一文理解Transformer整套流程
【备注】部分图片引至他人博客,详情关注参考链接
【PS】query 、 key & value 的概念其实来源于推荐系统。基本原理是:给定一个 query,计算query 与 key 的相关性,然后根据query 与 key 的相关性去找到最合适的 value。举个例子:在电影推荐中。query 是某个人对电影的喜好信息(比如兴趣点、年龄、性别等)、key 是电影的类型(喜剧、年代等)、value 就是待推荐的电影。在这个例子中,query, key 和 value 的每个属性虽然在不同的空间,其实他们是有一定的潜在关系的,也就是说通过某种变换,可以使得三者的属性在一个相近的空间中。
1.综述



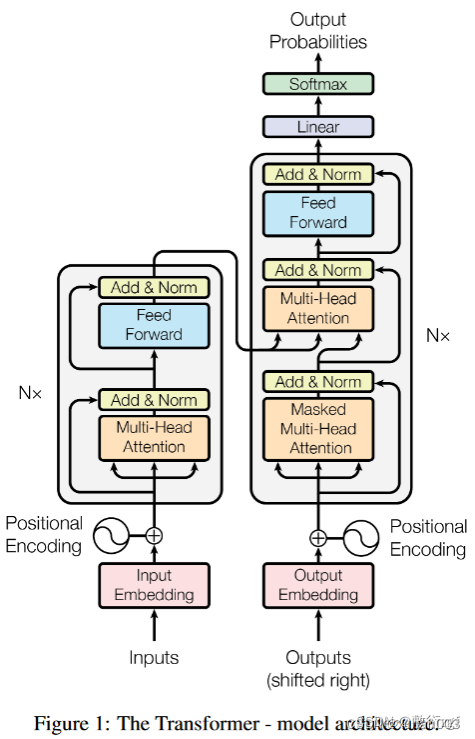
2.embedding
3.Positional Encoding
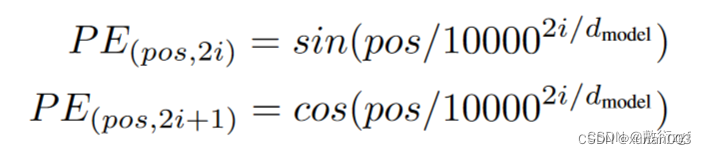
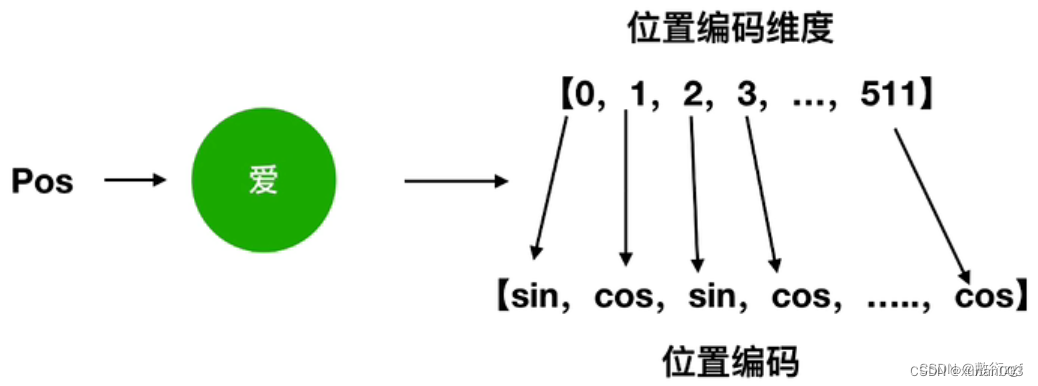
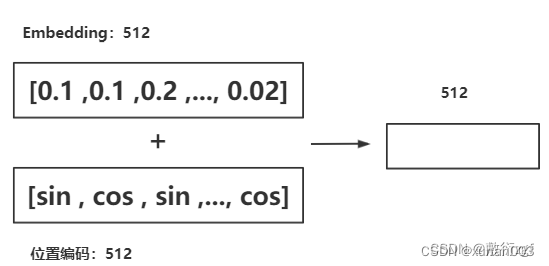
4.Encoder

