zookeeper + kafka集群搭建详解
目录
1.消息队列介绍
1.为什么需要消息队列 (MO)
2.使用消息队列的好处
3.消息队列的两种模式
2.Kafka相关介绍
1.Kafka定义
2.Kafka简介
3. Kafka的特性
3.Kafka系统架构
1. Broker(服务器)
2. Topic(一个队列)
3. Partition(相当于分区,记录有效数据)
4. Leader(负责读写)
5. Follower(负责复制和备份)
6. Replica(副本)
7. Producer(生产数据)
8. Consumer(消费者)
9. Consumer Group (CG )(消费者组)
10. offset偏移量(指定消费位置)
11. Zookeeper(存储元信息)
4.部署zookeeper + kafka 集群
1. 部署zookeeper + kafka 集群的操作步骤
2.部署zookeeper + kafka 集群的具体实验步骤
1.消息队列介绍
1.为什么需要消息队列 (MO)
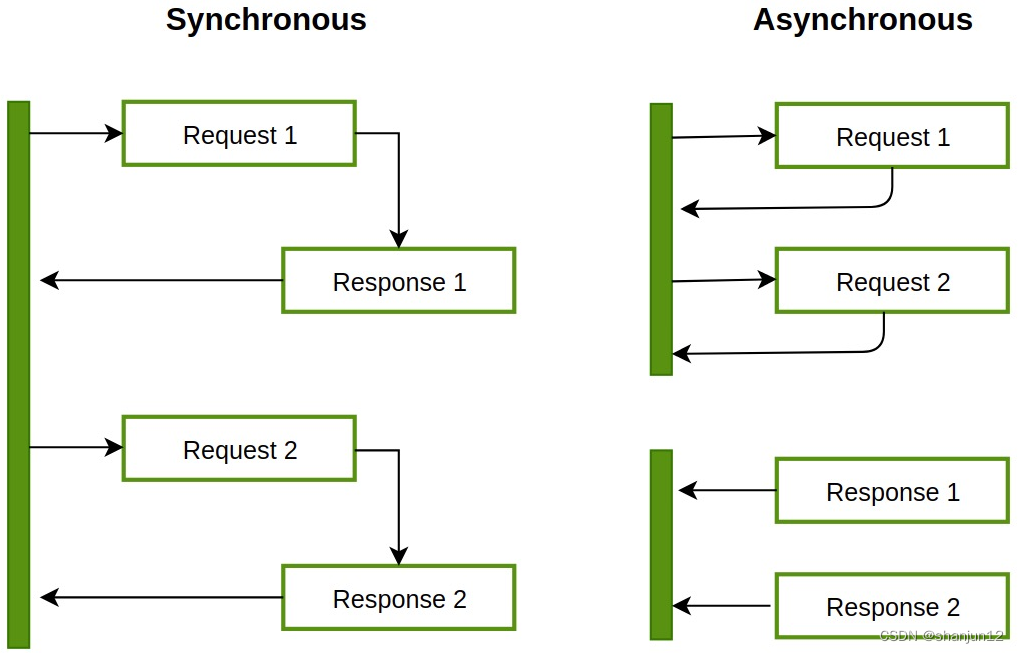
主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多, 从而触发 too many connection 错误, 引发雪崩效应。
我们使用消息队列,通过异步处理请求,从而缓解系统的压力。消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景当前比较常见的 MQ 中间件有 ActiveMQ、RabbitMQ、RocketMQ、Kafka 等。
2.使用消息队列的好处
(1)解耦
允许你独立的扩展或修改两边的处理过程, 只要确保它们遵守同样的接口约束。
(2)可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可 以在系统恢复后被处理。
(3)缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
(4)灵活性 & 峰值处理能力
在访问量剧增的情况下, 应用仍然需要继续发挥作用,但是这样的突发流量并不常见。 如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。 使用消息队列能够使关键组件顶住突发的访问压力, 而不会因为突发的超负荷的请求而完全崩溃。
(5)异步通信很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制, 允许用户把一个消息放入队列, 但并不立即处理它。 想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
3.消息队列的两种模式
1.点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
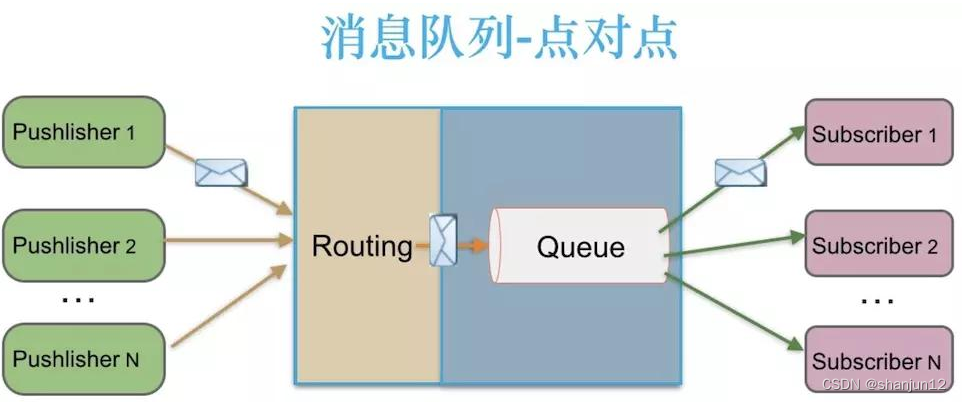
消息生产者生产消息发送到消息队列中, 然后消息消费者从消息队列中取出并且消费消息。 消息被消费以后, 消息队列中不再有存储,所以消息消费者不可能消费到已经被消费的消息。消息队列支持存在多个消费者, 但是对一个消息而言,只会有一个消费者可以消费。
2.发布/订阅模式(一对多, 又叫观察者模式,消费者消费数据之后不会清除消息)
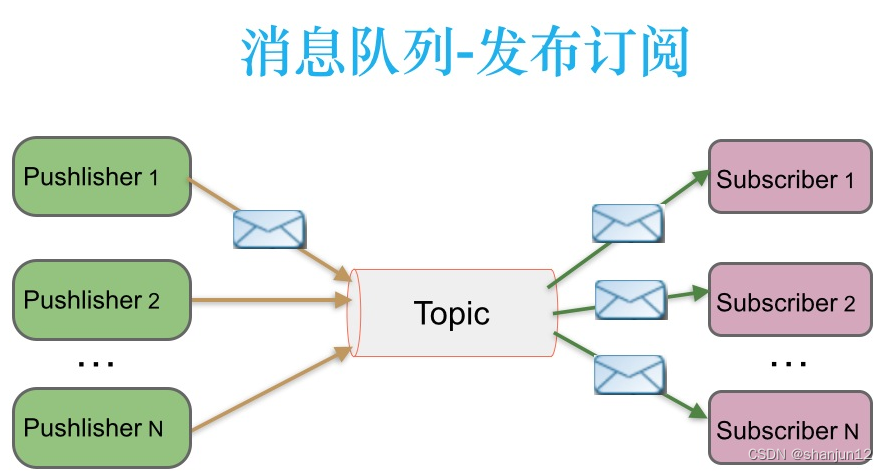
消息生产者 (发布)将消息发布到 topic 中,同时有多个消息消费者 (订阅)消费该消息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。
发布/订阅模式是定 义对象间一种—对多的依赖关系,使得每当一个对象 ( 目标对象)的状态发生改变, 则所有依赖干它的对象 (观察者对象)都会得到通知并自动更新。
2.Kafka相关介绍
1.Kafka定义
Kafka 是一个分布式的基于发布/订阅模式的消息队列(MQ,Message Queue),主要应用于大数据实时处理领域。
