【中间件】kafka
目录
- 一、概述
- 二、生产者
- 1. 发送原理
- 2. 生产者分区 Partition
- 分区好处
- 分区策略
- 3. 生产者如何提高吞吐量
- 4. 数据可靠性
- ACK应答级别
- 数据不丢失:ACK + ISR
- 数据不重复:幂等性
- 数据有序
- 三、broker
- 1. 工作流程
- 2. 副本相关
- 3. 底层存储
- 4. 高效读写数据
- 四、消费者
- 1. 工作流程
- 2. 分区分配和重平衡
- 3. offset 位移
一、概述
-
定义:是一个分布式的基于发布/订阅模式的消息队列(MessageQueue),主要应用于大数据实时处理领域
-
三大功能
- 削峰: 高峰期的消息可以积压到消息队列中,随后平滑地处理完成,避免突发访问压力压垮系统
- 解耦: 消息队列避免模块之间的相互调用,降低各个模块的耦合性,提高系统的可扩展性
- 异步: 发送方把消息放在消息队列中,接收方无需立即处理,可以等待合适的时间处理
-
基础架构:
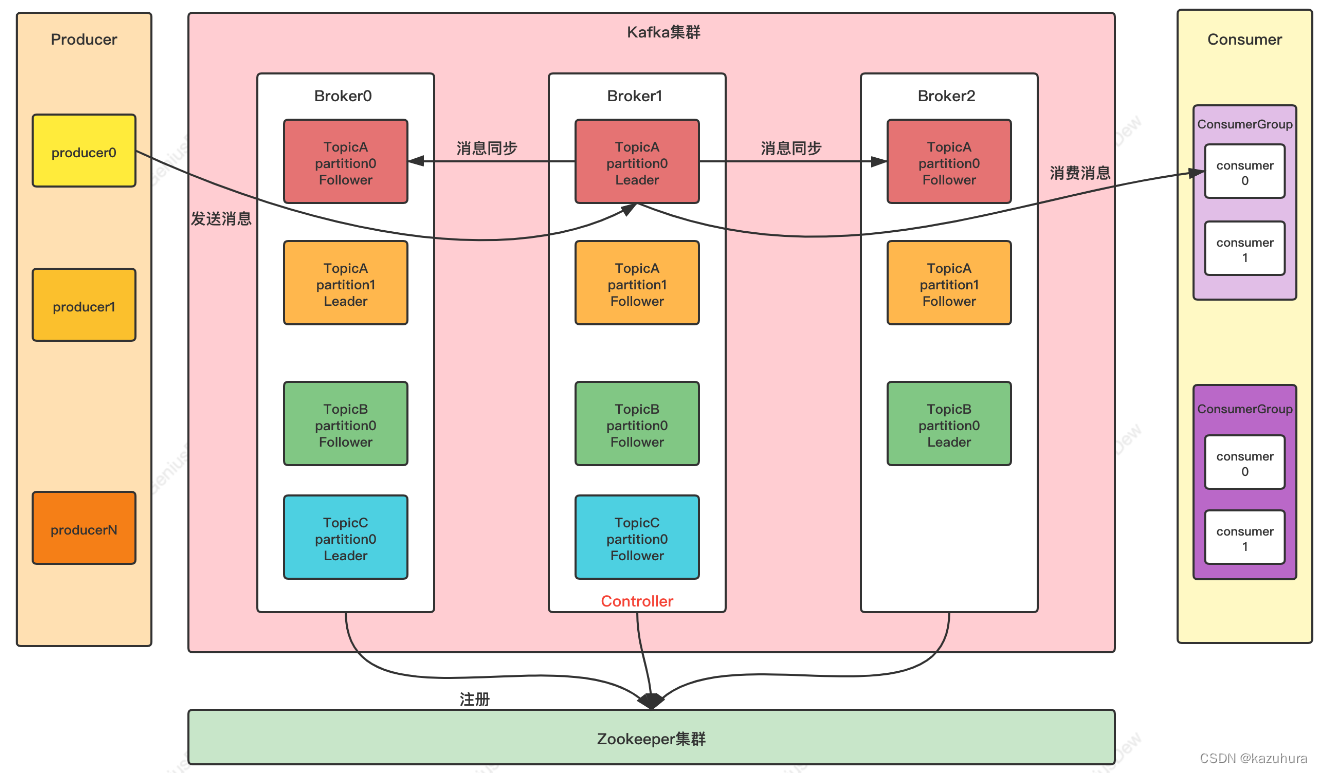
| 组件 | 作用 |
|---|---|
| Producer | 消息生产者,就是向 Kafka broker 发消息的客户端 |
| Consumer | 消息消费者,向 Kafka broker 取消息的客户端 |
| Consumer Group(CG) | 消费者组,由多个 consumer 组成。组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。消费者组是逻辑上的一个订阅者 |
| Broker | 一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个broker 可以容纳多个 topic |
| Topic | 消息主题(逻辑概念) ,生产者和消费者面向的都是一个 topic |
| Partition | 一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列 |
