超越时空:加速预训练语言模型的训练
超越时空:加速预训练语言模型的训练
随着自然语言处理(NLP)领域的快速发展,预训练语言模型(PTLM)已成为许多NLP任务的重要基石,如文本生成、情感分析、文本分类等。然而,传统的PTLM训练方法通常需要大量的计算资源和时间,限制了模型的训练速度和效果。那么,如何加速PTLM的训练过程,从而在时空上超越传统方法?本文将介绍一些基于原理的方法,结合实际案例和代码,来探讨如何在加速PTLM训练方面取得突破性的进展。
1. 传统PTLM训练方法的瓶颈
传统的PTLM训练方法,如BERT、GPT等,通常采用基于Transformer架构的自编码器(auto-encoder)结构,通过在大规模文本语料上进行无监督的预训练,从而学习到词汇的上下文表示。然后,通过在下游任务上进行有监督的微调,进一步优化模型性能。
然而,传统PTLM训练方法存在以下几个瓶颈,导致训练速度较慢:
大规模语料库:传统PTLM训练需要大规模的文本语料库作为训练数据,例如使用整个维基百科、Common Crawl等,这对于资源有限的研究者和企业来说是一项巨大的挑战。
长文本处理:传统PTLM训练方法在处理长文本时,会面临计算和存储资源的挑战,因为Transformer模型在每个时间步都需要计算全局的自注意力机制,导致模型难以处理长文本序列。
长时间训练:传统PTLM训练方法通常需要大量的训练时间,尤其是在使用大规模语料库和深层Transformer模型时,训练过程可能需要数周甚至数月的时间,从而限制了模型的迭代速度。
为了解决这些问题,研究者们提出了一系列基于原理的方法,从而在加速PTLM训练方面取得了显著的突破。
2. 原理展示:如何加速PTLM训练
2.1 小批量训练(Mini-batch Training)
传统PTLM训练方法通常使用大批量(batch)的训练数据进行训练,即一次性将多个样本放入模型进行计算。然而,这种方法在处理长文本序列时会导致计算和存储资源的负担较大。而小批量训练(mini-batch training)则可以将长文本序列切分成多个较短的子序列进行训练,从而减小计算和存储资源的开销。
小批量训练的实现方式可以通过修改Transformer模型的自注意力机制来实现。传统的自注意力机制在计算注意力权重时需要对所有的输入序列进行计算,导致计算复杂度较高。而在小批量训练中,可以通过将输入序列切分成多个子序列,并在每个子序列上独立计算注意力权重,从而减小计算复杂度。同时,为了保持子序列之间的上下文信息,可以通过引入特殊的边界标记来表示子序列之间的边界,从而保持序列的连续性。
以下是小批量训练的伪代码示例:
function mini_batch_training(model, input_sequence, batch_size):input_length = len(input_sequence)num_batches = input_length // batch_sizefor batch_idx in range(num_batches):# 从输入序列中抽取一个小批量的子序列start_idx = batch_idx * batch_sizeend_idx = (batch_idx + 1) * batch_sizeinput_batch = input_sequence[start_idx:end_idx]# 在小批量子序列上进行模型的前向计算和反向传播model.zero_grad()loss = model(input_batch)loss.backward()optimizer.step()
2.2 分布式训练(Distributed Training)
传统PTLM训练方法通常在单个GPU或者CPU上进行训练,限制了训练速度的提升。而分布式训练(distributed training)则通过将模型和训练数据分布到多个计算节点上进行并行计算,从而加速训练过程。
分布式训练的实现方式可以通过使用多台计算节点和通信库来实现。例如,可以使用分布式数据并行(Distributed Data Parallel)的方法,将模型复制到多个计算节点上,每个节点处理不同的小批量数据,并在计算节点之间进行梯度的同步和更新。这样可以充分利用多台计算节点的计算资源,加速训练过程。
以下是分布式训练的伪代码示例:
function distributed_training(model, input_sequence, batch_size, num_nodes):# 将模型复制到多个计算节点上model = model.to(device)model = torch.nn.parallel.DistributedDataParallel(model)# 使用分布式数据并行的方式进行训练for epoch in range(num_epochs):for batch_idx in range(num_batches):#从输入序列中抽取一个小批量的子序列start_idx = batch_idx * batch_sizeend_idx = (batch_idx + 1) * batch_sizeinput_batch = input_sequence[start_idx:end_idx]# 在小批量子序列上进行模型的前向计算和反向传播model.zero_grad()loss = model(input_batch)loss.backward()optimizer.step()# 进行梯度的同步和更新model.sync_gradients()model.update_parameters()
2.3 模型剪枝和量化(Model Pruning and Quantization)
模型剪枝(model pruning)是一种通过去除不重要的模型参数或神经元,从而减小模型的大小和计算复杂度的方法。模型量化(model quantization)则是一种将模型参数从高精度表示转换为低精度表示的方法,从而减小模型的存储空间和计算复杂度。
模型剪枝可以通过不同的方法来实现,例如:权重剪枝、通道剪枝、层剪枝等。在训练过程中,可以根据模型参数的重要性进行剪枝,将不重要的参数置零或者移除,从而减小模型的大小和计算复杂度。同时,剪枝后的模型可以通过精细调整和微调来保持模型的性能。
模型量化可以通过将模型参数从高精度浮点表示转换为低精度整数表示来实现,例如:8位整数表示、4位整数表示等。这样可以减小模型的存储空间和计算复杂度,从而加速模型的训练和推理过程。
以下是模型剪枝和量化的伪代码示例:
function model_pruning_and_quantization(model, input_sequence, batch_size):
# 训练模型并进行剪枝
for epoch in range(num_epochs):for batch_idx in range(num_batches):# 从输入序列中抽取一个小批量的子序列start_idx = batch_idx * batch_sizeend_idx = (batch_idx + 1) * batch_sizeinput_batch = input_sequence[start_idx:end_idx]# 在小批量子序列上进行模型的前向计算和反向传播model.zero_grad()loss = model(input_batch)loss.backward()optimizer.step()# 进行模型剪枝model.prune()# 进行模型量化model.quantize()
2.4 硬件加速(Hardware Acceleration)
硬件加速是通过使用专门的硬件设备来加速模型的训练和推理过程的方法。例如,使用图形处理单元(GPU)或者张量处理单元(TPU)等专门的硬件加速设备可以显著加速模型的计算速度。这些硬件设备可以并行处理大量计算任务,从而在训练过程中加速模型的参数更新和优化过程。