2.Kafka简介
Kafka 是最初由 Linkedin 公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于 Zookeeper协调的分布式消息中间件系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于 hadoop的批处理系统、低延迟的实时系统、Spark/Flink 流式处理引擎,nginx 访问日志,消息服务等等,用 scala 语言编写, Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。
3. Kafka的特性
(1)高吞吐量、低延迟
Kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒。每个 topi可以分多个 Partition,Consumer Group 对 Partition 进行消费操作,提高负载均衡能力和消费能力。
(2)可扩展性
kafka 集群支持热扩展;
(3)持久性、可靠性
消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
(4)容错性
允许集群中节点失败(多副本情况下,若副本数量为 n,则允许 n-1 个节点失败);
(5)高并发
支持数干个客户端同时读写。
3.Kafka系统架构
1. Broker(服务器)
一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
2. Topic(一个队列)
可以理解为一个队列,生产者和消费者面向的都是一个 topic。类似于数据库的表名或者 ES 的 index物理上不同 topic 的消息分开存储。
3. Partition(相当于分区,记录有效数据)
为了实现扩展性,一个非常大的 topic 可以分布到多个 broker (即服务器)上,一个 topic 可以分割为一个或多个 partition,每个 partition 是一个有序的队列。Kafka 只保证 partition 内的记录是有序的,而不保证 topic 中不同 partition 的顺序。
每个 topid 至少有一个
partition,当生产者产生数据的时候,会根据分配策略选择分区,然后将消息追加到指定的分区的队列末尾。##Partation 数据路由规则;
1.指定了patition,则直接使用;
2.未指定 patition 但指定 key(相当于消息中某个属性),通过对 key 的 value 进行 hash 取模,选出一个 patition;
4. patition 和 key 都未指定,使用轮询选出一个 patition。
5.
每条消息都会有一个自增的编号,用于标识消息的偏移量,标识顺序从 0 开始。每个 partition 中的数据使用多个 segment 文件存储。
如果 topic 有多个 partition,消费数据时就不能保证数据的顺序
。严格保证消息的消费顺序的场景下 (例如商品秒杀、抢红包), 需要将 partition 数目设为 1。
(1)broker 存储 topic 的数据。如果某 topic 有 N 个 partition,集群有 N 个 broker,那么每个 broker 存储该 topic的一个 partition。
(2)如果某 topic 有 N 个 partition,集群有(N+M)个 broker,那么其中有 N 个 broker 存储 topic 的一个 partition剩下的 M 个 broker 不存储该 topic 的 partition 数据。
(3)如果某 topic 有 N 个 partition,集群中 broker 数目少于 N 个,那么一个 broker 存储该 topic 的一个或多个 partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致 Kafka 集群数据不均衡。
分区的原因:
(1)方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整群就可以适应任意大小的数据了;
