Ceph常见问题
1. CephFS问题诊断
1.1 无法创建
创建新CephFS报错Error EINVAL: pool ‘rbd-ssd’ already contains some objects. Use an empty pool instead,解决办法:
ceph fs new cephfs rbd-ssd rbd-hdd --force
1.2 mds.0 is damaged
断电后出现此问题。MDS进程报错: Error recovering journal 0x200: (5) Input/output error。诊断过程:
# 健康状况
ceph health detail
# HEALTH_ERR mds rank 0 is damaged; mds cluster is degraded
# mds.0 is damaged# 文件系统详细信息,可以看到唯一的MDS Boron启动不了
ceph fs status
# cephfs - 0 clients
# ======
# +------+--------+-----+----------+-----+------+
# | Rank | State | MDS | Activity | dns | inos |
# +------+--------+-----+----------+-----+------+
# | 0 | failed | | | | |
# +------+--------+-----+----------+-----+------+
# +---------+----------+-------+-------+
# | Pool | type | used | avail |
# +---------+----------+-------+-------+
# | rbd-ssd | metadata | 138k | 106G |
# | rbd-hdd | data | 4903M | 2192G |
# +---------+----------+-------+-------+# +-------------+
# | Standby MDS |
# +-------------+
# | Boron |
# +-------------+# 显示错误原因
ceph tell mds.0 damage
# terminate called after throwing an instance of 'std::out_of_range'
# what(): map::at
# Aborted# 尝试修复,无效
ceph mds repaired 0# 尝试导出CephFS日志,无效
cephfs-journal-tool journal export backup.bin
# 2019-10-17 16:21:34.179043 7f0670f41fc0 -1 Header 200.00000000 is unreadable
# 2019-10-17 16:21:34.179062 7f0670f41fc0 -1 journal_export: Journal not readable, attempt object-by-object dump with `rados`Error ((5) Input/output error)# 尝试重日志修复,无效
# 尝试将journal中所有可回收的 inodes/dentries 写到后端存储(如果版本比后端更高)
cephfs-journal-tool event recover_dentries summary
# Events by type:
# Errors: 0
# 2019-10-17 16:22:00.836521 7f2312a86fc0 -1 Header 200.00000000 is unreadable# 尝试截断日志,无效
cephfs-journal-tool journal reset
# got error -5from Journaler, failing
# 2019-10-17 16:22:14.263610 7fe6717b1700 0 client.6494353.journaler.resetter(ro) error getting journal off disk
# Error ((5) Input/output error)# 删除重建,数据丢失
ceph fs rm cephfs --yes-i-really-mean-it## 又一次遇到此问题# 深度清理,发现200.00000000存在数据不一致
ceph osd deep-scrub all
40.14 shard 14: soid 40:292cf221:::200.00000000:head data_digest0x6ebfd975 != data_digest 0x9e943993 from auth oi 40:292cf221:::200.00000000:head(22366'34 mds.0.902:1 dirty|data_digest|omap_digest s 90 uv 34 dd 9e943993 od ffffffff alloc_hint [0 0 0])
40.14 deep-scrub 0 missing, 1 inconsistent objects
40.14 deep-scrub 1 errors# 查看RADOS不一致对象详细信息
rados list-inconsistent-obj 40.14 --format=json-pretty
{"epoch": 23060,"inconsistents": [{"object": {"name": "200.00000000",},"errors": [],"union_shard_errors": [# 错误原因,校验信息不一致"data_digest_mismatch_info"],"selected_object_info": {"oid": {"oid": "200.00000000",},},"shards": [{"osd": 7,"primary": true,"errors": [],"size": 90,"omap_digest": "0xffffffff"},{"osd": 14,"primary": false,# errors:分片之间存在不一致,而且无法确定哪个分片坏掉了,原因:
# data_digest_mismatch 此副本的摘要信息和主副本不一样
# size_mismatch 此副本的数据长度和主副本不一致
# read_error 可能存在磁盘错误"errors": [# 这里的原因是两个副本的摘要不一致"data_digest_mismatch_info"],"size": 90,"omap_digest": "0xffffffff","data_digest": "0x6ebfd975"}]}]
}
# 转为处理inconsistent问题,停止OSD.14,Flush 日志,启动OSD.14,执行PG修复
# 无效…… 执行PG修复后Ceph会自动以权威副本覆盖不一致的副本,但是并非总能生效,
# 例如,这里的情况,主副本的数据摘要信息丢失# 删除故障对象
rados -p rbd-ssd rm 200.00000000
2. OSD问题诊断
2.1 启动后立即崩溃
通常可以认为属于Ceph的Bug。这些Bug可能因为数据状态引发,有些时候将崩溃OSD的权重清零,可以恢复:
# 尝试解决osd.17启动后立即宕机
ceph osd reweight 17 0
3. PG问题诊断
3.1 所有PG卡在unkown
如果创建一个存储池后,其所有PG都卡在此状态,可能原因是CRUSH map不正常。你可以配置osd_crush_update_on_start为true让集群自动调整CRUSH map。
3.2 卡在peering
ceph -s显示如下状态,长期不恢复:
cluster: health: HEALTH_WARN Reduced data availability: 2 pgs inactive, 2 pgs peering19 slow requests are blocked > 32 secdata:pgs: 0.391% pgs not active510 active+clean2 peering
此案例中,使用此PG的Pod呈Known状态。
检查卡在inactive状态的PG:
ceph pg dump_stuck inactivePG_STAT STATE UP UP_PRIMARY ACTING ACTING_PRIMARY
17.68 peering [3,12] 3 [3,12] 3
16.32 peering [4,12] 4 [4,12] 4
输出其中一个PG的诊断信息,片断如下:
// ceph pg 17.68 query
{ "info": { "stats": {"state": "peering","stat_sum": {"num_objects_dirty": 5},"up": [3,12],"acting": [3,12],// 因为哪个OSD而阻塞"blocked_by": [12],"up_primary": 3,"acting_primary": 3}},"recovery_state": [// 如果顺利,第一个元素应该是 "name": "Started/Primary/Active"{"name": "Started/Primary/Peering/GetInfo","enter_time": "2018-06-11 18:32:39.594296",// 但是,卡在向OSD 12 请求信息这一步上"requested_info_from": [{"osd": "12"}]},{"name": "Started/Primary/Peering",},{"name": "Started",}]
}
没有获得osd-12阻塞Peering的明确原因。
查看日志,osd-12位于10.0.0.104,osd-3位于10.0.0.100,后者为Primary OSD。
osd-3日志,在18:26开始出现,和所有其它OSD之间心跳检测失败。此时10.0.0.100负载很高,卡死。
osd-12日志,在18:26左右大量出现:
osd.12 466 heartbeat_check: no reply from 10.0.0.100:6803 osd.4 since back 2018-06-11 18:26:44.973982 ...
直到18:44分仍然无法进行心跳检测,重启osd-12后一切恢复正常。
3.3 incomplete
检查无法完成的PG:
ceph pg dump_stuck# PG_STAT STATE UP UP_PRIMARY ACTING ACTING_PRIMARY
# 17.79 incomplete [9,17] 9 [9,17] 9
# 32.1c incomplete [16,9] 16 [16,9] 16
# 17.30 incomplete [16,9] 16 [16,9] 16
# 31.35 incomplete [9,17] 9 [9,17] 9
查询PG 17.30的诊断信息:
// ceph pg 17.30 query
{"state": "incomplete","info": {"pgid": "17.30","stats": {// 被osd.11阻塞而无法完成,此osd已经不存在"blocked_by": [11],"up_primary": 16,"acting_primary": 16}},// 恢复的历史记录"recovery_state": [{"name": "Started/Primary/Peering/Incomplete","enter_time": "2018-06-17 04:48:45.185352",// 最终状态,此PG没有完整的副本"comment": "not enough complete instances of this PG"},{"name": "Started/Primary/Peering","enter_time": "2018-06-17 04:48:45.131904","probing_osds": ["9","16","17"],// 期望检查已经不存在的OSD"down_osds_we_would_probe": [11],"peering_blocked_by_detail": [{"detail": "peering_blocked_by_history_les_bound"}]}]
