深度学习12. CNN经典网络 VGG16
深度学习12. CNN经典网络 VGG16
- 一、简介
- 1. VGG 来源
- 2. VGG分类
- 3. 不同模型的参数数量
- 4. 3x3卷积核的好处
- 5. 关于学习率调度
- 6. 批归一化
- 二、VGG16层分析
- 1. 层划分
- 2. 参数展开过程图解
- 3. 参数传递示例
- 4. VGG 16各层参数数量
- 三、代码分析
- 1. VGG16模型定义
- 2. 训练
- 3. 测试

一、简介
1. VGG 来源
VGG(Visual Geometry Group)是一个视觉几何组在2014年提出的深度卷积神经网络架构。
VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG19最为著名。
VGG16和VGG19网络架构非常相似,都由多个卷积层和池化层交替堆叠而成,最后使用全连接层进行分类。两者的区别在于网络的深度和参数量,VGG19相对于VGG16增加了3个卷积层和一个全连接层,参数量也更多。
VGG网络被广泛应用于图像分类、目标检测、语义分割等计算机视觉任务中,并且其网络结构的简单性和易实现性使得VGG成为了深度学习领域的经典模型之一。
本文参考内容:https://www.kaggle.com/code/blurredmachine/vggnet-16-architecture-a-complete-guide
2. VGG分类
下图中的D就是VGG16,E就是VGG19。
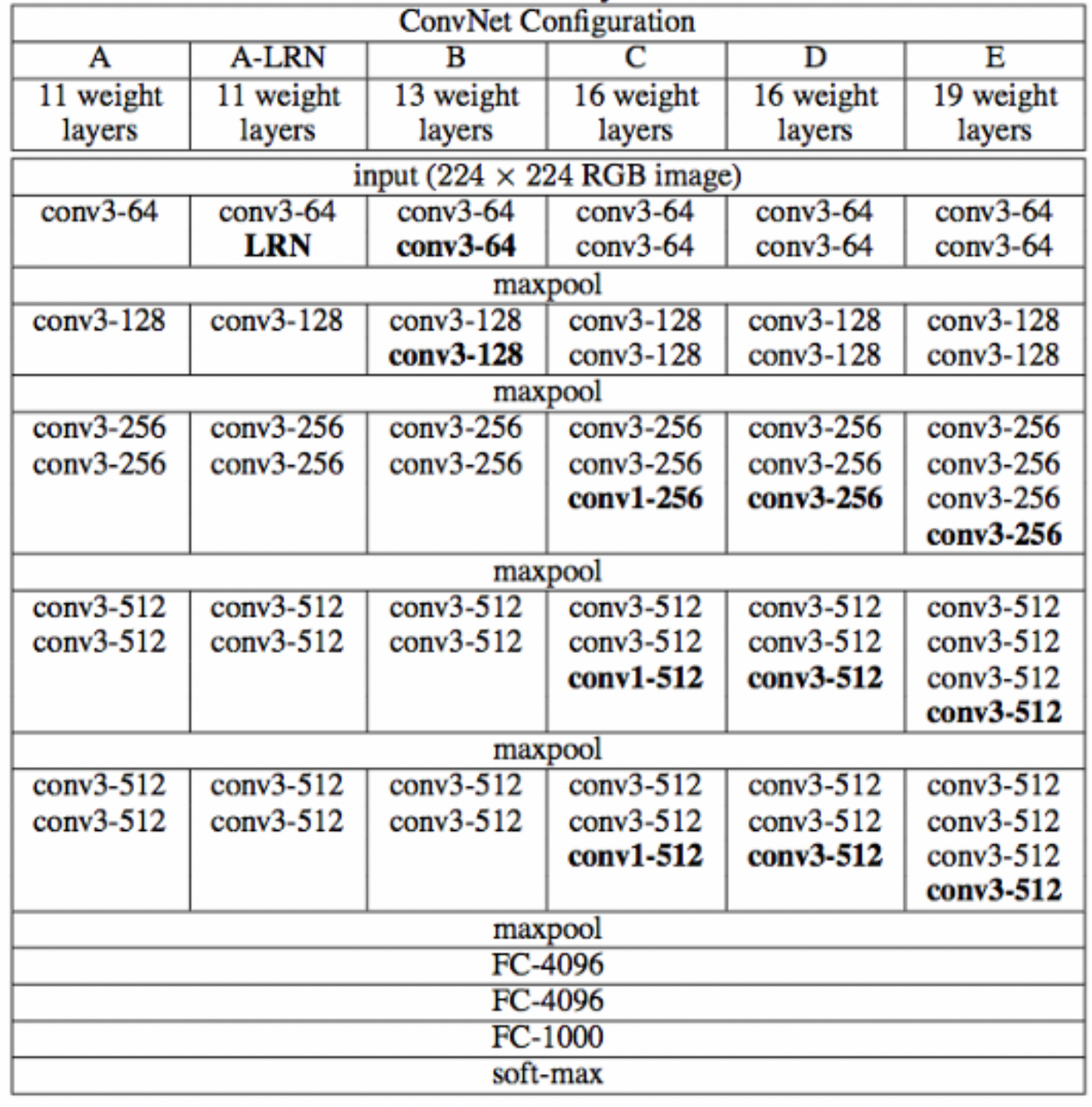
从图中看出,当层数变深时,通道数量会翻倍。
一些特点说明 :
- 每个模型分成了5个Block,所有卷积层采用的都是3x3大小的卷积核 ;
- 模型带LRN的,是加了LRN层;
- 使用 2x2 小池化核;
- 网络测试阶段将训练阶段的三个全连接替换为三个卷积;
- 测试重用训练时的参数,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入。
3. 不同模型的参数数量
单位:百万
| Network | A,A-LRN | B | C | D | E |
|---|---|---|---|---|---|
| 参数数量 | 133 | 133 | 134 | 138 | 144 |
VGG的参数数量非常大。
4. 3x3卷积核的好处
- 参数少: 一个3x3卷积核拥有9个权重参数,而一个5x5卷积核则需要25个权重参数,因此采用3x3卷积核可以大幅度减少网络的参数数量,从而减少过拟合的风险;
- 提高非线性能力: 多个3x3卷积核串联起来可以形成一个感受野更大的卷积核,而且这个组合具有更强的非线性能力。在VGG中,多次使用3x3卷积核相当于采用了更大的卷积核,可以提高网络的特征提取能力;
- 减少计算量: 一个3x3的卷积核可以通过步长为1的卷积操作,得到与一个5x5卷积核步长为2相同的感受野,但计算量更小(即2个3x3代替一个5x5);3个3x3代替一个7x7的卷积;因此,VGG网络采用多个3x3的卷积核,可以在不增加计算量的情况下增加感受野,提高网络的性能;
5. 关于学习率调度
学习率调度(learning rate scheduling)是优化神经网络模型时调整学习率的技术,它会随着训练的进行动态地调整学习率的大小。通过学习率调度技术,可以更好地控制模型的收敛速度和质量,避免过拟合等问题。
常用的学习率调度包括常数衰减、指数衰减、余弦衰减和学习率分段调整等。
本文将使用StepLR学习率调度器,代码示例:
schedule = optim.lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=0.5, last_epoch=-1)
optim.lr_scheduler.StepLR 是 PyTorch中提供的一个学习率调度器。这个调度器根据训练的迭代次数来更新学习率,当训练的迭代次数达到step_size的整数倍时,学习率会乘以gamma这个因子,即新学习率 = 旧学习率 * gamma。例如,如果设置了step_size=10和gamma=0.5,那么学习率会在第10、20、30、40…次迭代时变成原来的一半。
本文使用的 optimizer是SGD优化器。
6. 批归一化
nn.BatchNorm2d(256)是一个在PyTorch中用于卷积神经网络模型中的操作,它可以对输入的二维数据(如图片)的每个通道进行归一化处理。
Batch Normalization 通过对每批数据的均值和方差进行标准化,使得每层的输出都具有相同的均值和方差,从而加快训练速度,减少过拟合现象。nn.BatchNorm2d(256)中的256表示进行标准化的通道数,通常设置为输入数据的特征数或者输出数据的通道数。
在使用nn.BatchNorm2d(256)时,需要将其作为神经网络的一部分,将其添加进网络层中,位置是在卷积后、ReLU前,经过训练之后,每个卷积层的输出在经过BatchNorm层后都经过了归一化处理,从而使得神经网络的训练效果更加稳定。
二、VGG16层分析
1. 层划分
- 输入:224x224的RGB 彩色图像;
- block1:包含2个 [64x3x3] 的卷积层;
- block2:包含2个 [128x3x3] 的卷积层;
- block3:包含3个 [256x3x3] 的卷积层;
- block4:包含3个 [512x3x3] 的卷积层;
- block5:包含3个 [512x3x3] 的卷积层;
- 接着有3个全连接层;
- 一个分类输出层,经过 SoftMax 输出 1000个类的后验概率。
2. 参数展开过程图解
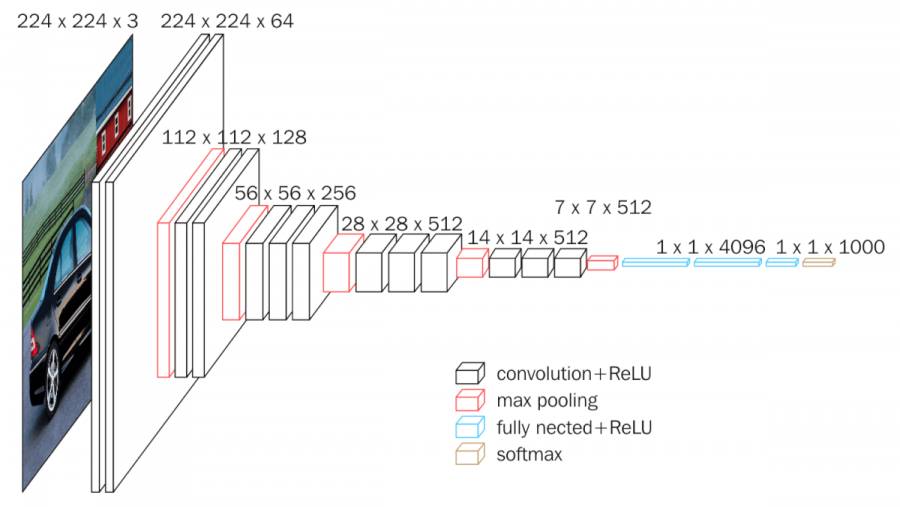
- 上图中神经网络划分了5个block;
- 红色:下采样 (Max Pooling);
- 白色:卷积层+ReLU;
- 蓝色:全连接+ReLU;
- 神经网络参数传递从左向右;
- 参数传递过程中,通道数越来越深,尺寸越来越小;
- 从7x7x512下采样后,参数被拉平为1x1的长向量,进入全连接层;
下图可以更清晰看出每个层的参数尺寸:
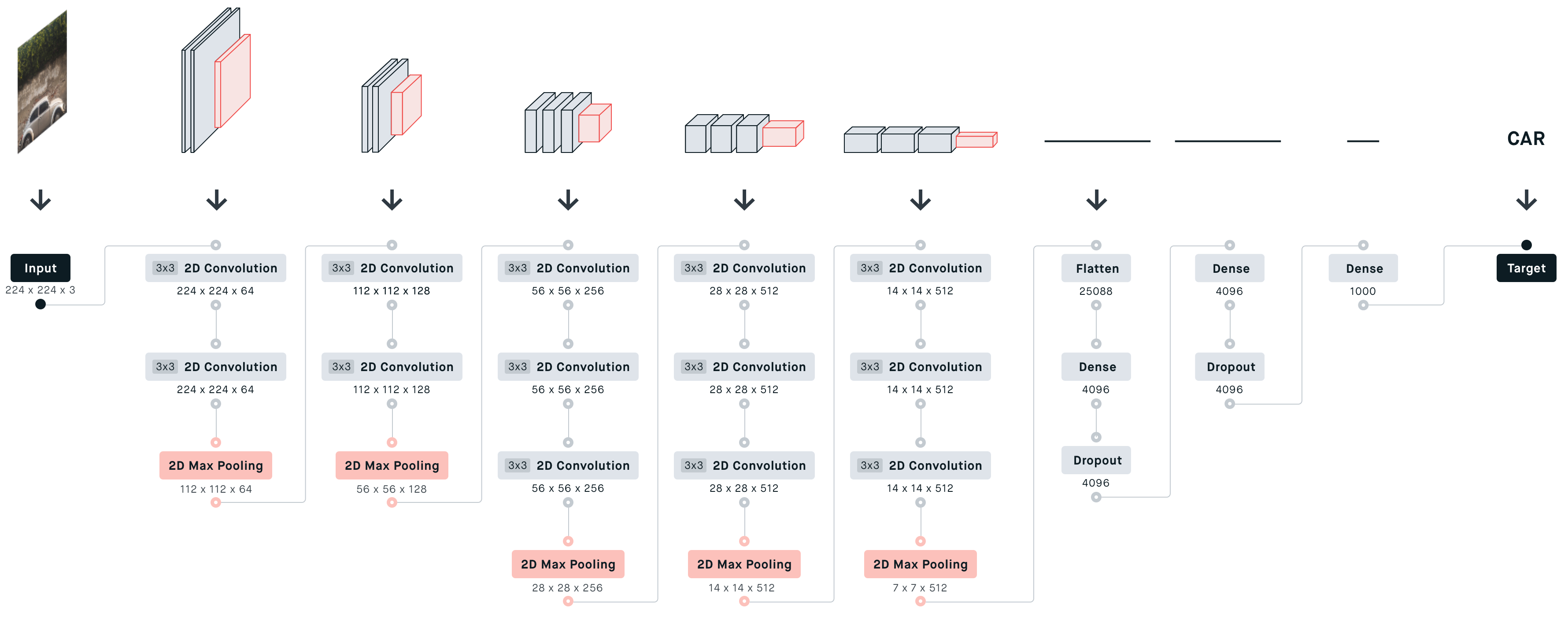
3. 参数传递示例
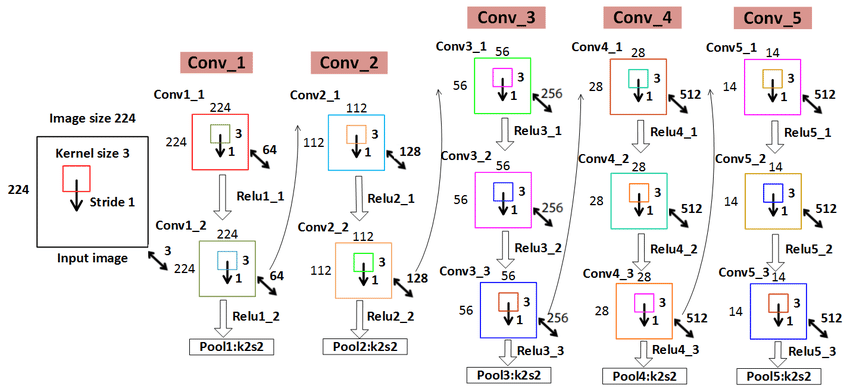
4. VGG 16各层参数数量
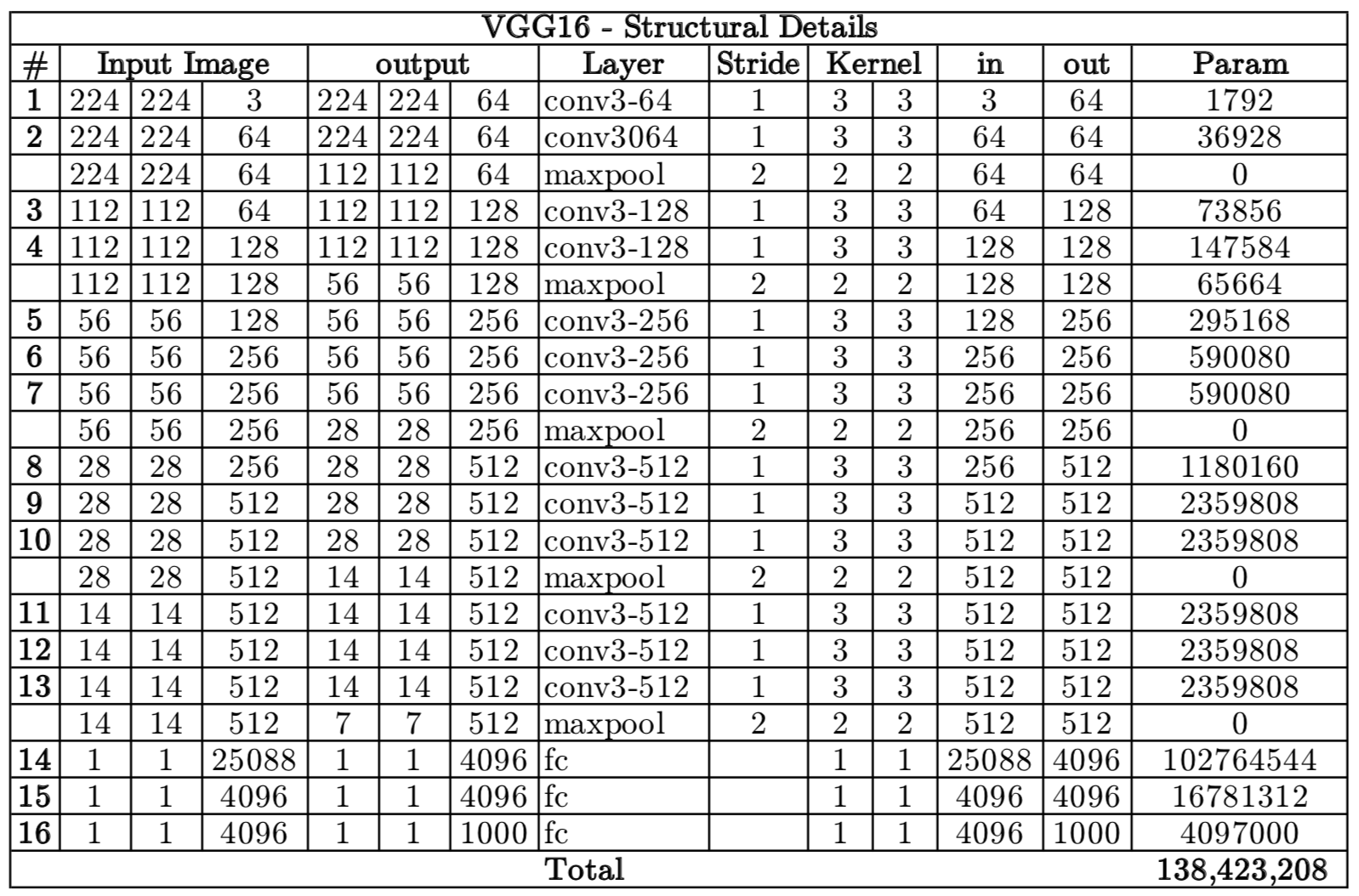
从图中可以看出,第一个全连接nfcr参数数量最多,达到了1亿多,这是因为前一个卷积层输出的向量在拉长成25088维向量,第一个全连接层4096要与25088相乘(每个神经元都要相连)。
三、代码分析
1. VGG16模型定义
import torch
from torch import nn, optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms# VGG16网络模型
class Vgg16_net(nn.Module):def __init__(self):super(Vgg16_net, self).__init__()# 第一层卷积层self.layer1 = nn.Sequential(# 输入3通道图像,输出64通道特征图,卷积核大小3x3,步长1,填充1nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1),# 对64通道特征图进行Batch Normalizationnn.BatchNorm2d(64),# 对64通道特征图进行ReLU激活函数nn.ReLU(inplace=True),# 输入64通道特征图,输出64通道特征图,卷积核大小3x3,步长1,填充1nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),# 对64通道特征图进行Batch Normalizationnn.BatchNorm2d(64),# 对64通道特征图进行ReLU激活函数nn.ReLU(inplace=True),# 进行2x2的最大池化操作,步长为2nn.MaxPool2d(kernel_size=2, stride=2))# 第二层卷积层self.layer2 = nn.Sequential(# 输入64通道特征图,输出128通道特征图,卷积核大小3x3,步长1,填充1nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),# 对128通道特征图进行Batch Normalizationnn.BatchNorm2d(128),# 对128通道特征图进行ReLU激活函数nn.ReLU(inplace=True),# 输入128通道特征图,输出128通道特征图,卷积核大小3x3,步长1,填充1nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),# 对128通道特征图进行Batch Normalizationnn.BatchNorm2d(128),nn.ReLU(inplace=True),# 进行2x2的最大池化操作,步长为2nn.MaxPool2d(2, 2))# 第三层卷积层self.layer3 = nn.Sequential(# 输入为128通道,输出为256通道,卷积核大小为33,步长为1,填充大小为1nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),# 批归一化nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2))self.layer4 = nn.Sequential(nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2))self.layer5 = nn.Sequential(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2))self.conv = nn.Sequential(self.layer1,self.layer2,self.layer3,self.layer4,self.layer5)self.fc = nn.Sequential(nn.Linear(512, 512),nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(512, 256),nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(256, 10))def forward(self, x):x = self.conv(x)# 对张量的拉平(flatten)操作,即将卷积层输出的张量转化为二维,全连接的输入尺寸为512x = x.view(-1, 512)x = self.fc(x)return x2. 训练
# 批大小
batch_size = 64
# 每n个batch打印一次损失
num_print = 100# 总迭代次数
epoch_num = 30
# 初始学习率
lr = 0.01
# 每n次epoch更新一次学习率
step_size = 10
# 更新学习率每次减半
gamma = 0.5def transforms_RandomHorizontalFlip():# 训练集数据增强:随机水平翻转、转换为张量、使用均值和标准差进行归一化transform_train = transforms.Compose([transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])# 测试集数据转换为张量、使用均值和标准差进行归一化transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.226, 0.224, 0.225))])train_dataset = datasets.CIFAR10(root='../path/cifar10', train=True, transform=transform_train, download=True)test_dataset = datasets.CIFAR10(root='../path/cifar10', train=False, transform=transform, download=True)return train_dataset, test_dataset# 随机翻转,获取训练集和测试集数据
train_dataset, test_dataset = transforms_RandomHorizontalFlip()
# 创建DataLoader用于加载训练集和测试集数据
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 创建Vgg16_net模型,并将其移动到GPU或CPU
model = Vgg16_net().to(device)
# 定义损失函数为交叉熵
criterion = nn.CrossEntropyLoss()
# 定义优化器为随机梯度下降,学习率为lr,动量为0.8,权重衰减为0.001
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.8, weight_decay=0.001)
# 定义学习率调度器,每step_size次epoch将学习率减半
schedule = optim.lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=gamma, last_epoch=-1)# 训练
loss_list = []# 每个epoch循环训练一遍
for epoch in range(epoch_num):# 当前迭代次数ww = 0# 累计损失值running_loss = 0.0# 遍历数据加载器,获取每个batchfor i, (inputs, labels) in enumerate(train_loader, 0):# 将数据和标签移动到GPU/CPU上inputs, labels = inputs.to(device), labels.to(device)# 梯度清零optimizer.zero_grad()# 输入数据进行前向传播,行到预测结果outputs = model(inputs)# 计算损失loss = criterion(outputs, labels).to(device)# 反向传播,计算每个参数的梯度loss.backward()# 更新参数optimizer.step()# 累计损失值running_loss += loss.item()# 将损失值放到loss_listloss_list.append(loss.item())# 打印当前epoch的平均损失值if (i + 1) % num_print == 0:print('[%d epoch,%d] loss:%.6f' % (epoch + 1, i + 1, running_loss / num_print))running_loss = 0.0lr_1 = optimizer.param_groups[0]['lr']# 打印学习率print("learn_rate:%.15f" % lr_1)schedule.step()
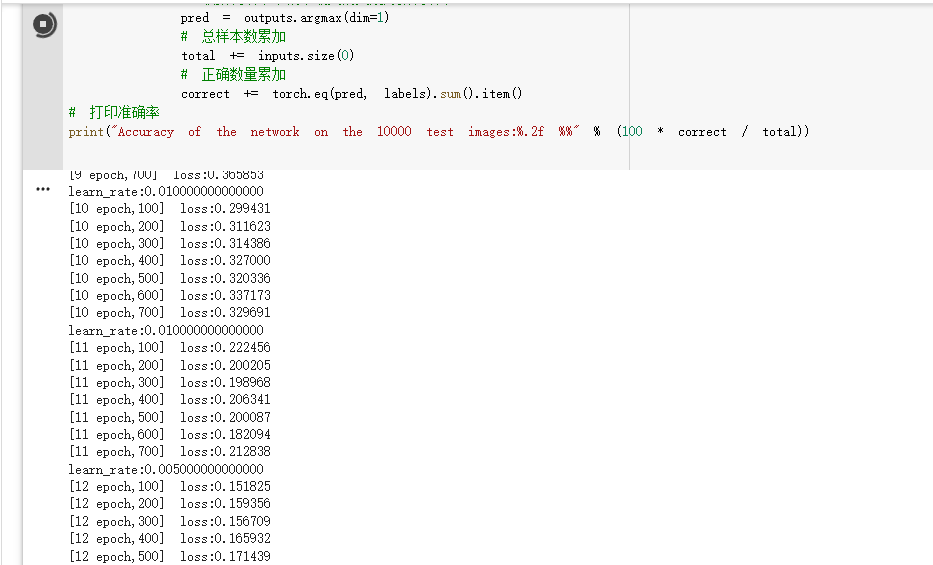
3. 测试
# 测试
model.eval()
# 记录分类正确的样本数和总样本数
correct = 0.0
total = 0
with torch.no_grad():for inputs, labels in test_loader:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)# 取预测结果中概率最大的类别为预测结果pred = outputs.argmax(dim=1)# 总样本数累加total += inputs.size(0)# 正确数量累加correct += torch.eq(pred, labels).sum().item()
# 打印准确率
print("Accuracy of the network on the 10000 test images:%.2f %%" % (100 * correct / total))运行示例:
相关文章:
深度学习12. CNN经典网络 VGG16
深度学习12. CNN经典网络 VGG16 一、简介1. VGG 来源2. VGG分类3. 不同模型的参数数量4. 3x3卷积核的好处5. 关于学习率调度6. 批归一化 二、VGG16层分析1. 层划分2. 参数展开过程图解3. 参数传递示例4. VGG 16各层参数数量 三、代码分析1. VGG16模型定义2. 训练3. 测试 一、简…...

Doris(3):创建用户与创建数据库并赋予权限
Doris 采用 MySQL 协议进行通信,用户可通过 MySQL client 或者 MySQL JDBC连接到 Doris 集群。选择 MySQL client 版本时建议采用5.1 之后的版本,因为 5.1 之前不能支持长度超过 16 个字符的用户名。 1 创建用户 Root 用户登录与密码修改 Doris 内置 r…...
深入浅出 Golang 内存管理
了解内存管理~ 前言: 本节课主要介绍了内存管理知识与自动内存管理机制,并对目前 Go 内存管理过程中存在的问题提出了解决方案,同时结合了上次课程学习的《Go 语言性能优化》相关知识,提供可行性的优化建议 … 自动内存管理 Go…...

基于Python的简单40例和爬虫详细讲解(文末赠书)
目录 先来看看Python40例 学习Python容易坐牢? 介绍一下什么是爬虫 1、收集数据 2、爬虫调研 3、刷流量和秒杀 二、爬虫是如何工作的? 三、爬虫与SEO优化 什么是python爬虫 Python爬虫架构 最担心的问题 本期送书 随着人工智能以及大数据的兴起…...

Vector - CAPL - CAN x 总线信息获取(续2)
继续.... 目录 ErrorFrameCount -- 错误帧数量 代码示例 ErrorFrameRate -- 错误帧速率 代码示例 ExtendedFrameCount -- 扩展帧数量 代码示例 ExtendedFrameRate -- 扩展帧速率 代码示例 ExtendedRemoteFrameCount -- 远程扩展帧数量 代码示例 ExtendedRemoteFrameRa…...