(2)可以提高并发,因为可 以以Partition为单位读写了。
4. Leader(负责读写)
每个 partition 有多个副本,其中有且仅有一个作为 Leader,Leader 是当前负责数据的读写的 partition。
5. Follower(负责复制和备份)
Follower 跟随 Leader,所有写请求都通过 Leader 路由,数据变更会广播给所有 Follower,Follower 与 Leader保持数据同步。Follower 只负责备份,不负责数据的读写。如果 Leader 故障,则从 Follower 中选举出一个新的 Leader。
如果 Leader 故障,则从 Follower 中选举出一个新的 Leader。当 Follower 挂掉、卡住或者同步太慢,Leader 会把这个 Follower 从 ISR(Leader 维护的一个和 Leader 保持同步的 Follower 集合) 列表中删除,重新创建一个 Follower。
6. Replica(副本)
副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower
7. Producer(生产数据)
生产者即数据的发布者,该角色将消息发布到 Kafka 的 topic 中。
broker 接收到生产者发送的消息后,broker 将该消息追加到当前用于追加数据的 segment 文件中。生产者发送的消息,存储到一个 partition 中,生产者也可以指定数据存储的 partition。
8. Consumer(消费者)
消费者可以从 broker 中读取数据。消费者可以消费多个 topic 中的数据。
9. Consumer Group (CG )(消费者组)
消费者组,由多个consumer 组成。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。可为每个消费者指定组名,若不指定组名则属于默认的。将多个消费者集中到一起去处理某一个Topic的数据,可以更快的提高数据的消费能力。
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由-一个组内消费者消费,防止数据被重复读取。消费者组之间互不影响。
10. offset偏移量(指定消费位置)
以唯一的标识一条消息。偏移量决定读取数据的位置,不会有线程安全的问题,消费者通过偏移量来决定下次读取的消息(即消费位置)。消息被消费之后,并不被马上册除,这样多个业务就可以重复使用 Kafka 的消息。某一个业务也可 以通过修改偏移量达到重新读取消息的目的,偏移量由用户控制。消息最终还是会被删除的,默认生命周期为 1 周 (7*24小时)。
11. Zookeeper(存储元信息)
Kafka 通过 Zookeeper 来存储集群中各组件的 meta 信息(元信息)。
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。Kafka 0.9版本之前,consumer 默认将offset 保存在Zookeeper 中;从0.9版本开始,consumer默认将offset 保存在Kafka 一个内置的topic 中,该topic 为_consumer_ offsets。
4.部署zookeeper + kafka 集群
1. 部署zookeeper + kafka 集群的操作步骤
1.下载安装包
官方下载地址:http://kafka.apache.org/downloads.htmlcd /opt
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz2.安装 Kafka
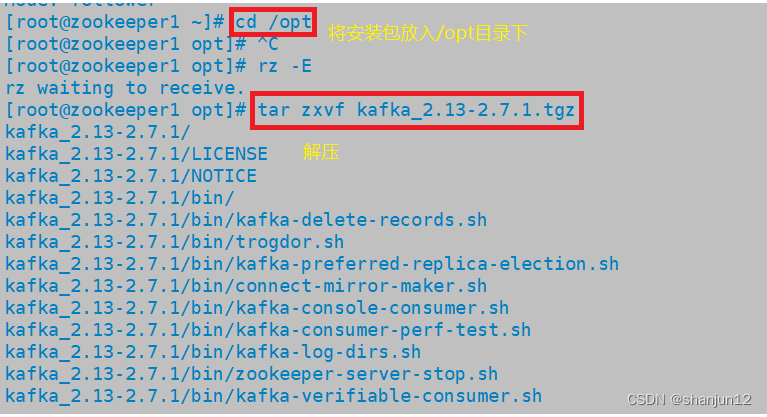
cd /opt/
tar zxvf kafka_2.13-2.7.1.tgz
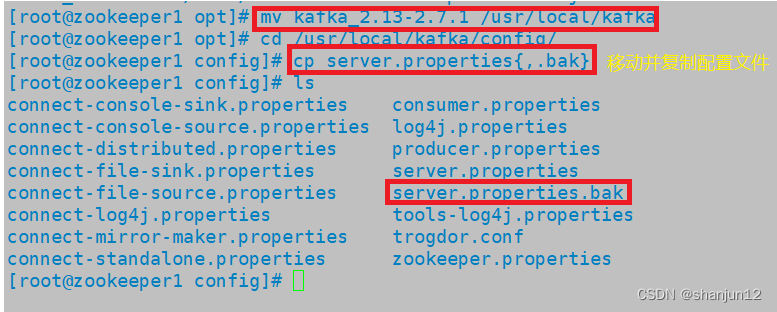
mv kafka_2.13-2.7.1 /usr/local/kafka//修改配置文件
