Hadoop之Yarn篇

目录
编辑
Yarn的工作机制:
全流程作业:
Yarn的调度器与调度算法:
FIFO调度器(先进先出):
容量调度器(Capacity Scheduler):
容量调度器资源分配算法:
编辑
公平调度器(Fair Scheduler):
Yarn的常用命令:
yarn application查看任务
(1)列出所有Application:
(2)根据Application状态过滤:
(3)Kill掉Application:
yarn logs查看日志:
(1)查询Application日志:
(2)查询Container日志:
yarn applicationattempt查看尝试运行的任务
yarn container查看容器
(1)列出所有Container:
(2)打印Container状态:
***注:只有在任务跑的途中才能看到container的状态
yarn node查看节点状态:
列出所有节点:
yarn rmadmin更新配置
加载队列配置:
yarn queue查看队列:
打印队列信息:
Yarn生产环境核心参数:
环境配置代码:
2.2.4 任务优先级
公平调度器案例
Yarn的工作机制:
(其实主要为YARN与MapReduce的交互)
(0): 在linux中运行打包的Java程序 (wc.jar)程序的入口是main方法
在程序的最后一行 job.waitForCompletion()会创建YarnRunner(本地创建---)
(1): YarnRunner向集群(ResourceManger)申请Application(后边详讲作用)=
(2): Application资源提交路径
(3): 提交job运行所需要的资源(Job.spilt Job.xml wc.jar )(按照(2)中提供的路径进行上传)
(4) 资源提交完毕后,申请运行mrAppMaster (程序运行的老大)
(5) 将用户的请求初始化成一个Task (让后放入任务队列中---FIFO调度队列)
(6) NodeManger领取Task任务
(7) NodeManger创建容器,任何任务的执行都是在容器中执行的(容器中有cpu+ram--网络资 源),并且在容器中启动了一个MRAppmaster
(8) MRAppmaster下载job资源到本地
(9) MRAppmaster根据job资源(切片)申请运行MapTask容器
(10) 领取任务,创建MapTask容器(NodeManager)(cpu+ram+jar)
(11) MRAppmaster 发送程序,启动脚本(MapTask)
(12) MapTask运行结束后MRAppmaster得到信息,向RM申请两个容器,运行Reduce Task程序
(13) Reduce向Map获取相应分区的数据
(14) 程序结束后,MR会向RM注销自己(释放资源)

全流程作业:
主要了解HDFS,YARN,MapReduce三者之间的关系
Yarn的调度器与调度算法:
多个客户端向集群提交任务,任务多了集群会把任务放入到任务队列中进行管理。
Hadoop作业调度器主要有三种:FIFO、容量(Capacity Scheduler)和公平(Fair Scheduler)。Apache Hadoop3.1.3默认的资源调度器是Capacity Scheduler。
CDH框架默认调度器是Fair Scheduler。
FIFO调度器(先进先出):
FIFO调度器(First In First Out):单队列,根据提交作业的先后顺序,进行先来先服务。
优点:简单易懂;
缺点:不支持多队列,生产环境很少使用;(在大数据中,体现大容量,高并发,不能满足)
容量调度器(Capacity Scheduler):
Capacity Scheduler是Yahoo开发的多用户调度器。(多个用户可以提交任务)

容量调度器资源分配算法:

公平调度器(Fair Scheduler):
Fair Schedulere是Facebook开发的 多用户调度器。

缺额问题:





