(Deep Learning)交叉验证(Cross Validation)
交叉验证(Cross Validation)
交叉验证(Cross Validation)是一种评估模型泛化性能的统计学方法,它比单次划分训练集和测试集的方法更加稳定、全面。
交叉验证不但可以解决数据集中数据量不够大的问题,也可以解决模型参数调优的问题。
交叉验证主要有以下三种方式:
1.简单交叉验证(Simple Cross Validation)
其中,简单交叉验证将原始数据集随机划分为训练集(Train Set)和测试集(Test Set)两部分。
例如:将原始数据样本按照7:3的比例划分为两部分,其中70%的样本用于训练模型,30%的样本用于测试模型及参数。

缺点:
(1)数据样本仅被使用一次,没有得到充分的利用。
(2)在测试集上得到的最终评估指标可能与数据集的划分有很大的关系。
2.K折交叉验证(K-fold Cross Validation)
为了解决简单交叉验证的不足,提出了K折交叉验证。
K折交叉验证的流程为:
(1)首先将全部样本划分成K个大小相等的样本子集
(2)依次遍历这K个子集,每次把当前子集作为验证集,其余所有样本作为训练集,进行模型的训练和评估
(3)最后把K次评估指标的平均值作为最终的评估指标,在实际实验中,K通常取10
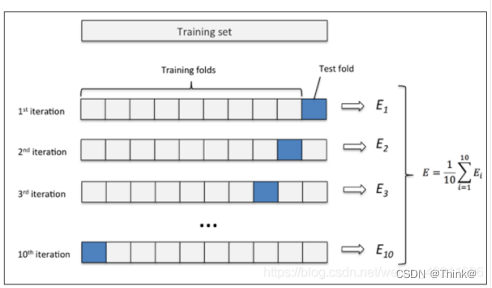
例如,当K取10时,K折交叉验证如下图所示:

(1)先将原始数据集分成10份,此时每一份中包含的数据样本数为D
(2)每次将其中的一份作为测试集,剩下的9份(即K-1份)作为训练集,此时训练集就变成了(K-1)*D
(3)最后计算K次求得的评价指标的平均值,作为该模型或者假设函数的真实性能
3.留一交叉验证(Leave-one-out Cross Validation)
留一交叉验证是K折交叉验证的特殊情况,当K等于样本数N时,对于这N个样本,每次选择N-1个样本来训练数据,留一个样本来验证模型预测的好坏。
留一交叉验证主要用于样本量非常少的情况,例如:对于普通适中问题,当N小于50时通常使用留一交叉验证。
交叉验证的方法在数据理解上较为简单,且具有说服性,但需要谨记的是,当样本总数过大时,使用留一法的时间开销极大。
以下内容转载自知乎:
一:交叉验证(Cross Validation)
在K折交叉验证之前最常用的验证方法是简单交叉验证,即把数据划分为训练集(Train Set)、验证集(Validation Set)和测试集(Test Set)。一般的划分比例为6:2:2。但如何合理的抽取样本就成为了使用交叉验证的难点,不同的抽取方式会导致截然不同的训练性能。同时由于验证集和测试集是不参与训练的,导致大量的数据无法应用于学习,所以显而易见的会导致训练的效果下降。
二:K折交叉验证
将训练集(Train Set)数据划分为K部分,利用其中的K-1份训练模型,剩余的1份作为测试,最后取平均测试误差做为泛化误差。这样做的好处是,训练集(Train Set)的所有样本在必然成为训练数据的同时也必然有机会成为1次测试集。因此,K折交叉验证可以更好的利用训练集(Train Set)数据。
在K折交叉验证中,K越大,被视为泛化误差的平均误差结果就越可靠,但K越大,进行K折交叉验证所花费的时间也是呈线性增长的。
三:存在的问题
以上所述均为书上的内容,但我发现这一步存在一个问题?即在进行K折之前是否需要划分训练集(Train Set)和测试集(Test Set)。
如果划分训练集(Train Set)和测试集(Test Set),(跑论文的实验)在利用公开数据集进行训练时,在相同网络相同数据集的情况下,你的结果可能比别人差(你只使用80%的数据进行训练,而不进行划分则可以使用所有的数据进行训练)。
如果划分测试集,在一些小规模的数据集中该怎么办?可能数据集本身就只有少量数据,此时分走20%用做测试,则用于训练的数据更加不够。
如果不划分测试集(Test Set),直接对所有数据进行K折,网络层数、学习率(Learning Rate)这些参数好定,但是学习轮次(Epoch)怎么决定,到什么程度停止学习。你不能选择测试集上效果最好的轮次,因为这会泄露一部分信息给模型。同时如果最后想要选出一个最佳的模型怎么办?
四:不同情况下给出的可行的——K折验证的方案
情况1:大数据规模
直接使用简单交叉验证(Simple Cross Validation),无需使用K折。因为数据规模较大时,即使以6:2:2的形式划分训练集(Train Set)-验证集(Validation Set)-测试集(Test Set)。其中60%的数据都足以代表所有数据的分布。
举个例子:现在我们需要通过统计的方法去计算投掷骰子时,每个点出现的概率。你现在做了100万次独立的实验,即使你只使用了其中的六十万次的结果也足以得到一个让人信服的概率,即每个点数出现的概率为六分之一。
情况2:中小规模的数据
1:公司使用的情况:首先划分训练集(Train Set)和测试集(Test Set)。在训练集上进行K折,K折中每1折在验证集中误差最小的模型(因为事先划分了训练集和测试集,书中所述的K折中的测试集我在这里称它为验证集(Validation Set))被放在测试集上进行测试,计算测试误差。最后模型的性能为每折中选中的模型在测试集上误差的平均。
(为什么说K折中每1折在验证集上误差最小的模型。因为在训练之前我们并不知道算法需要训练多少轮次才会达到最佳效果,所以我的想法是尽可能的让他多跑,然后在里面选在验证集上表现最佳的模型。再把选出来的模型丢到测试集上去测。)

对中小规模数据集、公司商用情况下流程的意识流示意图
ps:划分之后,会存在训练集数据不足的问题,但是在公司的项目中你必然要选出一个合适的模型进行部署,不先进行训练集和测试集的划分是选不出来合适的模型的!
2:论文实验的情况:如在论文实验中划分训练集(Train Set)和测试集(Test Set),则会存在说服力的问题。即:如何保证你选用的测试集不是经过你精心挑选的,十分容易判断的简单样例!所以,在不需要挑选出最佳模型而仅需评估方法效果的情况下,可以直接在所有的数据上进行K折。这样做的好处在于:你所使用的数据多了,模型的效果也更好,在测试集上的测试误差也会更加接近于泛化误差。
但是这样做会存在一个训练的迭代次数的问题,即:你将在何时停止你学习的过程。
在仅划分训练集(Train Set)和测试集(Test Set)的情况下,你只有两种可行的方法:
(1)选测试集上效果最好的,这就存在将测试集数据分布泄露给训练集的问题。
(2)定死迭代次数,这存在怎么选迭代次数的问题。
因此给出我的方法:在整个数据集上进行K折。在划分的训练集(Train Set)中,抽取一小部分比如5%做为验证集(Validation Set),然后将验证集(Validation Set)上效果最佳的模型置于测试集(Test Set)中测试,然后重复进行K次,泛化误差约等于K次测试误差的平均。
这种方法存在以下两个好处:
(1)所有的样本都在测试集中出现了一次,即不存在说服力不足的问题。
(我全都测了,总不可能说我故意选最容易评估的了吧!)
(2)训练数据集中的样本数据没有显著的减小。
(我只是在划分出来的训练集中再划分出一小部分做验证集),得出的模型效果会更加接近模型的真实泛化误差。
Reference:
- K折验证交叉验证_k折交叉验证_*Snowgrass*的博客-CSDN博客
- K-折交叉验证(记一个坑) - 知乎
- http://t.csdn.cn/8hgXy
相关文章:
(Deep Learning)交叉验证(Cross Validation)
交叉验证(Cross Validation) 交叉验证(Cross Validation)是一种评估模型泛化性能的统计学方法,它比单次划分训练集和测试集的方法更加稳定、全面。 交叉验证不但可以解决数据集中数据量不够大的问题,也可以…...
通俗举例讲解动态链接】静态链接
参考动态链接 - 知乎 加上我自己的理解,比较好懂,但可能在细节方面有偏差,但总体是一致的 静态链接的背景 静态链接使得不同的程序开发者和部门能够相对独立的开发和测试自己的程序模块,从某种意义上来讲大大促进了程序开发的效率…...

K8S部署常见问题归纳
目录一. 常用错误发现手段二、错误问题1. token 过期2. 时间同步问题3. docker Cgroup Driver 不是systemd4. Failed to create cgroup(未验证)子节点误执行kubeadm reset一. 常用错误发现手段 我们在部署经常看到的提示是: [kubelet-check] It seems …...
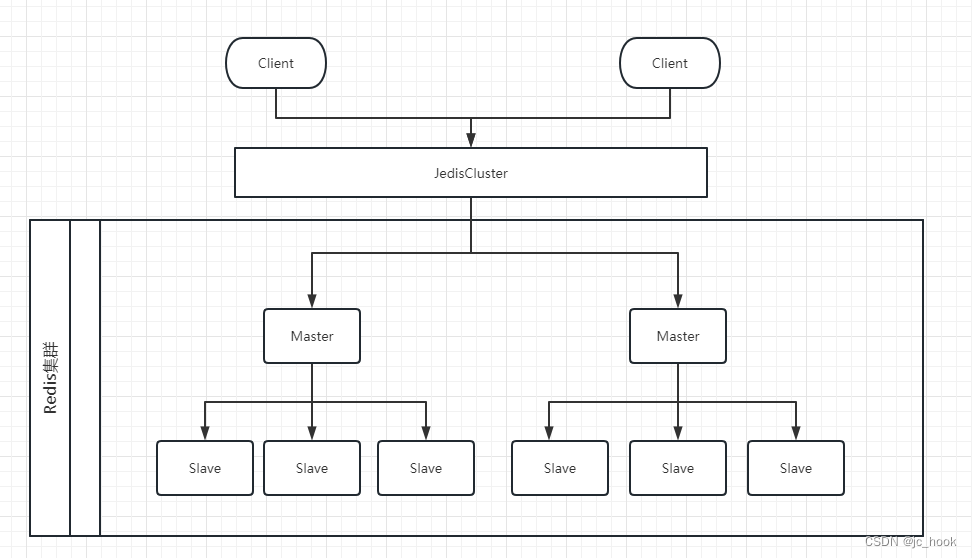
Redis高可用
最近离职后还没开始找工作,在找工作前去学习一下Redis高可用方案。 目录Redis高可用高可用的概念实现方式持久化主从复制简单结构优化结构优缺点哨兵模式(Sentinel)哨兵进程的作用自动故障迁移(Automatic failover)优缺点集群优缺点Redis高可…...
Hyperledger Fabric 2.2版本环境搭建
前言 部署环境: CentOS7.9 提前安装好以下工具 git客户端golangdockerdocker-composecurl工具 以下是个人使用的版本 git: 2.39.2golang: 1.18.6docker: 23.0.3dockkekr-compose: v2.17.2curl: 7.29.0 官方文档参考链接:跳转链接,不同的版本对应的官…...
macOS Monterey 12.6.5 (21G531) Boot ISO 原版可引导镜像
本站下载的 macOS 软件包,既可以拖拽到 Applications(应用程序)下直接安装,也可以制作启动 U 盘安装,或者在虚拟机中启动安装。另外也支持在 Windows 和 Linux 中创建可引导介质。 2023 年 4 月 10 日(北京…...
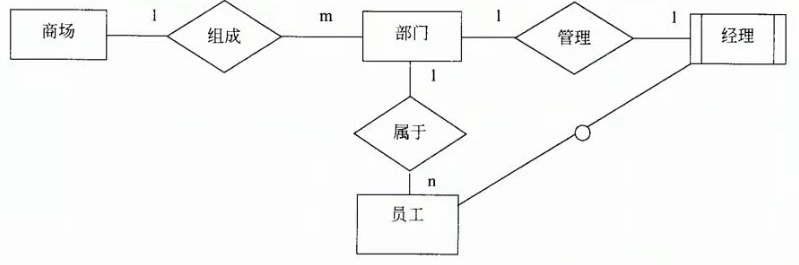
【软件设计师13】数据库设计
数据库设计 1. 数据库设计过程 2. E-R模型 3. E-R图向关系模型的转换 例如一对一联系,可以将联系单独做为关系模式,也可以存放到任意一个实体中 而一对多要合并只能合并到多这边,不能存放到1 多对多则联系必须单独转成一个关系模式 4. 案…...