C++基础知识【8】模板
目录 一、什么是C模板? 二、函数模板 三、类模板 四、模板特化 五、模板参数 六、可变模板参数 七、模板元编程 八、嵌套模板 九、注意事项 一、什么是C模板? C模板是C编程中非常重要的一部分,它允许程序员以一种通用的方式编写代码…...
MAC-安装Java环境、JDK配置、IDEA插件推荐
背景:发现经常换电脑装环境等比较麻烦,主要还是想记录一下,不要每次安装都到处翻。。 1、下载并安装JDK 到官网下载所需的JDK:https://www.oracle.com/technetwork/java/javase/downloads/jdk11-downloads-5066655.html 这儿下…...

Mysql如何避免常见的索引失效
Mysql索引算是非常常用了,用得好提高效率,用的不好适得其反 如何避免常见的索引失效 1.模糊查询 使用 LIKE 查询时,如果搜索表达式以通配符开头,如 %value,MySQL 就无法使用索引来加速查询,因为它无法倒序…...
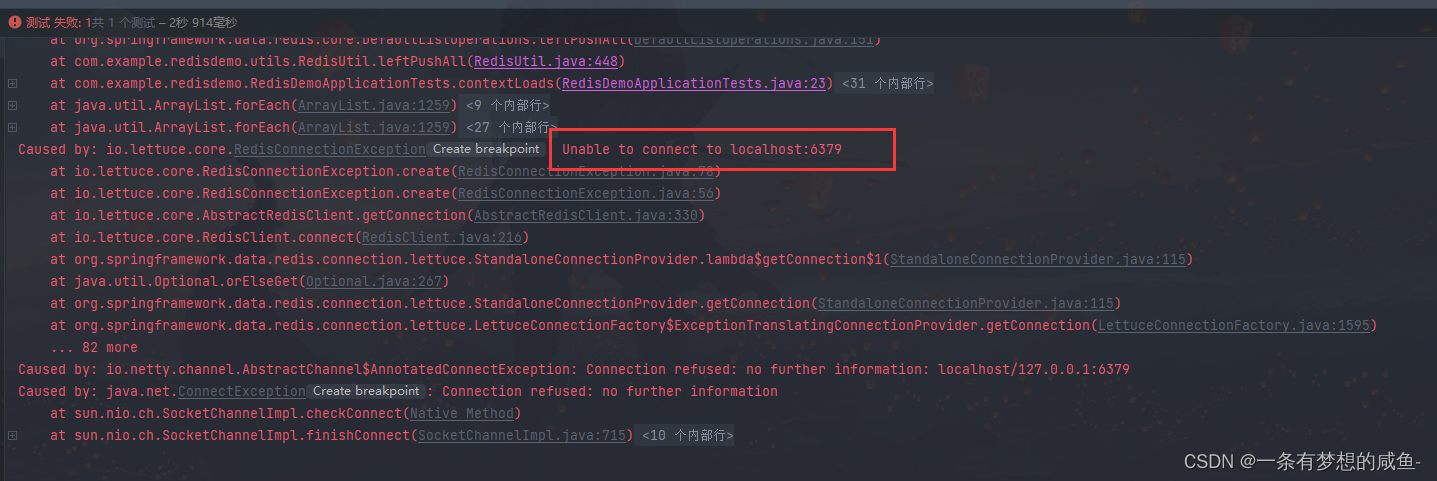
SpringBoot集成Redis及问题解决
SpringBoot集成Redis 此篇文章为SpringBoot集成Redis的简单介绍,依赖、序列化操作、工具类都可以在后面的实操中直接搬运使用或者在此基础上进行改进使用 1、集成Redis 1.1、新建SpringBoot项目 新建项目这边就不一一介绍了,大家如果还有不会的可以自行…...

