MySQL表的增删查改
目录
一 插入
1 基本语法
①全列插入
②指定列插入
③多条记录插入
④冲突更新
二 查询
查询全部数据
指定列查询
显示
拼接
取别名
去重查找
where
逻辑运算符和比较运算符
结果排序
Limit
group by 分组
聚合函数
对于count
对于sum
对于group by
相关的语法细节:
①如果有多个分组条件?
②关于显示
③关于分组后筛选
关于执行顺序
三 UPDATE 更新
四 DELETE/TRUNCATE 删除
DELETE
语法
注意:
TRUNCATE
一 插入
1 基本语法
先创建一个表之后插入

有几种写法,可以基本分类成是否带上列名,是否是多条记录插入,是否有冲突更新
①全列插入
不带列名,默认是一一对应的全列插入
INSERT INTO table_name
VALUES (value1, value2, value3, ...);示例
![]()
全插入的话自增的值也是要指定的
![]()
②指定列插入
带上列名,默认插入的值是和自己指定的列名的顺序一一对应
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);![]()
可以省略自增的值
注意:
此时如果默认省略了列名,进行全列插入的话,不能够省略自增字段的值,不会自动更新
此时如果指定了列名进行插入的话,可以省略自增长的值,会自动补充
③多条记录插入
在上述两种插入的基础上增加新的记录
INSERT INTO table_name
VALUES (value1, value2, value3, ...),(value1, value2, value3, ...),(value1, value2, value3, ...);或者
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...),(value1, value2, value3, ...),(value1, value2, value3, ...);

④冲突更新
冲突理解
如果表中已经存在的主键或者唯一键和我要插入的值是一样的,此时就发生了冲突,如果发生冲突的话,mysql就会直接进行拦截,不允许该信息的插入。
本质:插入冲突是因为我们之前存在相同的值,如果不想让操作失败的话,可以先进行更新再插入。
其实就是一种替换,可以选择删除之前的数据再插入新的值。但是主键和唯一键不被修改,其他的被修改
语法
INSERT INTO ……
ON DUPLICATE KEY UPDATE column = values [,column = value]……
其实replace可以替换掉上述的语句,两者的意思是一样的
示例
有冲突,并且冲突值不一样
有冲突但是冲突值和之前是一样的
没有冲突直接插入
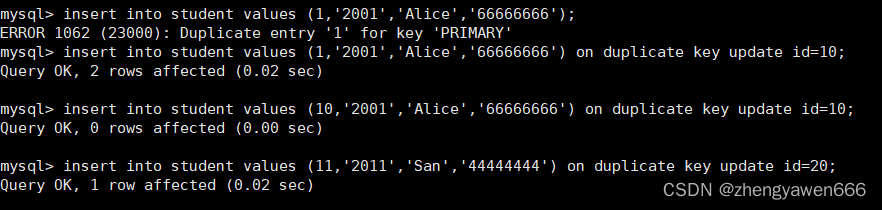
和replace是一样的
影响
此时分为几种情况:
①插入的时候无冲突,直接插入,一行受影响-----》只有自己插入的这一行受影响
②插入的时候发生键值冲突了,但是冲突的值和之前的是一样的,此时0行受影响
③插入的时候发生键值冲突了,并且冲突的值不一致,这时候就会删除之前的,然后插入新的,(假设之前只有1行记录冲突),那么就是两行受影响
二 查询
在一个数据库内,做一个表的组合查询
语法
SELECT
{* | <字段列名>}
[
FROM <表 1>, <表 2>…
[WHERE <表达式>
[GROUP BY <group by definition>
[HAVING <expression> [{<operator> <expression>}…]]
[ORDER BY <order by definition>]
[LIMIT[<offset>,] <row count>]
]先来简单介绍一下这些意思,
from就是要指明在哪些表中进行查找
where的话设定对应的查询条件,通过逻辑运算符或者算数运算符进行设置
order by的话是排序的意思,有升序和降序,默认是升序
limit的话,是筛选出指定行。我们可以和order by搭配使用,这样的话,就可以选出符合条件的前几条或者最后几条数据
演示一下对应的操作,先创建一个表并且插入数据做准备
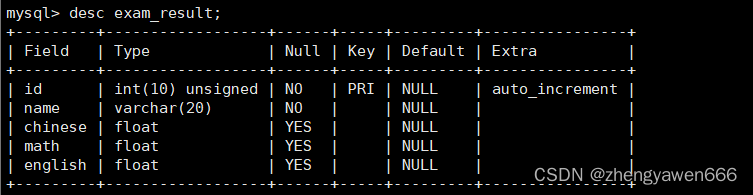
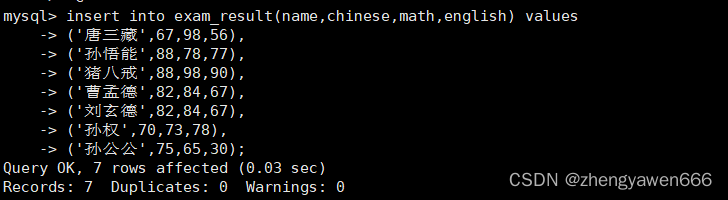
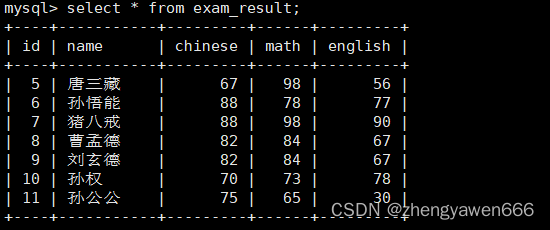
1 查询全部数据
后面不带任何的筛选条件就是查询所有的数据。但是这样的话,如果对于数据量非常大的表来说的话,数据量非常大,而且筛选不出符合自己条件的。
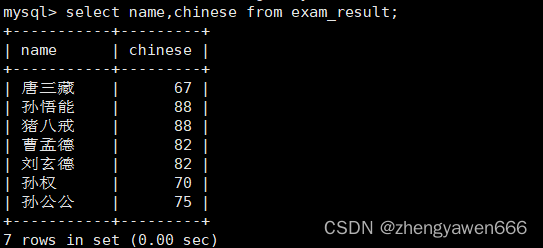
指定列查询
可以只查询自己关心的列。但是也是所有数据的。
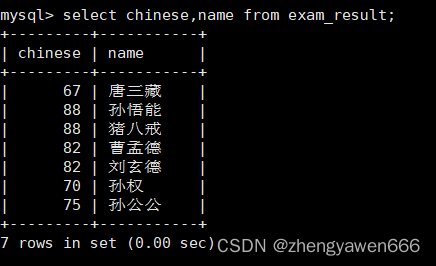
显示
我们在查询列的时候,显示结果是跟着自己的指定列的,而非创建表的时候的顺序
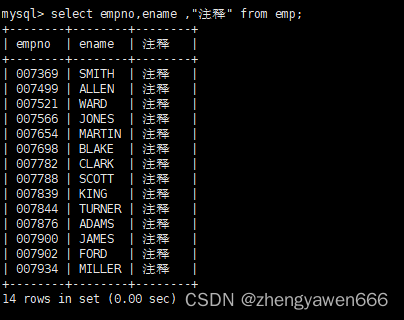
拼接
我们查找的时候还可以拼接常数或者计算式或者字符串
取别名
as 取别名 (取别名的时候也可以不加as)

