SparkStreaming学习之——无状态与有状态转化、遍历kafka的topic消息、WindowOperations
目录
一、状态转化
二、kafka topic A→SparkStreaming→kafka topic B
(一)rdd.foreach与rdd.foreachPartition
(二)案例实操1
1.需求:
2.代码实现:
3.运行结果
(三)案例实操2
1.需求:
2.代码实现:
3.运行结果
三、WindowOperations
1.WindowOperations 窗口概述
2.代码示例
3.运行结果
一、状态转化
无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上,也就是转化 DStream 中的每一个 RDD。
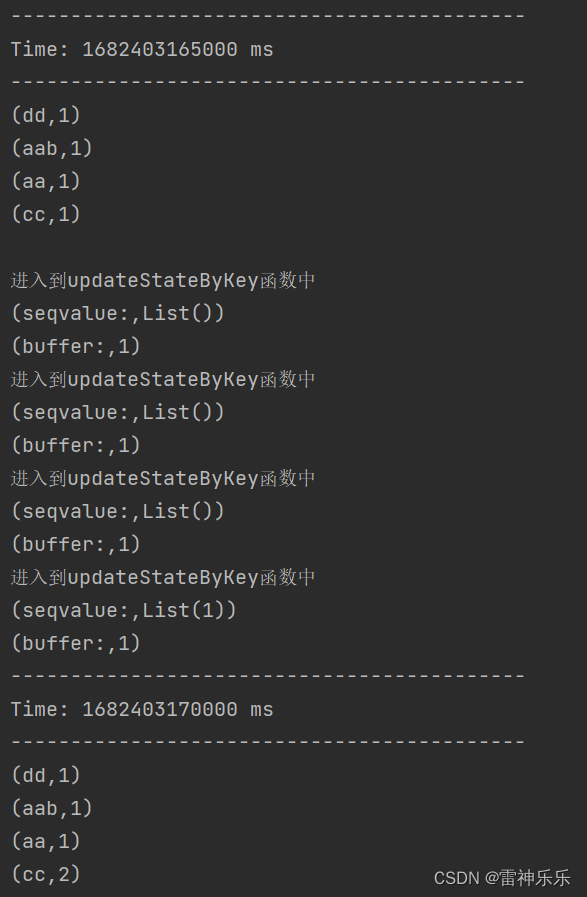
有状态转化操作就是窗口与窗口之间的数据有关系。上次一UpdateStateByKey 原语用于记录历史记录,有时,我们需要在 DStream 中跨批次维护状态(例如流计算中累加 wordcount)。针对这种情况,updateStateByKey()为我们提供了对一个状态变量的访问,用于键值对形式的 DStream。给定一个由(键,事件)对构成的 DStream,并传递一个指 定如何根据新的事件更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态) 对。
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}object SparkStreamingKafkaSource {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("sparkKafkaStream").setMaster("local[*]")val streamingContext = new StreamingContext(conf, Seconds(5))streamingContext.checkpoint("checkpoint")val kafkaParams = Map((ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "lxm147:9092"),(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.GROUP_ID_CONFIG -> "sparkstreamgroup1"))val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe(Set("sparkkafkastu"), kafkaParams))// TODO 无状态:每个窗口数据独立/*val wordCountStream: DStream[(String, Int)] = kafkaStream.flatMap(_.value().toString.split("\\s+")).map((_, 1)).reduceByKey(_ + _)wordCountStream.print()*/// TODO 有状态:窗口与窗口之间的数据有关系val sumStateStream: DStream[(String, Int)] = kafkaStream.flatMap(x => x.value().toString.split("\\s+")).map((_, 1)).updateStateByKey {case (seq, buffer) => {println("进入到updateStateByKey函数中")println("seqvalue:", seq.toList.toString())println("buffer:", buffer.getOrElse(0).toString)val sum: Int = buffer.getOrElse(0) + seq.sumOption(sum)}}sumStateStream.print()streamingContext.start()streamingContext.awaitTermination()}
}
有状态转化会将之前的历史记录与当前输入的数据进行计算:

二、kafka topic A→SparkStreaming→kafka topic B
(一)rdd.foreach与rdd.foreachPartition
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}import java.util/*** 将数据从kafka的topic A取出数据后加工处理,之后再输出到kafka的topic B中*/
object SparkStreamKafkaSourceToKafkaSink {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("sparkKafkaStream2").setMaster("local[*]")val streamingContext = new StreamingContext(conf, Seconds(5))streamingContext.checkpoint("checkpoint")streamingContext.checkpoint("checkpoint")val kafkaParams = Map( // TODO 连接生产者端的topic(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "lxm147:9092"),(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.GROUP_ID_CONFIG -> "kfkgroup2"))val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,// 如果没有topic需要创建// kafka-topics.sh --create --zookeeper lxm147:2181 --topic sparkkafkademoin --partitions 1 --replication-factor 1ConsumerStrategies.Subscribe(Set("sparkkafkademoin"), kafkaParams))println("1.配置spark消费kafkatopic")// TODO 使用foreachRDD太过消耗资源——不推荐kafkaStream.foreachRDD( // 遍历rdd => {println("2.遍历spark DStream中每个RDD")// 每隔5秒输出一次/* rdd.foreach(y => { // y:kafka中的keyValue对象println(y.getClass + " 遍历RDD中的每一条kafka的记录")val props = new util.HashMap[String, Object]()// TODO 连接消费者端的topicprops.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "lxm147:9092")props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")val producer = new KafkaProducer[String, String](props)val words: Array[String] = y.value().toString.trim.split("\\s+") // hello worldfor (word <- words) {val record = new ProducerRecord[String, String]("sparkkafkademoout", word + ",1")producer.send(record)}}) */rdd.foreachPartition(rdds => { // rdds是包含rdd某个分区内的所有元素println("3.rdd 每个分区内的所有kafka记录集合")val props = new util.HashMap[String, Object]() // TODO 连接消费者端的topicprops.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "lxm147:9092")props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")val producer = new KafkaProducer[String, String](props)rdds.foreach(y => {println("4.遍历获取rdd某一个分区内的每一条消息")val words: Array[String] = y.value().trim.split("\\s+")for (word <- words) {val record = new ProducerRecord[String, String]("sparkkafkademoout", word + ",1")producer.send(record)}})})})streamingContext.start()streamingContext.awaitTermination()}
}
(二)案例实操1
1.需求:
清洗前:
user , friends
3197468391,1346449342 3873244116 4226080662 1222907620清洗后:
user ,friends 目标topic:user_friends2
3197468391,1346449342
3197468391,3873244116
3197468391,4226080662
3197468391,1222907620
2.代码实现:
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}import java.utilobject SparkStreamUserFriendrawToUserFriend {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("sparkufStream2").setMaster("local[2]")val streamingContext = new StreamingContext(conf, Seconds(5))streamingContext.checkpoint("checkpoint")val kafkaParams = Map( // TODO 连接生产者端的topic(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "lxm147:9092"),(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.GROUP_ID_CONFIG -> "sparkuf3"),(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "earliest"))val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,// 如果没有topic需要创建// kafka-topics.sh --create --zookeeper lxm147:2181 --topic user_friends2 --partitions 1 --replication-factor 1ConsumerStrategies.Subscribe(Set("user_friends_raw"), kafkaParams))kafkaStream.foreachRDD(rdd => {rdd.foreachPartition(x => {val props = new util.HashMap[String, Object]() // TODO 连接消费者端的topicprops.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "lxm147:9092")props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")val producer = new KafkaProducer[String, String](props)x.foreach(y => {val splits: Array[String] = y.value().split(",")if (splits.length == 2) {val userid: String = splits(0)val friends: Array[String] = splits(1).split("\\s+")for (friend <- friends) {val record = new ProducerRecord[String, String]("user_friends2", userid + "," + friend)producer.send(record)}}})})})streamingContext.start()streamingContext.awaitTermination()}
}
3.运行结果