cd /usr/local/kafka/config/
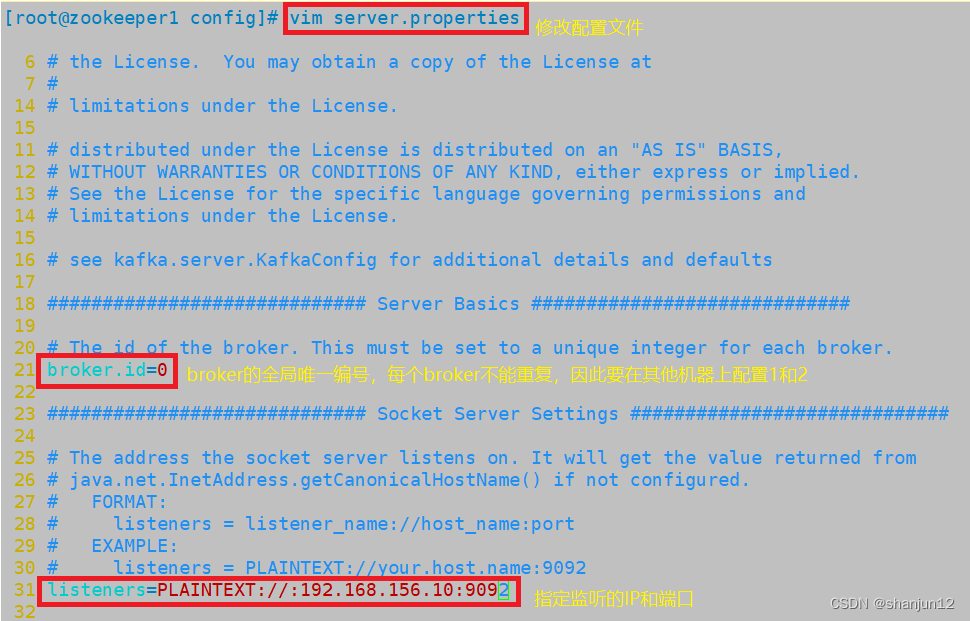
cp server.properties{,.bak}vim server.properties
broker.id=0 ●21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2
listeners=PLAINTEXT://192.168.80.10:9092 ●31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
num.network.threads=3 #42行,broker 处理网络请求的线程数量,一般情况下不需要去修改
num.io.threads=8 #45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数
socket.send.buffer.bytes=102400 #48行,发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #51行,接收套接字的缓冲区大小
socket.request.max.bytes=104857600 #54行,请求套接字的缓冲区大小
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
num.partitions=1 #65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
num.recovery.threads.per.data.dir=1 #69行,用来恢复和清理data下数据的线程数量
log.retention.hours=168 #103行,segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
log.segment.bytes=1073741824 #110行,一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
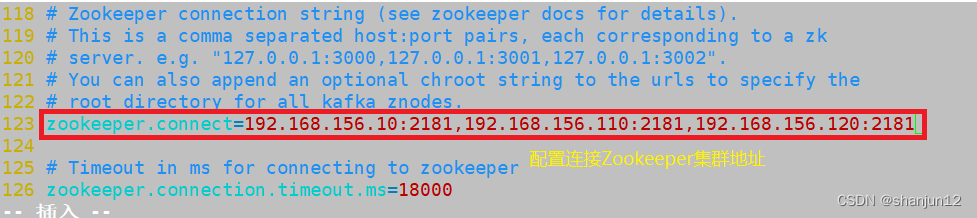
zookeeper.connect=192.168.156.10:2181,192.168.156.110:2181,192.168.156.120:2181 ●123行,配置连接Zookeeper集群地址//修改环境变量
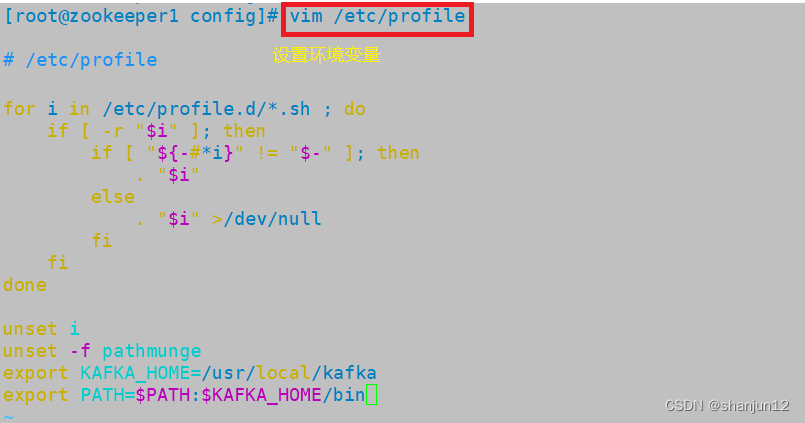
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/binsource /etc/profile//配置 Zookeeper 启动脚本
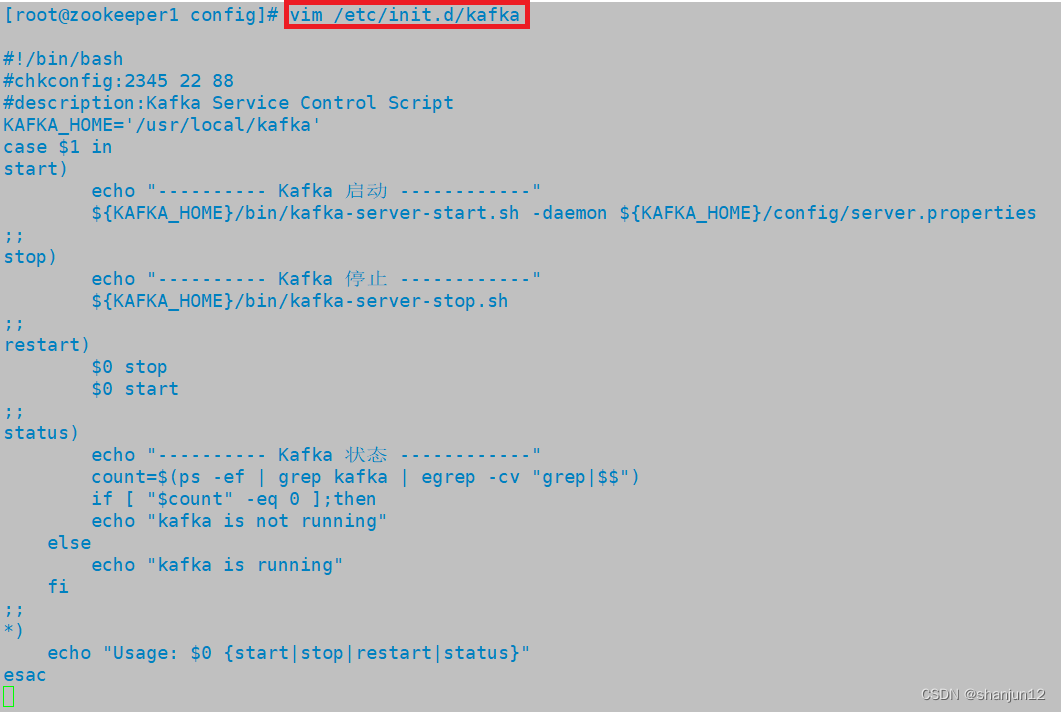
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)echo "---------- Kafka 启动 ------------"${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)echo "---------- Kafka 停止 ------------"${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)$0 stop$0 start
;;
status)echo "---------- Kafka 状态 ------------"count=$(ps -ef | grep kafka | egrep -cv "grep|$$")if [ "$count" -eq 0 ];thenecho "kafka is not running"elseecho "kafka is running"fi
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac//设置开机自启
