【AI理论学习】深入理解Prompt Learning和Prompt Tuning
深入理解Prompt Learning和Prompt Tuning
- 背景
- Prompt Learning简介
- 1. Prompt是什么?
- 2. 为什么要使用Prompt?
- 3. Prompt Learning的形式(举例)
- 4. 有哪些Pre-training language model?
- 5. 常见的Prompt Learning的方法
- Prompt Tuning的策略
- 1. Fine-turn的策略
- 2. NLP中基于Prompt的fine-tune
- 3. CV中基于Prompt的fint-tune
- 1. 分类
- 2. 持续学习
- 3. 多模态模型
- 1. Vision-Language Model: Context Optimization (CoOp)
- 2. Conditional Prompt Learning for Vision-Language Models
- 4. 域适应
- Domain Adaptation via Prompt Learning
- 内容来源
- 参考文献
近年来NLP学术领域发展真是突飞猛进,从 对比学习(
contrastive learning)到现在的
提示学习(prompt learning)。自从Self-Attention 和 Transformer出现以来,它们就成为了NLP领域的热点。由于全局注意力机制和并行化的训练策略,基于Transformer的自然语言模型能够方便地编码长距离依赖关系,同时可以在大规模自然语言数据集上进行并行化训练。
众所周知,数据标注数据很大程度上决定了AI算法上限,并且成本非常高,无论是对比学习还是提示学习都着重解决少样本学习而提出,甚至在没有标注数据的情况下,也能让模型表现比较好的效果。而且由于自然语言处理领域任务种类繁多,而且任务之间的差别微小,所以为每个任务单独创建一个大语言模型很不划算。与此同时,在CV中,不同的图像识别任务往往也需要微调整个大模型。
因此,Prompt Learning的提出给这个问题提供了一个很好的方向。本文主要介绍prompt learning的基本思想和目前常用的方法。
背景
(1)基于传统机器学习模型:在以往的机器学习方法中,基本上都是基于全监督学习(fully supervised learning)的方法。然而,由于监督学习需要大量的数据学习性能优异的模型,而NLP中为特定任务标注的数据集往往是不足的,因此在深度学习出现之前研究者通常聚焦于特征工程(feature engineering),即利用领域知识从数据中提取好的特征;在这一阶段的方法例如tf-idf特征+朴素贝叶斯等机器算法;
(2)基于深度学习模型: 深度学习出现之后,由于可以从数据中得到隐含的特征,因此研究人员转向了结构工程(architecture engineering),即通过设计一个合适的网络结构来把归纳偏置(inductive bias)引入模型中,从而有利于学习好的特征。例如word2vec 特征 + LSTM 等深度学习算法,相比于传统方法,模型准确有所提高,特征工程的工作也有所减少;
(3)基于预训练模型 + finetuning: 自从BERT出现之后,NLP研究者开始转向另一个新的模式,即预训练 + 微调(pre-train and fine-tune)。在这个模式中, 先用一个固定的结构预训练一个语言模型(language model, LM),预训练的方式就是让模型补全上下文(比如完形填空)。相比于深度学习模型,模型准确度显著提高,但是模型也随之变得更大,但小数据集就可训练出好模型;
(4)基于预训练模型 + Prompt + 预测的方法:在预训练的过程中,由于不需要专家知识,因此可以在网络上搜集的大规模文本上直接进行训练。然后这个LM通过引入额外的参数或微调来适应到下游任务上。这就逐渐形成了目标工程(objective engineering),即为预训练任务和微调任务设计更好的目标函数。
可以发现,整个NLP领域是朝着精度更高、少监督,甚至无监督的方向发展的,而Prompt Learning是目前学术界向这个方向进军最新也是最火的研究成果。
Prompt Learning简介
1. Prompt是什么?
预训练模型中存在大量知识;预训练模型本身具有少样本学习能力。GPT-3 提出的In-Context Learning,也有效证明了在Zero-shot、Few-shot场景下,模型不需要任何参数,就能达到不错的效果,特别是近期很火的GPT3.5系列中的ChatGPT。
在做objective engineering的过程中,研究者发现让下游任务的目标与预训练的目标对齐是有好的。因此下游任务通过引入文本提示符(textual prompt),把原来的任务目标重构为与预训练模型一致的填空题。
比如一个输入 “I missed the bus today.” 的重构:
- 情感预测任务。输入:“I missed the bus today. I felt so___.” 其中 “I felt so” 就是提示词(prompt),然后使用 LM 用一个表示情感的词填空。
- 翻译任务。输入:“English: I missed the bus today. French: ___.” 其中 “English:” 和 “French:” 就是提示词,然后使用 LM 应该再空位填入相应的法语句子。
用不同的prompt加到相同的输入上,就能实现不同的任务,从而使得下游任务可以很好的对齐到预训练任务上,实现更好的预测效果。然而,有研究表明,在同一个任务上使用不同的 prompt,预测效果也会有显著差异,因此现在有许多研究开始聚焦于prompt engineering。
因此,Prompt Learning 的本质是将所有下游任务统一成预训练任务;以特定的模板,将下游任务的数据转成自然语言形式,充分挖掘预训练模型本身的能力。即设计一个比较契合上游预训练任务的模板,通过模板的设计就是挖掘出上游预训练模型的潜力,让上游的预训练模型在尽量不需要标注数据的情况下比较好的完成下游的任务。Prompt Learning关键包括三个步骤:
- 设计预训练语言模型的任务
- 设计输入模板样式(Prompt Engineering)
- 设计label样式,以及模型的输出映射到label的方式(Answer Engineering)
2. 为什么要使用Prompt?
先从Prompt Learning之前的学习模式来分析,即预训练模型PLM+finetuning范式,常用的是BERT+finetuning。如下图所示:
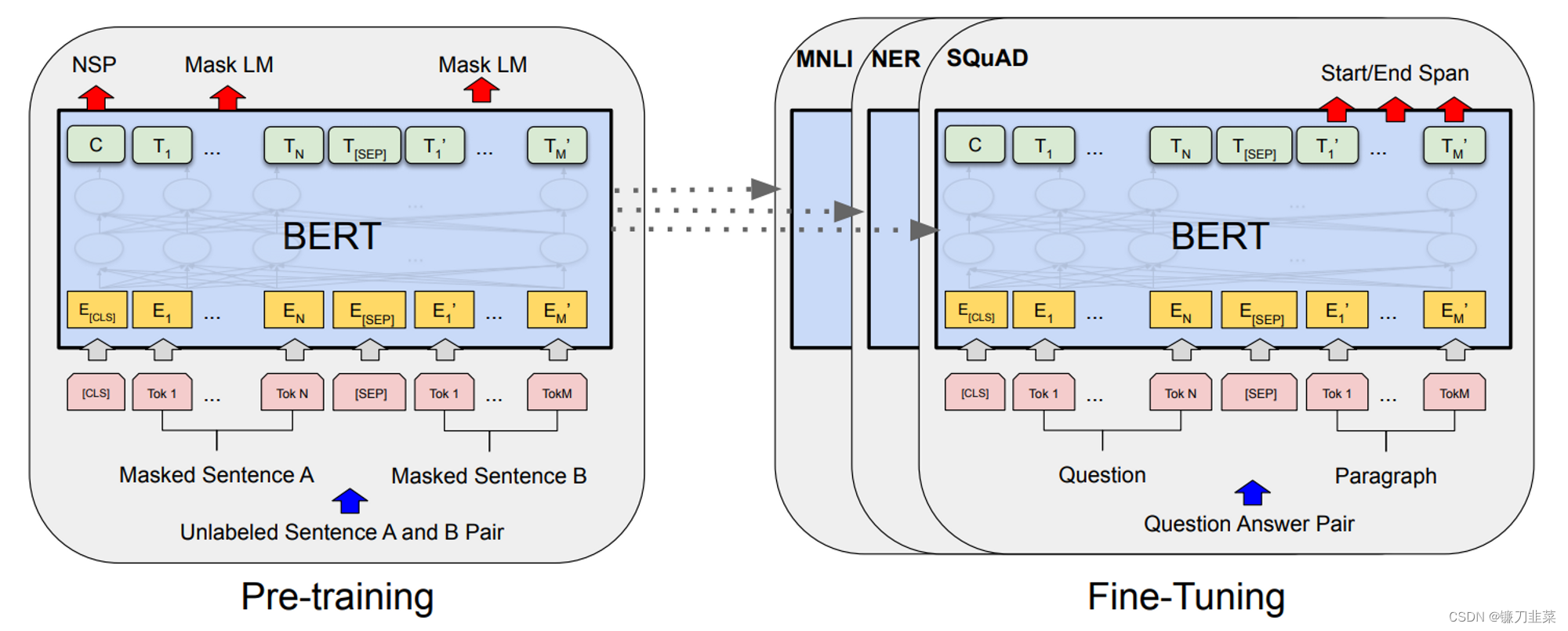
这种学习模式是想要预训练模型更好的应用在下游任务,需要利用下游数据对模型参数微调;首先,模型在预训练的时候,采用的训练形式:自回归、自编码,这与下游任务形式存在极大的gap,不能完全发挥预训练模型本身的能力。必然导致:较多的数据来适应新的任务形式——>少样本学习能力差、容易过拟合。