5.self-attention
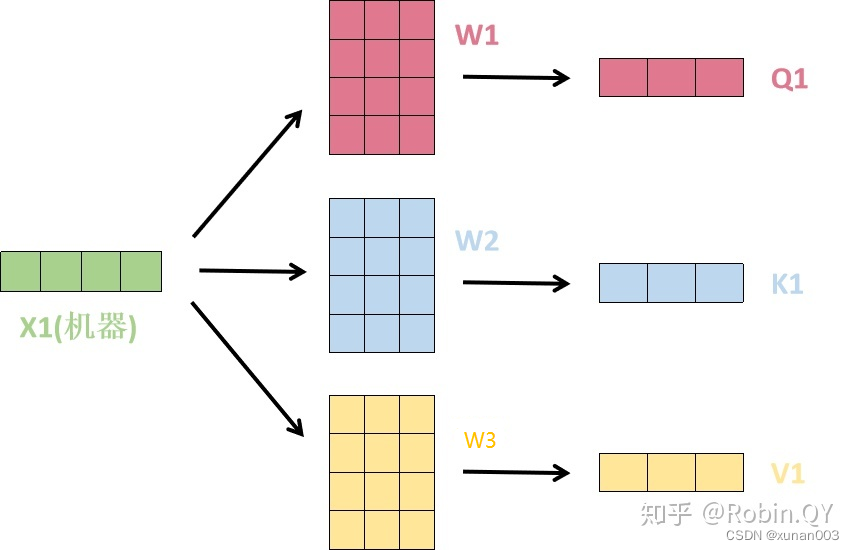
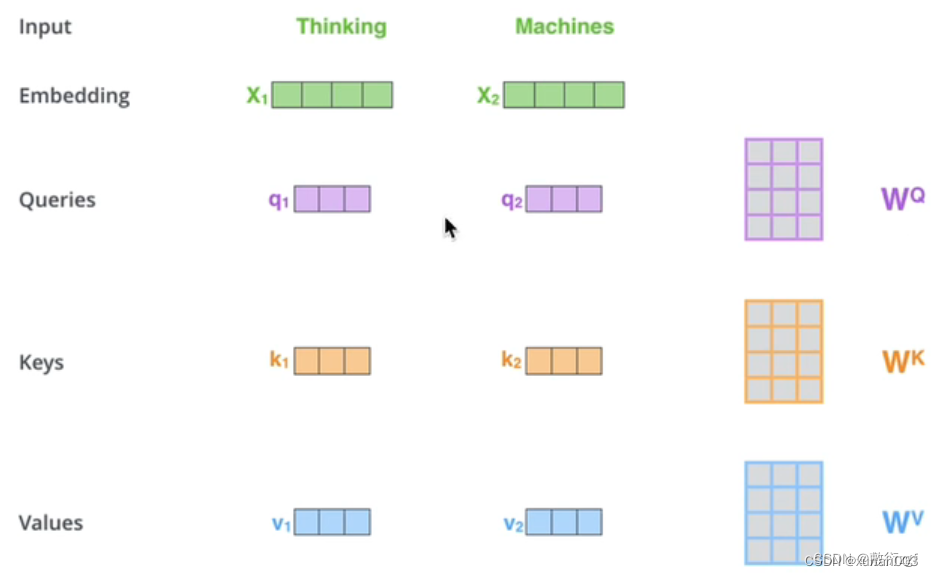
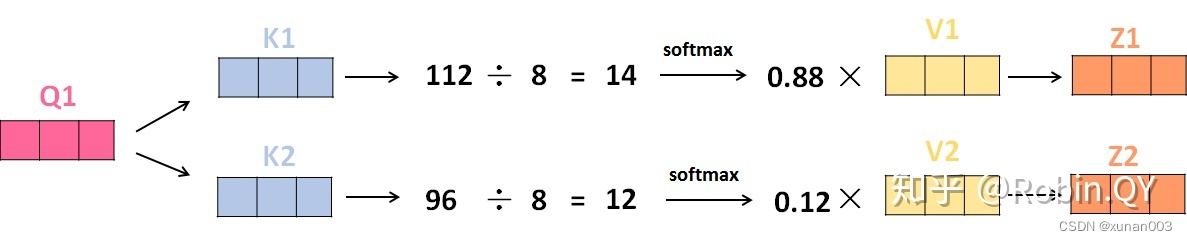