(三)案例实操2
1.需求:
清洗前:
event , yes , maybe , invited ,no
1159822043,1975964455 3973364512,2733420590 ,1723091036 795873583,3575574655清洗前后:
eventid ,friendid ,status
1159822043,1975964455,yes
1159822043,3973364512,yes
1159822043,2733420590,maybe
1159822043,1723091036,invited1159822043,795873583,invited
1159822043,3575574655,no
2.代码实现:
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}import java.utilobject SparkStreamEventAttToEvent2 {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("sparkufStream2").setMaster("local[2]")val streamingContext = new StreamingContext(conf, Seconds(5))streamingContext.checkpoint("checkpoint")val kafkaParams = Map( // TODO 连接生产者端的topic(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "lxm147:9092"),(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.GROUP_ID_CONFIG -> "sparkevent"),(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "earliest"))val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,// 如果没有topic需要创建// kafka-topics.sh --create --zookeeper lxm147:2181 --topic event2 --partitions 1 --replication-factor 1ConsumerStrategies.Subscribe(Set("event_attendees_raw"), kafkaParams))kafkaStream.foreachRDD(rdd => {rdd.foreachPartition(x => {val props = new util.HashMap[String, Object]() // TODO 连接消费者端的topicprops.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "lxm147:9092")props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")val producer = new KafkaProducer[String, String](props)x.foreach(y => { // todo 遍历获取rdd某一个分区内的每一条消息val splits: Array[String] = y.value().split(",")val eventID: String = splits(0)if (eventID.trim.nonEmpty) {if (splits.length >= 2) {val yesarr: Array[String] = splits(1).split("\\s+")for (yesID <- yesarr) {val yes = new ProducerRecord[String, String]("event2", eventID + "," + yesID + ",yes")producer.send(yes)}}if (splits.length >= 3) {val maybearr: Array[String] = splits(2).split("\\s+")for (maybeID <- maybearr) {val yes = new ProducerRecord[String, String]("event2", eventID + "," + maybeID + ",maybe")producer.send(yes)}}if (splits.length >= 4) {val invitedarr: Array[String] = splits(3).split("\\s+")for (invitedID <- invitedarr) {val invited = new ProducerRecord[String, String]("event2", eventID + "," + invitedID + ",invited")producer.send(invited)}}if (splits.length >= 5) {val noarr: Array[String] = splits(4).split("\\s+")for (noID <- noarr) {val no = new ProducerRecord[String, String]("event2", eventID + "," + noID + ",no")producer.send(no)}}}})})})streamingContext.start()streamingContext.awaitTermination()}
}3.运行结果