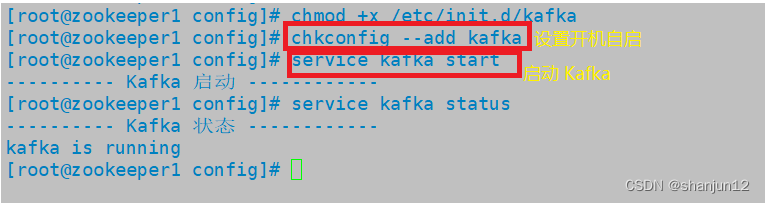
chmod +x /etc/init.d/kafka
chkconfig --add kafka//分别启动 Kafka
service kafka start3.Kafka 命令行操作
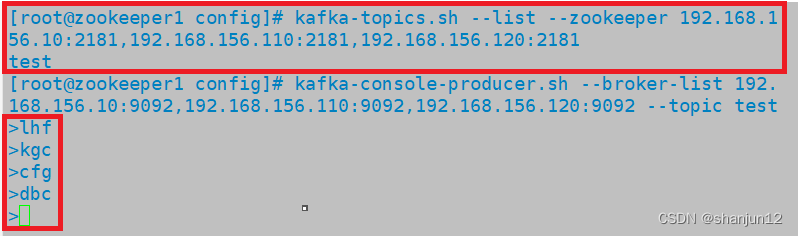
//创建topic
kafka-topics.sh --create --zookeeper 192.168.156.10:2181,192.168.156.110:2181,192.168.156.120:2181 --replication-factor 2 --partitions 3 --topic test-------------------------------------------------------------------------------------
--zookeeper:定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor:定义分区副本数,1 代表单副本,建议为 2
--partitions:定义分区数
--topic:定义 topic 名称
-------------------------------------------------------------------------------------//查看当前服务器中的所有 topic
kafka-topics.sh --list --zookeeper 192.168.156.10:2181,192.168.156.110:2181,192.168.156.120:2181 //查看某个 topic 的详情
kafka-topics.sh --describe --zookeeper 192.168.156.10:2181,192.168.156.110:2181,192.168.156.120:2181 //发布消息
kafka-console-producer.sh --broker-list 192.168.156.10:9092,192.168.156.110:9092,192.168.156.120:9092 --topic test//消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.156.10:9092,192.168.156.110:9092,192.168.156.120:9092 --topic test --from-beginning-------------------------------------------------------------------------------------
--from-beginning:会把主题中以往所有的数据都读取出来
-------------------------------------------------------------------------------------//修改分区数
kafka-topics.sh --zookeeper 192.168.156.10:2181,192.168.156.110:2181,192.168.156.120:2181 --alter --topic test --partitions 6//删除 topic
kafka-topics.sh --delete --zookeeper 192.168.156.10:2181,192.168.156.110:2181,192.168.156.120:2181 --topic test
2.部署zookeeper + kafka 集群的具体实验步骤
1.检查之前zookeeper集群的状态
由于步骤相同,我这里只展示一台设备的搭建
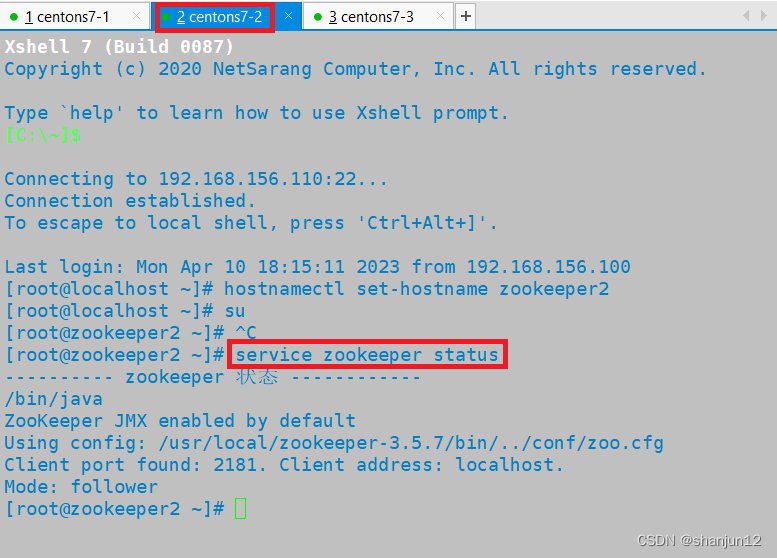
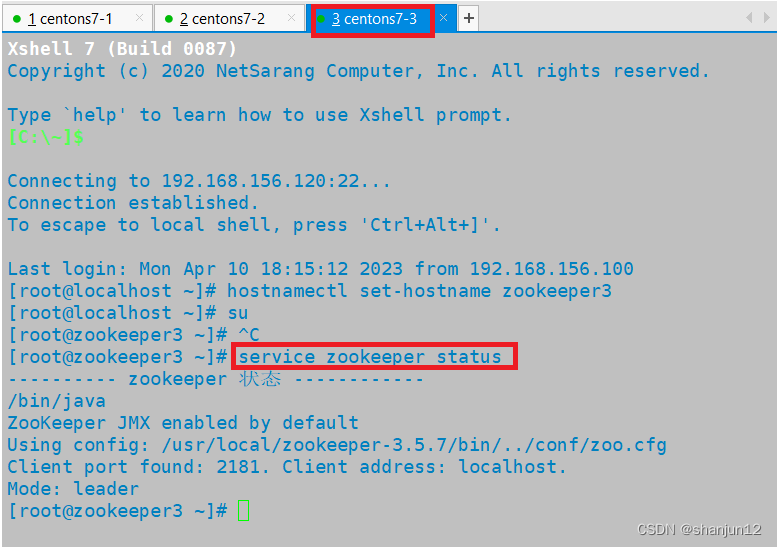
2.在/opt目录下放入安装包,解压
3.移动并将配置文件进行备份
4.修改配置文件