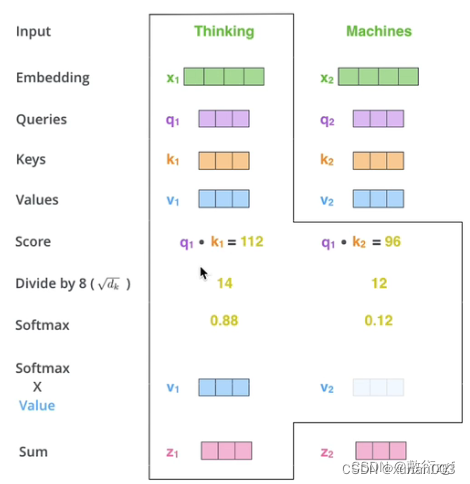
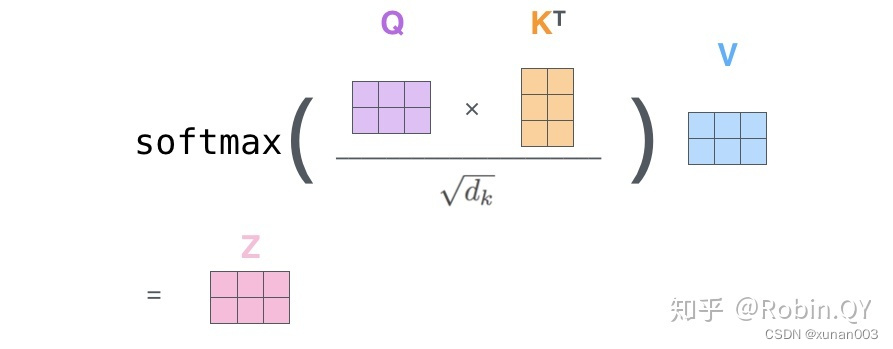
6.MultiHead-attention
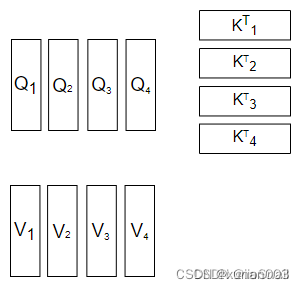
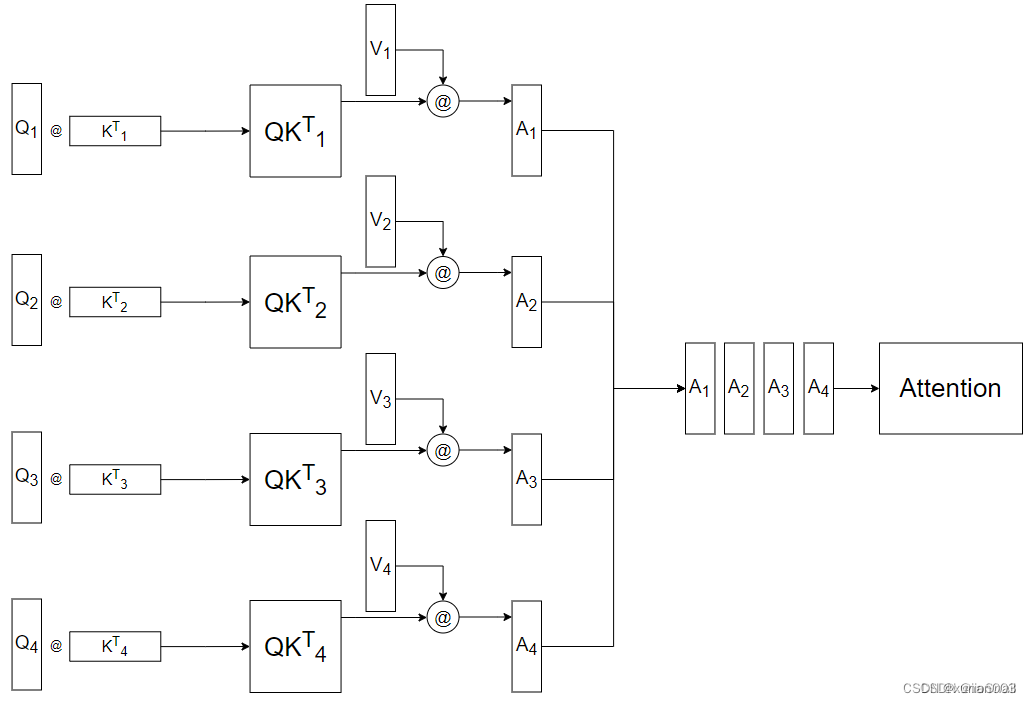
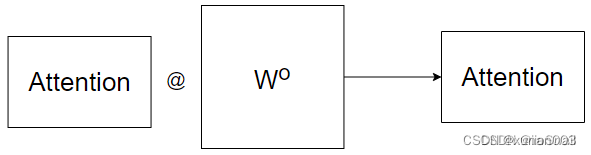