PyTorch 人工智能研讨会:6~7
原文:The Deep Learning with PyTorch Workshop 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关心…...

AI绘图设计师Stable Diffusion成为生产力工具(五):放大并修复老照片、马赛克照片、身份证件照
S:你安装stable diffusion就是为了看小姐姐么? I :当然不是,当然是为了公司的发展谋出路~~ 预先学习: 安装webui《Windows安装Stable Diffusion WebUI及问题解决记录》。运行使用时问题《Windows使用Stable Diffusion时…...

cubase正版下载安装包-cubase正版下载v1.2.0.69 软件激活版
cubase正版下载是一款实用的音乐创作类软件。我们可以通过这款软件实现创作音乐的自由,再也不用花大价钱请别人来帮忙制作,只需自己动动手就可以轻松完成我们所想要的,这款软件做到了让每一位热爱音乐的人都可以实现自己的梦想。 cubase正版…...
Python机器学习:支持向量机
这是我读本科的时候第一个接触到的机器学习算法,但也是第一个听完就忘的。。。 他的基本思想很简单:想办法把一个样本集划成两个部分:对于空间中的样本点集合,我们找到一个超平面把这个样本点集合给分成两个部分,其中…...

矩阵和线性代数的应用
矩阵和线性代数是数学中重要的概念,它们被广泛应用于物理、工程、计算机科学、经济学等众多领域。本文将讨论矩阵和线性代数的一些基本概念以及它们在实际应用中的重要性和影响。 一、矩阵和线性代数的基本概念 矩阵是由数字组成的矩形数组。它可以表示线性方程组…...

六:内存回收
内存回收: 应用程序通过 malloc 函数申请内存的时候,实际上申请的是虚拟内存,此时并不会分配物理内存。 当应用程序读写了这块虚拟内存,CPU 就会去访问这个虚拟内存, 这时会发现这个虚拟内存没有映射到物理内存&…...

【cpolar 内网穿透】Openwrt 软路由实现内网穿透
cpolar 是一种安全的内网穿透云服务,它将内网下的本地服务器通过安全隧道暴露至公网。使得公网用户可以正常访问内网服务。 文章目录 前言一、上传 cpolar 安装包二、配置cpolar环境变量三、安装并配置 cpolar 服务3.1 安装 cpolar3.2 启动 cpolar3.3 进行其他配置 …...

Android 10.0 Camera2 拍照功能默认选前摄像头
1.概述 在10.0的系统产品开发中,对于app调用系统api来打开摄像头拍照的功能也是常有的功能,而拍照一般是默认打开后置摄像头拍照的,由于 客户的产品特殊要求,需要打开前置摄像头拍照功能,所以需要了解拍照功能的流程,然后修改默认前置摄像头打开拍照功能就可以了 app调…...
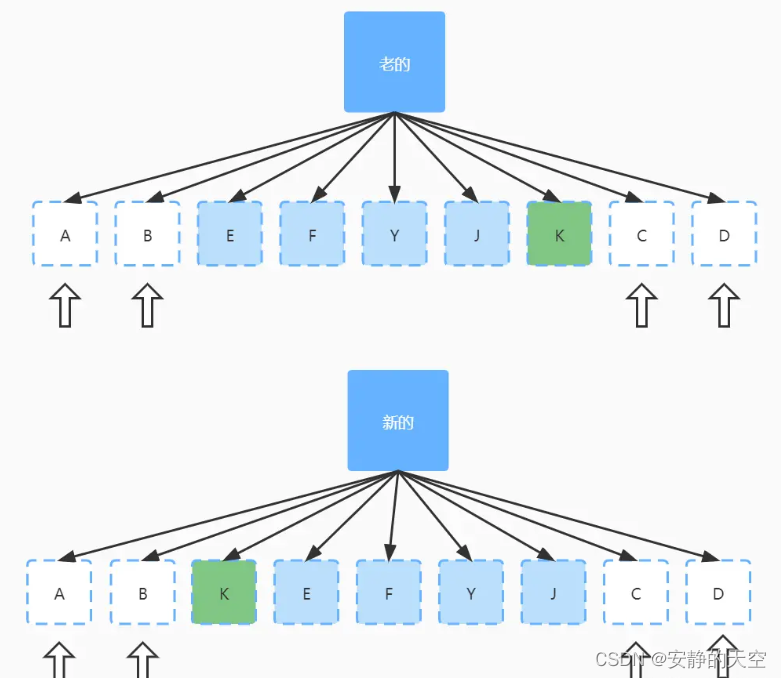
vue-vue2和vue3的diff算法
核心要点 数据变化时,vue如何更新节点虚拟DOM 和 真实DOM 的区别vue2 diff 算法vue3 diff 算法 一、 数据变化时,vue如何更新节点 首先渲染真实DOM的开销是很大,比如有时候我们修改了某个数据且修改的数据量很大时,此时会频繁的…...

一文解读基于PaddleSeg的钢筋长度超限监控方案
项目背景 钢铁厂生产钢筋的过程中会存在部分钢筋长度超限的问题,如果不进行处理,容易造成机械臂损伤。因此,需要通过质检流程,筛选出存在长度超限问题的钢筋批次,并进行预警。传统的处理方式是人工核查,该方…...
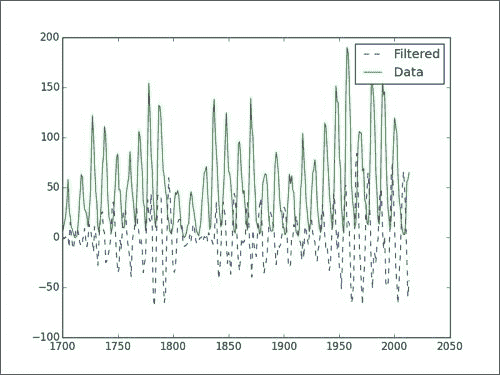
NumPy 数组学习手册:1~5
原文:Learning NumPy Array 协议:CC BY-NC-SA 4.0 译者:飞龙 一、NumPy 入门 让我们开始吧。 我们将在不同的操作系统上安装 NumPy 和相关软件,并查看一些使用 NumPy 的简单代码。 正如“序言”所述,SciPy 与 NumPy 密…...

数学科研效率提升300%,NotebookLM辅助建模全流程解析,含独家提示词矩阵与误差校验协议
更多请点击: https://intelliparadigm.com 第一章:NotebookLM数学研究辅助的范式革命 传统数学研究长期依赖纸笔推演、孤立文献查阅与手工公式验证,而NotebookLM通过其独特的“语义锚点双文档协同推理”机制,重构了从问题建模到定…...

Windows 11 下 flash-attention 高效部署:避坑指南与预编译版本实战
1. 为什么Windows 11需要flash-attention? 在深度学习领域,Transformer模型已经成为自然语言处理、计算机视觉等任务的主流架构。而flash-attention作为优化后的自注意力实现,能够显著提升模型训练和推理效率。对于Windows 11用户而言&#…...

为什么92%的戏剧研究生还没用上NotebookLM真正能力?——解锁其多源文本互文性推理的3个密钥
更多请点击: https://intelliparadigm.com 第一章:NotebookLM戏剧研究辅助的范式革命 传统戏剧研究长期依赖人工文本比对、手写批注与线性阅读,面对莎士比亚全集、元杂剧数百种版本、当代实验戏剧脚本等海量非结构化文本,知识提取…...

如何用Win11Debloat轻松优化Windows系统:完整指南
如何用Win11Debloat轻松优化Windows系统:完整指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custom…...
)
别再手动点选了!用Python脚本5分钟搞定Abaqus批量加载节点力(附完整代码)
Python自动化赋能Abaqus:高效批量加载节点力的工程实践 在有限元分析领域,Abaqus作为行业标杆软件,其强大的计算能力与灵活的二次开发接口深受工程师青睐。然而,当面对需要为数百甚至上千个节点分别施加不同载荷的复杂工况时&…...

如何快速打造专业直播画面:OBS StreamFX插件终极指南
如何快速打造专业直播画面:OBS StreamFX插件终极指南 【免费下载链接】obs-StreamFX StreamFX is a plugin for OBS Studio which adds many new effects, filters, sources, transitions and encoders! Be it 3D Transform, Blur, complex Masking, or even custom…...

C语言日志分级系统设计:从原理到工业级实现
1. 项目概述:为什么日志分级是C项目的“体检报告” 在C语言项目里,尤其是那些需要长期稳定运行的后台服务、嵌入式系统或者网络中间件,日志系统就是开发者的“眼睛”和“耳朵”。没有它,程序就像在黑箱里运行,一旦出问…...

深入解析Umi-OCR:开源离线OCR工具的技术架构与实践应用
深入解析Umi-OCR:开源离线OCR工具的技术架构与实践应用 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语…...

5分钟实现专业级3D高斯泼溅渲染:Unity场景重建终极指南
5分钟实现专业级3D高斯泼溅渲染:Unity场景重建终极指南 【免费下载链接】UnityGaussianSplatting Toy Gaussian Splatting visualization in Unity 项目地址: https://gitcode.com/gh_mirrors/un/UnityGaussianSplatting 想象一下,你花费数小时扫…...

掌握高效B站会员购抢票技巧:biliTickerBuy实战指南
掌握高效B站会员购抢票技巧:biliTickerBuy实战指南 【免费下载链接】biliTickerBuy b站会员购购票辅助工具 项目地址: https://gitcode.com/GitHub_Trending/bi/biliTickerBuy biliTickerBuy是一款专为B站会员购平台设计的开源抢票辅助工具,通过P…...