除了使用专门的硬件设备外,还可以通过硬件优化和加速技术来提高模型的训练速度。例如,使用高速存储器(例如GPU的显存)来存储中间计算结果,减小数据传输的开销;使用硬件加速库(例如cuDNN、TensorRT等)来优化卷积、循环等常用的神经网络操作,加速模型的计算过程;使用硬件加速接口(例如CUDA、OpenCL等)来实现自定义的加速操作,提高模型的计算效率等。
以下是硬件加速的伪代码示例:
function hardware_acceleration(model, input_sequence, batch_size):# 设置硬件加速设备(例如GPU或TPU)device = get_acceleration_device()model.to(device)# 使用硬件加速库进行优化model.optimize_with_acceleration_lib()# 训练模型并进行硬件加速for epoch in range(num_epochs):for batch_idx in range(num_batches):# 将输入数据移动到硬件加速设备input_batch = input_sequence.to(device)# 在硬件加速设备上进行模型的前向计算和反向传播model.zero_grad()loss = model(input_batch)loss.backward()optimizer.step()# 进行硬件加速操作(例如使用硬件加速接口实现的自定义操作)model.custom_acceleration_operation()
2.5 分布式训练(Distributed Training)
分布式训练是一种将模型的训练任务分配给多台计算设备进行并行处理的方法,从而加速模型的训练过程。分布式训练可以通过在多个计算设备上进行并行计算、通信和同步操作,从而加速模型的参数更新和优化过程,提高训练速度。
分布式训练可以采用不同的策略,例如:数据并行、模型并行、副本并行等。在数据并行策略中,将输入数据分成多个小批量,并在不同的计算设备上进行并行处理;在模型并行策略中,将模型的不同部分分配到不同的计算设备上进行并行计算;在副本并行策略中,将模型的多个副本分布在不同的计算设备上,每个副本处理不同的输入数据。
以下是分布式训练的伪代码示例:
function distributed_training(model, input_sequence, batch_size):# 设置分布式训练环境(例如使用MPI、NCCL等通信库)setup_distributed_training_env()# 将输入数据分为多个小批量input_batches = split_input_into_batches(input_sequence, batch_size)# 在每个计算设备上创建模型的副本model_replicas = create_model_replicas(model, num_devices)# 同步模型参数sync_model_parameters(model_replicas)# 进行分布式训练for epoch in range(num_epochs):for batch_idx in range(num_batches):# 在每个计算设备上进行并行计算for device_idx in range(num_devices):input_batch = input_batches[device_idx]model_replica = model_replicas[device_idx]# 在当前设备上进行模型的前向计算和反向传播model_replica.zero_grad()loss = model_replica(input_batch)loss.backward()optimizer.step()# 同步模型参数sync_model_parameters(model_replicas)# 返回合并后的模型参数return merge_model_parameters(model_replicas)
2.6 轻量化模型(Model Compression)
轻量化模型是一种通过减小模型的参数量和计算量来提高模型训练速度的方法。轻量化模型可以通过多种方式实现,例如权重剪枝、量化、低秩近似等。
权重剪枝是一种通过将模型中的小权重或不重要的权重剪掉,从而减小模型的参数量和计算量的方法。剪枝可以在训练过程中进行,也可以在训练后进行。例如,可以根据权重的绝对值大小进行剪枝,将小于某个阈值的权重置为零,并且在后续的训练过程中保持零值不变。这样可以减小模型的参数量,从而加速模型的训练速度。
量化是一种通过将模型中的浮点数权重和激活值转换为较低位数的定点数或者离散的符号数来减小模型的计算量的方法。例如,可以将模型中的浮点数权重和激活值量化为8位定点数或者二值(1位)符号数,从而减小模型的存储和计算开销,加速模型的训练速度。
低秩近似是一种通过将模型中的高秩矩阵近似为低秩矩阵,从而减小模型的参数量和计算量的方法。例如,可以通过奇异值分解(SVD)将模型中的卷积核或者全连接层权重矩阵近似为低秩矩阵,从而减小模型的参数量,加速模型的训练速度。
以下是轻量化模型的伪代码示例:
function model_compression(model, input_sequence, batch_size):# 将输入数据分为小批量input_batches = split_input_into_batches(input_sequence, batch_size)# 进行模型训练前的剪枝、量化或低秩近似操作pruned_model = weight_pruning(model) # 权重剪枝quantized_model = weight_quantization(model) # 权重量化low_rank_model = low_rank_approximation(model) # 低秩近似# 在剪枝、量化或低秩近似后的模型上进行训练for epoch in range(num_epochs):for batch_idx in range(num_batches):input_batch = input_batches[batch_idx]# 在剪枝、量化或低秩近似后的模型上进行前向计算和反向传播pruned_model.zero_grad()quantized_model.zero_grad()low_rank_model.zero_grad()# 根据不同的轻量化方法进行前向计算和反向传播pruned_loss = pruned_model(input_batch)pruned_loss.backward()pruned_optimizer.step()quantized_loss = quantized_model(input_batch)quantized_loss.backward()quantized_optimizer.step()low_rank_loss = low_rank_model(input_batch)low_rank_loss.backward()low_rank_optimizer.step()# 返回轻量化后的模型return pruned_model, quantized_model, low_rank_model
2.7 使用高效的优化器(Efficient Optimizers)
优化器是深度学习模型训练中的关键组件,它负责在训练过程中更新模型的参数以最小化损失函数。选择高效的优化器可以显著加速预训练语言模型的训练速度。
目前,许多高效的优化器已经被提出,例如Adam、SGD、RMSprop等。这些优化器在不同场景下表现出不同的性能,因此需要根据具体情况选择合适的优化器。