其次,现在的预训练模型参数量越来越大,为了一个特定的任务去 finetuning 一个模型,然后部署于线上业务,也会造成部署资源的极大浪费。
3. Prompt Learning的形式(举例)
- 以电影评论情感分类任务为例,模型需根据输入句子做二分类:
「原始输入」:特效非常酷炫,我很喜欢。
「Prompt输入」:- 「提示模板1」: 特效非常酷炫,我很喜欢。这是一部[MASK]电影;
- 「提示模板2」: 特效非常酷炫,我很喜欢。这部电影很[MASK]
提示模板的作用就在于:将训练数据转成自然语言的形式,并在合适的位置 MASK,以激发预训练模型的能力。
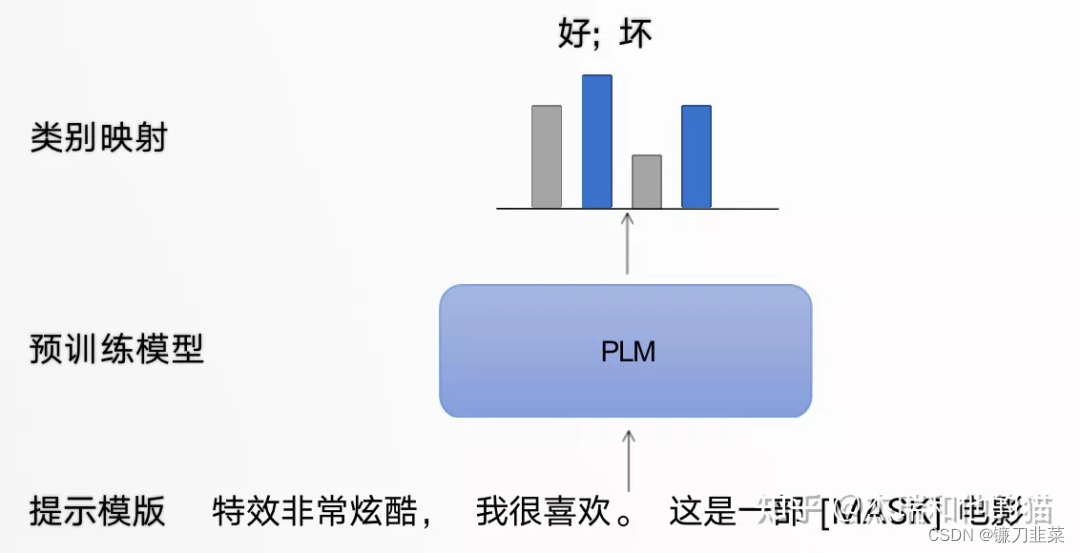
- 类别映射/Verbalizer:选择合适的预测词,并将这些词对应到不同的类别。
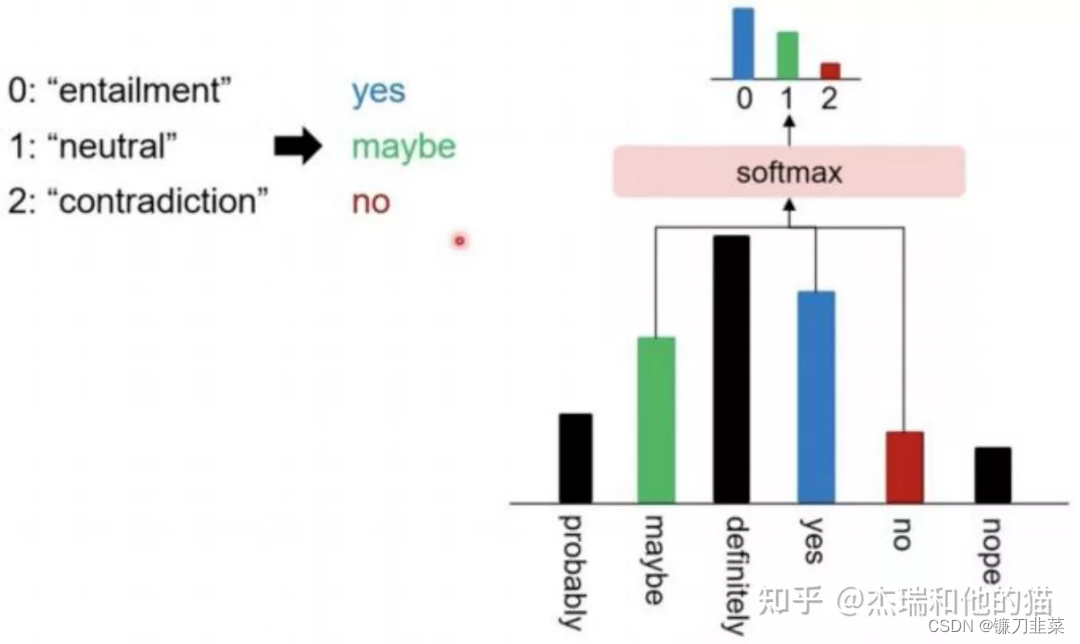
通过构建提示学习样本,只需要少量数据的Prompt Tuning,就可以实现很好的效果,具有较强的零样本/少样本学习能力。
4. 有哪些Pre-training language model?
Left-to-Right LM: GPT, GPT-2, GPT-3Masked LM: BERT, RoBERTaPrefix LM: UniLM1, UniLM2Encoder-Decoder: T5, MASS, BART
5. 常见的Prompt Learning的方法
- 按照 prompt 的形状划分:完形填空式,前缀式。
- 按照人的参与与否:人工设计的,自动的(离散的,连续的)
 人工设计的 Prompt
人工设计的 Prompt
Prompt Tuning的策略
1. Fine-turn的策略
在下游任务上微调大规模预训练模型已经成为大量NLP和CV任务常用的训练模式。然而,随着模型尺寸和任务数量越来越多,微调整个模型的方法会储存每个微调任务的模型副本, 消耗大量的储存空间。尤其是在边缘设备上存储空间和网络速度有限的情况下,共享参数就变得尤为重要。
一个比较直接的共享参数的方法是只微调部分参数,或者向预训练模型中加入少量额外的参数。比如,对于分类任务:
Linear:只微调分类器 (一个线性层), 冻结整个骨干网络。Partial-k:只微调骨干网络最后的 k 层, 冻结其他层。MLP-k:增加一个 k 层的 MLP 作为分类器。Side-tuning:训练一个 “side” 网络,然后融合预训练特征和 “side” 网络的特征后输入分类器。Bias:只微调预训练网络的 bias 参数。Adapter:通过残差结构,把额外的MLP模块插入Transformer。
另一种方式是使用Transformer。近年来,Transformer模型在NLP和CV上大放异彩。基于Transformer的模型在大量CV任务上已经比肩甚至超过基于卷积的模型。
Transformer 与 ConvNet 比较:Transformer 相比于 ConvNet 的一个显著的特点是:它们在对于空间(时间)维度的操作是不同的。
ConvNet:卷积核在空间维度上执行卷积操作,因此空间内不同位置的特征通过卷积(可学习的)操作融合信息, 且只在局部区域融合。Transformer:空间(时间)维度内不同位置的特征通过 Attention(非学习的)操作融合信息,且在全局上融合。
Transformer在特征融合时非学习的策略使得其很容易的通过增加额外的 feature 来扩展模型。
2. NLP中基于Prompt的fine-tune
- Prefix-Tuning
- Prompt-Tuning
- P-Tuning
- P-Tuning-v2
3. CV中基于Prompt的fint-tune
1. 分类
Visual Prompt Tuning

