月薪20k的性能测试必备技能:发现性能瓶颈掌握性能调优
背景
当下云计算、大数据盛行的背景下,大并发和大吞吐量的需求已经是摆在企业面前的问题了,其中网络的性能要求尤为关键,除了软件本身需要考虑到性能方面的要求,一些硬件上面的优化也是必不可少的。
作为一名测试工作者,对于性能测试的问题肯定不会陌生,但是测试不仅仅是执行和收集数据,更多的应该是分析问题、找到性能瓶颈以及一些优化工作。
毕竟在客户现场测试性能的时候,能够通过一些系统层面的调优,提升软件的性能,那对项目无疑是一件锦上添花的事。

指标【文末分享性能测试学习资源】
不管你做何种性能测试,指标是绕不过去的事,指标是量化性能测试的重要依据。衡量某个性能的指标有很多,比如衡量数据库性能通常用TPS、QPS和延时,衡量io性能通常用iops、吞吐量和延时,衡量网络的性能指标也有很多,在业界有一个RFC2544的标准,参考链接:https://www.rfc-editor.org/rfc/rfc2544。
这里稍微解释一下几个指标:
-
背靠背测试:在一段时间内,以合法的最小帧间隔在传输介质上连续发送固定长度的包而不引起丢包时的数据量。
-
丢包率测试:在路由器稳定负载状态下,由于缺乏资源而不能被转发的帧占所有该被转发的帧的百分比。
-
时延测试:输入帧的最后一位到达输入端口到输出帧的第一位出现在输出端看的时间间隔。
-
吞吐量测试:没有丢包情况下能够转发的最大速率。
通常客户对于吞吐量和时延的指标是比较关心的,吞吐量反应了系统的并发的处理能力,时延反应了整体业务的响应时间。
测试准备
本文以网卡中的战斗机intel X710为测试对象,进行小包的吞吐量测试。
Tips:通常大包的测试可以达到线速,小包则很难线速,相同mtu下,包越小单位时间内cpu处理的包数越多,cpu的压力越大。
1、测试拓扑
在被测设备上插入X710网卡,使用网卡的2个网口建立linux bridge,通过测试仪发送接收数据包:
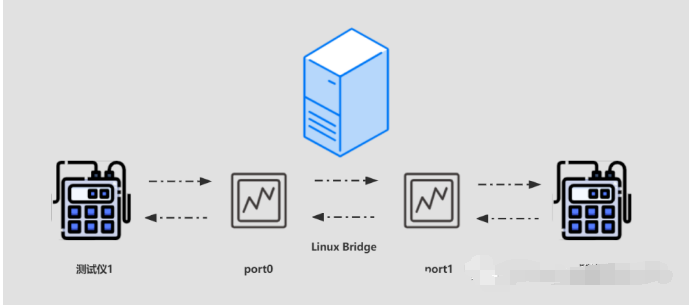
[root@localhost ~]# brctl addbr test[root@localhost ~]# brctl addif test enp11s0f2 enp11s0f3[root@localhost ~]# ip link set test up[root@localhost ~]# brctl showbridge name bridge id STP enabled interfacestest 8000.6cb311618c30 no enp11s0f2enp11s0f3virbr0 8000.5254004c4831 yes virbr0-nic
(左右滑动查看完整代码)
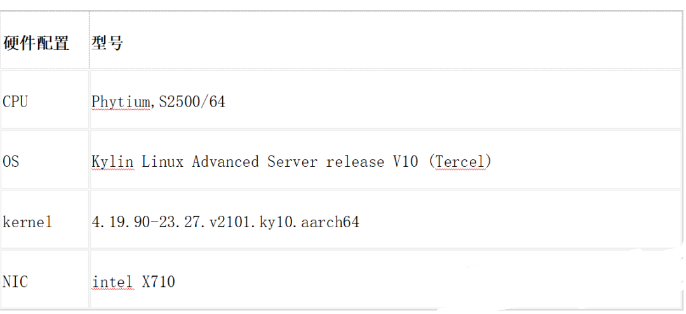
2、硬件信息
有个伟人曾说过,“如果性能测试不谈硬件,那么就和恋爱不谈结婚一个道理,都是耍流氓”。
鲁迅:"我没说过!"
题外话,这里先简单说一下数据包进入网卡后的流程:数据包进入到网卡后,将数据缓存到服务器内存后通知内核进行处理,接着协议栈进行处理,通常netfilter也是在协议栈去处理,最后应用程序从socker buff读取数据。