此外,还可以考虑使用基于一阶梯度和二阶梯度的优化器,例如Newton法和L-BFGS等。这些优化器在某些情况下可能比传统的梯度下降法更加高效,从而加速模型的训练速度。
以下是使用高效优化器的伪代码示例:
function train_with_efficient_optimizer(model, input_sequence, batch_size, optimizer_type):# 将输入数据分为小批量input_batches = split_input_into_batches(input_sequence, batch_size)# 根据优化器类型选择对应的优化器if optimizer_type == 'adam':optimizer = Adam(model.parameters(), lr=learning_rate)elif optimizer_type == 'sgd':optimizer = SGD(model.parameters(), lr=learning_rate)elif optimizer_type == 'rmsprop':optimizer = RMSprop(model.parameters(), lr=learning_rate)elif optimizer_type == 'newton':optimizer = NewtonMethod(model.parameters(), lr=learning_rate)elif optimizer_type == 'l-bfgs':optimizer = L_BFGS(model.parameters(), lr=learning_rate)else:raise ValueError("Invalid optimizer type")# 将模型设置为训练模式model.train()# 进行模型训练for epoch in range(num_epochs):for batch_idx in range(num_batches):input_batch = input_batches[batch_idx]# 清零梯度optimizer.zero_grad()# 前向计算和反向传播loss = model(input_batch)loss.backward()# 更新参数optimizer.step()# 返回训练后的模型return model
2.8 使用硬件加速(Hardware Acceleration)
使用硬件加速技术可以显著提高预训练语言模型的训练速度。目前,许多硬件加速技术已经被广泛应用于深度学习模型的训练,包括GPU、TPU、FPGA等。
GPU(图形处理器)是一种高性能的并行计算设备,可以在训练过程中同时处理多个数据样本,从而加速模型的训练速度。在使用GPU加速时,需要确保模型和数据能够充分利用GPU的并行计算能力,例如使用GPU版本的深度学习框架(如TensorFlow、PyTorch)以及优化模型的计算图。
TPU(张量处理器)是一种由Google开发的专用硬件加速器,针对深度学习计算进行了优化。TPU在训练速度和能效方面具有显著优势,尤其在大规模模型和大规模数据集上的训练中,可以显著加速训练速度。
FPGA(现场可编程门阵列)是一种灵活可编程的硬件加速器,可以根据模型的需求进行定制化的硬件加速。FPGA在低功耗和高性能方面具有优势,可以在特定场景下提供显著的训练加速。
以下是使用硬件加速技术的伪代码示例:
function train_with_hardware_acceleration(model, input_sequence, batch_size, hardware_type):# 将输入数据分为小批量input_batches = split_input_into_batches(input_sequence, batch_size)# 将模型移动到对应的硬件设备上if hardware_type == 'gpu':model = model.to('cuda')elif hardware_type == 'tpu':model = model.to('tpu')elif hardware_type == 'fpga':model = model.to('fpga')else:raise ValueError("Invalid hardware type")# 将模型设置为训练模式model.train()# 进行模型训练for epoch in range(num_epochs):for batch_idx in range(num_batches):input_batch = input_batches[batch_idx]# 将输入数据移动到对应的硬件设备上if hardware_type == 'gpu':input_batch = input_batch.to('cuda')elif hardware_type == 'tpu':input_batch = input_batch.to('tpu')elif hardware_type == 'fpga':input_batch = input_batch.to('fpga')# 清零梯度model.zero_grad()# 前向计算和反向传播loss = model(input_batch)loss.backward()# 更新参数model.optimizer.step()# 将模型移回CPUif hardware_type == 'gpu':model = model.to('cpu')elif hardware_type == 'tpu':model = model.to('cpu')elif hardware_type == 'fpga':model = model.to('cpu')# 返回训练后的模型return model
2.9 使用分布式训练(Distributed Training)
分布式训练是一种将计算任务分配到多个计算节点上并行进行训练的方法,可以显著加速模型的训练速度。在分布式训练中,每个计算节点可以有自己的计算资源(如GPU、TPU)和内存,从而可以同时处理多个数据样本,并在节点间共享模型参数。
分布式训练需要特定的硬件和软件设置,包括网络通信、参数同步和梯度累积等。在使用分布式训练时,需要注意同步和通信开销,以及数据的划分和负载均衡,以确保训练的效果和速度。
以下是使用分布式训练的伪代码示例:
function distributed_training(model, input_sequence, batch_size, num_nodes):# 将输入数据分为小批量input_batches = split_input_into_batches(input_sequence, batch_size)# 设置分布式训练环境setup_distributed_training(num_nodes)# 将模型移动到各个计算节点上model = model.to('distributed')# 将模型设置为训练模式model.train()# 进行模型训练for epoch in range(num_epochs):for batch_idx in range(num_batches):input_batch = input_batches[batch_idx]# 将输入数据移动到对应的计算节点上input_batch = input_batch.to('distributed')# 清零梯度model.zero_grad()# 前向计算和反向传播loss = model(input_batch)loss.backward()# 更新参数model.optimizer.step()# 返回训练后的模型return model
相关文章:

超越时空:加速预训练语言模型的训练
超越时空:加速预训练语言模型的训练 随着自然语言处理(NLP)领域的快速发展,预训练语言模型(PTLM)已成为许多NLP任务的重要基石,如文本生成、情感分析、文本分类等。然而,传统的PTLM…...
数据库管理系统PostgreSQL部署安装完整教程
PostgreSQL是一个开源的关系型数据库管理系统,它支持大量的数据类型和复杂的查询语言,可以用于各种应用程序。它是一个高性能的数据库,可以处理大量的数据,并且具有良好的可扩展性和可靠性。 目录 一.Linux系统安装PostgresSQL&a…...
有学生问我,重构是什么?我应该如何回答?
重构到底是什么?只是代码的推倒重新编码?还是有规则、有方法可寻?当然,结论肯定是有的,本文,我们通过一个简单的实例,来理解一下重构。 1.借助一个实例需求 这是一个影片出租店用的程序&#…...

交际场合---英文单词
目录 前言原文邀请生日和聚会离别探病婚礼新居落成葬礼聚会相关单词婚礼相关单词乔迁相关单词丧礼相关单词前言 加油 原文 邀请 1.invite[ɪnˈvaɪt]vt. 邀请 invitation [ˌɪnvəˈteʃən] n. 邀请;邀请函 invite sb to v. 邀请某人从事…… accept / decline /…...
【网络安全】文件上传漏洞及中国蚁剑安装
文件上传漏洞描述中国蚁剑安装1. 官网下载源码和加载器2.解压至同一目录并3.安装4.可能会出现的错误文件上传过程必要条件代码示例dvwa靶场攻击示例1.书写一句话密码进行上传2. 拼接上传地址3.使用中国蚁剑链接webshell前端js绕过方式服务端校验请求头中content-type黑名单绕过…...
[Java]面向对象高级篇
文章目录包装类包装类层次结构基本类型包装类特殊包装类数组一维数组多维数组可变长参数字符串String类StringBuilder类内部类成员内部类静态内部类局部内部类匿名内部类Lambda表达式方法引用异常机制自定义异常抛出异常异常的处理常用工具类数学工具类随机数数组工具类包装类 …...

