NumPy 秘籍中文第二版:八、质量保证
原文:NumPy Cookbook - Second Edition
协议:CC BY-NC-SA 4.0
译者:飞龙
“如果您对计算机撒谎,它将帮助您。”
– Perry Farrar,ACM 通讯,第 28 卷
在本章中,我们将介绍以下秘籍:
- 安装 Pyflakes
- 使用 Pyflakes 执行静态分析
- 用 Pylint 分析代码
- 使用 Pychecker 执行静态分析
- 使用
docstrings测试代码 - 编写单元测试
- 使用模拟测试代码
- 以 BDD 方式来测试
简介
与普遍的看法相反,质量保证与其说是发现错误,不如说是发现它们。 我们将讨论两种提高代码质量,从而防止出现问题的方法。 首先,我们将对已经存在的代码进行静态分析。 然后,我们将讨论单元测试; 这包括模拟和行为驱动开发(BDD)。
安装 Pyflakes
Pyflakes 是 Python 代码分析包。 它可以分析代码并发现潜在的问题,例如:
- 未使用的导入
- 未使用的变量
准备
如有必要,请安装pip或easy_install。
操作步骤
选择以下之一来安装pyflakes:
-
使用
pip命令安装 pyflakes:$ sudo pip install pyflakes -
使用
easy_install命令安装 Pyflakes:$ sudo easy_install pyflakes -
这是在 Linux 上安装此包的两种方法:
Linux 包的名称也为
pyflakes。 例如,在 RedHat 上执行以下操作:$ sudo yum install pyflakes在 Debian/Ubuntu 上,命令如下:
$ sudo apt-get install pyflakes
另见
- Pyflakes 主页
使用 Pyflakes 执行静态分析
我们将对 NumPy 代码库的一部分执行静态分析。 为此,我们将使用 Git 签出代码。 然后,我们将使用pyflakes对部分代码进行静态分析。
操作步骤
要检查 NumPy 代码中,我们需要 Git。 安装 Git 超出了本书的范围:
-
用 Git 命令检索代码如下:
$ git clone git://github.com/numpy/numpy.git numpy或者,从这里下载源档案。
-
上一步使用完整的 NumPy 代码创建一个
numpy目录。 转到此目录,并在其中运行以下命令:$ pyflakes *.py pavement.py:71: redefinition of unused 'md5' from line 69 pavement.py:88: redefinition of unused 'GIT_REVISION' from line 86 pavement.py:314: 'virtualenv' imported but unused pavement.py:315: local variable 'e' is assigned to but never used pavement.py:380: local variable 'sdir' is assigned to but never used pavement.py:381: local variable 'bdir' is assigned to but never used pavement.py:536: local variable 'st' is assigned to but never used setup.py:21: 're' imported but unused setup.py:27: redefinition of unused 'builtins' from line 25 setup.py:124: redefinition of unused 'GIT_REVISION' from line 118 setupegg.py:17: 'setup' imported but unused setupscons.py:61: 'numpy' imported but unused setupscons.py:64: 'numscons' imported but unused setupsconsegg.py:6: 'setup' imported but unused这将对代码样式进行分析,并检查当前目录中所有 Python 脚本中的 PEP-8 违规情况。 如果愿意,还可以分析单个文件。
工作原理
正如您所见,分析代码样式并使用 Pyflakes 查找违反 PEP-8 的行为非常简单。 另一个优点是速度。 但是,Pyflakes 报告的错误类型的数量是有限的。
使用 Pylint 分析代码
Pylint 是另一个由 Logilab 创建的开源静态分析器 。 Pylint 比 Pyflakes 更复杂; 它允许更多的自定义和代码检查。 但是,它比 Pyflakes 慢。 有关更多信息,请参见手册。
在本秘籍中,我们再次从 Git 存储库下载 NumPy 代码-为简便起见,省略了此步骤。
准备
您可以从源代码发行版中安装 Pylint。 但是,有很多依赖项,因此最好使用easy_install或pip进行安装。 安装命令如下:
$ easy_install pylint
$ sudo pip install pylint操作步骤
我们将再次从 NumPy 代码库的顶部目录进行分析。 注意,我们得到了更多的输出。 实际上,Pylint 打印了太多文本,因此在这里大部分都必须省略:
$ pylint *.py
No config file found, using default configuration
************* Module pavement
C: 60: Line too long (81/80)
C:139: Line too long (81/80)
...
W: 50: TODO
W:168: XXX: find out which env variable is necessary to avoid the pb with python
W: 71: Reimport 'md5' (imported line 143)
F: 73: Unable to import 'paver'
F: 74: Unable to import 'paver.easy'
C: 79: Invalid name "setup_py" (should match (([A-Z_][A-Z0-9_]*)|(__.*__))$)
F: 86: Unable to import 'numpy.version'
E: 86: No name 'version' in module 'numpy'
C:149: Operator not followed by a space
if sys.platform =="darwin":^^
C:202:prepare_nsis_script: Missing docstring
W:228:bdist_superpack: Redefining name 'options' from outer scope (line 74)
C:231:bdist_superpack.copy_bdist: Missing docstring
W:275:bdist_wininst_nosse: Redefining name 'options' from outer scope (line 74)工作原理
Pylint 默认输出原始文本; 但是我们可以根据需要请求 HTML 输出。 消息具有以下格式:
MESSAGE_TYPE: LINE_NUM:[OBJECT:] MESSAGE消息类型可以是以下之一:
[R]:这意味着建议进行重构[C]:这意味着存在违反代码风格的情况[W]:用于警告小问题[E]:用于错误或潜在的错误[F]:这表明发生致命错误,阻止了进一步的分析
另见
- 使用 Pyflakes 执行静态分析
使用 Pychecker 执行静态分析
Pychecker 是一个古老的静态分析工具。 它不是十分活跃的开发工具,但它在此提到的速度又足够好。 在编写本书时,最新版本是 0.8.19,最近一次更新是在 2011 年。Pychecker 尝试导入每个模块并对其进行处理。 然后,它搜索诸如传递不正确数量的参数,使用不存在的方法传递不正确的格式字符串以及其他问题之类的问题。 在本秘籍中,我们将再次分析代码,但是这次使用 Pychecker。
操作步骤
-
从 Sourceforge 下载
tar.gz。 解压缩源归档文件并运行以下命令:$ python setup.py install或者,使用
pip安装 Pychecker:$ sudo pip install http://sourceforge.net/projects/pychecker/files/pychecker/0.8.19/pychecker-0.8.19.tar.gz/download -
分析代码,就像先前的秘籍一样。 我们需要的命令如下:
$ pychecker *.py ... Warnings......setup.py:21: Imported module (re) not used setup.py:27: Module (builtins) re-imported...
使用文档字符串测试代码
Doctests 是注释字符串,它们嵌入在类似交互式会话的 Python 代码中。 这些字符串可用于测试某些假设或仅提供示例。 我们需要使用doctest模块来运行这些测试。
让我们写一个简单的示例,该示例应该计算阶乘,但不涵盖所有可能的边界条件。 换句话说,某些测试将失败。
操作步骤
-
用将通过的测试和将失败的另一个测试编写
docstring。docstring文本应类似于在 Python shell 中通常看到的文本:""" Test for the factorial of 3 that should pass. >>> factorial(3) 6Test for the factorial of 0 that should fail. >>> factorial(0) 1 """ -
