小白学Pytorch系列--Torch.optim API Base class(1)
小白学Pytorch系列–Torch.optim API Base class(1)

torch.optim是一个实现各种优化算法的包。大多数常用的方法都已得到支持,而且接口足够通用,因此将来还可以轻松集成更复杂的方法。
如何使用优化器
使用手torch.optim您必须构造一个优化器对象,该对象将保存当前状态,并将根据计算出的梯度更新参数。
构造它
要构造一个优化器,你必须给它一个包含参数(所有应该是变量)的可迭代对象来优化。然后,您可以指定特定于优化器的选项,如学习率、权重衰减等。
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr=0.0001)
每个参数选项
优化器还支持指定每个参数的选项。要做到这一点,不是传递一个变量的迭代对象,而是传递一个dict的迭代对象。它们每个都将定义一个单独的参数组,并且应该包含一个params键,包含属于它的参数列表。其他键应该与优化器接受的关键字参数匹配,并将用作该组的优化选项。
注意: 您仍然可以将选项作为关键字参数传递。在没有覆盖它们的组中,它们将作为默认值使用。当您只想改变一个选项,同时在参数组之间保持所有其他选项一致时,这很有用。
例如,当想要指定每层的学习率时,这是非常有用的
optim.SGD([{'params': model.base.parameters()},{'params': model.classifier.parameters(), 'lr': 1e-3}], lr=1e-2, momentum=0.9)
这意味着这个model.base参数将使用默认的学习率1e-2,model.classifier’参数将使用1e-3的学习率,所有参数将使用0.9的动量。
进行优化步骤
所有优化器都实现了一个step()方法,用于更新参数。它有两种用法
optimizer.step()
这是大多数优化器支持的简化版本。该函数可以在梯度计算完成后调用,例如backward()。
例如:
for input, target in dataset:optimizer.zero_grad()output = model(input)loss = loss_fn(output, target)loss.backward()optimizer.step()
optimizer.step(closure)
一些优化算法(如共轭梯度和LBFGS)需要多次重新计算函数,所以你必须传入一个闭包,允许它们重新计算你的模型。闭包应该清除梯度,计算损失并返回。
for input, target in dataset:def closure():optimizer.zero_grad()output = model(input)loss = loss_fn(output, target)loss.backward()return lossoptimizer.step(closure)
Base class
这部分参考了:https://zhuanlan.zhihu.com/p/87209990
PyTorch 的优化器基本都继承于 “class Optimizer”,这是所有 optimizer 的 base class。
下面是Optimizer的结构
class Optimizer(object):def __init__(self, params, defaults):self.defaults = defaultsself._hook_for_profile()if isinstance(params, torch.Tensor):raise TypeError("params argument given to the optimizer should be ""an iterable of Tensors or dicts, but got " +torch.typename(params))self.state = defaultdict(dict)self.param_groups = []param_groups = list(params)if len(param_groups) == 0:raise ValueError("optimizer got an empty parameter list")if not isinstance(param_groups[0], dict):param_groups = [{'params': param_groups}]for param_group in param_groups:self.add_param_group(param_group)def state_dict(self):...def load_state_dict(self, state_dict):...def cast(param, value):...def zero_grad(self, set_to_none: bool = False):...def step(self, closure):...def add_param_group(self, param_group): ...
init 函数初始化
params和defaults是两个重要的参数,defaults定义了全局优化默认值,params定义了模型参数和局部优化默认值。
add_param_group
defaultdict的作用在于当字典里的 key 被查找但不存在时,返回的不是keyError而是一个默认值,此处defaultdict(dict)`返回的默认值会是个空字典。最后一行调用的self.add_param_group(param_group),其中param_group是个字典,Key 就是params,Value 就是param_groups = list(params)。
def add_param_group(self, param_group):params = param_group['params']if isinstance(params, torch.Tensor):param_group['params'] = [params]elif isinstance(params, set):raise TypeError('optimizer')else:param_group['params'] = list(params)for param in param_group['params']:if not isinstance(param, torch.Tensor):raise TypeError("optimizer " + torch.typename(param))if not param.is_leaf:raise ValueError("can't optimize a non-leaf Tensor")for name, default in self.defaults.items():if default is required and name not in param_group:raise ValueError("parameter group didn't specify a value of required optimization parameter " +name)else:param_group.setdefault(name, default) # 给参数设置默认参数params = param_group['params']if len(params) != len(set(params)):warnings.warn("optimizer contains ", stacklevel=3)param_set = set()for group in self.param_groups:param_set.update(set(group['params']))if not param_set.isdisjoint(set(param_group['params'])): # 判断两个集合是否包含相同的元素raise ValueError("some parameters appear in more than one parameter group")self.param_groups.append(param_group)zero_grad
就是将所有参数的梯度置为零p.grad.zero_()。detach_()的作用是Detaches the Tensor from the graph that created it, making it a leaf. self.param_groups是列表,其中的元素是字典。
def zero_grad(self):r"""Clears the gradients of all optimized :class:`torch.Tensor` s."""for group in self.param_groups:for p in group['params']:if p.grad is not None:p.grad.detach_()p.grad.zero_()
step
更新参数作用, 在父类 Optimizer 的 step 函数中只有一行代码raise NotImplementedError。网络模型参数和优化器的参数都保存在列表 self.param_groups 的元素中,该元素以字典形式存储和访问具体的网络模型参数和优化器的参数。所以,可以通过两层循环访问网络模型的每一个参数 p 。获取到梯度d_p = p.grad.data之后,根据优化器参数设置是否使用 momentum或者nesterov再对参数进行调整。最后一行 p.data.add_(-group['lr'], d_p)的作用是对参数进行更新。state用于保存本次更新是优化器第几轮迭代更新参数。
下面以SGD优化器为例
def step(self, closure=None):loss = Noneif closure is not None:with torch.enable_grad():loss = closure()for group in self.param_groups:params_with_grad = []d_p_list = []momentum_buffer_list = []weight_decay = group['weight_decay']momentum = group['momentum']dampening = group['dampening']nesterov = group['nesterov']maximize = group['maximize']lr = group['lr']for p in group['params']:if p.grad is not None:params_with_grad.append(p)d_p_list.append(p.grad)state = self.state[p]if 'momentum_buffer' not in state:momentum_buffer_list.append(None)else:momentum_buffer_list.append(state['momentum_buffer'])F.sgd(params_with_grad,d_p_list,momentum_buffer_list,weight_decay=weight_decay,momentum=momentum,lr=lr,dampening=dampening,nesterov=nesterov,maximize=maximize,)# update momentum_buffers in statefor p, momentum_buffer in zip(params_with_grad, momentum_buffer_list):state = self.state[p] ## 保存state['momentum_buffer'] = momentum_bufferreturn loss
F.sgd
def sgd(params: List[Tensor],d_p_list: List[Tensor],momentum_buffer_list: List[Optional[Tensor]],*,weight_decay: float,momentum: float,lr: float,dampening: float,nesterov: bool,maximize: bool):for i, param in enumerate(params):d_p = d_p_list[i]if weight_decay != 0:d_p = d_p.add(param, alpha=weight_decay)if momentum != 0:buf = momentum_buffer_list[i]if buf is None:buf = torch.clone(d_p).detach()momentum_buffer_list[i] = bufelse:buf.mul_(momentum).add_(d_p, alpha=1 - dampening)if nesterov:d_p = d_p.add(buf, alpha=momentum)else:d_p = bufalpha = lr if maximize else -lrparam.add_(d_p, alpha=alpha)
SGD上引入了一个Momentum(又叫Heavy Ball)的改进。

load_state_dict
加载优化器状态。
def load_state_dict(self, state_dict):# deepcopy, to be consistent with module APIstate_dict = deepcopy(state_dict)# Validate the state_dictgroups = self.param_groupssaved_groups = state_dict['param_groups']if len(groups) != len(saved_groups):raise ValueError("loaded state dict has a different number of ""parameter groups")param_lens = (len(g['params']) for g in groups)saved_lens = (len(g['params']) for g in saved_groups)if any(p_len != s_len for p_len, s_len in zip(param_lens, saved_lens)):raise ValueError("loaded state dict contains a parameter group ""that doesn't match the size of optimizer's group")# Update the stateid_map = {old_id: p for old_id, p inzip(chain.from_iterable((g['params'] for g in saved_groups)),chain.from_iterable((g['params'] for g in groups)))}def cast(param, value):r"""Make a deep copy of value, casting all tensors to device of param."""if isinstance(value, torch.Tensor):# Floating-point types are a bit special here. They are the only ones# that are assumed to always match the type of params.if param.is_floating_point():value = value.to(param.dtype)value = value.to(param.device)return valueelif isinstance(value, dict):return {k: cast(param, v) for k, v in value.items()}elif isinstance(value, container_abcs.Iterable):return type(value)(cast(param, v) for v in value)else:return value# Copy state assigned to params (and cast tensors to appropriate types).# State that is not assigned to params is copied as is (needed for# backward compatibility).state = defaultdict(dict)for k, v in state_dict['state'].items():if k in id_map:param = id_map[k]state[param] = cast(param, v)else:state[k] = v
state_dict
以字典的形式返回优化器的状态。
def state_dict(self): # Save order indices instead of Tensorsparam_mappings = {}start_index = 0def pack_group(group):nonlocal start_indexpacked = {k: v for k, v in group.items() if k != 'params'}param_mappings.update({id(p): i for i, p in enumerate(group['params'], start_index)if id(p) not in param_mappings})packed['params'] = [param_mappings[id(p)] for p in group['params']]start_index += len(packed['params'])return packedparam_groups = [pack_group(g) for g in self.param_groups]# Remap state to use order indices as keyspacked_state = {(param_mappings[id(k)] if isinstance(k, torch.Tensor) else k): vfor k, v in self.state.items()}return {'state': packed_state,'param_groups': param_groups,}
相关文章:
小白学Pytorch系列--Torch.optim API Base class(1)
小白学Pytorch系列–Torch.optim API Base class(1) torch.optim是一个实现各种优化算法的包。大多数常用的方法都已得到支持,而且接口足够通用,因此将来还可以轻松集成更复杂的方法。 如何使用优化器 使用手torch.optim您必须构造一个优化器对象&…...

flac格式如何转mp3,3招帮你搞定
flac格式如何转mp3,3招帮你搞定的方法来啦。当你的音频是flac格式是不是很头疼,又不知道怎么转mp3 。然后网上搜索出很多方法又不知道从哪个下手,是不是很疑惑?那今天就来看看小编推荐的方法吧,一定让你眼前一亮&#…...
Redis入门到入土(day01)
NoSQL概述 为什么用NoSQL 1、单机MySQL的美好年代 在90年代,一个网站的访问量一般不大,用单个数据库完全可以轻松应付! 在那个时候,更多的都是静态网页,动态交互类型的网站不多。 上述架构下,我们来看看…...
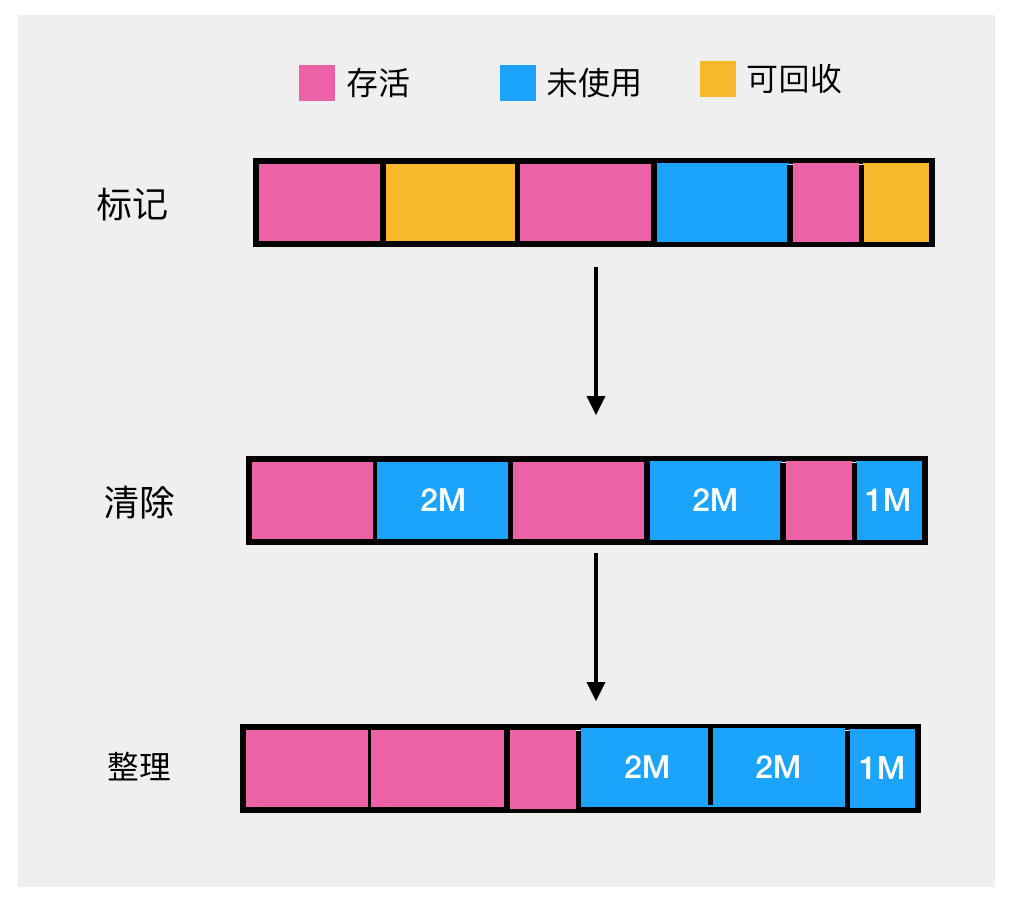
JVM垃圾回收GC 详解(java1.8)
目录 垃圾判断算法(你是不是垃圾?) 引用计数法 可达性算法 对象的引用 强引用 软引用 弱引用 虚引用 对象的自我救赎 垃圾回收算法--分代 标记清除算法 复制算法 标记整理法 垃圾处理器 垃圾判断算法(你是不是垃圾&…...

