分治与减治算法实验: 排序中减治法的程序设计
目录
前言
实验内容
实验目的
实验分析
实验过程
流程演示
写出伪代码
实验代码
代码详解
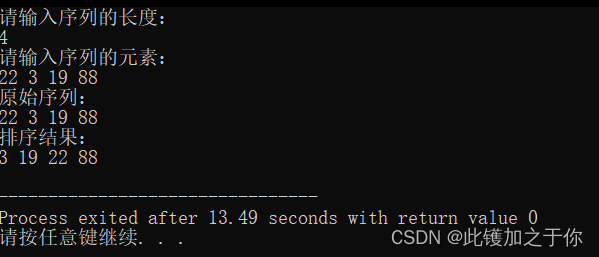
运行结果
总结
前言
本文介绍了算法实验排序中减治法的程序设计。减治法是一种常用的算法设计技术,它通过减少问题的规模来求解问题。减治法可以应用于排序问题,例如插入排序、选择排序和快速排序等。本文将分析这些排序算法的原理、实现和性能,并给出相应的程序代码和测试结果。
本文中使用的语言是C语言,使用的工具是devc++
实验内容
给出一个记录序列,用堆排序的方法将其进行升序排列,输出结果,输出时要求有文字说明。请任选一种语言编写程序实现上述算法,并分析其算法复杂度。
实验目的
(1)掌握堆的有关概念;
(2)掌握堆排序的基本思想和其算法的实现过程;
(3)熟练掌握筛选算法的实现过程;
(4)在掌握的基础上编程实现堆排序的具体实现过程。
实验分析
这个题目要求使用堆排序的方法将一个记录序列进行升序排列,并输出结果和文字说明。需要选择一种编程语言来实现堆排序算法,并分析其算法复杂度。这个题目考察了对堆排序算法的理解和应用能力,以及你对编程语言的掌握程度和代码风格的规范性。需要注意以下几点:
- 堆排序算法是一种基于二叉堆结构的排序方法,它利用了二叉堆的性质,即堆顶元素是最大或最小值,来不断地选出序列中的最大或最小值,并将其放在正确的位置。它分为两个步骤:构建堆和调整堆。构建堆是从最后一个非叶子节点开始,自下而上地调整每个节点,使其满足大顶堆或小顶堆的性质。调整堆是从最后一个元素开始,将堆顶元素与末尾元素交换,然后调整剩余的元素为新的堆,重复这个过程直到只剩一个元素。
- 堆排序算法的时间复杂度为O(nlogn),空间复杂度为O(1)。它是一种原地排序算法,不需要额外的空间来存储数据。它的时间复杂度是由构建堆和调整堆的次数决定的,每次构建或调整堆都需要O(logn)的时间,而总共需要进行n次构建或调整,所以总的时间复杂度为O(nlogn)。它的空间复杂度是由交换元素所需的辅助空间决定的,每次交换只需要一个临时变量来存储数据,所以总的空间复杂度为O(1)。
实验过程
流程演示
- 首先,我们从最后一个非叶子节点开始,自下而上构建大顶堆。最后一个非叶子节点的索引是(n/2-1),其中n是序列的长度。在这个例子中,n=9,所以最后一个非叶子节点的索引是3,对应的元素是6。我们从这个节点开始,依次向上调整每个节点,使其满足大顶堆的性质。调整的过程是:比较当前节点和它的左右孩子,如果当前节点小于它的左右孩子中的任何一个,就交换它们,并递归地调整被交换的子树。调整后的结果如下:
9/ \8 7/ \ / \6 5 4 3/ \2 1
- 然后,我们将堆顶元素与末尾元素交换,即将9和1交换,这样我们就得到了序列中的最大值,并将其放在了正确的位置。交换后,我们将剩余的元素(除了最后一个)看作一个新的堆,并对其进行调整,使其满足大顶堆的性质。调整后的结果如下:
8/ \6 7/ \ / \2 5 4 3/
1
- 接着,我们重复上面的步骤,将堆顶元素与末尾元素交换,即将8和2交换,这样我们就得到了序列中的第二大值,并将其放在了正确的位置。交换后,我们将剩余的元素(除了最后两个)看作一个新的堆,并对其进行调整,使其满足大顶堆的性质。调整后的结果如下:
7/ \6 4/ \ /1 5 3/
2
- 我们继续重复上面的步骤,直到只剩一个元素为止。每次交换和调整后,我们都会得到序列中的一个最大值,并将其放在了正确的位置。最终,我们得到了升序排列的序列[1, 2, 3, 4, 5, 6, 7, 8, 9]
写出伪代码
//定义一个交换函数,接受一个数组和两个索引作为参数,交换这两个索引对应的元素
swap(arr, i, j):temp <- arr[i]arr[i] <- arr[j]arr[j] <- temp//定义一个调整函数,接受一个数组,一个数组的长度,和一个需要调整的节点的索引作为参数,调整该节点和它的子树,使其满足大顶堆的性质
heapify(arr, n, i):largest <- i //假设当前节点为最大值left <- 2 * i + 1 //左孩子的索引right <- 2 * i + 2 //右孩子的索引//如果左孩子存在且大于当前节点,更新最大值的索引if left < n and arr[left] > arr[largest]:largest <- left//如果右孩子存在且大于当前节点,更新最大值的索引if right < n and arr[right] > arr[largest]:largest <- right//如果最大值不是当前节点,交换它们,并递归地调整被交换的子树if largest != i:swap(arr, i, largest)heapify(arr, n, largest)//定义一个堆排序函数,接受一个数组和一个数组的长度作为参数,对该数组进行升序排列
heapSort(arr, n)://从最后一个非叶子节点开始,自下而上地构建大顶堆for i from n / 2 - 1 to 0:heapify(arr, n, i)//从最后一个元素开始,将堆顶元素与末尾元素交换,然后调整剩余的元素为新的大顶堆,重复这个过程直到只剩一个元素for i from n - 1 to 1:swap(arr, 0, i)heapify(arr, i, 0)//定义一个打印函数,接受一个数组和一个数组的长度作为参数,打印该数组中的每个元素
printArray(arr, n):for i from 0 to n - 1:print arr[i] and a spaceprint a newline//测试代码
main()://通过键盘输入序列的长度和元素print "请输入序列的长度:"read n //读取序列的长度print "请输入序列的元素:"arr <- an array of size n //动态分配内存空间存储序列for i from 0 to n - 1:read arr[i] //读取每个元素//输出原始序列print "原始序列:"printArray(arr, n)//使用堆排序算法对序列进行升序排列heapSort(arr, n)//输出排序结果print "排序结果:"printArray(arr, n)实验代码
#include <stdio.h>
#include <stdlib.h>//交换数组中的两个元素
void swap(int arr[], int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;
}//调整数组中的元素,使其满足大顶堆的性质
void heapify(int arr[], int n, int i) {int largest = i; //假设当前节点为最大值int left = 2 * i + 1; //左孩子的索引int right = 2 * i + 2; //右孩子的索引//如果左孩子存在且大于当前节点,更新最大值的索引if (left < n && arr[left] > arr[largest]) {largest = left;}//如果右孩子存在且大于当前节点,更新最大值的索引if (right < n && arr[right] > arr[largest]) {largest = right;}//如果最大值不是当前节点,交换它们,并递归调整被交换的子树if (largest != i) {swap(arr, i, largest);heapify(arr, n, largest);}
}//堆排序算法
void heapSort(int arr[], int n) {//从最后一个非叶子节点开始,自下而上构建大顶堆for (int i = n / 2 - 1; i >= 0; i--) {heapify(arr, n, i);}//从最后一个元素开始,将堆顶元素与末尾元素交换,然后调整剩余的元素为新的大顶堆,重复这个过程直到只剩一个元素for (int i = n - 1; i > 0; i--) {swap(arr, 0, i);heapify(arr, i, 0);}
}//打印数组
void printArray(int arr[], int n) {for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}printf("\n");
}//测试代码
int main() {//通过键盘输入序列的长度和元素printf("请输入序列的长度:\n");int n;scanf("%d", &n); //读取序列的长度printf("请输入序列的元素:\n");int *arr = (int *)malloc(sizeof(int) * n); //动态分配内存空间存储序列for (int i = 0; i < n; i++) {scanf("%d", &arr[i]); //读取每个元素}//输出原始序列printf("原始序列:\n");printArray(arr, n);//使用堆排序算法对序列进行升序排列heapSort(arr, n);//输出排序结果printf("排序结果:\n");printArray(arr, n);//释放内存空间free(arr);return 0;
}代码详解
代码分为以下几个部分:
- 交换数组中的两个元素的函数swap,它接受一个数组和两个索引作为参数,然后将这两个索引对应的元素互换位置。
- 调整数组中的元素,使其满足大顶堆的性质的函数heapify,它接受一个数组,一个数组的长度,和一个需要调整的节点的索引作为参数。它首先假设当前节点为最大值,然后比较它和它的左右孩子,如果左右孩子中有比它大的,就更新最大值的索引。如果最大值不是当前节点,就交换它们,并递归地调整被交换的子树。
- 堆排序算法的函数heapSort,它接受一个数组和一个数组的长度作为参数。它首先从最后一个非叶子节点开始,自下而上构建大顶堆。然后从最后一个元素开始,将堆顶元素与末尾元素交换,然后调整剩余的元素为新的大顶堆,重复这个过程直到只剩一个元素。
- 打印数组的函数printArray,它接受一个数组和一个数组的长度作为参数。它遍历数组中的每个元素,并打印出来。
- 测试代码的主函数main,它定义了一个待排序的序列,并调用了heapSort函数对其进行排序,并打印了排序前后的结果。
运行结果
总结
减治法是一种算法设计策略,它的基本思想是将一个规模为n的问题转化为一个规模为n-1的子问题,然后利用子问题的解来求解原问题。减治法可以分为三种类型,分别是减去一个常量、减去一个常数因子和减去一个可变因子。在排序问题中,减治法有很多应用,例如插入排序、堆排序等。
插入排序是一种基于减一法的排序算法,它的过程类似于扑克牌抓牌时的排序。每次从未排序的序列中取出一个元素,将其插入到已排序的序列中合适的位置,使得已排序的序列仍然有序。插入排序的时间复杂度为O(n^2),空间复杂度为O(1)。插入排序是一种稳定的排序算法,也就是说,相同元素的相对顺序不会改变。
堆排序是一种基于减去常数因子的排序算法,它的过程利用了堆这种数据结构。堆是一种特殊的完全二叉树,它满足堆序性质,即每个节点的值都不小于(或不大于)其子节点的值。堆可以分为最大堆和最小堆,分别用于降序和升序排列。堆排序的过程分为两个步骤:建堆和调整堆。建堆是将一个无序的数组构造成一个堆,调整堆是每次将堆顶元素与最后一个元素交换,并将剩余的元素重新调整成一个堆,直到只剩下一个元素。堆排序的时间复杂度为O(nlogn),空间复杂度为O(1)。堆排序是一种不稳定的排序算法,也就是说,相同元素的相对顺序可能会改变。
相关文章:
分治与减治算法实验: 排序中减治法的程序设计
目录 前言 实验内容 实验目的 实验分析 实验过程 流程演示 写出伪代码 实验代码 代码详解 运行结果 总结 前言 本文介绍了算法实验排序中减治法的程序设计。减治法是一种常用的算法设计技术,它通过减少问题的规模来求解问题。减治法可以应用于排序问题&…...

leetcode两数、三数、四数之和
如有错误,感谢不吝赐教、交流 文章目录 两数之和题目方法一:暴力两重循环(不可取)方法二:HashMap空间换时间 三数之和题目方法一:当然是暴力破解啦方法二:同两数之和的原理,借助Has…...
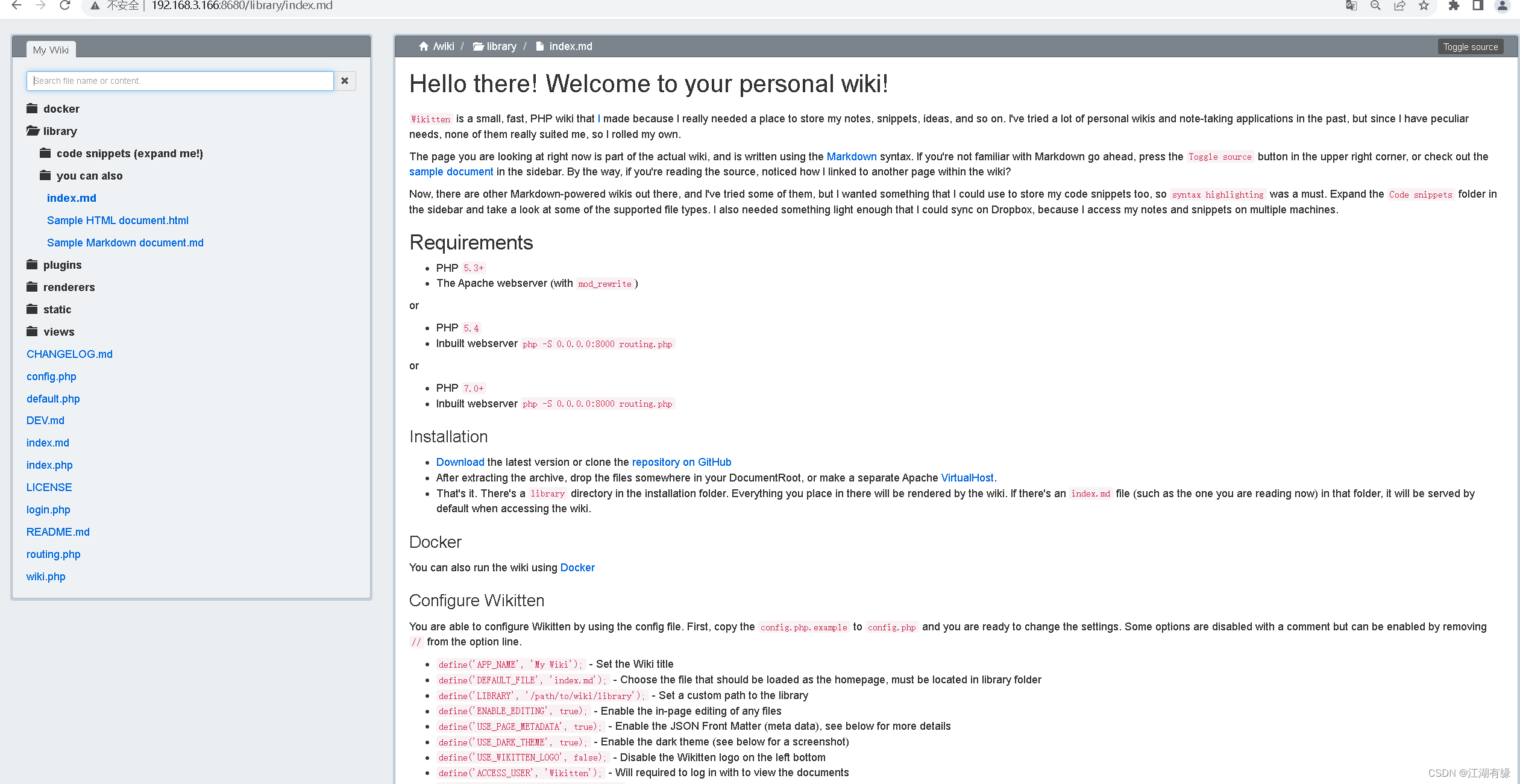
使用Docker部署wikitten个人知识库
使用Docker部署wikitten个人知识库 一、wikitten介绍1.wikitten简介2.wikitten特点 二、本地实践环境介绍三、本地环境检查1.检查Docker服务状态2.检查Docker版本 四、部署wikitten个人知识库1.创建数据目录2.下载wikitten镜像3.创建wikitten容器4.查看wikitten容器状态5.检查w…...
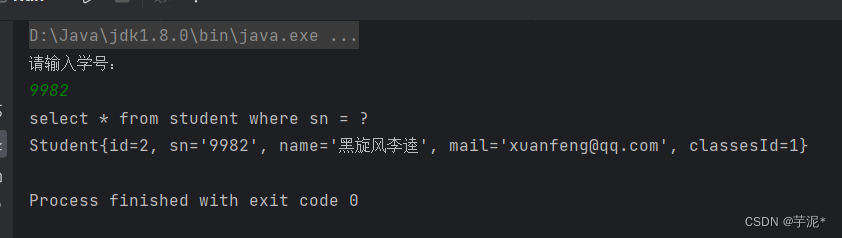
【MYSQL】Java的JDBC编程(idea连接数据库)
1. 配置 (1)新建一个项目 (2)Build System 那里选择Maven,下一步Create (3)配置pom.xml文件 首先查看自己的MYSQL版本:进入MySQL命令窗口 我的MYSQL版本是8.0版本的. 下一步,…...
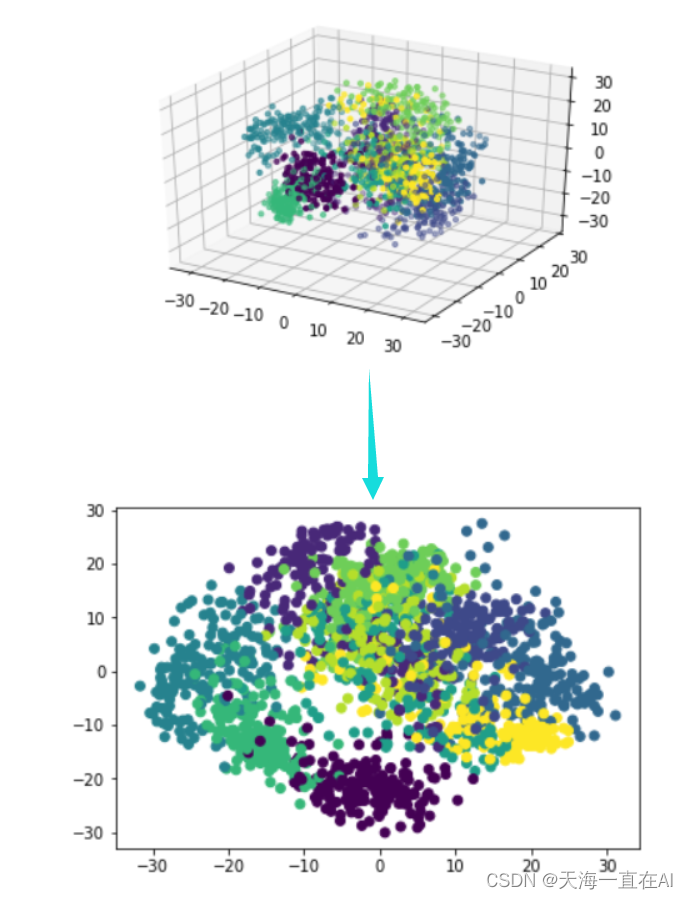
机器学习——主成分分析法(PCA)概念公式及应用python实现
机器学习——主成分分析法(PCA) 文章目录 机器学习——主成分分析法(PCA)一、主成分分析的概念二、主成分分析的步骤三、主成分分析PCA的简单实现四、手写体识别数字降维 一、主成分分析的概念 主成分分析(PCA&#x…...
手写axios源码系列二:创建axios函数对象
文章目录 一、模块化目录介绍二、创建 axios 函数对象1、创建 axios.js 文件2、创建 defaults.js 文件3、创建 _Axios.js 文件4、总结 当前篇章正式进入手写 axios 源码系列,我们要真枪实弹的开始写代码了。 因为 axios 源码的代码量比较庞大,所以我们这…...

HTB-Time
HTB-Time 信息收集80端口 立足pericles -> root 信息收集 80端口 有两个功能,一个是美化JSON数据。 一个是验证JSON,并且输入{“abc”:“abc”}之类的会出现报错。 Validation failed: Unhandled Java exception: com.fasterxml.jackson.core.JsonPa…...

零基础C/C++开发到底要学什么?
作者:黑马程序员 链接:https://www.zhihu.com/question/597037176/answer/2999707086 先和我一起看看,C/C学完了可以做什么: 软件工程师:负责设计、开发、测试和维护各类型的软件应用程序;游戏开发&#x…...

OpenStack中的CPU与内存超分详解
目录 什么是超分 CPU超分 查看虚拟机虚拟CPU运行在哪些物理CPU上 内存超分 内存预留 内存共享 如何设置内存预留和内存共享 全局设置 临时设置 什么是超分 超分通常指的是CPU或者GPU的分区或者分割,以在一个物理CPU或GPU内模拟多个逻辑CPU或GPU的功能。这…...

main.m文件解析--@autoreleasepool和UIApplicationMain
iOS 程序入口UIApplicationMain详解,相信大家新建一个工程的时候都会看到一个main.m文件,只不过我们很少了解它,现在我们分析一下它的作用是什么? 一、main.m文件 int main(int argc, char * argv[]) {autoreleasepool {return …...
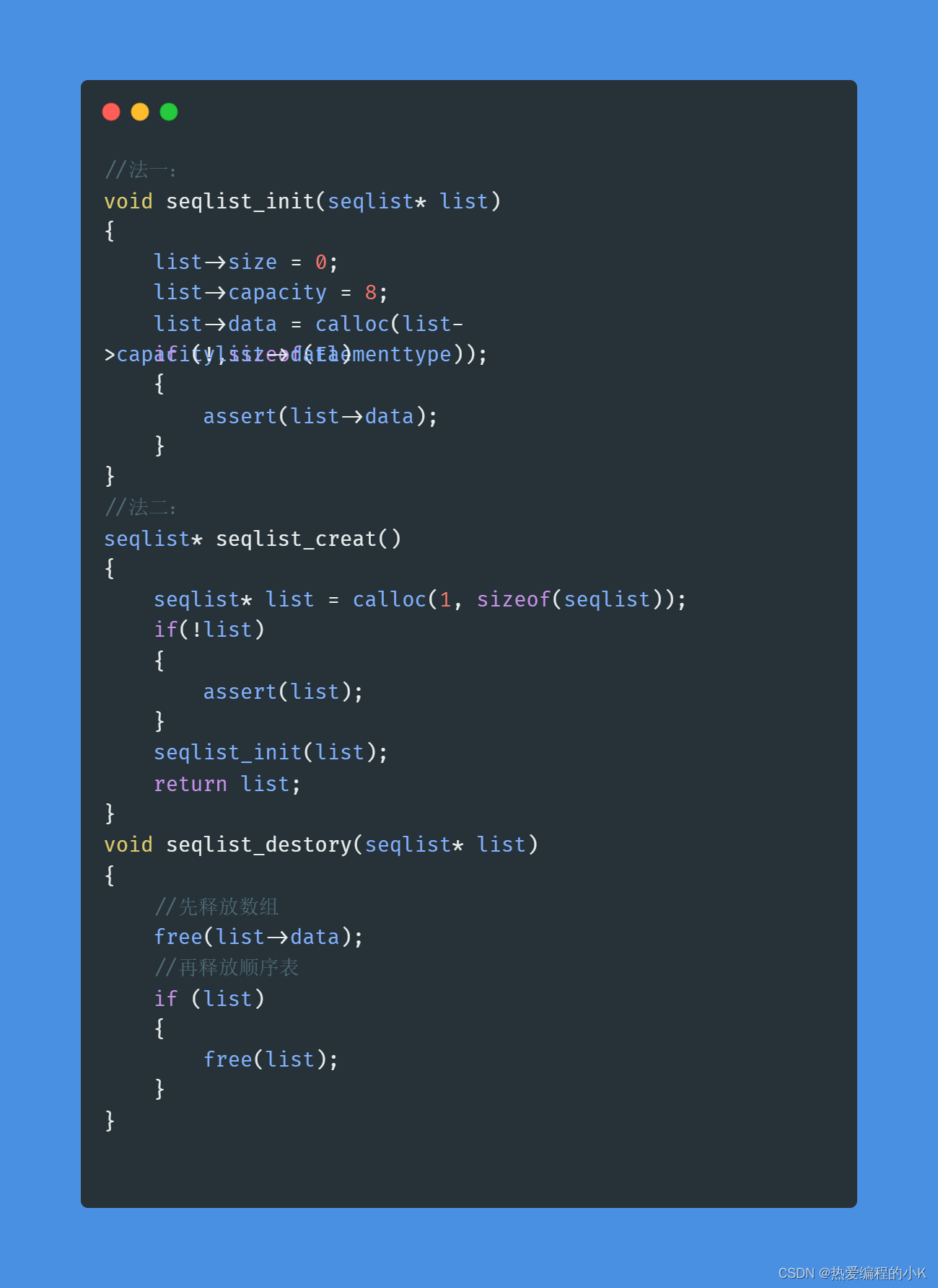
C语言复习之顺序表(十五)
📖作者介绍:22级树莓人(计算机专业),热爱编程<目前在c阶段>——目标C、Windows,MySQL,Qt,数据结构与算法,Linux,多线程,会持续分享…...
学系统集成项目管理工程师(中项)系列10_立项管理
1. 系统集成项目管理至关重要的一个环节 2. 重点在于是否要启动一个项目,并为其提供相应的预算支持 3. 项目建议 3.1. Request for Proposal, RFP 3.2. 立项申请 3.3. 项目建设单位向上级主管部门提交的项目申请文件,是对拟建项目提出的总体设想 3…...

电视盒子哪个好?数码小编盘点2023电视盒子排行榜
随着网络剧的热播,电视机又再度受宠,电视盒子也成为不可缺少的小家电。但面对复杂的参数和品牌型号,挑选时不知道电视盒子哪款最好,小编根据销量和用户评价整理半个月后盘点了电视盒子排行榜前五,对电视盒子哪个好感兴…...
flink动态表的概念详解
目录 前言🚩 动态表和持续不断查询 stream转化成表 连续查询 查询限制 表转化为流 前言🚩 传统的数据库SQL和实时SQL处理的差别还是很大的,这里简单列出一些区别: 尽管存在这些差异,但使用关系查询和SQL处理流并…...

ArcGIS Pro用户界面
目录 1 功能区 1.1 快速访问工具栏 1.2 自定义快速访问工具栏 1.3 自定义功能区选项 1.3.1 添加组和命令 1.3.2 添加新选项卡 2 视图 3 用户界面排列 编辑 4 窗格 4.1 内容窗格 4.2 目录窗格 4.3 目录视图(类似ArcCatalog) 4.4 浏览对话框…...

HDCTF 2023 Pwn WriteUp
Index 前言Pwnner分析EXP: KEEP_ON分析EXP: Minions分析EXP: 后记: 前言 本人是菜狗,比赛的时候只做出来1题,2题有思路但是不会,还是太菜了。 栈迁移还是不会,但又都是栈迁移的题,真头大。得找时间好好学学…...

【 Spring 事务 】
文章目录 一、为什么需要事务(简单回顾)二、MySQL 中的事务使⽤三、Spring 中事务的实现3.1 Spring 编程式事务(手动事务)3.2 Spring 声明式事务(自动事务)3.2.1 Transactional 作⽤范围3.2.2 Transactional 参数说明3.2.3 Transactional 不进行事务回滚的情况3.2.4 Transactio…...
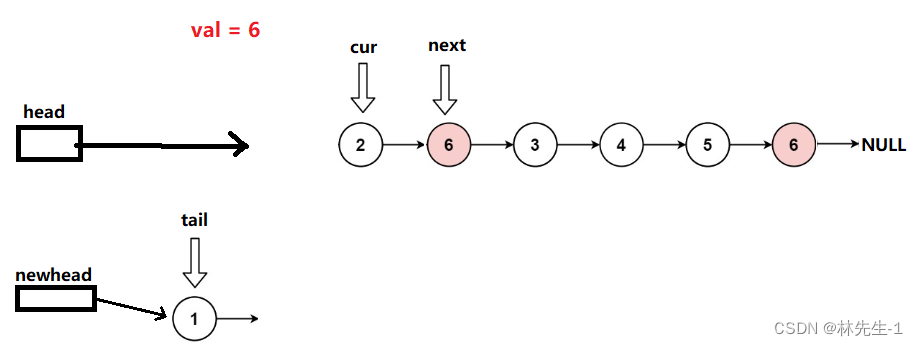
【刷题之路】LeetCode 203. 移除链表元素
【刷题之路】LeetCode 203. 移除链表元素 一、题目描述二、解题1、方法1——在原链表上动刀子1.1、思路分析1.2、代码实现 2、方法2——使用额外的链表2.1、思路分析2.2、代码实现 一、题目描述 原题连接: 203. 移除链表元素 题目描述: 给你一个链表的…...
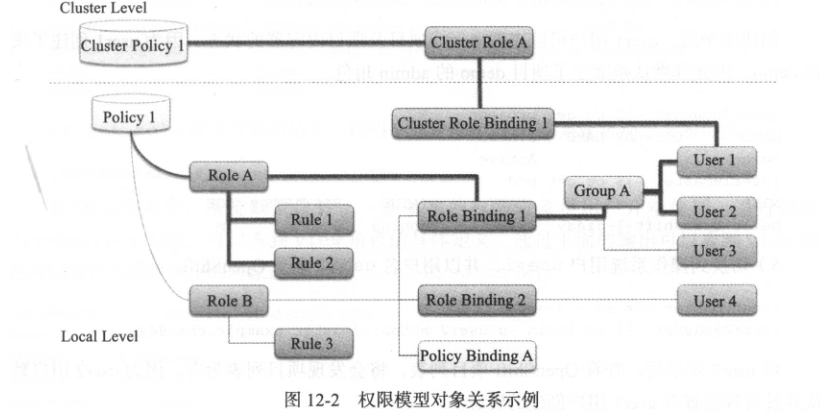
关于Open Shift(OKD) 中 用户认证、权限管理、SCC 管理的一些笔记
写在前面 因为参加考试,会陆续分享一些 OpenShift 的笔记博文内容为 openshift 用户认证和权限管理以及 scc 管理相关笔记学习环境为 openshift v3 的版本,有些旧这里如果专门学习 openshift ,建议学习 v4 版本理解不足小伙伴帮忙指正 对每个…...
)
活动文章测试(勿删)
大家好! 我是CSDN官方博客! 恭喜你正式加入CSDN博客,迈上技术成神之路~~ 路漫漫其修远兮——身为技术人,求索之路道阻且艰,但一万次的翘首却比不过一次的前行。 现在,就来开启你的个人博客,发布…...