Yarn的常用命令:
yarn application查看任务
(1)列出所有Application:
yarn application -list 是查看mapreduce运行过程的状态
在测试中经常用下述命令,简单解释一下:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /outputhadoop: Hadoop框架的命令行工具jar: 运行MapReduce任务所需的Java可执行jar包share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar: Hadoop自带的MapReduce示例程序的jar包,其中包括了一些常用的MapReduce任务的示例代码wordcount: 示例程序中的一个任务,表示统计给定文本中每个单词出现的次数(wordcount是一个由Apache Hadoop社区提供的系统自带的示例MapReduce程序,用于统计给定文本中每个单词出现的次数。在Hadoop安装包中的hadoop-mapreduce-examples-*.jar文件中包含了wordcount等多个示例程序的源代码和二进制文件。使用
)wordcount示例程序可以帮助开发人员了解MapReduce编程的基本概念和实现方式,同时也可以作为一个基础模板,为开发定制化的MapReduce任务提供参考。因此,在学习和使用Hadoop MapReduce时,wordcount通常是第一个学习的示例程序之一。/input: 待处理的输入文件或文件夹路径,输入文件可以是本地文件系统上的文件,也可以是HDFS上的文件/output: 处理结果输出路径,输出结果将会写入HDFS上的这个路径中,如果该路径不存在,则会自动创建
因此,运行这个命令会在Hadoop集群上启动一个名为wordcount的MapReduce任务,统计/input路径下的文本中每个单词出现的次数,并将结果输出到/output路径中。
(2)根据Application状态过滤:
yarn application -list -appStates (所有状态:ALL、NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED)
yarn application -list -appStates FINISHED 是查看已经结束的任务
(3)Kill掉Application:
yarn application -kill 任务ID
在某个任务比较消耗时间的时候 需要杀死 启用此命令
yarn logs查看日志:
(1)查询Application日志:
yarn logs -applicationId <任务ID--应用程序>
(2)查询Container日志:
yarn logs -applicationId <ApplicationId> -containerId(容器) <ContainerId>
yarn applicationattempt查看尝试运行的任务
即查看正在运行的状态
yarn applicationattempt -list 任务ID
yarn container查看容器
(1)列出所有Container:
yarn container -list <ApplicationAttemptId>
(2)打印Container状态:
yarn container -status <ContainerId>
***注:只有在任务跑的途中才能看到container的状态
yarn node查看节点状态:
列出所有节点:
yarn node -list -all
yarn rmadmin更新配置
加载队列配置:
yarn rmadmin -refreshQueues
yarn queue查看队列:
打印队列信息:
yarn queue -status <QueueName>
(都有 default队列)
Yarn生产环境核心参数:

环境配置代码:
将代码添加到yarn-site.xml文件下
让后进行分发
重置后要重启集群才能发挥作用
<!-- 选择调度器,默认容量 -->
<property><description>The class to use as the resource scheduler.</description><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property><!-- ResourceManager处理调度器请求的线程数量,默认50;如果提交的任务数大于50,可以增加该值,但是不能超过3台 * 4线程 = 12线程(去除其他应用程序实际不能超过8) -->
<property><description>Number of threads to handle scheduler interface.</description><name>yarn.resourcemanager.scheduler.client.thread-count</name><value>8</value>
</property><!-- 是否让yarn自动检测硬件进行配置,默认是false,如果该节点有很多其他应用程序,建议手动配置。如果该节点没有其他应用程序,可以采用自动 -->
<property><description>Enable auto-detection of node capabilities such asmemory and CPU.</description><name>yarn.nodemanager.resource.detect-hardware-capabilities</name><value>false</value>
</property><!-- 是否将虚拟核数当作CPU核数,默认是false,采用物理CPU核数 -->
<property><description>Flag to determine if logical processors(such ashyperthreads) should be counted as cores. Only applicable on Linuxwhen yarn.nodemanager.resource.cpu-vcores is set to -1 andyarn.nodemanager.resource.detect-hardware-capabilities is true.</description><name>yarn.nodemanager.resource.count-logical-processors-as-cores</name><value>false</value>
</property><!-- 虚拟核数和物理核数乘数,默认是1.0 -->
<property><description>Multiplier to determine how to convert phyiscal cores tovcores. This value is used if yarn.nodemanager.resource.cpu-vcoresis set to -1(which implies auto-calculate vcores) andyarn.nodemanager.resource.detect-hardware-capabilities is set to true. The number of vcores will be calculated as number of CPUs * multiplier.</description><name>yarn.nodemanager.resource.pcores-vcores-multiplier</name><value>1.0</value>
</property><!-- NodeManager使用内存数,默认8G,修改为4G内存 -->
<property><description>Amount of physical memory, in MB, that can be allocated for containers. If set to -1 andyarn.nodemanager.resource.detect-hardware-capabilities is true, it isautomatically calculated(in case of Windows and Linux).In other cases, the default is 8192MB.</description><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value>
</property><!-- nodemanager的CPU核数,不按照硬件环境自动设定时默认是8个,修改为4个 -->
<property><description>Number of vcores that can be allocatedfor containers. This is used by the RM scheduler when allocatingresources for containers. This is not used to limit the number ofCPUs used by YARN containers. If it is set to -1 andyarn.nodemanager.resource.detect-hardware-capabilities is true, it isautomatically determined from the hardware in case of Windows and Linux.In other cases, number of vcores is 8 by default.</description><name>yarn.nodemanager.resource.cpu-vcores</name><value>4</value>
</property><!-- 容器最小内存,默认1G -->
<property><description>The minimum allocation for every container request at the RM in MBs. Memory requests lower than this will be set to the value of this property. Additionally, a node manager that is configured to have less memory than this value will be shut down by the resource manager.</description><name>yarn.scheduler.minimum-allocation-mb</name><value>1024</value>
</property><!-- 容器最大内存,默认8G,修改为2G -->
<property><description>The maximum allocation for every container request at the RM in MBs. Memory requests higher than this will throw an InvalidResourceRequestException.</description><name>yarn.scheduler.maximum-allocation-mb</name><value>2048</value>
</property><!-- 容器最小CPU核数,默认1个 -->
<property><description>The minimum allocation for every container request at the RM in terms of virtual CPU cores. Requests lower than this will be set to the value of this property. Additionally, a node manager that is configured to have fewer virtual cores than this value will be shut down by the resource manager.</description><name>yarn.scheduler.minimum-allocation-vcores</name><value>1</value>
</property><!-- 容器最大CPU核数,默认4个,修改为2个 -->
<property><description>The maximum allocation for every container request at the RM in terms of virtual CPU cores. Requests higher than this will throw anInvalidResourceRequestException.</description><name>yarn.scheduler.maximum-allocation-vcores</name><value>2</value>
</property><!-- 虚拟内存检查,默认打开,修改为关闭 -->
<property><description>Whether virtual memory limits will be enforced forcontainers.</description><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property><!-- 虚拟内存和物理内存设置比例,默认2.1 -->
<property><description>Ratio between virtual memory to physical memory when setting memory limits for containers. Container allocations are expressed in terms of physical memory, and virtual memory usage is allowed to exceed this allocation by this ratio.</description><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value>
</property>2.2.4 任务优先级
容量调度器,支持任务优先级的配置,在资源紧张时,优先级高的任务将优先获取资源。默认情况,Yarn将所有任务的优先级限制为0,若想使用任务的优先级功能,须开放该限制。
- 修改yarn-site.xml文件,增加以下参数
<property>
<name>yarn.cluster.max-application-priority</name>
<value>5</value>
</property>
让后分发配置,重启yarn
公平调度器案例
公平调度器常用于中大厂,也默认有defaule队列
创建两个队列,分别是test和atguigu(以用户所属组命名)。期望实现以下效果:若用户提交任务时指定队列,则任务提交到指定队列运行;若未指定队列,test用户提交的任务到root.group.test队列运行,atguigu提交的任务到root.group.atguigu队列运行(注:group为用户所属组)。
公平调度器的配置涉及到两个文件,一个是yarn-site.xml,另一个是公平调度器队列分配文件fair-scheduler.xml(文件名可自定义)。
相关文章:
Hadoop之Yarn篇
目录 编辑 Yarn的工作机制: 全流程作业: Yarn的调度器与调度算法: FIFO调度器(先进先出): 容量调度器(Capacity Scheduler): 容量调度器资源分配算法࿱…...

Spring Cloud Nacos使用总结
目录 安装Nacos服务器 服务发现与消费 服务发现与消费-添加依赖 服务发现-配置文件 服务发现-注解 服务发现-Controller 服务消费-配置文件 服务消费-注解与Ribbon消费代码 服务消费-运行 配置管理 配置管理-添加依赖 配置管理-配置文件 配置管理-注解 配置管理-…...

