统设置”->【环境变量】。在这里可以看见用户变量和系统变量,如果你这台机器不是你一个人使用设置为用户变量…...

物业企业如何加快向现代服务业转型
近年来,随着人民生活水平的提高,人们对住宅质量提出更高的要求,在此前提下,全国各地涌现出了一些运用现代的计算机、控制与通信技术建设的智能化住宅小区。但是许多智能化住宅小区都存在建好了智能硬件环境却没有智能化的软件在上…...
java ssm人力资源系统Y3程序
1.系统登录:系统登录是员工访问系统的路口,设计了系统登录界面,包括员工名、密码和验证码,然后对登录进来的员工判断身份信息,判断是管理员还是普通员工。 2.系统员工管理:不管是超级…...

leetcode重点题目分类别记录(三)动态规划深入与素数理论
文章目录动态规划背包问题01背包抽象出求解目标尝试进程子问题拆分基本情况根据拆分过程定义dp数组与转移方程遍历顺序与状态压缩模板归纳题目应用变种提升组合问题多维01背包有特殊限制的01背包完全背包打家劫舍股票系列子序列类数位dp动态规划 背包问题 01背包 有C0-Cx件物…...

Sunshine游戏串流实战:从零搭建你的专属云游戏平台
Sunshine游戏串流实战:从零搭建你的专属云游戏平台 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想过在客厅电视上畅玩PC游戏,或者想在出差时…...

Ovito模块在Python环境下的兼容性排查与实战配置指南
1. 为什么你的Ovito模块总是安装失败? 每次看到那个红色的报错提示,我都想砸键盘。去年给实验室配LAMMPS后处理环境时,光Ovito模块就折腾了我三天。后来才发现,90%的问题都出在Python环境上。Windows系统里32位和64位Python就像两…...

从零到一:基于Ultralytics框架与自定义数据集实战RT-DETR模型训练
1. RT-DETR与Ultralytics框架初探 第一次接触RT-DETR时,我被它的"实时检测Transformer"组合惊艳到了。这个由百度开发的检测器,完美解决了传统Transformer模型在实时场景下的性能瓶颈。不同于YOLO系列的锚框机制,RT-DETR采用端到端…...
)
告别python-pcl!用pclpy在Windows上轻松玩转PCL点云处理(Python 3.6/3.7保姆级教程)
告别python-pcl!用pclpy在Windows上轻松玩转PCL点云处理(Python 3.6/3.7保姆级教程) 在三维视觉和机器人领域,点云处理一直是核心技术难点之一。PCL(Point Cloud Library)作为开源领域的标杆工具库&#x…...

Arm Neoverse CMN-650架构与性能优化解析
1. Arm Neoverse CMN-650架构概览在现代多核处理器系统中,一致性互连网络扮演着至关重要的角色。作为Arm Neoverse平台的核心组件,CMN-650采用Mesh拓扑结构设计,为多核处理器集群提供高效的数据传输和缓存一致性管理。这种架构特别适合需要高…...

Doramagic开源工具箱:开发者效率提升的模块化实践
1. 项目概述:Doramagic,一个为开发者打造的魔法工具箱最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“tangweigang-jpg/Doramagic”。光看这个名字,可能有点摸不着头脑,但点进去一看,发现这其…...

Linux僵死IO与不可中断睡眠分析
Linux僵死IO与不可中断睡眠分析在 Linux 系统里,有一类问题特别让人困惑:进程存在、CPU 不高,但命令卡住、服务停不下来、甚至 kill 也无效。很多这类现象最终都与不可中断睡眠状态有关,尤其常见于 IO 阻塞场景。中级阶段需要理解…...

LibreOffice Online 终极指南:如何在浏览器中实现免费办公协作
LibreOffice Online 终极指南:如何在浏览器中实现免费办公协作 【免费下载链接】online Read-only Mirror - no pull request (use https://gerrit.libreoffice.org instead) 项目地址: https://gitcode.com/gh_mirrors/onl/online 还在为昂贵的在线办公软件…...

DayZ社区离线模式完全指南:打造你的专属末日沙盒世界
DayZ社区离线模式完全指南:打造你的专属末日沙盒世界 【免费下载链接】DayZCommunityOfflineMode A community made offline mod for DayZ Standalone 项目地址: https://gitcode.com/gh_mirrors/da/DayZCommunityOfflineMode 想在DayZ中完全掌控自己的生存命…...

WarcraftHelper终极指南:5步解决魔兽争霸3闪退与兼容性问题
WarcraftHelper终极指南:5步解决魔兽争霸3闪退与兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3闪退问题烦恼吗…...