去重查找
规则:要根据对应查找的内容整体来判断的
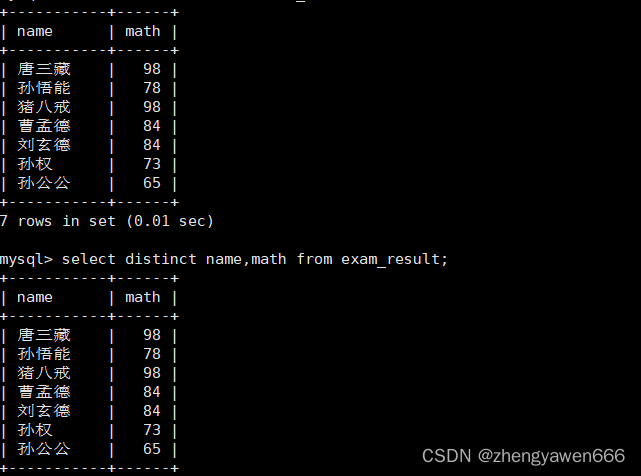
比如这里根据名字和数学成绩一起去重,虽然数学成绩有重复的,但是名字是没有重复的,也没有数据被筛选掉,都被看成不重复的
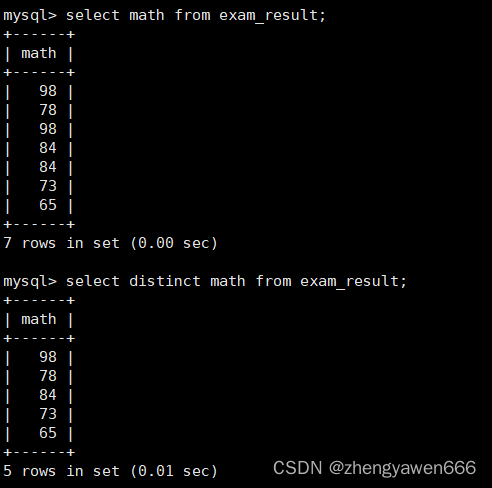
这样才会去重
where
主要使用两大类运算符来进行筛选:
逻辑运算符和比较运算符
以下是比较运算符的种类
| 运算符 | 说明 |
| > >= < <= | 大于 大于等于 小于 小于等于 |
| = | 等于 不能对NULL运算 |
| <=> | 等于 可以用来比较NULL |
| != , <> | 不等于 |
| BETWEEN AND | 闭区间内的一个值 |
| IN(option1,option2,……) | 如果是option中的任意一个,就可以返回TRUE |
| IS NULL | 是NULL |
| IS NOT NULL | 不是NULL |
| LIKE | 模糊匹配 %匹配多个 _匹配一个 |
>,>=,<,<=一般来说是可以来比较整数或者浮点数的大小的
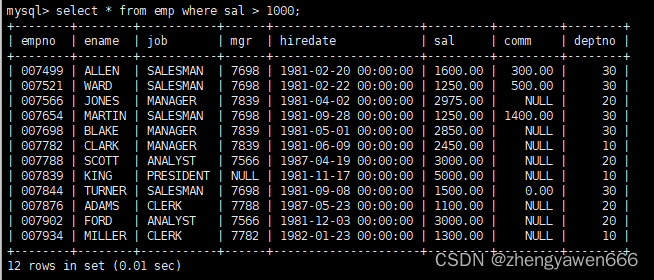
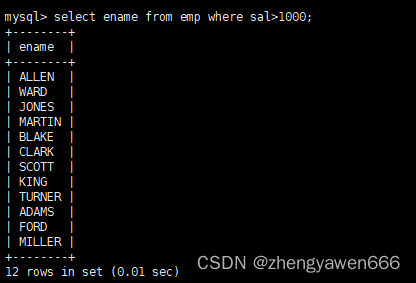
比如这个语句就筛选出了薪水大于1000的
=除了比较数字之外,还可以用来比较字符串,但是不能对NULL进行比较
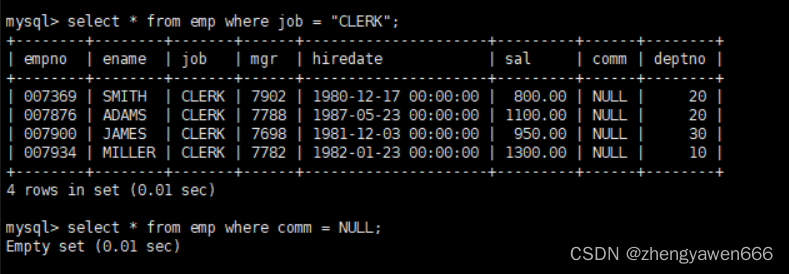
注意:mysql中的等于是=,而非语言中的==
对于NULL值的运算可以使用<=> 或者 IS (NOT)NUL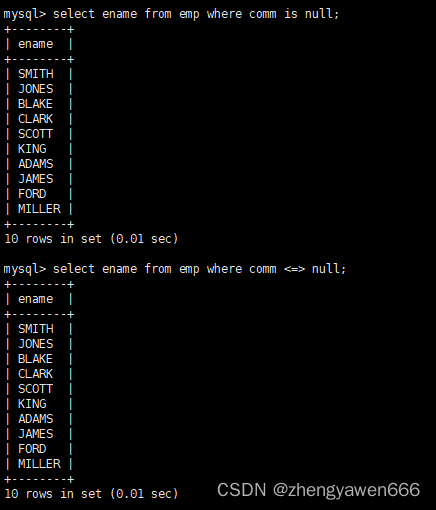
注意null值和空串的区分对于空串是可以使用 = ' '进行筛选出来的,但是null的话只能使用<=> 或者IS(NOT)NULL运算
‘ ’表示的是空串,他是个字符串类型,只不过内容是空的
NULL一般不参与计算,=这个运算符只能比较存在的数据,因此对于这个不存在的NULL不能进行比较
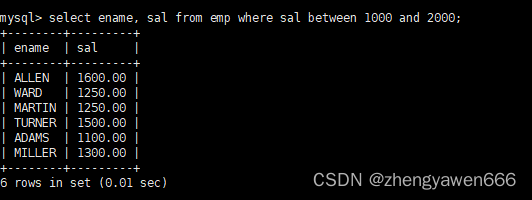
查找一个区间内的数字
一般整数和浮点数才能进行查找
比如筛选出工资在1000到2000的
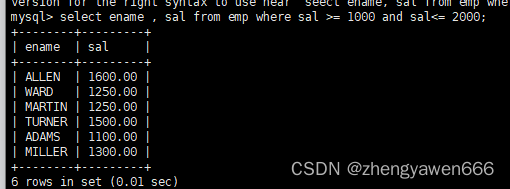
这个其实和这个查找语句是等同的
查找在一个集合内的
成功找到就返回1,找不到就返回-1
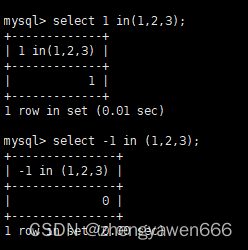
也可以查看某一条记录的某个数据是否在集合范围内
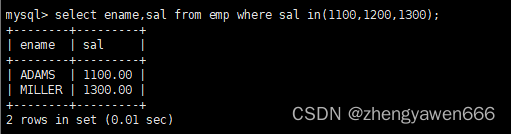
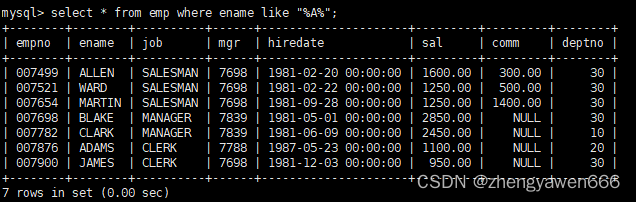
模糊匹配
%多个匹配
-一个匹配
查找以A开头的姓名的人的所有信息