| Replica | 副本。每个分区都有若干个副本,一个 Leader 和若干个Follower |
| Leader | 一组副本中的“主”,只有主和生产者消费者交互 |
| Follower | 一组副本中的“从”,实时从 Leader 中同步数据,保持和Leader 数据的同步 |
| Segment | Partition 物理上被分成多个 Segment,每个 Segment 1个G |
| Zookeeper | 保存元信息,现已废除 |
二、生产者
1. 发送原理

涉及到了两个线程——main 线程和 Sender 线程
- 在 main 线程中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给消息队列
- 当消息队列内的消息达到一定大小,或者达到时间限制,会通知sender线程
- Sender 线程不断从消息队列中拉取消息发送到 Kafka Broker
- 可以选择是异步还是同步(同步就是sender等待收到broker的ack后,再去发送新消息)
2. 生产者分区 Partition
分区好处
- 便于合理使用存储资源,可以把海量的数据按照分区切割成一块一块数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果
- 提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据
分区策略
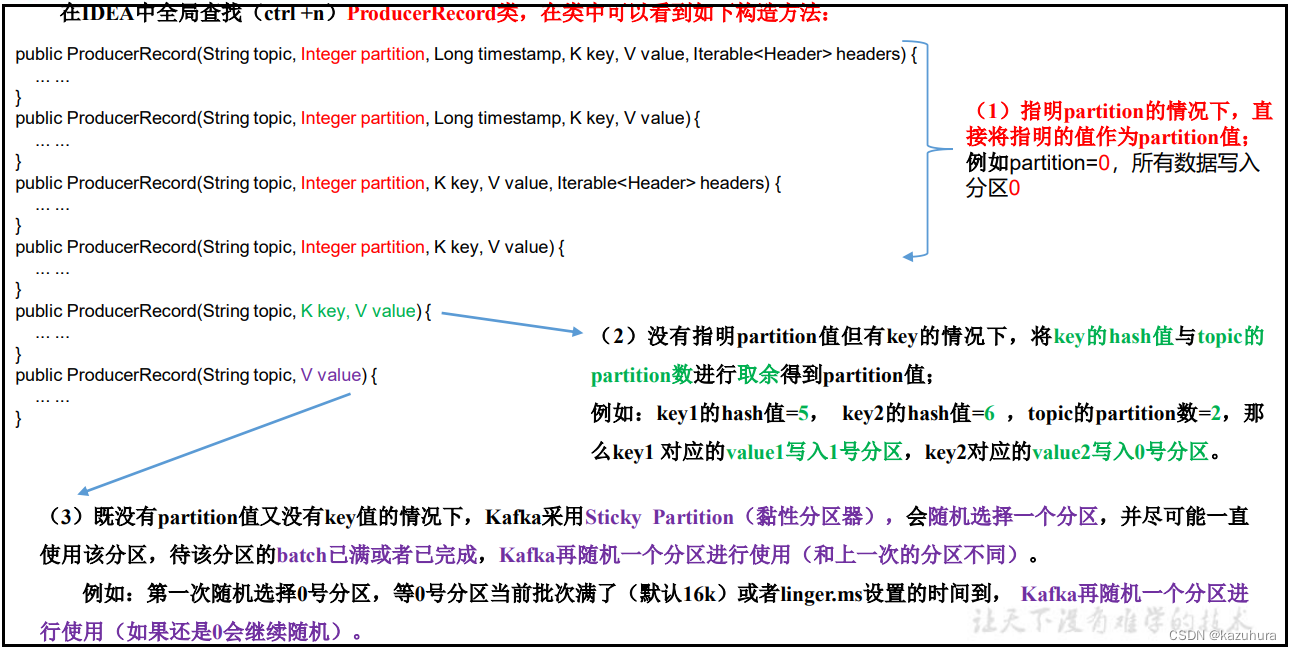
生产者生产消息的时候:
-
指明partition的情况下,直接将指明的值作为partition值;例如partition=0,所有数据写入分区0
-
没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值
例如:key1的hash值=5, key2的hash值=6 ,topic的partition数=2,那么key1 对应的value1写入1号分区,key2对应的value2写入0号分区
-
既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器),会随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或者已完成,Kafka再随机一个分区进行使用(和上一次的分区不同)。
例如:第一次随机选择0号分区,等0号分区当前批次满了(默认16k)或者linger.ms设置的时间到, Kafka再随机一个分区进行使用(如果还是0会继续随机)
-
自定义分区:定义类实现 Partitioner 接口,重写 partition()方法,方法返回分区号
3. 生产者如何提高吞吐量
- 提高main线程创建的消息队列大小:缓存大一点
- 提高batchsize大小:多等一些数据再传
- 调整等待时间:双刃剑,太短一次传的消息太少,太长有延迟
- 对传输数据做压缩:能传更多的消息
4. 数据可靠性
ACK应答级别
0:生产者发送过来的数据,不需要等数据落盘应答
1:生产者发送过来的数据,Leader收到数据后应答
-1:生产者发送过来的数据,Leader和ISR队列里面的所有节点收齐数据后应答
单纯用0或1都会导致丢数,而单纯用-1会导致多数重复
数据不丢失:ACK + ISR
ACK = -1 + 副本 >= 2 + ISR最小副本数量 >= 2
数据不重复:幂等性
-
数据语义
- 最多一次:ACK = 0
- 至少一次:ACK = -1 + 副本 >= 2 + ISR最小副本数量 >= 2
- 精确一次:幂等性 + 至少一次
-
重复数据的判断标准:具有 <PID, Partition, SeqNumber> 相同主键的消息提交时,Broker只会持久化一条
- PID是Kafka每次重启都会分配一个新的Producer ID
- Partition 表示分区号
- Sequence Number是单调自增的
所以幂等性只能保证的是在单分区单会话内不重复
全局不重复需要开启事务
数据有序
- 生产者有序发送消息
- 一个一个消息的发:一个 Topic 下的同一个 Partition 一定是有序的
- 不是一个一个发:需要开启幂等性且一次发不能超过5个,这样如果乱序到达的话,broker会自己排序
- 消费者有序消费