2026年,IP地理位置精准查询的几个硬核技术变化
关于IP定位相关最近和几个同行交流,发现大家对IP定位的理解还停留在之前,想把自己这段时间的一些实践整理出来,希望能给同样在搞网络或风控的同行一些参考。 IPv6流量超过IPv4、住宅代理攻击泛滥、CGNAT覆盖越来越广……这些变化正在悄悄改变…...

通过用量看板分析不同模型在taotoken上的实际token消耗差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析不同模型在taotoken上的实际token消耗差异 效果展示类,分享一名开发者在完成一个多轮对话项目后&…...

RLHF工程化实践:用合成反馈替代人工标注的完整闭环
1. 这不是“替代人类”的口号,而是一套可落地的RLHF工程闭环“Build Your Own RLHF LLM — Forget Human Labelers!” 这个标题一出来,很多同行第一反应是皱眉——不是质疑技术可行性,而是警惕它背后可能隐含的简化主义陷阱。我带过三轮大模型…...

无监督聚类挖掘声音语义:从音乐描述文本发现认知规律
1. 这不是传统聚类,而是一场对“声音语言”的考古式挖掘你有没有试过听一首歌,然后被某段音色击中——那种“像融化的玻璃糖纸裹着雨滴坠落”的感觉?或者在音乐评论区刷到“低频像沉入深海的青铜钟”“人声有未拆封的羊皮纸质感”这类描述&am…...

时序分析核心概念与实战:从数据特征到数据库选型
1. 项目概述:为什么我们需要“时序分析”?如果你在金融、物联网、工业制造、运维监控或者电商数据分析等领域工作过,那么“时序数据”这个词对你来说一定不陌生。简单来说,时序数据就是一系列按时间顺序排列的数据点。听起来很简单…...

Mainframer错误排查指南:常见问题及解决方法大全
Mainframer错误排查指南:常见问题及解决方法大全 【免费下载链接】mainframer Tool for remote builds. Sync project to remote machine, execute command, sync back. 项目地址: https://gitcode.com/gh_mirrors/ma/mainframer Mainframer是一款高效的远程…...

iTorrent完整指南:如何在iPhone上实现专业级种子下载管理
iTorrent完整指南:如何在iPhone上实现专业级种子下载管理 【免费下载链接】iTorrent Torrent client for iOS 16 项目地址: https://gitcode.com/gh_mirrors/it/iTorrent iTorrent是一款专为iOS 16设备设计的专业种子客户端应用,让你能够在iPhone…...

Real-ESRGAN图像增强:3步掌握AI超分辨率魔法
Real-ESRGAN图像增强:3步掌握AI超分辨率魔法 【免费下载链接】Real-ESRGAN Real-ESRGAN aims at developing Practical Algorithms for General Image/Video Restoration. 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN 你是否曾为模糊的老照片、…...

【Midjourney拟物化风格实战指南】:20年视觉设计专家亲授3大材质渲染公式与5步出图工作流
更多请点击: https://kaifayun.com 第一章:拟物化风格的本质与Midjourney语义解码 拟物化(Skeuomorphism)并非简单的视觉仿拟,而是一种通过材质、光影、物理反馈等多维语义锚点唤起用户认知惯性的交互范式。在AI图像生…...

离子阱量子变分算法原理与优化实践
1. 离子原生量子变分算法解析在量子计算领域,变分量子算法(VQA)已成为解决组合优化问题的主流方法。这类算法的核心在于设计高效的参数化量子线路(ansatz),而传统方法通常依赖于大量纠缠门的组合。离子阱量…...