查找姓名中有A的
逻辑运算符
这个是用来连接多个条件的,有时候查询条件可能不止符合一个
| 运算符 | 注释 |
| AND | 多个条件都必须为真才为真 |
| OR | 任意一个条件为真就可以为真 |
| NOT | 如果为真,结果就是假 |
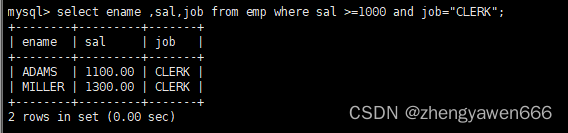
其他的使用也是类似的
需要注意的是,最终结果的显示和查找的条件中的列数可以不相等。比如想查找符合某条件的,但是最终显示的时候不显示对应列也是可以的
比如这个查找的对应工资要大于1000的,但是最后只显示工资大于1000的人的对应的姓名
结果排序
我们可以对查找的结果按照某些顺序进行排序,比如可以按照薪资的多少进行排序,默认是升序,如果我们想按照降序排列带上des
排序不是筛选条件是显示条件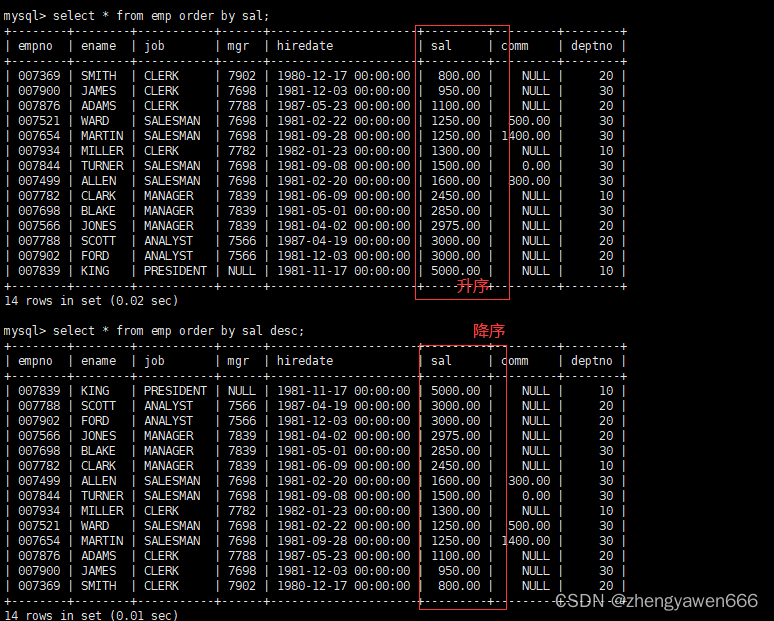
这里一些sal相同的也有顺序,其实是因为这个排序是以排序的关键字为key值进行排序,把整条记录都进行排序了。
对于NULL的话,默认是最小的,如果是升序排序就出现在最上面,降序排序就出现在最下面
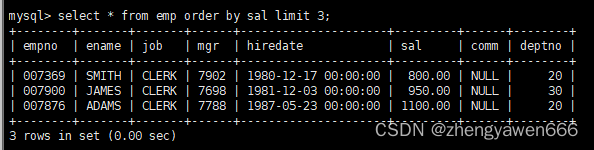
Limit
如何查找符合某些条件的前几名
这样就选出了工资最少的前三名
也可以指定一个区间,起始下标从0开始
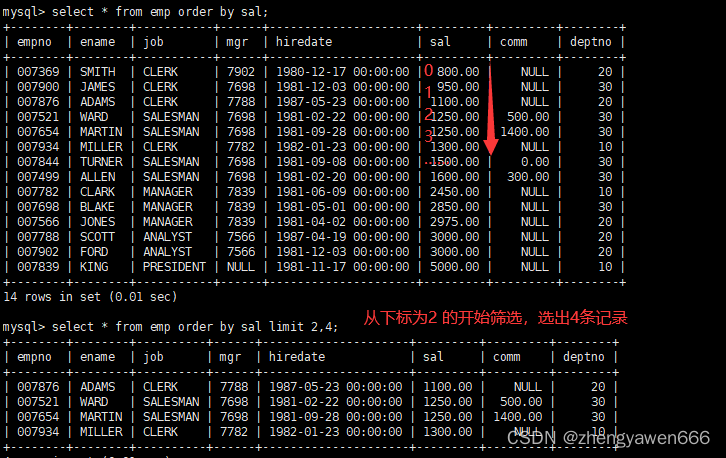
利用这个条件筛选可以实现分批取出数据的目的,一页limit多少数据,这一页放不下就放到下一页
group by 分组
在讲这个的时候,引入聚合函数的概念。因为聚合函数一般都是和group by搭配使用的
聚合函数
mysql内部本身就挺了一些数据库的函数以供我们使用。
对于聚合函数的理解
聚合函数是直接或者简介对列的数据进行统计。由于是列的数据,那么就具有相同的属性。换句话说,相同属性的就具有了聚合函数统计的前提
并且由于是列统计,那么对于一个表的数据进行统计一定是一行或者多行的(一批数据)
总结:对列,具有相同属性 对于一批数据
| 函数 | 注释 |
| COUNT | 返回查询到的数据的数量 |
| SUM | 返回查询到的数据的总和,必须是数字 |
| AVG | 返回查询到的数据的平均值,必须是数字 |
| MAX | 返回查询到的数据的最大值,必须是数字 |
| MIN | 返回查询到的数据的最小值,必须是数字 |
对于count
想查询有多少条记录
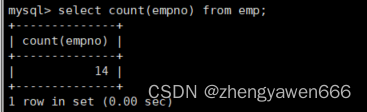
也可以进行重命名
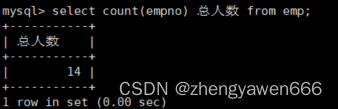
其他的写法
所有的记录*
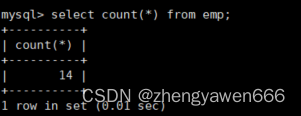
Select 1的时候其实已经把所有的数据都筛选出来了,只不过显示的时候只显示1
这样我们有多少条记录,就有多少个1。
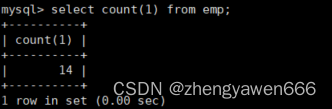
注意直接筛选的时候,null是不参与运算的,也要注意‘ ’为了避免空串的统计可以在条件中设置
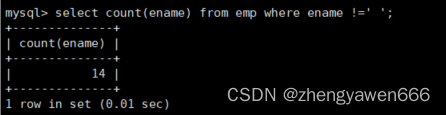
去重
如果不想统计的数据中有重复的,我们就可以使用这个进行去重
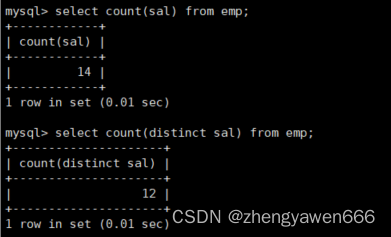
执行的时候先去选出符合条件的不重复的数据,之后再进行统计是比较好的;如果先统计再计算的话,不符合要求,去重之后还需要再次统计,没意义
如果是distinct count(math)的话,是先去统计math的,已经统计了重复的。之后选出数据之后再去重,只不过此时不显示,这样的话我们看到的是7(统计没去重的)
如果是count(distinct math)的话, 是要先对count内部的math做去重之后再进行统计
总结:count的话,是先执行count内的
count都是先有最后的结果数据再统计的
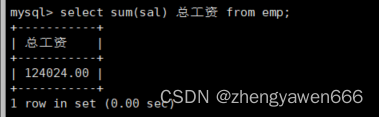
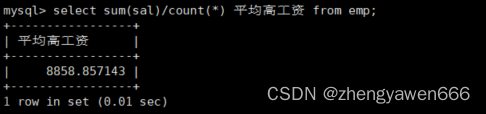
对于sum
也是差不多的,可以计算总和,总和计算出来之后可以计算平均值
这个相当于
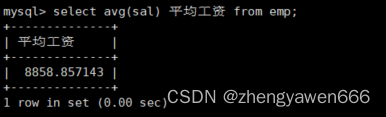
同理,其他的聚合函数也是这么使用的
都是遍历列之后聚合的
对于group by
对指定列分组查询。
之间我们select查询的时候,都是将数据作为一个整体来查询的。其实,mysql也可以支持按照指定的列对数据进行分组,在分组的数据中操作。
比如,可以查找某个部门的最高,最低工资,平均工资
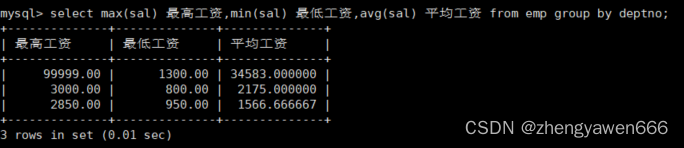
group by和聚合函数搭配使用,执行的顺序是先去执行group by对结果进行分组,之后再去每一组里面进行聚合。如果先执行聚合的话,是对所有数据的,而非组的。
比如上面的,就是先按照部门把人分出来,之后在每一个部门里面分别查找最高最低和平均的工资
相关的语法细节:
①如果有多个分组条件?
比如这个按照部门和工作进行分组,就是先对部门进行分组,再在部门内部根据工作进行分组
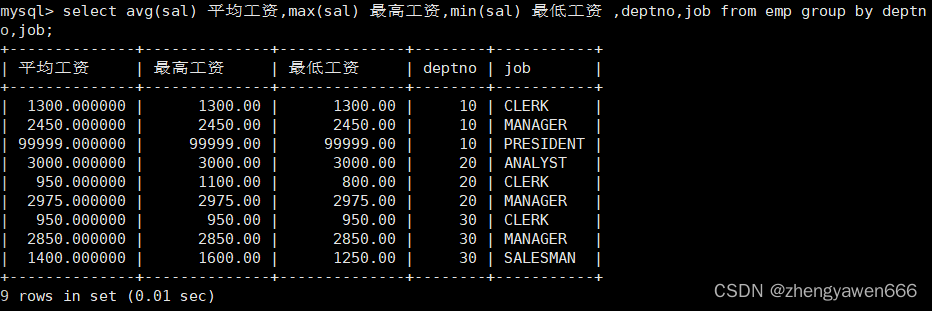
其实相当于一棵多叉树的结构,先按照一个分组的依据,分成一个一个的小表,之后再在小表的内部继续分。
②关于显示
只有group by作为分组条件的列之后在显示的时候才能够显示出来。比如我这里显示想显示部门号和工作,但是我在输入分组条件的时候没有把工作作为分组的依据,因此就不能