目标检测框架yolov5环境搭建
目前,目标检测框架中,yolov5 是很火的,它基于pytorch框架,集成opencv等框架,项目地址:https://github.com/ultralytics/yolov5,对我来说,机器学习、深度学习才开始接触,本…...
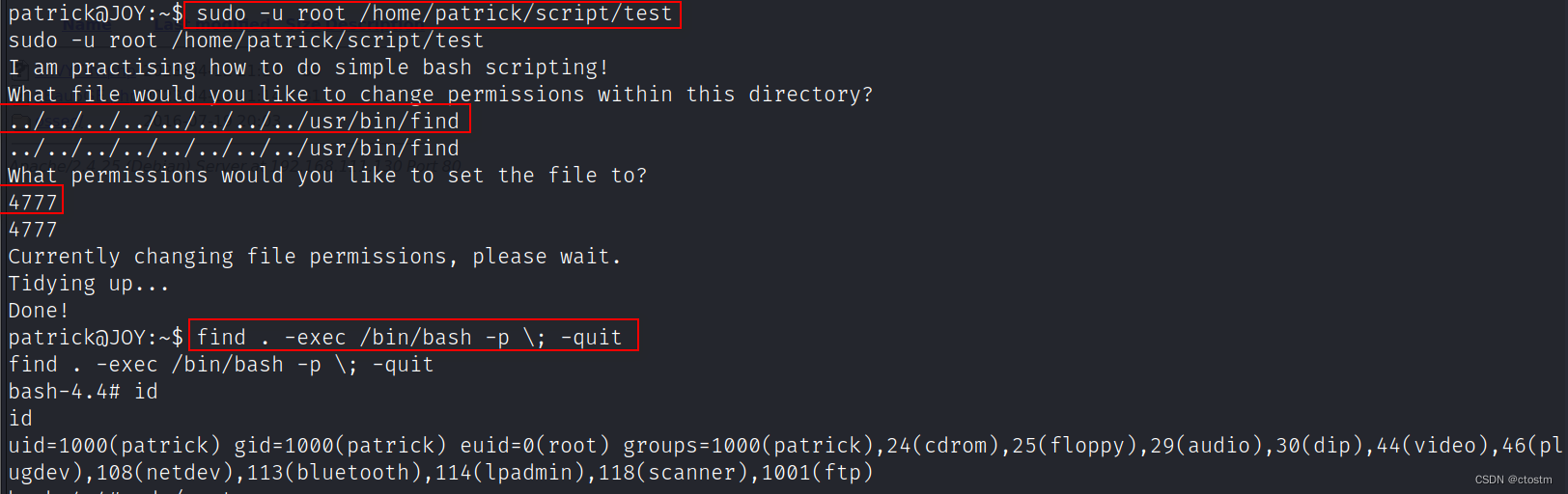
Vulnhub:Digitalworld.local (JOY)靶机
kali:192.168.111.111 靶机:192.168.111.130 信息收集 端口扫描 nmap -A -v -sV -T5 -p- --scripthttp-enum 192.168.111.130 使用enum4linux枚举目标smb服务,发现两个系统用户 enum4linux -a 192.168.111.130 ftp可以匿名登陆ÿ…...

STL源码剖析-六大部件, 部件的关系,复杂度, 区间表示
C标准库-体系结构与内核分析 根据源代码来分析 介绍 自学C侯捷老师的STL源码剖析的个人笔记,方便以后进行学习,查询。 为什么要学STL?按侯捷老师的话来说就是:使用一个东西,却不明白它的道理,不高明&…...

总有一个可用的连接,metaIPC1.2进入智能连接新时代
概述 metaIPC有1.0和2.0两个产品系列,2.0版本是可视对讲IPC,1.0新版本1.2在全面兼容ICE规范基础上进行了扩展,使metaIPC1.2进入智能化连接新时代。 metaIPC1.2在host/stun/turn/srs/zlm/janus/freeswitch等p2p/sfu/mcu进行全方位连通测试&a…...

棋盘问题c
在一个给定形状的棋盘(形状可能是不规则的)上面摆放棋子,棋子没有区别。要求摆放时任意的两个棋子不能放在棋盘中的同一行或者同一列,请编程求解对于给定形状和大小的棋盘,摆放k个棋子的所有可行的摆放方案C。 Input …...

华纳云:Linux系统下怎么创建普通用户并更改用户组
本篇内容主要讲解“Linux系统下怎么创建普通用户并更改用户组”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Linux系统下怎么创建普通用户并更改用户组”吧! 要求 项目做权限管理,不用root部…...

「她时代」背后的欧拉力量
2018年大热电视剧《北京女子图鉴》,讲述了一群在北京打拼的职业女性,她们背井离乡,被现实包裹,被压力、责任困扰,但依旧用倔强的个性、不屈的进取心和深厚的知识技能努力营造、交织出一片励志的天空,既激昂…...

kubespray v2.21.0 在线部署 kubernetes v1.24.0 集群【2】
文章目录创建 虚拟机模板虚拟机名称配置静态地址配置代理yum 配置配置主机名安装 git安装 docker安装 ansible配置内核参数安装 k8s定制安装新增节点配置主机名配置代理配置互信更新 inventory报错kubespray v2.21.0 部署 kubernetes v1.24.0 集群 【1】在 Rocky linux 8.7 使用…...

聚焦运营商信创运维,美信时代监控易四大亮点值得一试!
2021年11月《“十四五”信息通信行业发展规划》提出,到2025年,我国将建立高速泛在、集成互联、智能绿色、安全可靠的新型数字基础设施体系。 此《规划》让我国运营商信创进一步加速,中国移动、中国电信、中国联通等都先后加入信创大军&#x…...