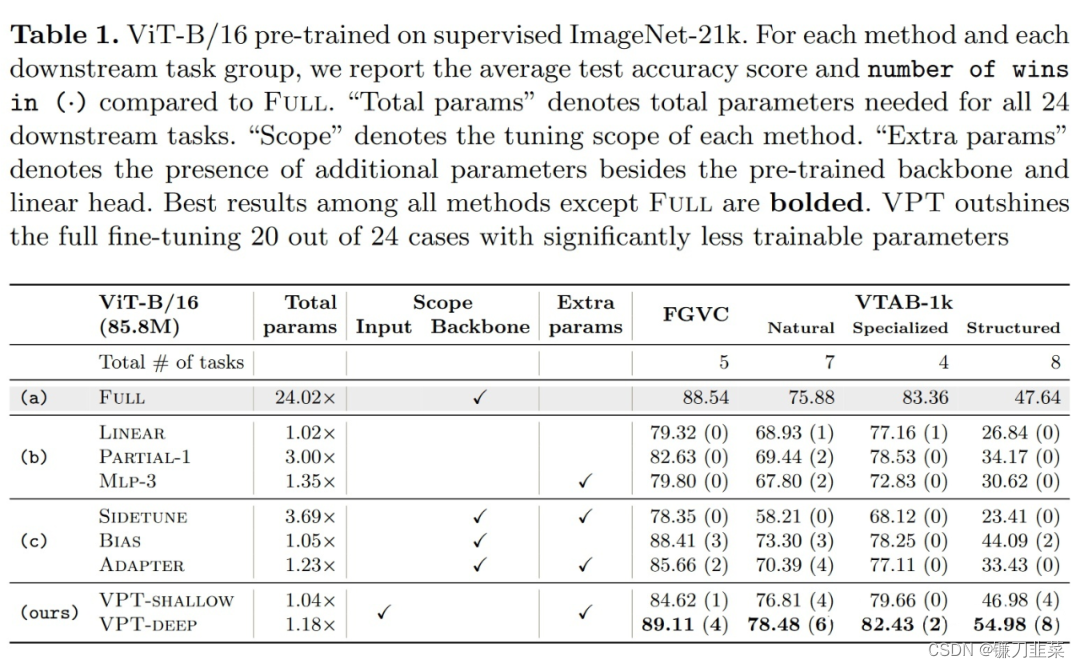
目前调整预训练模型的工作方式包括更新所有骨干参数,即全面微调(full fine-tuning)。本文介绍了Visual Prompt Tuning(VPT),它是视觉中大型Transformer模型full fine-tuning的一种有效替代方案。VPT从有效调整大型语言模型的最新进展中获得灵感,在输入空间中只引入少量(不到模型参数的1%)可训练参数,同时保持模型主干冻结。通过对各种下游识别任务的大量实验,表明,与其他参数有效的调优协议相比,VPT实现了显著的性能提升。最重要的是,在许多情况下,在模型容量和训练数据规模方面,VPT甚至优于完全微调,同时降低了每个任务的存储成本。
论文地址:https://arxiv.org/abs/2203.12119
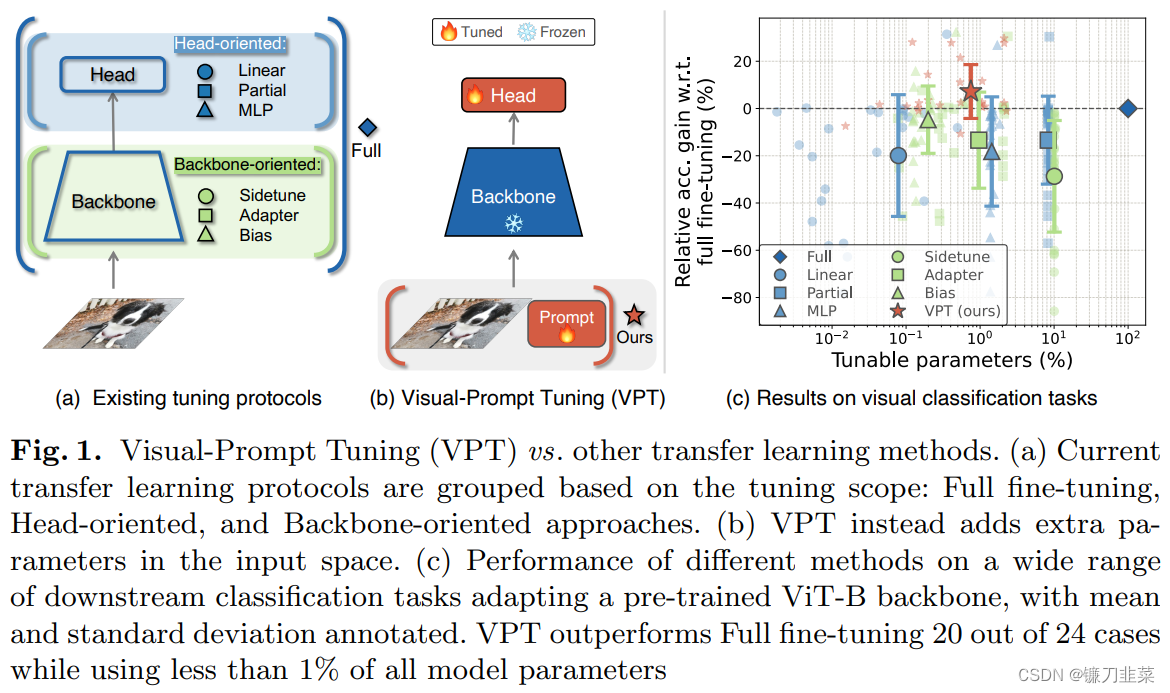
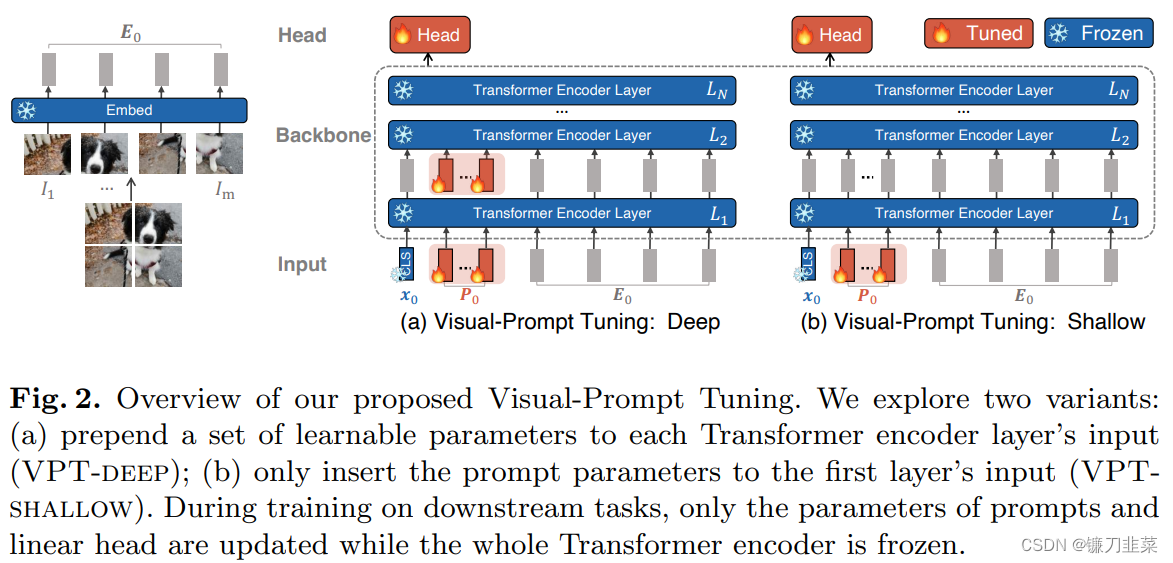
给定一个预先训练好的Transformer,在Embed层后的输入空间引入一组d维的p个连续embedding,即prompts。在微调过程中,只有prompts会被更新,主干将会冻结,根据加入prompts的层的数量分为VPT-shallow和VPT-deep。
(1)VPT-Shallow:Prompts仅插入第一层。每一个prompt token都是一个可学习的d维参数。shallow-prompted ViT表示如下:
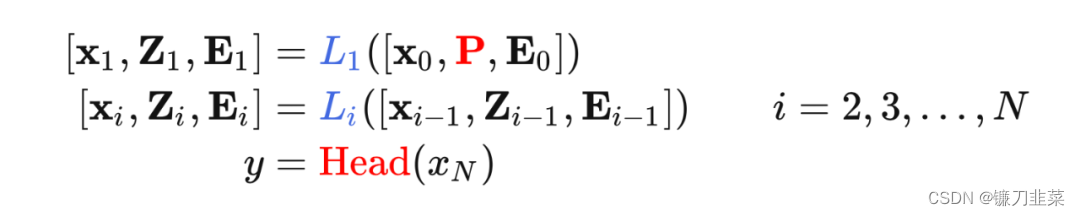
(2)VPT-Deep:Prompt被插入到每一个Transformer layer的输入空间。deep-prompted ViT表示如下:
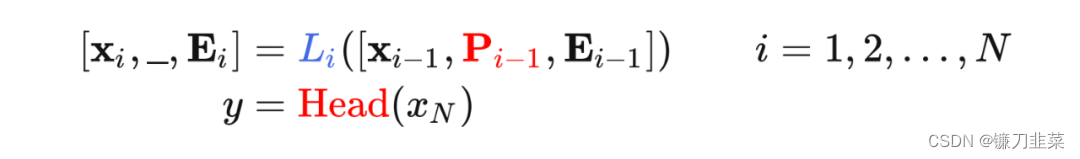
2. 持续学习
Learning to Prompt for Continue Learning

持续学习背后的主流范式是将模型参数调整到非平稳数据分布中,灾难性遗忘是核心挑战。典型的方法依赖于测试时间的彩排缓冲区或已知的任务标识来检索学习的知识和地址遗忘,而这项工作为持续学习提供了新的范式,旨在训练更简洁的记忆系统而不在测试时间访问任务身份。我们的方法学会了动态提示dynamically prompt(L2P)一个预训练的模型,以在不同的任务转换下依次学习任务。在我们提出的框架中,提示是小的可学习参数,可维持在记忆空间中。目的是优化提示,以指导模型预测,并在维持模型可塑性的同时明确管理任务不变和特定于任务的知识。我们在流行的图像分类基准下进行全面的实验,并具有不同的挑战性持续学习设置,其中L2P始终优于先前的最新方法。令人惊讶的是,L2P即使没有排练缓冲液,也可以针对基于排练的方法取得竞争成果,并且直接适用于挑战性的任务无关持续学习。
论文地址:https://doi.org/10.48550/arXiv.2112.08654
代码地址:https://github.com/google-research/l2p
引入一个 prompt pool,对每个 input,从 pool 中取出与其最近的 N 个 prompts 加入 image tokens。input 和 prompts 距离的度量通过计算 input feature 和每个 prompt 的 key 的距离来得到,这些 key 通过梯度随分类目标一起优化。
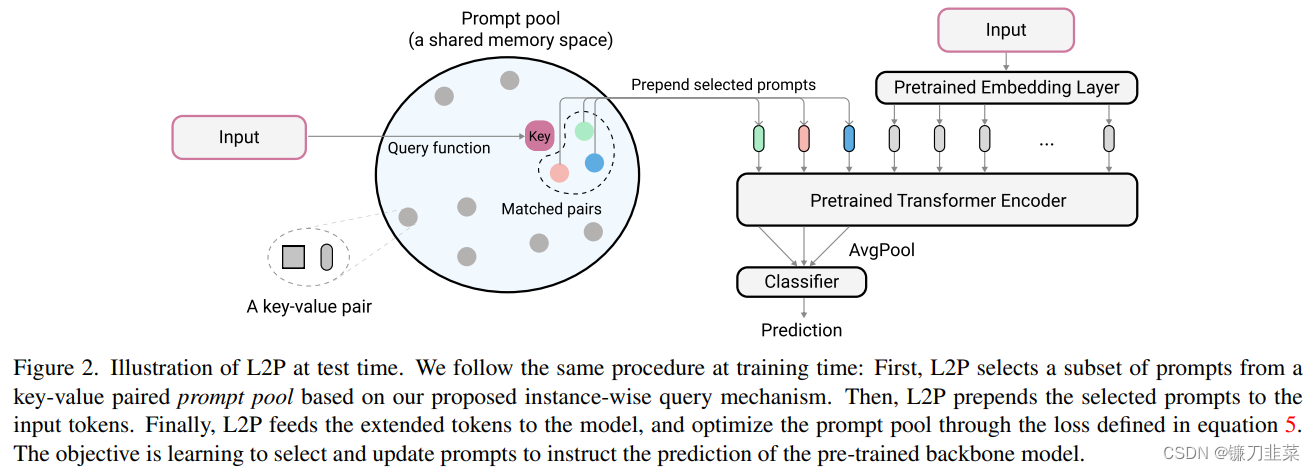
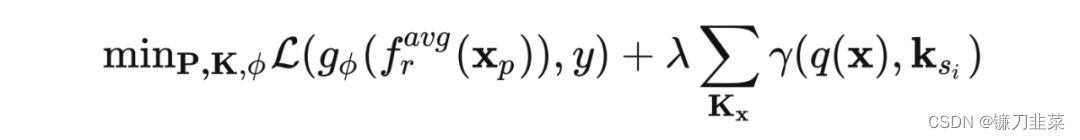
注意,最后使用 prompt 来分类。
3. 多模态模型
1. Vision-Language Model: Context Optimization (CoOp)

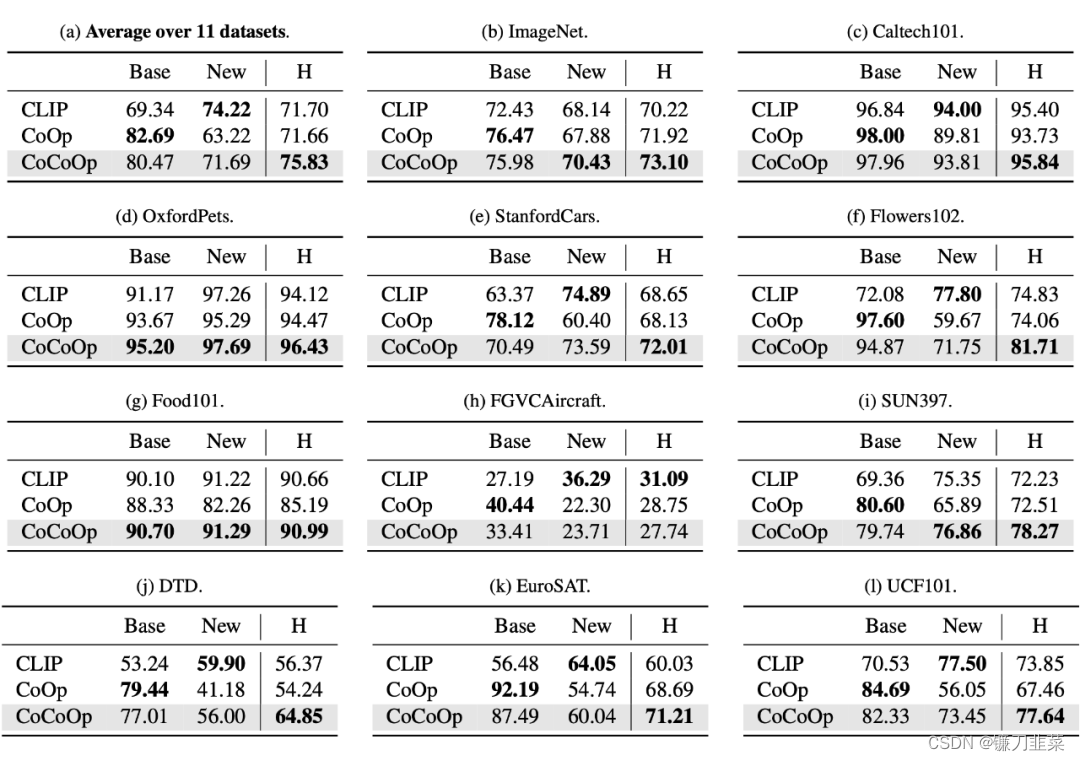
大预训练视觉-语言模型(如CLIP)学得的表征可以迁移到广泛的下游任务上,展现出了巨大的潜力。不同于传统的从离散的标签中进行表征学习,视觉-语言预训练在一个共同的特征空间中对齐图像和文本,这样就可以通过prompting的方式实现下游任务的zero-shot transfer,比我们可以通过语言来描述物体而获取分类的权重。这篇文章展示了在实际应用中prompt engineering(提示工程)存在很大的挑战,因为提示工程往往需要专业知识并且很耗时间去设计。作者受到NLP中的prompt learning的启发,提出Context Optimization(CoOp)。CoOp是一个将CLIP之类的视觉-语言预训练模型适应到下游任务上的方法。具体地,CoOp用可学的向量来model prompt中的单词,而整个过程中预训练模型的参数都是固定的。为了解决不同的图像识别任务,作者提供了CoOp的两种实现:unified context和class-specific context。作者在11个下游任务上验证CoOp的有效性,结果显示CoOp的性能明显好于原始预训练模型如CLIP。
论文地址:https://arxiv.org/abs/2109.01134
多模态学习的预训练模型。比如CLIP,通过对比学习对齐文本和图像的特征空间,如下图所示:
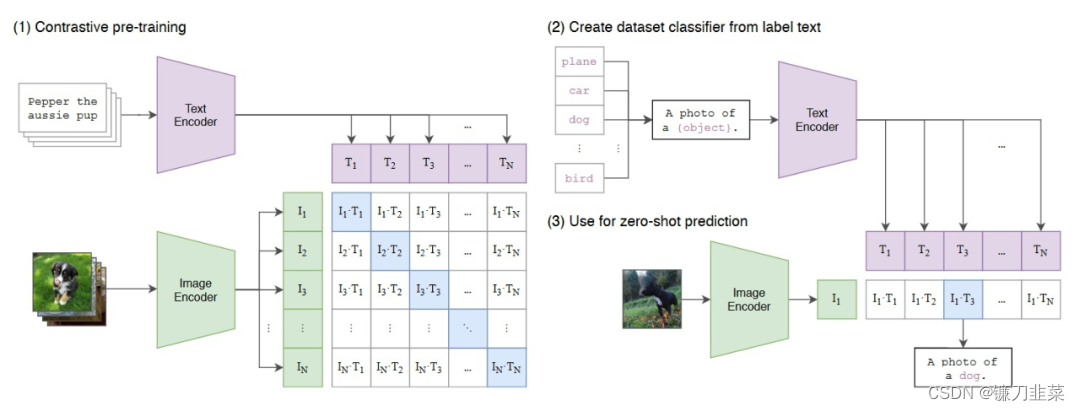
在CLIP在zero-shot预测中,text encoder输入的text是固定的,如“A photo of a {object}.”。而在CoOp中,输入的text是learnable,随着在下游任务的few-shot样本而更新。
选择不同的文本 prompt 对于精度影响较大。一张图其实可能有多种描述,比如一张猫的图像可能的描述:“一个猫。”,“一张猫的照片。”,“这是一只猫。”等。其实CLIP原文中,其作者发现了这个问题,并且发现prompt对预测性能的影响还挺大,于是还做了prompt ensembling。CoOp其实就是为了研究这个问题,就是说我们能不能不要手工设计prompt了,直接learn一个最优的prompt?

Prompt engineering vs Context Optimization (CoOp)
把人工设定的 prompt 替换为 learnable 的 prompt:
- [CLASS]放在后面

