MySQL数据库,联合查询

目录
1. 联合查询
1.1 内查询
1.2 外查询
1.3 自连接
1.4 子查询
1.5 合并查询

1. 联合查询
联合查询,简单的来讲就是多个表联合起来进行查询。这样的查询在我们实际的开发中会用到很多,因此会用笛卡尔积的概念。
啥是笛卡尔积?两张表经过笛卡尔积后得到的新表的列数是两表列数之和,行数是两表行数之积。
我们可以看到下图中两表形成一个笛卡尔积后,把这两张表组成情况的所有的可能性都罗列出来了。因此会造成出现很多无用数据,这就是笛卡尔积的一个简单理解。因此,我们在查询两个表时得使用一些方法来避免类似于笛卡尔积这种情况的出现,这些方法的总称就是联合查询。
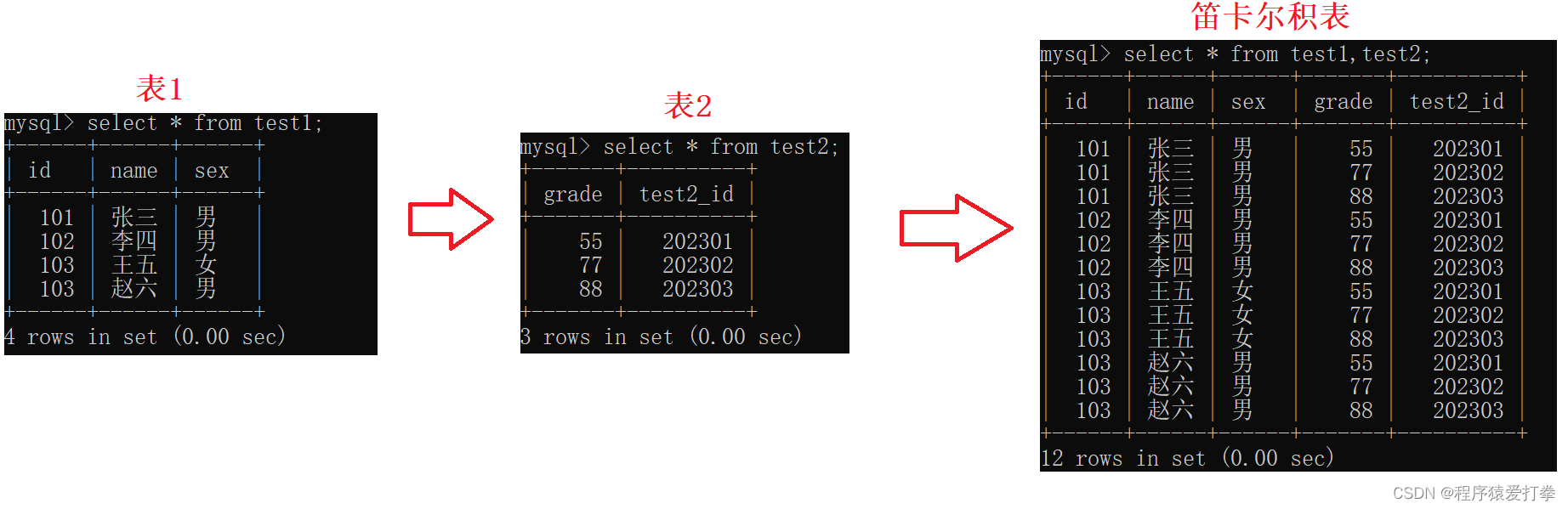
当然,上图两表中的数据没有任何关联,在此解释一下。
在我们进入联合查询的各个知识点讲解之前,我们先来创建几张表。下方的所有联合查询都是通过这几张表来进行演示的。
首先创建一个名为student的表作为学生表:
//创建student表
mysql> create table student(-> id int primary key auto_increment,-> sn varchar(20),-> name varchar(20),-> e_mail varchar(20),-> classes_id int-> );
Query OK, 0 rows affected (0.02 sec)//往student表中插入数据
mysql> insert into student(id,sn,name,e_mail,classes_id) values-> (1,23001,'阿三','asan@qq.com',1),-> (2,23005,'李四','lisi@qq.com',2),-> (3,23011,'王五',null,2),-> (4,23002,'赵六','zhaoliu@qq.com',2),-> (5,23015,'老八',null,1);
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0student表的内容为:

创建一个名为classes的表作为成绩表:
//创建表classes
mysql> create table classes(-> id int primary key auto_increment,-> name varchar(20),-> descr varchar(100)-> );
Query OK, 0 rows affected (0.02 sec)//往classes中插入数据
mysql> insert into classes(id,name,descr) values-> (1,'计算机专业','学习了C、Java、数据结构与算法'),-> (2,'医护专业','学习了康复相关知识');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0classe表的内容为:

创建一个名为course的表作为课程表:
//创建course表
mysql> create table course(-> id int primary key auto_increment,-> name varchar(20)-> );
Query OK, 0 rows affected (0.02 sec)//往course表中插入数据
mysql> insert into course(id,name) values-> (1,'Java'),-> (2,'英语'),-> (3,'数学'),-> (4,'中华传统文化'),-> (5,'摆烂');
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0course表的内容为:

创建一个名为score的表作为成绩表:
//创建一个score表
mysql> create table score(-> score int,-> student_id int,-> course_id int-> );
Query OK, 0 rows affected (0.02 sec)//插入相应的数据
mysql> insert into score(score,student_id,course_id) values-> (80,1,1),-> (60,1,2),-> (70,1,5),-> (66,2,4),-> (88,2,1),-> (99,3,5),-> (20,3,1),-> (78,4,4),-> (66,4,2),-> (89,4,1),-> (99,5,2),-> (77,5,3),-> (76,5,4);
Query OK, 13 rows affected (0.01 sec)
Records: 13 Duplicates: 0 Warnings: 0score表中的内容为:

通过上面创建的四张表,我们可以知道这几张表之间的联系。
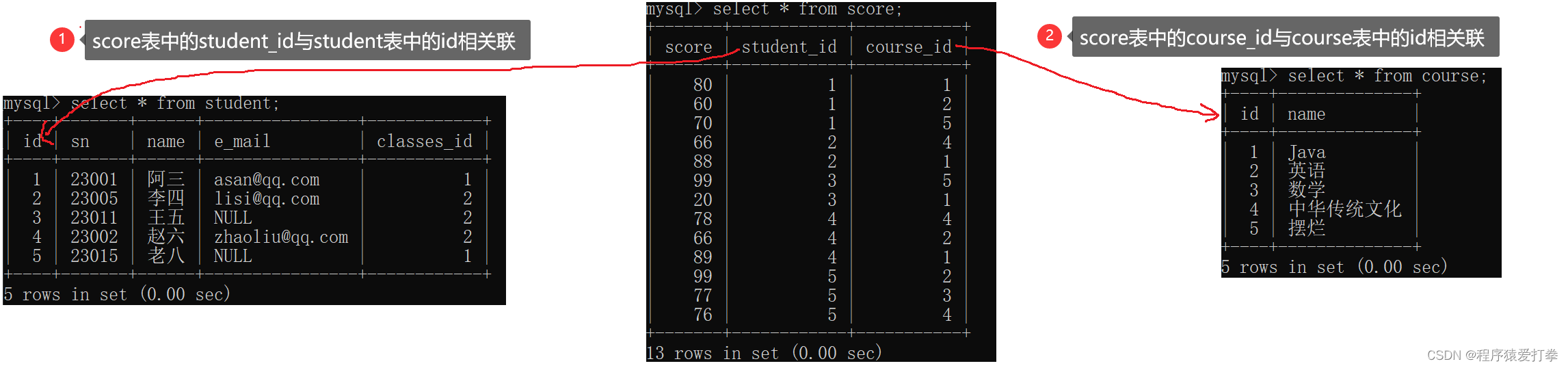
当然不止上图三表中之间有联系,student表中的classes_id与classes表中的id也是有关联。因此,这四张表之间都是相互关联的,那么我们就可以通过联合查询来操作相应的数据。
1.1 内查询
内查询是表与表之间通过一些内部相同数据的关联进行查询,因此当我们把需要查询的表进行笛卡尔积后,可以根据表之间内部相同的字段来作为连接条件从而筛选到要想的数据。内连接语法为:
- select 字段 from 表1 别名1 join 表2 别名2 on 连接条件 and 其他连接条件;
- select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他连接条件;
如果查我们要找名为阿三同学的成绩,这时就会使用到两张表:student、score。这两张表进行笛卡尔积后数据非常的冗杂:
mysql> select * from student,score;
足足有65行数据,我们要查找阿三的同学的成绩会使用到两个条件:第一个条件为name='阿三',第二个条件就是student.id = score.student_id。这样就能避免出现其他无效的数据。
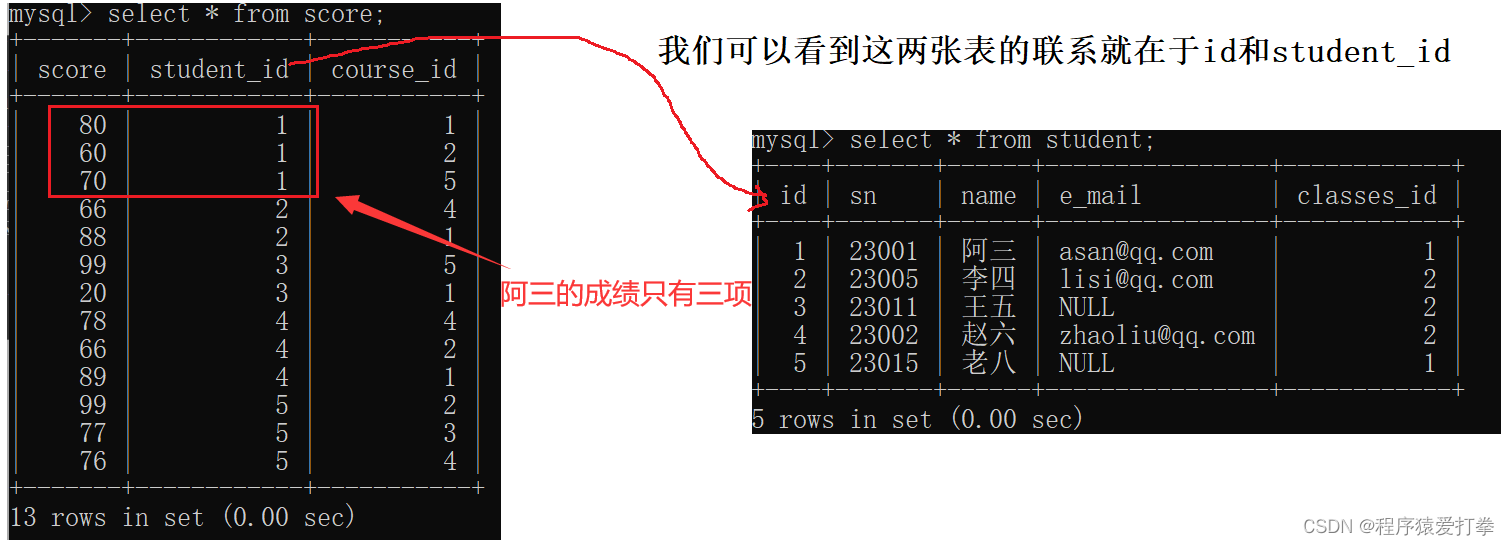
那么在对两张表进行笛卡尔积过后,我们有两种方式来进行查询阿三同学的成绩,第一种使用join on的方式进行查询:
mysql> select name,score from student join score on name='阿三' and student.id=score.student_id;
+------+-------+
| name | score |
+------+-------+
| 阿三 | 80 |
| 阿三 | 60 |
| 阿三 | 70 |
+------+-------+
3 rows in set (0.00 sec)第二种方式,使用where的方式进行查询:
mysql> select name,score from student,score where name='阿三' and student.id = score.student_id;
+------+-------+
| name | score |
+------+-------+
| 阿三 | 80 |
| 阿三 | 60 |
| 阿三 | 70 |
+------+-------+
3 rows in set (0.00 sec)通过上方代码之间的比较我们不难发现,join on和where这两种方式都能达到我们的目的,因此只要能掌握其中一种方式就能达到内查询的效果。注意,上述代码中我们可以通过.号来引用相关字段。当两张表中有相同字段name时我们可以通过表1.name来访问到表1中的name,通过表2.name来访问到表2中的name。
经过上方简单的程序相信大家已经对内查询有了初步的了解,下面我们来升级难度:查询所有同学的总成绩,及同学的个人信息。
首先我们要知道这些数据的来源于student和score这两张表,并且我们要得到student中的所有学生信息、score中的成绩总和,以及条件为student中的id等于score中的student_id。这样我们就可以写出以下代码:
mysql> select stu.id,stu.name,stu.e_mail,stu.classes_id,sum(sco.score)-> from student stu join score sco on stu.id=sco.student_id-> group by sco.student_id;
+----+------+----------------+------------+----------------+
| id | name | e_mail | classes_id | sum(sco.score) |
+----+------+----------------+------------+----------------+
| 1 | 阿三 | asan@qq.com | 1 | 210 |
| 2 | 李四 | lisi@qq.com | 2 | 154 |
| 3 | 王五 | NULL | 2 | 119 |
| 4 | 赵六 | zhaoliu@qq.com | 2 | 233 |
| 5 | 老八 | NULL | 1 | 252 |
+----+------+----------------+------------+----------------+
5 rows in set (0.00 sec)在上述代码中stu是student的别名,sco是score的别名。因此我们from前就可以使用这两个别名进行.操作来获取字段,但这种代码的可读性并不太高,建议使用原表名来获取字段而不是使用别名来获取字段。如将上方代码修改为使用表名来.引用字段:
select student.id,student.name,student.e_mail,student.classes_id,sum(score.score)from student join score on student.id = score.student_idgroup by score.student_id;1.2 外查询
那么在上述内查询的使用时,其实都是表之间的“内连接”,在MySQL中还有一种联合查询叫作“外连接”,也就是现在我们要学的外查询。
何为外查询,如在两张表中有一部分数据是有关联的另一部分数据是没有关联的,我们可以通过外查询把表1中不存在的数据或表2中不存的的数据通过外查询显示出来。有些抽象,下面我就用实例来讲解。外查询分为左外连接与右外连接,语法为:
- select 字段 from 表1 left join 表2 on 连接条件; --左外连接,表1完全显示
- select 字段 from 表1 right join 表2 on 连接条件; --右外连接,表2完全显示
在mytest数据库中创建两张表,student学生表和score课程表:
//创建名为mytest的数据库
mysql> create database mytest charset utf8;
Query OK, 1 row affected (0.00 sec)//使用该数据库
mysql> use mytest;
Database changed//创建学生表
mysql> create table student(-> id int,-> name varchar(10),-> sex varchar(10)-> );
Query OK, 0 rows affected (0.02 sec)
//插入对应数据
mysql> insert into student values-> (101,'张三','男'),-> (102,'李四','女'),-> (103,'王五','男');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0//创建成绩表
mysql> create table score(-> student_id int,-> score int-> );
Query OK, 0 rows affected (0.02 sec)
//插入相应数据
mysql> insert into score values (101,99),(102,89);
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0这两张表的内容为:
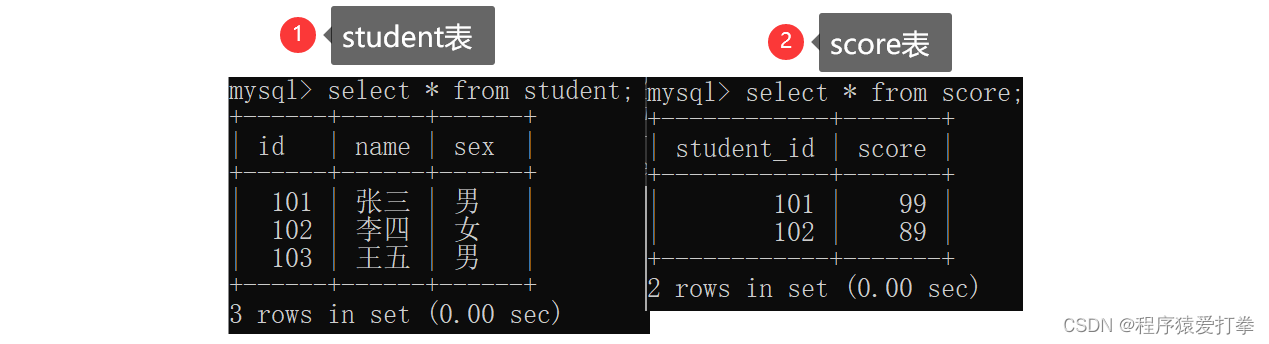
有一需求:查找这两张表的id,name,score这三条信息,要求为有效信息。当我们通过内连接,左外连接以及右外连接进行查询就会发现不同之处。
内连接查询:
mysql> select student.id,student.name,score.score from student join score on student.id = score.student_id;
+------+------+-------+
| id | name | score |
+------+------+-------+
| 101 | 张三 | 99 |
| 102 | 李四 | 89 |
+------+------+-------+
2 rows in set (0.00 sec)我们发现使用内连接进行查询得到的结果是正确的,关联性比较强。我们再来看左连接查询:
mysql> select student.id,student.name,score.score from student left join score on student.id = score.student_id;
+------+------+-------+
| id | name | score |
+------+------+-------+
| 101 | 张三 | 99 |
| 102 | 李四 | 89 |
| 103 | 王五 | NULL |
+------+------+-------+
3 rows in set (0.00 sec)通过上述代码我们发现,查询的结果并不有效。把score表中不存在的字段给查询出来了,我们可以把student和score这两张表看作两个数学里面的集合,这样就不难理解:
 当我们的连接条件为student.id=score.student_id时,我们通过左外连接时强制要得到左表也就是student表中的信息,那么student表中id为103的行中没有score值,此时就会显示null。右连接则不会出现这种情况:
当我们的连接条件为student.id=score.student_id时,我们通过左外连接时强制要得到左表也就是student表中的信息,那么student表中id为103的行中没有score值,此时就会显示null。右连接则不会出现这种情况:
mysql> select id,name,score from student right join score on student.id = score.student_id;
+------+------+-------+
| id | name | score |
+------+------+-------+
| 101 | 张三 | 99 |
| 102 | 李四 | 89 |
+------+------+-------+
2 rows in set (0.00 sec)因为右连接根据右表也就是score表进行查询,score表中关于id的信息有101和102因此通过条件为student.id=score.student_id进行查询后得到的结果也是存在的。
1.3 自连接
自连接是一种特殊情况下才使用的查询方式,它是一种取巧的查询方式,何为取巧?我们通过上方的内连接与外连接的学习知道了这两种都是表与表之间进行连接的,而自连接它是表自己和自己进行连接的,因此我认为它是取巧的一种方式。
如使用自连接查找Java成绩要大于摆烂成绩:
因为是自连接所以只能用到score这一张表。此外,我们需要知道Java成绩的课程id和摆烂成绩的课程id这样才能去比较它们的成绩。
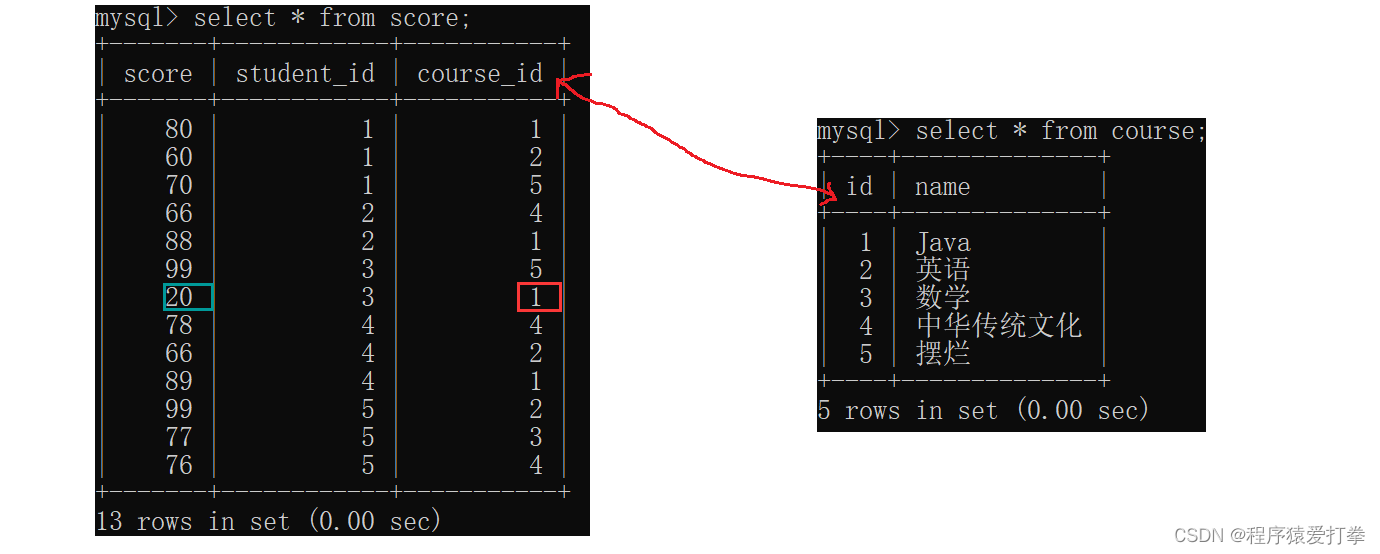
因此,我们可以写出以下代码:
mysql> select-> s1.*-> from-> score s1,-> score s2-> where-> s1.student_id = s2.student_id-> and s1.score<s2.score-> and s1.course_id = 1-> and s2.course_id = 5;
+-------+------------+-----------+
| score | student_id | course_id |
+-------+------------+-----------+
| 20 | 3 | 1 |
+-------+------------+-----------+
1 row in set (0.00 sec)当然,我们也可以使用join on方式来实现:
mysql> select-> s1.*-> from-> score s1-> join-> score s2-> on-> s1.student_id = s2.student_id-> and s1.score<s2.score-> and s1.course_id = 1-> and s2.course_id = 5;
+-------+------------+-----------+
| score | student_id | course_id |
+-------+------------+-----------+
| 20 | 3 | 1 |
+-------+------------+-----------+
1 row in set (0.00 sec)我们可以看到,Java小于摆烂的成绩只有一条。
1.4 子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询。什么意思呢,就是在查询一些数据的时候使用另一条select语句作为查询条件,从而达到特定的查询效果。
如查找老八及与同班级的学生,首先我们要查找student表中的所有信息,在where条件后面再加上条件。这个条件为classes_id=老八的classes_id,注意老八的classes_id可以使用另一条select语句来查询。因此可以写出以下代码:
mysql> select * from student where classes_id=(select classes_id from student where name = '老八');
+----+-------+------+-------------+------------+
| id | sn | name | e_mail | classes_id |
+----+-------+------+-------------+------------+
| 1 | 23001 | 阿三 | asan@qq.com | 1 |
| 5 | 23015 | 老八 | NULL | 1 |
+----+-------+------+-------------+------------+
2 rows in set (0.01 sec)使用in关键字也能做到嵌套查询这种效果,如查询与李四同班的同学信息:
mysql> select * from student where classes_id in (select classes_id from student where name = '李四');
+----+-------+------+----------------+------------+
| id | sn | name | e_mail | classes_id |
+----+-------+------+----------------+------------+
| 2 | 23005 | 李四 | lisi@qq.com | 2 |
| 3 | 23011 | 王五 | NULL | 2 |
| 4 | 23002 | 赵六 | zhaoliu@qq.com | 2 |
+----+-------+------+----------------+------------+
3 rows in set (0.00 sec)注意,in关键可以表示一个范围,只要是满足in()里面的内容就可以被查询出来,查询一个字段满足5,6,7这三个条件。则字段 in(5,6,7)即可。
1.5 合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用union和union all时,前后查询的结果集中,字段需要一致。
union操作符:
查找id<3并且name=摆烂的课程,我们会用到course表,使用两个select语句进行查询我们会使用union这个操作符进行连接,因此有以下代码:
mysql> select * from course where id < 3 union select * from course where name = '摆烂';
+----+------+
| id | name |
+----+------+
| 1 | Java |
| 2 | 英语 |
| 5 | 摆烂 |
+----+------+
3 rows in set (0.00 sec)或者我们使用or来实现:
mysql> select * from course where id < 3 or name = '摆烂';注意,使用union操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
union all操作符:
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。如查询id<3或者name='Java'的课程:
mysql> select * from course where id < 3 union all select * from course where name = 'Java';
+----+------+
| id | name |
+----+------+
| 1 | Java |
| 2 | 英语 |
| 1 | Java |
+----+------+
3 rows in set (0.00 sec)我们可以看到,重复被查询的Java字段出现了两次。
今天这篇博文内容比较丰富,大家下来了可以自行测试每个查询所实现的效果,只有自己尝试了并且实现了一些效果,这样才会更好的掌握这些知识点。

本期博文到这里就结束,感谢各位的阅读。
相关文章:
MySQL数据库,联合查询
目录 1. 联合查询 1.1 内查询 1.2 外查询 1.3 自连接 1.4 子查询 1.5 合并查询 1. 联合查询 联合查询,简单的来讲就是多个表联合起来进行查询。这样的查询在我们实际的开发中会用到很多,因此会用笛卡尔积的概念。 啥是笛卡尔积?两张表…...
)
springboot注解(全)
一、什么是Spring Boot Spring Boot是一个快速开发框架,快速的将一些常用的第三方依赖整合(通过Maven子父亲工程的方式),简化xml配置,全部采用注解形式,内置Http服务器(Jetty和Tomcat࿰…...
进制转换—包含整数和小数部分转换(二进制、八进制、十进制、十六进制)手写版,超详细
目录 1.进制转换必备知识: 1.1 二进制逢2进1 8进制逢8进1 10进制逢10进1 16进制逢16进1 1.2为了区分二、八、十、十六进制,我们通常在数字后面加字母进行区分 2. 二进制与八进制、十六进制相互转换 2.1 二进制转八进制 2.2 八…...

什么是UML?
文章目录 00 | 基础知识01 | 静态建模类图对象图用例图 02 | 动态建模时序图通信图状态图活动图 03 | 物理建模构件图部署图 UML(Unified Model Language),统一建模语言,是一种可以用来表现设计模式的直观的,有效的框图…...

5.3 Mybatis映射文件 - 零基础入门,轻松学会查询的select标签和resultMap标签
本文目录 前言一、创建XML映射文件二、MybatisX插件安装三、mapper标签四、select标签UserMapper接口方法UserMapper.xml 五、resultMap标签定义resultMap标签修改select标签 总结 前言 MyBatis的强大在于它的语句映射,它提供了注解和XML映射文件两种开发方式&…...
)
“华为杯”研究生数学建模竞赛2020年-【华为杯】B题:汽油辛烷值优化建模(附获奖论文和python代码实现)
目录 摘 要: 1 问题重述 1.1 问题背景 1.2 问题重述 2 模型假设 3 符号说明...

C6678开发概述与Sys/bios基本使用
C6678开发概述 参考开发环境标记及术语创建sys/bios自定义平台运行第一个sys/bios程序Clock模块使用Demo 参考 TMS320C6678 Multicore Fixed and Floating-Point Digital Signal Processor Datasheet TMS320C66x DSP CorePac User Guide 官方手册 创龙6678开发教程 开发环境 …...
)
python算法中的图算法之网络流算法(详解二)
目录 学习目标: 学习内容: 网络流算法 Ⅰ. 网络流模型 Ⅱ . Ford-Fulk...

企业电子招投标采购系统之项目说明和开发类型源码
项目说明 随着公司的快速发展,企业人员和经营规模不断壮大,公司对内部招采管理的提升提出了更高的要求。在企业里建立一个公平、公开、公正的采购环境,最大限度控制采购成本至关重要。符合国家电子招投标法律法规及相关规范,以及…...

ERTEC200P-2 PROFINET设备完全开发手册(8-1)
8.1 IRT通讯实验 这里我们使用APP3 IsoApp,修改源代码usrapp_cfg.h的宏为 #define EXAMPL_DEV_CONFIG_VERSION 3 使能App3,对应的主程序为“usriod_main_isoapp.c” 编译后下载运行。打开4.2建立的TIA项目,添加等时模式组织块,…...

手撕Twitter推荐算法
Twitter近期开源了其推荐系统源码[1,2,3],截止现在已经接近36k star。但网上公开的文章都是blog[1]直译,很拗口,因此特地开个系列系统分享下。系列涵盖: Twitter整体推荐系统架构:涵盖图数据挖掘、召回、精排、规则多…...

JAVA多态性测试的基本实验------JAVA入门基础教程
package duotai;public class Person {public void eat(){System.out.println("人吃饭");}public void Pdrink(){System.out.println("人喝水");} }package duotai;public class Man extends Person {public void eat(){System.out.println("男人吃饭…...

小说作者推荐: 妄鸦合集
《惊悚练习生》作品介绍 主人公叫弥赛亚,宗九的小说是《惊悚练习生》,它的作者是妄鸦倾心创作的一本现代耽美、娱乐圈、才女类型的小说,书中主要讲述了:作者:妄鸦 落魄魔术师宗九穿书了他穿到一本恐怖无限流选秀文里,…...

MySQL-自带工具介绍
目录 🍁mysql 🍁mysqladmin 🦐博客主页:大虾好吃吗的博客 🦐MySQL专栏:MySQL专栏地址 MySQL数据库不仅提供了数据库的服务器端应用程序,同时还提供了大量的客户端工具程序,如mysql&a…...

12个你应该知道的Python库
12个你应该知道的Python库 1. python命令行argparse 更简单的begins2. colorama改善命令行窗口3. pyqtgraph 它提供了不同的功能选择,尤其适用于实时和交互式可视化4. 网页浏览器Pywebview5. psutil 提供了完整的获取系统信息的方法 或许cpu近5s的基本报告6. Watchd…...

【数据分析之道-NumPy(七)】numpy字符串函数
文章目录 专栏导读1、函数说明2、add()函数3、multiply()函数4、center()函数5、capitalize()函数6、title()函数7、lower()函数8、upper()函数9、split()函数10、splitlines()函数11、strip()函数12、join()函数 专栏导读 ✍ 作者简介:i阿极,CSDN Pytho…...
【Linux】Linux基本指令(1)
一.前言 从这篇文章开始,博主就开启了Linux学习之路了,本篇文章也是博主的第一篇Linux的文章,今后也会持续不断更新的。 二.理解文件 1.文件 文件文件数据文件属性(所以一个建好的文件就算没有数据,也占用存储空间&am…...

更全面的对比GPT4和Claude对MLIR的掌握能力
本文构造了20个MLIR基础概念的问题以及使用OneFlow IR转换为Tosa IR的5个代码段来评测GPT4和Claude对于MLIR的掌握能力,我的结论是对于基础概念的理解Claude整体上和GPT4持平,而在阅读相关代码片段时Claude表现出了比GPT4更强一点的理解能力。 0x0. 前言…...
阿里ARouter 路由框架解析
一、简介 众所周知,在日常开发中,随着项目业务越来越复杂,项目中的代码量也越来越多,如果维护、扩展、解耦等成了一个非常头疼问题,随之孕育而生的诸如插件化、组件化、模块化等热门技术。 而其中组件化中一项的难点&…...
大型医院健康体检管理系统源码(PEIS)
一、体检管理系统(PEIS)概念 体检管理系统(PEIS)是以健康为中心的身体检查。一般医学家认为健康体检是指在身体尚未出现明显疾病时,对身体进行的全面检查。方便了解身体情况,筛查身体疾病。即应用体检手段对…...

避坑指南:uniapp在微信小程序中调用相机和人脸识别的权限与兼容性问题
Uniapp微信小程序相机与人脸识别开发避坑指南 微信小程序作为轻量级应用平台,其相机与人脸识别功能在金融、社交、教育等领域应用广泛。然而,当开发者使用Uniapp这一跨平台框架进行微信小程序开发时,往往会遇到各种兼容性和权限问题。本文将深…...

桌面CNC木质游戏手柄外壳制作:从Fusion 360设计到实战加工全流程
1. 项目概述:从数字模型到木质手柄的旅程如果你和我一样,既痴迷于复古游戏的怀旧情怀,又享受亲手将数字设计变为实体物件的成就感,那么这个项目绝对能点燃你的热情。我们这次要做的,不是一个简单的3D打印外壳ÿ…...

AI赋能安全分析:hexstrike-ai项目实战与提示词工程详解
1. 项目概述:一个为安全研究而生的AI助手如果你是一名安全研究员、逆向工程师或者渗透测试人员,那么你肯定对“工具链”这个词深有体会。我们的工作台就像是一个复杂的车间,摆满了IDA Pro、Ghidra、x64dbg、Burp Suite、Wireshark……这些工具…...

【Clickhouse从入门到精通】第03篇:ClickHouse适用场景深度剖析
上一篇【第02篇】ClickHouse横空出世——天下武功唯快不破 下一篇【第04篇】ClickHouse生态全景与生产实践者巡礼 摘要 技术选型是数据架构设计的核心命题。再优秀的工具,若用错了场景,也会事倍功半。ClickHouse 以"极速分析查询"著称&#x…...

提示工程实战:从核心模式到高级技巧的AI交互优化指南
1. 项目概述:从代码仓库到提示工程实战指南最近在GitHub上看到一个名为“SKY-lv/prompt-engineer”的仓库,点进去一看,发现这不仅仅是一个简单的代码集合,更像是一位资深从业者(SKY-lv)精心整理的提示工程实…...

嵌入式开发革命:LuatOS云编译实战指南与效率提升
1. 项目概述:为什么我们需要云编译?作为一名在嵌入式领域摸爬滚打了十多年的老鸟,我太懂那种“买板一时爽,环境火葬场”的痛了。尤其是这几年,合宙、乐鑫、兆易这些厂商的产品线越来越丰富,Air780E、ESP32-…...

ctfileGet:城通网盘直连地址解析工具的技术原理与实用指南
ctfileGet:城通网盘直连地址解析工具的技术原理与实用指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet ctfileGet是一个基于Web的开源工具,专门用于解析城通网盘分享链接并获…...

Arduino电机与舵机控制:从晶体管驱动到PWM调速实战
1. 项目概述与核心价值在机器人、智能小车或者任何一个需要“动起来”的嵌入式项目中,电机控制都是你绕不开的一道坎。你可能已经能让LED闪烁、让屏幕显示文字,但当你第一次尝试让一个小马达转起来,却发现Arduino板子上的引脚直接冒烟时&…...

支持 SSML 标签,让配音精准控制语调与重音
🎯 支持 SSML 标签,让配音精准控制语调与重音在文字转语音(TTS)应用中,机械感的读音往往缺乏情感。 顶伯文字转语音工具全面支持 SSML(语音合成标记语言) 标签,让您通过简单标记精准…...

【Midjourney Tea印相全链路解析】:从提示词工程到胶片质感渲染的7大隐性参数控制法则
更多请点击: https://intelliparadigm.com 第一章:Midjourney Tea印相的技术起源与美学范式 Midjourney Tea印相并非传统摄影工艺的简单复刻,而是融合生成式AI语义理解、茶渍拓印物理建模与东亚留白美学的一次跨媒介实验。其技术雏形可追溯至…...