C++ 并发编程
文章目录
- 基本概念
- 编程
- 创建线程
- 启动
- 共享数据相关
- 条件变量
- 时间相关
- future相关——等待一次性事件
- 读写锁
- 原子操作与缓存一致性关系
- 线程管理
- 启动线程
- 从类的方法来创建线程
- 传参
- 标识线程
- 常用API
- 等待线程完成
- 后台运行
- 线程移动
- 线程间共享数据
- 互斥量(mutex)
- unique_ptr
- 线程池
- 内存
- 内存对齐
- 类的内存
- 内存管理
- atomic
- 内存顺序
- 内存模型
- 并发存在的问题
基本概念
线程与进程:
任务并行与数据并行:两种方式利用并发提高性能:第一,将一个单个任务分成几部分,且各自并行运行,从而降低总运行时间。这就是任务并行(task parallelism)。虽然这听起来很直观,但它是一个相当 复杂的过程,因为在各个部分之间可能存在着依赖。区别可能是在过程方面——一个线程执行算法的一部分,而另一个线程执行算法的另一个部分——或是在数据方面——每个线程在不同的数据部分上执行相同的操作(第二种方式)。后一种方法被称为数据并行(data parallelism)
何时使用并发:除非潜在的性能增益足够大或关注点分离地足够清晰,能抵消所需的额外的开发时间以及与维护多线程代码相关的额外成本(代码正确的前提下);否则,别用并发。
编程
多线程编程实例:
- 添加头文件:
#include <thread> - 创建线程对象:
std::thread t1(foo2);或者std::thread t1(foo2, params);其中第一个表示通过无参数的函数创建线程对象,另外一个表示通过函数和相对于的参数创建线程对象 t1.join()等待线程结束
创建线程
- 从普通函数名创建
std::thread th(func, args)
- 从类的成员函数创建
类内部:非成员函数创建线程时,传入this指针,类外部则改为指向类实例对象的指针。
静态成员函数:
std::thread th(&Class::Func, args)
非静态成员函数:
std::thread th(&Class::Func,this,args)
- 使用std::bind函数
std::thread th(std::bind(&Class::Func,this, args))
- 使用lambda表达式创建
std::thread th([](){func();};)
启动
std::thread::hardware_concurrency():硬件线程数量
detach()
join()
joinable():返回是否可被join()
std::move(th);:线程只能被移动,不能被拷贝复制。
标识:
std::thread::id
get_id()
暂停线程:
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
量产
std::for_each(threads.begin(), threads.end(), std::mem_fn(&std::thread::join));
共享数据相关
常见问题:
- 条件竞争(race condition);当不变量遭到破坏时,才会产生条件竞争,对数据的条件竞争通常表示为“恶性”(problematic)条件竞争。
- 数据竞争(data race)一种特殊的条件竞争:并发的去修改一个独立对象(参见5.1.2节)。
解决办法:
- 互斥量、锁:mutex
- 事务:transacting
避免死锁:
- 避免嵌套锁:尽量保证每个线程只持有一个锁,锁上就不会产生死锁;如果持有多个锁,那么使用std::lock();
- 避免在持有锁时调用用户提供的代码
- 使用固定顺序获取锁
当其中一个成员函数返回的是保护数据的指针或引用时,会破坏对数据的保护。
互斥量保护的数据需要对接口的设计相当谨慎,要确保互斥量能锁住任何对保护数据的访问,并且不留后门。
已经对锁的粒度有所了解:锁的粒度是一个“摆手术语”(hand-waving term),用来描述通过一个锁保护着的数据量大小。一个细粒度锁(a fine-grained lock)能够保护较小的数据量,一个粗粒度锁(a coarse-grained lock)能够保护较多的数据量。
std::mutex mtx;
-
lock();:上锁 -
unlock();:解锁 -
std::lock(mtx1, mtx2):一次性锁住多个互斥量,并且没有副作用(死锁风险)
std::std::recursive_mutex:嵌套锁一般用在可被多线程并发访问的类上,所以其拥有一个互斥量保护其成员数据。每个公共成员函数都会对互斥量上锁,然后完成对应的功能,之后再解锁互斥量
std::lock_guard<std::mutex> guard(mtx);
std::unique_lock<std::mutex> ulck(mtx);
ulck(mtx, std::adopt_lock)等
条件变量
如果互斥量在线程休眠期间保持锁住状态,准备数据的线程将无法锁住互斥量,也无法添加数据到队列中;同样的,等待线程也永远不会知道条件何时满足。
std::condition_variable con_var;
wait(ulck)wait(ulck, bool)
wait()会去检查这些bool条件,当条件满足返回(程序继续执行)。如果条件不满足,wait()函数将解锁互斥量,并且将这个线程置于阻塞或等待状态。
notify_one()
当准备数据的线程调用notify_one()通知条件变量时,处理数据的线程从阻塞或者等待状态中苏醒,重新获取互斥锁,并且对条件再次检查——当条件不满足时,线程将对互斥量解锁,并且重新开始等待。在条件满足的情况下,从wait()返回并继续持有锁。
应用场景:当线程用来分解工作负载,并且只有一个线程可以对通知做出反应
这就是为什么用 std::unique_lock 而不使用 std::lock_guard ——等待中的线程必须在等待期间解锁互斥量,并在这这之后对互斥量再次上锁,而 std::lock_guard 没有这么灵活。
notify_all()
应用场景:很多线程等待同一事件,对于通知他们都需要做出回应。这会发生在共享数据正在初始化的时候,当处理线程可以使用同一数据时,就要等待数据被初始化(有不错的机制可用来应对;
时间相关
限定等待一个事件的时间:wait_for()和wait_until()
std::cv_status::timeout
std::condition_variable cv;
std::mutex m;
auto now = std::chrono::steady_clock::now();
std::unique_lock<std::mutex> lk(m);
cv.wait_until(lk, now + std::chrono::milliseconds(500));
cv.wait_for(lk, std::chrono::milliseconds(35));
if(cv.wait_until(lk, timeout)==std::cv_status::timeout)break;
//====================================================
std::package<Data> promise;
std::future<Data> future = promise.get_future();
future.wait_for(std::chrono::milliseconds(35));
//====================================================
当线程因为指定时延而进入睡眠时,可使用sleep_for()唤醒;或因指定时间点睡眠的,可使用sleep_until唤醒,超时和延迟处理功能:std::this_thread::sleep_for() 和 std::this_thread::sleep_until()