编写以下 NumPy 代码:
return np.arange(1, n+1).cumprod()[-1]我们希望这段代码有时会故意失败。 它将创建一个序列号数组,计算该数组的累积乘积,并返回最后一个元素。
-
使用
doctest模块运行测试:doctest.testmod()以下是本书代码包中
docstringtest.py文件的完整测试示例代码:import numpy as np import doctestdef factorial(n):"""Test for the factorial of 3 that should pass.>>> factorial(3)6Test for the factorial of 0 that should fail.>>> factorial(0)1"""return np.arange(1, n+1).cumprod()[-1]doctest.testmod()我们可以使用
-v选项获得详细的输出,如下所示:$ python docstringtest.py -v Trying:factorial(3) Expecting:6 ok Trying:factorial(0) Expecting:1 ********************************************************************** File "docstringtest.py", line 11, in __main__.factorial Failed example:factorial(0) Exception raised:Traceback (most recent call last):File ".../doctest.py", line 1253, in __runcompileflags, 1) in test.globsFile "<doctest __main__.factorial[1]>", line 1, in <module>factorial(0)File "docstringtest.py", line 14, in factorialreturn numpy.arange(1, n+1).cumprod()[-1]IndexError: index out of bounds 1 items had no tests:__main__ ********************************************************************** 1 items had failures:1 of 2 in __main__.factorial 2 tests in 2 items. 1 passed and 1 failed. ***Test Failed*** 1 failures.
工作原理
如您所见,我们没有考虑零和负数。 实际上,由于数组为空,我们出现了index out of bounds错误。 当然,这很容易解决,我们将在下一个教程中进行。
另见
doctest官方文档
编写单元测试
测试驱动开发(TDD)是本世纪软件开发诞生的最好的事情。 TDD 的最重要方面之一是,几乎把重点放在单元测试上。
注意
TDD 方法使用所谓的测试优先方法,在此方法中,我们首先编写一个失败的测试,然后编写相应的代码以通过测试。 测试应记录开发人员的意图,但要比功能设计的水平低。 一组测试通过降低回归概率来增加置信度,并促进重构。
单元测试是自动测试,通常测试一小段代码,通常是一个函数或方法。 Python 具有用于单元测试的 PyUnit API。 作为 NumPy 的用户,我们也可以使用numpy.testing模块中的便捷函数。 顾名思义,该模块专用于测试。
操作步骤
让我们编写一些代码进行测试:
-
首先编写以下
factorial()函数:def factorial(n):if n == 0:return 1if n < 0:raise ValueError, "Don't be so negative"return np.arange(1, n+1).cumprod()该代码与前面的秘籍中的代码相同,但是我们添加了一些边界条件检查。
-
让我们写一个类; 此类将包含单元测试。 它从
unittest模块扩展了TestCase类,是 Python 标准测试的一部分。 我们通过调用factorial()函数并运行以下代码来运行测试:-
一个正数-幸福的道路!
-
边界条件等于
0 -
负数,这将导致错误:
class FactorialTest(unittest.TestCase):def test_factorial(self):#Test for the factorial of 3 that should pass.self.assertEqual(6, factorial(3)[-1])np.testing.assert_equal(np.array([1, 2, 6]), factorial(3))def test_zero(self):#Test for the factorial of 0 that should pass.self.assertEqual(1, factorial(0))def test_negative(self):#Test for the factorial of negative numbers that should fail.# It should throw a ValueError, but we expect IndexErrorself.assertRaises(IndexError, factorial(-10))factorial()函数和整个单元测试的代码如下:import numpy as np import unittestdef factorial(n):if n == 0:return 1if n < 0:raise ValueError, "Don't be so negative"return np.arange(1, n+1).cumprod()class FactorialTest(unittest.TestCase):def test_factorial(self):#Test for the factorial of 3 that should pass.self.assertEqual(6, factorial(3)[-1])np.testing.assert_equal(np.array([1, 2, 6]), factorial(3))def test_zero(self):#Test for the factorial of 0 that should pass.self.assertEqual(1, factorial(0))def test_negative(self):#Test for the factorial of negative numbers that should fail.# It should throw a ValueError, but we expect IndexErrorself.assertRaises(IndexError, factorial(-10))if __name__ == '__main__':unittest.main()负数测试失败,如以下输出所示:
.E. ====================================================================== ERROR: test_negative (__main__.FactorialTest) ---------------------------------------------------------------------- Traceback (most recent call last):File "unit_test.py", line 26, in test_negativeself.assertRaises(IndexError, factorial(-10))File "unit_test.py", line 9, in factorialraise ValueError, "Don't be so negative" ValueError: Don't be so negative---------------------------------------------------------------------- Ran 3 tests in 0.001sFAILED (errors=1)
-
工作原理
我们看到了如何使用标准unittest Python 模块实现简单的单元测试。 我们编写了一个测试类 ,该类从unittest模块扩展了TestCase类。 以下函数用于执行各种测试:
| 函数 | 描述 |
|---|---|
numpy.testing.assert_equal() | 测试两个 NumPy 数组是否相等 |
unittest.assertEqual() | 测试两个值是否相等 |
unittest.assertRaises() | 测试是否引发异常 |
testing NumPy 包具有许多我们应该了解的测试函数,如下所示:
| 函数 | 描述 |
|---|---|
assert_almost_equal() | 如果两个数字不等于指定的精度,则此函数引发异常 |
assert_approx_equal() | 如果两个数字在一定意义上不相等,则此函数引发异常 |
assert_array_almost_equal() | 如果两个数组不等于指定的精度,此函数会引发异常 |
assert_array_equal() | 如果两个数组不相等,则此函数引发异常 |
assert_array_less() | 如果两个数组的形状不同,并且此函数引发异常,则第一个数组的元素严格小于第二个数组的元素 |
assert_raises() | 如果使用定义的参数调用的可调用对象未引发指定的异常,则此函数将失败 |
assert_warns() | 如果未抛出指定的警告,则此函数失败 |