5.设置环境变量

6.配置 Zookeeper 启动脚本
7.设置开机自启并启动
测试阶段:
1.创建topic

2.查看当前服务器中的所有 topic

3.发布消息
4.消费消息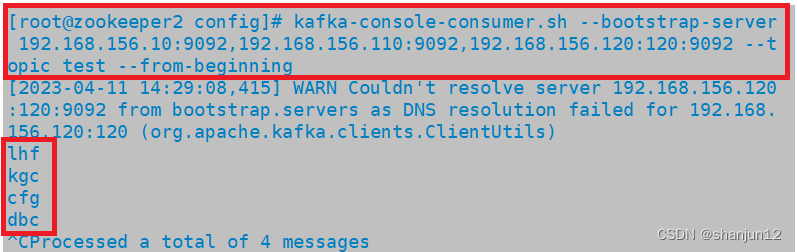
相关文章:
zookeeper + kafka集群搭建详解
目录 1.消息队列介绍 1.为什么需要消息队列 (MO) 2.使用消息队列的好处 3.消息队列的两种模式 2.Kafka相关介绍 1.Kafka定义 2.Kafka简介 3. Kafka的特性 3.Kafka系统架构 1. Broker(服务器) 2. Topic(一个队…...

【数据结构与算法】 - 双向链表 - 详细实现思路及代码
目录 一、概述 二、双向链表 三、双向链表实现步骤 📌3.1 C语言定义双向链表结点 📌3.2 双向链表初始化 📌3.3 双向链表插入数据 📌3.4 双向链表删除数据 📌3.5 双向链表查找数据 📌3.6 双向链…...

面试官在线点评4份留学生简历! 这些坑你中了几个?如何写项目描述才能被大厂发面试?转专业简历该咋写 | 还有优秀简历展示!
我们给大家展示一下 从材料的准备 也就是说到底包含哪些具体的项目 为什么说这些项目是不错的 第二呢就是说在陈述上 在整个这个简历的结构 他的完备性他的准确性 他的正确性 以及最后他的具体的这种项目的描述 那讲完了这个好的简历呢 我们另外搜集了几份简历 那这些简历呢其实…...
一觉醒后ChatGPT 被淘汰了
OpenAI 的 Andrej Karpathy 都大力宣传,认为 AutoGPT 是 prompt 工程的下一个前沿。 近日,AI 界貌似出现了一种新的趋势:自主人工智能。 这不是空穴来风,最近一个名为 AutoGPT 的研究开始走进大众视野。特斯拉前 AI 总监、刚刚回归…...

spring框架的事务
1.什么是事务? 事务:是数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作;这些操作作为一个整体一起向系统提交,要么都执行、要么都不执行;事务是一组不可再分割的操作集合(工作逻辑单元…...