③关于分组后筛选
由于where筛选的时候是先有对应的条件才会去对数据进行筛选;但是聚合函数是先有了对应的数据才会去聚合,分组。因此where后面是不能够带上group by的
如果想对group by的结果进行筛选的话,应该需要使用having语句

这里是对group by分组出来的数据,再进行having条件的筛选
总结
group by的话一定会和聚合函数搭配使用统计
如果需要对分组后的条件再进行筛选的话,需要用having语句进行筛选。只有group by才使用having
having与where的区别
where对数据进行初筛;having 对where筛选和group by分组之后的数据再次进行筛选
where的话,执行语句是比较靠前的,是在分组之前先按照where的条件进行筛选,符合条件才会进入group by 的having
having之前通常有聚合函数统计和group by分组
举例子:比如我需要筛选出工资>1000的人,在这条件之下按照部门分组,平均工资<2000的人的相关信息

①先去from emp找到对应的表的数据
②where 对表的数据进行筛选
③group by分组
④avg聚合
⑤对这样分组和聚合的数据进行 having条件筛选
关于执行顺序
where条件设置的时候吗,是按照这样的一个逻辑来查找数据的:
①我们先要去找到对应的表,因此是from先找到表
②之后利用where进行数据的筛选
③group by分组,以便执行聚合函数和having
④执行聚合函数,如果之后有having筛选条件在having最后显示的时候筛选
⑤这样我们就完成了对应的条件的筛选,再去执行select找出符合的对应的列
⑥有了这样的数据才会知道有没有重复的,再去考虑distinct去重
⑦最后order by排序,因为还有一个limit是要在所有的数据都执行的差不多了的情况下才会去找出对应的几条数据
from -》where-》group by -》聚合函数-》having -》 select -》 distinct-》as-》order by -》limit
我们可以这样分类了之后去理解,有两类查询:where和having。与where相关的先用红色标出,橙色的也属于红色,只不过select后面可以重命名和去重比较特殊单独再拎出来
我们执行的时候先去执行where的执行条件,再去看having的
要执行where必须有数据,数据从表来,因此最开始from
from找得出数据后就可以where先进行一轮筛选,筛选的数据如果还需要分组等的筛选,就去执行蓝色的逻辑
这样就相当于完成了两轮的筛选,然后我们再根据一些显示的要求进行设置
order by在select之后是因为必须有select选出的数据再去排序才有意义,防止了一些重复的工作
最后limit一定是最后的,完成了所有工作之后才能去选出符合条件的
三 UPDATE 更新
UPDATE <表名> SET 字段 1=值 1 [,字段 2=值 2… ] [WHERE 子句 ]
[ORDER BY 子句] [LIMIT 子句]更新一般是搭配查询来使用的,把符合条件的数据进行更新。因为只有有了对应的数据,才能对符合条件的数据进行更新。因为如果不配合对应的WHERE语句的话,就把所有的数据都更新了
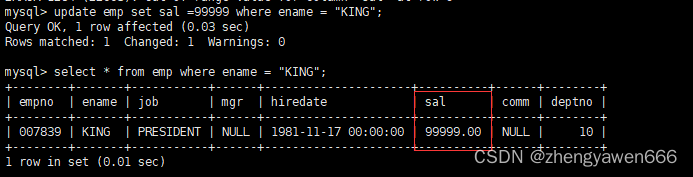
这样就把对应的名字为KING的员工的薪水修改成了99999;
相应的,数据一旦被修改,那么按照之前的条件进行筛选的话,很有可能会产生差异
四 DELETE/TRUNCATE 删除
删除这个操作,一般会带来比较严重的后果,所以不能够轻易地进行删除,只有特定权限的才能删除。
与UPDATE同理,删除的时候一定要注意筛选条件,否则很有可能就把所有的数据都删除了
DELETE
语法
DELETE FROM <表名> [WHERE 子句] [ORDER BY 子句] [LIMIT 子句]注意:
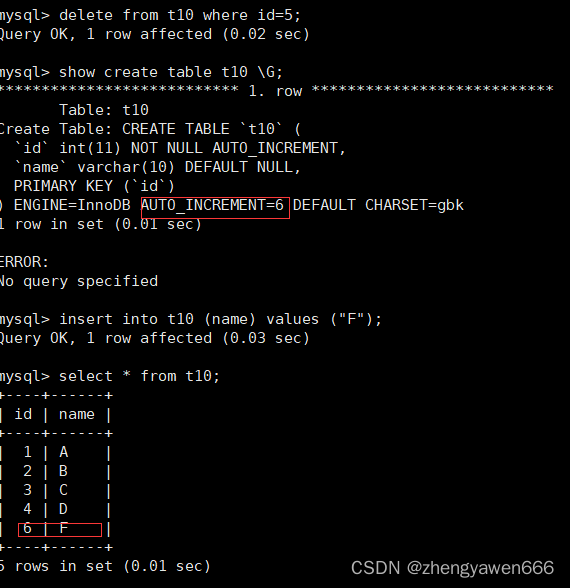
删除数据仅仅是把对应的记录删除了,但是对于auto_increment并不改变,下一次插入的数据也是接着上一个auto_increment的值继续往后插入的
比如我这边有5个数据,我现在删除了1个数据,auto_increment的值并不会变成5,也就是说下一次插入的时候,会被自动分配6
TRUNCATE
TRUNCATE TABLE name这个操作的特点是不能像DELETE一样,设置删除的条件,只能整体删除
这一个操作导致的后果就是表被清空的同时,auto_increment的值也会被修改,从初始值开始。
因为TRUNCATE在删除的时候,比DELETE更快,因为他不经过真正的事务,所以无法进行回滚。它不是对数据进行操作,也不会更新日志,直接把表清空,比delete要快是因为她的工作量更少。他直接干掉表数据,对应的索引结构,日志信息。没法回滚了。
相关文章:
MySQL表的增删查改
目录 一 插入 1 基本语法 ①全列插入 ②指定列插入 ③多条记录插入 ④冲突更新 二 查询 查询全部数据 指定列查询 显示 拼接 取别名 去重查找 where 逻辑运算符和比较运算符 结果排序 Limit group by 分组 聚合函数 对于count 对于sum 对于group by 相关的语…...

详解C语言string.h中常用的14个库函数(三)
本篇博客继续讲解C语言string.h头文件中的库函数。本篇博客计划讲解3个函数,分别是:strstr, strtok, strerror。其中strstr函数我会用一种最简单的方式模拟实现。 strstr char * strstr ( const char * str1, const char * str2 );strstr可以在str1中查…...

无人机视频与GIS融合三维实景怎么实现?
无人机视频与GIS融合三维实景怎么实现?无人机三维GIS作为一项新兴的测绘重要手段,具有续航时间长、成本低、机动灵活等优点,为城市的规划建设带来极大便利。 那么此项技术有什么样的特点呢?下面智汇云舟就带大家一起来了解一下。 三维是将采集以及经运…...

瞬间让你效率提高一倍的高效学习方法
方法不对,努力白费;方法对了,事半功倍!在学习的过程中我们会遇到各种困难与阻碍,如何发现并优化自己的学习方法就变得尤为重要。高效学习方法是指通过科学的、有效的方法来提高学习效率,实现更好的学习成果…...

442. 数组中重复的数据|||41. 缺失的第一个正数|||485. 最大连续 1 的个数
442. 数组中重复的数据 题目 给你一个长度为 n 的整数数组 nums ,其中 nums 的所有整数都在范围 [1, n] 内,且每个整数出现 一次 或 两次 。请你找出所有出现 两次 的整数,并以数组形式返回。 你必须设计并实现一个时间复杂度为 O(n) 且仅…...
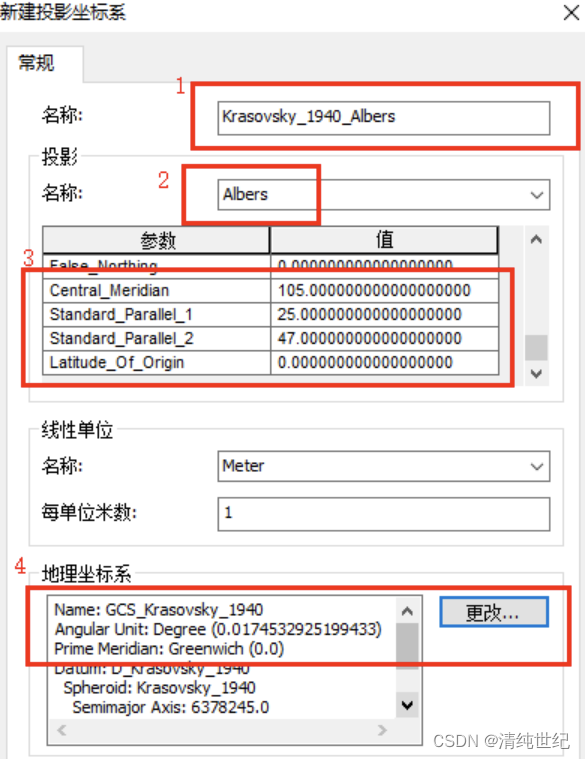
中国地图标准坐标和投影参数
目录 一、地理坐标 二、投影坐标 三、ArcGIS投影变换 四、说明 一、地理坐标 GCS_Krasovsky_1940(克拉索夫斯基_1940椭球体) 具体参数如下图: 每个国家或地区都有各自的基准面,我们通常所说的北京54坐标系、西安80坐标系实际上…...

CNN中卷积层、池化的计算公式
卷积计算公式 1、卷积层输入特征图(input feature map)的尺寸为:(batch_size,Channel,H,W) H(input)表示输入特征图的高 W(input)表示输入特征图的宽 C(input)表示输入特征图的通道数(如果是第一个卷积层则是输入图像的通道数,如果是中间…...

基类派生类多态虚函数?
通常在层次关系的根部有一个基类,其他类则直接或间接的从基类继承而来,这些继承得到的类称为派生类。基类负责定义在层次关系中所有类共同拥有的成员,而每个派生类定义各自特有的成员。 成员函数与继承派生类可以继承其基类的成员, 然而有时…...

像素是什么
像素分为设备像素和设备无关像素。 下面说说来龙去脉。 一、显示器 显示图像的电子设备。 (一)显示器种类 1.LCD LCD(Liquid crystal display),是液体晶体显示,也就是液晶显示器,LCD具有功耗低…...

NAT转换
目录标题 NAT:网络地址转换(cisco篇)一对一(静态)一对多(动态)多对多(动、静均可)端口映射(静态) nat:网络地址转换(华为篇࿰…...

设计模式:创建者模式 - 单例模式
文章目录 1.介绍2.单例模式的结构3.单例模式的实现(饿汉、懒汉)饿汉式-方式1(静态变量方式)饿汉式-方式2(静态代码块方式)懒汉式-方式1(线程不安全)懒汉式-方式2(线程安全…...