}
以看到17.30期望到osd.11寻找权威数据,而osd.11已经永久丢失了。这种情况下,可以尝试强制标记PG为complete。
首先,停止PG的主OSD: service ceph-osd@16 stop
然后,运行下面的工具:
ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-16 --pgid 17.30 --op mark-complete
# Marking complete
# Marking complete succeeded
最后,重启PG的主OSD: service ceph-osd@16 start
3.4 单副本导致的stale
不做副本的情况下,单个OSD宕机即导致数据不可用:
ceph health detail
# 注意Acting Set仅仅有一个成员
# pg 2.21 is stuck stale for 688.372740, current state stale+active+clean, last acting [7]
# 但是其它PG的Acting Set则不是
# pg 3.4f is active+recovering+degraded, acting [9,1]
如果OSD的确出现硬件故障,则数据丢失。此外,你也无法对这种PG进行查询操作。
3.5 inconsistent
定位出问题PG的主OSD,停止它,刷出日志,然后修复PG:
ceph health detail
# HEALTH_ERR 2 scrub errors; Possible data damage: 2 pgs inconsistent
# OSD_SCRUB_ERRORS 2 scrub errors
# PG_DAMAGED Possible data damage: 2 pgs inconsistent
# pg 15.33 is active+clean+inconsistent, acting [8,9]
# pg 15.61 is active+clean+inconsistent, acting [8,16]# 查找OSD所在机器
ceph osd find 8# 登陆到osd.8所在机器
systemctl stop ceph-osd@8.service
ceph-osd -i 8 --flush-journal
systemctl start ceph-osd@8.service
ceph pg repair 15.61
4. 对象问题诊断
4.1 unfound
持有对象权威副本的OSD宕机或被剔除,会导致该问题出现。例如两个配对的OSD(共同处理某个PG):
- osd.1宕机
- osd.2独自处理了一些写操作
- osd1开机
- osd.1+osd2配对,由于osd.2独自的写操作,缺失的对象排队等候在osd.1上恢复
- 恢复完成之前,osd.2宕机,或者被移除
在上面这个事件序列中,osd.1知道权威副本存在,但是却找不到,这种情况下针对目标对象的请求会被阻塞,直到权威副本的持有者osd上线。
执行下面的命令,定位存在问题的PG:
ceph health detail | grep unfound
# OBJECT_UNFOUND 1/90055 objects unfound (0.001%)
# pg 33.3e has 1 unfound objects
# pg 33.3e is active+recovery_wait+degraded, acting [17,6], 1 unfound
进一步,定位存在问题的对象:
// ceph pg 33.3e list_missing
{"offset": {"oid": "","key": "","snapid": 0,"hash": 0,"max": 0,"pool": -9223372036854775808,"namespace": ""},"num_missing": 1,"num_unfound": 1,"objects": [{"oid": {// 丢失的对象"oid": "obj_delete_at_hint.0000000066","key": "","snapid": -2,"hash": 2846662078,"max": 0,"pool": 33,"namespace": ""},"need": "1723'1412","have": "0'0","flags": "none","locations": []}],"more": false
}
如果丢失的对象太多,more会显示为true。
执行下面的命令,可以查看PG的诊断信息:
// ceph pg 33.3e query
{"state": "active+recovery_wait+degraded","recovery_state": [{"name": "Started/Primary/Active","enter_time": "2018-06-16 15:03:32.873855",// 丢失的对象所在的OSD"might_have_unfound": [{"osd": "6","status": "already probed"},{"osd": "11","status": "osd is down"}],} ]
}
上面输出中的osd.11,先前已经出现硬件故障,被移除了。这意味着unfound的对象已经不可恢复。你可以标记:
# 回滚到前一个版本,如果是新创建对象则忘记其存在。不支持EC池
ceph pg 33.3e mark_unfound_lost revert
# 让Ceph忘记unfound对象的存在
ceph pg 33.3e mark_unfound_lost delete
5. ceph-deploy
5.1 TypeError: ‘Logger’ object is not callable
/usr/lib/python2.7/dist-packages/ceph_deploy/osd.py第376行,替换为:
LOG.info(line.decode('utf-8'))
5.2 Could not locate executable ‘ceph-volume’ make sure it is installed and available
应该安装ceph-deploy的1.5.39版本,2.0.0版本仅仅支持luminous:
apt remove ceph-deploy
apt install ceph-deploy=1.5.39 -y
5.3 部署MON后ceph-s卡死
在我的环境下,是因为MON节点识别的public addr为LVS的虚拟网卡的IP地址导致。修改配置,显式指定MON的IP地址即可:
[mon.master01-10-5-38-24]
public addr = 10.5.38.24
cluster addr = 10.5.38.24[mon.master02-10-5-38-39]
public addr = 10.5.38.39
cluster addr = 10.5.38.39[mon.master03-10-5-39-41]
public addr = 10.5.39.41
cluster addr = 10.5.39.41
6. ceph-helm
在我的环境下部署,出现一系列和权限有关的问题,如果你遇到相同问题且不关心安全性,可以修改配置:
# kubectl -n ceph edit configmap ceph-etc
apiVersion: v1
data:ceph.conf: |[global]fsid = 08adecc5-72b1-4c57-b5b7-a543cd8295e7mon_host = ceph-mon.ceph.svc.k8s.gmem.cc# 添加以下三行auth client required = noneauth cluster required = noneauth service required = none[osd]# 在大型集群里用单独的“集群”网可显著地提升性能cluster_network = 10.0.0.0/16ms_bind_port_max = 7100public_network = 10.0.0.0/16
kind: ConfigMap
如果需要保证集群安全,请参考下面几个案例。
6.1 ceph-mgr报Operation not permitted
-
问题现象
此Pod一直无法启动,查看容器日志,发现:
timeout 10 ceph --cluster ceph auth get-or-create mgr.xenial-100 mon ‘allow profile mgr’ osd ‘allow *’ mds ‘allow *’ -o /var/lib/ceph/mgr/ceph-xenial-100/keyring
0 librados: client.admin authentication error (1) Operation not permitted -
问题分析
连接到可以访问的ceph-mon,执行命令:kubectl -n ceph exec -it ceph-mon-nhx52 -c ceph-mon -- ceph发现报同样的错误。这说明client.admin的Keyring有问题。登陆到ceph-mon,获取Keyring列表:
# kubectl -n ceph exec -it ceph-mon-nhx52 -c ceph-mon bash # ceph --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-xenial-100/keyring auth list installed auth entries:client.adminkey: AQAXPdtaAAAAABAA6wd1kCog/XtV9bSaiDHNhw==auid: 0caps: [mds] allowcaps: [mgr] allow *caps: [mon] allow *caps: [osd] allow *client.bootstrap-mdskey: AQAgPdtaAAAAABAAFPgqn4/zM5mh8NhccPWKcw==caps: [mon] allow profile bootstrap-mds client.bootstrap-osdkey: AQAUPdtaAAAAABAASbfGQ/B/PY4Imoa4Gxsa2Q==caps: [mon] allow profile bootstrap-osd client.bootstrap-rgwkey: AQAJPdtaAAAAABAAswtFjgQWahHsuy08Egygrw==caps: [mon] allow profile bootstrap-rgw而当前使用的client.admin的Keyring内容为:
[client.admin]key = AQAda9taAAAAABAAgWIsgbEiEsFRJQq28hFgTQ==auid = 0caps mds = "allow"caps mon = "allow *"caps osd = "allow *"caps mgr = "allow *"内容不一致。使用auth list获得的client.admin的Keyring,可以发现是有效的:
ceph --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-xenial-100/keyring auth get client.admin > client.admin.keyyring
ceph --name client.admin --keyring client.admin.keyyring # OKskydns_skydns_dns_cachemiss_count_total{instance="172.27.100.134:10055"}
检查一下各Pod的/etc/ceph/ceph.client.admin.keyring,可以发现都是从Secret ceph-client-admin-keyring挂载的。那么这个Secret是如何生成的呢?执行命令:
kubectl -n ceph get job --output=yaml --export | grep ceph-client-admin-keyring -B 50
可以发现Job ceph-storage-keys-generator负责生成该Secret。 查看其Pod日志可以生成Keyring、创建Secret的记录。进一步查看Pod的资源定义,可以看到负责创建的脚本/opt/ceph/ceph-storage-key.sh挂载自ConfigMap ceph-bin中的ceph-storage-key.sh。
解决此问题最简单的办法就是修改Secret,将其修改为集群中实际有效的Keyring:
# 导出Secret定义
kubectl -n ceph get secret ceph-client-admin-keyring --output=yaml --export > ceph-client-admin-keyring
# 获得有效Keyring的Base64编码
cat client.admin.keyyring | base64
# 将Secret中的编码替换为上述Base64,然后重新创建Secret
kubectl -n ceph apply -f ceph-client-admin-keyring
此外Secret pvc-ceph-client-key中存放的也是admin用户的Key,其内容也需要替换到有效的:
kubectl -n ceph edit secret pvc-ceph-client-key
6.2 pvc无法提供
原因和上一个问题类似,还是权限问题。
查看无法绑定的PVC日志:
# kubectl -n ceph describe pvcNormal Provisioning 53s ceph.com/rbd ceph-rbd-provisioner-5544dcbcf5-n846s 708edb2c-4619-11e8-abf2-e672650d97a2 External provisioner is provisioning volume for claim
"ceph/ceph-pvc"Warning ProvisioningFailed 53s ceph.com/rbd ceph-rbd-provisioner-5544dcbcf5-n846s 708edb2c-4619-11e8-abf2-e672650d97a2 Failed to provision volume with StorageClass "general"
: failed to create rbd image: exit status 1, command output: 2018-04-22 13:44:35.269967 7fb3e3e3ad80 -1 did not load config file, using default settings.
2018-04-22 13:44:35.297828 7fb3e3e3ad80 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin: (2)No such file or directoryConnection to localhost closed by remote host.
Connection to localhost closed.e3e3ad80 0 librados: client.admin authentication error (1) Operation not permitted
rbd-provisioner需要读取StorageClass定义,获取需要的凭证信息:
# kubectl -n ceph get storageclass --output=yaml
apiVersion: v1
items:
- apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: generalparameters:adminId: adminadminSecretName: pvc-ceph-conf-combined-storageclassadminSecretNamespace: cephimageFeatures: layeringimageFormat: "2"monitors: ceph-mon.ceph.svc.k8s.gmem.cc:6789pool: rbduserId: adminuserSecretName: pvc-ceph-client-keyprovisioner: ceph.com/rbdreclaimPolicy: Delete
可以看到牵涉到两个Secret:pvc-ceph-conf-combined-storageclass、pvc-ceph-client-key,你需要把正确的Keyring内容写入其中。
6.3 pvc无法Attach
-
现象:
PVC可以Provision,RBD可以通过Ceph命令挂载,但是Pod无法启动,Describe之显示:auth: unable to find a keyring on /etc/ceph/keyring: (2) No such file or directory monclient(hunting): authenticate NOTE: no keyring found; disabled cephx authentication librados: client.admin authentication error (95) Operation not supported -
解决办法:
把ceph.client.admin.keyring拷贝一份为 /etc/ceph/keyring即可。
6.4 ceph-osd报Operation not permitted
原因和上一个问题一样。查看无法启动的容器日志:
kubectl -n ceph logs ceph-osd-dev-vdb-bjnbm -c osd-prepare-pod
# ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring health
# 0 librados: client.bootstrap-osd authentication error (1) Operation not permitted
# [errno 1] error connecting to the cluster
进一步查看,可以发现/var/lib/ceph/bootstrap-osd/ceph.keyring挂载自ceph-bootstrap-osd-keyring下的ceph.keyring:
# kubectl -n ceph get secret ceph-bootstrap-osd-keyring --output=yaml --export
apiVersion: v1
data:ceph.keyring: W2NsaWVudC5ib290c3RyYXAtb3NkXQogIGtleSA9IEFRQVlhOXRhQUFBQUFCQUFSQ2l1bVY1NFpOU2JGVWwwSDZnYlJ3PT0KICBjYXBzIG1vbiA9ICJhbGxvdyBwcm9maWxlIGJvb3RzdHJhcC1vc2QiCgo=
kind: Secret
metadata:creationTimestamp: nullname: ceph-bootstrap-osd-keyringselfLink: /api/v1/namespaces/ceph/secrets/ceph-bootstrap-osd-keyring
type: Opaque# BASE64解码后:
[client.bootstrap-osd]key = AQAYa9taAAAAABAARCiumV54ZNSbFUl0H6gbRw==caps mon = "allow profile bootstrap-osd"
获得实际有效的Keyring:
kubectl -n ceph exec -it ceph-mon-nhx52 -c ceph-mon -- ceph --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-xenial-100/keyring auth get client.bootstrap-osd
# 注意上述命令的输出的第一行exported keyring for client.bootstrap-osd不属于Keyring
[client.bootstrap-osd]key = AQAUPdtaAAAAABAASbfGQ/B/PY4Imoa4Gxsa2Q==caps mon = "allow profile bootstrap-osd"
修改Secret: kubectl **-**n ceph edit secret ceph-bootstrap-osd-keyring 替换为上述Keyring。
6.5 ceph-osd报No cluster conf with fsid
-
报错信息:
# kubectl -n ceph logs ceph-osd-dev-vdc-cpkxh -c osd-activate-pod ceph_disk.main.Error: Error: No cluster conf found in /etc/ceph with fsid 08adecc5-72b1-4c57-b5b7-a543cd8295e7 # 每个OSD都包同样的错误对应的配置文件内容:
kubectl -n ceph get configmap ceph-etc --output=yaml apiVersion: v1 data:ceph.conf: |[global]fsid = a4426e8a-c46d-4407-95f1-911a23a0dd6emon_host = ceph-mon.ceph.svc.k8s.gmem.cc[osd]cluster_network = 10.0.0.0/16ms_bind_port_max = 7100public_network = 10.0.0.0/16 kind: ConfigMap metadata:name: ceph-etcnamespace: ceph可以看到,fsid不一致。修改一下ConfigMap中的fsid即可解决此问题。
6.6 容器无法Attach PV
-
报错信息:
describe pod报错:timeout expired waiting for volumes to attach/mount for pod
kubelet报错:executable file not found in $PATH, rbd output -
原因分析:
动态提供的持久卷,包含两个阶段:- 卷提供,原本由控制平面负责,controller-manager中需要包含rbd命令,才能在Ceph集群中创建供K8S使用的镜像。目前这个职责由external_storage项目的rbd-provisioner完成
- 卷依附/分离,由使用卷的Pod所在的Node的kubelet负责完成。这些Node需要安装rbd命令,并提供有效的配置文件
-
解决方案:
# 安装软件 apt install -y ceph-common # 从ceph-mon拷贝以下文件: # /etc/ceph/ceph.client.admin.keyring # /etc/ceph/ceph.conf应用上述方案后,如果继续报错:rbd: map failed exit status 110, rbd output: rbd: sysfs write failed In some cases useful info is found in syslog。则查看一下系统日志:
dmesg | tail# [ 3004.833252] libceph: mon0 10.0.0.100:6789 feature set mismatch, my 106b84a842a42 # < server's 40106b84a842a42, missing 400000000000000 # [ 3004.840980] libceph: mon0 10.0.0.100:6789 missing required protocol features对照本文前面的特性表,可以发现内核版本必须4.5+才可以(CEPH_FEATURE_NEW_OSDOPREPLY_ENCODING)。
最简单的办法就是升级一下内核:# Desktop apt install --install-recommends linux-generic-hwe-16.04 xserver-xorg-hwe-16.04 -y # Server apt install --install-recommends linux-generic-hwe-16.04 -ysudo apt-get remove linux-headers-4.4.* -y && \ sudo apt-get remove linux-image-4.4.* -y && \ sudo apt-get autoremove -y && \ sudo update-grub或者,将tunables profile调整到hammer版本的Ceph:
ceph osd crush tunables hammer # adjusted tunables profile to hammer
6.7 OSD启动失败报文件名太长
报错信息:ERROR: osd init failed: (36) File name too long
报错原因:使用的文件系统为EXT4,存储的xattrs大小有限制,有条件的话最好使用XFS
解决办法:修改配置文件,如下:
osd_max_object_name_len = 256
osd_max_object_namespace_len = 64
6.8 无法打开/proc/0/cmdline
报错信息:Fail to open ‘/proc/0/cmdline’ error No such file or directory
报错原因:在CentOS 7上,将ceph-mon和ceph-osd(基于目录)部署在同一节点(基于Helm)报此错误,分离后问题消失。此外部署mon的那些节点还设置了虚IP,其子网和Ceph的Cluster/Public网络相同,这导致了某些OSD监听的地址不正确。
再次遇到此问题,原因是一个虚拟网卡lo:ngress使用和eth0相同的网段,导致OSD使用了错误的网络。
解决办法是写死OSD监听地址:
[osd.2]
public addr = 10.0.4.1
cluster addr = 10.0.4.1
6.9 无法挂载RBD
报错信息:Input/output error,结合dmesg | tail可以看到更细节的报错
报错原因,可能情况:
- CentOS7下报错,提示客户端不满足特性CEPH_FEATURE_CRUSH_V4(1000000000000)。解决办法,将Bucket算法改为straw。注意,之后加入的OSD仍然默认使用straw2,使用的镜像的标签为tag-build-master-luminous-ubuntu-16.04。
6.10 write error: File name too long
external storage中的CephFS可以正常Provisioning,但是尝试读写数据时报此错误。原因是文件路径过长,和底层文件系统有关,为了兼容部分Ext文件系统的机器,我们限制了osd_max_object_name_len。
解决办法,不使用UUID,而使用namespace + pvcname来命名目录。修改cephfs-provisioner.go,118行
// create random share name
share := fmt.Sprintf("%s-%s", options.PVC.Namespace,options.PVC.Name)
// create random user id
user := fmt.Sprintf("%s-%s", options.PVC.Namespace,options.PVC.Name)
重新编译即可。
7. k8s相关
7.1 rbd image * is still being used
describe pod发现:
rbd image rbd-unsafe/kubernetes-dynamic-pvc-c0ac2cff-84ef-11e8-9a2a-566b651a72d6 is still being used
说明有其它客户端正在占用此镜像。如果尝试删除镜像,你会发现无法成功:
rbd rm rbd-unsafe/kubernetes-dynamic-pvc-c0ac2cff-84ef-11e8-9a2a-566b651a72d6 librbd::image::RemoveRequest: 0x560e39df9af0 check_image_watchers: image has watchers - not removing
Removing image: 0% complete...failed.
rbd: error: image still has watchers
This means the image is still open or the client using it crashed. Try again after closing/unmapping it or waiting 30s for the crashed client to timeout.
要知道watcher是谁,可以执行:
rbd status rbd-unsafe/kubernetes-dynamic-pvc-c0ac2cff-84ef-11e8-9a2a-566b651a72d6
Watchers:watcher=10.5.39.12:0/1652752791 client.94563 cookie=18446462598732840961
可以发现10.5.39.12正在占用镜像。
另一种获取watcher的方法是,使用rbd的header对象。执行下面的命令获取rbd的诊断信息:
rbd info rbd-unsafe/kubernetes-dynamic-pvc-c0ac2cff-84ef-11e8-9a2a-566b651a72d6 rbd image 'kubernetes-dynamic-pvc-c0ac2cff-84ef-11e8-9a2a-566b651a72d6':size 8192 MB in 2048 objectsorder 22 (4096 kB objects)block_name_prefix: rbd_data.134474b0dc51format: 2features: layeringflags: create_timestamp: Wed Jul 11 17:49:51 2018
字段block_name_prefix的值rbd_data.134474b0dc51,将data换为header即为header对象。然后使用命令:
rados listwatchers -p rbd-unsafe rbd_header.134474b0dc51watcher=10.5.39.12:0/1652752791 client.94563 cookie=18446462598732840961
既然知道10.5.39.12占用镜像,断开连接即可。 在此机器上执行下面的命令,显示当前映射的rbd镜像列表:
rbd showmappedid pool image snap device
0 rbd-unsafe kubernetes-dynamic-pvc-c0ac2cff-84ef-11e8-9a2a-566b651a72d6 - /dev/rbd0
1 rbd-unsafe kubernetes-dynamic-pvc-0729f9a6-84f0-11e8-9b75-5a3f858854b1 - /dev/rbd1
此机器上的rbd0虽然映射,但是没有挂载。解除映射:
rbd unmap /dev/rbd0
再次检查rbd镜像状态,发现没有watcher了:
rbd status rbd-unsafe/kubernetes-dynamic-pvc-c0ac2cff-84ef-11e8-9a2a-566b651a72d6 Watchers: none
7.2 rbd: map failed signal: aborted (core dumped)
kubectl describe报错Unable to mount volumes for pod… timeout expired waiting for volumes to attach or mount for pod…
检查发现目标rbd没有Watcher,Pod所在机器的Kubectl报错rbd: map failed signal: aborted (core dumped)。此前曾经在该机器上执行过rbd unmap操作。
手工 rbd map后问题消失。
8. 断电后无法启动OSD
journal do_read_entry: bad header magic
报错信息:journal do_read_entry(156389376): bad header magic…FAILED assert(interval.last > last)
这是12.2版本已知的BUG,断电后可能出现OSD无法启动,可能导致数据丢失。
9. 其他
9.1 Couldn’t init storage provider (RADOS)
RGW实例无法启动,通过journalctl看到上述信息。
要查看更多信息,需要查看RGW日志:
2020-10-22 16:51:55.771035 7fb1b0f20e80 0 ceph version 12.2.5 (cad919881333ac92274171586c827e01f554a70a) luminous (stable), process (unknown), pid 2546439
2020-10-22 16:51:55.792872 7fb1b0f20e80 0 librados: client.rgw.ceph02 authentication error (22) Invalid argument
2020-10-22 16:51:55.793450 7fb1b0f20e80 -1 Couldn't init storage provider (RADOS)
可以发现是和身份验证有关的问题。
通过 systemctl status ceph-radosgw@rgw.**$**RGW_HOST得到命令行,手工运行:
radosgw -f --cluster ceph --name client.rgw.ceph02 --setuser ceph --setgroup ceph -d --debug_ms 1
发现报错和上面一样。尝试增加–keyring参数,问题解决:
radosgw -f --cluster ceph --name client.rgw.ceph02 \--setuser ceph --setgroup ceph -d --debug_ms 1 \--keyring=/var/lib/ceph/radosgw/ceph-rgw.ceph02/keyring
看来是Systemd服务没有找到keyring导致。
9.2 禁用IPv6的机器上无法开启Prometheus模块
报错信息:Unhandled exception from module ‘prometheus’ while running on mgr.master01-10-5-38-24: error(‘No socket could
be created’,)
解决办法: ceph config-key set mgr/prometheus/server_addr 0.0.0.0
9.3 反复警告mon… clock skew
原因是时钟不同步警告阈值太低,在global段增加配置并重启MON:
mon clock drift allowed = 2
mon clock drift warn backoff = 30
或者执行下面的命令即时生效:
ceph tell mon.* injectargs '--mon_clock_drift_allowed=2'
ceph tell mon.* injectargs '--mon_clock_drift_warn_backoff=30'
或者检查ntp相关配置,保证时钟同步精度。
9.4 深度清理导致高IO
深度清理很消耗IO,如果长时间无法完成,可以禁用:
ceph osd set noscrub
ceph osd set nodeep-scrub
问题解决后,可以再启用:
ceph osd unset noscrub
ceph osd unset nodeep-scrub
使用CFQ作为IO调度器时,可以调整OSD IO线程的优先级:
# 设置调度器
echo cfq > /sys/block/sda/queue/scheduler# 检查当前某个OSD的磁盘线程优先级类型
ceph daemon osd.4 config get osd_disk_thread_ioprio_class# 修改IO优先级
ceph tell osd.* injectargs '--osd_disk_thread_ioprio_priority 7'
# IOPRIO_CLASS_RT最高 IOPRIO_CLASS_IDLE最低
ceph tell osd.* injectargs '--osd_disk_thread_ioprio_class idle'
如果上述措施没有问题时,可以考虑配置以下参数:
osd_deep_scrub_stride = 131072
# 每次Scrub的块数量范围
osd_scrub_chunk_min = 1
osd_scrub_chunk_max = 5
osd scrub during recovery = false
osd deep scrub interval = 2592000
osd scrub max interval = 2592000
# 单个OSD并发进行的Scrub个数
osd max scrubs = 1
# Scrub起止时间
osd max begin hour = 2
osd max end hour = 6
# 系统负载超过多少则禁止Scrub
osd scrub load threshold = 4
# 每次Scrub后强制休眠0.1秒
osd scrub sleep = 0.1
# 线程优先级
osd disk thread ioprio priority = 7
osd disk thread ioprio class = idle
9.5 强制unmap
如果Watcher被黑名单,则尝试Unmap镜像时会报错:rbd: sysfs write failed rbd: unmap failed: (16) Device or resource busy
可以使用下面的命令强制unmap: rbd unmap -o force ...
9.6 增加pg_num和pgp_num后无法A+C
部分PG状态卡死,可能原因是OSD允许的PG数量受限,修改全局配置项mon_max_pg_per_osd并重启MON即可。
此外注意:调整PG数量后,一定要进入A+C状态后,再进行下一次调整。
9.7 无法删除RBD镜像
下面第二个镜像对应的K8S PV已经删除:
rbd ls
# kubernetes-dynamic-pvc-35350b13-46b8-11e8-bde0-a2c14c93573f
# kubernetes-dynamic-pvc-78740b26-46eb-11e8-8349-e6e3339859d4
但是对应的RBD没有删除,手工删除:
rbd remove kubernetes-dynamic-pvc-78740b26-46eb-11e8-8349-e6e3339859d4
报错:
2018-04-23 13:37:25.559444 7f919affd700 -1 librbd::image::RemoveRequest: 0x5598e77831d0 check_image_watchers: image has watchers - not removing
Removing image: 0% complete…failed.
rbd: error: image still has watchers
This means the image is still open or the client using it crashed. Try again after closing/unmapping it or waiting 30s for the crashed client to timeout.
查看RBD状态:
# rbd info kubernetes-dynamic-pvc-78740b26-46eb-11e8-8349-e6e3339859d4
rbd image 'kubernetes-dynamic-pvc-78740b26-46eb-11e8-8349-e6e3339859d4':size 8192 MB in 2048 objectsorder 22 (4096 kB objects)block_name_prefix: rbd_data.1003e238e1f29format: 2features: layeringflags: create_timestamp: Mon Apr 23 11:42:59 2018#rbd status kubernetes-dynamic-pvc-78740b26-46eb-11e8-8349-e6e3339859d4
Watchers:watcher=10.0.0.101:0/4275384344 client.65597 cookie=18446462598732840963
到10.0.0.101这台机器上查看:
# df | grep e6e3339859d4
/dev/rbd2 8125880 251560 7438508 4% /var/lib/kubelet/plugins/kubernetes.io/rbd/rbd/rbd-image-kubernetes-dynamic-pvc-78740b26-46eb-11e8-8349-e6e3339859d4
重启Kubelet后可以删除RBD。
9.8 Error EEXIST: entity osd.9 exists but key does not match
# 删除密钥
ceph auth del osd.9
# 重新收集目标主机的密钥
ceph-deploy --username ceph-ops gatherkeys Carbon
9.9 创建新Pool后无法Active+Clean
pgs: 12.413% pgs unknown 20.920% pgs not active 768 active+clean 241 creating+activating 143 unknown
可能是由于PG总数太大导致,降低PG数量后很快Active+Clean
9.10 Orphaned pod无法清理
报错信息:Orphaned pod “a9621c0e-41ee-11e8-9407-deadbeef00a0” found, but volume paths are still present on disk : There were a total of 1 errors similar to this. Turn up verbosity to see them
临时解决办法:
rm -rf /var/lib/kubelet/pods/a9621c0e-41ee-11e8-9407-deadbeef00a0/volumes/rook.io~rook/
9.11 osd启动报错:ERROR: osd init failed: (1) Operation not permitted
可能原因是OSD使用的keyring和MON不一致。对于ID为14的OSD,将宿主机/var/lib/ceph/osd/ceph-14/keyring的内容替换为 ceph auth get osd.14的输出前两行即可。
9.12 Mount failed with ‘(11) Resource temporarily unavailable’
在没有停止OSD的情况下执行ceph-objectstore-tool命令,会出现此错误。
9.13 neither public_addr nor public_network keys are defined for monitors
通过ceph-deploy添加MON节点时出现此错误,将public_network配置添加到配置文件的global段即可。
9.14 journalctl删除pv后卡在Terminating
可能原因:
- 对应的PVC没有删除,还在引用此PV。先删除PV即可
chown: cannot access ‘/var/log/ceph’: No such file or directory
OSD无法启动,报上面的错误,可以配置:
ceph:storage:osd_log: /var/log
HEALTH_WARN application not enabled on
#池 # 功能
ceph osd pool application enable rbd block-devices
10. 诊断
调试日志
注意:详尽的日志每小时可能超过 1GB ,如果你的系统盘满了,这个节点就会停止工作。
10.1 临时启用调试日志
# 通过中心化配置下发
ceph tell osd.0 config set debug_osd 0/5# 到目标主机上,针对OSD进程设置
ceph daemon osd.0 config set debug_osd 0/5
10.2 配置日志级别
可以为各子系统定制日志级别
# debug {subsystem} = {log-level}/{memory-level}[global]debug ms = 1/5
[mon]debug mon = 20debug paxos = 1/5debug auth = 2
[osd]debug osd = 1/5debug filestore = 1/5debug journal = 1debug monc = 5/20
[mds]debug mds = 1debug mds balancer = 1debug mds log = 1debug mds migrator = 1
子系统列表:
| 子系统 | 日志级别 | 内存日志级别 |
|---|---|---|
| default | 0 | 5 |
| lockdep | 0 | 1 |
| context | 0 | 1 |
| crush | 1 | 1 |
| mds | 1 | 5 |
| mds balancer | 1 | 5 |
| mds locker | 1 | 5 |
| mds log | 1 | 5 |
| mds log expire | 1 | 5 |
| mds migrator | 1 | 5 |
| buffer | 0 | 1 |
| timer | 0 | 1 |
| filer | 0 | 1 |
| striper | 0 | 1 |
| objecter | 0 | 1 |
| rados | 0 | 5 |
| rbd | 0 | 5 |
| rbd mirror | 0 | 5 |
| rbd replay | 0 | 5 |
| journaler | 0 | 5 |
| objectcacher | 0 | 5 |
| client | 0 | 5 |
| osd | 1 | 5 |
| optracker | 0 | 5 |
| objclass | 0 | 5 |
| filestore | 1 | 3 |
| journal | 1 | 3 |
| ms | 0 | 5 |
| mon | 1 | 5 |
| monc | 0 | 10 |
| paxos | 1 | 5 |
| tp | 0 | 5 |
| auth | 1 | 5 |
| crypto | 1 | 5 |
| finisher | 1 | 1 |
| reserver | 1 | 1 |
| heartbeatmap | 1 | 5 |
| perfcounter | 1 | 5 |
| rgw | 1 | 5 |
| rgw sync | 1 | 5 |
| civetweb | 1 | 10 |
| javaclient | 1 | 5 |
| asok | 1 | 5 |
| throttle | 1 | 1 |
| refs | 0 | 0 |
| compressor | 1 | 5 |
| bluestore | 1 | 5 |
| bluefs | 1 | 5 |
| bdev | 1 | 3 |
| kstore | 1 | 5 |
| rocksdb | 4 | 5 |
| leveldb | 4 | 5 |
| memdb | 4 | 5 |
| fuse | 1 | 5 |
| mgr | 1 | 5 |
| mgrc | 1 | 5 |
| dpdk | 1 | 5 |
| eventtrace | 1 | 5 |
10.3 加快日志滚动
如果磁盘空间有限,可以配置/etc/logrotate.d/ceph,加快日志滚动:
rotate 7
weekly
size 500M
compress
sharedscripts
然后设置定时任务,定期检查并清理:
30 * * * * /usr/sbin/logrotate /etc/logrotate.d/ceph >/dev/null 2>&1相关文章:

Ceph常见问题
1. CephFS问题诊断 1.1 无法创建 创建新CephFS报错Error EINVAL: pool ‘rbd-ssd’ already contains some objects. Use an empty pool instead,解决办法: ceph fs new cephfs rbd-ssd rbd-hdd --force1.2 mds.0 is damaged 断电后出现此问题。MDS进…...
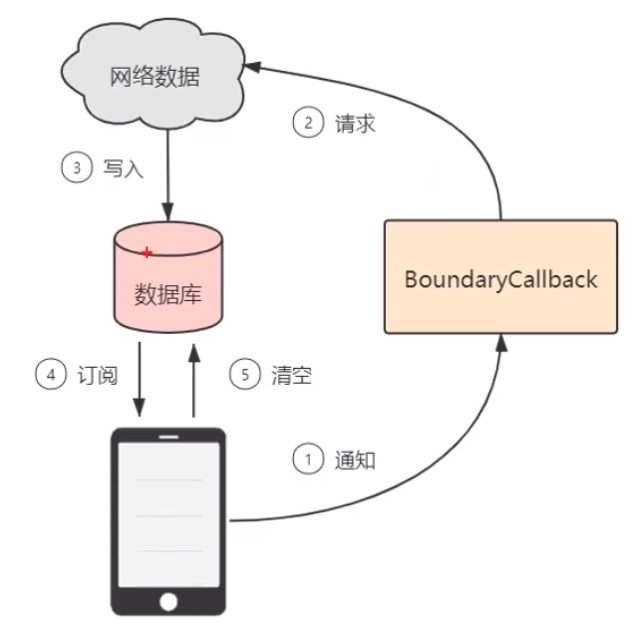
Android---Jetpack之Paging
目录 Paging 组件的意思 Paging 支持的架构类型 Paging 的工作原理 PositionalDataSource PagekeyedDataSource ItemKeyedDataSource BoundaryCallback Paging 组件的意思 分页加载是在应用程序开发过程中十分常见的需求,Paging 就是 Google 为了方便 Andr…...
 参数详解)
gensim.models.word2vec() 参数详解
1. Word2vec简介 Word2vec是一个用来产生词向量的模型。是一个将单词转换成向量形式的工具。 通过转换,可以把对文本内容的处理简化为向量空间中的向量运算,计算出向量空间上的相似度,来表示文本语义上的相似度。 2.Word2vec参数详解 class…...

光栅和矢量图像处理SDK:Graphics Mill 11.7Crack
Graphics Mill 是适用于 .NET 和 ASP.NET 开发人员的最强大的成像工具集。它允许用户轻松地向 .NET 应用程序添加复杂的光栅和矢量图像处理功能。 光栅图形 加载和保存 JPEG、PNG PSD 和其他 8 种图像格式 调整大小、裁剪、自动修复、色度键和 30 多种其他图像处理 使用任何维度…...

阿里云的客服 锻炼你心性的 一种方式 !!!
阿里云的产品,非常棒,开发的同学非常棒,专家们更棒,但,一切的开始就怕一个但字,但我还的说,但,阿里云的客服,OMG ,我已经忍耐了 1年了,是在忍不住…...

Linux常用的网络命令有哪些?快速入门!
在Linux系统中,有许多常用的网络命令可以用来进行网络配置和故障排除。这些命令可以帮助我们了解网络的状态和性能,并且可以快速诊断和解决网络问题。在本文中,我们将介绍一些常用的Linux网络命令,并提供一些案例来帮助您更好地理…...

PMP认证价值在哪?这个证书有什么用?
PMP证书是全球最权威的项目管理证书之一,获得该证书可以证明持证者具备高水平的项目管理知识和技能,拥有广泛的项目管理经验,并且符合全球项目管理行业的标准和规范。PMP证书的作用主要体现在以下几个方面: 1. 提升竞争力 在全球…...
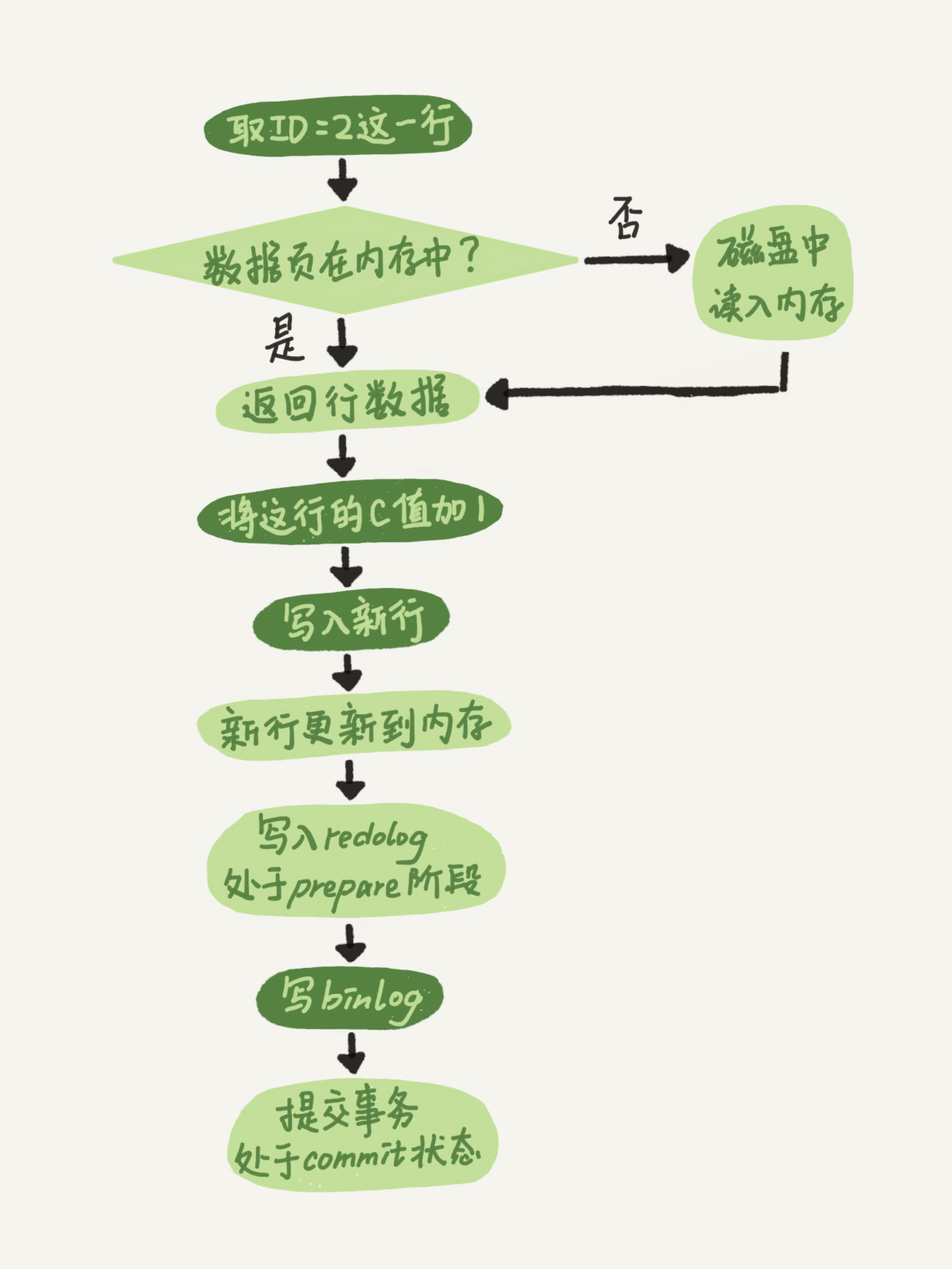
一条更新语句的执行流程又是怎样的呢?
当一个表上有更新的时候,跟这个表有关的查询缓存会失效,所以这条语句就会把表T上所有缓存结果都清空。这也就是我们一般不建议使用查询缓存的原因。 接下来,分析器会通过词法和语法解析知道这是一条更新语句。优化器决定要使用ID这个索引。然…...