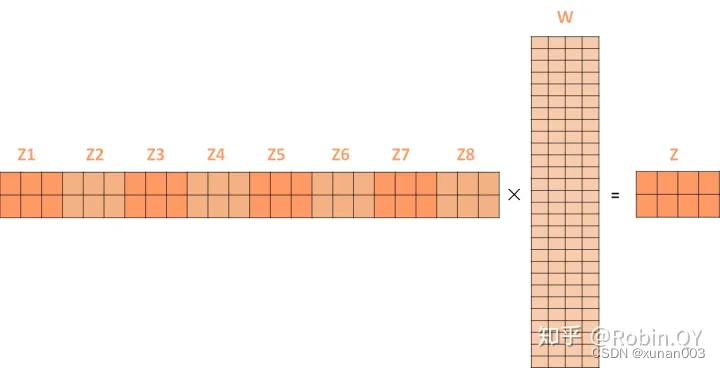
7.残差结构
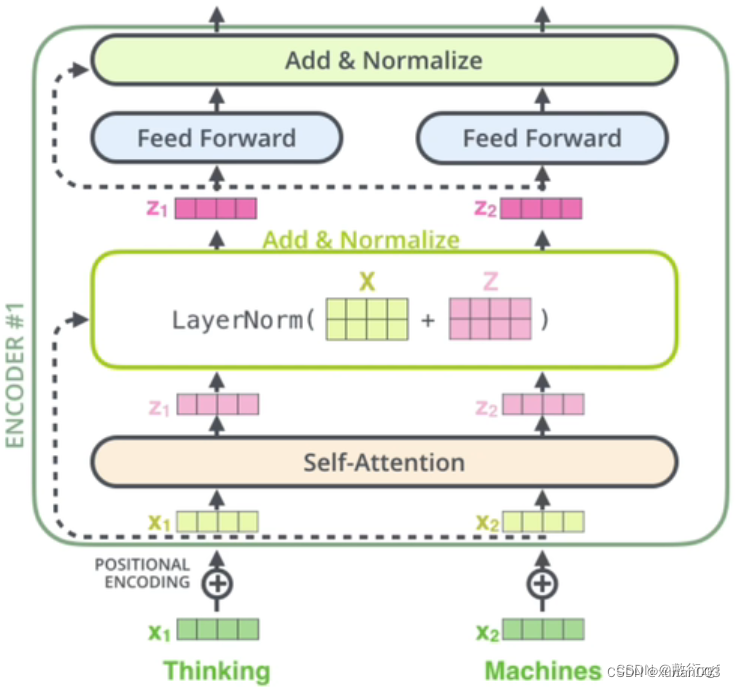
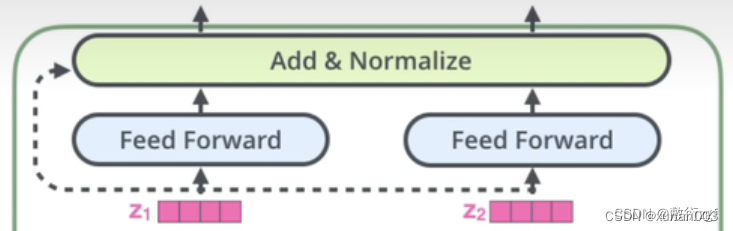
8.Feed_Forward(前馈网络)
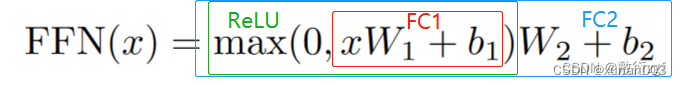
9.Decoder
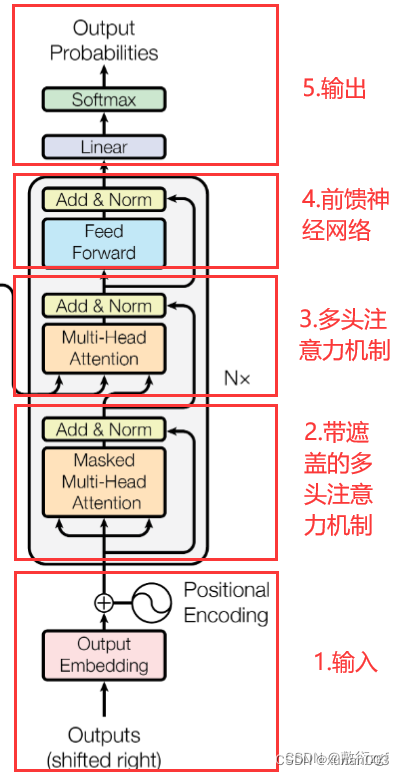
10.Decoder输入
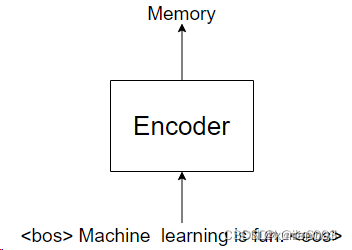
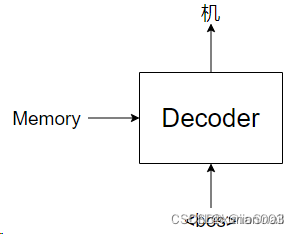
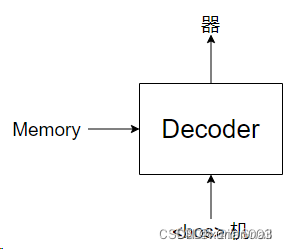
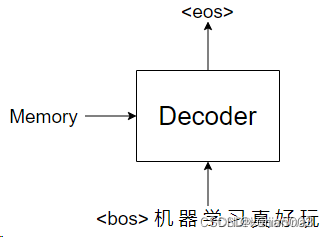
11.Masked MultiHead-attention
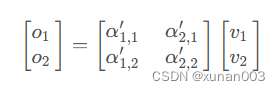
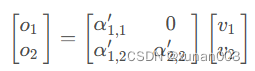
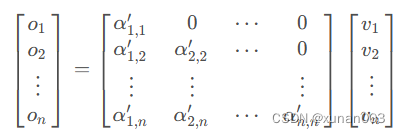