Spring配置数据源
Spring配置数据源数据源的作用环境准备手动创建c3p0数据源封装抽取关键信息,手动创建c3p0数据源使用Spring容器配置数据源数据源的作用 数据源(连接池)是提高程序性能如出现的 事先实例化数据源,初始化部分连接资源 使用连接资源时从数据源中获取 使用完…...

【前端之旅】Vue入门笔记
一名软件工程专业学生的前端之旅,记录自己对三件套(HTML、CSS、JavaScript)、Jquery、Ajax、Axios、Bootstrap、Node.js、Vue、小程序开发(Uniapp)以及各种UI组件库、前端框架的学习。 【前端之旅】Web基础与开发工具 【前端之旅】手把手教你安装VS Code并附上超实用插件…...
WPF教程(二)--Application WPF程序启动方式
1.Application介绍 WPF与WinForm一样有一个 Application对象来进行一些全局的行为和操作,并且每个 Domain (应用程序域)中仅且只有一个 Application 实例存在。和 WinForm 不同的是WPF Application默认由两部分组成 : App.xaml 和 App.xaml.…...

snmp 自定义子代理mib库
测试环境:centos8 1、安装软件 yum install -y net-snmp net-snmp-utils yum install -y net-snmp-perl net-snmp-devel net-snmp-libs 2、创建用户 net-snmp-create-v3-user 输入用户名 soft 输入密码 123456 输入密码 654321 service snmpd restart 3、创建…...

一文说透安全沙箱技术
在数字经济的东风中,数据安全至关重要。目前已经颁布了包括《数据安全法》、《个人信息保护法》和《数据安全管理办法》在内的国家政策,以促进整个数据要素的发展。 而近年来,随着移动应用程序的普及和小程序技术的崛起,安全沙箱…...
)
Java多线程基础面试总结(二)
创建三种线程的方式对比 使用实现Runnable、Callable接口的方式创建多线程。 优势 Java的设计是单继承的设计,如果使用继承Thread的方式实现多线程,则不能继承其他的类,而如果使用实现Runnable接口或Callable接口的方式实现多线程…...

NS32F407VGT6 NS32F407VET6软硬件通用STM32F407VGT6 407VET6
NS32F407VGT6 NS32F407VET6 器件基于高性能的 ARM Cortex-M4 32 位 RISC 内核,工作频率高达 168MHz 。 Cortex-M4 内核带有单精度浮点运算单元 (FPU) ,支持所有 ARM 单精度数据处理指令和数据类型。它还 具有一组 DSP 指令和提高应用安全性的一…...

Openstack: network: ovs: dpif/show 实例分析:interface
[TOC 实例 [cbis-adminovercloud–13 (overcloudrc) ~]$ sudo ovs-appctl dpif/show systemovs-system: hit:75198007884 missed:109924265 br-ex: br-ex 65534/3: (internal) ,65534 是port number; OpenFlow port number; 3 是 ofp_port_to_odp_port(ofproto, o…...

必要的项目管理软件因素
什么样的项目管理软件好?对于一个项目团队来说,从项目开始到项目结束,需要多个部门的配合。每个成员可能会参与一个以上的项目,这通常需要并行的多个项目。据介绍,国外90%以上的项目是用软件管理的,而中国只…...

大学刚毕业,用10000小时,走进字节跳动拿了offer
前言: 没有绝对的天才,只有持续不断的付出。对于我们每一个平凡人来说,改变命运只能依靠努力幸运,但如果你不够幸运,那就只能拉高努力的占比。 2020年7月,我有幸成为了字节跳动的一名测试开发,…...

docker 安装 redis
搜索镜像 docker search redis 拉取最新版本 Docker pull redis Docker挂载配置文件 docker run --restartalways --log-opt max-size100m --log-opt max-file2 -p 6379:6379 --name myredis -v /opt/myredis/redis.conf:/etc/redis/redis.conf -v /opt/myredis/data:/d…...

Ceph常见问题
1. CephFS问题诊断 1.1 无法创建 创建新CephFS报错Error EINVAL: pool ‘rbd-ssd’ already contains some objects. Use an empty pool instead,解决办法: ceph fs new cephfs rbd-ssd rbd-hdd --force1.2 mds.0 is damaged 断电后出现此问题。MDS进…...
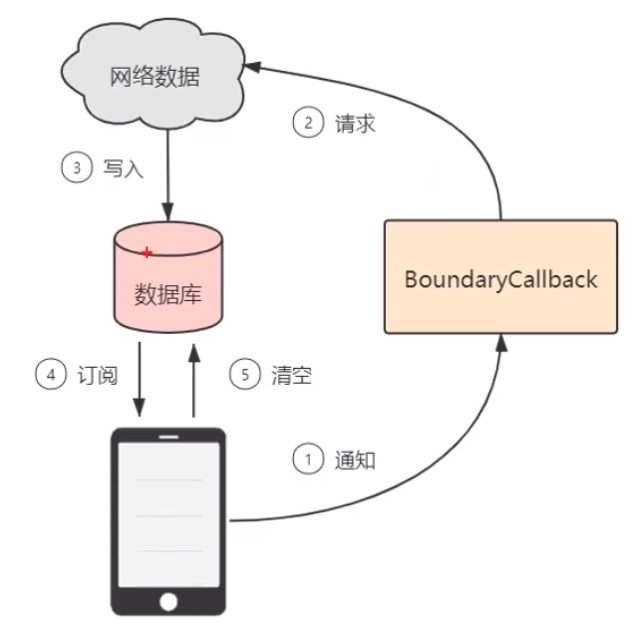
Android---Jetpack之Paging
目录 Paging 组件的意思 Paging 支持的架构类型 Paging 的工作原理 PositionalDataSource PagekeyedDataSource ItemKeyedDataSource BoundaryCallback Paging 组件的意思 分页加载是在应用程序开发过程中十分常见的需求,Paging 就是 Google 为了方便 Andr…...
 参数详解)
gensim.models.word2vec() 参数详解
1. Word2vec简介 Word2vec是一个用来产生词向量的模型。是一个将单词转换成向量形式的工具。 通过转换,可以把对文本内容的处理简化为向量空间中的向量运算,计算出向量空间上的相似度,来表示文本语义上的相似度。 2.Word2vec参数详解 class…...

