windows本地开发Spark[不开虚拟机]
1. windows本地安装hadoop
hadoop 官网下载 hadoop2.9.1版本
1.1 解压缩至C:\XX\XX\hadoop-2.9.1
1.2 下载动态链接库和工具库
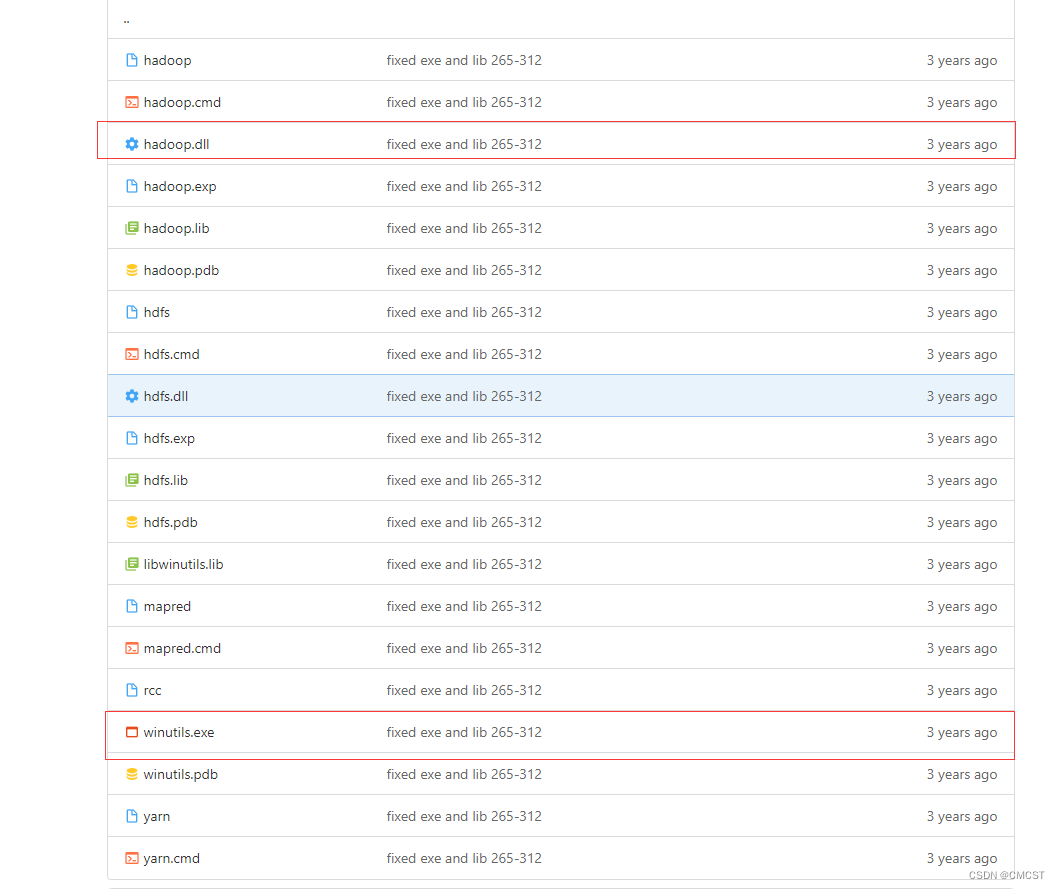
1.3 将文件winutils.exe放在目录C:\XX\XX\hadoop-2.9.1\bin下
1.4 将文件hadoop.dll放在目录C:\XX\XX\hadoop-2.9.1\bin下
1.5 将文件hadoop.dll放在目录C:\Windows\System32下
1.6 配置环境变量
| 添加方式 | 变量名 | 变量值 |
|---|---|---|
| 新建 | HADOOP_HOME | C:\XX\XX\hadoop-2.9.1 |
| 新建 | HADOOP_HOME | C:\XX\XX\hadoop-2.9.1 |
| 编辑(在Path中添加) | Path | %HADOOP_HOME%\bin |
1.7 重启计算机
2. windows本地安装scala
scala 官网下载 scala 2.12.17 版本
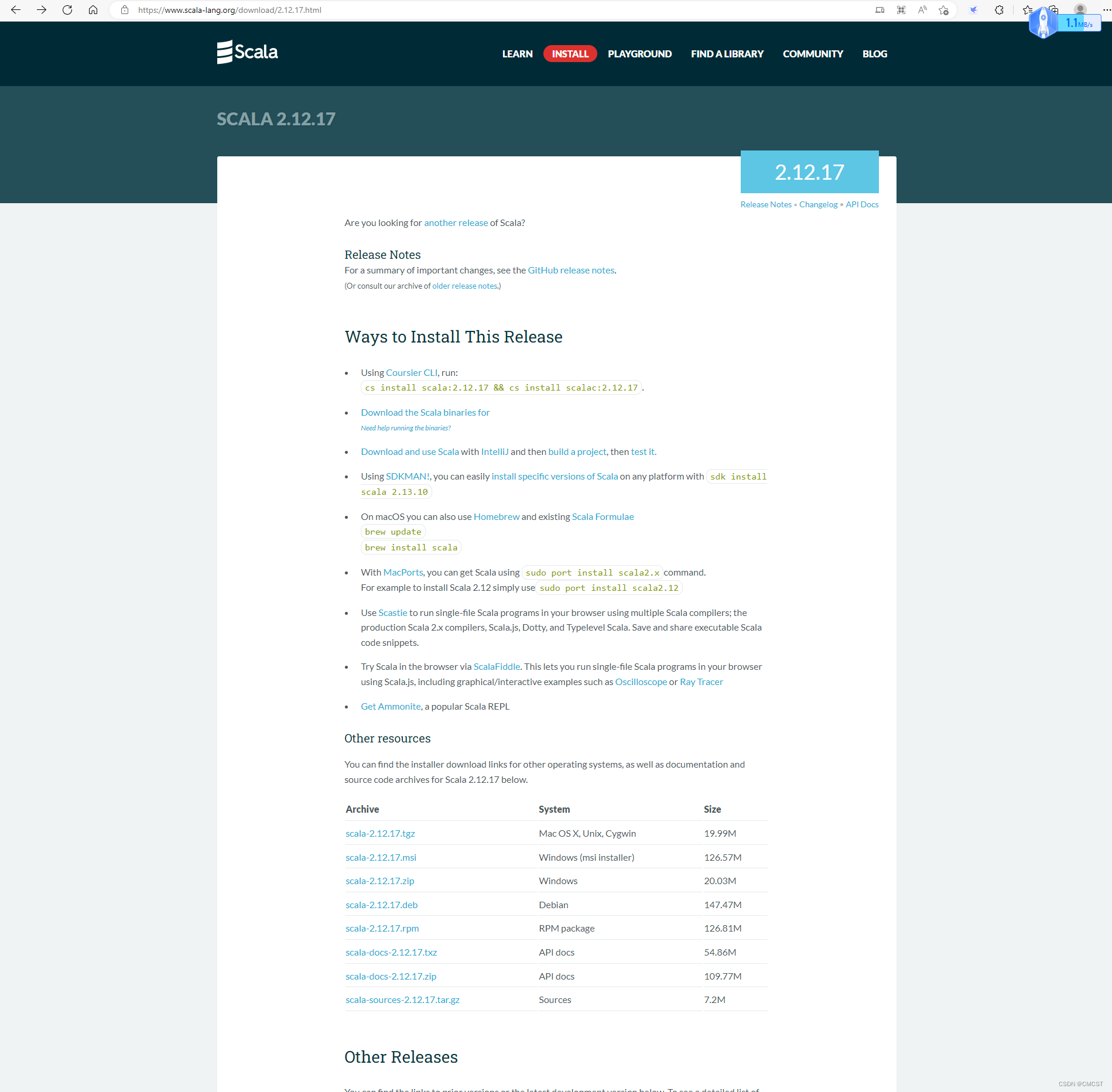
- 在上图中选择如下图所示下载
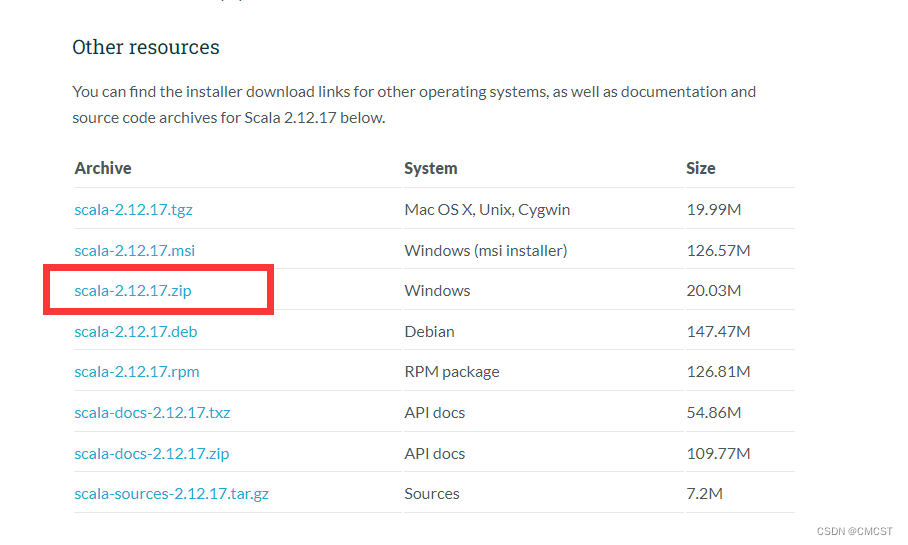
- 解压文件至 D:\Server\,并将文件夹名称由D:\Server\scala-2.12.17改为D:\Server\scala
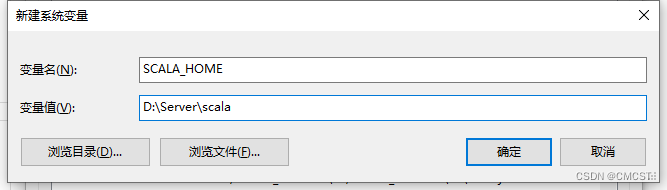
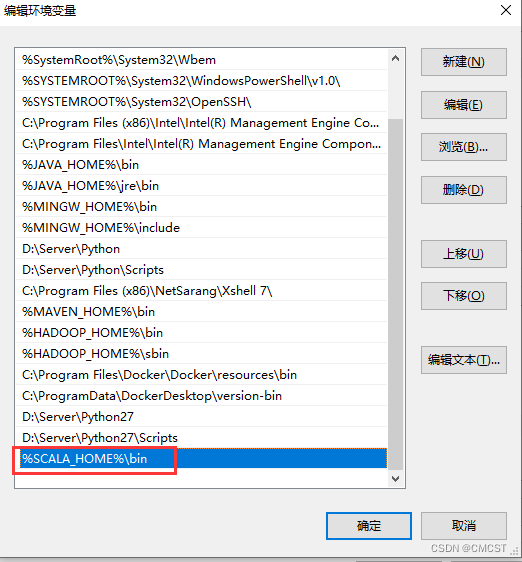
2.1 配置环境变量
| 操作方式 | 变量名 | 变量值 |
|---|---|---|
| 新建 | SCALA_HOME | D:\Server\scala |
| 添加 | Path | %SCALA_HOME%\bin |
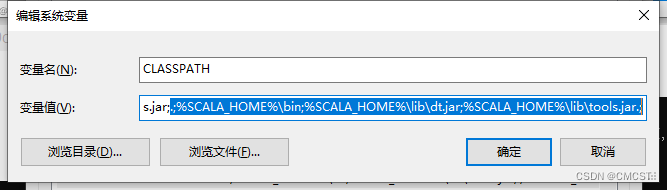
| 添加 | CLASSPATH | .;%SCALA_HOME%\bin;%SCALA_HOME%\lib\dt.jar;%SCALA_HOME%\lib\tools.jar.; |
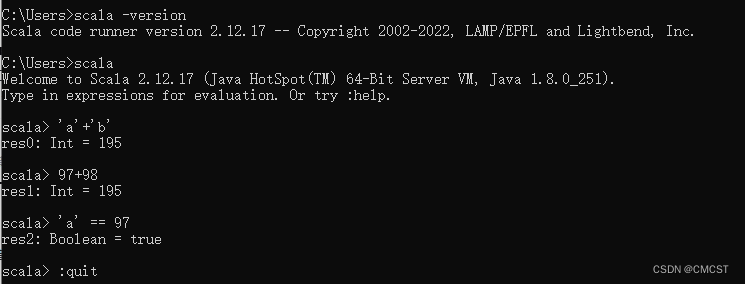
2.2 CMD初体验
3. Spark应用开发
3.1 IDEA 创建maven项目
maven安装教程
3.2 创建scala文件夹
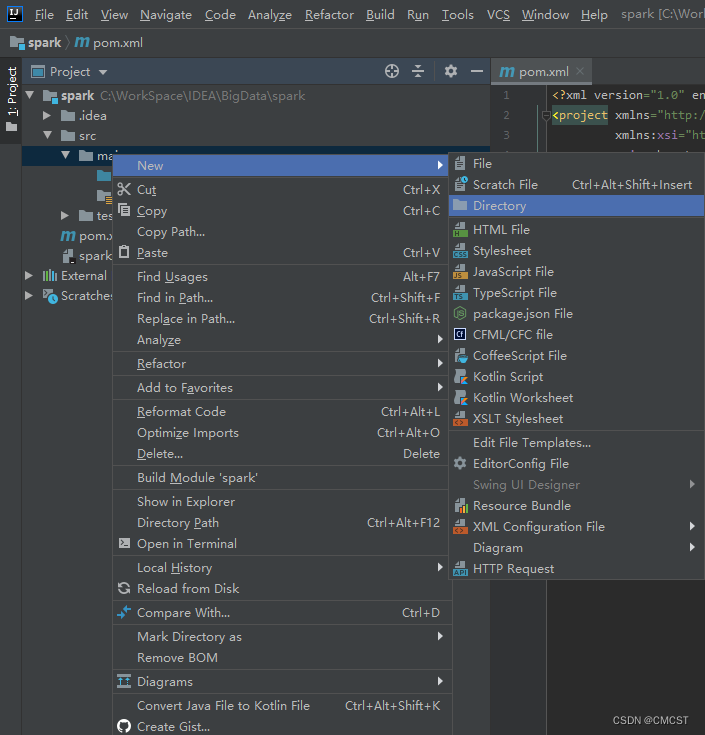
- 文件夹名为scala

- 将scala文件夹标记为源文件目录
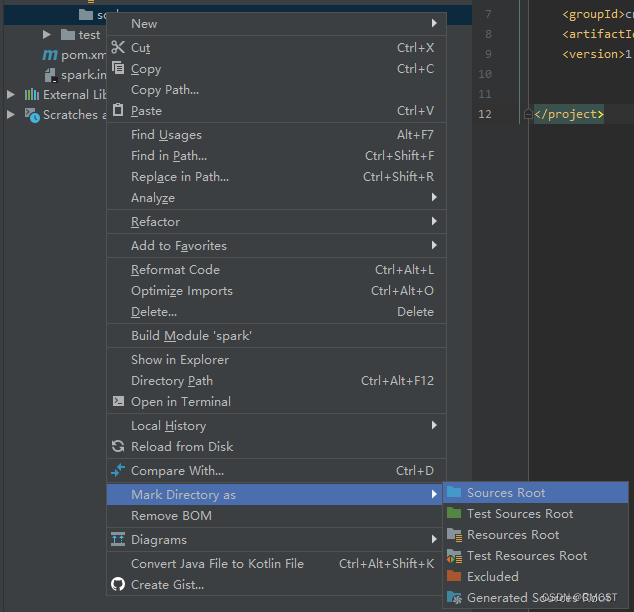
3.3 创建scala文件
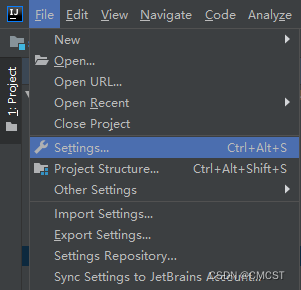
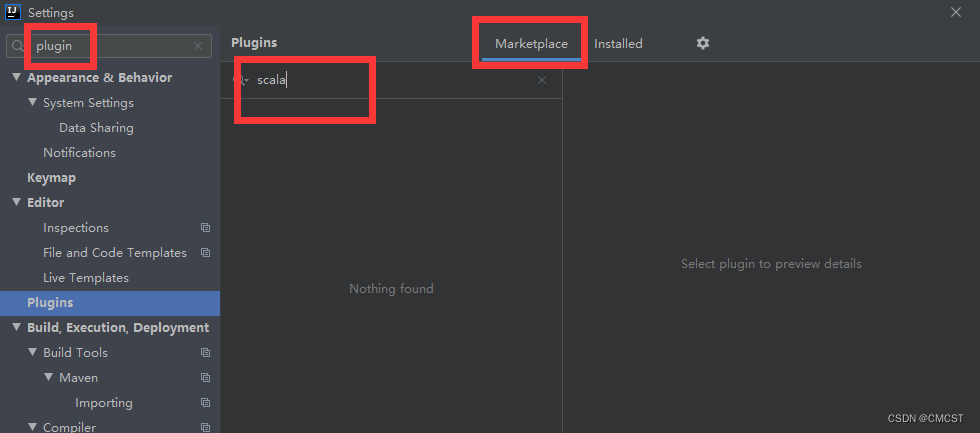
3.3.1 安装scala插件
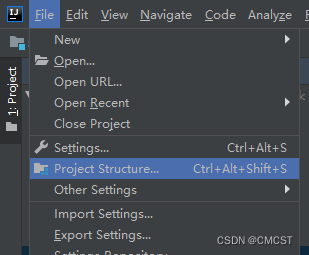
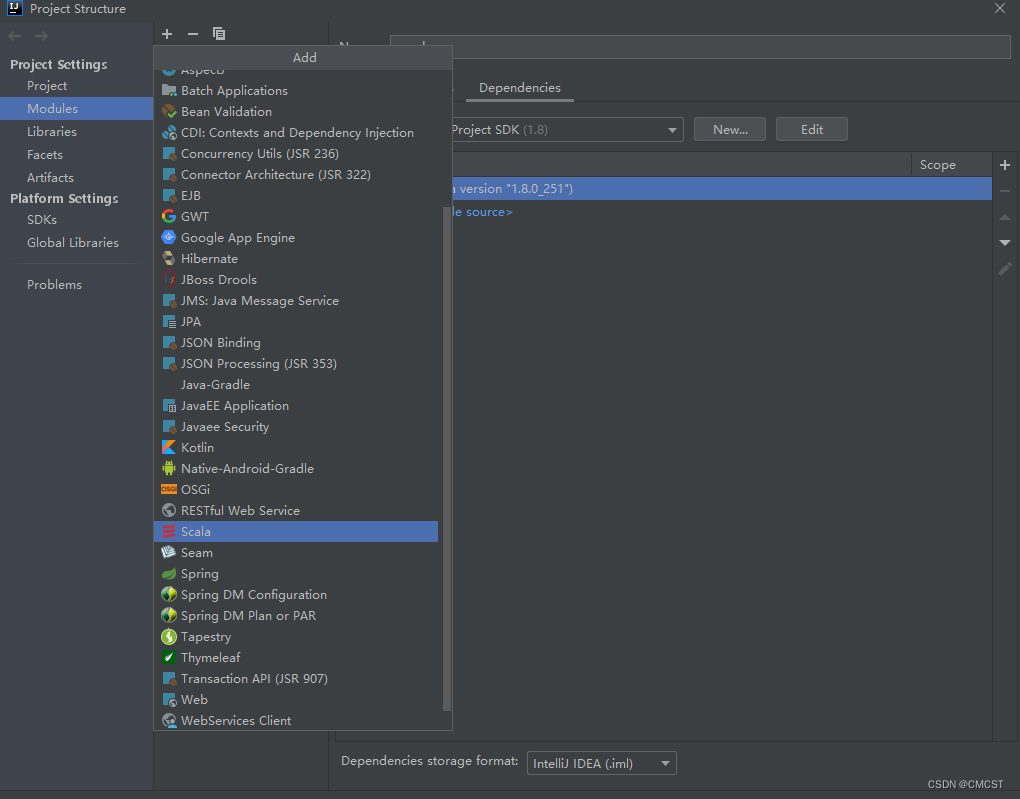
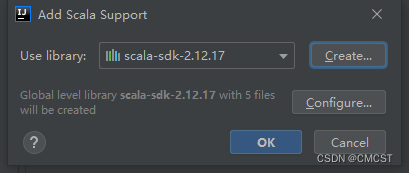
3.3.2 添加框架支持
3.3.3 修改pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>cn.cmcst</groupId><artifactId>spark</artifactId><version>1.0</version><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.7</maven.compiler.source><maven.compiler.target>1.7</maven.compiler.target><hadoop.version>2.9.1</hadoop.version><scala.version>2.12.17</scala.version></properties><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-compiler</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-reflect</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>2.4.8</version></dependency></dependencies><build><plugins><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><version>2.12.2</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><configuration><source>8</source><target>8</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>2.4</version><configuration><archive><manifest><mainClass>cn.cmcst.spark.WordCount</mainClass></manifest></archive><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
</project>
3.3.4 创建WordCount文件
package cn.cmcst.sparkimport org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]): Unit = {if(args.length < 2){System.err.println("Usage: WordCount <input> <output>")System.exit(0)}val input = args(0)val output = args(1)val conf = new SparkConf().setAppName("WordCount").setMaster("local[3]")val sc = new SparkContext(conf)val lines = sc.textFile(input)val result = lines.flatMap(_.split("\\s+")).map((_,1)).reduceByKey(_+_)result.collect().foreach(println)
// result.saveAsTextFile(output)sc.stop()}
}3.3.5 IDEA中输入参数