C++语言亚马逊国际获取AMAZON商品详情 API接口(
跨境电子商务是一种全新的互联网电商模式,运用电子化方式促成线上跨境交易,利用跨境物流运送商品,有利于打破传统的贸易格局,成为新的经济增长点。对我国来说,跨境电商平台正用一种全新的力量改变我国产业链的结构&…...
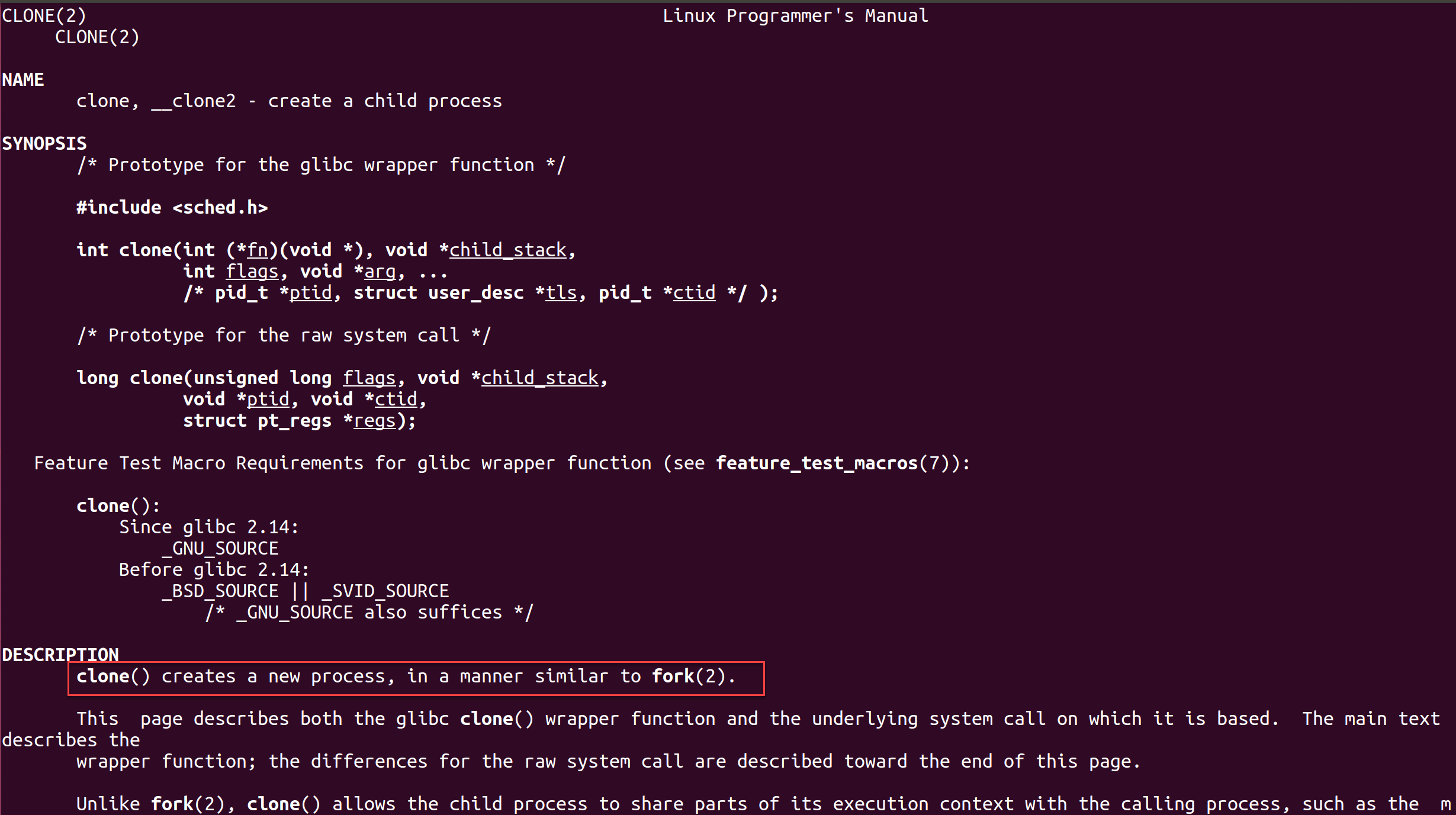
在程序里面执行system(“cd /某个目录“),为什么路径切换不成功?
粉丝提问: 彭老师,问下,在程序里面执行system(“cd /某个目录”),这样会切换不成功,为啥呢 实例代码: 粉丝的疑惑是明明第10行执行了cd /media操作, 为什么12行执行的pwd > test2.txt 结…...

c++ 对类与对象的基础框架+完整思维导图+基本练习题+深入细节+通俗易懂建议收藏
绪论 上一章,我们将c入门的基础知识进行了学习,本章其实才算真正的跨入到c开始可能比较难,但只有我们唯有不断的前进,才能斩断荆棘越过人生的坎坷! 话不多说安全带系好,发车啦(建议电脑观看&…...
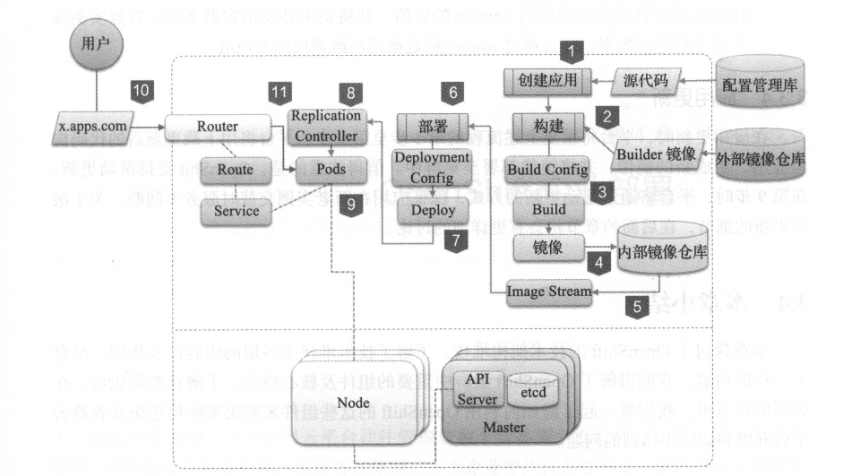
关于Open Shift(OKD) 中应用管理部署的一些笔记
写在前面 因为参加考试,会陆续分享一些 OpenShift 的笔记博文内容为介绍 openshift 不同的创建应用的方式,包括: 基于 IS 创建应用基于镜像创建应用基于源码和 image 创建应用基于源码和 IS 创建应用基于模板创建应用 学习环境为 openshift v…...
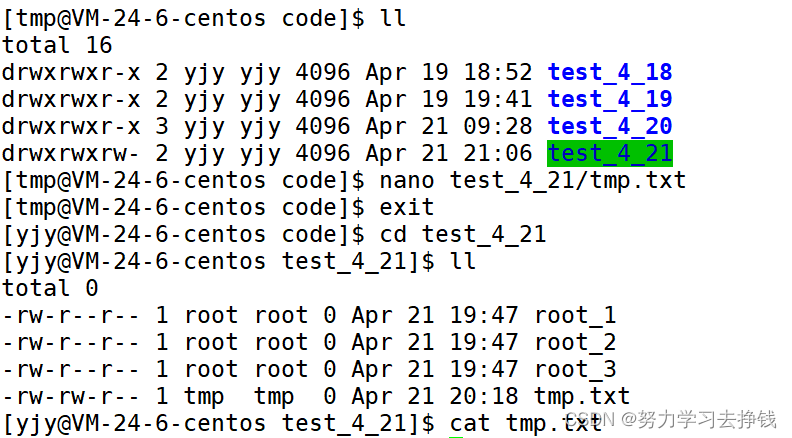
【linux】对于权限的理解
权限 Linux权限的概念用户之间的切换 Linux权限管理文件权限操作文件的人Linux文件默认权限的设置权限掩码 所属组/其他删除拥有者创建的文件文件拥有者、所属组的修改修改文件拥有者修改文件所属组一次性修改拥有者和所属组 目录的执行权限 Linux权限的概念 首先,…...
测试人必备技能:如何进行WebSocket接口测试?
目录 前言 WebSocket介绍 HTTP与WebSocket的区别 二者关系 WebSocket测试方法 使用Postman 使用Jmeter 使用Python 结语 前言 随着Web应用的日益普及,WebSocket作为一种全双工通信协议,在移动端、游戏、视频会议等方面得到广泛应用。 而对于需…...