future相关——等待一次性事件
应用场景:当等待线程只等待一次,当条件为true时,它就不会再等待条件变量了,所以一个条件变量可能并非同步机制的最好选择。尤其是,条件在等待一组可用的数据块时。在这样的情况下,期望(future)就是一个适合的选择。
“期望”对象本身并不提供同步访问。当多个线程需要访问一个独立“期望”对象时,他们必须使用互斥量或类似同步机制对访问进行保护
唯一期望:std::future 的实例只能与一个指定事件相关联
std::async()
std::future<Data> future = std::async(std::launch::async, func)
std::future<Data> future = std::async(std::launch::deffered, func)
Data data = future.get();future.wait();
std::packaged_task<> :对一个函数或可调用对象,绑定一个期望;它就会调用相关函数或可调用对象,将期望状态置为就绪,返回值也会被存储为相关数据。
应用场景:比如在任务所在线程上运行任务,或将它们顺序的运行在一个特殊的后台线程上。当一个粒度较大的操作可以被分解为独立的子任务时,其中每个子任务就可以包含在一个 std::packaged_task<> 实例中,之后这个实例将传递到任务调度器或线程池中。
- std::packaged_task<> 的模板参数是一个函数签名,如
std::packaged_task<double(double)>
std::packaged_task<int(std::string)> pk_task(func):func的函数签名必须是符合其模板参数。
调用pk_task(std::string s)是一个可调用对象。
pk_task.get_future()返回的future对象含有函数的调用结果。
std::promise/std::future
在future上可以阻塞等待线程,同时,提供数据的线程可以使用组合中的“promise”来对相关值进行设置,以及将“future”的状态置为“ready”;
”解决单线程多连接问题
std::promise<Data> promise;
-
promise.set_value(Data); -
std::future<Data> future = promise.getfuture();
std::advance()
共享期望: std::shared_future 的实例就能关联多个事件
std::shared_future<Data>
带返回值的后台任务:因为 std::thread 并不提供直接接收返回值的机制。这里就需要 std::async 函数模板(也是在头文件中声明的)了。
每个线程都通过自己拥有的 std::shared_future 对象获取结果,那么多个线程访问共享同步结果就是安全的
- 使用std::async 启动一个异步任务
- std::async 会返回一个 std::future 对象,这个对象持有最终计算出来的结果
- 当你需要这个值时,你只需要调用这个对象的get()成员函数;并且直到“期望”状态为就绪的情况下,线程才会阻塞。
通过future来进行初始化:
std::promise<Data> promise;
std::shared_future<Data> sf(promise.get_future());
std::future<Data> f(p.get_future());
std::shared_future<Data> sf(std::move(f))
auto sf = f.share();
层次锁:层级互斥量的实现。
hierarchical_mutex high_mtx(100);
函数化编程”(functional programming ( FP ))引用于一种编程方式,这种方式中的函数结果只依赖于传入函数的参数,并不依赖外部状态
替代同步的解决方案:函数化模式编程FP,完全独立执行的函数,不会受到外部环境的影响;消息传递模式FSP,以消息子系统为中介,向线程异步发送消息。
读写锁
原子操作与缓存一致性关系
当程序中的对同一内存地址中的数据访问存在竞争,你可以使用原子操作来 避免未定义行为。当然,这不会影响竞争的产生——原子操作并没有指定访问顺序——但原子操作把程序拉回了定义行为的区域内。
原子操作是一类不可分割的操作,当这样操作在任意线程中进行一半的时候,你是不能查看的;它的状态要不就是完成,要不就是未完成
std::atomic_flag()
解决缓存一致性问题?
CPU是多核的,写回策略会导致缓存一致性问题。
-
写传播——总线嗅探
-
事务的串行化——锁
-
优化:尽量广播给持有相关数据的核心而不是所有核心
MSEI一致性协议来实现!!!
M,已修改:某个数据块已修改到CPU cache但是没有同步到内存中
E,独占:某个数据块只在某个核心中,此时缓存和内存中数据一致
S,共享:某个数据块在多个核心都有,缓存和内存中数据一致。
I,已失效:某个数据块在核心中已失效,不是最新的数据。
——多核下,确保M、E这两个状态发生改变,任何尝试改变这两种状态的操作进行阻塞,实现原子操作。
线程管理
启动线程
void do_some_work();
std::thread my_thread(do_some_work);
对于类:可以通过重载()运算符来实现。
class background_task {
public: void operator()() const { do_something(); do_something_else(); }
};
background_task f;
std::thread my_thread(f);
注意:当把函数对象传入到线程构造函数中时,需要避免“最令人头痛的语法解析”——如果传递一个临时变量,而不是一个命名的变量;C++编译器会将其解析成函数声明,而不是类型对象的定义。
std::thread my_thread(background_task()); 这里相当与声明了一个名为my_thread的函数,这个函数带有一个参数(函数指针指向没有参数并返回background_task对象的函数),返回一个 std::thread 对象的函数,而非启动了一个线程。
解决办法:
std::thread my_thread((background_task())); // 1
std::thread my_thread{background_task()}; // 2
必须在 std::thread 对象销毁之前做出决定——加入或分离线程之前。 如果线程就已经结束,想再去分离它,线程可能会在 std::thread 对象销毁之后继续运行下去
使用一个能访问局部变量的函数去创建线程是一个糟糕的主意(除非十分确定线程会在函数完成前结束)
从类的方法来创建线程
创建线程用的函数指针是类方法的指针(&foo::bar),虽然这个方法没有声明参数,但是熟悉C++对象的朋友应该都知道,类方法隐含了自身实例的self指针,所以这里需要传给它的第一个参数就是指向实例foo_inst的指针。
class foo {void bar() {// ...}void create_thread() {this->my_thread = new std::thread(&foo::bar, this);}// ...private:std::thread* my_thread;};
传参
传递引用:std::ref(data)
标识线程
线程直接调用get_id函数来获取每个线程的id,即std::thread::id 对象,该对象可以自由的拷贝和对比,因为标识符就可以复用。如果两个对象的 std::thread::id 相等,那它们就是同一个线程,或者都“没有线程”。如果不等,那么就代表了两个不同线程,或者一个有线程,另一没有。
说明:std::thread::id 实例常用作检测线程是否需要进行一些操作,例如
std::thread::id master_thread;
if(std::this_thread::get_id()==master_thread)
{ do_master_thread_work();
}
要保证ID比较结果相等的线程,必须有相同的输出。
常用API
在前面加std::进行调用
| API | 参数 | 说明 |
|---|---|---|
| get_id | void | 用于标识线程 |
| move |
等待线程完成
就可以确保局部变量在线程完成后,才被销毁
my_thread.join()
只能对一个线程使用一次join();一旦已经使用过join(), std::thread 对象就不能再次加入了,当对其使用**joinable()**时,将返回否(false)
特殊情况下:
需要对一个还未销毁的 std::thread 对象使用join()或detach()。如果想要分离一个线程,可以在线程启动后,直接使用**detach()进行分离。如果打算等待对应线程,则需要细心挑选调用join()**的位置。
当倾向于在无异常的情况下使用join()时,需要在异常处理过程中调用join(),从而避免生命周期的问题
try { do_something_in_current_thread();
}
catch(...) { t.join(); // 1 throw;
}
t.join(); // 2
后台运行
使用detach()会让线程在后台运行,调用 std::thread 成员函数1detach()来分离一个线程。之后,相应的 std::thread 对象就与实际执行的线程无关了,并且这个线程也无法进行加入:
std::thread t(do_background_work);
t.detach();
assert(!t.joinable());
线程传递引用,提供的参数可以"移动"(move),但不能"拷贝"(copy)。"移动"是指:原始对象中的数 据转移给另一对象,而转移的这些数据就不再在原始对象中保存了(译者:比较像在文本编辑 时"剪切"操作)。 std::unique_ptr 就是这样一种类型(译者:C++11中的智能指针),这种类型 为动态分配的对象提供内存自动管理机制(译者:类似垃圾回收)。同一时间内,只允许一 个 std::unique_ptr 实现指向一个给定对象,并且当这个实现销毁时,指向的对象也将被删除 。
C++标准库中有很多资源占有(resource-owning)类型,比如 std::ifstream , std::unique_ptr 还有 std::thread 都是可移动(movable),但不可拷贝 (cpoyable)
线程移动
std::thread 支持移动,就意味着线程的所有权可以在函数外进行转移。
std::thread f() { void some_function(); return std::thread(some_function);
}
std::thread g() { void some_other_function(int); std::thread t(some_other_function,42); return t;
}
线程间共享数据
问题:无论结果如何,都是并行代码常见错误:条件竞争(race condition)
数据竞争:数据竞争(data race)这个术语,一种特殊的条件竞争:并发的去修改一个独立对象(参见5.1.2节)
恶性条件竞争通常发生于完成对多于一个的数据块的修改时,例如,对两个连接指针的修改 (如图3.1)。因为操作要访问两个独立的数据块,独立的指令将会对数据块将进行修改,并且其中一个线程可能正在进行时,另一个线程就对数据块进行了访问。因为出现的概率太低,条件竞争很难查找,也很难复现。如CPU指令连续修改完成后,即使数据结构可以让其他并发线程访问,问题再次复现的几率也相当低。当系统负载增加时,随着执行数量的增加,执行序列的问题复现的概率也在增加,这样的问题只可能会出现在负载比较大的情况下。
条件竞争通常是时间敏感的,所以程序以调试模式运行时,它们常会完全消失,因为调试模式会影响程序的执行时间(即使影响不多)。
如何避免恶性条件竞争?
- 最简单的办法就是对数据结构采用某种保护机制,确保只有进行修改的线程才能看到不变量被破坏时的中间状态
- 另一个选择是对数据结构和不变量的设计进行修改,修改完的结构必须能完成一系列不可分割的变化,也就是保证每个不变量保持稳定的状态,这就是所谓的无锁编程(lock-free programming)
- 使用事务(transacting)的方式去处理数据结构的更新(这里的"处理"就如同对数据库进行更新一样)。所需的一些数据和读取都存储在事务日志中,然后将之前的操作合为一步,再进行提交:当数据结构被另一个线程修改后,或处理已经重启的情况下,提交就会无法进行,这称作为“软件事务内存”(software transactional memory (STM))
互斥量(mutex)
unique_ptr
线程池
在用户线程中调用AfxGetMainWnd()函数,获取的不是应用程序主框架类指针,而是线程的m_pMainWnd。
https://blog.csdn.net/lidandan2016/article/details/72154490
内存
内存对齐
对于32位系统,其内存对齐至少为一个地址长度,也即2322^{32}232即4个字节长度,可以使用alignas(4的倍数)来表示想要对齐的内存大小,指针类型的大小为4个字节。
对于64位系统,其内存对齐至少为一个地址长度,也即2642^{64}264即8个字节长度,可以使用alignas(8的倍数)来表示想要对齐的内存大小,指针类型的大小为8个字节。
类的内存
空类的内存为1个字节,为了保证类的唯一实例化,以64位系统为例即指针大小为8个字节说明内存的详细情况:
内存管理
原子操作:std::atomic:要么完成,要么没完成,不存在中间状态
互斥量与原子操作不同点:
-
互斥量的加锁一般是针对一个代码段(几行代码);原子操作针对的都是一个变量,而不是针对一个代码段;
-
原子操作比互斥量在效率上更高
步骤:最常见的操作是原子读改写,简称RMW
- Read
- Modified
- Write
如何保证读和写保持顺序一致?下面这种是没有用锁和原子操作等机制,会发现两个线程一直保持独立!!!
int g_value;
void read() {while (true){cout << g_value << endl;}
}void write() {while (true){std::this_thread::sleep_for(std::chrono::seconds(1));g_value++;}
}
一般地:使用条件变量+锁asdsds
condition_variable con_var;
mutex g_mtx;
int g_value;
void read() {while (true){unique_lock<mutex> ul(g_mtx);con_var.wait(ul);cout << g_value << endl;}
}
void write() {while (true){std::this_thread::sleep_for(std::chrono::milliseconds(100));g_value++;con_var.notify_one();}
}
atomic
std::atomic_flag ato;
-
.test_and_set():-
1.如果atomic_flag ==true,返回true;
-
2.如果atomic_flag==false,返回false,并设置atomic_flag=true。
指定memory_order顺序设置。
-
-
.clear():设置atomic_flag =false
自旋锁与互斥锁:
- 一种是没有获取到锁的线程就一直循环等待判断该资源是否已经释放锁,这种锁叫做自旋锁,它不用将线程阻塞起来(NON-BLOCKING);
std::atomic_flag lock = ATOMIC_FLAG_INIT;
while (lock.test_and_set(std::memory_order_acquire)) // acquire lock; // spin
dosomthing();
lock.clear(std::memory_order_release);
- 还有一种处理方式就是把自己阻塞起来,等待重新调度请求,这种叫做
互斥锁
原子类型对象的主要特点:
-
从不同线程访问不会导致数据竞争(data race)。
-
因此从不同线程访问某个原子对象是良性 (
well-defined) 行为通常对于非原子类型而言,并发访问某个对象(如果不做任何同步操作)会导致未定义 (
undifined) 行为发生。
std::atomic<T>:不允许拷贝构造和拷贝赋值
std::atomic<bool> ato1 = false;
std::atomic<bool> ato3(false);
// std::atomic<bool> ato2 = ato1; // 错误,不能拷贝赋值
// std::atomic<bool> ato3(ato1); // 错误,不能拷贝构造
-
.is_lock_free():判断对象是否可lock-free即多个线程访问对象时会不会导致线程阻塞。 -
.store(T val, memory_order):修改被封装的值 -
.load(memory_order):读取被封装的值 -
T .exchange(T val, memory_order):修改值为新值,并返回之前的值 -
bool .compare_exchange_weak(T& expected, T val, memory_order):比较并交换被封装的值(weak)与参数expected所指定的值是否相等,整个操作是原子的,在某个线程读取和修改该原子对象时,另外的线程不能读取和修改该原子对象,如果:-
相等,则原子变量值=val,返回true。
-
不相等,则expected =原子变量值,返回false。
调用该函数之后,如果被该原子对象封装的值与参数
expected所指定的值不相等,expected中的内容就是原子对象的旧值。
-
-
bool .compare_exchange_strong(T& expected, T val, memory_order)等
std::atomic<T>:基本操作有fetch_add()和fetch_sub()提供,属于RMW操作。
fetch_add(T* ptr, memory_order):在存储地址上做原子加法fetch_sub(T* ptr, memory_order):在存储地址上做原子减法
std::atomic<自定义类> 这个类型必须有拷贝赋值运算符。这就意味着这个类型不能有任何虚函数或虚基类,以及必须使用编译器创建的拷贝赋值操作。自定义类型中所有的基类和非静态数据成员也都需要支持拷贝赋值操作。一个UDT类型对象可以使用memcpy()进行拷贝,还要确定其对象可以使用memcmp()对位进行比较。
对于特化的版本
内存顺序Memory Order
所谓的memory order,其实就是限制编译器以及CPU对单线程当中的指令执行顺序进行重排的程度(此外还包括对cache的控制方法)。这种限制,决定了以atom操作为基准点(边界),对其之前的内存访问命令,以及之后的内存访问命令,能够在多大的范围内自由重排(或者反过来,需要施加多大的保序限制)。从而形成了6种模式。它本身与多线程无关,是限制的单一线程当中指令执行顺序。
其他参考
relaxed, acquire, release, consume, acq_rel, seq_cst
它们表示的是三种内存模型:
-
sequential consistent(memory_order_seq_cst),
-
relaxed(memory_order_relaxed).
-
acquire release(memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel),
memory_order_relaxed: 只保证当前操作的原子性,不考虑线程间的同步,其他线程可能读到新值,也可能读到旧值,只保证操作的原子性和内存一致性。
在单个线程内,所有原子操作是顺序进行的。按照什么顺序?基本上就是代码顺序(sequenced-before)。这就是唯一的限制了!两个来自不同线程的原子操作是什么顺序?两个字:任意。
memory_order_release:(可以理解为 mutex 的 unlock 操作)
- 对写入施加 release 语义(store),在代码中这条语句前面的所有读写操作都无法被重排到这个操作之后,即 store-store 不能重排为 store-store, load-store 也无法重排为 store-load
- 当前线程内的所有写操作,对于其他对这个原子变量进行 acquire 的线程可见
- 当前线程内的与这块内存有关的所有写操作,对于其他对这个原子变量进行 consume 的线程可见
memory_order_acquire: (可以理解为 mutex 的 lock 操作)
- 对读取施加 acquire 语义(load),在代码中这条语句后面所有读写操作都无法重排到这个操作之前,即 load-store 不能重排为 store-load, load-load 也无法重排为 load-load
- 在这个原子变量上施加 release 语义的操作发生之后,acquire 可以保证读到所有在 release 前发生的写入。
memory_order_consume:
- 对当前要读取的内存施加 release 语义(store),在代码中这条语句后面所有与这块内存有关的读写操作都无法被重排到这个操作之前
- 在这个原子变量上施加 release 语义的操作发生之后,consume 可以保证读到所有在 release 前发生的并且与这块内存有关的写入,举个例子:
memory_order_acq_rel:
- 对读取和写入施加 acquire-release 语义,无法被重排
- 可以看见其他线程施加 release 语义的所有写入,同时自己的 release 结束后所有写入对其他施加 acquire 语义的线程可见
memory_order_seq_cst:(顺序一致性)
- 如果是读取就是 acquire 语义,如果是写入就是 release 语义,如果是读取+写入就是 acquire-release 语义
- 同时会对所有使用此 memory order 的原子操作进行同步,所有线程看到的内存操作的顺序都是一样的,就像单个线程在执行所有线程的指令一样
内存栅栏Memory Barrier:无锁(lock-free)数据结构的设计中,指令的乱序执行会造成无法预测的行为。所以我们通常引入内存栅栏(Memory Barrier)这一概念来解决可能存在的并发问题。
内存顺序
如下图所示,对于原子变量x,y,z
| 顺序类型 | 说明与举例 | 可操作类型 |
|---|---|---|
| relaxed | 只保证单个线程如线程1中对A的操作,如A0、A3、A5的顺序性或者线程2中对x的操作如B2、B3、B5操作的顺序性 | 都可以 |
| acquire | 不允许load操作后所有变量的操作被重排到load之前,比如不允许将线程2的B4的y操作重排到B3操作之前,但是在B3之后可以 | load\RMW |
| consume | 不允许load操作后的依赖于当前原子变量的变量的操作被重排到load之前,比如线程2中z_x的操作B1不可以被重排到B3之后,但是不依赖于x的y变量的操作B4就可以被移动到x的B3操作之前 | load\RMW |
| release | 不允许store操作前所有变量的操作被重排到store之后,比如不允许将线程1的A2、A1操作重排到A3操作之后,但是可以在A3之前 | store\RMW |
| acq_rel | 不允许跨越RMW操作重排,即只能在其左右两端进行重排 | RMW |
| seq_cst | 所有操作的前后语句不能跨越该操作进行重排,所有线程语句以全局内存修改顺序为参照 | 都可以 |


happens-before
happens-before关系表示的不同线程之间的操作先后顺序。如果A happens-before B,则A的内存状态将在B操作执行之前就可见
synchronizes-with
synchronizes-with关系强调的是变量被修改之后的传播关系(propagate), 即如果一个线程修改某变量的之后的结果能被其它线程可见,那么就是满足synchronizes-with关系的。synchronizes-with可以被认为是跨线程间的happends-before关系
Carries dependency
同一个线程内,表达式A sequenced-before 表达式B,并且表达式B的值是受表达式A的影响的一种关系, 称之为"Carries dependency"
内存模型
顺序连贯(sequential consistency, SC);SC有两点要求:
- 在每个处理器内,维护每个处理器的程序次序;在所有处理器间,维护单一的表征所有操作的次序。
- 对于写操作W1, W2, 不能出现从处理器 P1 看来,执行次序为 W1->W2; 从处理器 P2 看来,执行次序却为 W2->W1 这种情况
缓存一致性协议(cache coherence protocols)
维护写原子性(maintaining write atomicity):
- 要求1:针对同一地址的写操作被串行化(serialized). 图4阐述了对这个条件的需求:如果对 A 的写操作不是序列化的,那么 P3 和 P4 输出(寄存器 1,2)的结果将会不同,这违反了次序一致性
- 对一个新写的值的读操作,必须要等待所有(别的)缓存对该写操作都返回确认通知后才进行
为获得好的性能,我们可以引入放松内存一致性模型(relaxed memory consistency models),这些模型主要通过两种方式优化程序(读写):
放松对程序次序的要求:这种放松与此前所述的“在无缓存的体系结构中采用的优化”类似,仅适用于对不同地址的操作对(opeartion pairs)间使用。
放松对写原子性的要求:一些模型允许读操作在“一个写操作未对所有处理器可见”前返回值。这种放松仅适用于基于缓存的体系结构。
并发存在的问题
数据争用、兵乓缓存、伪共享
超额认购(oversubscription):如果有很多额外线程,就会有很多线程准备执行,而且数量远远大于可 用处理器的数量,不过操作系统就会忙于在任务间切换,以确保每个任务都有时间运行
Amdahl定律:当程序“串行”部分的时间用fs来表示,那么性能增益§就可以通过处理器数量(N)进行估计:

并发分离关注,可以将一个很长的任务交给一个全新的线程,并且留下一个专用的 GUI线程来处理这些事件。
相关文章:
C++ 并发编程
文章目录基本概念编程创建线程启动共享数据相关条件变量时间相关future相关——等待一次性事件读写锁原子操作与缓存一致性关系线程管理启动线程从类的方法来创建线程传参标识线程常用API等待线程完成后台运行线程移动线程间共享数据互斥量(mutex)unique…...
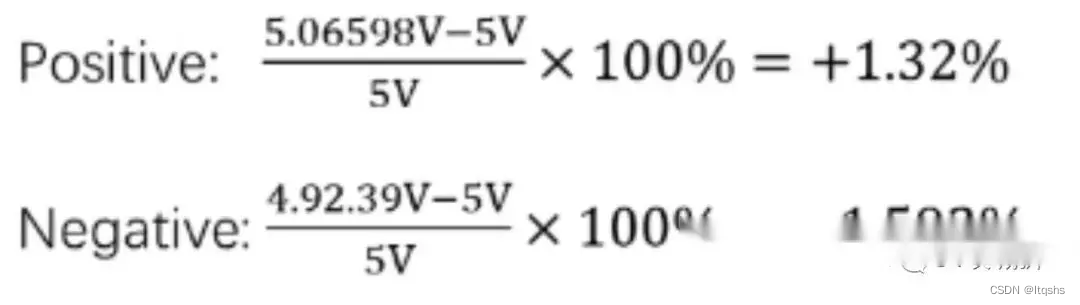
5V的LDO电源的WCCA分析-可靠性分析计算过程
WCCA(WorstCase Circuit Analysis)分析方法是一种电路可靠性分析设计技术,用来评估电路中各个器件同时发生变化时的性能,用于保证设计电路在整个生命周期的都可以可靠工作。通过WCCA分析,验证在上述参数在其容差范围内发生变化时,…...