言归真正,本文测试采用的是国产之光飞腾S2500服务器。
测试调优
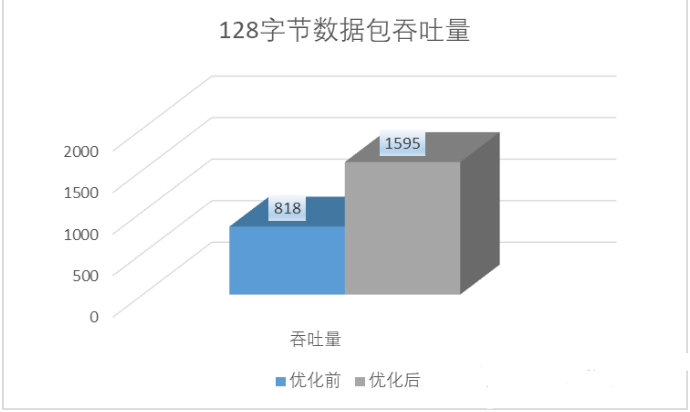
针对以上拓扑,发送128字节万兆双向流量,用RFC2544标准进行测试。

RFC2544的标准是0丢包测试吞吐量,结果是818Mbps。
以上都是前菜,接下来是本文的重头戏,根据已有资源做一些优化,提升“测试”性能,让客户满意。
1、调整队列数
调整网卡的队列数,利用网卡的多队列特性,不同的队列通过中断绑定到不同的cpu,提升cpu处理性能,提升网络带宽。
调整队列数,这里也不是越大越好,因为服务器的cpu个数是有上限的,队列多的话会出现多个中断绑定在同一个cpu上,这里我服务器单个numa有8个cpu,修改队列数为8:
[root@localhost ~]# ethtool -l enp11s0f2Channel parameters for enp11s0f2:Pre-set maximums:RX: 0TX: 0Other: 1Combined: 128Current hardware settings:RX: 0TX: 0Other: 1Combined: 8
(左右滑动查看完整代码)
因为数据包会根据hash来进入到多个收包队列,因此发送数据包的时候,可以选择源ip变化的流来确保使用了网卡的多队列,可以查看网卡的队列计数。
[root@localhost ~]# ethtool -S enp11s0f3NIC statistics:rx_packets: 4111490tx_packets: 4111490rx_bytes: 509824504tx_bytes: 509824504rx_errors: 0tx_errors: 0rx_dropped: 0tx_dropped: 0collisions: 0rx_length_errors: 0rx_crc_errors: 0rx_unicast: 4111486tx_unicast: 4111486...rx-2.rx_bytes: 63718020tx-3.tx_packets: 513838tx-3.tx_bytes: 63715912rx-3.rx_packets: 514847rx-3.rx_bytes: 63841028tx-4.tx_packets: 1027488tx-4.tx_bytes: 127408512rx-4.rx_packets: 513648rx-4.rx_bytes: 63692352tx-5.tx_packets: 52670tx-5.tx_bytes: 6530824rx-5.rx_packets: 514388rx-5.rx_bytes: 63784112tx-6.tx_packets: 1029202tx-6.tx_bytes: 127621048rx-6.rx_packets: 514742rx-6.rx_bytes: 63828008tx-7.tx_packets: 460901tx-7.tx_bytes: 57151724rx-7.rx_packets: 512859
(左右滑动查看完整代码)
修改完队列后再次使用RFC2544进行测试,性能比单队列提升了57%。

2、调整队列深度
除了调整网卡的队列数外,也可以修改网卡的队列深度,但是队列深度不是越大越好,具体还是需要看实际的应用场景。对于延时要求高的场景并不适合修改太大的队列深度。
查看当前队列深度为512,修改为1024再次测试:
[root@localhost ~]# ethtool -g enp11s0f2Ring parameters for enp11s0f2:Pre-set maximums:RX: 4096RX Mini: 0RX Jumbo: 0TX: 4096Current hardware settings:RX: 512RX Mini: 0RX Jumbo: 0TX: 512
(左右滑动查看完整代码)
修改tx和rx队列深度为1024:
[root@localhost ~]# ethtool -G enp11s0f3 tx 1024[root@localhost ~]# ethtool -G enp11s0f3 rx 1024[root@localhost ~]# ethtool -g enp11s0f2Ring parameters for enp11s0f2:Pre-set maximums:RX: 4096RX Mini: 0RX Jumbo: 0TX: 4096Current hardware settings:RX: 1024RX Mini: 0RX Jumbo: 0TX: 1024
(左右滑动查看完整代码)
再次进行RFC2544测试,这次也是有相应的提升。