12.Masked Multi-Head attention输出
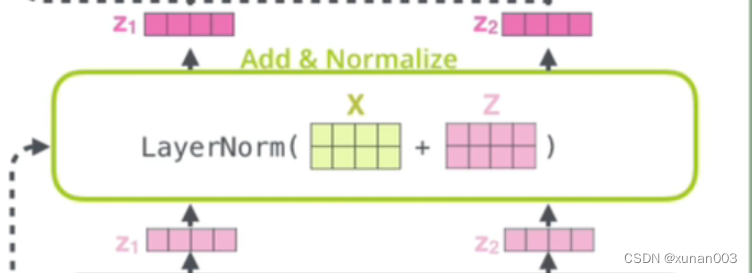
13.Transformer输出
相关文章:
一文理解Transformer整套流程
【备注】部分图片引至他人博客,详情关注参考链接 【PS】query 、 key & value 的概念其实来源于推荐系统。基本原理是:给定一个 query,计算query 与 key 的相关性,然后根据query 与 key 的相关性去找到最合适的 value。举个例…...

04、SpringBoot运维实用篇
一、配置文件1、临时属性设置目前我们的程序包打好了,可以发布了。但是程序包打好以后,里面的配置都已经是固定的了,比如配置了服务器的端口是8080。如果我要启动项目,发现当前我的服务器上已经有应用启动起来并且占用了8080端口&…...

3.Java运算符
Java运算符 运算符基本分为六类:算数运算符、赋值运算符、关系运算符、逻辑运算符、位运算符、三元(条件)运算符。 一、算术运算符 算数运算符,是指在Java运算中,计算数值类型的计算符号,既然是操作数值…...
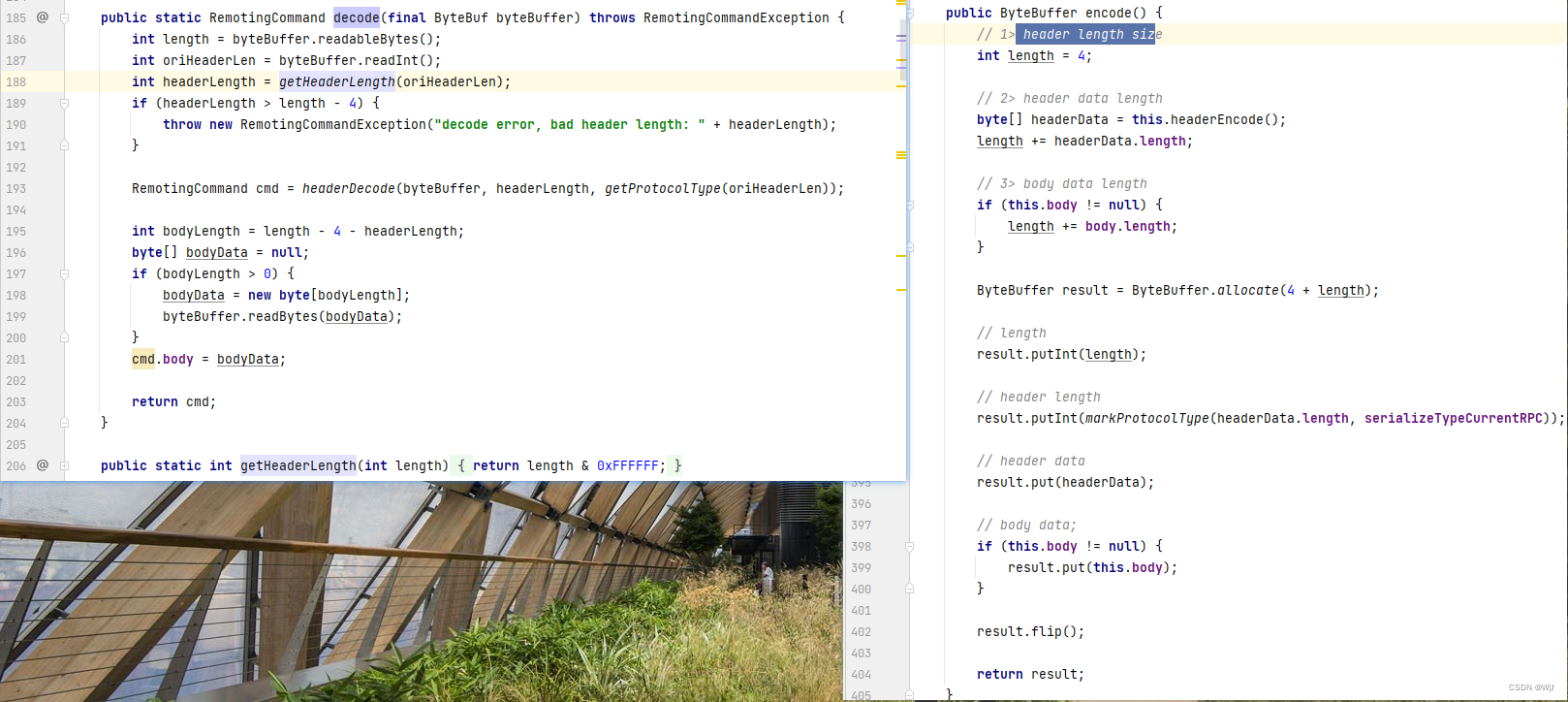
《RockectMQ实战与原理解析》Chapter4-分布式消息队列的协调者
4.1 NameServer 的功能 NameServer 是整个消息队列中的状态服务器,集群的各个组件通过它来了解全局的信息 。 同时,各个角色的机器都要定期向 NameServer 上报自己的状态,超时不上报的话, NameServer 会认为某个机器出故障不可用了…...