TensorFlow 深度学习第二版:6~10
原文:Deep Learning with TensorFlow Second Edition 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只…...

C++标准库 -- 顺序容器 (Primer C++ 第五版 · 阅读笔记)
C标准库 -- 顺序容器(Primer C 第五版 阅读笔记)第9章 顺序容器------(持续更新)9.1、顺序容器概述9.2、容器库概览9.2.1 、迭代器9.2.2 、容器类型成员9.2.3 、begin 和 end 成员9.2.4 、容器定义和初始化9.2.5 、赋值和 swap9.2.6 、容器大小操作9.2.7 、关系运算…...
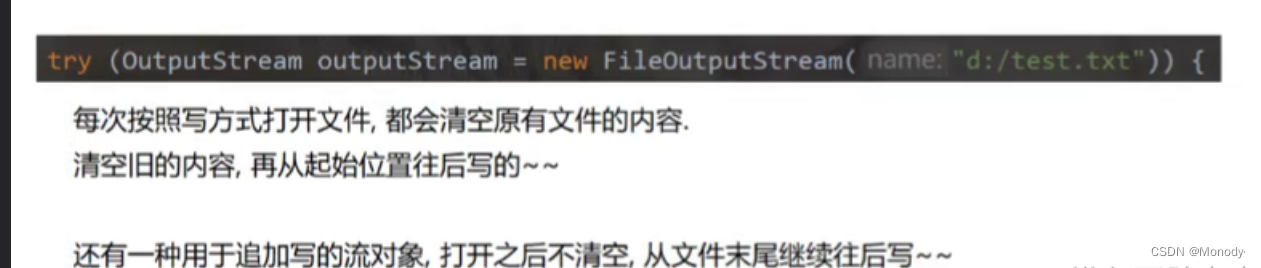
JavaEE初阶学习:文件操作
1.文件 1.认识文件 平时说的文件一般都是指存储再硬盘上的普通文件,形如txt,jpg,MP4,rar等这些文件都可以认为是普通文件,它们都是再硬盘上存储的。 在计算机中,文件可能是一个广义的概念,就…...

【外设零基础通用教程】GPIO 下
【外设零基础通用教程】GPIO 下使用方法GPIO 值输入读取值输出设置值GPIO输入输出应用GPIO输入应用GPIO输出应用文档使用理论补充输出方式推挽输出开漏输出上篇连接:【外设零基础通用教程】GPIO 上,主要是在做视频的时候,发现上篇理论很多&am…...
在window上安装python
在Windows上安装python 1.进入python官网https://www.python.org/ 下载配置环境,点击上方downloads,根据系统选择python环境下载(选择windows) 往下拉查找需要的版本并下载 下载后双击就可以安装python了 如何检验是否安装成功 通过【winr】调出【运行】弹窗,输…...

[hive SQL] 预约业务线
这两天有个数据需求,记录一下。 原始需求说明产品写得很乱不清晰确认了半天无语死了(开始骂人),直接列转换后的问题了 问题1: 现有一张办事预约服务记录表reservation_order,包含字段用户id、服务名称、服务…...

LNMP架构和论坛搭建以及一键部署
数据流向 一、Nginx服务安装 1、关闭防火墙 [rootking ~]# systemctl stop firewalld [rootking ~]# systemctl disable firewalld [rootking ~]# setenforce 0 2、将所需软件包拖入/opt目录下 3、安装依赖包 yum -y install pcre-devel zlib-devel gcc gcc-c make 4、创建运…...