Mybatis-Plus -03 Mybatis-Plus实现CRUD
Mybatis-Plus实现CRUD 1 Insert增加2 ID生成策略3 Delete删除4 逻辑删除5 Update修改6 Select查询 Mybatis-Plus实现CRUD 通用 CRUD 封装**BaseMapper (opens new window)**接口,为 Mybatis-Plus 启动时自动解析实体表关系映射转换为 Mybatis 内部对象注入容器参数 …...

综合能源系统中基于电转气和碳捕集系统的热电联产建模与优化研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
“智慧赋能 强链塑链”|工程物资供应链管理中的数字化应用
工程项目中的供应链管理至关重要 工程建设行业是国民经济的重要支柱之一,虽然在总产值上持续保持增长态势,但近年来行业的利润总额增速已连续多年呈现下降趋势。究其原因,可以大体从两个方面来看:一是行业盈利能力出现下降&#x…...

通过docker发布项目
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言例如:docker项目的发布方式 [docker发布的参考链接](https://www.cnblogs.com/emperorking/articles/11244253.html) 一、docker是什么?…...
为什么Spring和IDEA不推荐使用@Autowired注解?
在Spring开发中,Autowired注解是一个常用的依赖注入方式。但是,你可能会惊奇地发现,Spring和IDEA都不推荐使用Autowired注解。关于这个问题,其实答案相对统一,实际上用大白话说起来也容易理解。 官方答案 首先&#…...
windows下运行dpdk下的helloworld
打开“本地安全策略”管理单元,在搜索框输入secpol。 打开本地策略->用户权限分配->锁定内存页->添加用户或组->高级->立即查找 输入电脑用户名,选择并添加。点击确定后,重启电脑。 安装内核驱动,下载地址https://download.csdn.net/download/qq_36314864…...
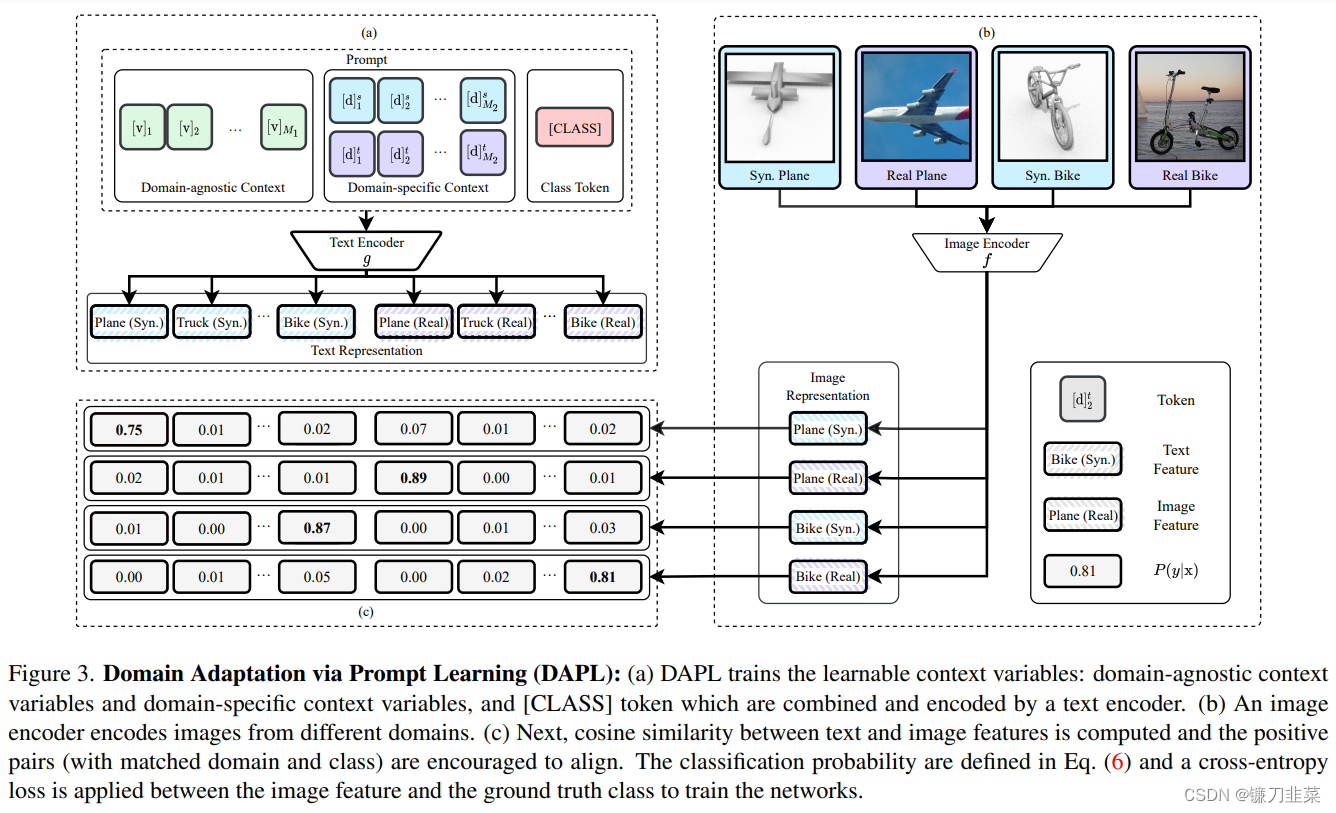
【AI理论学习】深入理解Prompt Learning和Prompt Tuning
深入理解Prompt Learning和Prompt Tuning 背景Prompt Learning简介1. Prompt是什么?2. 为什么要使用Prompt?3. Prompt Learning的形式(举例)4. 有哪些Pre-training language model?5. 常见的Prompt Learning的方法 Pro…...

从Authy中导出账户和secret
本文转载于我的博客从Authy中导出账户和secret 前言 因为最近买了CanoKey,所以多算试一下CanoKey的TOTP功能,但是之前一直用的Authy并且它默认不支持导出功能 在网上找了一些文档,终于在github上找到了一个有效且简单的方法 目前网上大部分…...

图像锐度评分算法,方差,点锐度法,差分法,梯度法
图像锐度评分算法,方差,点锐度法,差分法,梯度法 图像锐度评分是用来描述图像清晰度的一个指标。常见的图像锐度评分算法包括方差法、点锐度法、差分法和梯度法等。 方差法:该方法是通过计算图像像素值的方差来评估图像…...

查询练习:连接查询
准备用于测试连接查询的数据: CREATE DATABASE testJoin;CREATE TABLE person (id INT,name VARCHAR(20),cardId INT );CREATE TABLE card (id INT,name VARCHAR(20) );INSERT INTO card VALUES (1, 饭卡), (2, 建行卡), (3, 农行卡), (4, 工商卡), (5, 邮政卡); S…...