[python刷题模板] 博弈入门-记忆化搜索/dp/打表
[python刷题模板] 博弈入门-记忆化搜索/dp/打表 一、 算法&数据结构1. 描述2. 复杂度分析3. 常见应用4. 常用优化二、 模板代码1. 打表贪心的博弈2. 464. 我能赢吗3. Nim游戏--最最基础版n1。三、其他四、更多例题五、参考链接一、 算法&数据结构 1. 描述 博弈一直没…...
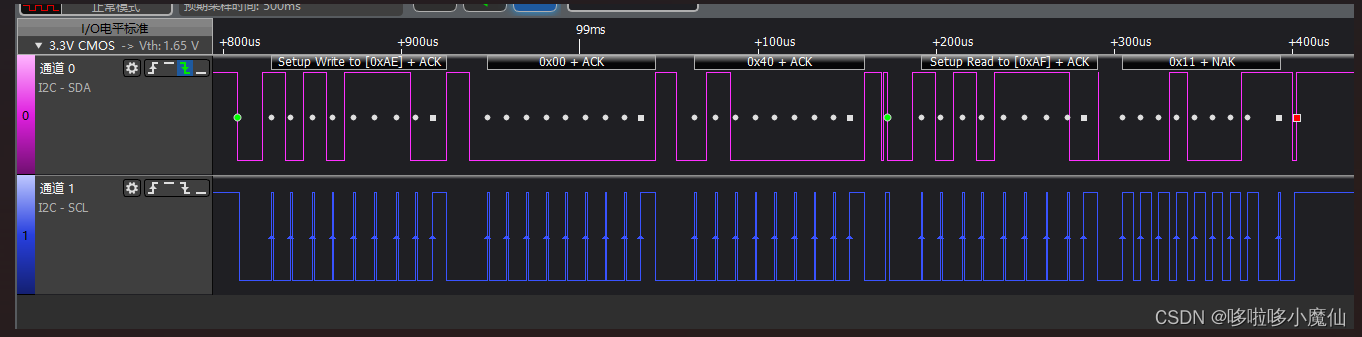
I2C通信
一、理论上了解I2C时序 I2C写数据时序如图: 通过解析器解析I2C通信如上图(SCL和SDA反了)。 1---起始信号 2、3---应答信号ACK 5---停止信号 起始信号:SCL线是高电平时,SDA线从高电平向低电平切换。 停…...
【Linux】man什么都搜不了,No manual entry for xxx的解决方案
本文首发于 慕雪的寒舍 man什么都搜不了,No manual entry for xxx的解决方案 系统 CentOS 7.6 1.问题描述 今天查手册的时候,发现man什么都查不了。不管是系统接口还是函数,都显示没有入口文档(No manual entry for)…...

STM32 库函数 GPIO_SetBits、GPIO_ResetBits、GPIO_WriteBit、GPIO_Write 区别
问题:当我使用STM32库函数对 I/O 口进行赋值时,在头文件中发现有四个相关的函数可以做这个操作,那么它们有什么区别呢? 一、GPIO_SetBits //eg: GPIO_SetBits(GPIOA, GPIO_Pin_1 | GPIO_Pin_2);解释:置位(置1)选择的数…...

在 RISC-V Linux 内核中添加模块
在 RISC-V Linux 内核中添加模块 flyfish 本例以添加helloworld字符设备为例 一 源码配置 1 源码 源码文件helloworld.c拷贝到 drivers/char 目录中 源码主要是输出Hello world init 2 Kconfig 打开drivers/char 目录下的Kconfig文件 在endmenu之前加上 config HELLO…...
利用AOP实现统一功能处理
目录 一、实现用户登录校验 实现自定义拦截器 将自定义的拦截器添加到框架的配置中,并且设置拦截的规则 二、实现统一异常处理 三、实现统一数据格式封装 一、实现用户登录校验 在之前的项目中,在需要验证用户登录的部分,每次都需要利…...

会话技巧---英文单词
目录 前言原文表示同意、答应表示不同意表示建议与忠告鼓励称赞担心与忧虑赞美夸奖-单词前言 加油 原文 表示同意、答应 1.agree[əˈgri]vi. 同意(=approve of); 答应(= consent to) agreement [əˈgrimənt] n. (意见或看法)一致 agree with sb about / on sth…...