三、WindowOperations
1.WindowOperations 窗口概述
Window Operations 可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Steaming 的允许状态。所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
➢ 窗口时长:计算内容的时间范围;
➢ 滑动步长:隔多久触发一次计算。
注意:这两者都必须为采集周期大小的整数倍。
2.代码示例
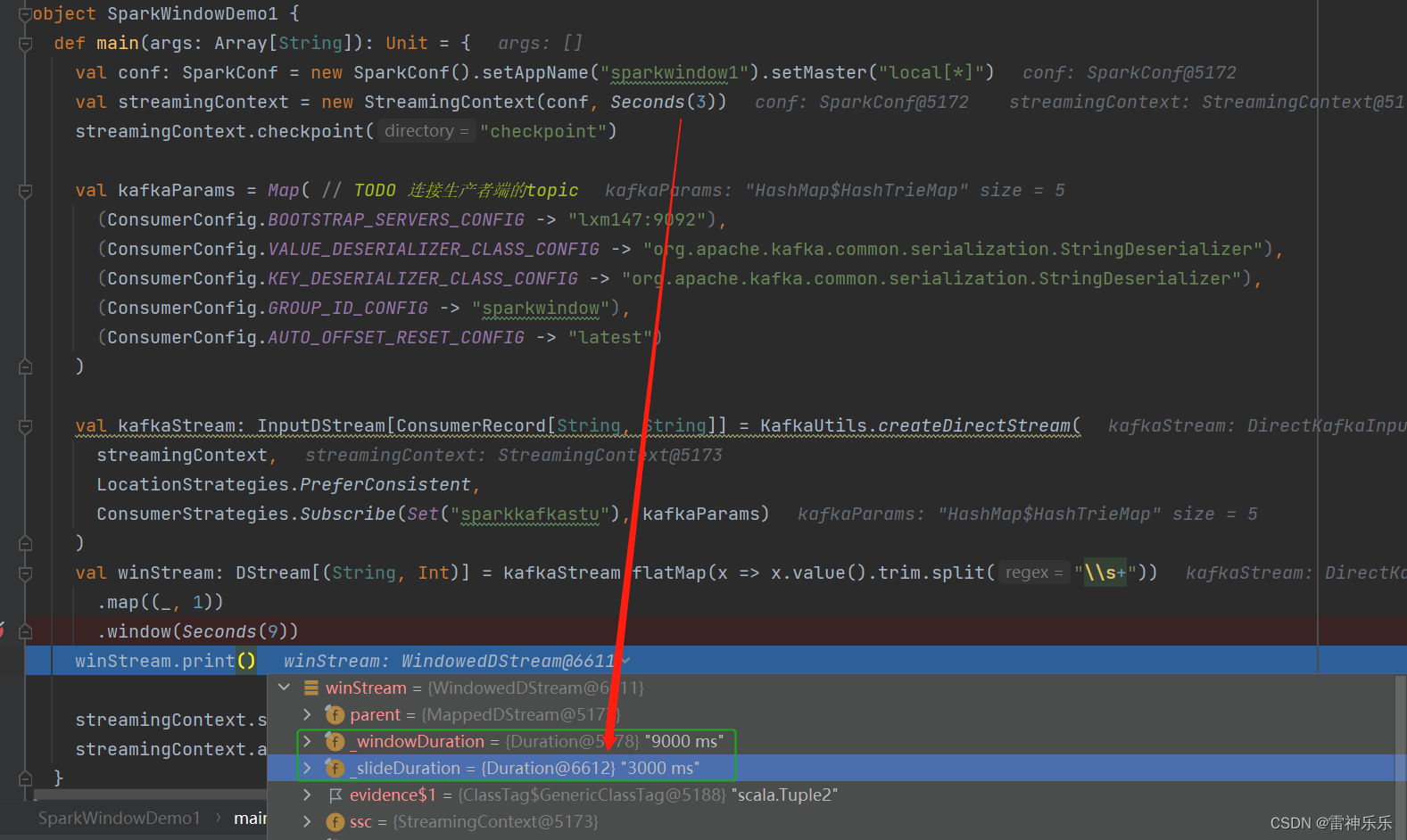
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}object SparkWindowDemo1 {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("sparkwindow1").setMaster("local[*]")val streamingContext = new StreamingContext(conf, Seconds(3))streamingContext.checkpoint("checkpoint")val kafkaParams = Map( // TODO 连接生产者端的topic(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "lxm147:9092"),(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.GROUP_ID_CONFIG -> "sparkwindow"),(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "latest"))val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe(Set("sparkkafkastu"), kafkaParams))val winStream: DStream[(String, Int)] = kafkaStream.flatMap(x => x.value().trim.split("\\s+")).map((_, 1)).window(Seconds(9), Seconds(3))winStream.print()streamingContext.start()streamingContext.awaitTermination()}
}注意:window的步长不进行设置,默认是采集周期
3.运行结果