- 一个分区只让一个消费者来消费,即能保证
三、broker
1. 工作流程
- 生产者将消息发送给分区 Leader
- Leader 将消息写入本地文件
- 对应的 Follower 从 Leader 拉取消息并写入本地文件
- Follower 向 Leader 发送 ACK
- Leader向生产者回复
- leader的维护由保存在paitition内的Controller来做,Controller也是分布式的,他会监听brokers节点的变化,在节点挂掉的时候辅助选举新leader,选举规则:在ids列表内按顺序选择
2. 副本相关
-
定义:每个partition都有多份,叫副本,来提高可靠性
- 副本分为Leader和Follower,只有Leader和生产者和消费者交互
- 副本AR = ISR + OSR
-
Leader 和 Follower 故障处理
- Follower故障:被踢出ISR,恢复后再加入ISR
- Leader故障:从ISR中选出一个新的Leader,恢复后去除旧数据,和新Leader进行同步(只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复)
-
副本分区分配
尽可能的把Leader散开,否则会对某一个broker产生很大的压力
3. 底层存储
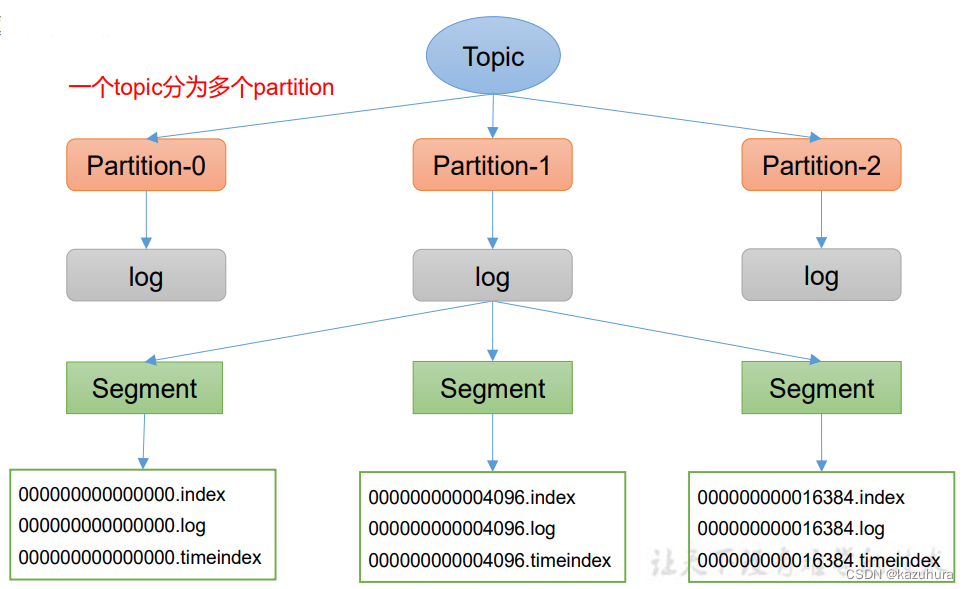
partition下进一步将数据分为Segment,每个1G
-
Segment分为
- log:存具体数据,以追加的方式
- index:索引,稀疏索引,4KB记一条索引
- 时间戳:过期删除用的
-
删除方法
- 删除:直接删除
- 压缩:相同key只保留最新的
4. 高效读写数据
- Kafka 本身是分布式集群,可以采用分区技术,并行度高
- 读数据采用稀疏索引,可以快速定位要消费的数据
- 顺序写磁盘
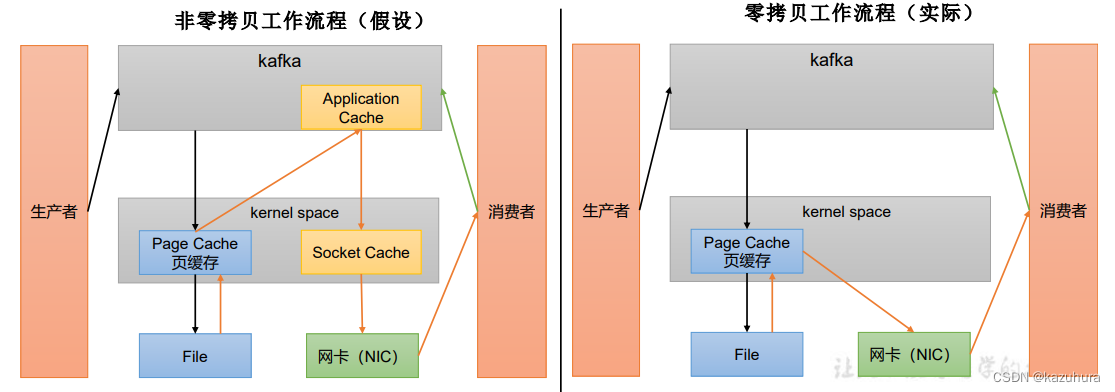
- 页缓存 + 零拷贝技术
- 页缓存PageCache:重度依赖底层操作系统提供的PageCache功能,写的时候直接交给页缓存,读的时候先读页缓存,没有再读磁盘
