redis原理及进化之路
Redis 的主从复制经历了多次演进,本文将从最基本的原理和实现讲起,并层层递进,逐步呈现 Redis 主从复制的演进历史。大家将了解到 Redis 主从复制的原理,以及各个改进版本解决了什么问题,并最终看清 Redis 7.0 主从复制原理的全貌。
什么是主从复制?
在数据库语境下,复制(replication)就是将数据从一个数据库复制到另一个数据库中。主从复制,是将数据库分为主节点和从节点,主节点源源不断地将数据复制给从节点,保证主从节点中存有相同的数据。
有了主从复制,数据可以有多份副本,这带来了多种好处:
第一,提升数据库系统的请求处理能力。单个节点能够支撑的读流量有限,部署多个节点,并构成主从关系,用主从复制保持主从节点数据一致,如此主从节点可以一起提供服务。
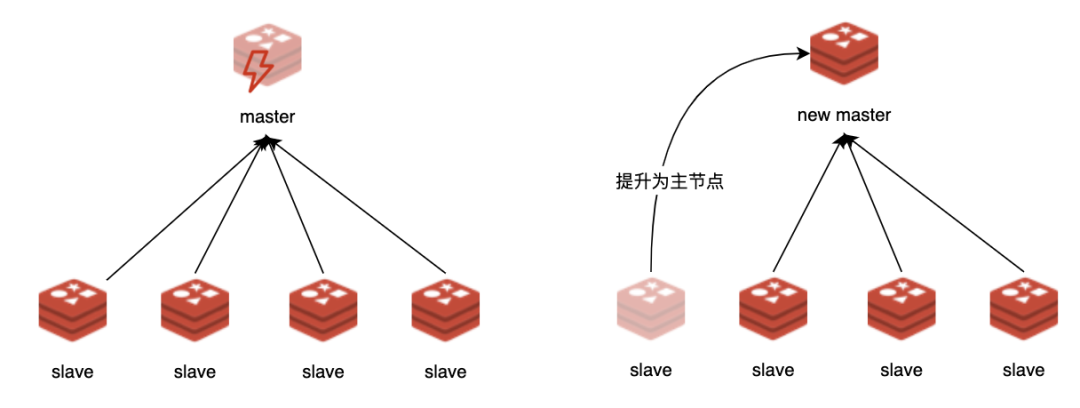
第二,提升整个系统的可用性。因为从节点中有主节点数据的副本,当主节点宕机后,可以立刻提升其中一个从节点为主节点,继续提供服务。
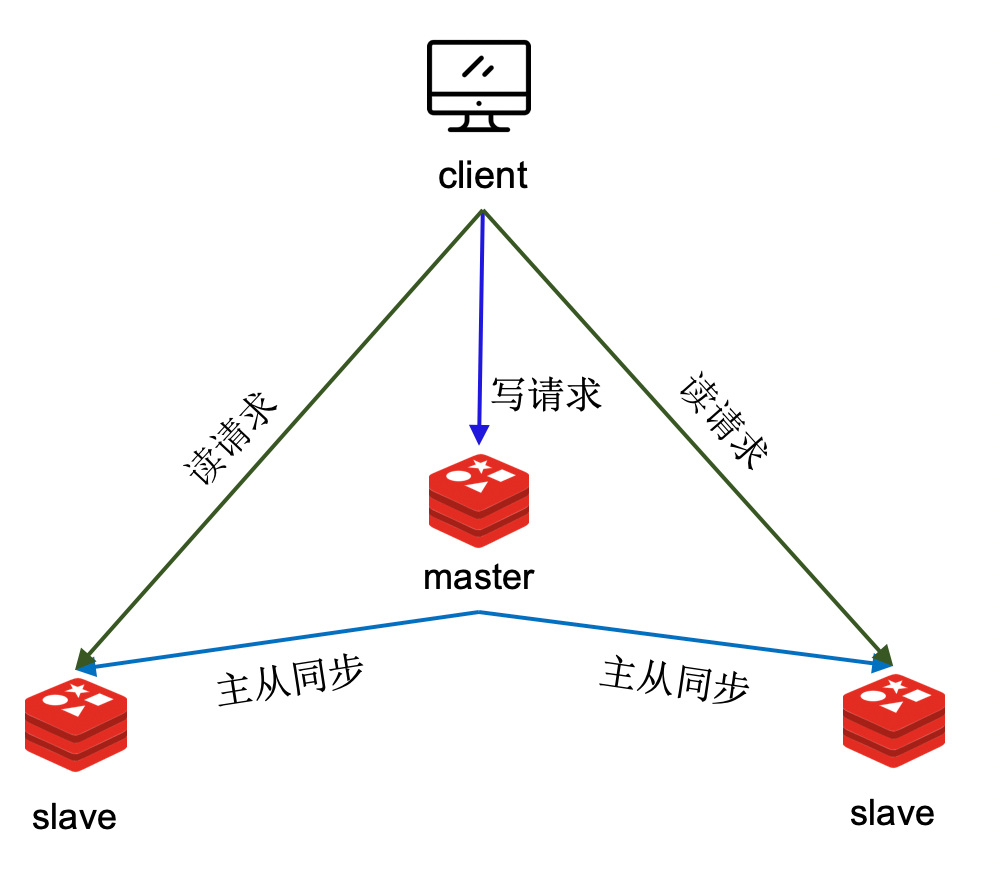
Redis 主从复制原理
实现主从复制,直观的思路是产生一份主节点数据的快照发送给从节点,并以此做为基准,随后将快照时刻之后的增量数据发送给从节点,如此就能保证主从数据的一致。总体来看,主从复制一般包含全量数据同步、增量同步两个阶段。
在 Redis 的主从复制实现中,包含两个类似阶段:全量数据同步和命令传播。
- 全量数据同步:主节点产生一份全量数据的快照,即 RDB 文件,并将此快照发送给从节点。且从产生快照时刻起,记录新接收到的写命令。当快照发送完成后,将累积的写命令发送给从节点,从节点执行这些写命令。此时基准已经建立完成,主从节点间数据已经大体一致。
- 命令传播:全量数据同步完成后,主节点将执行过的写命令源源不断地发送给从节点,从节点执行这些命令,保证主从节点中数据有相同的变更,如此保证主从数据持续一致。
下图中给出了 Redis 主从复制的整个过程:
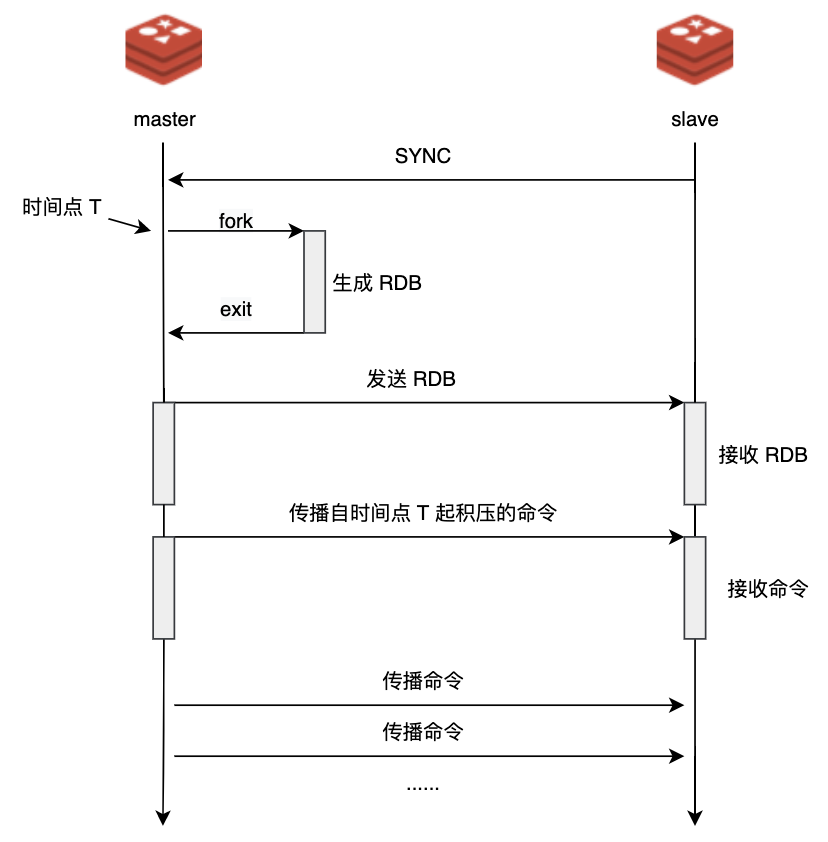
- 主从关系建立后,从节点向主节点发送一个 SYNC 命令请求进行主从同步。
- 主节点收到 SYNC 命令后,执行 fork 创建一个子进程,子进程中将所有的数据按特定编码存储到 RDB(Redis Database) 文件中,这就产生了数据库的快照。
- 主节点将此快照发送给从节点,从节点接收并载入快照。
- 主节点接着将生成快照、发送快照期间积压的写命令发送给从节点,从节点接收这些命令并执行,命令执行后,从节点中的数据也就有了同样的变更。
- 此后,主节点源源不断地新执行的写命令同步到从节点,从节点执行传播来的命令。如此,主从数据保持一致。需要说明的是,命令传播存在时延的,所以任意时刻,不能保证主从节点间数据完全一致。
以上就是 Redis 主从复制的基本原理,很简单很容易理解,Redis 最初就采用这种方案,但这种方案存在一些问题:
fork 耗时过长,阻塞主进程
执行fork 时,需要拷贝大量的内存页表,这是一个耗时较多的操作,尤其当内存使用量较大的时候。组内同学曾做过测试,内存占用 10GB 时,fork 需要消耗 100 多毫秒。fork 的时候主进程阻塞 100 多毫秒,这对 Redis 而言,实在太长了。另外fork 之后,如果主库中有不少的写入,那么由于写时复制机制,会额外消耗不少的内存,还会增大响应时间。