SpringMVC的全注解开发
文章目录一、spring-mvc.xml 中组件转化为注解形式二、DispatcherServlet加载核心配置类三、消除web.xml一、spring-mvc.xml 中组件转化为注解形式 跟之前全注解开发思路一致, xml配置文件使用核心配置类替代,xml中的标签使用对应的注解替代 <!-- 组件…...

C# | 导出DataGridView中的数据到Excel、CSV、TXT
C# | 导出DataGridView中的数据到Excel、CSV、TXT 文章目录C# | 导出DataGridView中的数据到Excel、CSV、TXT前言DataGridView数据转存DataTableDataTable转Excel方法一、使用Microsoft.Office.Interop.Excel方法二、使用EPPlus库方法三、使用NPOI库DataTable转CSVDataTable转T…...
新规拉开中国生成式AI“百团大战”序幕?
AI将走向何方? ChatGPT在全球范围掀起的AI热潮正在引发越来越多的讨论,AI该如何管理?AI该如何发展?一系列问题都成为人们热议的焦点。此前,马斯克等海外名人就在网络上呼吁OpenAI暂停ChatGPT的模型训练和迭代…...

日撸 Java 三百行day31
文章目录day31 整数矩阵及其运算面向对象思想java异常处理java中的getter和setter方法代码day31 整数矩阵及其运算 面向对象思想 结合之前day7和day8面向过程开发,只关注了矩阵加法和矩阵乘法的功能。而day31是面向对象开发,一个矩阵类,在这…...
在线绘制思维导图
思维导图是一种可视化的思维工具,它可以将放射性思考具体化为可视的图像和图表。 思维导图利用图文并重的技巧,把各级主题的关系用相互隶属与相关的层级图表现出来,把主题关键词与图像、颜色等建立记忆链接。 它运用图像和颜色等多种元素&…...

月薪20k的性能测试必备技能:发现性能瓶颈掌握性能调优
背景 当下云计算、大数据盛行的背景下,大并发和大吞吐量的需求已经是摆在企业面前的问题了,其中网络的性能要求尤为关键,除了软件本身需要考虑到性能方面的要求,一些硬件上面的优化也是必不可少的。 作为一名测试工作者…...

3、Web前端学习规划:CSS - 学习规划系列文章
CSS作为Web前端开发的第2种重要的语言,笔者建议在学了HTML之后进行。CSS主要是对于HTML做一个渲染,其也带了一些语言语法函数,功能也非常强大。 1、 简介; CSS(层叠样式表)是一种用于描述网页样式的语言。它可以控制网页中的字体、…...
城市轨道交通列车时刻表优化问题【最优题解】
文章目录城市轨道交通列车时刻表优化问题思路文章底部城市轨道交通列车时刻表优化问题 最新进度在文章最下方卡片,加入获取思路数据代码论文:2023十三届MathorCup交流 (第一时间在CSDN分享,文章底部) 题目为数据分析类题目。列车时刻表优化…...

常年不卷,按时下班,工作能力强,同事求助知无不言,不扯皮,不拉帮结派,这样的职场清流竟然被裁掉了!...
在职场上,你永远想不到什么样的员工会被优化,比如下面这位:常年不卷,按时下班,工作很专业,同事问什么都回答,不扯皮,不拉帮结派,简直是职场清流。在上个月竟然被优化了&a…...
基于改进多目标灰狼优化算法的考虑V2G技术的风、光、荷、储微网多目标日前优化调度研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Python 函数、文件与模块
“探索 Python” 这一系列的前几篇文章已为 Python 编程新手介绍了几方面的主题,包括变量、容器对象和复合语句。本文以这些概念为基础,构造一个完整的 Python 程序。引入了 Python 函数和模块,并展示了构建一个 Python 程序、将其存储在文件…...