光栅和矢量图像处理SDK:Graphics Mill 11.7Crack
Graphics Mill 是适用于 .NET 和 ASP.NET 开发人员的最强大的成像工具集。它允许用户轻松地向 .NET 应用程序添加复杂的光栅和矢量图像处理功能。 光栅图形 加载和保存 JPEG、PNG PSD 和其他 8 种图像格式 调整大小、裁剪、自动修复、色度键和 30 多种其他图像处理 使用任何维度…...

别再死记硬背了!用这 5 个核心功能理解 Final Cut Pro 的设计哲学
Final Cut Pro 的设计哲学:5个核心功能如何重塑你的剪辑思维 当你第一次打开Final Cut Pro(简称FCPX),可能会被它与其他剪辑软件截然不同的界面所困惑。这不是一个需要你适应传统时间线的工具,而是一个重新思考剪辑流程…...

从LVGL官方例程到自定义界面:在Windows上用CodeBlocks模拟器快速玩转GUI设计
从LVGL官方例程到自定义界面:在Windows上用CodeBlocks模拟器快速玩转GUI设计 对于嵌入式开发者而言,图形用户界面(GUI)设计往往需要在硬件平台上反复烧录测试,效率低下。而LVGL模拟器配合CodeBlocks的组合,为开发者提供了一个在PC…...

打破iOS修改壁垒:H5GG技术架构与实战路径全解析
打破iOS修改壁垒:H5GG技术架构与实战路径全解析 【免费下载链接】H5GG an iOS Mod Engine with JavaScript APIs & Html5 UI 项目地址: https://gitcode.com/gh_mirrors/h5/H5GG 在iOS生态中,游戏与应用修改一直被视为技术门槛较高的领域&…...

Simscape Electrical电机控制器设计实战:5大核心技术深度解析与性能优化
Simscape Electrical电机控制器设计实战:5大核心技术深度解析与性能优化 【免费下载链接】Design-motor-controllers-with-Simscape-Electrical This repository contains MATLAB and Simulink files used in the "How to design motor controllers using Sims…...

【免费下载】 探索地理信息的无限可能:MATLAB Mapping Toolbox 自由之旅【matlab下载】
探索地理信息的无限可能:MATLAB Mapping Toolbox 自由之旅 在数字化时代的浪潮中,地理信息系统(GIS)已成为连接现实世界与数字世界的桥梁。今天,我们特别向您推荐一个开源宝藏——MATLAB Mapping Toolbox R2019b提取版…...
)
别再被Windows权限卡脖子!用`--user`参数搞定pip安装报错(附详细排查步骤)
彻底解决Windows下Python包安装权限问题:从--user参数到环境配置全攻略 在Windows系统上进行Python开发时,许多开发者都曾遭遇过这样的尴尬时刻:当你满怀期待地输入pip install package_name准备安装一个新工具时,屏幕上却突然跳出…...
Linux用户必备的三大翻译神器:CuteTranslation如何解决多语言工作难题
Linux用户必备的三大翻译神器:CuteTranslation如何解决多语言工作难题 【免费下载链接】CuteTranslation Linux屏幕取词翻译软件 项目地址: https://gitcode.com/gh_mirrors/cu/CuteTranslation 对于长期在Linux环境下工作的开发者、研究人员和学生来说&…...

27考研er必备的那些学习工具!
对2027考研人来说,备考不是简单地“埋头刷题”,而是一场关于信息筛选、资源整合、时间管理和学习效率的长期战役。面对公共课、专业课、院校信息、经验帖、课程资源等海量内容,选对工具往往能让复习少走弯路。 以下这些平台和网站,…...

拷贝漫画第三方客户端完全解析:解锁高效漫画阅读新体验
拷贝漫画第三方客户端完全解析:解锁高效漫画阅读新体验 【免费下载链接】copymanga 拷贝漫画的第三方APP,仅提供基础功能,更多丰富功能请移步官方版本 项目地址: https://gitcode.com/gh_mirrors/co/copymanga 在数字阅读日益普及的今…...

让旧款iPhone/iPad重获新生:Legacy-iOS-Kit终极使用指南
让旧款iPhone/iPad重获新生:Legacy-iOS-Kit终极使用指南 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit …...