更全面的对比GPT4和Claude对MLIR的掌握能力
本文构造了20个MLIR基础概念的问题以及使用OneFlow IR转换为Tosa IR的5个代码段来评测GPT4和Claude对于MLIR的掌握能力,我的结论是对于基础概念的理解Claude整体上和GPT4持平,而在阅读相关代码片段时Claude表现出了比GPT4更强一点的理解能力。
0x0. 前言
前面的文章中以Review一段MLIR相关的Pass代码为例子,对比了ChatGPT3.5,Claude,NewBing在该任务上的理解能力。我得出的结论是在该MLIR的相关任务上,Claude>ChatGPT3.5>>Newbing,评论区有人指出GPT4 >> Clude。我感觉上次的任务设计得不是特别好,并没有充分考察ChatGPT和Claude对MLIR的一些核心概念的理解。然后我今天借到了一个GPT4的官方账号 (daquexian 大老师提供的),我打算更全面的对比一下GPT4和Claude在对MLIR的掌握能力。接下来将从MLIR基础概念以及一个OneFlow IR转换为TOSA IR的任务出发,更全面的评价GPT4和Claude对于MLIR的掌握能力。
0x1. MLIR基础概念
Q1: MLIR中的IR是什么?为什么需要多层IR?
ChatGPT4的回答:
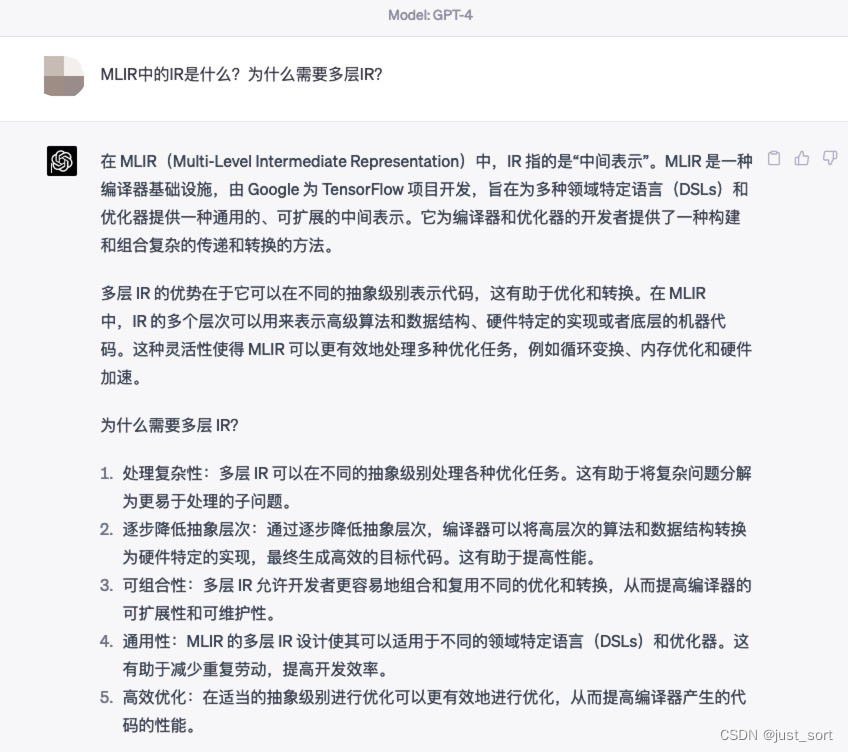
Claude回答:

对于MLIR中的IR是什么GPT4的回答更好一些,然后对于为什么需要多层IR这个问题Claude相比于GPT4更加细节一点。
Q2. 介绍一下MLIR Dialect的概念,并描述一下Dialect的相关组件。
GPT4:

Claude:

对于这个问题,GPT4的回答非常干净准确,而Claude虽然看起来更细节一些,但是总结得让人看起来很乱。
Q3: 在MLIR中如何定义和实现一个新的Dialect?
GPT4:
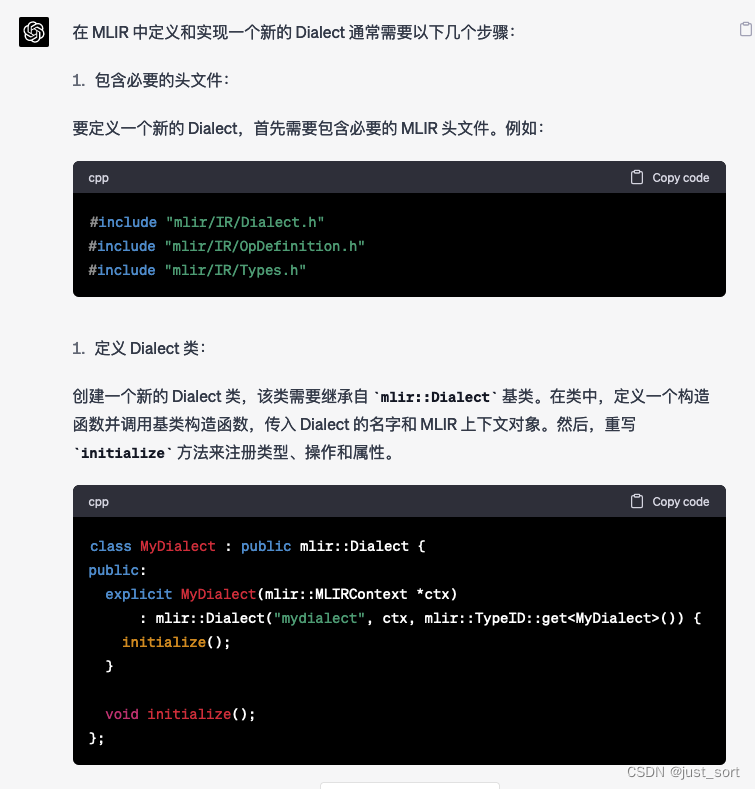
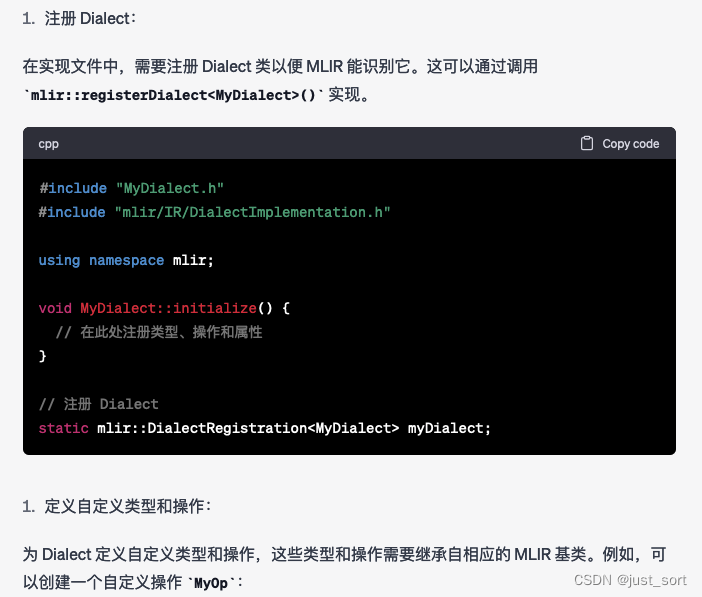
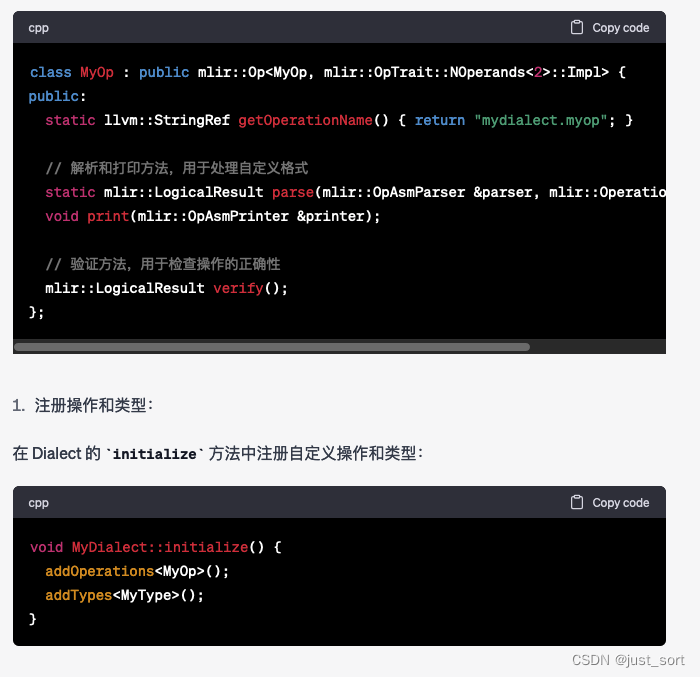


按照GPT4给出的步骤基本可以自定义一个Dialect以及相关的组件,不过现在一般对于Dialect以及Operation甚至Pass的定义都依靠了MLIR的ODS系统在相应的*.td文件中定义,并自动生成C++代码更加方便和通用。这里还可以发现GPT4在列举结果的时候,序号一直是1,并没有递增,不知道是不是BUG。
可以再看一下Claude的结果:


Claude的结果和GPT4的结果没有GPT4那么细节(比如GPT4把头文件的位置都列出来了),但是整体的步骤和GPT4基本一样,也算是比较好的理解了这个问题。
Q4: 介绍一下MLIR Dialect中的ModuleOp, FuncOp, Block
GPT4:
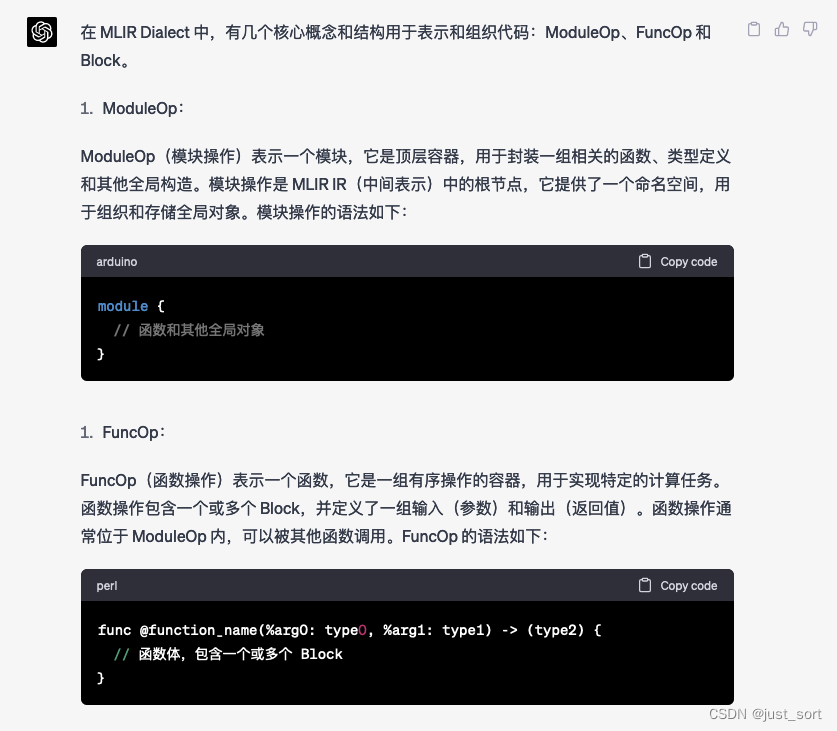
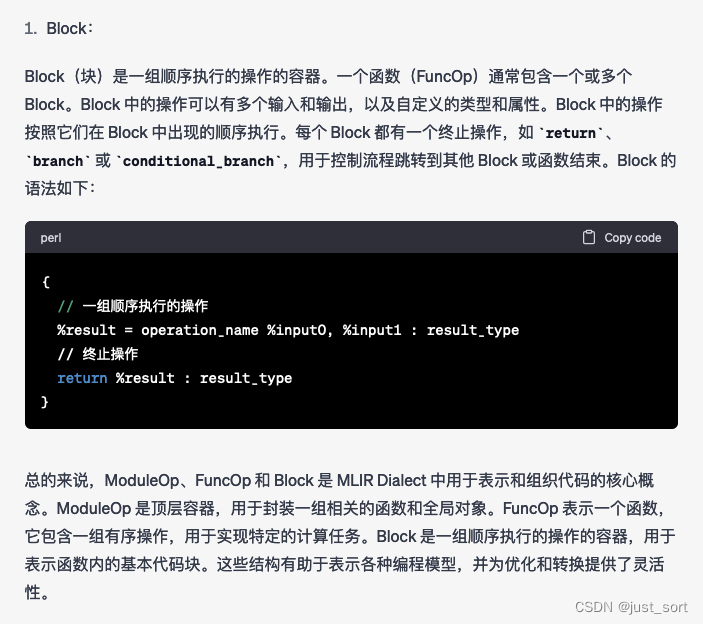
Claude:

GPT4的回答相比于Claude主要多了几个代码示例,但主体的内容两者是基本一样的。
Q5: 介绍一下MLIR Dialect中的Operation, Value, Type, Attribute
GPT4:


对概念的解释还是比较准确的,接下来看下Claude的结果:


对于这个问题,感觉Claude的回答是要比GPT4的回答好一点的。
为了进一步对比上述概念的理解,我们以MLIR的Toy Dialect示例中的transpose op定义为例,让GPT4和Claude分别详细解释下代码。
Q6: 详细解释下这行代码。%t_tensor = "toy.transpose"(%tensor) {inplace = true} : (tensor<2x3xf64>) -> tensor<3x2xf64> loc("example/file/path":12:1
GPT4:


Claude:


我们可以看到GPT4的源码分析更加细致,比如GPT4给我们解释了inplace的含义,但Claude并没有。
Q7:MLIR的Operation由Operation类和Op类的构成,请说一下它们的区别。 并说明一下ConstantOp和mlir::Operation *operation之间应该如何转换。
GPT4:

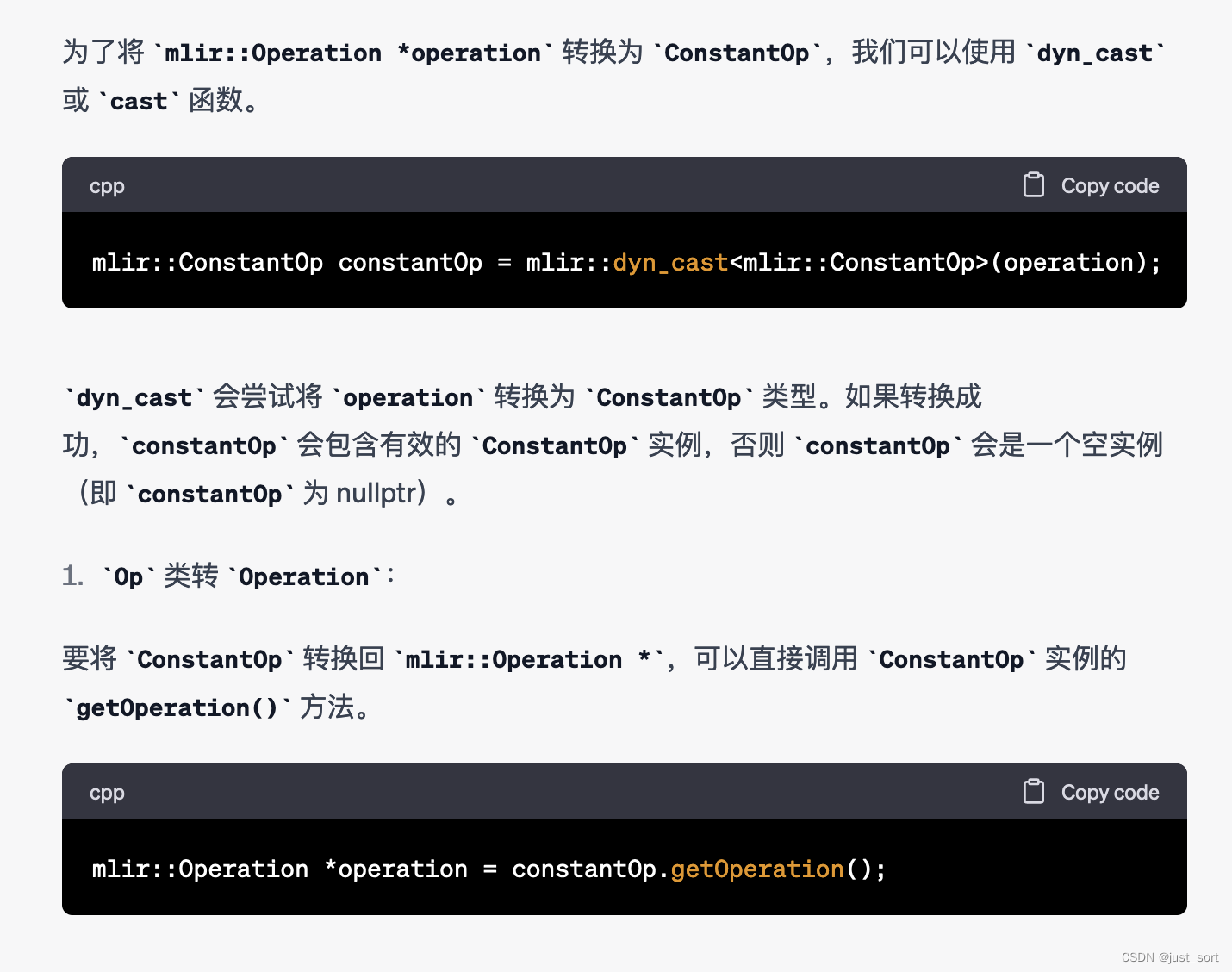

Claude:


GPT4和Claude的回答都还不错。
Q8:介绍一下MLIR Value的2个派生类BlockArgument和OpResult,并说明一下Value和mlir::Operantion *operation之间如何相互转换。