苹果应用商店上架流程
上架过程分七个步骤,按步骤一步步来。 仔细看这个流程,少走很多弯路,不用一步步去试错,新手也能快速掌握上架流程。 1、创建APP身份证(App IDs) 2、申请iOS发布证书 3、申请iOS发布描述文件 4、上传ios证…...
基于Eclipse下使用arm gcc开发GD32调用printf
系列目录 第一章 xxx 目录 系列目录 文章目录 文章目录 系列文章目录前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据总结前言 开发环境:Eclipse代替Keil,IAR 开发平台:GD32 开发编译器:arm-none-eabi- …...

5个降低云成本并提高IT运营效率的优先事项
在过去的十年里,公司在公有云和私有云基础设施上构建了大量的计算工作负载,或者将工作负载转移到云端。Gartner 预测,到2023年,全球终端用户在公共云服务上的支出将达到5910亿美元,比2021年增长43%。这是一个显著的增长…...
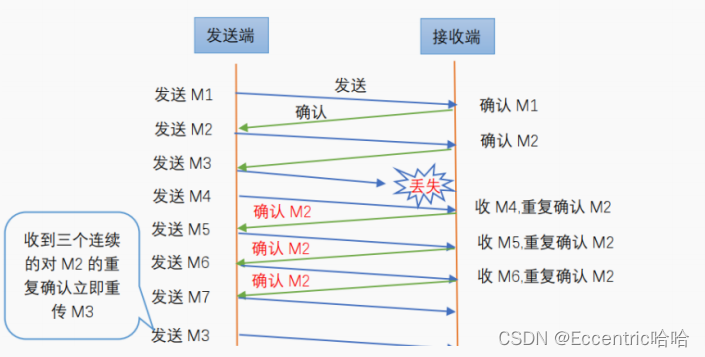
95-拥塞控制
拥塞控制1.什么是拥塞控制2.拥塞控制的方法(1)慢启动和拥塞避免(2)快速重传和快速恢复1.什么是拥塞控制 在计算机网络中的链路容量(即带宽)、交换结点中的缓存和处理机等,都是网络的资源。在某段时间,若对网络中某一资源的需求超…...