相关文章:
SparkStreaming学习之——无状态与有状态转化、遍历kafka的topic消息、WindowOperations
目录 一、状态转化 二、kafka topic A→SparkStreaming→kafka topic B (一)rdd.foreach与rdd.foreachPartition (二)案例实操1 1.需求: 2.代码实现: 3.运行结果 (三)案例实操2 1.需求: 2.代码实现: 3.运行结果 三、W…...
)
上市公司碳排放测算数据(1992-2022年)
根据《温室气体核算体系》,企业的碳排放可以分为三个范围。 范围一是直接温室气体排放,产生于企业拥有或控制的排放源,例如企业拥有或控制的锅炉、熔炉、车辆等产生的燃烧排放;拥有或控制的工艺设备进行化工生产所产生的排放。 范…...
Springboot 整合 JPA 及 Swagger2
首先是官方文档: Spring Data JPA - Reference Documentationhttps://docs.spring.io/spring-data/jpa/docs/2.2.4.RELEASE/reference/html/#repositories.query-methods 1、JPA相关概念 2、创建 Springboot 项目 修改 pom 文件,可以直接进行复制粘贴&a…...
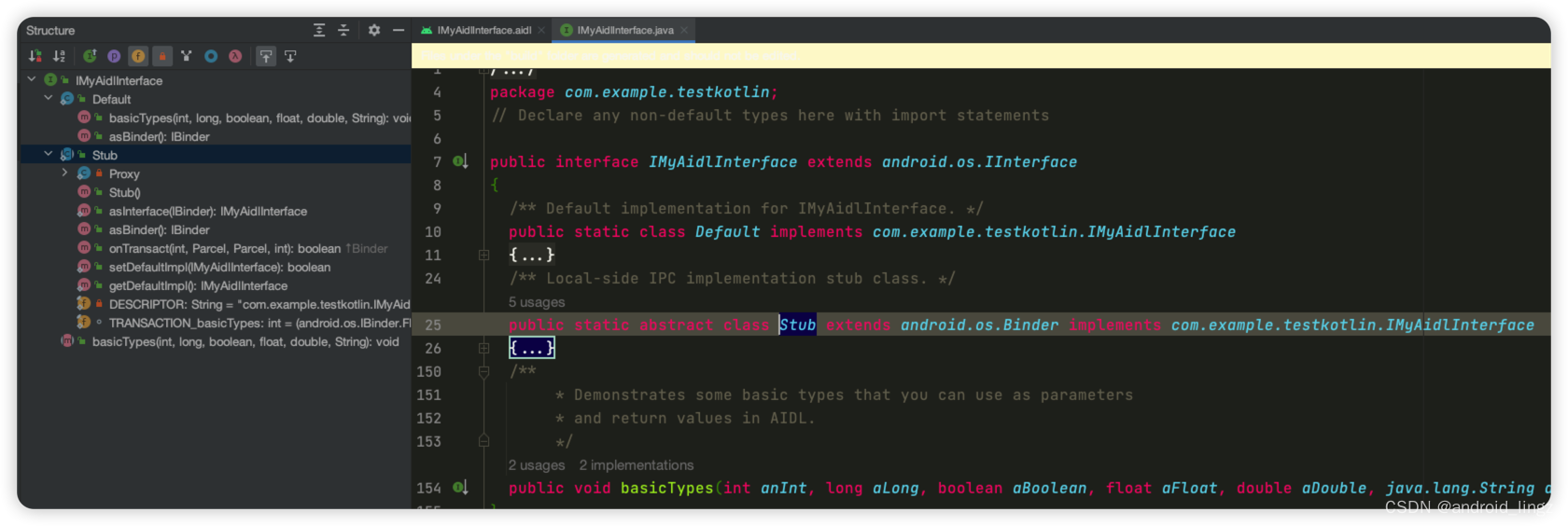
android aidl
本文只是记录个人学习aidl的实现,如需学习请参考下面两篇教程 官方文档介绍Android 接口定义语言 (AIDL) | Android 开发者 | Android Developers 本文参考文档Android进阶——AIDL详解_android aidl_Yawn__的博客-CSDN博客 AIDL定义:Android 接口…...
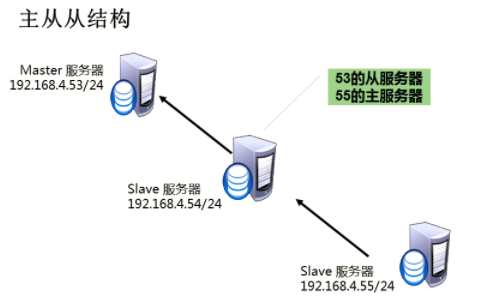
MYSQL---主从同步概述与配置
一、MYSQL主从同步概述 1、什么是MySQL主从同步? 实现数据自动同步的服务结构 主服务器(master): 接受客户端访问连接 从服务器(slave):自动同步主服务器数据 2、主从同步原理 Maste:启用binlog 日志 Slave:Slave_IO: 复制master主…...