【mmdeploy】【TODO】使用mmdeploy将mmdetection模型转tensorrt
mmdetection转换 文章目录 mmdetection转换mmdetection 自带转换ONNX——无法测试使用mmdeploy(0.6.0)使用mmdeploy转onnx使用mmdeploy直接转tensorRT调试记录 先上结论:作者最后是转tensorrt的小图才成功的,大图一直不行。文章仅作者自我记录使用&#…...

德赛西威上海车展重磅发布Smart Solution 2.0,有哪些革新点?
4月18日,全球瞩目的第二十届上海车展盛大启幕,作为国际领先的移动出行科技公司,德赛西威携智慧出行黑科技产品矩阵亮相,并以“智出行 共创享”为主题,重磅发布最新迭代的智慧出行解决方案——Smart Solution 2.0。 从…...

戴尔服务器是否需要开启cpupower.service
戴尔并不会默认开启cpupower.service,这取决于具体的操作系统和配置。cpupower.service是一个Linux系统服务,用于管理CPU的功耗和性能调节,可以通过调整CPU的频率和电源管理策略来降低能耗和温度。在某些情况下,开启cpupower.serv…...
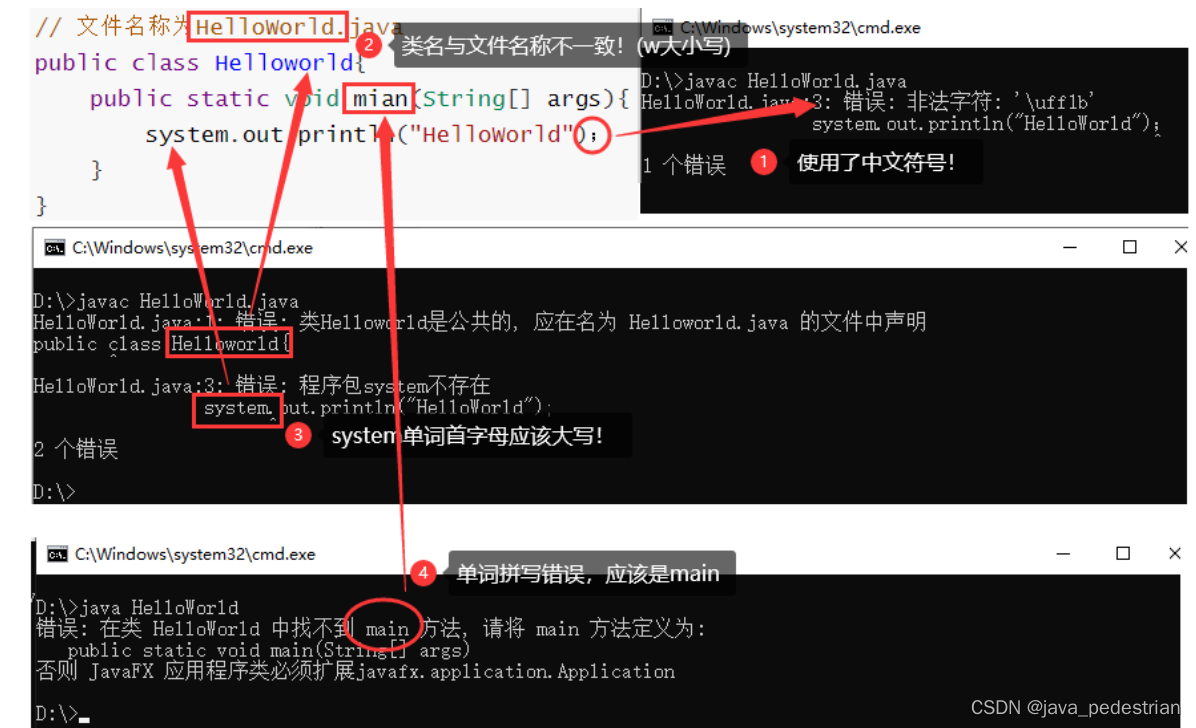
day02_第一个Java程序
在开发第一个Java程序之前,我们必须对计算机的一些基础知识进行了解。 常用DOS命令 Java语言的初学者,学习一些DOS命令,会非常有帮助。DOS是一个早期的操作系统,现在已经被Windows系统取代,对于我们开发人员…...
 | 机试题+算法思路+考点+代码解析)
【华为OD机试真题 】1011 - 第K个排列 (JAVA C++ Python JS) | 机试题+算法思路+考点+代码解析
文章目录 一、题目🔸题目描述🔸输入输出🔸样例1🔸样例2二、代码参考🔸C++代码🔸Java代码🔸Python代码🔸JS代码作者:KJ.JK🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🍂个人博客首页: KJ.JK 💖系列专栏:...