promise异步编程指南
promise 是什么 Promise 是异步编程的一种解决方案,可以替代传统的解决方案–回调函数和事件。ES6 统一了用法,并原生提供了 Promise 对象。作为对象,Promise 有以下两个特点: (1)对象的状态不受外界影响。 (2)一旦状态改变了就不…...

20230411----重返学习-网易云音乐首页案例-git远程仓库
day-047-forty-seven-20230411-网易云音乐首页案例-git远程仓库 网易云音乐首页案例 事件委托 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><title>2.事件委托</title><style>.parent-box…...
Ansys Zemax | 模拟 AR 系统中的全息光波导:第二部分
AR 系统通常使用全息图将光耦合到波导中。本文展示了如何继续改进 本系列文章的第一部分 (点击查看)中建模的初步设计。(联系我们获取文章附件) 简介 AR 是一种允许屏幕上的虚拟世界与现实场景结合并交互的技术。 本文演示了如何…...

常用Git命令
整理了一些常用的git命令,备忘 查看仓库状态 git status查看提交记录 git log创建本地分支 git branch [branch name]创建远程分支 git push origin [branch name]查看本地分支 git branch -v查看远程分支 git branch -a切换分支 git checkout [branch name]查看远程…...

新手程序员被职场PUA的时候正确的化解姿势
新手程序员遇到了职场p u a 应该怎么办 最近我和有个粉丝聊天 他刚毕业进入了一家公司 就遭遇到了职场p u a 导致自己的自信心被打击 非常的痛苦 他是属于进入一家小公司 而这家公司的代码真的是非常的烂 他截图发了一段他目前 正在处理的代码给我 真的是太烂了 很多代码就是属…...
LINUX_kali学习笔记
基础命令 命令说明示例pwd查看当前路径ls查看当前文件夹下文件 .开头为隐藏文件 (文件夹下使用ctrlh查看)ls -a(查看文件及隐藏文件)ls -alh(查看文件及显示详情)cd切换目录cd /(切换到根目录&…...
第十天面试实战篇
目录 一、springboot的常用注解? 二、springmvc常用注解? 三、mysql的内连接和外连接有什么区别?比如有两张表:A和B内连接只返回两个表A和B的交集部分 四、redis分布式锁的缺点有哪些? 五、如何使用reddssion解决r…...

YML是一种数据存储格式
读取yml配置信息 Value("${province}") private String province; Value("${user.sname}") private String name1; Value("${user1[1].name}") private String name; Value("${server.port}") private int port; server:port: 8099 #…...

笔记:Java关于轻量级锁与重量级锁之间的问答
问题:如果在轻量级锁状态下出现锁竞争,不一定会直接升级为重量级锁,而是会先尝试自旋获取锁,那么有a b两个线程竞争锁,a成功获取锁了,b就一定失败,那么轻量级锁就一定升级为重量级锁,…...

有哪些通过PMP认证考试的心得值得分享?
回顾这100多天来艰辛的备考经历,感慨颇多 一,对于pmp的认知 百度百科:PMP(Project Management Professional)指项目管理专业人士(人事)资格认证。美国项目管理协会(PMI)举…...
【unity learn】【Ruby 2D】角色发射飞弹
前面制作了敌人的随机运动以及动画控制,接下来就是Ruby和Robot之间的对决了! 世界观背景下,小镇上的机器人出了故障,致使全镇陷入了危机,而Ruby肩负着拯救小镇的职责,于是她踏上了修复机器人的旅途。 之前…...
C++模板基础(九)
完美转发与 lambda 表达式模板 void f(int& input) {std::cout << "void f(int& input)\t" << input << \n; }void f(int&& input) {std::cout << "void f(int&& input)\t" << input << \n;…...

GEO建站系统选型避坑指南:如何识别真正有效的服务商
AI搜索渗透率的持续攀升,正在改变企业官网的战略地位。过去,官网是展示门面;现在,官网内容是否能被DeepSeek、豆包、通义千问等大模型理解和引用,直接影响企业在潜在客户第一次提问时能否出现在答案里。这种变化催生了…...

从Hive Metastore到HiveServer2:手把手教你配置生产级远程访问服务
从Hive Metastore到HiveServer2:生产级远程访问服务架构与实践 在大数据生态系统中,Hive作为数据仓库工具扮演着至关重要的角色。随着企业数据规模的增长,单机部署模式已无法满足多用户并发访问的需求。本文将深入探讨如何构建一个高可用、安…...

如何永久保存微信聊天记录?WeChatMsg让你轻松实现数据自主管理
如何永久保存微信聊天记录?WeChatMsg让你轻松实现数据自主管理 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/…...

终极音乐歌词获取指南:163MusicLyrics让你的每首歌都有完美字幕
终极音乐歌词获取指南:163MusicLyrics让你的每首歌都有完美字幕 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为音乐播放器缺少歌词而烦恼?…...
)
保姆级教程:用Node-RED把传感器数据传到ThingsBoard仪表盘(MQTT全流程)
从零构建物联网数据可视化:Node-RED与ThingsBoard的实战融合 在智能家居、工业监测等物联网场景中,如何将物理世界的传感器数据转化为直观的可视化图表?本文将手把手带您完成从硬件数据采集到云端展示的完整链路实现。不同于单纯的理论讲解&a…...

书匠策AI论文生存指南:降重降AIGC,2025届毕业生的“反内卷外挂“
🎬 开场:一场关于"论文能不能活着毕业"的生存实验 朋友们,今天咱不开学术讲座,咱开一场生存发布会。 2025年写毕业论文是什么体验?你辛辛苦苦码了两万字,满怀信心点了查重——好家伙࿰…...

WebPlotDigitizer完整指南:5步从图表图像中智能提取数据,科研效率提升90%
WebPlotDigitizer完整指南:5步从图表图像中智能提取数据,科研效率提升90% 【免费下载链接】WebPlotDigitizer Computer vision assisted tool to extract numerical data from plot images. 项目地址: https://gitcode.com/gh_mirrors/we/WebPlotDigit…...

Univer开源项目部署完整指南:从零到生产环境
Univer开源项目部署完整指南:从零到生产环境 【免费下载链接】univer Build AI-native spreadsheets. Univer is a full-stack framework for creating and editing spreadsheets on both web and server. With Univer Platform, Univer Spreadsheets is driven dir…...

STC32G单片机开发实战:GPIO模式配置与寄存器详解
1. STC32G单片机GPIO基础认知 第一次拿到STC32G开发板时,我习惯性地想用STM32那套HAL库来操作GPIO,结果发现根本行不通。这就像拿着汽车钥匙去开保险箱,虽然都是"开锁",但机制完全不同。STC32G作为增强型8051架构单片机…...
)
别再死记ResNet结构了!用PyTorch手把手带你复现ResNet-50(附完整代码与可视化)
从零构建ResNet-50:PyTorch实战与架构解密 当你第一次看到ResNet的残差连接时,是否曾被那个"跳跃"的结构所困惑?为什么简单的跨层连接就能解决深度网络的退化问题?本文将以工程师视角,带你用PyTorch从第一行…...