WebClient学习
1. 介绍 Java中传统的RestTemplate 的主要问题在于不支持响应式流规范,也就无法提供非阻塞式的流式操作。而WebClient是响应式、非阻塞的客户端,属于Spring5中的spring-webflux库 2. 依赖 maven依赖 <dependency><groupId>org.springfra…...

「计算机控制系统」6. 直接设计法
特殊类型系统的最小拍无差设计 一般系统的最小拍无差设计 最小拍控制器的工程化改进 Dahlin算法 文章目录 特殊类型系统的最小拍无差设计理论分析典型输入函数的最小拍无差系统 一般系统的最小拍无差设计有波纹最小拍无差设计无波纹最小拍无差设计 最小拍控制器的工程化改进针对…...
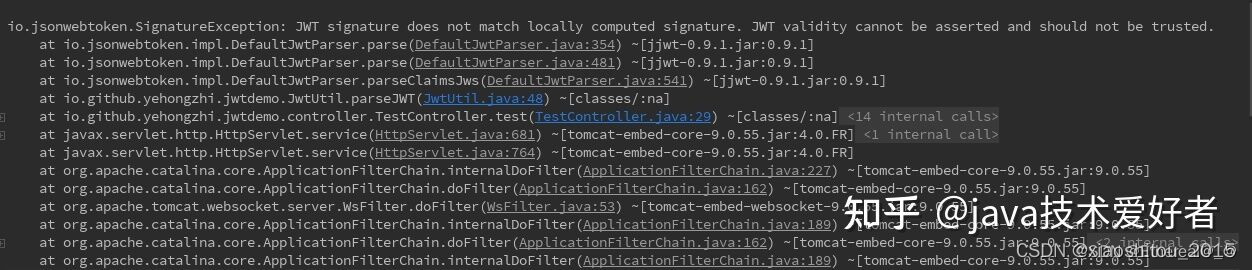
什么是JWT?
起源 需要了解一门技术,首先从为什么产生开始说起是最好的。JWT 主要用于用户登录鉴权,所以我们从最传统的 session 认证开始说起。 session认证 众所周知,http 协议本身是无状态的协议,那就意味着当有用户向系统使用账户名称和…...

STM32—0.96寸OLED液晶显示
本文主要介绍基于STM32F103的0.96寸的OLED液晶显示,详细关于0.96寸OLED液晶屏幕的介绍可参考这篇博客:https://blog.csdn.net/u011816009/article/details/130119426 一、简介 OLED被称为有机激光二极管,也被称为有机激光显示,O…...

Mysql的简介和选择
文章目录 前言一、为什么要使用数据库 数据库的概念为什么要使用数据库二、程序员为什么要学习数据库三、数据库的选择 主流数据库简介使用MySQL的优势版本选择四、Windows 平台下安装与配置MySQL 启动MySQL 服务控制台登录MySQL命令五、Linux 平台下安装与配置MySQL总结 前言…...

3D视觉之深度相机方案
随着机器视觉,自动驾驶等颠覆性的技术逐步发展,采用 3D 相机进行物体识别,行为识别,场景 建模的相关应用越来越多,可以说 3D 相机就是终端和机器人的眼睛。 3D 相机 3D 相机又称之为深度相机,顾名思义&…...
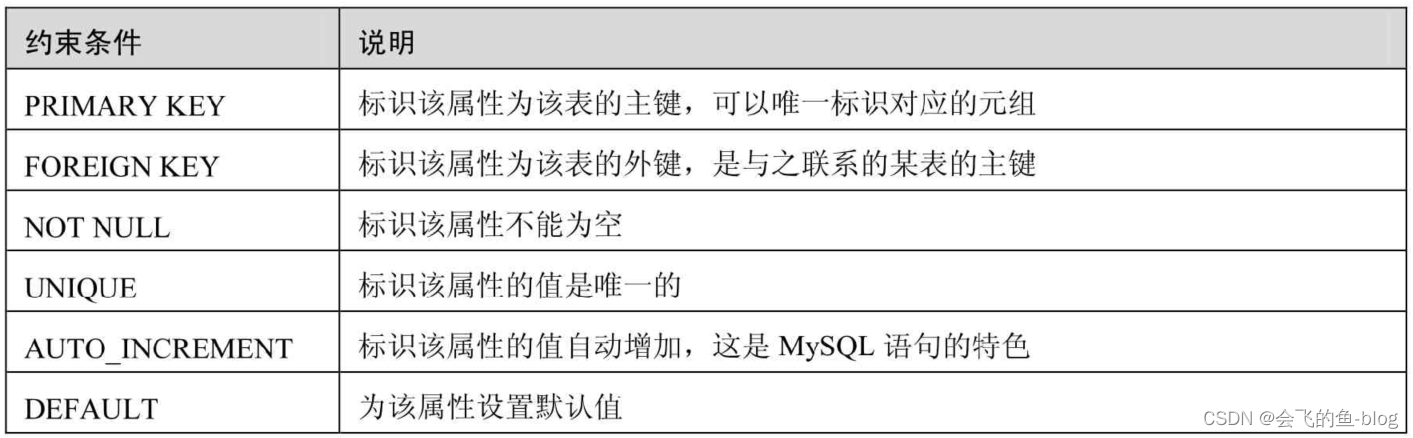
Mysql列的完整性约束详解(主键约束)
文章目录 前言一、设置表字段的主键约束(PRIMARY KEY,PK) 1.单字段主键2.多字段主键总结 前言 完整性约束条件是对字段进行限制,要求用户对该属性进行的操作符合特定的要求。如果不满足完整性约束条件,数据库系统将不再…...
母婴市场竞争激烈,如何通过软文营销脱颖而出
如今,随着宝宝数量增加以及人们对孩子的重视程度的增加,母婴市场愈发火爆。然而,母婴行业的竞争也越来越激烈,企业需要不断开拓新市场才能生存。在这样的情况下,软文营销成为了母婴企业拓展市场的一种有效方式。 首先&…...

java--线程池
目录 1.线程池概 2 为什么要使用线程池 1创建线程问题 2解决上面两个问题思路: 3线程池的好处 4线程池适合应用场景 3 线程池的构造函数参数 1.corePoolSize int 线程池核心线程大小 2.maximumPoolSize int 线程池最大线程数量 3.keepAliveTime long 空闲…...

asp.net765数码手机配件租赁系统
员工部分功能 1.员工登录,员工通过自己的账号和密码登录到系统中来,对租赁信息进行管理 2.配件查询,员工可以查询系统内的配件信息 3.客户信息管理,员工可以管理和店内有业务往来的客户信息 4.配件租赁,员工可以操作用…...

有关态势感知(SA)的卷积思考
卷积是一种数学运算,其本质是将两个函数进行操作,其中一个函数是被称为卷积核或滤波器的小型矩阵,它在另一个函数上滑动并产生新的输出。在计算机视觉中,卷积通常用于图像处理和特征提取,它可以通过滤波器对输入图像进…...
Docker快速部署springboot项目
有很多开发者在项目部署过程中都会遇到一些繁琐的问题,比如打包、上传、部署等。而使用Docker可以非常方便地解决这些问题。在本文中,将详细讲解如何使用IDEA中的docker打包插件,将代码打包并直接发布到服务器上。这样,我们就可以…...

Linux命令rsync增量同步目录下的文件
业务场景描述 最近遇到一个问题,需要编写相应的Linux命令,增量同步/var/mysql里的所有文件到另外一个目录/opt/mysql,但是里面相关的日志文件xx.log是不同步的,这个场景,可以使用rsync来实现 什么是rsync命令&#x…...
项目管理一般知识)
项目管理---(1)项目管理一般知识
一、项目管理一般知识 1.1 项目的一般知识 1.1.1 项目的定义: 项目是为创造独特的产品、服务或成果而进行的临时性工作。 1.1.2 项目的目标: 项目的目标包括成果性目标和约束性目标。 成果性目标:指通过项目开发出满足客户要求的产品、系…...