在Spring Boot微服务使用RedisTemplate操作Redis
记录:400 场景:在Spring Boot微服务使用RedisTemplate操作Redis缓存和队列。 使用ValueOperations操作Redis String字符串;使用ListOperations操作Redis List列表,使用HashOperations操作Redis Hash哈希散列,使用SetO…...
4月软件测试面试太难,吃透这份软件测试面试笔记后,成功跳槽涨薪30K
4 月开始,生活工作渐渐步入正轨,但金三银四却没有往年顺利。昨天跟一位高级架构师的前辈聊天时,聊到今年的面试。有两个感受,一个是今年面邀的次数比往年要低不少,再一个就是很多面试者准备明显不足。不少候选人能力其…...
)
手把手教你搞定Windows下的NAMD和VMD安装(附最新版下载与注册避坑指南)
Windows平台NAMD与VMD安装全攻略:从零开始玩转分子动力学模拟 当第一次接触分子动力学模拟时,软件安装往往是新手面临的第一个挑战。NAMD和VMD作为该领域最常用的工具组合,它们的安装过程看似简单,实则暗藏诸多细节。本文将带你从…...

CVAT教程
ubuntu服务器部署 https://blog.csdn.net/qq_48187848/article/details/146040443?spm1001.2101.3001.6661.1&utm_mediumdistribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogOpenSearchComplete%7ERate-1-146040443-blog-145734432.235%5Ev43%5Epc_blog_bottom…...

c++生产者消费者者模式笔记-1阻塞问题
生产者消费者模式是并发编程的核心模式之一,核心是想要提高程序的运行效率。 这里记录一下自己的思考,使用通俗易懂的语言,和以日志记录为例,解读生产者消费者模式,并实现生产者消费者模式。 将生产者消费者模式的核心…...

告别卡顿!用Sunshine打造私人游戏串流服务器的完整指南
告别卡顿!用Sunshine打造私人游戏串流服务器的完整指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想过在任何设备上流畅玩PC游戏?无论是躺…...

如何用3分钟完成淘宝淘金币全任务?终极自动化脚本完全指南
如何用3分钟完成淘宝淘金币全任务?终极自动化脚本完全指南 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi …...

死信队列与补偿作业
Skeyevss FAQ:死信队列与补偿作业 试用安装包下载 | SMS | 在线演示 项目地址:https://github.com/openskeye/go-vss 1. 什么是死信(DLQ) 消息在 最大重试次数 后仍失败,进入 死信队列 或 失败表,避免无…...

别再手动配环境了!用VMware一键导入bee-box镜像,5分钟搞定bWAPP靶场
5分钟极速部署bWAPP靶场:VMware镜像导入全指南 对于刚踏入Web安全领域的新手来说,最令人头疼的往往不是漏洞原理本身,而是那些看似简单却暗藏玄机的环境配置。PHP版本不兼容、MySQL服务启动失败、Apache模块缺失...这些"拦路虎"消…...

别再死记硬背了!用一张图+三个故事彻底搞懂PCIe TLP帧结构
用快递、交通与银行故事轻松掌握PCIe TLP帧结构 每次打开PCIe协议文档,看到那些密密麻麻的字段定义,是不是感觉头大如斗?Fmt、Type、TC、Attr...这些抽象术语就像一堵高墙,把许多工程师挡在了深入理解PCIe的大门之外。但今天&…...

从信号放大器到协议感知:深入解析Retimer与Redriver在高速链路中的角色演进
1. 高速链路中的信号完整性挑战 当你把手机靠近路由器时,网速会突然变快;用Type-C线连接移动硬盘传输大文件时,偶尔会出现卡顿——这些现象背后都隐藏着信号完整性这个关键问题。在AI服务器、数据中心互连、高端显卡这些需要高速数据传输的场…...

本地Perplexity服务突然中断?:排查systemd服务崩溃、GPU显存溢出与模型权重校验失败的5分钟应急清单
更多请点击: https://codechina.net 第一章:Perplexity本地服务查询 Perplexity 作为一款强调实时信息溯源与多源验证的 AI 助手,其官方未提供公开的本地化部署方案。但开发者可通过构建轻量级本地代理服务,模拟 Perplexity 的查…...