Linux常见操作命令【二】
一、Vi 编辑器 Vi 编辑器存在三者模式:命令、末行、编辑 1.1 命令模式 输入 vi 默认进入命令模式 输入n或者nG:定位到某一行行首 输入G:跳到文件最后一行行首 输入hjkl:表示左下上右移动光标(方向键也可以…...

Linux驱动中断和定时器
目录 中断 顶半部/底半部机制 软中断: Tasklet: 工作队列: 定时器 中断 中断是正在执行的程序被另一个程序打断,去执行另一个程序的处理函数,当执行完再返回执行被打断的程序。分为内中断(异常)和外中断(硬件中断)。 当cp…...

表达式和函数
表达式: 将数字和运算符连接起来的组合称为表达式。我们可以将数字称为操作数,单个操作数也可以被看作是一个表达式。 操作数:常数,列名,函数调用,其他表达式 运算符:算数运算符,…...

C#基础复习
目录 格式字符串 多重标记和值 预定义类型 用户定义类型 值类型和引用类型 存储引用类型对象的成员 C#类型的分类 静态类型和dynamic关键字 类的基本概念 类成员的类型 为数据分配内存 访问修饰符 格式字符串 多重标记和值 C#程序就是一组类型声明,学习C#就是学习…...

Windows服务器使用代码SSH免密登录并执行脚本
服务器操作系统 Window Server 2016 1、Windows服务器安装OpenSSH 有多种方式,本文介绍一种方式 下载页: https://github.com/PowerShell/Win32-OpenSSH/releases 在下载页下载文件OpenSSH-Win64.zip 本次实验解压至 D:\OpenSSH-Win64\OpenSSH-Win6…...

(Deep Learning)交叉验证(Cross Validation)
交叉验证(Cross Validation) 交叉验证(Cross Validation)是一种评估模型泛化性能的统计学方法,它比单次划分训练集和测试集的方法更加稳定、全面。 交叉验证不但可以解决数据集中数据量不够大的问题,也可以…...
通俗举例讲解动态链接】静态链接
参考动态链接 - 知乎 加上我自己的理解,比较好懂,但可能在细节方面有偏差,但总体是一致的 静态链接的背景 静态链接使得不同的程序开发者和部门能够相对独立的开发和测试自己的程序模块,从某种意义上来讲大大促进了程序开发的效率…...