assert_string_equal() | 此函数断言两个字符串相等 |
使用模拟测试代码
模拟是用来代替真实对象的对象,目的是测试真实对象的部分行为。 如果您看过电影《身体抢夺者》,您可能已经对基本概念有所了解。 一般来说, 仅在被测试的真实对象的创建成本很高(例如数据库连接)或测试可能产生不良副作用时才有用。 例如,我们可能不想写入文件系统或数据库。
在此秘籍中,我们将测试一个核反应堆,当然不是真正的反应堆! 此类核反应堆执行阶乘计算,从理论上讲,它可能导致连锁反应,进而导致核灾难。 我们将使用mock包通过模拟来模拟阶乘计算。
操作步骤
首先,我们将安装mock包; 之后,我们将创建一个模拟并测试一段代码:
-
要安装
mock包,请执行以下命令:$ sudo easy_install mock -
核反应堆类有一个
do_work()方法,该方法调用了我们要模拟的危险的factorial()方法。 创建一个模拟,如下所示:reactor.factorial = MagicMock(return_value=6)这样可以确保模拟返回值
6。 -
我们可以通过多种方式检查模拟的行为,然后从中检查真实对象的行为。 例如,断言使用正确的参数调用了潜在爆炸性的
factorial()方法,如下所示:reactor.factorial.assert_called_with(3, "mocked")带有模拟的完整测试代码如下:
from __future__ import print_function from mock import MagicMock import numpy as np import unittestclass NuclearReactor():def __init__(self, n):self.n = ndef do_work(self, msg):print("Working")return self.factorial(self.n, msg)def factorial(self, n, msg):print(msg)if n == 0:return 1if n < 0:raise ValueError, "Core meltdown"return np.arange(1, n+1).cumprod()class NuclearReactorTest(unittest.TestCase):def test_called(self):reactor = NuclearReactor(3)reactor.factorial = MagicMock(return_value=6)result = reactor.do_work("mocked")self.assertEqual(6, result)reactor.factorial.assert_called_with(3, "mocked")def test_unmocked(self):reactor = NuclearReactor(3)reactor.factorial(3, "unmocked")np.testing.assert_raises(ValueError)if __name__ == '__main__':unittest.main()
我们将一个字符串传递给factorial()方法,以显示带有模拟的代码不会执行实际的代码。 该单元测试的工作方式与上一秘籍中的单元测试相同。 这里的第二项测试不测试任何内容。 第二个测试的目的只是演示,如果我们在没有模拟的情况下执行真实代码,会发生什么。
测试的输出如下:
Working
.unmocked
.
----------------------------------------------------------------------
Ran 2 tests in 0.000sOK工作原理
模拟没有任何行为。 他们就像外星人的克隆人,假装是真实的人。 只能比外星人傻—外星人克隆人无法告诉您被替换的真实人物的生日。 我们需要设置它们以适当的方式进行响应。 例如,在此示例中,模拟返回6 。 我们可以记录模拟发生了什么,被调用了多少次以及使用了哪些参数。
另见
- Mock 包主页
以 BDD 方式来测试
BDD(行为驱动开发)是您可能遇到的另一个热门缩写。 在 BDD 中,我们首先根据某些约定和规则定义(英语)被测系统的预期行为。 在本秘籍中,我们将看到这些约定的示例。
这种方法背后的想法是,我们可以让可能无法编程或编写测试大部分内容的人员参加。 这些人编写的功能采用句子的形式,包括多个步骤。 每个步骤或多或少都是我们可以编写的单元测试,例如,使用 NumPy。 有许多 Python BDD 框架。 在本秘籍中,我们使用 Lettuce 来测试阶乘函数。
操作步骤
在本节中,您将学习如何安装 Lettuce,设置测试以及编写测试规范:
-
要安装 Lettuce,请运行以下命令之一:
$ pip install lettuce $ sudo easy_install lettuce -
Lettuce 需要特殊的目录结构进行测试。 在
tests目录中,我们将有一个名为features的目录,其中包含factorial.feature文件,以及steps.py文件中的功能说明和测试代码:./tests: features./tests/features: factorial.feature steps.py -
提出业务需求是一项艰巨的工作。 以易于测试的方式将其全部写下来更加困难。 幸运的是,这些秘籍的要求非常简单-我们只需写下不同的输入值和预期的输出。 我们在
Given,When和Then部分中有不同的方案,它们对应于不同的测试步骤。 为阶乘函数定义以下三种方案:Feature: Compute factorialScenario: Factorial of 0Given I have the number 0 When I compute its factorial Then I see the number 1Scenario: Factorial of 1Given I have the number 1 When I compute its factorial Then I see the number 1Scenario: Factorial of 3Given I have the number 3 When I compute its factorial Then I see the number 1, 2, 6 -
我们将定义与场景步骤相对应的方法。 要特别注意用于注释方法的文本。 它与业务场景文件中的文本匹配,并且我们使用正则表达式获取输入参数。 在前两个方案中,我们匹配数字,在最后一个方案中,我们匹配任何文本。
fromstring()NumPy 函数用于从 NumPy 数组创建字符串,字符串中使用整数数据类型和逗号分隔符。 以下代码测试了我们的方案:from lettuce import * import numpy as np@step('I have the number (\d+)') def have_the_number(step, number):world.number = int(number)@step('I compute its factorial') def compute_its_factorial(step):world.number = factorial(world.number)@step('I see the number (.*)') def check_number(step, expected):expected = np.fromstring(expected, dtype=int, sep=',')np.testing.assert_equal(world.number, expected, \"Got %s" % world.number)def factorial(n):if n == 0:return 1if n < 0:raise ValueError, "Core meltdown"return np.arange(1, n+1).cumprod() -
要运行测试,请转到
tests目录,然后键入以下命令:$ lettuceFeature: Compute factorial # features/factorial.feature:1Scenario: Factorial of 0 # features/factorial.feature:3Given I have the number 0 # features/steps.py:5When I compute its factorial # features/steps.py:9Then I see the number 1 # features/steps.py:13Scenario: Factorial of 1 # features/factorial.feature:8Given I have the number 1 # features/steps.py:5When I compute its factorial # features/steps.py:9Then I see the number 1 # features/steps.py:13Scenario: Factorial of 3 # features/factorial.feature:13Given I have the number 3 # features/steps.py:5When I compute its factorial # features/steps.py:9Then I see the number 1, 2, 6 # features/steps.py:131 feature (1 passed) 3 scenarios (3 passed) 9 steps (9 passed)
工作原理
我们定义了具有三个方案和相应步骤的函数。 我们使用 NumPy 的测试函数来测试不同步骤,并使用fromstring()函数从规格文本创建 NumPy 数组。
另见
- Lettuce 文档
相关文章:

NumPy 秘籍中文第二版:八、质量保证
原文:NumPy Cookbook - Second Edition 协议:CC BY-NC-SA 4.0 译者:飞龙 “如果您对计算机撒谎,它将帮助您。” – Perry Farrar,ACM 通讯,第 28 卷 在本章中,我们将介绍以下秘籍: …...
[ 应急响应篇基础 ] 日志分析工具Log Parser配合login工具使用详解(附安装教程)
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...
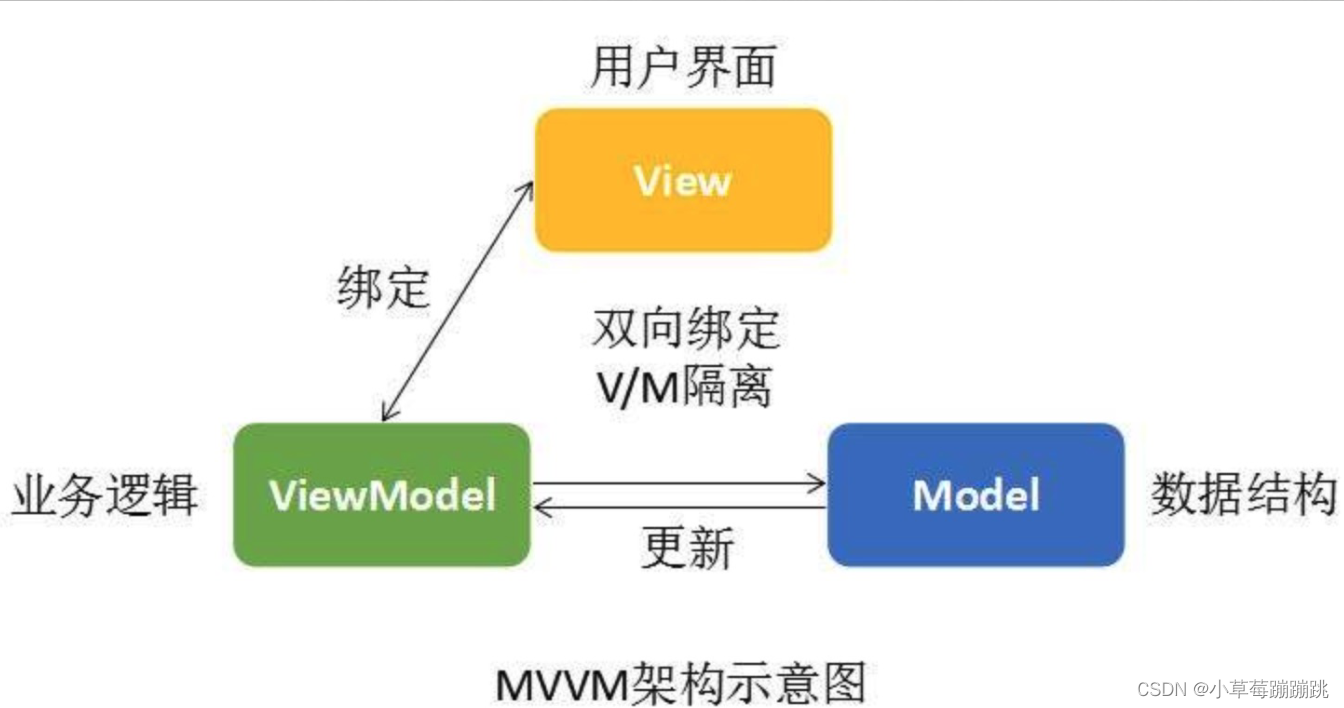
什么是MVVM?
MVVM 是 Model-View-ViewModel 的缩写,是M-V-VM三部分组成。它本质上就是MVC的改进版。 M:Model 代表数据模型,也可以在Model中定义数据修改和操作的业务逻辑。 V:View 代表视图UI,它负责将数据模型转化成UI 展现出来。…...