VS中解决方案和项目的区别
总目录 文章目录总目录一、概述1、解决方案2、项目3、项目文件4、解决方案文件夹二、图解1、图解解决方案和项目的关系2、图解sln文件3、图解项目文件结语一、概述 1、解决方案 解决方案是一个容器,通常包含多个项目,这些项目通常相互引用。 解决方案中…...

MyBatis的parameterType传入参数类型和resultType返回结果类型
记录:413 场景:MyBatis的parameterType传入参数类型和resultType返回结果类型。 版本:JDK 1.8,Spring Boot 2.6.3,mybatis-3.5.9。 1.传入参数parameterType是Integer 传入参数类型parameterType:java.lang.Integer。 返回结…...
Pixelle-Video:如何让AI为您的声音创作注入灵魂?
Pixelle-Video:如何让AI为您的声音创作注入灵魂? 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 在AI视频创作的…...

5分钟学会在PowerPoint中插入LaTeX公式:科研工作者的高效神器
5分钟学会在PowerPoint中插入LaTeX公式:科研工作者的高效神器 【免费下载链接】latex-ppt Use LaTeX in PowerPoint 项目地址: https://gitcode.com/gh_mirrors/la/latex-ppt 还在为PowerPoint里输入复杂的数学公式而头疼吗?作为科研人员、教师或…...

面试必问:医学知识库 RAG 怎么设计?这次彻底讲透
医学知识库 RAG 怎么设计?一次讲清指南检索、文献召回、权限控制与可追溯回答 大家好,我是一名有 4 年工作经验的 Java 后端开发。 AI 医疗平台里,如果说最适合先落地的一类能力,我会优先推荐医学知识库问答。 因为它既能发挥大模…...

前端工程化实战:代码规范、兼容性、调试与项目整合
前言学完 HTML 和 CSS 的核心知识后,如何写出规范、可维护、兼容性好的代码,并高效地调试和构建项目,是很多初学者的薄弱环节。本篇整合 代码书写规范、浏览器兼容性处理、Chrome DevTools 调试技巧、项目目录结构 以及 前端学习路径 等实用技…...

不止于解题:聊聊猪圈密码、圣堂武士密码和标准银河字母背后的历史与趣闻
不止于解题:猪圈密码、圣堂武士密码与标准银河字母的文化考古 当你在CTF竞赛中第一次遇到那些神秘的几何符号时,是否曾好奇过这些图形背后的故事?从共济会的秘密集会到《我的世界》游戏中的彩蛋,图形密码早已超越了单纯的加密工具…...

数据库备份与恢复策略
数据库备份与恢复策略 1. 技术分析 1.1 备份概述 备份是数据安全的基石: 备份类型完全备份: 全部数据增量备份: 变化数据差异备份: 上次完全备份后的变化备份策略:定期完全备份增量备份补充实时备份1.2 恢复策略 恢复类型完全恢复: 恢复到最新状态时间点恢复: 恢复到…...
)
别再只会拖控件了!FastReport 实战:手把手教你用代码搞定复杂报表(含分组、过滤、合计)
代码驱动报表革命:FastReport高级开发实战指南 在电商后台系统中,销售报表往往需要处理动态分组、条件过滤和跨页合计等复杂需求。传统拖拽式设计工具虽然入门简单,但面对这类业务场景时常常捉襟见肘。本文将带你突破界面限制,通过…...

电源BOM砍掉30%!这颗SiC PSR芯片让12W-200W设计更简单
摘要:传统反激电源设计中,光耦反馈网络、TL431基准源、补偿电路占据了大量BOM成本与PCB面积。芯茂微LP3798系列采用原边PSR架构内置/外推SiC功率管方案,无需光耦即可实现恒压恒流控制,全系满足7级能效,待机功耗<75m…...

Keil MDK-ARM许可证错误-25的解决方案
1. 问题现象与背景解析最近在升级Keil MDK-ARM到新版本后,不少开发者遇到了一个棘手的许可证错误。当尝试编译项目时,系统会弹出如下错误提示:Error: A9555E: License checkout for feature mdk_xxx_compiler5 with version 5.0201411 has be…...

LabVIEW开发者峰会:破解信息孤岛,构建实战技术生态
1. 为什么我们需要一场专属的LabVIEW开发者峰会?如果你是一名长期使用LabVIEW进行测控系统开发的工程师,可能经历过这样的场景:面对一个复杂的同步采集需求,你翻遍了官方帮助文档和范例,却总觉得方案不够优雅ÿ…...