3、中断绑定
网卡收包后,内核会触发软中断程序,如果此时运行中断的cpu和网卡不在一个numa上,则性能会降低。
查看网卡pci插槽对应numa node:
[root@localhost ~]# cat /sys/bus/pci/devices/0000\:0b\:00.3/numa_node0这里对应的numa node为0飞腾S2500有16个numa node,node8-15和node0所在的物理cpu不同,如果中断跑在上面性能会更加低[root@localhost ~]# numactl -Havailable: 16 nodes (0-15)node 0 cpus: 0 1 2 3 4 5 6 7node 0 size: 65009 MBnode 0 free: 46721 MBnode 1 cpus: 8 9 10 11 12 13 14 15node 1 size: 0 MBnode 1 free: 0 MBnode 2 cpus: 16 17 18 19 20 21 22 23node 2 size: 0 MBnode 2 free: 0 MBnode 3 cpus: 24 25 26 27 28 29 30 31node 3 size: 0 MBnode 3 free: 0 MBnode 4 cpus: 32 33 34 35 36 37 38 39node 4 size: 0 MBnode 4 free: 0 MBnode 5 cpus: 40 41 42 43 44 45 46 47node 5 size: 0 MBnode 5 free: 0 MBnode 6 cpus: 48 49 50 51 52 53 54 55node 6 size: 65466 MBnode 6 free: 64663 MBnode 7 cpus: 56 57 58 59 60 61 62 63node 7 size: 0 MBnode 7 free: 0 MBnode 8 cpus: 64 65 66 67 68 69 70 71node 8 size: 65402 MBnode 8 free: 63691 MBnode 9 cpus: 72 73 74 75 76 77 78 79node 9 size: 0 MBnode 9 free: 0 MBnode 10 cpus: 80 81 82 83 84 85 86 87node 10 size: 0 MBnode 10 free: 0 MBnode 11 cpus: 88 89 90 91 92 93 94 95node 11 size: 0 MBnode 11 free: 0 MBnode 12 cpus: 96 97 98 99 100 101 102 103node 12 size: 0 MBnode 12 free: 0 MBnode 13 cpus: 104 105 106 107 108 109 110 111node 13 size: 0 MBnode 13 free: 0 MBnode 14 cpus: 112 113 114 115 116 117 118 119node 14 size: 64358 MBnode 14 free: 63455 MBnode 15 cpus: 120 121 122 123 124 125 126 127node 15 size: 0 MBnode 15 free: 0 MBnode distances:node 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 150: 10 20 40 30 20 30 50 40 100 100 100 100 100 100 100 1001: 20 10 30 40 50 20 40 50 100 100 100 100 100 100 100 1002: 40 30 10 20 40 50 20 30 100 100 100 100 100 100 100 1003: 30 40 20 10 30 20 40 50 100 100 100 100 100 100 100 1004: 20 50 40 30 10 50 30 20 100 100 100 100 100 100 100 1005: 30 20 50 20 50 10 50 40 100 100 100 100 100 100 100 1006: 50 40 20 40 30 50 10 30 100 100 100 100 100 100 100 1007: 40 50 30 50 20 40 30 10 100 100 100 100 100 100 100 1008: 100 100 100 100 100 100 100 100 10 20 40 30 20 30 50 409: 100 100 100 100 100 100 100 100 20 10 30 40 50 20 40 5010: 100 100 100 100 100 100 100 100 40 30 10 20 40 50 20 3011: 100 100 100 100 100 100 100 100 30 40 20 10 30 20 40 5012: 100 100 100 100 100 100 100 100 20 50 40 30 10 50 30 2013: 100 100 100 100 100 100 100 100 30 20 50 20 50 10 50 4014: 100 100 100 100 100 100 100 100 50 40 20 40 30 50 10 3015: 100 100 100 100 100 100 100 100 40 50 30 50 20 40 30 10
(左右滑动查看完整代码)
查看网卡对应的中断绑定。
tips:系统会有一个中断平衡服务,系统会根据环境负载情况自行分配cpu到各个中断,所以这里为了强行把中断平均的绑定到各个cpu,需要先停止该服务:
[root@localhost ~]# cat /proc/interrupts | grep enp11s0f3 | cut -d: -f1 | while read i; do echo -ne irq":$i\t bind_cpu: "; cat /proc/irq/$i/smp_affinity_list; done | sort -n -t' ' -k3irq:654 bind_cpu: 0irq:653 bind_cpu: 1irq:656 bind_cpu: 2irq:657 bind_cpu: 2irq:659 bind_cpu: 3irq:655 bind_cpu: 4irq:652 bind_cpu: 5irq:658 bind_cpu: 6[root@localhost ~]# systemctl stop irqbalance.service手动修改网卡对应的cpu亲和性echo 0 > /proc/irq/654/smp_affinity_listecho 1 > /proc/irq/653/smp_affinity_listecho 2 > /proc/irq/656/smp_affinity_listecho 3 > /proc/irq/657/smp_affinity_listecho 4 > /proc/irq/659/smp_affinity_listecho 5 > /proc/irq/655/smp_affinity_listecho 6 > /proc/irq/652/smp_affinity_listecho 7 > /proc/irq/658/smp_affinity_list
(左右滑动查看完整代码)
调整后继续测试RFC2544,又有了一定的性能提升。