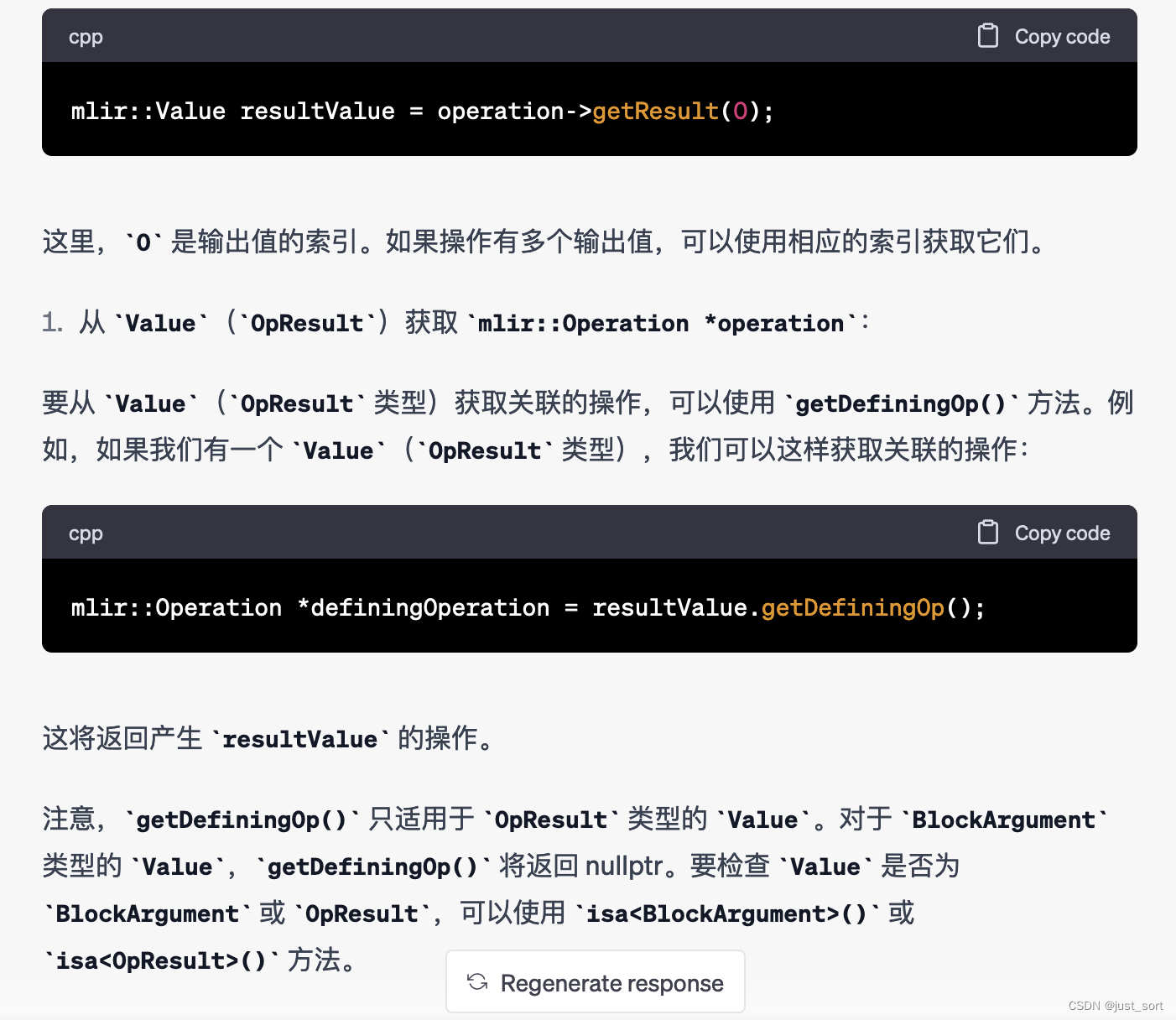

Claude:


对于Value的基础概念,GPT4和Claude都理解得不错。
Q9: 介绍一下mlir::Type,mlir::ShapedType以及mlir::TensorType
GPT4:


Claude:

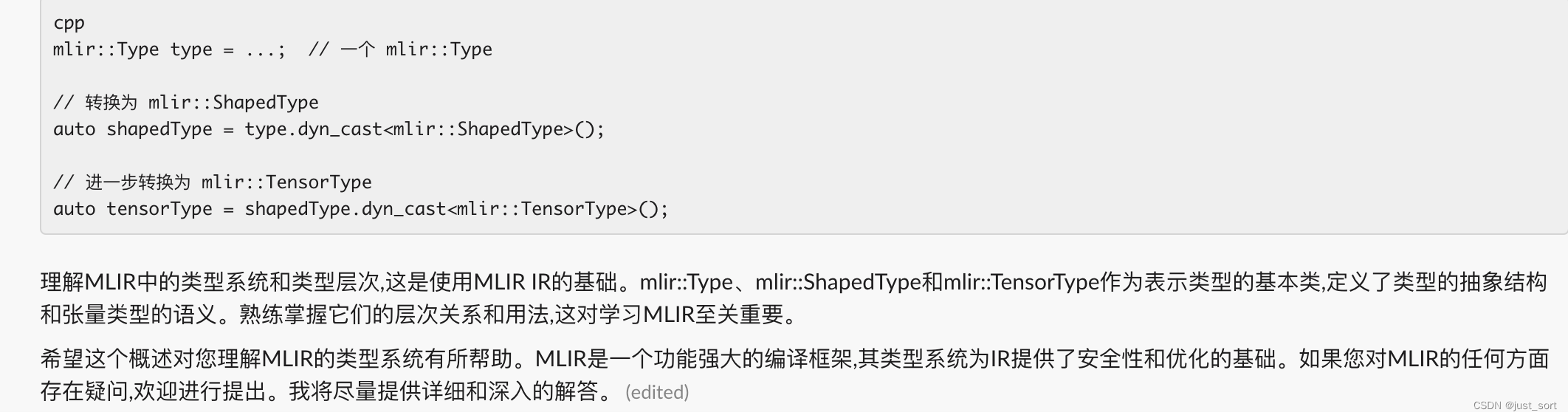
就这个回答来说,Claude的回答是超越了GPT4的。它不仅为我们解释了概念,还指出这三个Type的派生类之间应该如何转换。
Q10: TensorType又可以分成RankedTensorType和UnrankedTensorType,请说明一下它们的区别以及如何判断当前的TensorType是否是Ranked。
GPT4:


Claude:
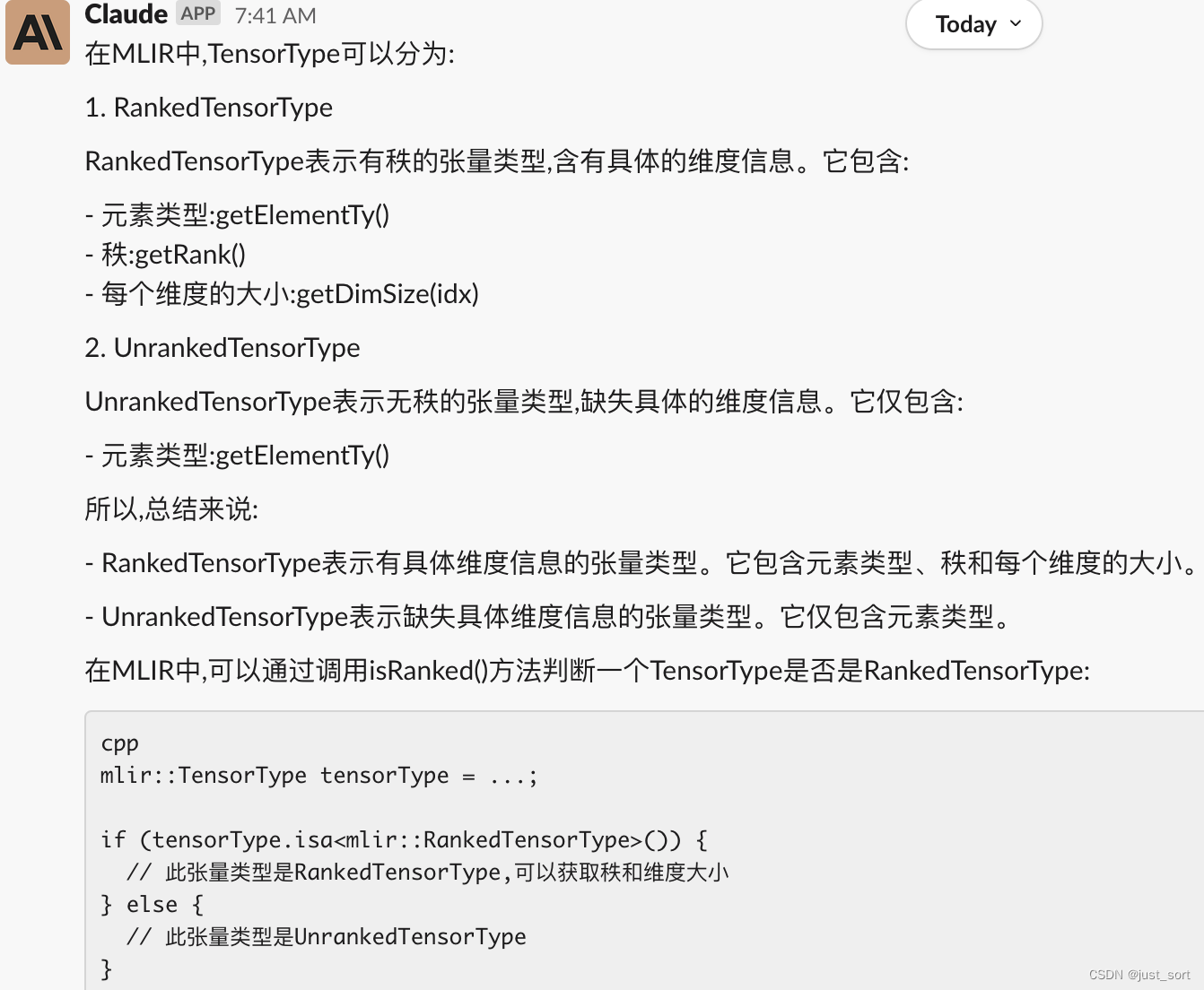

相比于GPT4,针对这个问题Claude的回答显得更好一点。主要好在它列出了RankedTensorType和UnrankedTensorType的主要成员函数并做了对比。
Q11: 介绍一下MLIR的Attribute
GPT4:


Claude:


对于Attribute的解释,我感觉Claude也是比GPT4好一点。
Q12:介绍一下MLIR的Builder和OpBuilder。
GPT4:
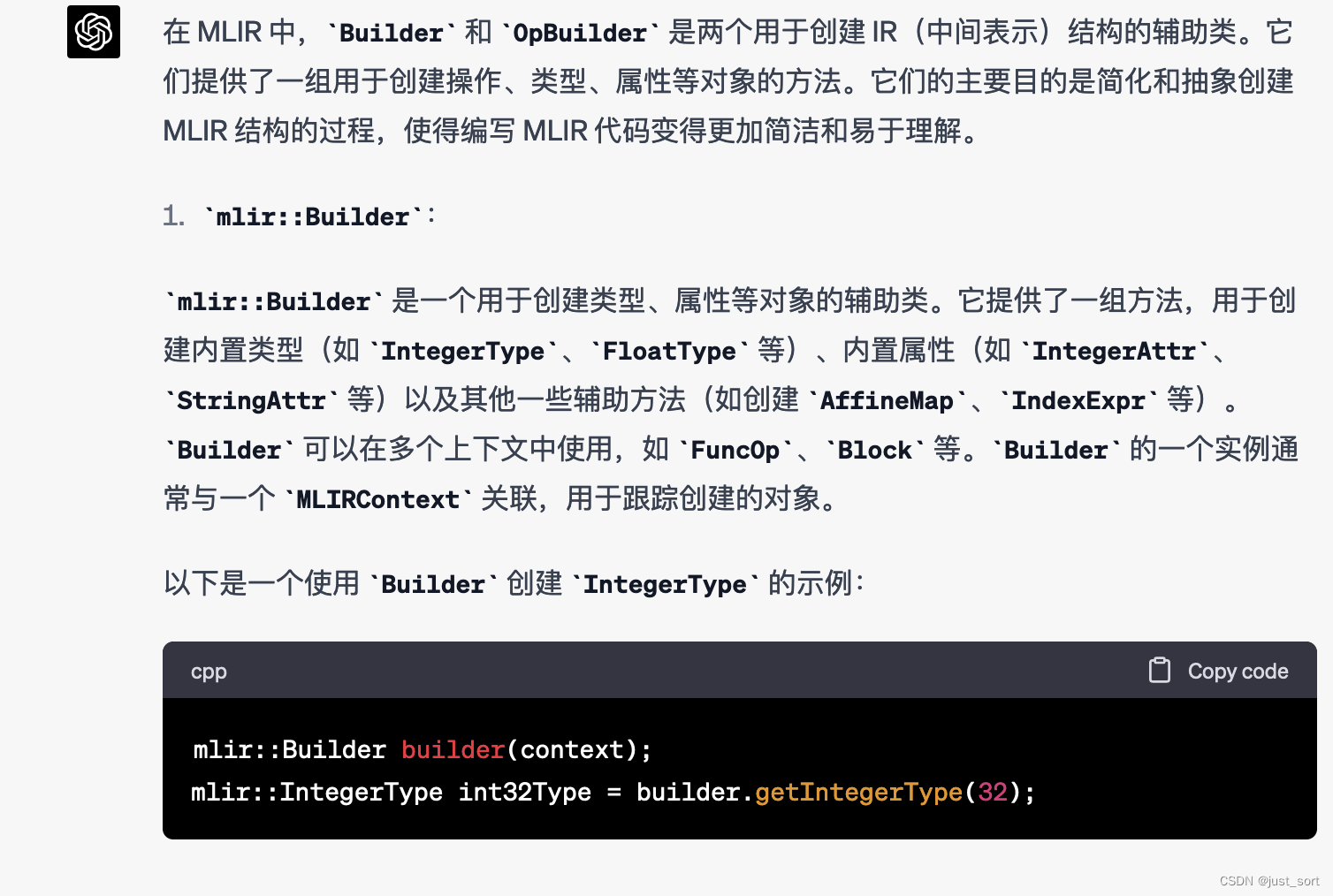
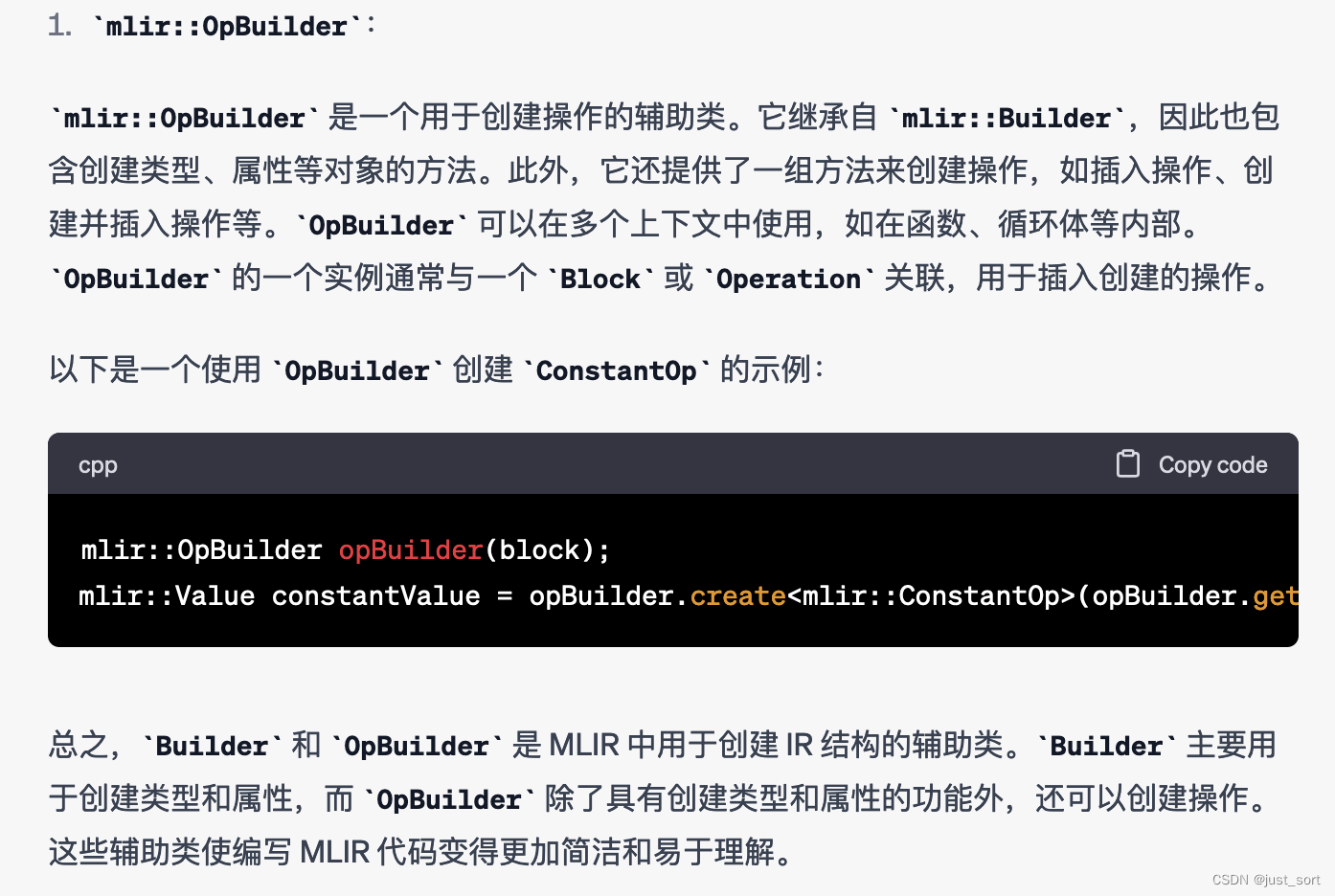
Claude:

个人感觉GPT4和Claude的回答都不是很完善,如果综合一下GPT4和Claude的结果会更好,这个问题双方算是平手。
Q13: 介绍一下MLIR Context和Region
GPT4:

Claude:

这个问题的回答,感觉Claude更加准确,并且Claude指出了使用Context和Region的一般构建流程。
我们知道在MLIR中定义OP有2种方式,一种是直接在C++定义,另外一种是基于ODS进行定义。目前主流的做法就是基于ODS也就是在一个td文件中定义OP,然后利用TableGen自动生成相应的C++代码。MLIR在OpBase.td中已经定义了一些公共的结构,接下来我们就提问GPT4和Claude是否知道这些公共的结构。
Q14: MLIR的OpBase.td有哪些公共结构


Claude:

我期待的回答应该类似于:

显然,GPT4和Claude都没有给出理想的答案,而是随机挑选了一些OpBase.td定义的类,所以这个问题并没有很好的被语言模型理解。
Q15: 解释一下TF Dialect中对AvgPool Op使用ODS进行定义涉及到的TableGen语法,AvgPool Op定义的代码如下:
# https://github.com/tensorflow/tensorflow/blob/master/tensorflow/compiler/mlir/tensorflow/ir/tf_generated_ops.td#L965
def TF_AvgPoolOp : TF_Op<"AvgPool", [Pure]> {let summary = "Performs average pooling on the input.";let description = [{
Each entry in `output` is the mean of the corresponding size `ksize`
window in `value`.}];let arguments = (insArg<TF_FloatTensor, [{4-D with shape `[batch, height, width, channels]`.}]>:$value,ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$ksize,ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$strides,TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding,DefaultValuedOptionalAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format);let results = (outsRes<TF_FloatTensor, [{The average pooled output tensor.}]>:$output);TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>;
}
GPT4:

Claude:

GPT4和Claude的结果比较类似,都是逐行解析了涉及到的TableGen语法。
Q16: 请解释一下MLIR中的Bufferization
GPT4:

Claude:


GPT4的回答宏观一些,Claude的回答更具体一些,都有优点。
Q17: 对于将分散的memref.alloc操作优化合并成单一的memref.alloc统一分配并通过类似memref.subview进行复用,你有什么建议吗,有现成的类似的pass实现吗
GPT4:


Claude:

对于这个问题,GPT4总结得比Claude更细一些。
Q18: 讲一下MLIR中One-Shot Bufferize设计的目的和目前成熟的应用
GPT4:

Claude:

两种回答差不多,不分高下。
Q19: https://mlir.llvm.org/docs/Bufferization/ 这个网页你能解读一下吗
GPT4:

Claude:

GPT4的总结稍微更贴合网页一些,但是自己去浏览网页可以发现还是有一些细节被漏掉了,如果要学习Bufferization还是建议去看下原始的网页。
Q20: 解释下linalg的算子融合算法
GPT4:

Claude:

对Linalg的学习有限,个人感觉这两个答案都是比较宏观的,需要查看Linalg的文档或者代码进一步获取相关信息。
上面一共问了20个问题,我个人感觉GPT4相比于Claude并没有很大的优势,我的初步结论是就MLIR的基础概念理解来看,GPT4和Claude几乎打成平手。
0x2. 代码阅读
这一节,我以OneFlow中的OneFlow Dialect中的Op转换为TOSA Dialect中的Op为例子,对比一下GPT4和Claude对相关代码的理解能力。这部分代码在 https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/ir/lib/OneFlow/Conversion/OneFlowToTosa.cpp 这个c++文件中。
Code 1
解释一下
Type convertToSignless(MLIRContext* context, Type type) {if (auto ranked_tensor = type.dyn_cast<RankedTensorType>()) {if (auto intTy = ranked_tensor.getElementType().dyn_cast<IntegerType>()) {if (!intTy.isSignless()) {return RankedTensorType::get(ranked_tensor.getShape(),IntegerType::get(context, intTy.getWidth(),mlir::IntegerType::SignednessSemantics::Signless));}}}return type;
}FunctionType convertToSignlessFuncType(MLIRContext* context, FunctionType funcType) {llvm::SmallVector<Type, 4> inputs;llvm::SmallVector<Type, 4> results;for (auto arg : funcType.getInputs()) { inputs.push_back(convertToSignless(context, arg)); }for (auto res : funcType.getResults()) { results.push_back(convertToSignless(context, res)); }return FunctionType::get(context, inputs, results);
}
GPT4:

Claude:

GPT4和Claude对这段代码的解释基本相同,并且都是正确的。
Code2
解释一下:
bool isSignLessTensorOrOther(Type type) {if (auto ranked_tensor = type.dyn_cast<RankedTensorType>()) {if (auto intTy = ranked_tensor.getElementType().dyn_cast<IntegerType>()) {if (intTy.isUnsigned()) { return false; }if (intTy.isSigned()) { return false; }}}return true;
}
bool allSignless(mlir::TypeRange types) {for (auto type : types) {if (!isSignLessTensorOrOther(type)) { return false; }}return true;
}bool allSignless(FunctionType funcType) {for (auto arg : funcType.getInputs()) {if (!isSignLessTensorOrOther(arg)) { return false; }}for (auto res : funcType.getResults()) {if (!isSignLessTensorOrOther(res)) { return false; }}return true;
}
GPT4:

Claude:

GPT4和Claude的结果也比较类似,但Claude有个优点就是它对每个函数都给出了一个例子,可以帮助读者更方便的去理解这段代码的含义。
Code3
解释一下:
Value CreateTransposeValue(Location& loc, ConversionPatternRewriter& rewriter, Value input,ArrayRef<int32_t> perms) {int perms_size = perms.size();auto transpose_perms = rewriter.create<tosa::ConstOp>(loc, RankedTensorType::get({perms_size}, rewriter.getI32Type()),rewriter.getI32TensorAttr(perms));const auto shape_type = input.getType().cast<ShapedType>();std::vector<int64_t> ranked_type;for (const auto& index : perms) ranked_type.push_back(shape_type.getDimSize(index));return rewriter.create<tosa::TransposeOp>(loc, RankedTensorType::get(ranked_type, shape_type.getElementType()), input, transpose_perms);
};RankedTensorType CreateTransposeType(ShapedType output, ArrayRef<int32_t> perms) {std::vector<int64_t> ranked_type;for (auto index : perms) ranked_type.push_back(output.getDimSize(index));return RankedTensorType::get(ranked_type, output.getElementType());
};
GPT4:

Claude:

相比之下,感觉Claude的解释可以胜出。
Code4
解释一下:
Value CreateBNOp(Location loc, ConversionPatternRewriter& rewriter, Type output_type, Value x,Value mean, Value variance, Value epsilon, Value gamma, Value beta) {// sub_op = sub(input, mean)auto sub_op0 = rewriter.create<tosa::SubOp>(loc, output_type, x, mean);// add_op0 = add(var, epsilon)auto add_op0 = rewriter.create<tosa::AddOp>(loc, variance.getType(), variance, epsilon);// rsqrt_op = rsqrt(add_op0)auto rsqrt_op = rewriter.create<tosa::RsqrtOp>(loc, variance.getType(), add_op0);// op4 = mul(sub_op, rsqrt_op)auto mul_op0 = rewriter.create<tosa::MulOp>(loc, output_type, sub_op0, rsqrt_op, 0);// op5 = mul(mul_op0, gamma)auto mul_op1 = rewriter.create<tosa::MulOp>(loc, output_type, mul_op0, gamma, 0);// op6 = add(mul_op1, beta)Value batch_norm = rewriter.create<tosa::AddOp>(loc, output_type, mul_op1, beta);return batch_norm;
};
GPT4:

Claude:

感觉GPT4和Claude对代码的理解是一样的。
Code5
再看一个卷积Op,解释一下:
struct Conv2DOpLowering final : public OpConversionPattern<Conv2DOp> {public:using OpConversionPattern<Conv2DOp>::OpConversionPattern;LogicalResult matchAndRewrite(Conv2DOp op, OpAdaptor adaptor,ConversionPatternRewriter& rewriter) const override {auto get_pair_int64_from_array = [](ArrayAttr arr) -> std::pair<int64_t, int64_t> {return {arr.getValue()[0].cast<IntegerAttr>().getSInt(),arr.getValue()[1].cast<IntegerAttr>().getSInt()};};auto stride_pairs = get_pair_int64_from_array(op.getStrides());auto pad_pairs = get_pair_int64_from_array(op.getPaddingBeforeAttr());auto dilation_pairs = get_pair_int64_from_array(op.getDilationRate());const auto pad = rewriter.getDenseI64ArrayAttr({pad_pairs.first, pad_pairs.second, pad_pairs.first, pad_pairs.second});const auto stride = rewriter.getDenseI64ArrayAttr({stride_pairs.first, stride_pairs.second});const auto dilation =rewriter.getDenseI64ArrayAttr({dilation_pairs.first, dilation_pairs.second});auto bias = op.getBias();auto loc = op.getLoc();if (!bias) {const auto output_shape = op.getOut().getType().cast<ShapedType>();// support nhwcconst auto output_channels = output_shape.getDimSize(op.IsNCHW() ? 1 : 3);const auto bias_elem_type = output_shape.getElementType();const auto type = RankedTensorType::get(output_channels, bias_elem_type);bias = rewriter.create<tosa::ConstOp>(op.getLoc(), type, DenseElementsAttr::get(type, rewriter.getZeroAttr(bias_elem_type)));}auto in = op.getIn();auto weight = op.getWeight();auto out_type = op.getOut().getType().cast<ShapedType>();if (out_type.getRank() != 4) {LOG(FATAL) << "Failed to lowering oneflow op";op->dump();}// support nhwcif (op.IsNCHW()) {const auto perms = {0, 2, 3, 1};const auto reverse_perms = {0, 3, 1, 2};in = CreateTransposeValue(loc, rewriter, in, perms);weight = CreateTransposeValue(loc, rewriter, weight, perms);out_type = CreateTransposeType(out_type, perms);auto conv2d =rewriter.create<tosa::Conv2DOp>(loc, out_type, in, weight, bias, pad, stride, dilation);auto res = CreateTransposeValue(loc, rewriter, conv2d, reverse_perms);rewriter.replaceOp(op, {res});} else {rewriter.replaceOpWithNewOp<tosa::Conv2DOp>(op, out_type, in, weight, bias, pad, stride,dilation);}return success();}
};
GPT4:

Claude:

我们再问一下,为什么format为"NHWC"的时候要加transpose操作?
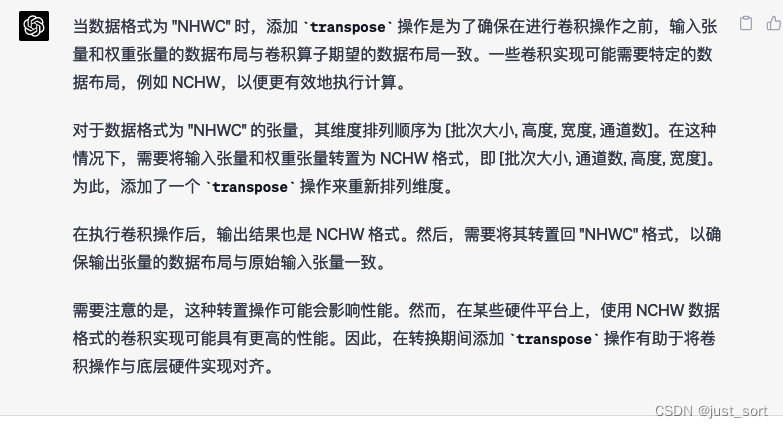

可以看到Claude理解了我的问题,并指出这是因为Tosa的conv2d不支持nhwc数据格式,所以需要加transpose。而GPT4在这个问题上就没有理解我的意思并字面意义的重复了我的问题。
0x3. 总结
本文构造了20个MLIR基础概念的问题以及使用OneFlow IR转换为Tosa IR的5个代码段来评测GPT4和Claude对于MLIR的掌握能力,我的结论是对于基础概念的理解Claude整体上和GPT4持平,而在阅读相关代码片段时Claude表现出了比GPT4更强一点的理解能力。
相关文章:
更全面的对比GPT4和Claude对MLIR的掌握能力
本文构造了20个MLIR基础概念的问题以及使用OneFlow IR转换为Tosa IR的5个代码段来评测GPT4和Claude对于MLIR的掌握能力,我的结论是对于基础概念的理解Claude整体上和GPT4持平,而在阅读相关代码片段时Claude表现出了比GPT4更强一点的理解能力。 0x0. 前言…...
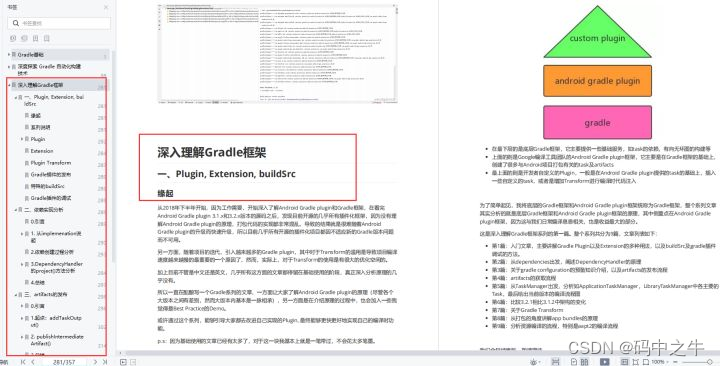
阿里ARouter 路由框架解析
一、简介 众所周知,在日常开发中,随着项目业务越来越复杂,项目中的代码量也越来越多,如果维护、扩展、解耦等成了一个非常头疼问题,随之孕育而生的诸如插件化、组件化、模块化等热门技术。 而其中组件化中一项的难点&…...
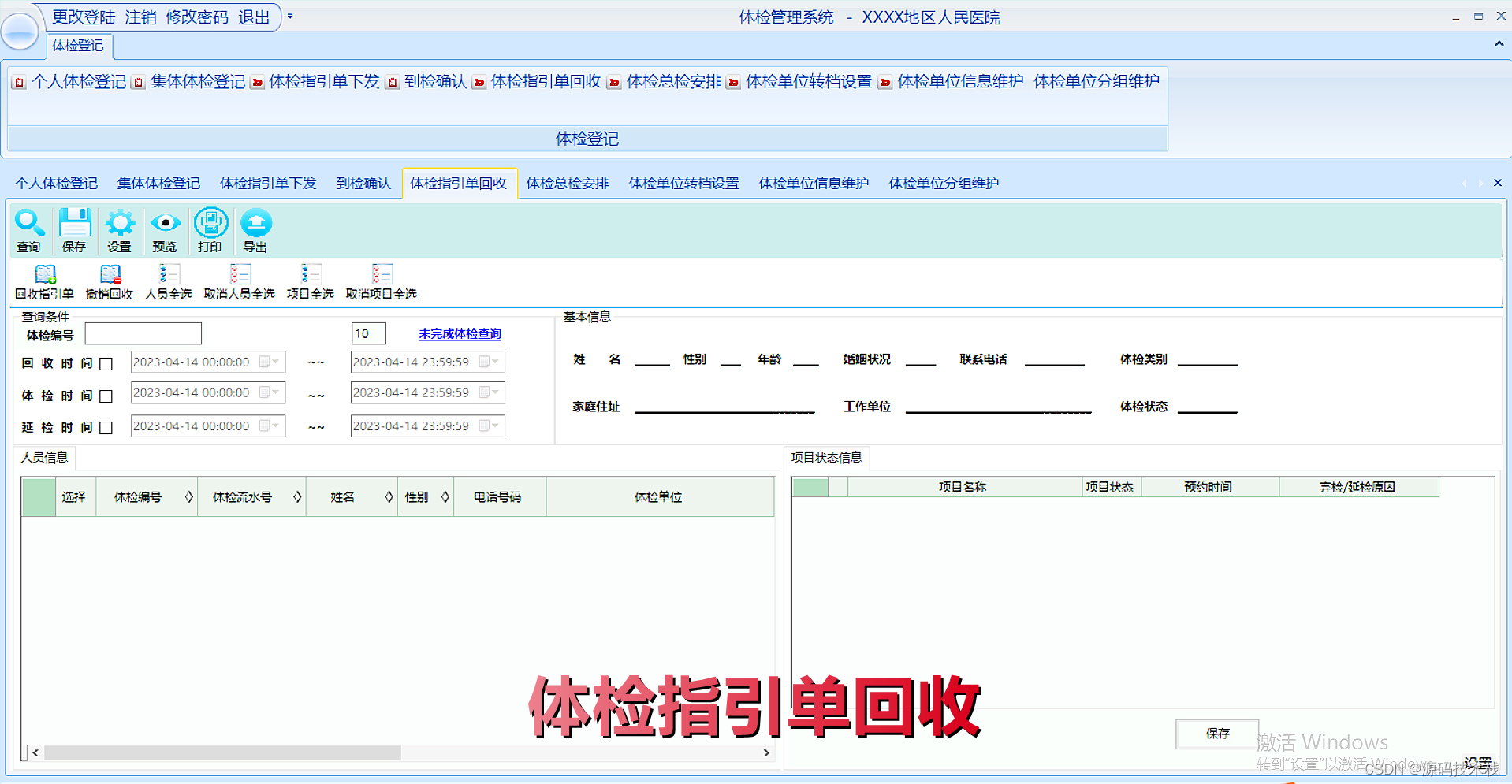
大型医院健康体检管理系统源码(PEIS)
一、体检管理系统(PEIS)概念 体检管理系统(PEIS)是以健康为中心的身体检查。一般医学家认为健康体检是指在身体尚未出现明显疾病时,对身体进行的全面检查。方便了解身体情况,筛查身体疾病。即应用体检手段对…...

java 获取时间的方法
Java的时间是通过字节码指令来控制的,所以 java程序的运行时间是通过字节码指令来控制的。但是由于 Java程序在运行时, JVM会产生一些状态,所以在执行 JVM指令时, JVM也会产生一些状态。 我们在执行 java程序时,主要是…...
- 用白话说说底层源码,不扯代码)
Block原理(二)- 用白话说说底层源码,不扯代码
之前有一篇关于block的源码探究分析 Block原理(一),时至今日,总觉的那篇文章说得不够流畅,今天打算从顶层设计的角度试着拆解下block的设计思想,拗脑的源码部分就不必再次触碰了,尽量保障这篇文…...