- [CLASS] 放在中间:
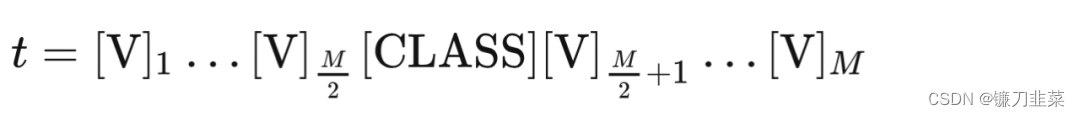
Prompt 可以在不同类之间公用,也可以为每个类使用不同的 prompts(对于细粒度分类任务更有效)。CoOp考虑了两种learnable prompt,第一种是unified context,也就是不管样本是什么类别,其learnable context都是一样的,而第二种则是class-specific context,也就是每个类别都有自己特有的learnable context。
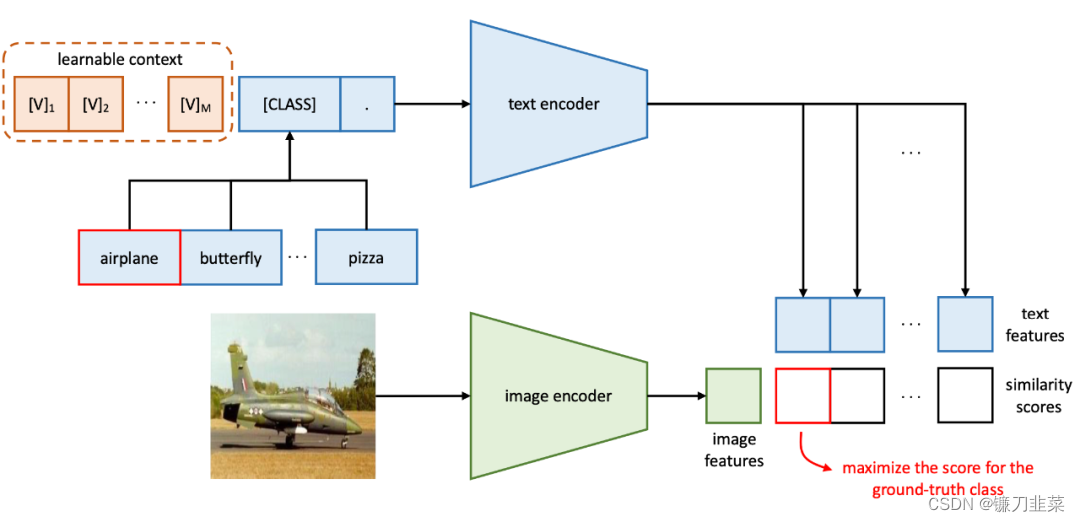
CoOp先在四个数据集上做实验,发现更合理的prompt能够大幅度的提升分类精度尤其是使用了本文提出的CoOp之后,最终的分类精度远超CLIP人为设计的prompt。
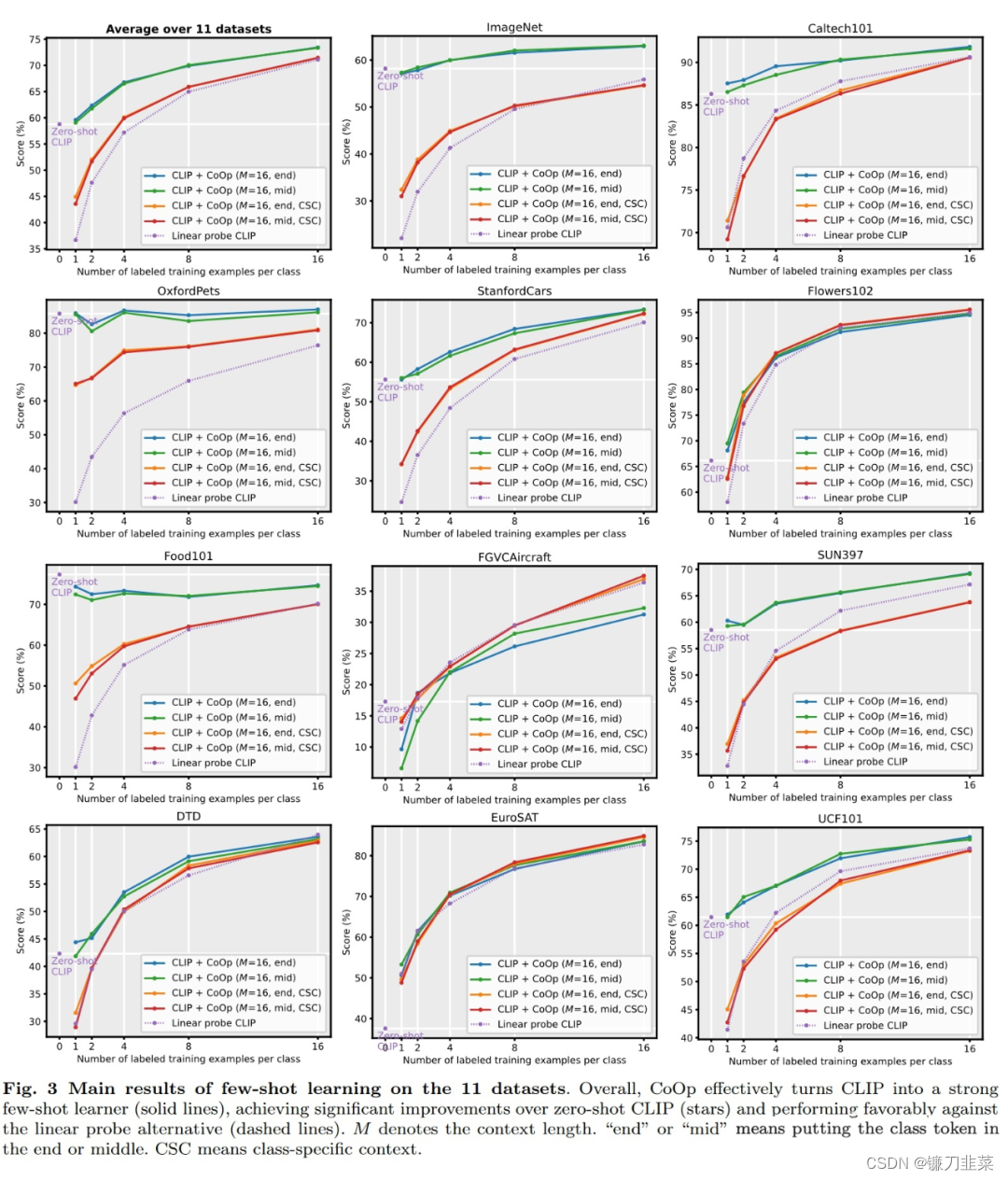
Learning to Prompt for Vision-Language Model
2. Conditional Prompt Learning for Vision-Language Models

随着大规模视觉-语言预训练模型如CLIP展现出的强大表征能力,如何有效地将这些预训练模型adapt到下游任务上变得至关重要。近期的工作CoOp将NLP中的prompt learning的概念初次引入到CV领域以更好地将上述预训练模型adapt到下游任务上。CoOp将原本CLIP中的手动设定的propmt变成learnable vectors,然后只需要借助few-shot labeled images就能带来很大的性能提升。但作者发现CoOp也同时存在一个问题:CoOp中learned context的泛化性不够好,很难泛化到同一个数据集内的unseen classes,这就意味着CoOp在训练时overfit到了base classes上。为了解决此问题,作者提出Conditional Context Optimization (CoCoOp)。CoCoOp在CoOp基础之上引入一个轻量级的神经网络为每张图像生成input-conditional tokens (vectors),这些tokens会加上原本CoOp中的learnable vectors上。相比CoOp中静态的prompt,CoCoOP这种动态的prompt是instance-adaptive的,对于class shift更加鲁棒。实验表明对于unseen class,CoCoOp的泛化性比CoOp好,甚至还展示了有潜力的单数据集迁移性。
论文地址:https://arxiv.org/abs/2203.05557
CoOp 在泛化到新的类别上时性能不好。

To learn generalizable prompts
所以把 prompt 设计为instance-conditional 的。
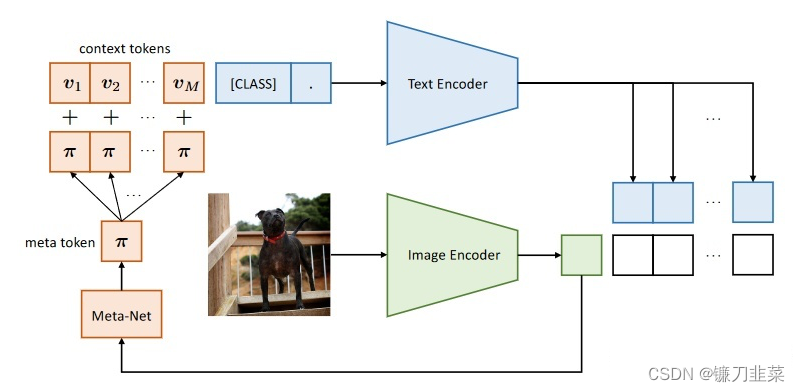
相比于CoOp, CoCoOp增加了一个轻量级的网络(Meta-Net) h θ ( ⋅ ) h_\theta(\cdot) hθ(⋅),Meta-Net的输入是image feature x x x,输出则是一个instance-conditional token π \pi π,然后再在每个context token v m v_m vm上加上 π \pi π。也就是为 prompt 加上一个跟当前图像相关的特征以提高泛化性能。具体来说,先用 Image Encoder 计算当前图像的 feature,然后通过一个 Meta-Net 把 feature 映射到 prompt 的特征空间,加到 prompt 上面。
实验使用的11个数据集和CoOp中的一致。
4. 域适应
Domain Adaptation via Prompt Learning

无监督域适应 (UDA) 旨在将从注释良好的源域学习的模型适应目标域,其中只给出未标记的样本。当前的 UDA 方法通过对齐源和目标特征空间来学习域不变特征。这种对齐是由诸如统计差异最小化或对抗训练等约束所施加的。然而,这些约束可能导致语义特征结构的扭曲和类别可辨别性的丧失。在本文中,我们介绍了一种新颖的 UDA Prompt学习范式,名为Domain Adaptation via Prompt Learning(DAPL)。与之前的工作相比,我们的方法利用了预训练的视觉语言模型,并且只优化了很少的参数。主要思想是将域信息嵌入到prompt中,这是一种由自然语言生成的表示形式,然后用于执行分类。该域信息仅由来自同一域的图像共享,从而根据每个域动态调整分类器。
论文地址:https://arxiv.org/abs/2202.06687
(1)用prompt来标识 domain 的信息。
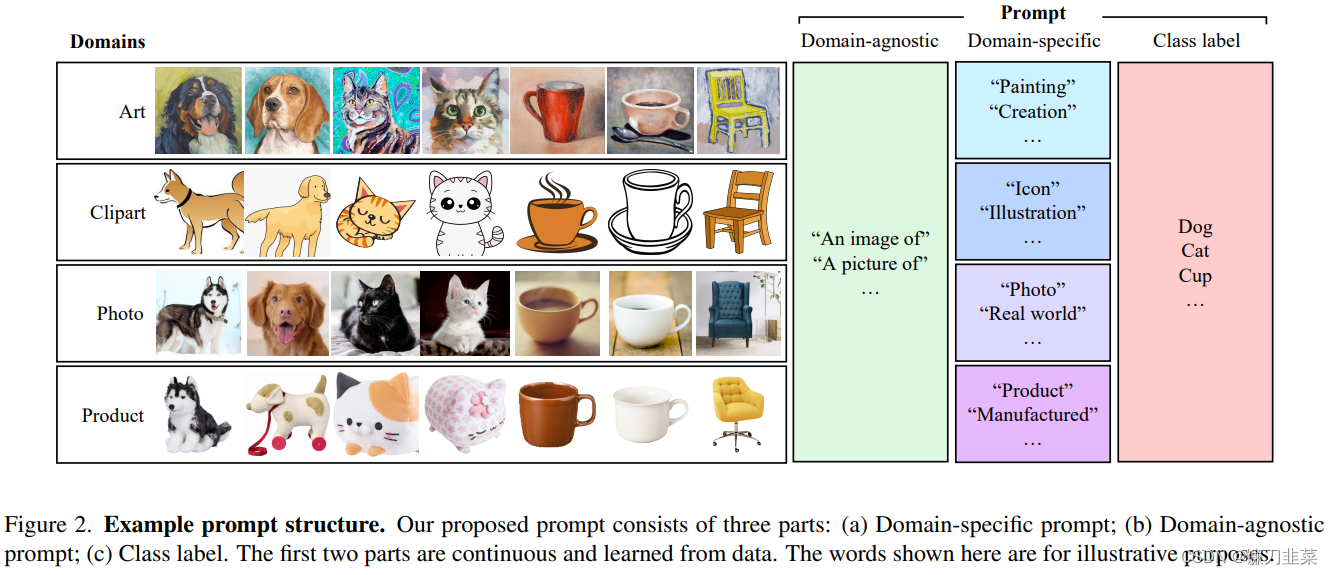
(2)通过对比学习解耦 representation 中的 class 和 domain 的表示。
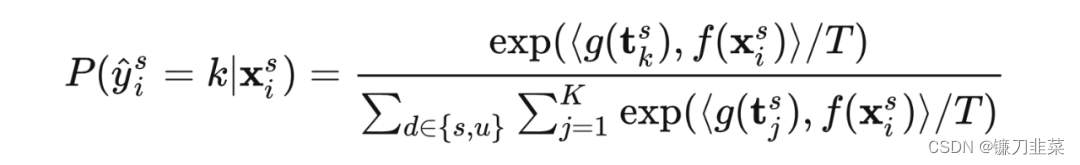
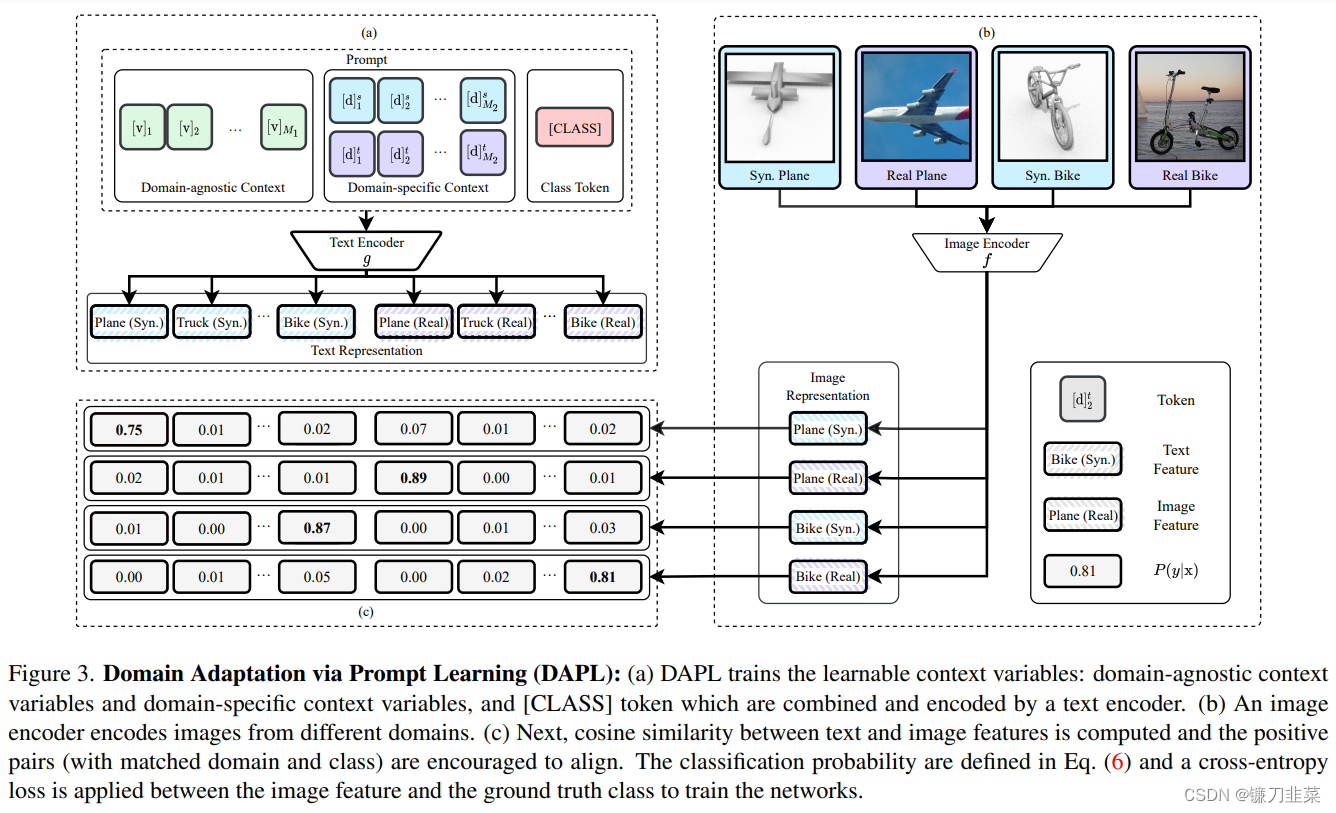
通过采用这种范式,我们表明我们的模型不仅在几个跨域基准测试上优于以前的方法,而且训练效率高且易于实现。
内容来源
- 一文详解Prompt学习和微调(Prompt Learning & Prompt Tuning)
- 《Visual Prompt Tuning》视觉prompt
- 深入浅出提示学习思想要旨 及 常用Prompt方法
- Prompt—从CLIP到CoOp,Visual-Language Model新范式
- CoOp: Learning to Prompt for Vision-Language Models
- CoCoOp: Conditional Prompt Learning for Vision-Language Models
参考文献
[1] Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, Graham Neubig. In arXiv 2021 https://arxiv.org/abs/2107.13586
[2] How transferable are features in deep neural networks? Jason Yosinski, Jeff Clune, Yoshua Bengio, Hod Lipson. In NeruIPS 2014 https://proceedings.neurips.cc/paper/2014/hash/375c71349b295fbe2dcdca9206f20a06-Abstract.html
[3] Masked autoencoders are scalable vision learners. Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick. In arXiv 2021 https://arxiv.org/abs/2111.06377
[4] Side-tuning: a baseline for network adaptation via additive side networks. Jeffrey O. Zhang, Alexander Sax, Amir Zamir, Leonidas Guibas, Jitendra Malik. In ECCV 2020 https://link.springer.com/chapter/10.1007/978-3-030-58580-8_41
[5] Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models.Elad Ben Zaken, Shauli Ravfogel, Yoav Goldberg. In ACL 2022 https://arxiv.org/abs/2106.10199
[6] TinyTL: Reduce memory, not parameters for efficient on-device learning. Han Cai, Chuang Gan, Ligeng Zhu, Song Han. In NeurIPS 2020 https://proceedings.neurips.cc/paper/2020/hash/81f7acabd411274fcf65ce2070ed568a-Abstract.html
[7] Parameter-efficient transfer learning for nlp. Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, Sylvain Gelly. In ICML 2019 http://proceedings.mlr.press/v97/houlsby19a.html
[8] Visual Prompt Tuning. Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, Ser-Nam Lim. In arXiv 2022 https://arxiv.org/abs/2203.12119
[9] Learning to Prompt for Continual Learning. Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, Tomas Pfister. In CVPR 2022 https://arxiv.org/abs/2112.08654
[10] Learning to Prompt for Vision-Language Models. Kaiyang Zhou, Jingkang Yang, Chen Change Loy, Ziwei Liu. In arXiv 2021 https://arxiv.org/abs/2109.01134
[11] Conditional Prompt Learning for Vision-Language Models. Kaiyang Zhou, Jingkang Yang, Chen Change Loy, Ziwei Liu. In CVPR 2022 https://arxiv.org/abs/2203.05557
[12] Domain Adaptation via Prompt Learning. Chunjiang Ge, Rui Huang, Mixue Xie, Zihang Lai, Shiji Song, Shuang Li, Gao Huang. In arXiv 2022 https://arxiv.org/abs/2202.06687
相关文章:
【AI理论学习】深入理解Prompt Learning和Prompt Tuning
深入理解Prompt Learning和Prompt Tuning 背景Prompt Learning简介1. Prompt是什么?2. 为什么要使用Prompt?3. Prompt Learning的形式(举例)4. 有哪些Pre-training language model?5. 常见的Prompt Learning的方法 Pro…...

从Authy中导出账户和secret
本文转载于我的博客从Authy中导出账户和secret 前言 因为最近买了CanoKey,所以多算试一下CanoKey的TOTP功能,但是之前一直用的Authy并且它默认不支持导出功能 在网上找了一些文档,终于在github上找到了一个有效且简单的方法 目前网上大部分…...

图像锐度评分算法,方差,点锐度法,差分法,梯度法
图像锐度评分算法,方差,点锐度法,差分法,梯度法 图像锐度评分是用来描述图像清晰度的一个指标。常见的图像锐度评分算法包括方差法、点锐度法、差分法和梯度法等。 方差法:该方法是通过计算图像像素值的方差来评估图像…...

查询练习:连接查询
准备用于测试连接查询的数据: CREATE DATABASE testJoin;CREATE TABLE person (id INT,name VARCHAR(20),cardId INT );CREATE TABLE card (id INT,name VARCHAR(20) );INSERT INTO card VALUES (1, 饭卡), (2, 建行卡), (3, 农行卡), (4, 工商卡), (5, 邮政卡); S…...

【mmdeploy】【TODO】使用mmdeploy将mmdetection模型转tensorrt
mmdetection转换 文章目录 mmdetection转换mmdetection 自带转换ONNX——无法测试使用mmdeploy(0.6.0)使用mmdeploy转onnx使用mmdeploy直接转tensorRT调试记录 先上结论:作者最后是转tensorrt的小图才成功的,大图一直不行。文章仅作者自我记录使用&#…...

德赛西威上海车展重磅发布Smart Solution 2.0,有哪些革新点?
4月18日,全球瞩目的第二十届上海车展盛大启幕,作为国际领先的移动出行科技公司,德赛西威携智慧出行黑科技产品矩阵亮相,并以“智出行 共创享”为主题,重磅发布最新迭代的智慧出行解决方案——Smart Solution 2.0。 从…...