Spring Boot 最适配的 UI 是什么
与Spring Boot一起使用的最佳 UI 是什么? 我经常碰到的一个常见问题是“与 Spring Boot 一起使用的最佳 UI 是什么?” UI,也称为“用户界面”,有许多不同的风格。 UI 应用程序可能是用 Java Swing、FX 或其他一些技术编写的桌面应…...

TensorFlow 1.x 深度学习秘籍:6~10
原文:TensorFlow 1.x Deep Learning Cookbook 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关心如…...
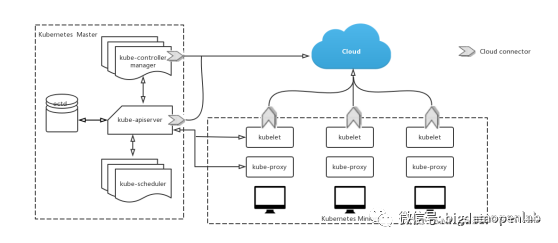
分布式场景下,Apache YARN、Google Kubernetes 如何解决资源管理问题?
所有的资源管理系统都需要解决资源的有效利用、任务的有效响应、调度策略的灵活配置这三个最基本问题。那么在分布式的场景下,YARN和Kubernetes是怎么解决的呢?本篇进行介绍。 — Apache YARN — YARN全称为(Yet Another Resource Negotiato…...

RK3399平台开发系列讲解(基础篇)POSIX 定时器
🚀返回专栏总目录 文章目录 一、clockid二、sigevent三、timerid四、flags五、 value & old_value六、POSIX 定时器的优势沉淀、分享、成长,让自己和他人都能有所收获!😄 📢为了克服传统定时器的局限性,POSIX 标准组织设计了新的计时器接口和规范,使它们能提供更…...
(完成度90%))
web小游戏开发:扫雷(三)(完成度90%)
web小游戏开发:扫雷(三) 实现布雷鼠标事件处理左键和右键单独实现实现递归展开追加地雷计数和时间计时小结书接前文啊,如果没看过前两篇的话,不好理解这里的定义了哦。 实现布雷 在之前两篇文章,我们已经把雷区布置好了,全部盖上了格子,现在我们需要把雷布出来,这就需…...

创建菜单栏、菜单、菜单项
1、QMainWindow窗口 1.1、创建菜单栏 this 代表的是 当前窗口(主窗口),也就是 当前窗口中添加/设置 菜单栏 this->resize(800,600); //创建 菜单栏 QMenuBar *menuBar new QMenuBar(this); //将菜单栏 添加到主窗口的特殊位置 this-&g…...