超过50多个热门的免费可用 API 分享
今天吃什么:随机返回一顿美味食物,解决你今天吃什么的难题。万年历:获取公历日期对应的农历、农历节日节气、天干地支纪年纪月纪日、生肖属相、宜忌、星座等信息。支持查询未来15天。笑话大全:各种最新、最及时的幽默、搞笑段子&a…...

用 MinIO 搭建 S3 兼容对象存储服务
用 MinIO 搭建 S3 兼容对象存储服务 分类:开源项目部署 MinIO 适合附件、备份归档和 S3 兼容对象文件。这类主题真正跑起来并不难,难的是上线后稳定、可备份、能排错。本文按实操方式整理一套可以直接落地的流程,默认你已经会登录 Linux 服务…...

5分钟上手京东自动抢购工具:Python脚本让限量商品轻松到手
5分钟上手京东自动抢购工具:Python脚本让限量商品轻松到手 【免费下载链接】autobuy-jd 使用python语言的京东平台抢购脚本 项目地址: https://gitcode.com/gh_mirrors/au/autobuy-jd 还在为抢不到心仪商品而烦恼吗?Autobuy-JD京东自动抢购工具为…...

AI导演系统:编排角色扮演,让多智能体协作效率飙升10倍
🧑💻 博主介绍 & 诚邀关注 作者:专注于 Java、Python、前端开发的技术博主 | 全网粉丝 30 万 在校期间协助导师完成毕业设计课题分类、论文格式初审及代码整理工作;工作后持续分享毕设思路,助力毕业生顺利完成…...

暗黑破坏神2存档编辑器完整指南:三步轻松修改D2/D2R角色与装备
暗黑破坏神2存档编辑器完整指南:三步轻松修改D2/D2R角色与装备 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 你是否厌倦了在暗黑破坏神2中反复刷装备却一无所获?是否因为早期加点失误导致角色后期无法应…...

我见过最聪明的技术人,都在偷偷培养这3种“非技术能力”
在软件测试行业摸爬滚打这些年,我见过太多天赋异禀的技术从业者:有人能一夜吃透新的自动化测试框架,有人能对着流量日志半小时定位出隐藏半年的内存泄漏问题,有人能把性能测试指标优化到远超行业标准。可几年过去,真正…...

ElevenLabs安徽话输出失真?3类高频崩溃场景+5行Python代码实时修复音频相位偏移
更多请点击: https://codechina.net 第一章:ElevenLabs安徽话语音输出失真现象全景扫描 ElevenLabs 作为当前主流的高质量文本转语音(TTS)服务提供商,其多语言支持能力广受开发者青睐。然而,在面向中文方言…...
)
保姆级教程:用vsomeip实现一个简单的车内服务发现与通信(附C++代码)
车载通信实战:基于vsomeip的服务发现与消息交互全流程解析 在智能座舱与自动驾驶技术快速迭代的今天,车载电子控制单元(ECU)间的可靠通信成为系统设计的核心挑战。SOME/IP作为汽车电子领域广泛采用的通信协议,其开源实…...

量子增强生成模型革新格点场理论计算
1. 量子增强生成模型在格点场理论中的突破性应用在计算物理领域,特别是高能物理研究中,格点场理论(Lattice Field Theory, LFT)一直是研究非微扰量子场论的重要工具。传统方法如马尔可夫链蒙特卡洛(MCMC)虽…...

3分钟搞定!Windows性能优化神器CPUDoc零基础上手指南
3分钟搞定!Windows性能优化神器CPUDoc零基础上手指南 【免费下载链接】CPUDoc 项目地址: https://gitcode.com/gh_mirrors/cp/CPUDoc 你有没有遇到过这样的情况?明明电脑配置不错,玩游戏时帧数却忽高忽低;多开几个软件就感…...

高性能企业级数据集成架构设计:Pentaho Kettle 11.0核心引擎深度解析与部署指南
高性能企业级数据集成架构设计:Pentaho Kettle 11.0核心引擎深度解析与部署指南 【免费下载链接】pentaho-kettle Pentaho Data Integration ( ETL ) a.k.a Kettle 项目地址: https://gitcode.com/gh_mirrors/pe/pentaho-kettle Pentaho Data Integration&am…...