通过以上三种优化方式后,性能提升了95%,很显然,如果发生在客户现场,那绝对是值得高兴的一件事。
4、其他优化项
除了以上几种方式外,还有一些日常的调优手段,大家可以试一下针对不同的场景,选择不同的方式。
1、打开tso和gso
利用网卡硬件进行分片或者推迟协议栈分片,以此来降低cpu负载,提升整体性能。
2、调整TLP
调整pcie总线每次数据传输的最大值,根据实际情况调整,bios中可以修改。
3、调整聚合中断
合并中断,减少中断处理次数,根据实际情况调整。
4、应用程序cpu绑定
如果测试是使用类似netperf,qperf的工具,可以使用taskset命令绑定该测试进程到指定cpu。
总结
随着性能测试的发展以及对测试工程师的要求提高,优化性能已经不再是单纯开发同学所要做的事情,使用合适的测试方法和测试工具进行测试,收集数据找到性能瓶颈,并能进行一系列的调优,这才是性能测试团队做的真正有意义以及有价值的事情。
绵薄之力
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
这些资料,对于想进阶【自动化测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!凡事要趁早,特别是技术行业,一定要提升技术功底。希望对大家有所帮助……

相关文章:
月薪20k的性能测试必备技能:发现性能瓶颈掌握性能调优
背景 当下云计算、大数据盛行的背景下,大并发和大吞吐量的需求已经是摆在企业面前的问题了,其中网络的性能要求尤为关键,除了软件本身需要考虑到性能方面的要求,一些硬件上面的优化也是必不可少的。 作为一名测试工作者…...

3、Web前端学习规划:CSS - 学习规划系列文章
CSS作为Web前端开发的第2种重要的语言,笔者建议在学了HTML之后进行。CSS主要是对于HTML做一个渲染,其也带了一些语言语法函数,功能也非常强大。 1、 简介; CSS(层叠样式表)是一种用于描述网页样式的语言。它可以控制网页中的字体、…...
城市轨道交通列车时刻表优化问题【最优题解】
文章目录城市轨道交通列车时刻表优化问题思路文章底部城市轨道交通列车时刻表优化问题 最新进度在文章最下方卡片,加入获取思路数据代码论文:2023十三届MathorCup交流 (第一时间在CSDN分享,文章底部) 题目为数据分析类题目。列车时刻表优化…...