K8S部署常见问题归纳
目录一. 常用错误发现手段二、错误问题1. token 过期2. 时间同步问题3. docker Cgroup Driver 不是systemd4. Failed to create cgroup(未验证)子节点误执行kubeadm reset一. 常用错误发现手段 我们在部署经常看到的提示是: [kubelet-check] It seems …...
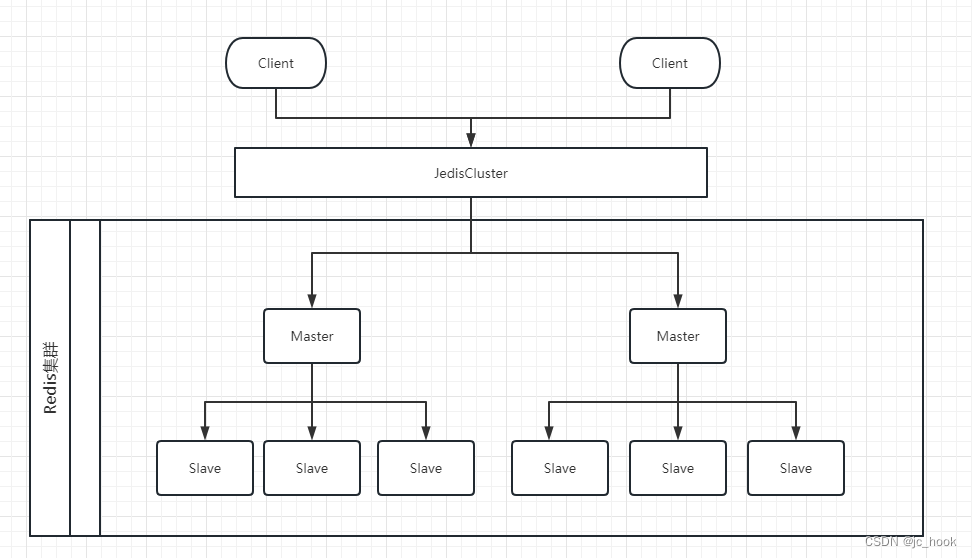
Redis高可用
最近离职后还没开始找工作,在找工作前去学习一下Redis高可用方案。 目录Redis高可用高可用的概念实现方式持久化主从复制简单结构优化结构优缺点哨兵模式(Sentinel)哨兵进程的作用自动故障迁移(Automatic failover)优缺点集群优缺点Redis高可…...
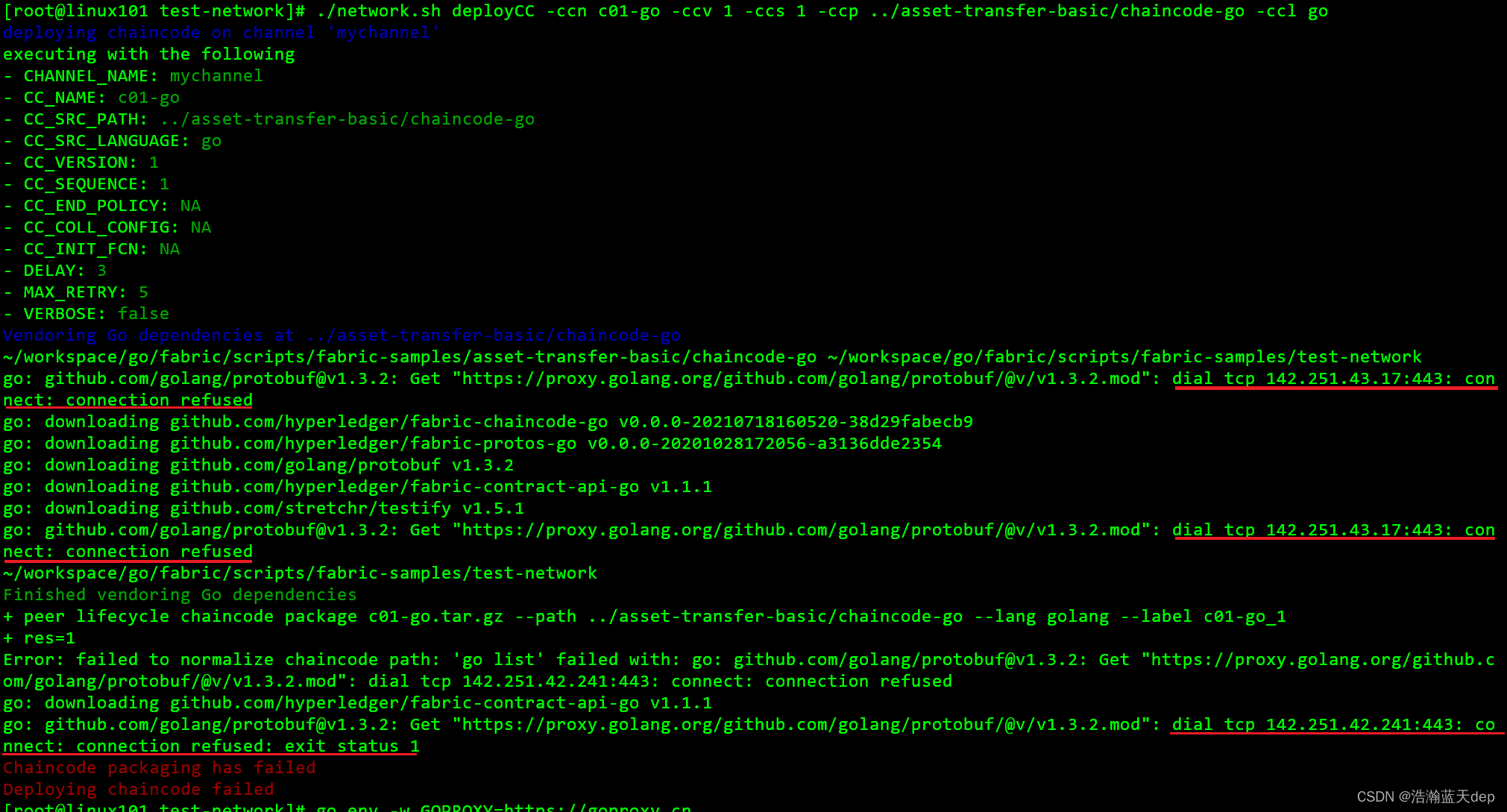
Hyperledger Fabric 2.2版本环境搭建
前言 部署环境: CentOS7.9 提前安装好以下工具 git客户端golangdockerdocker-composecurl工具 以下是个人使用的版本 git: 2.39.2golang: 1.18.6docker: 23.0.3dockkekr-compose: v2.17.2curl: 7.29.0 官方文档参考链接:跳转链接,不同的版本对应的官…...
)
Cadence SKILL脚本实战:5分钟搞定TESTKEY原理图批量创建(附完整代码)
Cadence SKILL脚本实战:5分钟搞定TESTKEY原理图批量创建(附完整代码) 在集成电路设计领域,TESTKEY(测试结构)的创建是验证工艺模型和器件特性的基础工作。传统手动放置器件的方式不仅效率低下,还…...