RK3568平台开发系列讲解(设备驱动篇)V4L2程序实现流程
🚀返回专栏总目录 文章目录 一、V4L2 进行视频采集二、命令标识符三、V4L2程序实例3.1、打开设备3.2、查询设备属性3.3、显示所有支持的格式3.4、设置图像帧格式3.5、申请缓冲区3.6、将申请的缓冲帧从内核空间映射到用户空间3.7、将申请的缓冲帧放入队列,并启动数据流3.8、启…...

人工智能中的顶级会议
当搭建好了AI领域的知识架构,即具备了较好的数学、编程及专业领域知识后,如果想在AI领域追踪前沿研究,就不能再只看教材了。毕竟AI领域的发展一日千里,教材上的知识肯定不是最新的。此时,应该将关注的重点转向AI领域的…...

【Python OpenCV】第六天:图像的基础操作
文章目录 一、本期目标二、获取并修改像素值三、获取图像属性(1)img.shape(2)img.size(3)img.dtype四、图像 ROI五、拆分及合并图像通道六、为图像扩边(填充)一、本期目标 获取像素值并修改获取图像的属性(信息)图像的 ROI图像通道的拆分及合并几乎所有这些操作与 Nu…...

2022年陕西省职业院校技能大赛“网络搭建与应用”赛项竞赛试题
2022年陕西省职业院校技能大赛 “网络搭建与应用”赛项 竞赛试题 竞赛说明 一、竞赛内容发布 “网络搭建与应用”赛项竞赛共分三个部分,其中: 第一部分:网络搭建及安全部署项目(500分) 第二部分:服务器配置及应用项目(480分) 第三部分:职业规范与素养(20分) 二、竞赛…...

面经-01
面试java开发工程师 常用数据结构,区别及使用场景 以下是一些常用的数据结构,它们的区别以及适用场景: 数组 (Array): 区别:数组是一种连续内存空间的数据结构,具有固定的大小,用于存储相同类型…...
c/c++:visual studio的代码快捷键,VS设置自定义默认代码,使用快捷键
c: 2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,此时学会c的话, 我所知道的周边的会c的同学,可手握10多个offer,随心所欲,而找啥算法岗的,基本gg 提…...

mysql基本语法
-- 显示所有数据库 show databases;-- 创建数据库 CREATE DATABASE test;-- 切换数据库 use test;-- 显示数据库中的所有表 show tables;-- 创建数据表 CREATE TABLE pet (name VARCHAR(20),owner VARCHAR(20),species VARCHAR(20),sex CHAR(1),birth DATE,death DATE );-- 查看…...
出苗率相关论文
文章目录2021Automatic UAV-based counting of seedlings in sugar-beet field and extension to maize and strawberry(Computers and Electronics in Agriculture)2022Detection and Counting of Maize Leaves Based on Two-Stage Deep Learning with UAV-Based RGB Image&am…...

【Kubernetes】StatefulSet对象详解
文章目录简介1. StatefulSet对象的概述、作用及优点1.1 对比Deployment对象和StatefulSet对象1.2 以下是比较Deployment对象和StatefulSet对象的优缺点:2. StatefulSet对象的基础知识2.1 StatefulSet对象的定义2.1.1 下表为StatefulSet对象的定义及其属性࿱…...
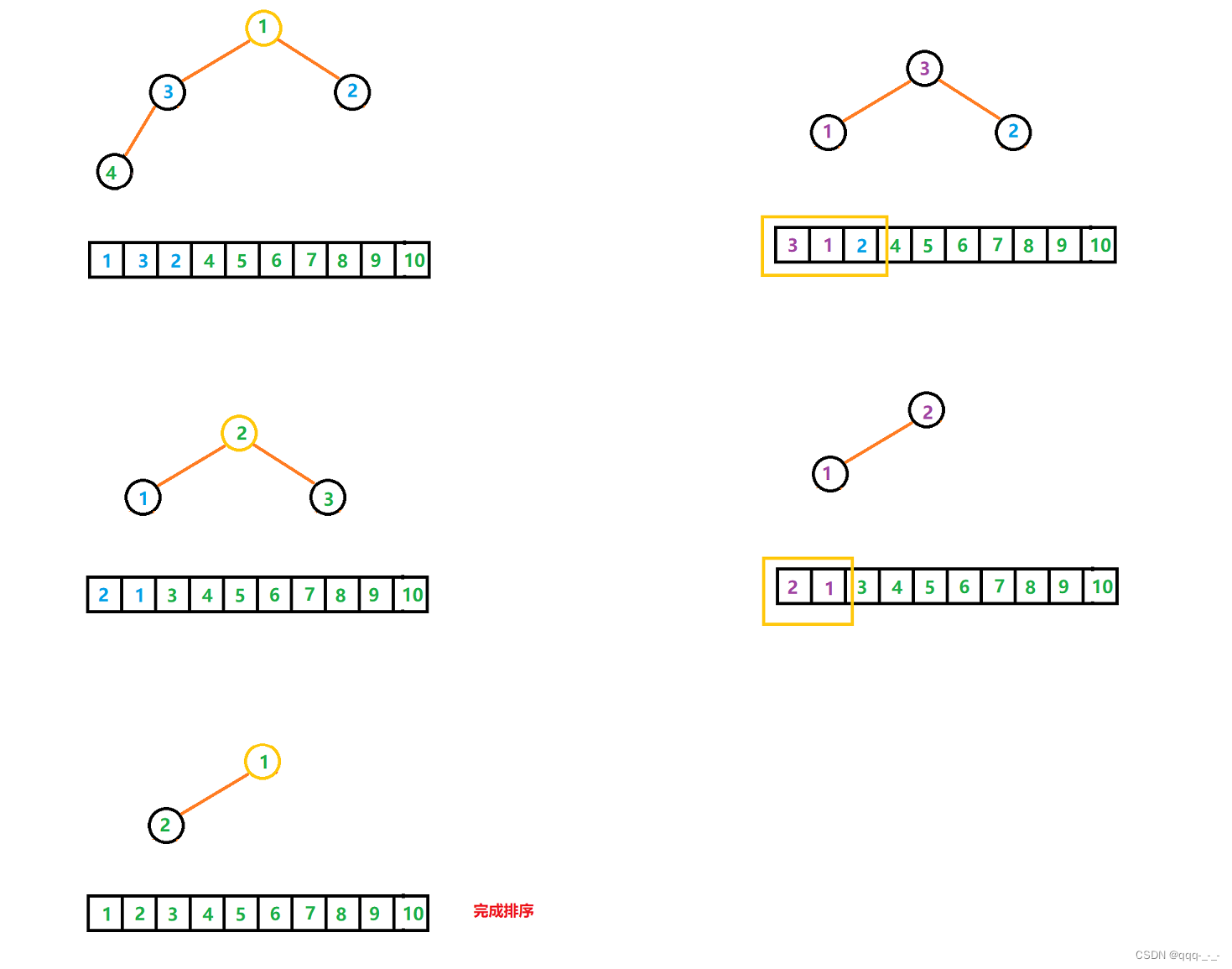
选择排序与堆排序
全文目录引言选择排序思路实现堆排序思路实现总结引言 从这篇文章开始,将介绍几大排序算法:选择排序、堆排序、直接插入排序、希尔排序、冒泡排序、快速排序、归并排序以及计数排序。 在本篇文章中要介绍的是选择排序与堆排序,它们都属于选…...
AI绘图体验:想象力无限,创作无穷!(文生图)
基础模型:3D二次元 PIXEL ART (1)16-bit pixel art, outside of caf on rainy day, light coming from windows, cinematic still(电影剧照), hdr (2) 16-bit pixel art, island in the clouds, by studio ghibli(吉卜力工作室…...