Java 企业电子招投标采购系统源码:采购过程更规范,更透明
满足采购业务全程数字化, 实现供应商管理、采购需求、全网寻源、全网比价、电子招 投标、合同订单执行的全过程管理。 电子招标采购,是指在网上寻源和采购产品和服务的过程。对于企业和企业主来说,这是个既省钱又能提高供应链效率的有效方法…...
)
1384:珍珠(bead)
1384:珍珠(bead) 时间限制: 1000 ms 内存限制: 65536 KB 【题目描述】 有n颗形状和大小都一致的珍珠,它们的重量都不相同。n为整数,所有的珍珠从1到n编号。你的任务是发现哪颗珍珠的重量刚好处于正中间,即在所有珍珠的重量…...

34岁本科男,做了5年功能测试想转行,除了进厂还能干什么?
我的建议是不要给自己设限。任何一个行业只要做到顶尖都是很有作为的,何况是IT行业,本身就比别的行业有优势,如果你现在是功能测试,应该想的是进阶自动化测试或者测试开发 如何在半年时间由功能测试成长为年薪30W的测试开发&#…...
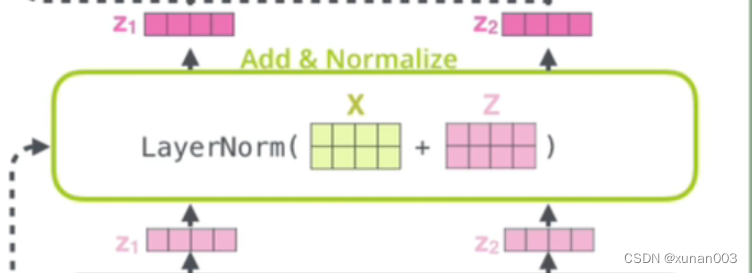
一文理解Transformer整套流程
【备注】部分图片引至他人博客,详情关注参考链接 【PS】query 、 key & value 的概念其实来源于推荐系统。基本原理是:给定一个 query,计算query 与 key 的相关性,然后根据query 与 key 的相关性去找到最合适的 value。举个例…...