常年不卷,按时下班,工作能力强,同事求助知无不言,不扯皮,不拉帮结派,这样的职场清流竟然被裁掉了!...
在职场上,你永远想不到什么样的员工会被优化,比如下面这位:常年不卷,按时下班,工作很专业,同事问什么都回答,不扯皮,不拉帮结派,简直是职场清流。在上个月竟然被优化了&a…...
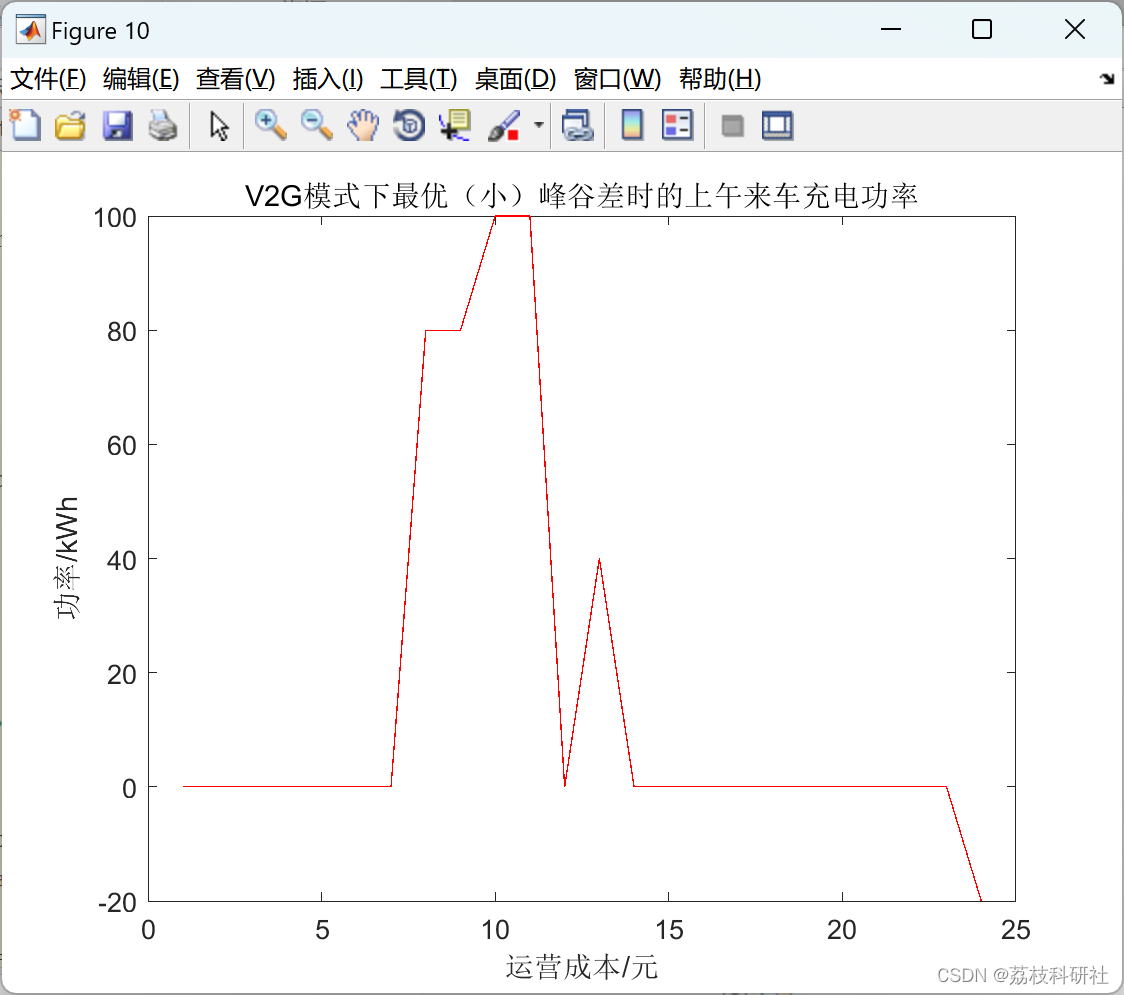
基于改进多目标灰狼优化算法的考虑V2G技术的风、光、荷、储微网多目标日前优化调度研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Python 函数、文件与模块
“探索 Python” 这一系列的前几篇文章已为 Python 编程新手介绍了几方面的主题,包括变量、容器对象和复合语句。本文以这些概念为基础,构造一个完整的 Python 程序。引入了 Python 函数和模块,并展示了构建一个 Python 程序、将其存储在文件…...

在Spring Boot微服务使用RedisTemplate操作Redis
记录:400 场景:在Spring Boot微服务使用RedisTemplate操作Redis缓存和队列。 使用ValueOperations操作Redis String字符串;使用ListOperations操作Redis List列表,使用HashOperations操作Redis Hash哈希散列,使用SetO…...
4月软件测试面试太难,吃透这份软件测试面试笔记后,成功跳槽涨薪30K
4 月开始,生活工作渐渐步入正轨,但金三银四却没有往年顺利。昨天跟一位高级架构师的前辈聊天时,聊到今年的面试。有两个感受,一个是今年面邀的次数比往年要低不少,再一个就是很多面试者准备明显不足。不少候选人能力其…...