主从间网络闪断会触发全量同步
假如主从之间的网络出现了故障,连接意外断开,主节点无法继续传播命令至该从节点。之后网络恢复,从节点重新连接上主节点后,主节点不能再继续传播新接收到的命令了,因为从节点已经漏掉了一些命令。此时,从节点需要从头再来,再次执行全部的同步过程,而这要付出很高的代价。
网络闪断是常发生的事情,闪断期间主节点中可能只写入了比较少的数据,但就因为这很少的一部分数据,需要让从节点进行一次代价高昂的全量同步。这种做法是非常低效的,该如何解决这问题呢?下一节 Redis 部分重同步给你答案。
Redis 部分重同步
网络短暂断开后,从节点需要重新同步,这很浪费资源,很不环保。从节点为什么需要重新同步呢?因为主从断开期间有部分命令没有同步到从节点上去。如果忽略这些命令继续传播后续的命令,则会导致数据的错乱,因为丢失掉的命令是不能忽略的。为什么不将那些命令保存下来呢?这样当从节点重新连接后,就可以将断连期间的命令补充给它了,这样就不需要重新全量同步了。
Redis 2.8 版本后,引入了部分同步。它在主节点中维护了一个复制积压缓冲区,命令一方面会传播到从节点,另外还会记录在这个缓冲区中。保存所有的命令是不必要的,Redis 中使用了一个环形的缓冲区,这样就可以只保留最近的一些命令了。
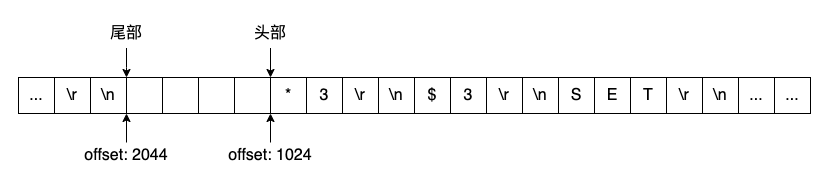
命令是保存下来了,但从节点重新连接后,主节点该从什么地方开始给从节点发送命令呢?如果能给所有命令编一个号,则从节点只需要告诉主节点自己最后收到的命令的编号,主节点就知道该从什么位置发送命令了。Redis 的实现中是对字节进行编号,这个编号在 Redis 的语境中叫做复制偏移量。
有了部分同步后,主从复制的流程变成了下面这样:
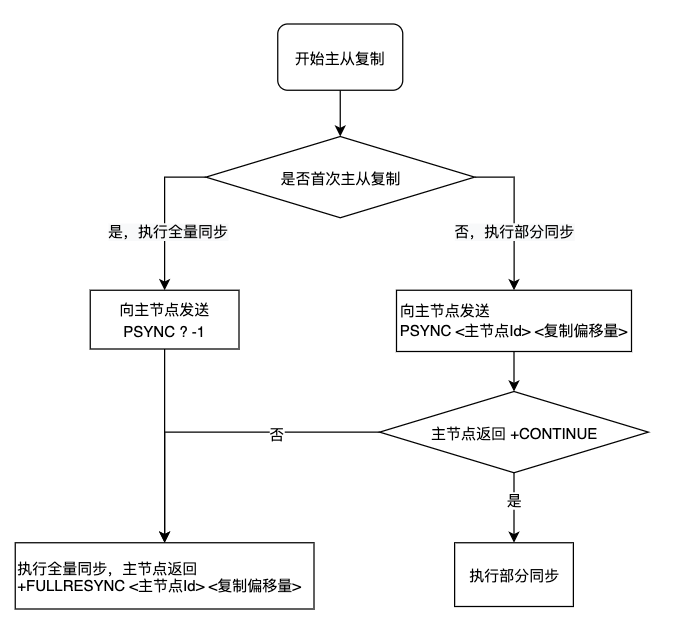
主从复制的时候不再使用SYNC命令,而是使用PSYNC,意思的Partial SYNC,部分同步。PSYNC的语法如下:
PSYNC <master id> <replication offset>
命令中的两个参数,一个是主节点的编号,一个是复制偏移量。每个Redis节点都有一个 40 字节的编号,PSYNC 命令中携带的编号是期望进行同步的主节点的编号。复制偏移量则表示当前从节点想要从什么地方开始部分同步。
如果是第一次进行主从复制,自然是不知道主节点的编号,复制偏移量也无意义,此时使用 PSYNC ? -1 来进行全量同步。另外,如果从节点指定的复制偏移量不在主节点的复制积压缓冲区的范围内,部分同步会失败,会转向全量同步。
有了部分同步,网络闪断后就可以避免全量同步了。但是因为主节点只能保留最近的部分命令,保存多少取决于复制积压缓冲区的大小。如果从节点断开时间过长,或者断开期间主节点新执行的写命令足够多,漏掉的命令就无法全部保存到复制积压缓冲区中了。加大复制积压缓冲区可以尽可能多地避免全量同步,但这同时会造成额外的内存消耗。
部分同步消耗了部分内存来保存最近执行的写命令,避免闪断后的全同步,这是很直观、很容易想象的解决方案。这种方案很好,是否还存在其他问题呢?考虑以下问题:
假如从节点重启了怎么办?
部分同步依赖主节点的编号和复制偏移量,从节点在初次同步的时候会获取到主节点的编号,并在之后的同步中不断调整复制偏移量,这些信息都存储在内存中。当从节点意外重启后,尽管本地存有 RDB 或 AOF 文件,还是需要进行一次全量同步。但实际上完全可以载入本地数据,并执行部分同步即可。
假如主从切换了怎么办?
假如主节点意外宕机,外围监控组件执行了主从切换。此时其他从节点对应的主节点就变化了,从节点中记录的主节点编号就匹配不上新的主节点了,此时会进行一次全量同步。但实际上所有的从节点在主从切换之前同步进度应该是差不多的,而且新提升的从节点包含的数据应该最全,切主后所有从节点都执行一次全量同步,这实在不合理。
以上问题如何解决,请继续往后看。
同源增量同步
从节点重启后丢失了原主节点编号和复制偏移量,这导致重启后需要全量同步,这很好办,把这些信息存下来就可以了。
主从切换后,主节点信息变化了,导致从节点需要全量同步,这也容易解决,只需能确认新主节点上的数据是从原主节点复制来的,那就可以继续从新的主节点上进行复制。
Redis 4.0 以后,对 PSYNC 进行了改进,提出了同源增量复制的解决方案,该方案解决了前面提到的两个问题。
从节点重启后,需要跟主节点全量同步,这本质上是因为从节点丢失了主节点的编号信息,在 Redis 4.0 后,主节点的编号信息被写入到 RDB 中持久化保存。
切主后,从节点需要和新主节点全量同步,本质原因是新的主节点不认原主节点的编号。从节点发送 PSYNC <原主节点编号> <复制偏移量> 给新的主节点,如果新的主节点能够认识 <原主节点编号>,并明白自己的数据就是从该节点复制来的。那么新的主节点就应该清楚它和该从节点师出同门,应该接受部分同步。如何才能识别呢,只需要让从节点在切换为主节点时,将自己之前的主节点的编号记录下来即可。
Redis 4.0 以后,主从切换后,新的主节点会将先前的主节点记录下来,观察 info replication 的结果,可以可以看到 master_replid 和 master_replid2 两个编号,前者是当前主节点的编号,后者为先前主节点的编号:
127.0.0.1:6379> slaveof no one
OK
127.0.0.1:6379> info replication
#Replication
role:master
...
master_replid:b34aff08d983991b3feb4567a2ac0308984a892a
master_replid2:a3f2428d31e096a99d87affa6cc787cceb6128a2
master_repl_offset:38599
second_repl_offset:38600
...
repl_backlog_histlen:5180
Redis 中目前值保留了两个主节点编号,但完全可以实现一个链表,将过往的主节点的编号信息都记录下来,这样就可以追溯的更远了。这样以来,如果一个从节点断开后,执行了多次主从切换,该从节重新连接后,依然可以识别出它们的数据是同源的。但 Redis 没有这么做,这是因为没有必要,因为就算数据是同源的,但复制积压缓冲区中保存的数据是有限的,多次主从切换后,复制积压缓冲区中保存的命令已经无法满足部分同步了。
有了同源增量复制后,主节点切换后,其他从节点可以基于新的主节点继续增量同步。
此时,主从复制看起来已经不存在太大的问题了。但做 Redis 的那帮家伙,总挖空心思想着能不能再做些优化。下面我将描述 Redis 主从复制的一些优化策略。
无盘全量同步和无盘加载
Redis 执行全量复制,需要生成当前数据库的一份快照,具体做法是执行 fork 创建子进程,子进程遍历所有数据并编码后写入 RDB 文件中。RDB 生成后,在主进程中,会读取此文件并发送给从节点。
读写磁盘上的 RDB 文件是比较耗资源的,在主进程中执行势必会导致 Redis 的响应时间变长。因此一个优化方案是 dump 后直接将数据直接发送数据给从节点,不需要将数据先写入到 RDB 。Redis 6.0 中实现了这种无盘全量同步和无盘加载的策略。
采用无盘全量同步,避免了对磁盘的操作,但也有缺点。一般情况下,在子进程中直接使用网络发送数据,这比在子进程中生成 RDB 要慢,这意味着子进程需要存活的时间相对较长。子进程存在的时间越长,写时复制造成的影响就越大,进而导致消耗的内存会更多。
在全量复制时候,从节点一般是先接收 RDB 将其存在本地,接收完成后再载入 RDB。同样地,从节点也可以直接载入主节点发来的数据,避免将其存入本地的 RDB 文件中,而后再从磁盘加载。
共享主从复制缓冲区
在主节点的视角中,从节点就是一个客户端,从节点发送了 PSYNC 命令后,主节点就要与它们完成全量同步,并不断地把写命令同步给从节点。Redis 的每个客户端连接上存在一个发送缓冲区。
主节点执行了写命令后,就会将命令内容写入到各个连接的发送缓冲区中。发送缓冲区存储的是待传播的命令,这意味着多个发送缓冲区中的内容其实是相同的。而且,这些命令还在复制积压缓冲区中存了一份呢。这就造成了大量的内存浪费,尤其是存在很多从节点的时候。
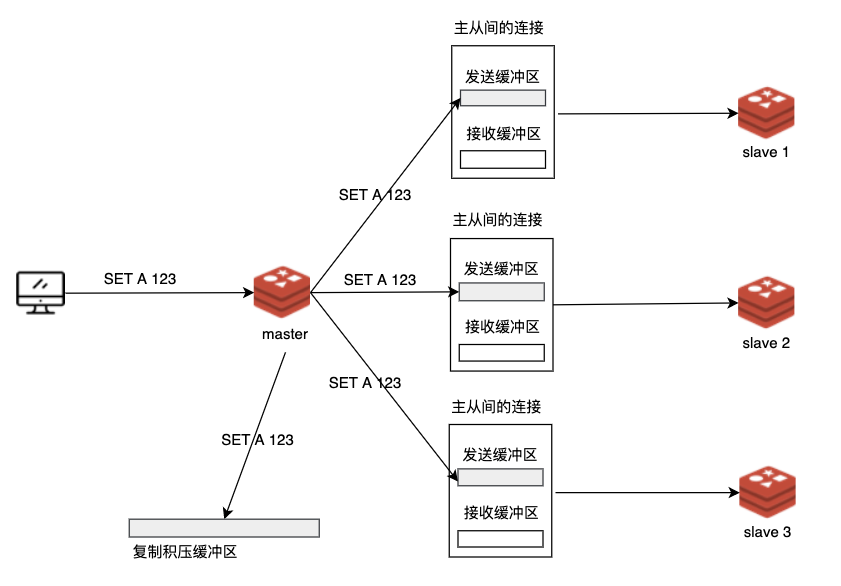
在 Redis 7.0 中,我们团队的同学提出并实现了共享主从复制缓冲区的方案解决了这个问题。该方案让发送缓冲区与复制积压缓冲区共享,避免了数据的重复,可有效节省内存。
总结
本文回顾并总结了 Redis 主从复制的演化过程,并解释了各次演化所解决的问题。最后,描述了对 Redis 主从复制进行优化的一些策略。
下面是对全文的总结:
- 宏观来看 Redis 的主从复制分为全量同步和命令传播两个阶段。主节点先发送快照给从节点,然后源源不断地将命令传播给从节点,以此保证主从数据的一致。
- Redis 2.8 之前的主从复制存在闪断后需要重新全量同步的问题,Redis 2.8 引入了复制积压缓冲区解决了这一问题。
- 在 Redis 4.0 中,同源增量复制的策略被提出,解决了主从切换后从节点需要全量同步的问题。至此,Redis 的主从复制整体上已经比较完善了。
- Redis 6.0 中,为进一步优化主从复制的性能,无盘同步和加载被提出,避免全量同步时读写磁盘,提高主从同步的速度。
- 在 Redis 7.0 rc1 中,采用了共享主从复制缓冲区的策略,降低了主从复制带来的内存开销。
希望本文能帮助大家回顾 Redis 主从复制的原理,并对其建立更加深刻的印象。
相关文章:
redis原理及进化之路
Redis 的主从复制经历了多次演进,本文将从最基本的原理和实现讲起,并层层递进,逐步呈现 Redis 主从复制的演进历史。大家将了解到 Redis 主从复制的原理,以及各个改进版本解决了什么问题,并最终看清 Redis 7.0 主从复制…...
ai智能写作助手-ai自动写作软件
为什么要用ai智能写作工具 在数字化时代,AI(人工智能)技术已经被广泛应用于各种领域,其中之一是写作。AI智能写作工具是利用自然语言处理技术和机器学习算法来生成高质量的文章、博客、新闻稿等。这些工具不仅提供了便捷、高效的…...

redis持久化
redis提供两种方式进行持久化,一种是RDB持久化(原理是将Reids在内存中的数据库记录定时dump到磁盘上的RDB持久化),另外一种是AOF持久化(原理是将Reids的操作日志以追加的方式写入文件)。那么这两种持久化方…...
Vue项目基于driverjs实现新用户导航
引导页就是当用户第一次或者手动进行触发的时候,提示给用户当前系统的模块介绍,比如哪里是退出,哪里是菜单等等相应的操作。 无论是开发 APP 还是 web 应用,新手引导都是一个很常见的需求,一般在这2个方面需要新手引导…...
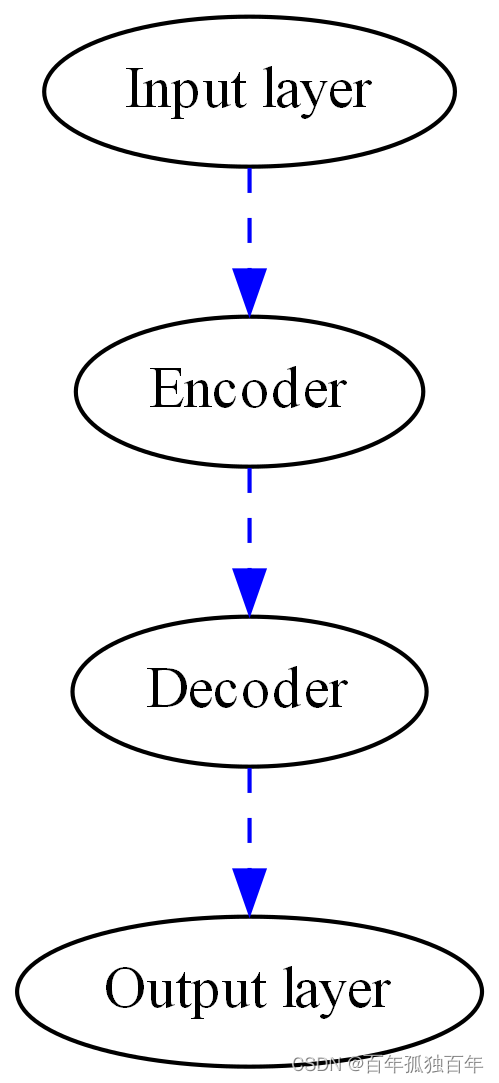
自编码器简单介绍—使用PyTorch库实现一个简单的自编码器,并使用MNIST数据集进行训练和测试
文章目录 自编码器简单介绍什么是自编码器?自动编码器和卷积神经网络的区别?如何构建一个自编码器?如何训练自编码器?如何使用自编码器进行图像压缩?总结使用PyTorch构建简单的自动编码器第一步:导入库和数…...
redis单机最大并发量
redis单机最大并发量 布隆过滤器多级缓存客户端缓存应用层缓存Expires和Cache-Control的区别Nginx缓存管理 服务层缓存进程内缓存进程外缓存 缓存数据一致性问题的解决引入多级缓存设计的时刻 Redis的速度非常的快,单机的Redis就可以⽀撑 每秒十几万的并发,相对于MySQL来说,性…...
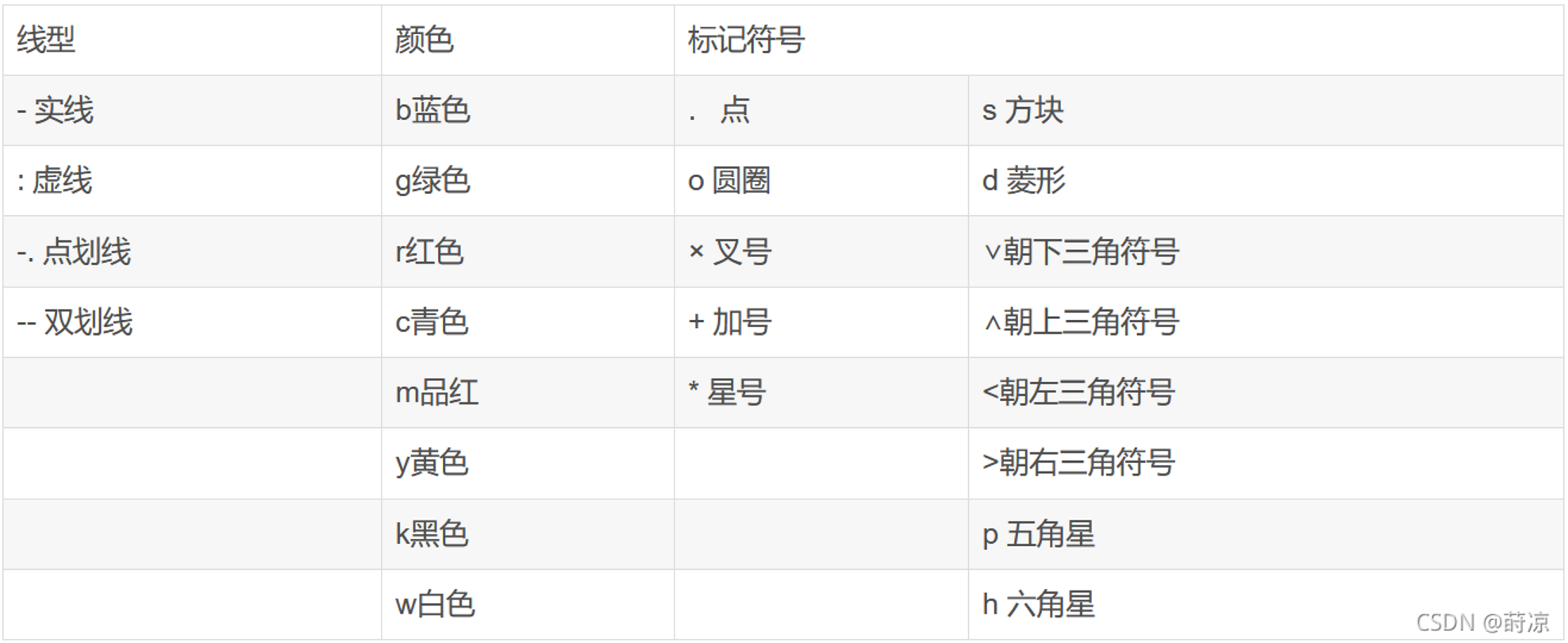
MTLAB绘图
这里写目录标题 一、图例1、散点图 二、绘图1、总体图形参数2、坐标、图框、网格图框去上右边框小刻度网格坐标范围和刻度控制旋转 坐标、刻度 3、图例图例位置和方向 Location和Orientation图例加标题 、分多列 4、文本 字、字体、字号5、线型 符号6、颜色栏 colorbar7、颜色8…...

自媒体必备素材库,免费、商用,赶紧马住~
自媒体经常需要用到各类素材,本期就给大家安利6个自媒体必备的素材网站,免费、付费、商用都有,建议收藏起来~ 1、菜鸟图库 https://www.sucai999.com/video.html?vNTYwNDUx 菜鸟图库可以找到设计、办公、图片、视频、音频等各种素材。视频素…...

ESP32设备驱动-BMP388气压传感器驱动
BMP388气压传感器驱动 文章目录 BMP388气压传感器驱动1、BMP388介绍2、硬件准备3、软件准备4、驱动实现1、BMP388介绍 BMP388 是一款非常小巧、低功耗和低噪声的 24 位绝对气压传感器。 它可以实现精确的高度跟踪,特别适合无人机应用。 BMP388 在 0-65C 之间的同类最佳 TCO,…...
攻防世界-Reversing-x64Elf-100
Reversing-x64Elf-100 18最佳Writeup由 yuchouxuan 提供 收藏 反馈 难度:1 方向:Reverse 题解数:15 解出人数:2460 题目来源: 题目描述: 暂无 note:undefined8 FUN_004006fd(long param_1){int local_2c;char *local_28 …...

C/C++每日一练(20230419)
目录 1. 插入区间 🌟🌟🌟 2. 单词拆分 🌟🌟 3. 不同路径 🌟🌟 🌟 每日一练刷题专栏 🌟 Golang每日一练 专栏 Python每日一练 专栏 C/C每日一练 专栏 Java每日…...
[自注意力神经网络]Mask Transfiner网络-论文解读
本文为CVPR2022的论文。国际惯例,先贴出原文和源码: 原论文地址https://arxiv.org/pdf/2111.13673.pdf源码地址https://github.com/SysCV/transfiner 一、概述 传统的Two-Stage网络,如Mask R-CNN虽然在实例分割上取得了较好的效果ÿ…...

漫画:是喜,还是悲?AI竟帮我们把Office破活干完了
图文原创:亲爱的数据 国产大模型烈火制造。阿里百度字节美团各科技大佬不等闲。 大模型嘛,重大工程,对我等“怀保小民”来说,只关心怎么用,不关心怎么造。 我来介绍一下自己,我是一个写稿男团组合的成员&am…...

ChatGPT的原理分析
1.前言 ChatGPT是一种基于自然语言处理和人工智能技术的聊天机器人,它的基础是由OpenAI研发的GPT模型,其中GPT是Generative Pre-trained Transformer的缩写。GPT模型的训练使用了海量的语料库,可以预测下一个单词、短语、句子或文本…...
在线免费把Markdown格式文件转换为PDF格式
用CSDN的MarkDown编辑器在线转换 CSDN的MarkDown编辑器说实话还是挺好用的。 导出PDF操作步骤,图文配合看: 在MD编辑模式下写好MarkDown文章或者直接把要转换的MarkDown贴进来; 使用预览模式,然后在预览文件上右键选择打印&…...

R7-5 列车厢调度
R7-5 列车厢调度 分数 25 全屏浏览题目 切换布局 作者 周强 单位 青岛大学 1 <--移动方向/3 \2 -->移动方向 大家或许在某些数据结构教材上见到过“列车厢调度问题”(当然没见过也不要紧)。今天,我们就来实际操作一下列车…...
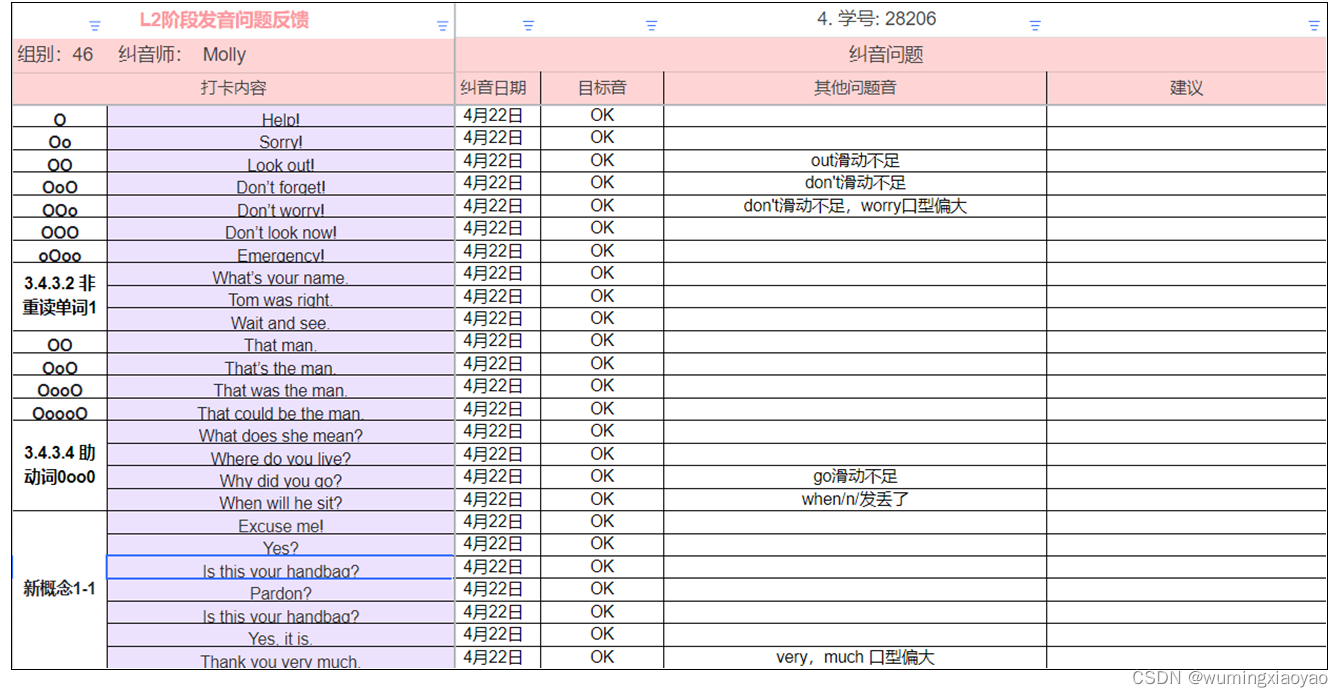
English Learning - L2 第 16 次小组纠音 弱读和语调 2023.4.22 周六
English Learning - L2 第 16 次小组纠音 弱读和语调 2023.4.22 周六 共性问题help /help/ 中的 e 和 lsorry /ˈsɒri/ 中的 ɒ 和 ilook out /lʊk aʊt/ 中的 ɒ 和 aʊdont /dəʊnt/ 中的 əʊemergency /ɪˈmɜːʤənsɪ/ 中的 ɜːname /neɪm/ 中的 eɪright /raɪt/…...