04、SpringBoot运维实用篇
一、配置文件1、临时属性设置目前我们的程序包打好了,可以发布了。但是程序包打好以后,里面的配置都已经是固定的了,比如配置了服务器的端口是8080。如果我要启动项目,发现当前我的服务器上已经有应用启动起来并且占用了8080端口&…...

3.Java运算符
Java运算符 运算符基本分为六类:算数运算符、赋值运算符、关系运算符、逻辑运算符、位运算符、三元(条件)运算符。 一、算术运算符 算数运算符,是指在Java运算中,计算数值类型的计算符号,既然是操作数值…...
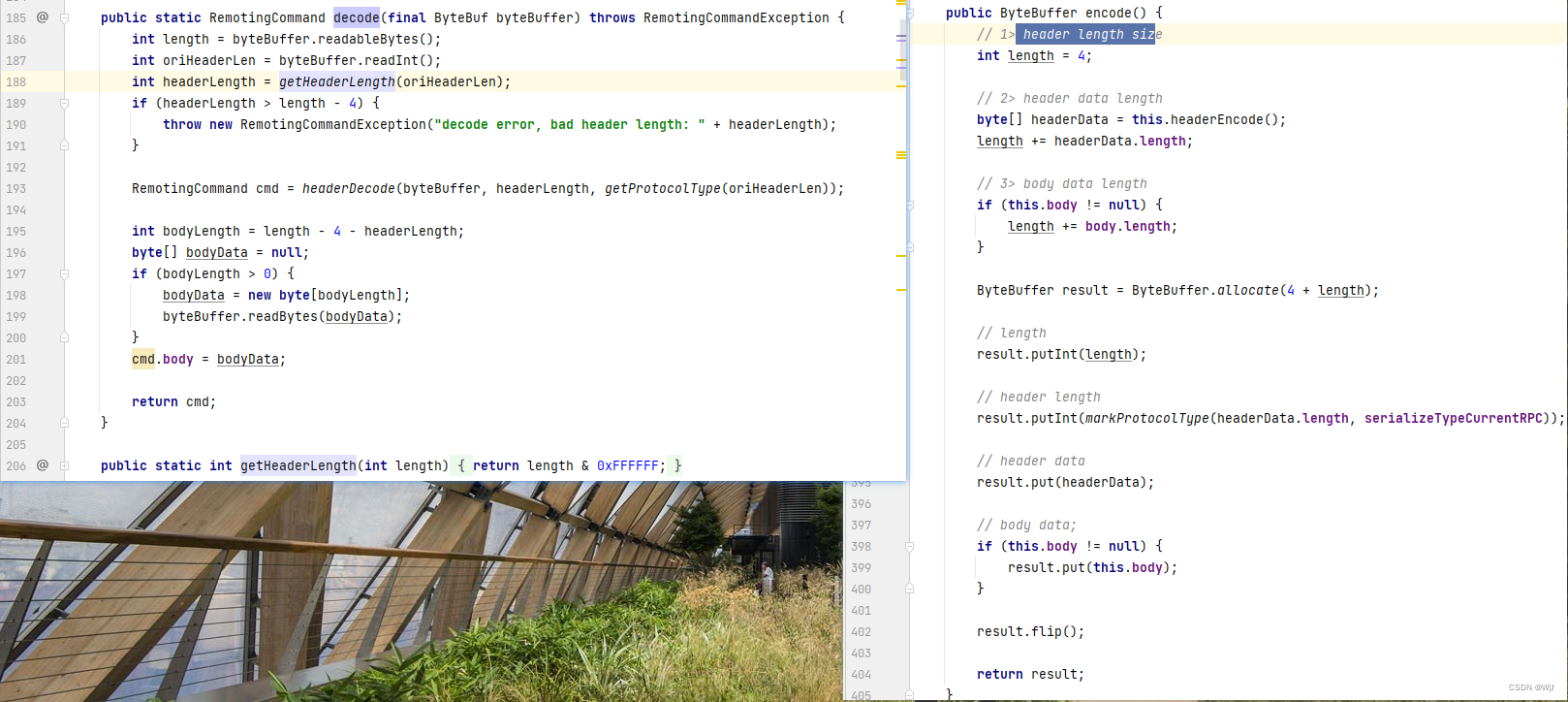
《RockectMQ实战与原理解析》Chapter4-分布式消息队列的协调者
4.1 NameServer 的功能 NameServer 是整个消息队列中的状态服务器,集群的各个组件通过它来了解全局的信息 。 同时,各个角色的机器都要定期向 NameServer 上报自己的状态,超时不上报的话, NameServer 会认为某个机器出故障不可用了…...

Spring Boot 最适配的 UI 是什么
与Spring Boot一起使用的最佳 UI 是什么? 我经常碰到的一个常见问题是“与 Spring Boot 一起使用的最佳 UI 是什么?” UI,也称为“用户界面”,有许多不同的风格。 UI 应用程序可能是用 Java Swing、FX 或其他一些技术编写的桌面应…...