springboot整合knife4j接口文档成公共模块使用
theme: smartblue 之前项目中一直用的是swagger-ui进行接口文档的调用和使用,最近前端一直反馈页面不美观,调用凌乱,等一系列问题。基于这个问题我决定将其进行更改调整,上网搜索了一下发现knife4j是目前接口文档不错的一款插件。…...
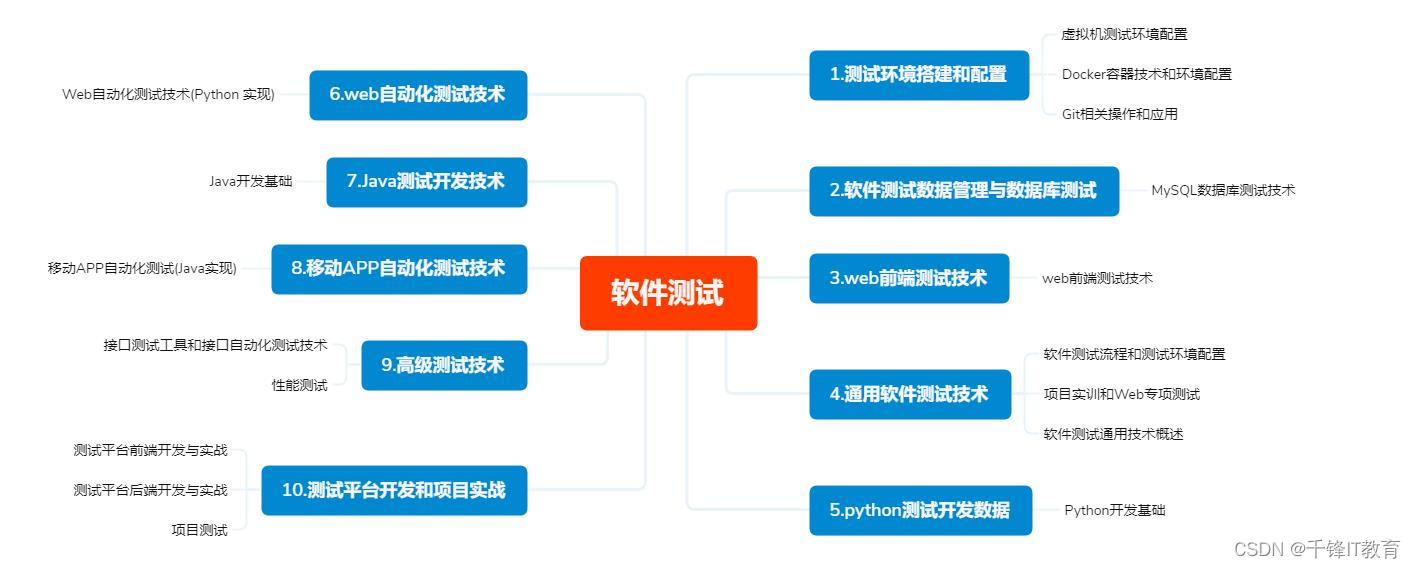
软件测试需要学什么
软件测试近些年也是比较热门的行业,薪资高、入门门槛低,让很多开发人员想纷纷加入软件开发这个行业,想要成为这一岗位的一员,想要进入软件测试行业,他们需要学习什么呢? 软件测试需要学习的还挺多的&#…...

【蓝桥杯省赛真题17】python删除字符串 青少年组蓝桥杯python编程省赛真题解析
目录 python删除字符串 一、题目要求 1、编程实现 2、输入输出 二、解题思路...

C# LINQ 查询语句和方法的区别及使用
C# LINQ(Language-Integrated Query)是一种强类型、编译时的查询技术,它可以通过统一的语法对多种数据源进行查询和操作,包括对象、集合、数据库等。LINQ 提供了两种查询方式:查询语句和扩展方法。 查询语句ÿ…...
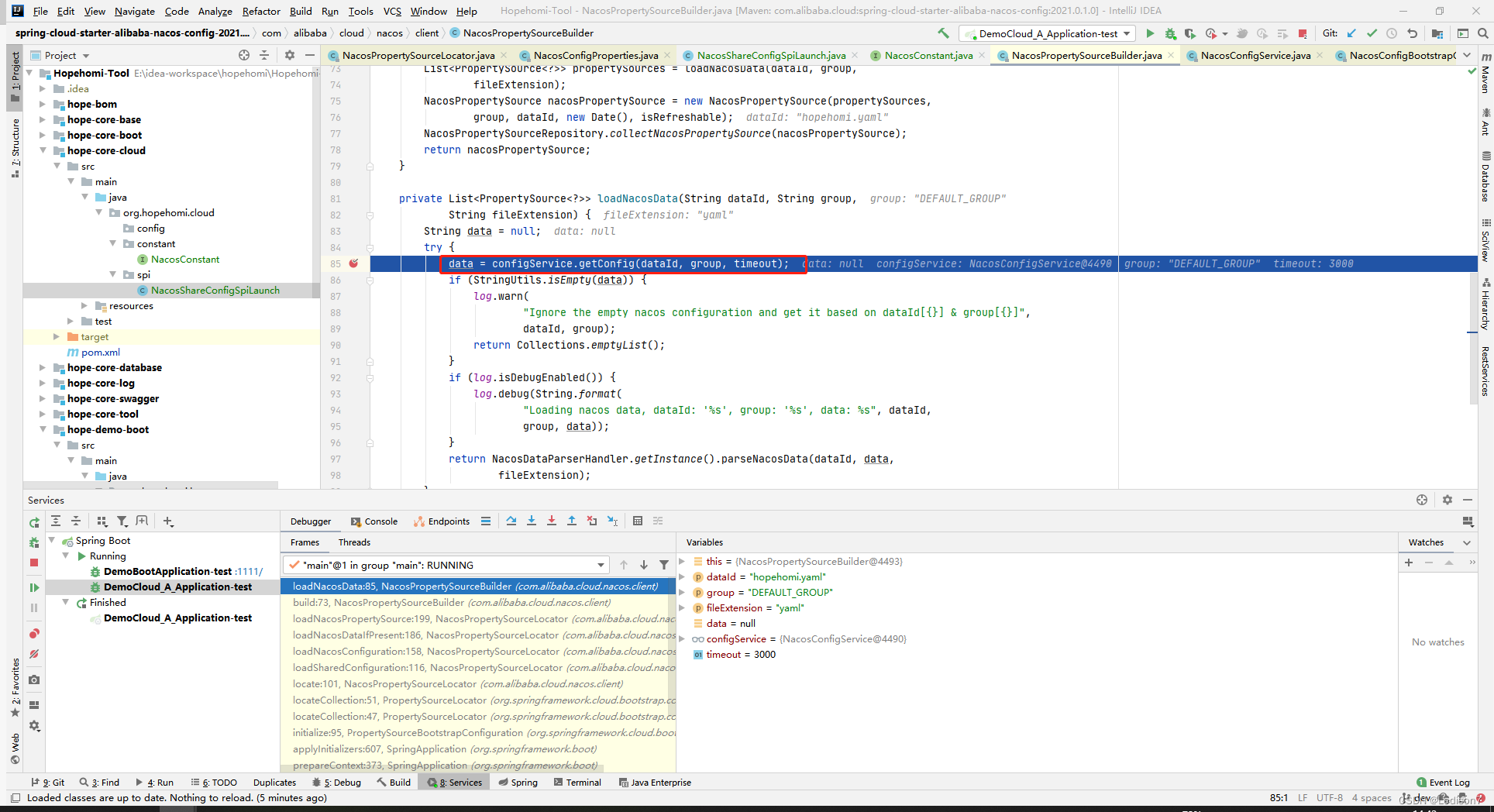
【nacos配置中心】源码部分解析
启动初始化 SpringApplication.prepareContext applyInitializers 回调ApplicationContextInitializer的initialize方法 getInitializers()从applicationContext获取List<ApplicationContextInitializer<?>> initializers 这个集合是通过SpringApplication的…...

Kotlin 1.6.0 的新特性
1、稳定版对于枚举、密封类与布尔值主语穷尽 when 语句 一个详尽的when语句包含了所有主题可能的类型或值的分支,或者对于一些类型包含一个else分支。它覆盖了所有可能的情况,使代码更加安全。 即将禁止非详尽的when语句,以使行为与when表达…...
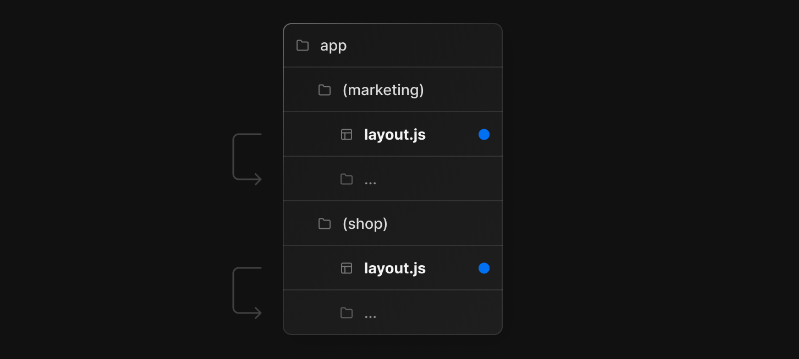
nextjs13临时笔记
动态路由 文件夹以中括号命名[id] -pages: --list: ---[id]: ----index.jsx(访问路径/list/1 即这种形式/list/:id) ---index.jsx(访问路径/list)[...params]gpt接口分析 初始化项目 npm install next react react-dom # or yarn add next react react-dom # or pnpm add n…...