戴尔服务器是否需要开启cpupower.service
戴尔并不会默认开启cpupower.service,这取决于具体的操作系统和配置。cpupower.service是一个Linux系统服务,用于管理CPU的功耗和性能调节,可以通过调整CPU的频率和电源管理策略来降低能耗和温度。在某些情况下,开启cpupower.serv…...
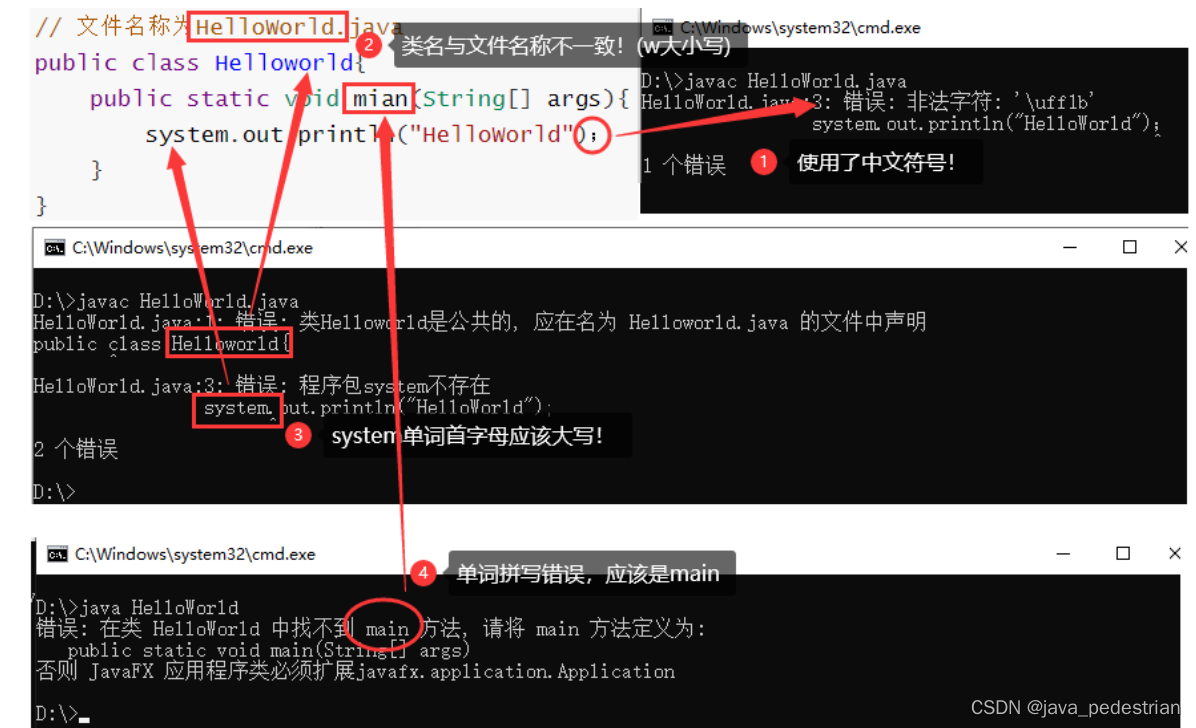
day02_第一个Java程序
在开发第一个Java程序之前,我们必须对计算机的一些基础知识进行了解。 常用DOS命令 Java语言的初学者,学习一些DOS命令,会非常有帮助。DOS是一个早期的操作系统,现在已经被Windows系统取代,对于我们开发人员…...
 | 机试题+算法思路+考点+代码解析)
【华为OD机试真题 】1011 - 第K个排列 (JAVA C++ Python JS) | 机试题+算法思路+考点+代码解析
文章目录 一、题目🔸题目描述🔸输入输出🔸样例1🔸样例2二、代码参考🔸C++代码🔸Java代码🔸Python代码🔸JS代码作者:KJ.JK🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🍂个人博客首页: KJ.JK 💖系列专栏:...

基于php的校园校园兼职网站的设计与实现
摘要 近年来,信息技术在大学校园中得到了广泛的应用,主要体现在两个方面:一是学校管理系统,包括教务管理、行政管理和分校管理,是我国大学管理和信息传递的主要渠道。二是学生生活服务平台。而随着大学生毕业人数的年…...

django部署
1. 配置服务器 安装django,python等服务–尽量和你的自己的配置相同,一摸一样避免出现问题 2.django项目迁移 sudo scp /home/tarena/django/mysitel root88.77.66.55:/home/root/xxx #然后输入密码3,用uWSGI 替代python manage.py runse…...

OpenCV 图像处理学习手册:1~5
原文:Learning Image Processing with OpenCV 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 当别人说你没有底线的时候,…...
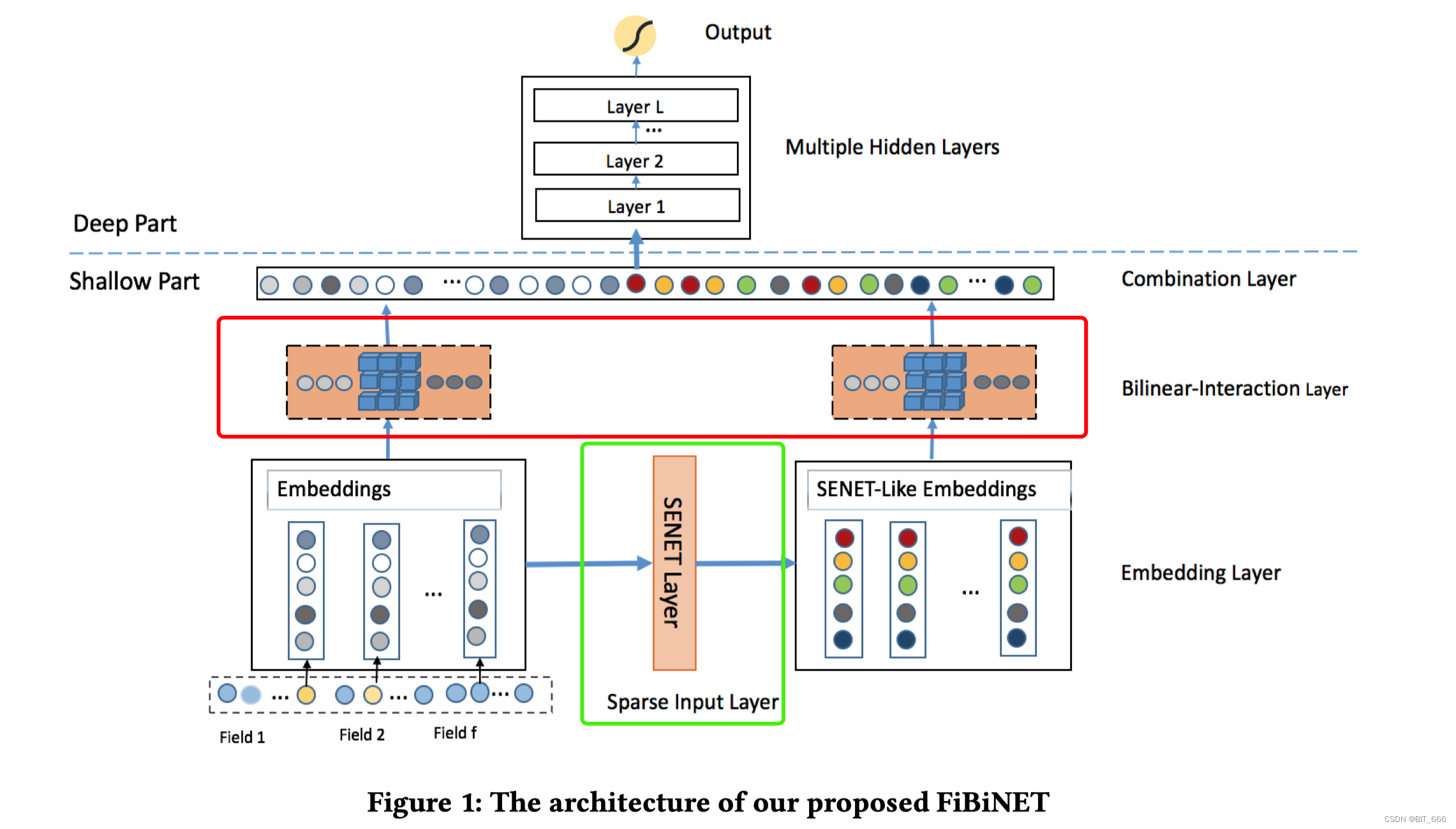
深度学习 - 43.SeNET、Bilinear Interaction 实现特征交叉 By Keras
目录 一.引言 二.SENET Layer 1.简介 2.Keras 实现 2.1 Init Function 2.2 Build Function 2.3 Call Function 2.4 Test Main Function 2.5 完整代码 三.BiLinear Intercation Layer 1.简介 2.Keras 实现 2.1 Init Function 2.2 Build Function 2.3 Call Functi…...
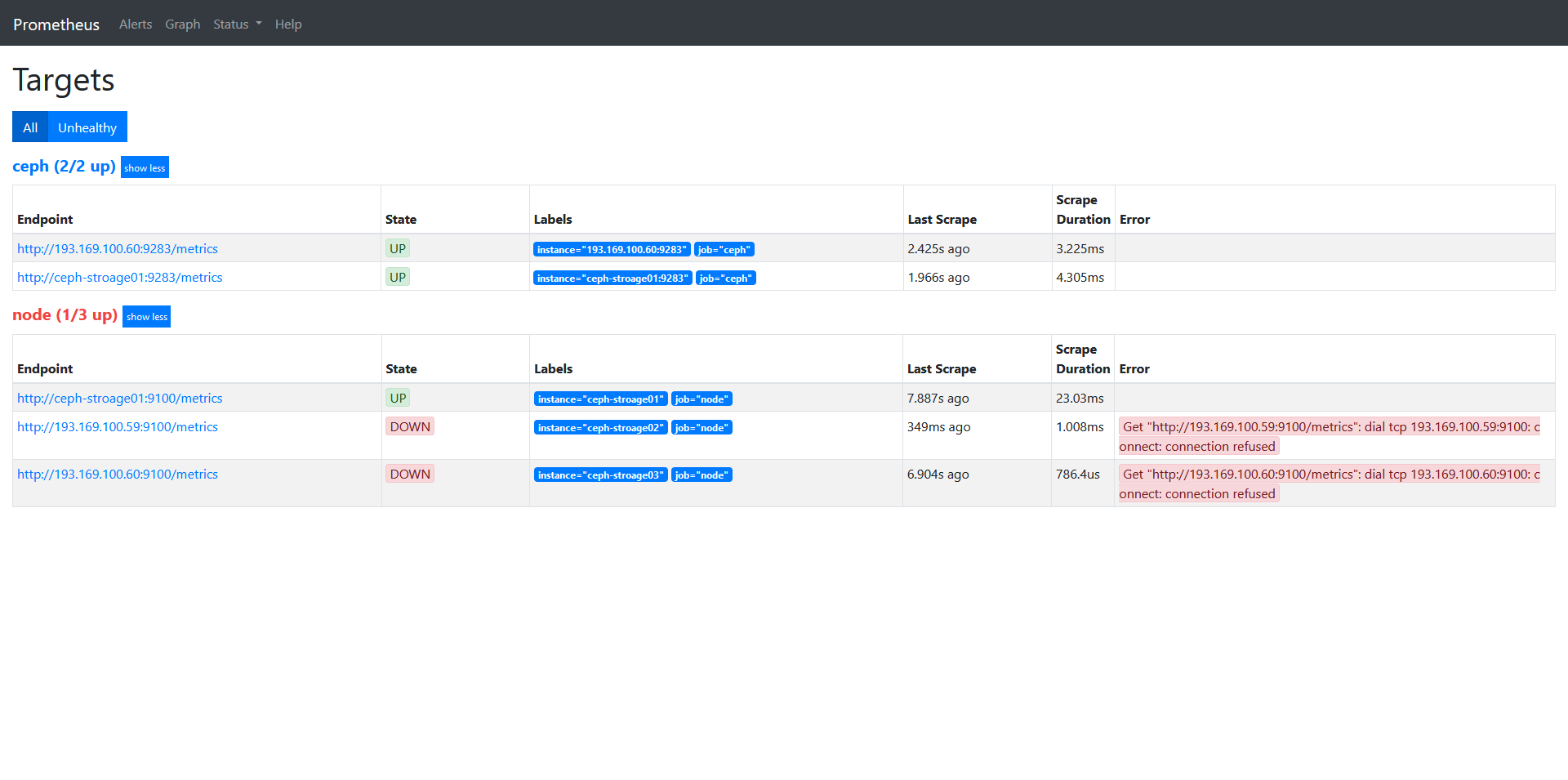
Ceph入门到精通-Cephadm安装Ceph(v17.2.5 Quincy)全网最全版本
Deploy Ceph(v17.2.5 Quincy) cluster to use Cephadm - DevOps - dbaselife Install cephadm Cephadm creates a new Ceph cluster by “bootstrapping” on a single host, expanding the cluster to encompass any additional hosts, and then depl…...