- 零拷贝:消息从磁盘里读出来之后不走应用层代码,直接走网卡,不占用CPU
四、消费者
1. 工作流程
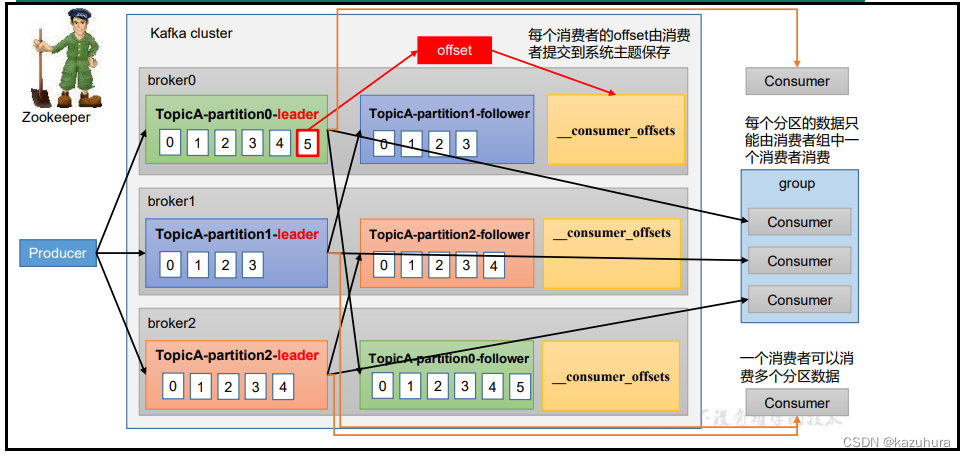
- 消费者可以分组,一个分区只能由组内的一个消费者消费,消费者组是逻辑上的一个订阅者
- 用offset标识消费的位置,由消费者提交,保存在主题内,由coordinator管理,这也是个分布式
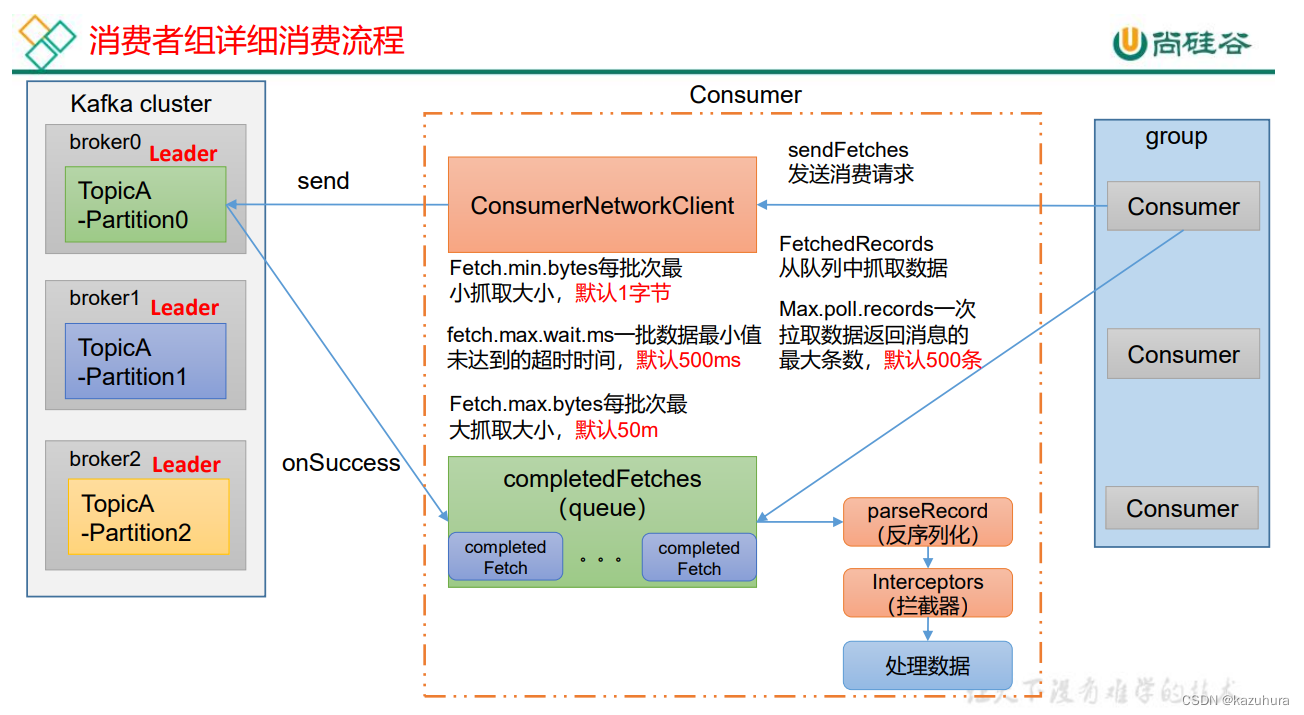
主要就是从broker里拉取数据
2. 分区分配和重平衡
分区分配问题:一个consumer group中有多个consumer组成,一个 topic有多个partition组成,问题是,到底由哪个consumer来消费哪个partition的数据
-
分区分配策略
- Range:对每个 topic 而言, partitions数/consumer数来决定,会产生数据倾斜
- RoundRobin:针对集群中所有Topic而言,所有的 partition轮询分配
- Sticky:尽量均匀地分配分区,根据上次的分配结果尽量减少变动
3. offset 位移
-
位移保存方式:存在__consumer_offsets里,采用 key 和 value 的方式存储数据。key 是 group.id+topic+分区号,value 就是当前 offset 的值
-
位移的提交方式
-
自动提交(可能造成重复消费)
重复消费:已经消费了数据,但是 offset 没提交
比如每隔5s,下一轮过了2s挂了,会重复消费这2s的内容 -
手动提交(可能造成漏消费)
漏消费:先提交 offset 后消费,有可能会造成数据的漏消费
比如消费者取了,还在内存里,刚提交还没来得及落盘就挂了,没落盘的就漏消费了
不管是重复消费还是漏消费,都是提交和落盘的间隙出现宕机的情况,可以开启事务,把这两个动作原子绑定
-
相关文章:
【中间件】kafka
目录 一、概述二、生产者1. 发送原理2. 生产者分区 Partition分区好处分区策略 3. 生产者如何提高吞吐量4. 数据可靠性ACK应答级别数据不丢失:ACK ISR数据不重复:幂等性数据有序 三、broker1. 工作流程2. 副本相关3. 底层存储4. 高效读写数据 四、消费者…...

Html5版音乐游戏制作及分享(H5音乐游戏)
这里实现了Html5版的音乐游戏的核心玩法。 游戏的制作借鉴了,很多经典的音乐游戏玩法,通过简单的代码将音乐的节奏与操作相结合。 可以通过手机进行游戏,准确点击下落时的目标,进行得分。 点击试玩 游戏内的下落数据是通过手打记…...
Python基于Pytorch Transformer实现对iris鸢尾花的分类预测,分别使用CPU和GPU训练
1、鸢尾花数据iris.csv iris数据集是机器学习中一个经典的数据集,由英国统计学家Ronald Fisher在1936年收集整理而成。该数据集包含了3种不同品种的鸢尾花(Iris Setosa,Iris Versicolour,Iris Virginica)各50个样本&am…...

【运动规划算法项目实战】如何实现简单的状态机
文章目录 简介一、状态机1.1 简介1.2 原理介绍1.3 使用方法二、行为树2.1 简介2.2 原理介绍2.3 使用方法三、如何实现一个简单的状态机四、其他的决策模型简介四、总结简介 在机器人算法中,状态机和行为树是常用的两种设计模式。它们能够帮助机器人在复杂的环境中更好地执行任…...

JavaScript实现用while语句计算1+n的和的代码
以下为用while语句计算1n的和实现结果的代码和运行截图 目录 前言 一、实现用while语句计算1n的和 1.1运行流程及思想 1.2代码段 1.3 JavaScript语句代码 1.4运行截图 【附加】用while计算110的和 1.1代码段 1.3 运行截图 前言 1.若有选择,您可以在目录里…...
Three.js教程:顶点索引复用顶点数据
推荐:将 NSDT场景编辑器 加入你3D工具链 其他工具系列: NSDT简石数字孪生 顶点索引复用顶点数据 通过几何体BufferGeometry的顶点索引属性BufferGeometry.index可以设置几何体顶点索引数据,如果你有WebGL基础很容易理解顶点索引的概念&#…...
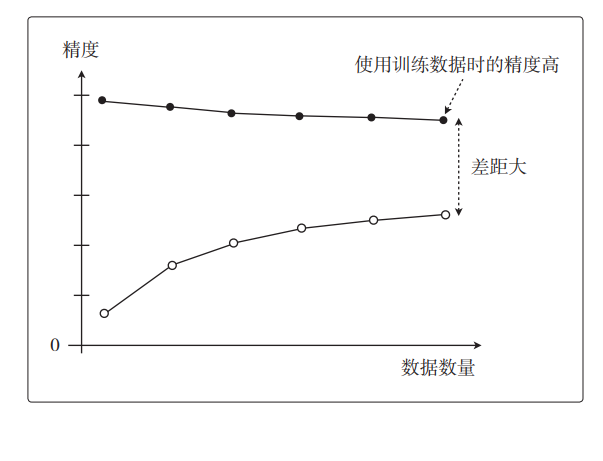
机器学习中的数学——学习曲线如何区别欠拟合与过拟合
通过这篇博客,你将清晰的明白什么是如何区别欠拟合与过拟合。这个专栏名为白话机器学习中数学学习笔记,主要是用来分享一下我在 机器学习中的学习笔记及一些感悟,也希望对你的学习有帮助哦!感兴趣的小伙伴欢迎私信或者评论区留言&…...
【Java】类和对象,封装
目录 1.类和对象的定义 2.关键字new 3.this引用 4.对象的构造及初始化 5.封装 //包的概念 //如何访问 6.static成员 7.代码块 8.对象的打印 1.类和对象的定义 对象:Java中一切皆对象。 类:一般情况下一个Java文件一个类,每一个类…...

Python小姿势 - 知识点:
知识点: Python的字符串格式化 标题: Python字符串格式化实例解析 顺便介绍一下我的另一篇专栏, 《100天精通Python - 快速入门到黑科技》专栏,是由 CSDN 内容合伙人丨全站排名 Top 4 的硬核博主 不吃西红柿 倾力打造。 基础知识…...

【Python】【进阶篇】9、Django路由系统精讲
目录 Django路由系统精讲1. Django 路由系统应用1)配置第一个URL实现页面访问2)正则与正则分组使用3)正则捕获组使用 2. path()与re_path() Django路由系统精讲 在《URL是什么》一节中,我们对 URL 有了基本的认识,在本…...
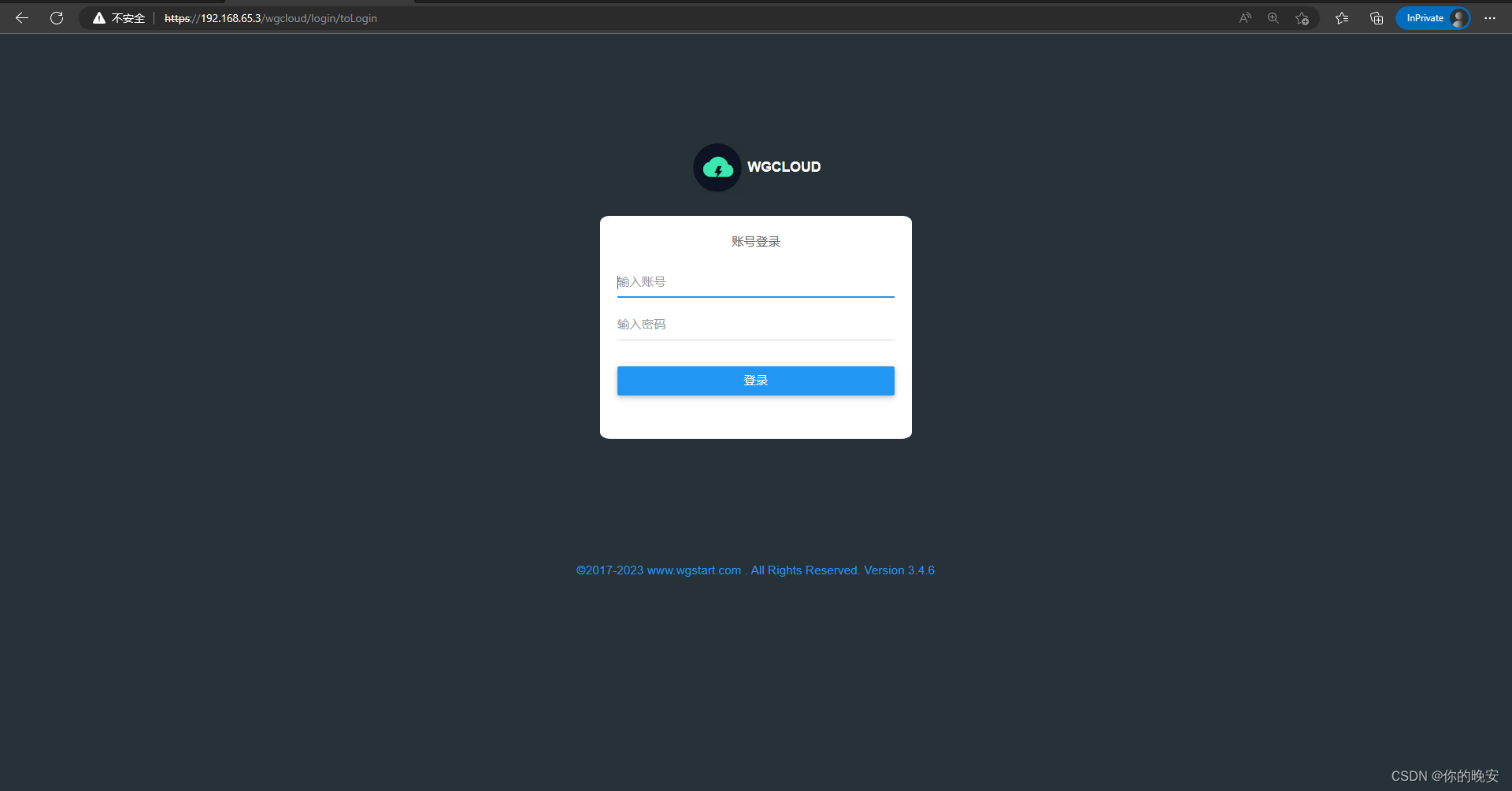
在Linux操作系统上部署wgcloud监控
1.wgcloud监控介绍 1.1 介绍 这是一款开源的主机监控系统,可以支持主机各种指标监测(cpu使用率,cpu温度,内存使用率,磁盘容量空间,磁盘IO,硬盘SMART健康状态,系统负载ÿ…...

浙大的SAMTrack,自动分割和跟踪视频中的任何内容
Meta发布的SAM之后,Meta的Segment Anything模型(可以分割任何对象)体验过感觉很棒,既然能够在图片上面使用,那肯定能够在视频中应用,毕竟视频就是一帧一帧的图片的组合。 果不其然浙江大学就发布了这个SAMTrack,就是在…...
Spring第三方资源配置管理