专访丨AWS量子网络中心科学家Antía Lamas谈量子计算
Anta Lamas Linares(图片来源:网络) 47岁的Anta Lamas Linares出生于西班牙西北部的圣地亚哥德孔波斯特拉。她在当地学习物理学,然后在牛津大学和加利福尼亚继续深造。后来,她在新加坡领导了亚马逊网络服务…...
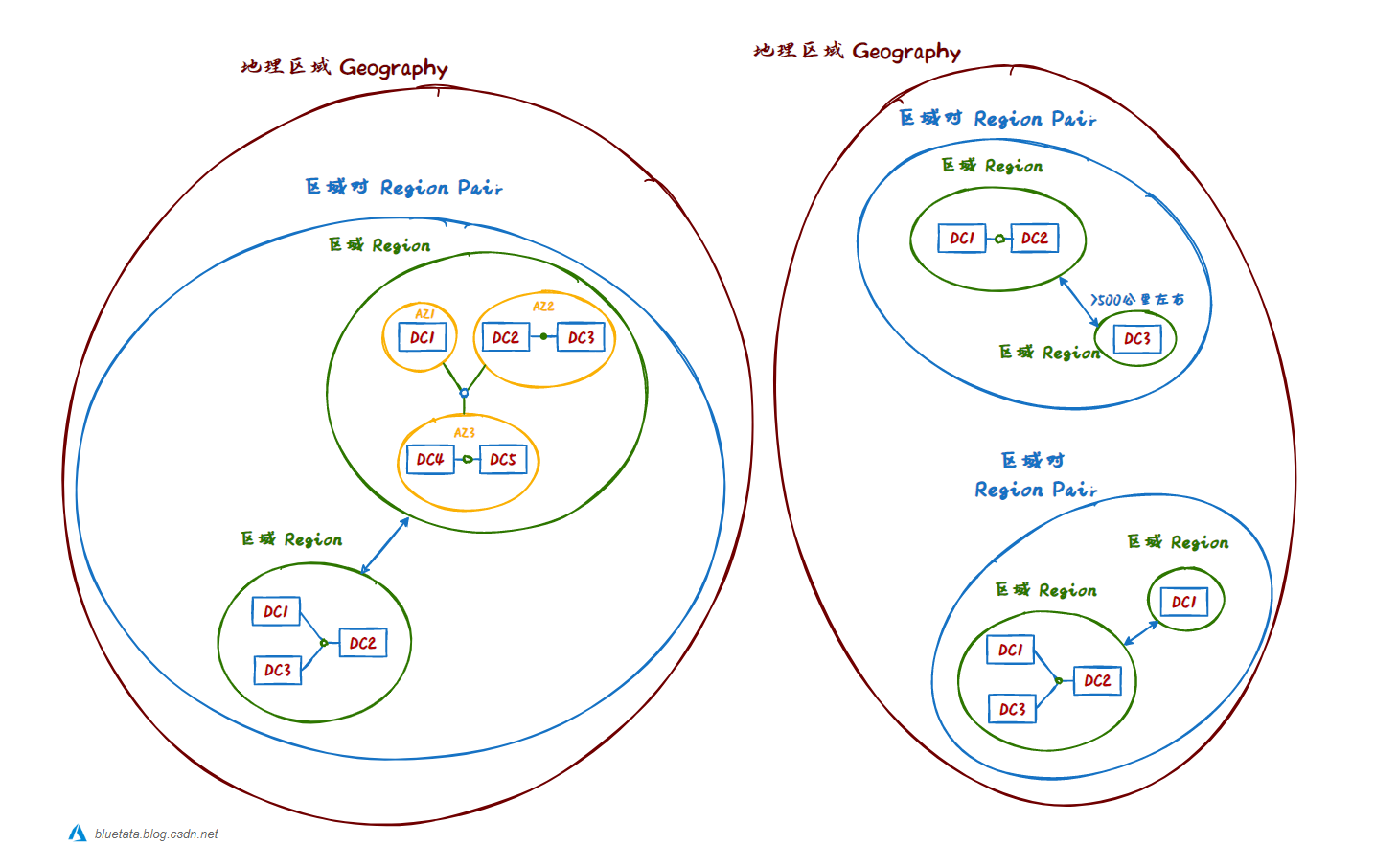
[ 云计算 | Azure ] Chapter 04 | 核心体系结构之数据中心、区域与区域对、可用区和地理区域
本章节主要内容进行讲解:Azure云计算的核心体系结构组件中的:Azure物理基础设施(Physical infrastructure),区域(Regions)和区域对(Region Pairs)、地理数据中心…...

升级长江存储最新闪存,忆恒创源发布新一代企业级NVMe SSD
2023年4月11日 —— 北京忆恒创源科技股份有限公司(Memblaze)正式发布搭载高品质国产闪存的PBlaze6 6541 系列企业级PCIe 4.0 NVMe SSD。作为 MUFP 平台化开发的最新作品,PBlaze6 6541 采用长江存储最新一代晶栈 Xtacking 3D NAND,…...

Xcode14:”Failed to prepare the device for development“解决
当前Xcode版本14.2,测试机iOS版本16.4, 结果出现提示:Failed to prepare the device for development,经过Clean,重装都无效,最后发现其他人也有类似的问题 https://developer.apple.com/forums/thread/714388 PS:首先…...

程序员的“灵魂笔记本“:五款高效笔记软件推荐
大家好,我是 jonssonyan。作为一名程序员,我们经常需要记录和整理大量的代码、知识和项目信息,以便在日后能够高效地进行查阅和复用。而好用的笔记软件则成为了我们的"灵魂笔记本",帮助我们提高工作效率。在这篇文章中&…...

Linux基础命令-scp远程复制文件
Linux基础命令-seq打印数字序列 前言 有时候不可避免的需要将文件复制到另外一台服务器上,那么这时就可以使用scp命令远程拷贝文件,scp命令是基于SSH协议,在复制的过程中数据都是加密过的,会比明文传输更为安全。 一.命令介绍 …...
、min()、max()函数)
【python学习】基础篇-列表元素排序操作 sort()、min()、max()函数
列表对象中提供了 sort0 方法,该方法用于对原列表中的元素进行排序,排序后原列表中的元素顺序将发生改变。 其语法格式如下: listname.sort(keyNone, reverseFalse) key:用于比较的键 reverse:可选参数,Fal…...