基于php的校园校园兼职网站的设计与实现
摘要 近年来,信息技术在大学校园中得到了广泛的应用,主要体现在两个方面:一是学校管理系统,包括教务管理、行政管理和分校管理,是我国大学管理和信息传递的主要渠道。二是学生生活服务平台。而随着大学生毕业人数的年…...

Claude Desktop for Linux桌面集成:.desktop文件与MIME类型配置
Claude Desktop for Linux桌面集成:.desktop文件与MIME类型配置 【免费下载链接】claude-desktop-debian Claude Desktop for Linux 项目地址: https://gitcode.com/GitHub_Trending/cl/claude-desktop-debian Claude Desktop for Linux是一款强大的桌面应用…...

三年级下册语文第三单元作文:我做了一个小实验300字
三年级下册语文《我做了一个小实验》作文,重点要写清楚:做了什么实验实验前准备了什么实验过程看到了什么变化明白了什么道理我用夸克网盘分享了「三年级下册语文作文」,1-8单元。链接:https://pan.quark.cn/s/a80b7ca7f993这类作…...

神州细胞递表港交所 创新生物制药领军者构筑A+H双平台全球化版图
5月22日,北京神州细胞生物技术集团股份公司(证券代码:688520,证券简称:神州细胞)正式向香港联合交易所有限公司递交上市申请,迈出“AH”双资本平台布局的关键一步。公司以科创板上市为根基&…...

DeepSeek LeetCode 2561. 重排水果 Java实现
LeetCode 2561. 重排水果题目分析有两个长度为 n 的数组 basket1 和 basket2,每个数组包含若干水果。每次操作可以交换两个数组中的任意水果,花费为这两个水果中较小的那个值。目标是使两个数组中的水果种类和数量完全相同(即两个数组重排后相…...

商业空间吸音地毯怎么选?16 年品牌雅尔居靠谱
商业空间装修,噪音控制是刚需。办公室人声嘈杂、酒店走廊脚步声扰客、工装大堂回音重,都会直接影响空间体验与使用效率。选对吸音地毯,既能高效降噪,又能提升空间质感,是商业空间地面材料的优选。今天就来聊聊吸音地毯…...

如何快速配置FanControl风扇控制:从安装到优化的完整指南
如何快速配置FanControl风扇控制:从安装到优化的完整指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...

可控硅调光原理与舞台照明系统设计实战:以LTH16-08为例
1. 项目概述:舞台照明系统与可控硅的深度绑定在舞台、演播厅、剧场这些光影变幻的现场,每一束光的明暗、每一次色彩的渐变,背后都有一套精密、可靠且响应迅速的调光系统在支撑。从业十多年,我调试过无数灯光设备,深知其…...

三国杀卡牌DIY终极指南:5分钟打造你的专属武将
三国杀卡牌DIY终极指南:5分钟打造你的专属武将 【免费下载链接】Lyciumaker 在线三国杀卡牌制作器 项目地址: https://gitcode.com/gh_mirrors/ly/Lyciumaker 还在羡慕别人能设计出酷炫的三国杀武将卡牌吗?Lyciumaker这个免费开源的三国杀卡牌制作…...
)
保姆级教程:用vsomeip实现一个简单的车内服务发现与通信(附C++代码)
车载通信实战:基于vsomeip的服务发现与消息交互全流程解析 在智能座舱与自动驾驶技术快速迭代的今天,车载电子控制单元(ECU)间的可靠通信成为系统设计的核心挑战。SOME/IP作为汽车电子领域广泛采用的通信协议,其开源实…...

【.NET新特性·第2篇】C# 12 全特性回顾:语法糖的盛宴
C# 12 带来了主构造函数、集合表达式、Inline Arrays 等 8 个新特性,让代码更简洁 版本定位 适用版本:.NET 8 | C# 12 前置知识:C# 11 基础语法 背景 C# 11 引入了原始字符串字面量、list patterns 等特性,但开发者们期待更多语法…...