BIOS与POST自检
一、什么是BIOS BIOS是英文"BasicInput-Output System",中文名称就是"基本输入输出系统",是集成在主板上的一个ROM芯片,意思是只读存储器基本输入输出系统。顾名思义,它保存着计算机最重要的基本输入输出的程…...
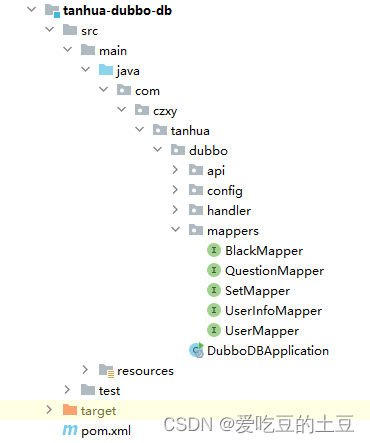
交友项目【查询好友动态,查询推荐动态】实现
目录 1:圈子 1.1:查询好友动态 1.1.1:接口分析 1.1.2:流程分析 1.1.2:代码实现 1.2:查询推荐动态 1.2.1:接口分析 1.2.2:流程分析 1.2.3:代码实现 1:…...

24个强大的HTML属性,建议每位前端工程师都应该掌握!
HTML属性非常多,除了一些基础属性外,还有许多有用的特别强大的属性 本文将介绍24个强大的HTML属性,可以使您的网站更具有动态性和交互性,让用户感到更加舒适和愉悦。 让我们一起来探索这24个强大的HTML属性吧! 1、Acc…...

前端--移动端布局--2移动开发之flex布局
目标: 能够说出flex盒子的布局原理 能够使用flex布局的常用属性 能够独立完成携程移动端首页案例 目录: flex布局体验 flex布局原理 flex布局父项常见属性 flex布局子项常见属性 写出网首页案例制作 1.flex布局体验 1.1传统布局与flex布局 传…...

【移动端网页布局】移动端网页布局基础概念 ① ( 移动端浏览器 | 移动端屏幕分辨率 | 移动端网页调试方法 )
文章目录 一、移动端浏览器二、移动端屏幕分辨率三、移动端网页调试方法 一、移动端浏览器 移动端浏览器 比 PC 端浏览器发展要晚 , 使用的技术比较新 , 对 HTML5 CSS3 支持较好 , 常见的浏览器如下 : UC / QQ / Opera / Chrom / 360 / 百度 / 搜狗 / 猎豹 国内的浏览器 基本…...

无线洗地机哪款性价比高?高性价比的洗地机分享
虽说现在市面上清洁工具很多,但是要说清洁效果最好的,肯定非洗地机莫属。它集合了吸,洗,拖三大功能,干湿垃圾一次清理,还能根据地面的脏污程度进行清洁,达到极致的清洁效果,省时省力…...

快速上手:ClaudeCode安装全攻略
以下是从零开始安装 Claude Code 的详细操作步骤,涵盖环境准备、安装过程与验证方法。请根据你的操作系统选择对应的分支操作。 (PS: 官方文档: 接入 Claude Code | DeepSeek API Docs) 一、安装 Node.js 18 或更高版本 Claude Code 基于 Node.js 运行…...

别再让FFT精度拖后腿了!手把手教你用三点插值法把频率估计误差降到最低
别再让FFT精度拖后腿了!手把手教你用三点插值法把频率估计误差降到最低 在音频调谐器里校准乐器音高时,工程师发现440Hz的标准音高在1024点FFT中总是显示为439.2Hz;5G基站接收端解调时,载波频率的微小偏移导致误码率飙升ÿ…...

2026 国内 ChatGPT 镜像站推荐
📖 国内直接访问,支持 GPTs、绘图、文件分析,对话数据隔离 ✅ 写方案/周报,描述需求直接生成,5分钟搞定 ✅ 代码报错,粘贴进去秒出解决方案 ✅ 读文件/PDF,上传即可提问,不用逐字看…...

航空航班延误预测:可解释性模型与四源融合实战
1. 项目概述:这不是一个“预测准不准”的问题,而是一个“预测有没有用”的问题我做航班延误预测项目,不是为了在Kaggle排行榜上刷个0.89的AUC就收工。真正让我在凌晨三点改完第17版特征工程脚本、盯着滚动的日志等模型收敛的,是去…...

Spine骨骼动画集成:Unity 2D游戏性能优化实战指南
1. 为什么Spine不是“另一个动画插件”,而是2D游戏性能分水岭在Unity里做2D游戏,很多人卡在同一个地方:角色动起来很卡,美术给的PSD切图动效一多就掉帧,UI动画和角色动画抢资源,打包后APK体积暴涨——你试过…...

并发数据结构设计与无锁编程实践
1. 并发数据结构的设计挑战与解决方案在现代多线程编程中,并发数据结构的设计一直是个棘手的问题。想象一下,你正在管理一个繁忙的机场控制塔,多架飞机同时请求降落许可,而你必须确保每架飞机都能安全降落,不会发生冲突…...

用RT-Thread硬件定时器实现精准任务调度:一个LED呼吸灯与数据采集的案例
用RT-Thread硬件定时器实现精准任务调度:一个LED呼吸灯与数据采集的案例 在嵌入式开发中,任务调度和时间管理是核心挑战之一。RT-Thread作为一款优秀的实时操作系统,其硬件定时器(HWTIMER)功能为开发者提供了高精度的时…...

2026线下全网营销课程5大甄选:高适配内容改善品牌转化低迷现状
引文/摘要把流量费花在无效投放上,不如先从内部梳理内容适配度。2026年全网营销进入新阶段,据调研超过78%的营销团队已将AI工具纳入日常工作流。然而很多企业面临“内容做了不少,转化却上不去”的尴尬。本质问题往往不是内容不够多࿰…...

鸿蒙同城兴趣圈页面构建:今晚活动与同频推荐模块详解
鸿蒙同城兴趣圈页面构建:今晚活动与同频推荐模块详解 前言 在 HarmonyOS 6.0 应用开发中,社交类页面的活动展示和用户推荐是提升用户参与度的核心功能模块。本文将以“同城兴趣圈”应用中的“今晚活动”时间线模块和“同频推荐”用户卡片网格为例&#x…...
)
libigl 极小曲面(全局优化之二)
文章目录 一、简介 二、实现代码 三、实现效果 参考资料 一、简介 二、实现代码 #include <numeric>//igl #include <igl/readPLY.h>...