机器视觉检测系统的基本流程你知道吗
工业制造业种,首先我们便需要了解其基本流程,作为工厂信息科人员,我们不能只依靠视觉服务商的巡检驻检来解决问题,为了产线的效率提升,我们更多的应该培养产线技术人员,出现问题便可以最快速度解决问题&…...

【vue】Vue 开发技巧:
文章目录1.路由参数解耦2.功能组件3.样式范围4.watch的高级使用5.watch监听多个变量6.事件参数$event7.程序化事件监听器8.监听组件生命周期1.路由参数解耦 通常在组件中使用路由参数,大多数人会做以下事情。 export default {methods: {getParamsId() {return th…...

Kubebuilder Hello World
Kubebuilder Hello World 摘要:从0开始建立kubebuilder第一个程序 文章目录Kubebuilder Hello World0. 环境 简介0.1 环境0.2 什么是kubebuilder?1. 安装Kubebuilder1.1 需要预先准备好的环境1.2 安装kubebuilder & kustomize2. 项目初始化2.1 新建…...

订阅Token Plan套餐如何在实际开发中有效控制大模型调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 订阅Token Plan套餐如何在实际开发中有效控制大模型调用成本 对于开发团队而言,将大模型能力集成到自动化流程或内部工…...

【爱她就为她买龙虾】Open Claw 搭建使用全图文流程
❤️核心亮点❤️ 零代码门槛|全程可视化|无需手动配置环境|内置完整依赖|28 万 Tokens 额度 ༺♥༻下载地址 https://xiake.yun/api/download/package/16?promoCodeIV8E496E2F7A 🤍前言 2026 年热门的「数字员工…...

Folcolor:14种色彩让Windows文件夹管理效率提升300%
Folcolor:14种色彩让Windows文件夹管理效率提升300% 【免费下载链接】Folcolor Windows explorer folder coloring utility 项目地址: https://gitcode.com/gh_mirrors/fo/Folcolor 你是否厌倦了在无数个黄色文件夹中寻找目标文件?Folcolor为你带…...

从门电路到芯片:拆解一个D触发器,看数字电路如何实现‘记忆’这个核心功能
从门电路到芯片:拆解一个D触发器,看数字电路如何实现‘记忆’这个核心功能 数字世界的每一个比特信息都需要被精确存储和传递,而实现这一功能的核心元件便是触发器。当我们按下电脑的电源键,屏幕上闪现的第一个像素到硬盘中保存的…...

迪文串口屏界面开发避坑指南:T5L_DGUS Tool变量地址设置与数据通信那些事儿
迪文串口屏界面开发避坑指南:T5L_DGUS Tool变量地址设置与数据通信实战解析 在工业控制、智能家居和物联网设备的人机交互界面开发中,迪文串口屏因其高性价比和易用性广受欢迎。然而,当开发者从基础界面制作进阶到实际数据通信时,…...
)
仅剩最后47份!《Midjourney概念艺术创作密钥手册》(含23个受版权保护的材质编码+动态光照参数表)
更多请点击: https://codechina.net 第一章:《Midjourney概念艺术创作密钥手册》核心价值与版权说明 核心价值定位 本手册聚焦于概念艺术创作中“意图—提示—反馈—迭代”的闭环实践,提炼出可复用的提示工程范式、风格锚定策略与跨模态语义…...

CP2K实战指南:CUTOFF与REL_CUTOFF参数的系统化调优策略
1. 理解CUTOFF与REL_CUTOFF的核心作用 刚开始用CP2K做材料计算时,最让我头疼的就是MGRID里这两个参数。记得第一次跑硅晶体能量优化,结果比文献值差了近10%,导师指着屏幕问:"你的网格精度设对了吗?"当时真是…...

Layerdivider深度解析:5步实现智能图像分层,生成专业级PSD文件
Layerdivider深度解析:5步实现智能图像分层,生成专业级PSD文件 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider Layerdivider是一款…...

CANN/hccl参数面建链阶段故障诊断
参数面建链阶段 【免费下载链接】hccl 集合通信库(Huawei Collective Communication Library,简称HCCL)是基于昇腾AI处理器的高性能集合通信库,为计算集群提供高性能、高可靠的通信方案 项目地址: https://gitcode.com/cann/hcc…...
)
从LaTeX到手写笔记:希腊字母的‘两栖’书写实战指南(含清晰对比图)
从LaTeX到手写笔记:希腊字母的‘两栖’书写实战指南 在数字化与纸质化并行的学术工作流中,希腊字母的书写问题常常成为效率瓶颈。当你在深夜推导公式时,是否曾因手写θ与δ难以区分而被迫重新查阅资料?当你在整理课堂笔记时&#…...