李辉《曾国藩日记》笔记:人到晚年,最重保全!
李辉《曾国藩日记》笔记:人到晚年,最重保全!原文:同治三年五月二十日早饭后清理文件。见客,坐见者二次,立见者一次。程希辕来,围棋二局,又观程与鲁秋航一局。习字一纸。巳刻见客二次…...

无代码物联网开发实战:WipperSnapper与Adafruit IO快速构建数据采集系统
1. 项目概述:当硬件开发告别代码如果你和我一样,对物联网项目充满热情,但又时常被嵌入式编程的编译、烧录、调试劝退,那么今天聊的这个工具,可能会彻底改变你的工作流。我们不再需要为读取一个按键的状态去写几行digit…...

OpenClaw性能调优实战:从监控到压测的全链路优化指南
1. 项目概述:从开源项目到性能调优的实战指南最近在社区里看到不少朋友在讨论一个名为“openclaw”的开源项目,尤其是在性能优化方面遇到了不少挑战。这个项目本身是一个功能强大的工具或框架,但在实际部署和运行时,很多开发者发现…...

单片机开发者如何通过Taotoken快速接入大模型API提升代码效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 单片机开发者如何通过Taotoken快速接入大模型API提升代码效率 对于单片机开发者而言,嵌入式开发工作往往伴随着大量重复…...

Cursor智能体工具包:从AI编程助手到自主规划开发伙伴
1. 项目概述:一个为AI编程助手赋能的智能工具包如果你和我一样,日常重度依赖Cursor这类AI编程助手,那你肯定也经历过这样的时刻:面对一个复杂的重构任务,你不得不把需求拆成十几条指令,一条条喂给AI&#x…...

AI智能体框架选型指南:从LangChain到AutoGen的实战解析
1. 项目概述:为什么我们需要一个“智能体框架”导航站?最近几年,如果你关注AI领域,尤其是大语言模型的应用开发,一定会被一个词频繁刷屏:Agent(智能体)。它不再是科幻电影里的概念&a…...

10分钟精通rpatool:掌握Ren‘Py游戏资源管理的核心技术
10分钟精通rpatool:掌握RenPy游戏资源管理的核心技术 【免费下载链接】rpatool (migrated to https://codeberg.org/shiz/rpatool) A tool to work with RenPy archives. 项目地址: https://gitcode.com/gh_mirrors/rp/rpatool rpatool是一个专门处理RenPy游…...

人机协同中的因果与相关
在人机协同的智能生态中,机器与人类分别扮演着“相关性计算”与“因果性算计”的互补角色:机器擅长从海量数据中挖掘事物共变的相关关系,通过高效的模式识别与概率预测提供精准的态势感知;而人类则凭借领域经验与逻辑思维…...

ARM GICv3中断控制器架构与ICC_CTLR_EL3寄存器解析
1. ARM GICv3中断控制器架构概述在现代处理器架构中,中断控制器是连接外设与CPU核心的关键枢纽。ARM的通用中断控制器(Generic Interrupt Controller, GIC)经过多代演进,GICv3架构在虚拟化支持、多安全域管理和扩展性方面实现了显著提升。作为GICv3的核心…...

深入解析 gRPC:高性能开源 RPC 框架的原理与实战
深入解析 gRPC:高性能开源 RPC 框架的原理与实战 文章目录深入解析 gRPC:高性能开源 RPC 框架的原理与实战引言一、gRPC 概览二、核心技术解析1. HTTP/2:传输层的革命2. Protocol Buffers:高效的序列化与契约3. 四种服务方法&…...