TensorFlow 1.x 深度学习秘籍:6~10
原文:TensorFlow 1.x Deep Learning Cookbook 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关心如…...
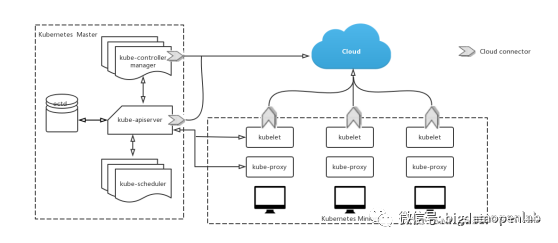
分布式场景下,Apache YARN、Google Kubernetes 如何解决资源管理问题?
所有的资源管理系统都需要解决资源的有效利用、任务的有效响应、调度策略的灵活配置这三个最基本问题。那么在分布式的场景下,YARN和Kubernetes是怎么解决的呢?本篇进行介绍。 — Apache YARN — YARN全称为(Yet Another Resource Negotiato…...

RK3399平台开发系列讲解(基础篇)POSIX 定时器
🚀返回专栏总目录 文章目录 一、clockid二、sigevent三、timerid四、flags五、 value & old_value六、POSIX 定时器的优势沉淀、分享、成长,让自己和他人都能有所收获!😄 📢为了克服传统定时器的局限性,POSIX 标准组织设计了新的计时器接口和规范,使它们能提供更…...
(完成度90%))
web小游戏开发:扫雷(三)(完成度90%)
web小游戏开发:扫雷(三) 实现布雷鼠标事件处理左键和右键单独实现实现递归展开追加地雷计数和时间计时小结书接前文啊,如果没看过前两篇的话,不好理解这里的定义了哦。 实现布雷 在之前两篇文章,我们已经把雷区布置好了,全部盖上了格子,现在我们需要把雷布出来,这就需…...

创建菜单栏、菜单、菜单项
1、QMainWindow窗口 1.1、创建菜单栏 this 代表的是 当前窗口(主窗口),也就是 当前窗口中添加/设置 菜单栏 this->resize(800,600); //创建 菜单栏 QMenuBar *menuBar new QMenuBar(this); //将菜单栏 添加到主窗口的特殊位置 this-&g…...

专访丨AWS量子网络中心科学家Antía Lamas谈量子计算
Anta Lamas Linares(图片来源:网络) 47岁的Anta Lamas Linares出生于西班牙西北部的圣地亚哥德孔波斯特拉。她在当地学习物理学,然后在牛津大学和加利福尼亚继续深造。后来,她在新加坡领导了亚马逊网络服务…...
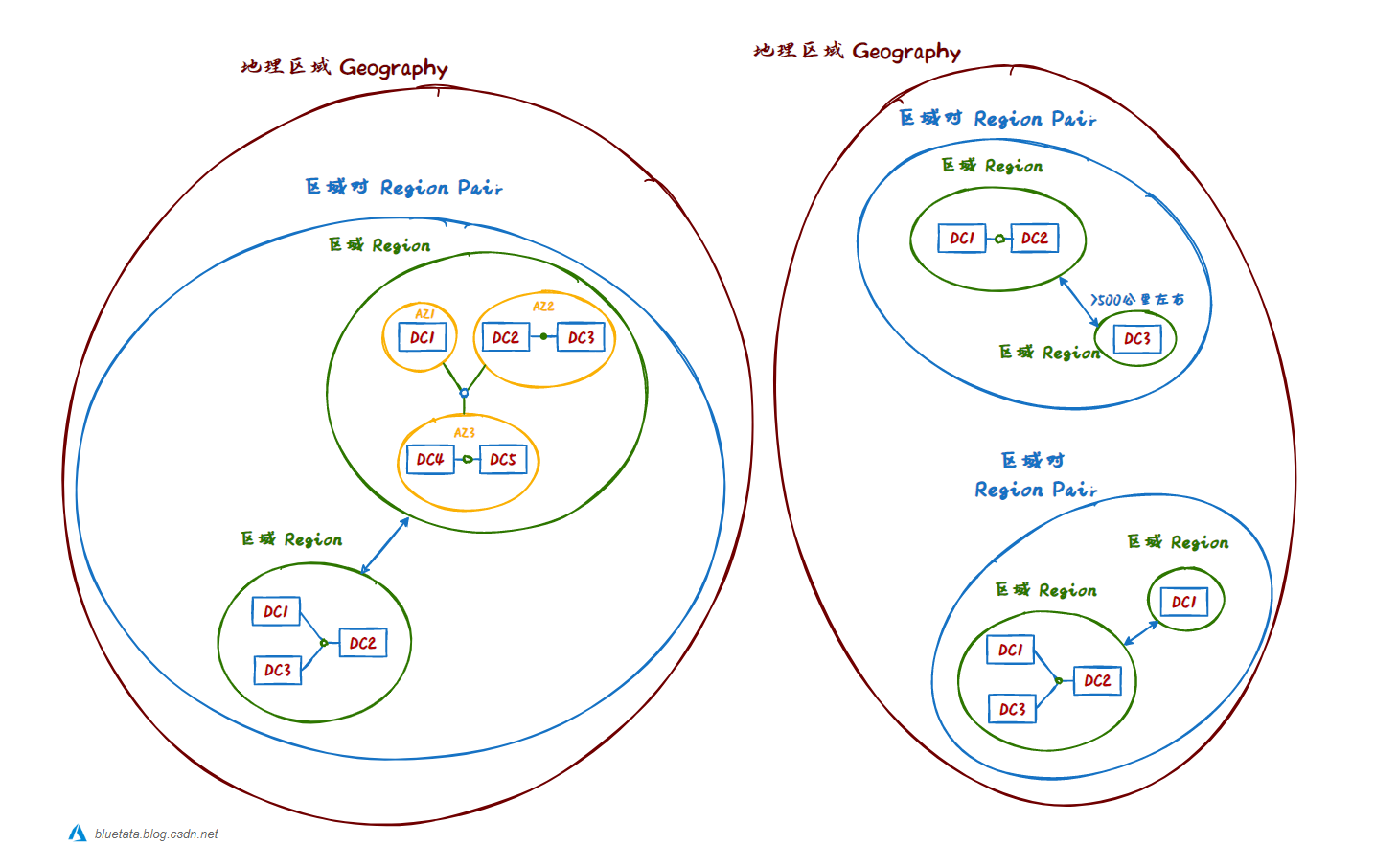
[ 云计算 | Azure ] Chapter 04 | 核心体系结构之数据中心、区域与区域对、可用区和地理区域
本章节主要内容进行讲解:Azure云计算的核心体系结构组件中的:Azure物理基础设施(Physical infrastructure),区域(Regions)和区域对(Region Pairs)、地理数据中心…...