【Android FrameWork (三)】- SystemServer
文章目录 知识回顾启动第一个流程initZygote的流程 前言源码分析1.system_server2.SystemServer.main3,startBootstrapServices4,startService 拓展知识LoadApkcontext 对于Android context 大家是怎么理解的?LocalServices.java: addServece方法中 ArrayMap和HashM…...

Docker容器部署及基本使用
文章目录 一、环境初始化配置二、安装Docker三、优化配置四、基础命令 一、环境初始化配置 1、关闭防火墙 systemctl stop firewalld systemctl disable firewalldsetenforce 0sed -i s/SELINUXenforcing/SELINUXdisabled/g /etc/selinux/config sed -i s/SELINUXenforcing/S…...
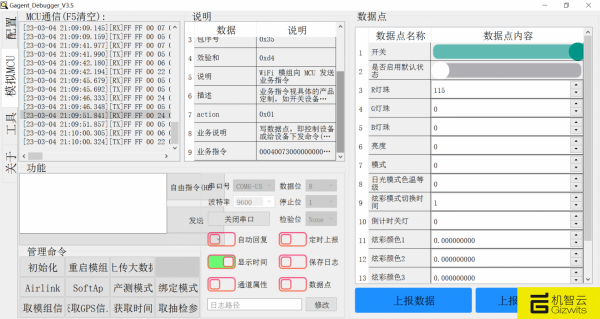
【机智云物联网低功耗转接板】+模拟MCU快速上手
GE211是机智云自研的定制化转接板,使用 ESP32-C3-WROOM-02 通讯模块,适用于白色智能家电等设备应用。 转接板已经烧录了机智云连云的最新GAgent固件,所以不需要烧写任何软件就可以快速上手使用。 GE211板卡带有一个串口,一般是把这…...

python智能ai技术的智慧城市便民服务管理中心平台_668r7c05
目录同行可拿货,招校园代理 ,本人源头供货商项目背景核心技术功能模块应用场景优势与创新项目技术支持获取博主联系方式 源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目…...

怎样快速去掉照片背景?2026年AI抠图工具实测对比与使用指南
还在为复杂的照片背景发愁?想要快速批量处理多张照片?本文将带你深入了解2026年最新的照片去背景方法,从零基础的在线工具到专业级别的桌面软件,再到智能AI抠图方案,帮你找到最适合自己的解决方案。快速去背景的核心方…...

Armv8/v9架构系统寄存器解析:SCXTNUM与SMCR深度剖析
1. AArch64系统寄存器概述 在Armv8/v9架构中,系统寄存器是处理器状态和控制的核心枢纽。与通用寄存器不同,系统寄存器专门用于配置处理器功能、监控运行状态以及实现安全隔离。AArch64架构通过精心设计的寄存器命名规范,使得寄存器的功能和访…...

Godot原生强化学习集成:零Python实现AI训练与部署
1. 这不是又一个“Hello World”式教程:为什么GodotRL的组合值得你花10分钟认真看我第一次在Godot Asset Library里点开那个标着“Reinforcement Learning Agent”的插件时,心里是带着怀疑的——毕竟过去三年里,我试过七种不同方式把强化学习…...

TokUnion 技术架构解析:AI+GEO 驱动的跨境增长数据闭环设计
摘要最近这个时间段,是国货出海精细化与合规化转型背景的深度期,传统粗放式广告投放,和单一渠道运营模式面临获客成本高、ROI 不可控、数据孤岛、合规风险突出等问题。下面这个文章,我会以TokUnion数字化协同体系为研究对象&#…...

Taotoken多模型聚合能力在内容生成场景中的灵活应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken多模型聚合能力在内容生成场景中的灵活应用 对于新媒体运营和内容创作者而言,内容生成是核心工作之一。不同的…...

MapReduce与Spark核心原理对比:从批处理到内存计算的演进
1. 从“批处理之王”到“内存计算引擎”:大数据处理范式的演进如果你刚接触大数据领域,可能会被Hadoop、MapReduce、Spark这些名词搞得晕头转向。它们听起来都像是处理海量数据的“重型武器”,但各自的设计哲学和适用场景却大相径庭。简单来说…...

终极指南:3分钟学会用Awoo Installer免费安装Switch游戏
终极指南:3分钟学会用Awoo Installer免费安装Switch游戏 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 还在为Switch游戏安装而烦恼吗…...

保姆级教程✅ 从零学InVEST/SolVES模型,附QGIS/PostgreSQL/R语言实操+数据预处理全流程
本内容将讲述用于评估生态系统服务价值的当量因子法、InVEST模型、SolVES模型及其原理,通过本课程的学习,您将学会三种模型的原理与运行方法:如何获取与制备模型数据;如何进行当量因子转换;如何利用InVEST模型进行生态…...

揭秘AI专著撰写:工具加持,20万字专著快速成型!
AI专著写作:挑战与工具解决方案 学术专著的撰写,不仅考验着研究者的学术能力,更是对心理耐受力的一种挑战。与团队合作撰写论文不同,专著大多是由个人独立完成的。从选题到框架构建,再到具体内容的撰写、修改…...