( “树” 之 前中后序遍历) 145. 二叉树的后序遍历 ——【Leetcode每日一题】
基础概念:前中后序遍历 1/ \2 3/ \ \ 4 5 6层次遍历顺序:[1 2 3 4 5 6]前序遍历顺序:[1 2 4 5 3 6]中序遍历顺序:[4 2 5 1 3 6]后序遍历顺序:[4 5 2 6 3 1] 层次遍历使用 BFS 实现,利用的就是 BFS…...

NPOI與Crystal report 13.0關於ICSharpCode.SharpZipLib控件版本衝突的解決方法
公司原來的系統用了Crystal report 13.0,它關聯使用ICSharpCode.SharpZipLib.dll (壓縮控件)的版本為0.85.1.271;後來因需要新增加 NPOI2.3控件,它關聯使用了ICSharpCode.SharpZipLib.dll 的版本為 高版本0.86…...

Sass @extend 与 继承
Sass extend 与 继承 extend 指令告诉 Sass 一个选择器的样式从另一选择器继承。 如果一个样式与另外一个样式几乎相同,只有少量的区别,则使用 extend 就显得很有用。 以下 Sass 实例中,我们创建了一个基本的按钮样式 .button-basic&#…...

Ollama客户端开发指南:构建本地大模型交互工具的核心原理与实践
1. 项目概述:一个与Ollama对话的客户端工具如果你正在本地运行像Llama 3、Mistral或者Qwen这类开源大语言模型,那么Ollama这个名字对你来说一定不陌生。它让部署和管理这些模型变得像在命令行里敲几个单词一样简单。但Ollama本身主要是一个服务端工具&am…...

自托管OSINT平台Sovereign Shield:构建数据主权的容器化情报系统
1. 项目概述:一个面向开源情报与数字资产保护的“主权之盾” 在开源情报(OSINT)和数字资产安全领域,从业者常常面临一个核心矛盾:一方面,我们需要强大的自动化工具来高效地收集、分析和监控公开信息&#x…...

Redis分布式锁进阶第一二十五篇
Redis分布式锁进阶第二十五篇:联锁深度拆解 多资源交叉死锁根治 复杂业务多级加锁绝对有序方案一、本篇前置衔接 第二十四篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实…...

嵌入式Linux CAN通信实战:从原理到SocketCAN编程与调试
1. 项目概述:在国产工业板上玩转CAN-BUS最近在做一个工业数据采集的项目,需要把几台分散的设备数据汇总到一个主控单元。现场布线复杂,干扰又大,RS485虽然经典,但主从轮询的机制在实时性上总觉得差点意思,而…...

ACK多集群配置同步:MCP Server架构、部署与实战指南
1. 项目概述:ACK多集群管理平台的服务端核心如果你正在或计划使用阿里云容器服务ACK来管理多个Kubernetes集群,并且对如何高效、统一地分发应用配置感到头疼,那么你很可能已经接触或正在寻找类似“ack-mcp-server”这样的解决方案。这个项目&…...

5分钟掌握百度网盘高速下载神器:完全免费的开源解析工具终极指南
5分钟掌握百度网盘高速下载神器:完全免费的开源解析工具终极指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘非会员下载速度只有几十KB而烦恼吗…...

如何用MAA自动化助手彻底解放你的《明日方舟》游戏时间:5个实用技巧
如何用MAA自动化助手彻底解放你的《明日方舟》游戏时间:5个实用技巧 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址…...
)
Midjourney碳素印相风格实战手册(胶片级颗粒+铁盐棕褐渐变+微裂纹纹理全还原)
更多请点击: https://intelliparadigm.com 第一章:碳素印相工艺的历史溯源与数字复刻价值 碳素印相(Carbon Printing)诞生于1864年,由英国科学家约瑟夫斯旺(Joseph Swan)发明,是摄影…...

开源大模型适配器Basaran:一键兼容OpenAI API,无缝集成私有化部署
1. 项目概述:当开源大模型遇上“文本补全”接口 如果你最近在折腾开源的大型语言模型(LLM),比如 LLaMA、Falcon 或者国内的 ChatGLM、Qwen 系列,你肯定遇到过这样的场景:模型本身能力很强,但它…...

从数据同步工具往后看,NineData 社区版 V5.0.0 这次补齐了什么
从数据同步工具和 ChatDBA 这类能力往后看,V5.0.0 更像一次连续补强,而不是单点加功能。再结合异构数据库迁移工具这类需求,链路扩展、迁移评估和智能诊断一起往前推,社区版的可用边界也随之往前走了一步。落地之前先看这套能力框…...