人人拥有ChatGPT的时代来临了,这次微软很大方!
技术迭代的在一段时间内是均匀发展甚至止步不前的,但在某段时间内会指数级别的爆发。 ChatGPT背后的GPT 3.5训练据说花了几百万美金外加几个月的时间,参数大概有1700多亿。 这对于绝大多数的个人或企业来说绝对是太过昂贵的。 然而,微软&am…...
)
【C++11】自动类型推导(Type Inference)
C11 中的自动类型推导是通过 auto 关键字实现的。auto 关键字可以用于声明变量,让编译器自动推导变量的类型。具体来说,编译器会根据变量的初始化表达式来推导变量的类型。 例如,下面的代码中,变量 x 的类型会被推导为 int 类型&…...

拐点!智能座舱破局2023
“这是我们看到的整个座舱域控渗透率,2022年是8.28%,主力的搭载车型仍然是30-35万区间。”3月29日,2023年度(第五届)高工智能汽车市场峰会上,高工智能汽车研究院首发《2022-2025年中国智能汽车产业链市场数…...
SAP开发环境ABAP的搭建(客户端和服务器),Developer Key和AccessKey的绕过方法
目录 一.前言 二.客户端GUI安装 1.下载好SAP GUI 750 2.解压后找到SAPGUISetup.exe 3.安装 4.安装完整教程 三.服务端搭建 1.安装VmWare虚拟机 2.下载虚拟机镜像 3.打开虚拟机 4.调整内存大小 5.启动虚拟机 四.创建程序 1.创建包 2.创建程序 3.Developer Key和A…...
VSCode的C/C++编译调试环境搭建(亲测有效)
文章目录前言1.安装VSCode和mingw642.配置环境变量3.配置VSCode的运行环境3.1设置CodeRunner3.2设置C/C4.调试环境配置前言 这片博客挺早前就写好了,一直忘记发了,写这篇博客之前自己配的时候也试过很多博客,但无一例外,都各种js…...

物理世界的互动之旅:Matter.js入门指南
theme: smartblue 本文简介 戴尬猴,我是德育处主任 欢迎来到《物理世界的互动之旅:Matter.js入门指南》。 本文将带您探索 Matter.js,一个强大而易于使用的 JavaScript 物理引擎库。 我将介绍 Matter.js 的基本概念,包括引擎、世界…...
在线文章生成器-文章生成器在线生成
免费自动写作软件 目前市面上存在一些免费自动写作软件,以下介绍几个开源的自动写作软件。 GPT-2:这是由OpenAI推出的一款自动写作工具,它可以生成高质量的文章,其优点在于能够理解语言结构和语法规则,从而生成表达自…...

第十四届蓝桥杯大赛软件赛省赛-试题 B---01 串的熵 解题思路+完整代码
欢迎访问个人网站来查看此文章:http://www.ghost-him.com/posts/db23c395/ 问题描述 对于一个长度为 n 的 01 串 Sx1x2x3...xnS x_{1} x_{2} x_{3} ... x_{n}Sx1x2x3...xn,香农信息熵的定义为 H(S)−∑1np(xi)log2(p(xi))H(S ) − {\textstyl…...

【Leetcode】消失的数字 [C语言实现]
👻内容专栏:《Leetcode刷题专栏》 🐨本文概括: 面试17.04.消失的数字 🐼本文作者:花 碟 🐸发布时间:2023.4.10 目录 思想1:先排序再查找 思想2:异或运算 代…...

SpringBoot接口 - 如何实现接口限流之单实例
在以SpringBoot开发Restful接口时,当流量超过服务极限能力时,系统可能会出现卡死、崩溃的情况,所以就有了降级和限流。在接口层如何做限流呢? 本文主要回顾限流的知识点,并实践单实例限流的一种思路。 SpringBoot接口 …...

【花雕学AI】深度挖掘ChatGPT角色扮演的一个案例—CHARACTER play : 莎士比亚
CHARACTER play : 莎士比亚 : 52岁,男性,剧作家,诗人,喜欢文学,戏剧,爱情 : 1、问他为什么写《罗密欧与朱丽叶》 AI: 你好,我是莎士比亚,一位英国的剧作家和诗人。我很高兴你对我的…...