Desktop Postflop:免费开源的德州扑克GTO求解器完整指南
Desktop Postflop:免费开源的德州扑克GTO求解器完整指南 【免费下载链接】desktop-postflop [Development suspended] Advanced open-source Texas Holdem GTO solver with optimized performance 项目地址: https://gitcode.com/gh_mirrors/de/desktop-postflop …...

【实用程序】基于 Java 的简易HTTP 反向代理
本站内的程序及源代码下载地址。 第一章 概述 本项目是一个基于 Java 的简易 HTTP 反向代理实现。反向代理(Reverse Proxy)的核心职责是代表客户端向目标服务器发起请求,并将目标服务器的响应透明地返回给客户端。客户端感知不到后端真实服务的存在,所有交互都通过代理层…...

DELL R730XD加装二手阵列卡后风扇狂转?手把手教你用ipmitool命令降噪
DELL R730XD二手阵列卡引发的风扇狂转:深度解析与ipmitool实战降噪指南 当你为心爱的DELL R730XD服务器加装二手阵列卡后,迎接你的不是性能提升的喜悦,而是直升机起飞般的风扇轰鸣——这种场景对于许多精打细算的企业IT人员来说再熟悉不过。本…...

MindCluster集群调度实践-通用超节点调度算法
作者:昇腾实战派 一、超节点的重要性 随着模型参数量的上升,训练任务运行所需的芯片数量也达到了万卡、十万卡级别。如何将如此庞大的芯片链接起来,并且做到通信带宽和成本的平衡,成为硬件层面的一大难题。 图1.资源扩展方式示…...

搞懂对数收益率:为什么金融圈都在悄悄用它?
搞懂对数收益率:为什么金融圈都在悄悄用它?如果你曾经被“涨10%再跌10%,怎么还亏了?”这个问题困扰过,那么读完这篇文章,你会豁然开朗。一、一个让你“感觉不对”的小实验 假设朋友向你推荐一只期货合约&am…...
5分钟快速上手:Translumo终极免费实时屏幕翻译工具完整指南
5分钟快速上手:Translumo终极免费实时屏幕翻译工具完整指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 想…...

CANN/asc-devkit SIMD数据搬运API
LoadUnzipIndex 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode…...

AzurLaneAutoScript:解放双手的碧蓝航线智能自动化脚本
AzurLaneAutoScript:解放双手的碧蓝航线智能自动化脚本 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为《…...

Phantora:革新GPU集群模拟的LLM训练优化技术
1. Phantora:GPU集群模拟技术的革新者 在大型语言模型(LLM)训练领域,分布式GPU集群的性能优化一直是个棘手问题。传统方法通常需要在实际硬件上反复试错,这不仅成本高昂,而且调试周期漫长。想象一下&#x…...