升级长江存储最新闪存,忆恒创源发布新一代企业级NVMe SSD
2023年4月11日 —— 北京忆恒创源科技股份有限公司(Memblaze)正式发布搭载高品质国产闪存的PBlaze6 6541 系列企业级PCIe 4.0 NVMe SSD。作为 MUFP 平台化开发的最新作品,PBlaze6 6541 采用长江存储最新一代晶栈 Xtacking 3D NAND,…...

Xcode14:”Failed to prepare the device for development“解决
当前Xcode版本14.2,测试机iOS版本16.4, 结果出现提示:Failed to prepare the device for development,经过Clean,重装都无效,最后发现其他人也有类似的问题 https://developer.apple.com/forums/thread/714388 PS:首先…...

PDF怎么另存为JPG?5款工具2026年实测对比,电脑和手机都能用
想要把PDF文件转换成图片格式?无论是为了方便分享、减小文件大小,还是为了在不同平台使用,PDF转JPG都是一个常见需求。这篇文章就为你详细介绍PDF另存为JPG的多种方法,涵盖电脑和手机两大场景,让你快速找到最适合自己的…...

从代码到生活:技术人的自我成长之路
从代码到生活:技术人的自我成长之路 引言 作为一名技术人,我们的成长不仅体现在技术能力的提升上,更体现在个人生活的方方面面。今天就来分享一下我的自我成长之路,希望能给你一些启发。 技术成长 持续学习 技术发展很快ÿ…...

对比官方原价Taotoken活动价带来的Token成本优化感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方原价与Taotoken活动价带来的Token成本优化感受 1. 引言:开发者视角下的模型调用成本 对于频繁使用大模型API进…...

别再让脚本报错了!按键精灵CBool、CStr、CInt等6种类型转换函数保姆级教程
按键精灵类型转换实战指南:从报错到精通的六种武器 在自动化脚本开发的世界里,按键精灵就像一位不知疲倦的数字助手,能够代替我们完成各种重复性操作。但这位助手有时也会闹脾气——当你从网页抓取的数据需要计算时,当界面读取的…...
)
从芯片手册到PCB:手把手教你用TPS5430搞定24V转15V电源(附完整BOM清单)
从芯片手册到PCB:手把手教你用TPS5430搞定24V转15V电源(附完整BOM清单) 在硬件设计领域,电源模块的设计往往是最基础却也最考验工程师功底的环节。一个优秀的电源设计不仅需要满足电压转换的基本需求,还要兼顾效率、稳…...

Flutter代码混淆实战:五大常见问题与解决方案详解
1. 项目概述:为什么Flutter代码混淆是“必修课”而非“选修课”最近在跟几个独立开发者和中小团队聊Flutter应用上架后的安全状况,发现一个挺普遍的现象:很多人对Flutter的代码混淆要么是“听说过但没做过”,要么是“做了但问题一…...

告别寄存器操作:在RA4M2上体验瑞萨FSP库点灯,对比STM32 HAL/LL库有何不同?
从STM32到RA4M2:FSP库与HAL/LL库的深度对比与实践指南 如果你已经习惯了STM32的HAL库或LL库开发,初次接触瑞萨RA4M2的FSP库可能会感到既熟悉又陌生。本文将带你深入比较这两种开发方式的异同,并通过一个实际的LED控制案例,展示如何…...

统计显著性骗局
原文:towardsdatascience.com/the-statistical-significance-scam-db904be36714?sourcecollection_archive---------0-----------------------#2024-11-09 深入剖析科学最爱工具的缺陷 https://medium.com/caiparryjones96?sourcepost_page---byline--db904be367…...
)
告别串口打印!用STM32+DS18B20做个OLED温湿度计(HAL库+SSD1306)
STM32实战:打造OLED温湿度监测系统(DS18B20SSD1306) 每次调试嵌入式项目时,盯着串口助手看数据总有种隔靴搔痒的感觉。最近在工作室整理零件时,发现抽屉里还躺着几片0.96寸OLED和DS18B20温度传感器,突然萌生…...

PotPlayer智能字幕翻译:用百度翻译API打破语言障碍的观影体验
PotPlayer智能字幕翻译:用百度翻译API打破语言障碍的观影体验 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu 你是否曾在观…...