腾讯云物联网开发平台 LoRaWAN 透传接入 更新版
前言 之前有一篇文章介绍LoRaWAN透传数据,不过还是用物模型云端数据解析脚本,不是真正的透传。腾讯云物联网开发平台也支持对LoRaWAN原始数据的透传、转发。今天来介绍下。腾讯云 IoT Explorer 是腾讯云主推的一站式物联网开发平台,IoT 小能手…...

告别环境配置烦恼:Windows 10/11下RT-Thread Studio 2.2.7保姆级安装与首次运行指南
告别环境配置烦恼:Windows 10/11下RT-Thread Studio 2.2.7保姆级安装与首次运行指南 对于刚接触嵌入式开发的初学者来说,环境配置往往是第一个"拦路虎"。本文将手把手带你完成RT-Thread Studio在Windows系统下的完整安装流程,避开常…...
)
别再只用ROC了!用R语言ggplot2为你的Logistic回归模型画个校准曲线(附完整代码)
超越ROC:用R语言打造兼具诊断力与美学的Logistic回归校准曲线 当我们在医学统计或信用评分领域构建预测模型时,常常陷入一个认知陷阱——过度依赖ROC曲线和AUC值作为模型评估的唯一标准。这种单一视角可能掩盖了预测模型中更本质的问题:当模型…...

【实用程序】基于 Java 的简易HTTP 反向代理
本站内的程序及源代码下载地址。 第一章 概述 本项目是一个基于 Java 的简易 HTTP 反向代理实现。反向代理(Reverse Proxy)的核心职责是代表客户端向目标服务器发起请求,并将目标服务器的响应透明地返回给客户端。客户端感知不到后端真实服务的存在,所有交互都通过代理层…...

从DJI N3到PX4:高飞老师组px4ctrl状态机实战解析与避坑指南
从DJI N3到PX4:状态机设计与控制逻辑迁移实战指南 在无人机飞控系统开发领域,状态机设计一直是核心难点之一。当开发者需要从DJI N3平台迁移到PX4生态时,控制逻辑的差异往往成为最大的技术障碍。本文将深入解析两种平台的状态机实现差异&…...

Arm Neoverse N2与CMN-700系统中的PoC与缓存一致性解析
1. Neoverse N2与CMN-700系统中的PoC定位解析 在基于Arm Neoverse N2处理器和CMN-700互连架构的系统中,理解Point of Coherency(PoC)的位置对于正确执行缓存维护操作至关重要。PoC是系统中所有能够访问内存的代理(包括那些未连接到…...

RISC-V开发板测评实战:从申请到深度评测的完整指南
1. 项目概述:一次深度参与RISC-V生态的绝佳机会最近在电子发烧友论坛上看到了一个挺有意思的活动——“第二届RISC-V开发板测评大赛”,主办方是昊芯。对于咱们这些搞嵌入式、玩单片机、或者对开源硬件和RISC-V架构感兴趣的朋友来说,这绝对是一…...

LabVIEW开发者峰会:破解信息孤岛,构建实战技术生态
1. 为什么我们需要一场专属的LabVIEW开发者峰会?如果你是一名长期使用LabVIEW进行测控系统开发的工程师,可能经历过这样的场景:面对一个复杂的同步采集需求,你翻遍了官方帮助文档和范例,却总觉得方案不够优雅ÿ…...

Perplexity移动端体验崩塌实录:iOS/Android双平台1372条崩溃日志聚类分析,含Google Play App Store差评时间戳热力图
更多请点击: https://codechina.net 第一章:Perplexity用户评论汇总 Perplexity AI 作为一款以“引用驱动”为特色的问答式搜索引擎,自上线以来持续吸引学术研究者、开发者与技术爱好者群体。其用户评论呈现高度两极化特征:一方面…...

ContextMenuManager:3步实现Windows右键菜单精准管理的开源解决方案
ContextMenuManager:3步实现Windows右键菜单精准管理的开源解决方案 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager Windows右键菜单是操作系统中最频…...

Kubernetes集群能耗监测:RAPL与Prometheus方案对比
1. 项目概述在Kubernetes集群中实现精确的能耗监测一直是系统优化领域的难点问题。作为一名长期从事分布式系统性能调优的工程师,我最近完成了一项关于RAPL与Prometheus在Kubernetes集群能耗监测中的对比研究。这项研究源于我们在实际工作中遇到的一个具体问题&…...