云计算与区块链之间有什么区别?
区块链是一种去中心化的分布式数字账本,可实现安全透明的交易和数据存储。 它使用节点网络来验证和验证交易。 云计算通过互联网提供计算资源,例如服务器、存储和软件。区块链是一种分散且不可变的虚拟数据分类账,用于维护交易信息和监控网络…...

sed命令常用例子
替换文件中的文本 将文件file.txt中的所有"old_text"替换成"new_text": sed -i ‘s/old_text/new_text/g’ file.txt 删除文件中的某行 删除文件file.txt中的第5行: sed -i ‘5d’ file.txt 在文件中添加一行 在文件file.txt…...

MB510 3BSE002540R1在机器视觉工业领域最基本的应用
MB510 3BSE002540R1在机器视觉工业领域最基本的应用 大家都说人类感知外界信息的80%是通过眼睛获得的,图像包含的信息量是最巨大的。那么机器视觉技术的出现,就是为机器设备安上了感知外界的眼睛,使机器具有像人一样的视觉功能,…...
nightingale-0-介绍单机二进制部署
(一) 夜莺介绍 Nightingale | 夜莺监控,一款先进的开源云原生监控分析系统,采用 All-In-One 的设计,集数据采集、可视化、监控告警、数据分析于一体,与云原生生态紧密集成,提供开箱即用的企业级监控分析和告警能力。于…...

一个从培训学校走出来的测试工程师自述....
简单介绍一下我自己,1997年的,毕业一年了,本科生,专业是机械制造及其自动化。 在校度过了四年,毕业,找工作,填三方协议,体检,入职。我觉得我可能就这么度过我平平无奇的…...

关于pyqt的一些用法
QT原生是C,pyqt基于python语言。 关于插件: 安装一个PyUIC,一个Qt Designer 点击Qt Designer可以出来ui配置页面,和qt原生IDE基本一样 上面操作会生成.ui文件,选中此文件,点击PyUIC,会生成对…...
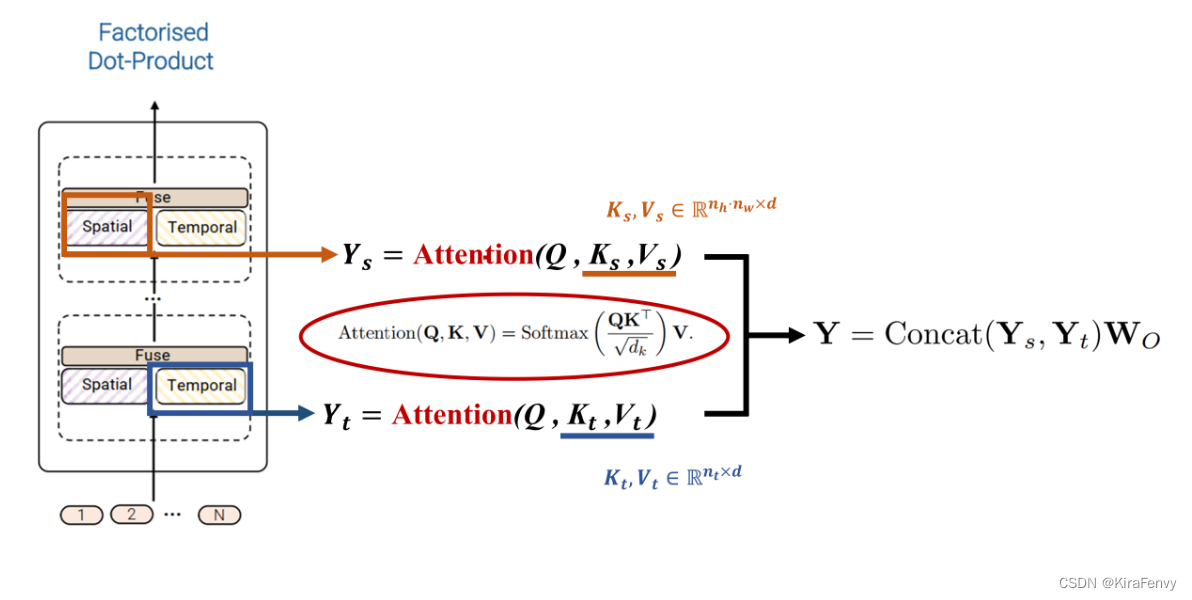
【Paper Note】ViViT: A Video Vision Transformer
ViViT: A Video Vision Transformer AbstractOverview of vision transformer 回顾ViTEmbedding video clips 视频编码方式Uniform frame sampling 均匀采样Tubelet embedding 时空管采样初始化3D卷积代码介绍视频编码输入到模型当中 Transformer Models for VideoSpatio-tempo…...

Java入坑之IO操作
目录 一、IO流的概念 二、字节流 2.1InputStream的方法 2.2Outputstream的方法 2.3资源对象的关闭: 2.4transferTo()方法 2.5readAllBytes() 方法 2.6BufferedReader 和 InputStreamReader 2.7BufferedWriter 和 OutputStreamWriter 三、路径:…...

Arduino nRF52 BLE开发:GATT服务与特征值配置实战详解
1. 项目概述如果你正在用Arduino和nRF52系列芯片(比如nRF52832或nRF52840)做蓝牙低功耗(BLE)开发,那你肯定绕不开GATT(通用属性配置文件)这一关。GATT是BLE通信的“语言规则”,它定义…...

ViewTurbo:基于响应式依赖追踪的前端渲染优化方案
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫 ViewTurbo。这名字听起来就带点“涡轮增压”的劲儿,事实上,它也确实是一个旨在为视图渲染“加速”的工具。简单来说,ViewTurbo 的核心目标,是解决在复杂前端…...

Proof Engine:简化零知识证明开发,降低区块链应用门槛
1. 项目概述:Proof Engine,一个为现代开发者设计的证明引擎如果你和我一样,在构建需要复杂逻辑验证、状态证明或零知识证明(ZKP)相关应用时,常常感到头疼——工具链复杂、学习曲线陡峭、不同框架间的兼容性…...

TPU材料3D打印iPad Pro保护框:从设计到成品的完整实践指南
1. 项目概述:为什么选择TPU为iPad Pro打造专属保护框?作为一名折腾过几十公斤耗材的3D打印老玩家,我始终认为,这项技术最迷人的地方不在于复刻网上的模型,而在于为手头的心爱之物量身定制解决方案。就拿我手边的这台iP…...

DDalkkak:逆向解析KakaoTalk数据库,实现聊天记录本地化备份与迁移
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫aristoapp/DDalkkak。乍一看这个仓库名,可能有点摸不着头脑,但如果你对韩国本土的即时通讯应用KakaoTalk有所了解,或者对数据迁移、备份工具有需求,那这个项…...

基于Python与Playwright的招聘信息自动化聚合与智能筛选工具实践
1. 项目概述:一个面向求职者的自动化信息聚合与投递工具最近在和一些做开发的朋友聊天,发现大家普遍有个痛点:找工作太费时间了。每天要在几个招聘App之间来回切换,重复筛选岗位、刷新列表、投递简历,机械性的操作占据…...

GitHub宝藏项目:生成式AI公司全景导航图与实战应用指南
1. 项目概述:一份AI创业公司的全景导航图最近在GitHub上闲逛,发现了一个宝藏仓库,名字叫“awesome-generative-ai-companies”。这个项目,说白了,就是一个由社区驱动的、持续更新的生成式AI公司名录。它不像那些商业咨…...

6000万美元拿下世界杯:FIFA终于清醒了?
5月15号下午,央视和国际足联官宣了新周期的版权合作。朋友圈里炸开了锅,大家都在讨论那个数字:6000万美元。这是2026年美加墨世界杯的中国区转播权价格。说实话,看到这个价格我有点意外。上一届卡塔尔世界杯,传闻中的版…...

AI团队协作镜像:Docker容器化实现环境一致性与高效复现
1. 项目概述:从开源镜像到AI协作平台的深度解构最近在GitHub上看到一个名为“team9ai/team9”的仓库,这个看似简单的镜像名背后,其实隐藏着一个非常典型的现代AI项目协作范式。它不是某个单一的算法模型,也不是一个孤立的工具&…...

深入解析Ayiks project-genesis-framework:模块化架构元框架的设计与实践
1. 项目概述与核心价值最近在梳理一些老项目的技术债,发现很多早期为了快速上线而写的代码,现在维护起来简直是一场灾难。业务逻辑和底层框架耦合得死死的,想换个数据库或者加个缓存层,都得把整个项目翻个底朝天。这种时候&#x…...