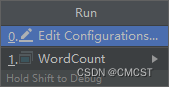
- 红框中输入两个参数:程序中要读取文件输入目录 文件输出目录
- words.log文件内容为
flink flink flink
hadoop hadoop hadoop
spark spark spark
davinci davinci davinci
hive zookeeper sqoop mysql
hive zookeeper sqoop mysql
IDEA IDEA IDEA
2.3.6 输出结果
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
23/02/14 13:59:34 INFO SparkContext: Running Spark version 2.4.8
23/02/14 13:59:35 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
23/02/14 13:59:35 INFO SparkContext: Submitted application: WordCount
23/02/14 13:59:35 INFO SecurityManager: Changing view acls to: CMCST,root
23/02/14 13:59:35 INFO SecurityManager: Changing modify acls to: CMCST,root
23/02/14 13:59:35 INFO SecurityManager: Changing view acls groups to:
23/02/14 13:59:35 INFO SecurityManager: Changing modify acls groups to:
23/02/14 13:59:35 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(CMCST, root); groups with view permissions: Set(); users with modify permissions: Set(CMCST, root); groups with modify permissions: Set()
23/02/14 13:59:36 INFO Utils: Successfully started service 'sparkDriver' on port 9229.
23/02/14 13:59:36 INFO SparkEnv: Registering MapOutputTracker
23/02/14 13:59:36 INFO SparkEnv: Registering BlockManagerMaster
23/02/14 13:59:36 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
23/02/14 13:59:36 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
23/02/14 13:59:36 INFO DiskBlockManager: Created local directory at C:\Users\CMCST\AppData\Local\Temp\blockmgr-87f53eb9-52f3-4323-83b0-ebc53bfc2073
23/02/14 13:59:36 INFO MemoryStore: MemoryStore started with capacity 897.6 MB
23/02/14 13:59:36 INFO SparkEnv: Registering OutputCommitCoordinator
23/02/14 13:59:36 INFO Utils: Successfully started service 'SparkUI' on port 4040.
23/02/14 13:59:36 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://DESKTOP-0DK2AAM:4040
23/02/14 13:59:36 INFO Executor: Starting executor ID driver on host localhost
23/02/14 13:59:37 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 9252.
23/02/14 13:59:37 INFO NettyBlockTransferService: Server created on DESKTOP-0DK2AAM:9252
23/02/14 13:59:37 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
23/02/14 13:59:37 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, DESKTOP-0DK2AAM, 9252, None)
23/02/14 13:59:37 INFO BlockManagerMasterEndpoint: Registering block manager DESKTOP-0DK2AAM:9252 with 897.6 MB RAM, BlockManagerId(driver, DESKTOP-0DK2AAM, 9252, None)
23/02/14 13:59:37 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, DESKTOP-0DK2AAM, 9252, None)
23/02/14 13:59:37 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, DESKTOP-0DK2AAM, 9252, None)
23/02/14 13:59:37 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 214.6 KB, free 897.4 MB)
23/02/14 13:59:37 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 20.4 KB, free 897.4 MB)
23/02/14 13:59:37 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on DESKTOP-0DK2AAM:9252 (size: 20.4 KB, free: 897.6 MB)
23/02/14 13:59:37 INFO SparkContext: Created broadcast 0 from textFile at WordCount.scala:18
23/02/14 13:59:37 INFO FileInputFormat: Total input paths to process : 1
23/02/14 13:59:38 INFO SparkContext: Starting job: collect at WordCount.scala:21
23/02/14 13:59:38 INFO DAGScheduler: Registering RDD 3 (map at WordCount.scala:19) as input to shuffle 0
23/02/14 13:59:38 INFO DAGScheduler: Got job 0 (collect at WordCount.scala:21) with 2 output partitions
23/02/14 13:59:38 INFO DAGScheduler: Final stage: ResultStage 1 (collect at WordCount.scala:21)
23/02/14 13:59:38 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
23/02/14 13:59:38 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0)
23/02/14 13:59:38 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount.scala:19), which has no missing parents
23/02/14 13:59:38 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 5.8 KB, free 897.4 MB)
23/02/14 13:59:38 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 3.4 KB, free 897.4 MB)
23/02/14 13:59:38 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on DESKTOP-0DK2AAM:9252 (size: 3.4 KB, free: 897.6 MB)
23/02/14 13:59:38 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1184
23/02/14 13:59:38 INFO DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount.scala:19) (first 15 tasks are for partitions Vector(0, 1))
23/02/14 13:59:38 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
23/02/14 13:59:38 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 7381 bytes)
23/02/14 13:59:38 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL, 7381 bytes)
23/02/14 13:59:38 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
23/02/14 13:59:38 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
23/02/14 13:59:38 INFO HadoopRDD: Input split: file:/C:/WorkSpace/IDEA/BigData/spark/input/words.log:0+77
23/02/14 13:59:38 INFO HadoopRDD: Input split: file:/C:/WorkSpace/IDEA/BigData/spark/input/words.log:77+78
23/02/14 13:59:38 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1163 bytes result sent to driver
23/02/14 13:59:38 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 1163 bytes result sent to driver
23/02/14 13:59:38 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 523 ms on localhost (executor driver) (1/2)
23/02/14 13:59:38 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 508 ms on localhost (executor driver) (2/2)
23/02/14 13:59:39 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
23/02/14 13:59:39 INFO DAGScheduler: ShuffleMapStage 0 (map at WordCount.scala:19) finished in 0.627 s
23/02/14 13:59:39 INFO DAGScheduler: looking for newly runnable stages
23/02/14 13:59:39 INFO DAGScheduler: running: Set()
23/02/14 13:59:39 INFO DAGScheduler: waiting: Set(ResultStage 1)
23/02/14 13:59:39 INFO DAGScheduler: failed: Set()
23/02/14 13:59:39 INFO DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCount.scala:19), which has no missing parents
23/02/14 13:59:39 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 4.1 KB, free 897.4 MB)
23/02/14 13:59:39 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 2.5 KB, free 897.4 MB)
23/02/14 13:59:39 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on DESKTOP-0DK2AAM:9252 (size: 2.5 KB, free: 897.6 MB)
23/02/14 13:59:39 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1184
23/02/14 13:59:39 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCount.scala:19) (first 15 tasks are for partitions Vector(0, 1))
23/02/14 13:59:39 INFO TaskSchedulerImpl: Adding task set 1.0 with 2 tasks
23/02/14 13:59:39 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 2, localhost, executor driver, partition 0, ANY, 7141 bytes)
23/02/14 13:59:39 INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID 3, localhost, executor driver, partition 1, ANY, 7141 bytes)
23/02/14 13:59:39 INFO Executor: Running task 0.0 in stage 1.0 (TID 2)
23/02/14 13:59:39 INFO Executor: Running task 1.0 in stage 1.0 (TID 3)
23/02/14 13:59:39 INFO ShuffleBlockFetcherIterator: Getting 2 non-empty blocks including 2 local blocks and 0 remote blocks
23/02/14 13:59:39 INFO ShuffleBlockFetcherIterator: Getting 2 non-empty blocks including 2 local blocks and 0 remote blocks
23/02/14 13:59:39 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 9 ms
23/02/14 13:59:39 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 9 ms
23/02/14 13:59:39 INFO Executor: Finished task 1.0 in stage 1.0 (TID 3). 1285 bytes result sent to driver
23/02/14 13:59:39 INFO Executor: Finished task 0.0 in stage 1.0 (TID 2). 1355 bytes result sent to driver
23/02/14 13:59:39 INFO TaskSetManager: Finished task 1.0 in stage 1.0 (TID 3) in 195 ms on localhost (executor driver) (1/2)
23/02/14 13:59:39 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 2) in 199 ms on localhost (executor driver) (2/2)
23/02/14 13:59:39 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
23/02/14 13:59:39 INFO DAGScheduler: ResultStage 1 (collect at WordCount.scala:21) finished in 0.215 s
23/02/14 13:59:39 INFO DAGScheduler: Job 0 finished: collect at WordCount.scala:21, took 1.181680 s
23/02/14 13:59:39 INFO BlockManagerInfo: Removed broadcast_1_piece0 on DESKTOP-0DK2AAM:9252 in memory (size: 3.4 KB, free: 897.6 MB)
23/02/14 13:59:39 INFO SparkUI: Stopped Spark web UI at http://DESKTOP-0DK2AAM:4040
(hive,2)
(flink,3)
(davinci,3)
(zookeeper,2)
(mysql,2)
(sqoop,2)
(spark,3)
(hadoop,3)
(IDEA,3)
23/02/14 13:59:39 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
23/02/14 13:59:39 INFO MemoryStore: MemoryStore cleared
23/02/14 13:59:39 INFO BlockManager: BlockManager stopped
23/02/14 13:59:39 INFO BlockManagerMaster: BlockManagerMaster stopped
23/02/14 13:59:39 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
23/02/14 13:59:39 INFO SparkContext: Successfully stopped SparkContext
23/02/14 13:59:39 INFO ShutdownHookManager: Shutdown hook called
23/02/14 13:59:39 INFO ShutdownHookManager: Deleting directory C:\Users\CMCST\AppData\Local\Temp\spark-3a48779f-a780-43f5-9898-d8a95cbdbcec
相关文章:
windows本地开发Spark[不开虚拟机]
1. windows本地安装hadoop hadoop 官网下载 hadoop2.9.1版本 1.1 解压缩至C:\XX\XX\hadoop-2.9.1 1.2 下载动态链接库和工具库 1.3 将文件winutils.exe放在目录C:\XX\XX\hadoop-2.9.1\bin下 1.4 将文件hadoop.dll放在目录C:\XX\XX\hadoop-2.9.1\bin下 1.5 将文件hadoop.dl…...

一文教你快速估计个股交易成本
交易本身对市场会产生影响,尤其是短时间内大量交易,会影响金融资产的价格。一个订单到来时的市场价格和订单的执行价格通常会有差异,这个差异通常被称为交易成本。在量化交易的策略回测部分,不考虑交易成本或者交易成本估计不合理…...

Leetcode—移除元素、删除有序数组中的重复项、合并两个有序数组
移除元素 此题简单,用双指针方法即可, 如果右指针指向的元素不等于val,它一定是输出数组的一个元素,我们就将右指针指向的元素复制到左指针位置,然后将左右指针同时右移; 如果右指针指向的元素等于 val&…...
大疆 安全开发 C++1面)
面试(十)大疆 安全开发 C++1面
1. 在C++开发中定义一个变量,若不做初始化直接使用会怎样? 如果该变量是一个普通变量,则如果对其进行访问,会返回一个随机值,int类型不一定为0,bool类型也不一定为false 如果该变量为一个静态变量,则初始值都是一个0; 如果该变量是一个指针,那么在后续程序运行中很…...
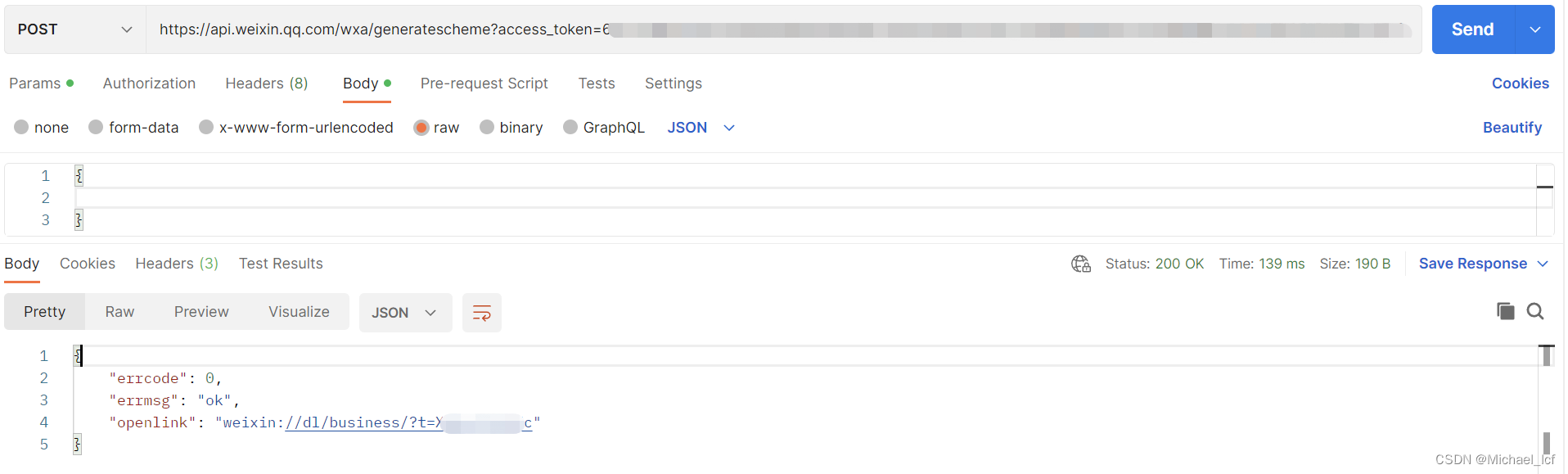
短信链接跳转微信小程序
短信链接跳转微信小程序1 实现方案1.1 通过URL Scheme实现1.2 通过URL Link实现1.3 通过云开发静态网站实现2 实现方案对比3 实践 URL Schema 方案3.1 获取微信access_token3.2 获取openlink3.3 H5页面(模拟短信跳转,验证ok)4 问题小节4.1 io…...

吉林电视台启用乾元通多卡聚合系统广电视频传输解决方案
随着广播电视数字化、IP化、智能化的逐步深入,吉林电视台对技术改造、数字设备升级提出了更高要求,通过对系统性能、设计理念的综合评估,正式启用乾元通多卡聚合系统广电视频传输解决方案,将用于大型集会、大型演出、基层直播活动…...
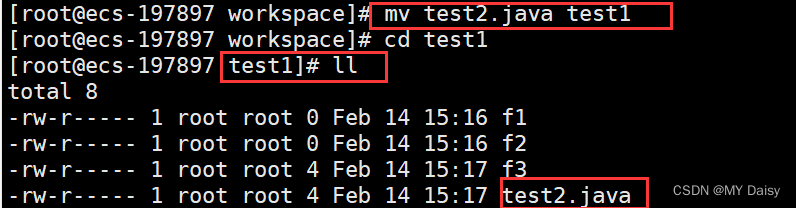
Linux常用命令1
目录1、远程登陆服务器2、文件相关(1)文件和目录属性(2)创建目录mkdir(3)删除目录rmdir(4)创建文件touch(5)删除文件或目录rm(6)ls命令…...

【C++进阶】一、继承(总)
目录 一、继承的概念及定义 1.1 继承概念 1.2 继承定义 1.3 继承基类成员访问方式的变化 二、基类和派生类对象赋值转换 三、继承中的作用域 四、派生类的默认成员函数 五、继承与友元 六、继承与静态成员 七、菱形继承及菱形虚拟继承 7.1 继承的分类 7.2 菱形虚拟…...
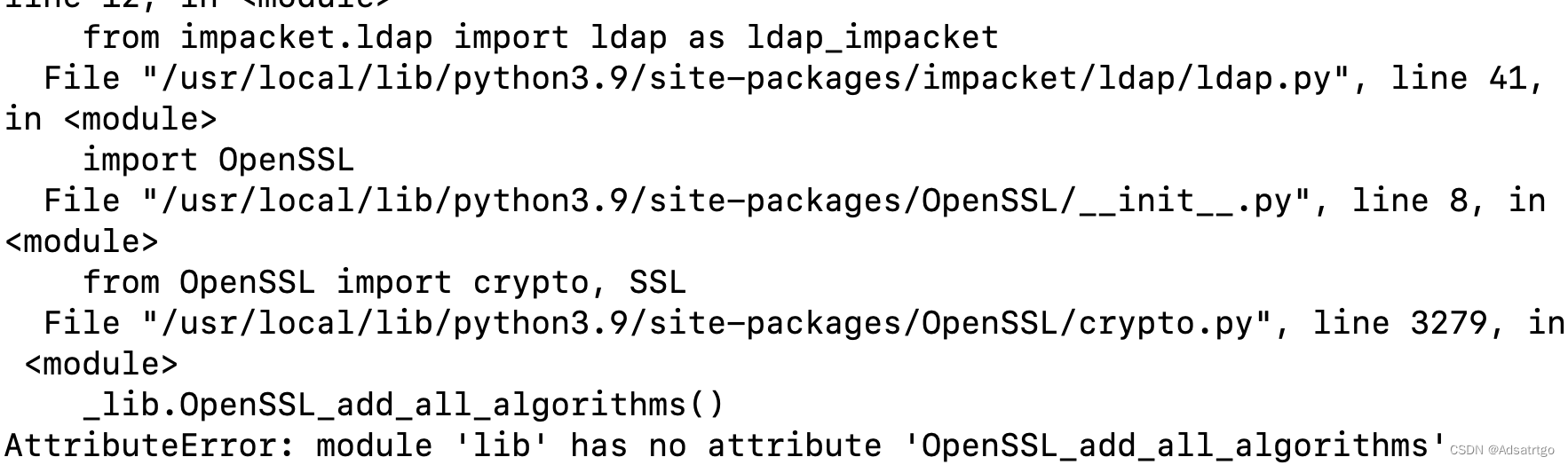
AttributeError: module ‘lib‘ has no attribute ‘OpenSSL_add_all_algorithms
pip安装crackmapexec后,运行crackmapexec 遇到报错 AttributeError: module lib has no attribute OpenSSL_add_all_algorithms 直接安装 pip3 install crackmapexec 解决 通过 python3 -m pip install --upgrade openssl 或者 python3 -m pip install openssl>22.1.…...

Python实现视频自动打码功能,避免看到羞羞的画面
前言 嗨呀嗨呀,最近重温了一档综艺节目 至于叫什么 这里就不细说了 老是看着看着就会看到一堆马赛克,由于太好奇了就找了一下原因,结果是因为某艺人塌房了…虽然但是 看综艺的时候满影响美观的 咳咳,这里我可不是来教你们如何解…...
说说Knife4j
Knife4j是一款基于Swagger2的在线API文档框架使用Knife4j, 需要 添加Knife4j的依赖当前建议使用的Knife4j版本, 只适用于Spring Boot2.6以下版本, 不含Spring Boot2.6 在主配置文件(application.yml)中开启Knife4j的增强模式必须在主配置文件中进行配置, 不要配置在个性化配置文…...
Java学习笔记-03(API阶段-2)集合
集合 我们接下来要学习的内容是Java基础中一个很重要的部分:集合 1. Collection接口 1.1 前言 Java语言的java.util包中提供了一些集合类,这些集合类又称之为容器 提到容器不难想到数组,集合类与数组最主要的不同之处是,数组的长度是固定的,集合的长度是可变的&a…...
)
「3」线性代数(期末复习)
🚀🚀🚀大家觉不错的话,就恳求大家点点关注,点点小爱心,指点指点🚀🚀🚀 矩阵的秩 定义4:在mxn矩阵A中,任取k行与k列(k<m,k<n),位…...
)
【CSDN竞赛】27期题解(Javascript)
前言 本来排名是20的,不过第一题有点输出bug,最后实际测出来又重新排名,刚好卡在第10。但是考试报告好像过了12小时就下载不到了,所以就只写题目求解的JS函数吧。 1. 幸运数字 小艺定义一个幸运数字的标准包含3条: 仅包含4或7幸…...

高压放大器在骨的逆力电研究中的应用
实验名称:高压放大器在骨的逆力电研究中的应用研究方向:生物医学测试目的:骨中的胶原和羟基磷灰石沿厚度分布不均匀,骨试样在直流电压作用下,内部出现传导电流引起试样内部温度升高,不同组分热变形不一致&a…...
思科网络部署,(0基础)入门实验,超详细
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放࿰…...
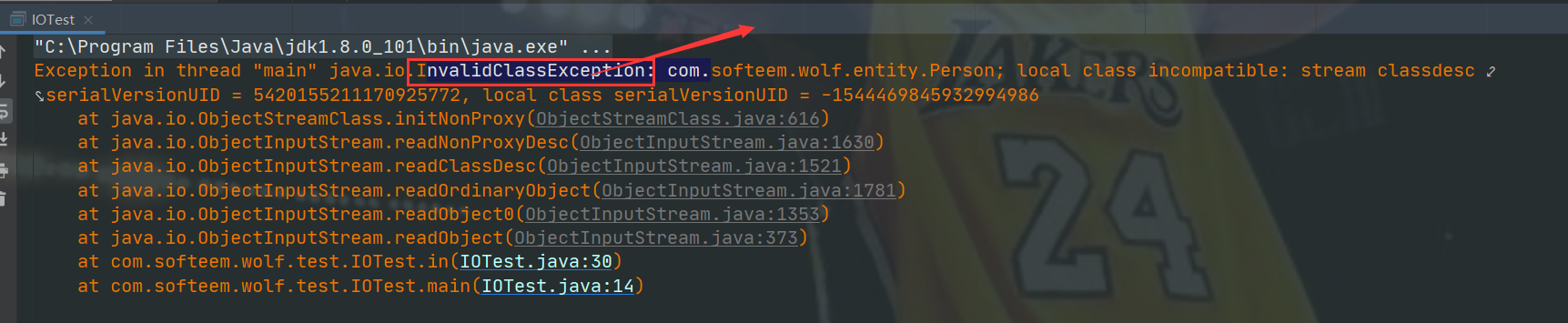
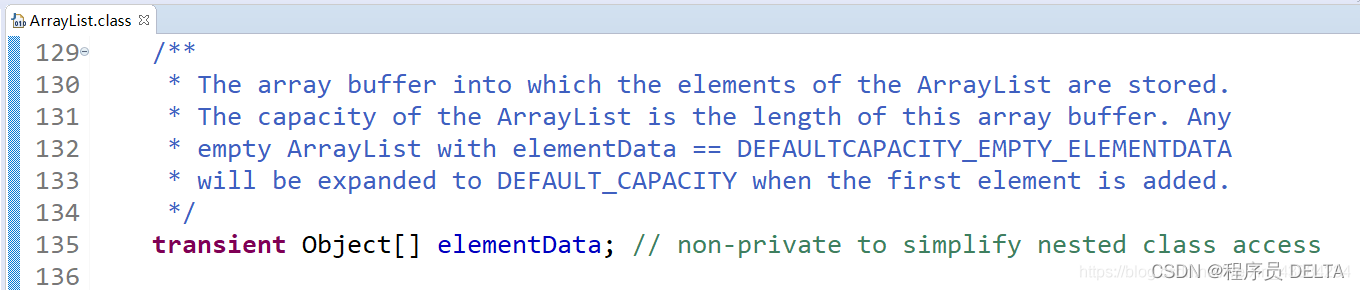
private static final Long serialVersionUID= 1L详解
我们知道在对数据进行传输时,需要将其进行序列化,在Java中实现序列化的方式也很简单,可以直接通过实现Serializable接口。但是我们经常也会看到下面接这一行代码,private static final Long serialVersionUID 1L;这段代…...
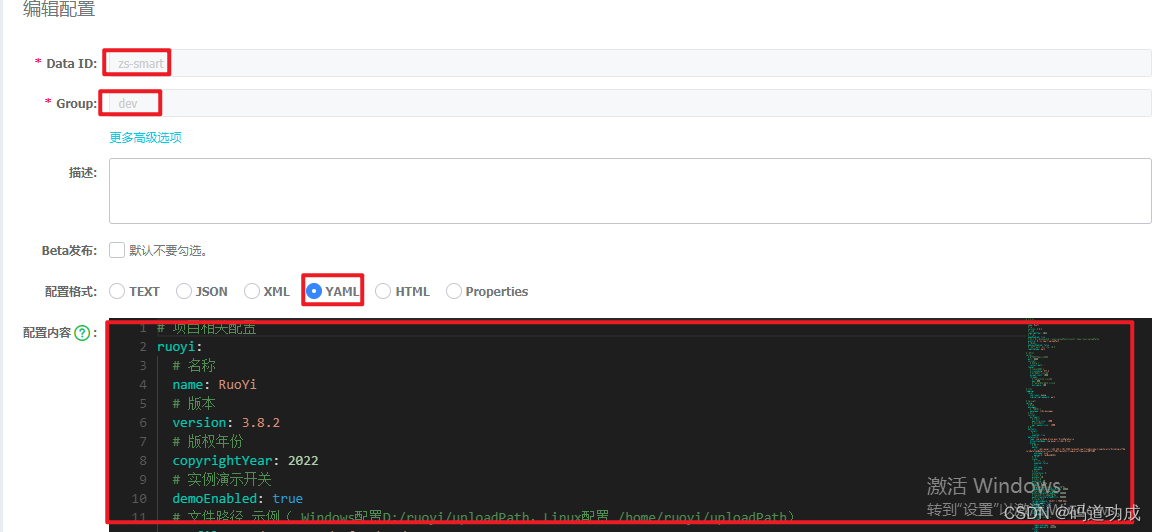
若依前后端分离版集成nacos
根据公司要求,需要将项目集成到nacos中,当前项目是基于若依前后端分离版开发的,若依的版本为3.8.3,若依框架中整合的springBoot版本为2.5.14。Nacos核心提供两个功能:服务注册与发现,动态配置管理。 一、服…...
)
JAVA面试八股文一(mysql)
B-Tree和BTree区别共同点;一个节点可以有多个元素, 排好序的不同点:BTree叶子节点之间有指针,非叶子节点之间的数据都冗余了一份在叶子节点BTree是B-Tree 的升级mysql什么情况设置了索引,但无法使用a.没符合最左原则b.…...

动静态库概念及创建
注意在库中不能写main()函数。 复习gcc指令 预处理-E-> xx.i 编译 -S-> xx.s 汇编 -c-> xx.o 汇编得到的 xx.o称为目标可重定向二进制文件,此时的文件需要把第三方库链接进来才变成可执行程序。 gcc -o mymath main.c myadd.c mysub.c得到的mymath可以执…...

2026届学术党必备的六大降重复率神器横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 减小AIGC率的关键之处在于使文本的统计规律性以及模式化特性得以弱化。首先,别去…...

纯电商用车再生制动能量回收模糊控制策略【附代码】
✨ 本团队擅长数据搜集与处理、建模仿真、程序设计、仿真代码、EI、SCI写作与指导,毕业论文、期刊论文经验交流。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于自适应扩展卡尔曼滤波的SOC精确估计与能量管理…...

[hadoop] 初识Spark
初识Spark采用的方法是:由新手不断地追问老手问题,老手给出一定的回答。 在这个过程中,新手会慢慢理解Spark 参考资料: 《Hadoop 3.x大数据开发实战》 文章目录参考资料:11.11.2233.14555.166.16.21 Spark集群的启动…...

2026AI大模型API中转服务实测:多平台全方位对比,探寻最适配开发者的优质之选
跨国网络延迟、复杂的支付方式以及分散的接口协议,使得开发者在调用AI大模型API时体验欠佳。而智能中转平台的出现,能让这一切变得像调用本地服务一样轻松。API中转平台能够一站式解决国内外主流AI模型在价格差异、网络连通性以及支付方式等方面的问题。…...

为什么顶尖AI产品团队正秘密重构设计系统?——AI原生用户体验的4层认知断层与SITS 2026破局公式
更多请点击: https://intelliparadigm.com 第一章:AI原生用户体验设计:SITS 2026交互设计新趋势 AI原生体验不再将模型能力“封装后隐藏”,而是让智能成为界面的第一公民——用户在输入框中键入自然语言时,系统实时推…...

智能庭院机器人公司「长曜创新」获数千万元 A+ 融资,Tron Ultra 系列年中全球开售
硬氪获悉,智能庭院机器人公司「长曜创新」近日完成数千万元 A 融资,领投方为盈峰环境,老股东 XGROUP 持续加注。公司聚焦无边界割草机器人,其旗舰产品 Tron Ultra 系列将年中全球开售。融资情况与发展方向长曜创新近日完成数千万元…...

ImageGlass终极指南:5分钟掌握这款轻量级图片查看器的完整使用技巧
ImageGlass终极指南:5分钟掌握这款轻量级图片查看器的完整使用技巧 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass ImageGlass是一款专为Windows系统设计的轻量…...

BUUCTF:[极客大挑战 2019]RCE ME 深度解析:从正则绕开到LD_PRELOAD的完整利用链
1. 题目背景与初步分析 BUUCTF的[极客大挑战 2019]RCE ME是一道典型的PHP代码审计与绕过题目。题目给出了一个简单的PHP页面,核心代码如下: <?php error_reporting(0); if(isset($_GET[code])){$code$_GET[code];if(strlen($code)>40){die(&quo…...

JavaScript条形码生成技术:JsBarcode架构设计与跨平台实现方案
JavaScript条形码生成技术:JsBarcode架构设计与跨平台实现方案 【免费下载链接】JsBarcode Barcode generation library written in JavaScript that works in both the browser and on Node.js 项目地址: https://gitcode.com/gh_mirrors/js/JsBarcode 在现…...

认知神经科学研究报告【20260042】
文章目录ForeSight 5.87.4 多元时间序列预测 — 测试报告ForeSight 5.87.4 多元时间序列预测 — 测试报告 测试目标:让系统从数据中自动发现变量之间的因果关系和预测模型,不预设任何模型结构。 测试数据:500个时间点的模拟经济数据&#x…...