Spring第三方资源配置管理 1. 管理DataSource连接池对象1.1 管理Druid连接池【重点】1.2 管理c3p0连接池 2. 加载properties属性文件【重点】2.1 基本用法2.2 配置不加载系统属性2.3 加载properties文件写法 说明:以管理DataSource连接池对象为例讲解第三方资源配置…...

网络编程代码实例:多进程版
文章目录 前言代码仓库内容代码(有详细注释)server.cclient.cMakefile 结果总结参考资料作者的话 前言 网络编程代码实例:多进程版。 代码仓库 yezhening/Environment-and-network-programming-examples: 环境和网络编程实例 (github.com)E…...

一家传统制造企业的上云之旅,怎样成为了数字化转型典范?
众所周知,中国是一个制造业大国。在想要上云以及正在上云的企业当中,传统制造企业也占据了相当大的比例。 那么这类企业在实施数字化转型的时候,应该如何着手?我们不妨来看看一家传统制造企业的现身说法。 国茂股份的数字化转型诉…...

C++入门(C++)
目录 命名空间 1、命名空间的定义 2、命名空间的使用 1、加名空间名称和作用域限定符 2、使用using namespace 命名空间引入 3、使用using将命名空间中某个成员引入 C的输入与输出 缺省参数 1、缺省参数的概念 2、缺省参数分类 1、全缺省参数 2、半缺省参数 函数重载 1、函数重…...

Linux 利用网络同步时间
yum -y install ntp ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime ntpdate ntp1.aliyun.com 创建加入crontab echo "*/20 * * * * /usr/sbin/ntpdate -u ntp.api.bz >/dev/null &" >> /var/spool/cron/rootntp常用服务器 中国国家授…...

炫技亮点 SpringBoot下消灭If Else,让你的代码更亮眼
文章目录 背景案例第一阶段 萌芽第二阶段 屎上雕花第三阶段 策略工厂模式重构第四阶段 优化 总结 背景 大家好,我是大表哥laker。今天,我要和大家分享一篇关于如何使用策略模式和工厂模式消除If Else耦合问题的文章。这个方法能够让你的代码更加优美、简…...
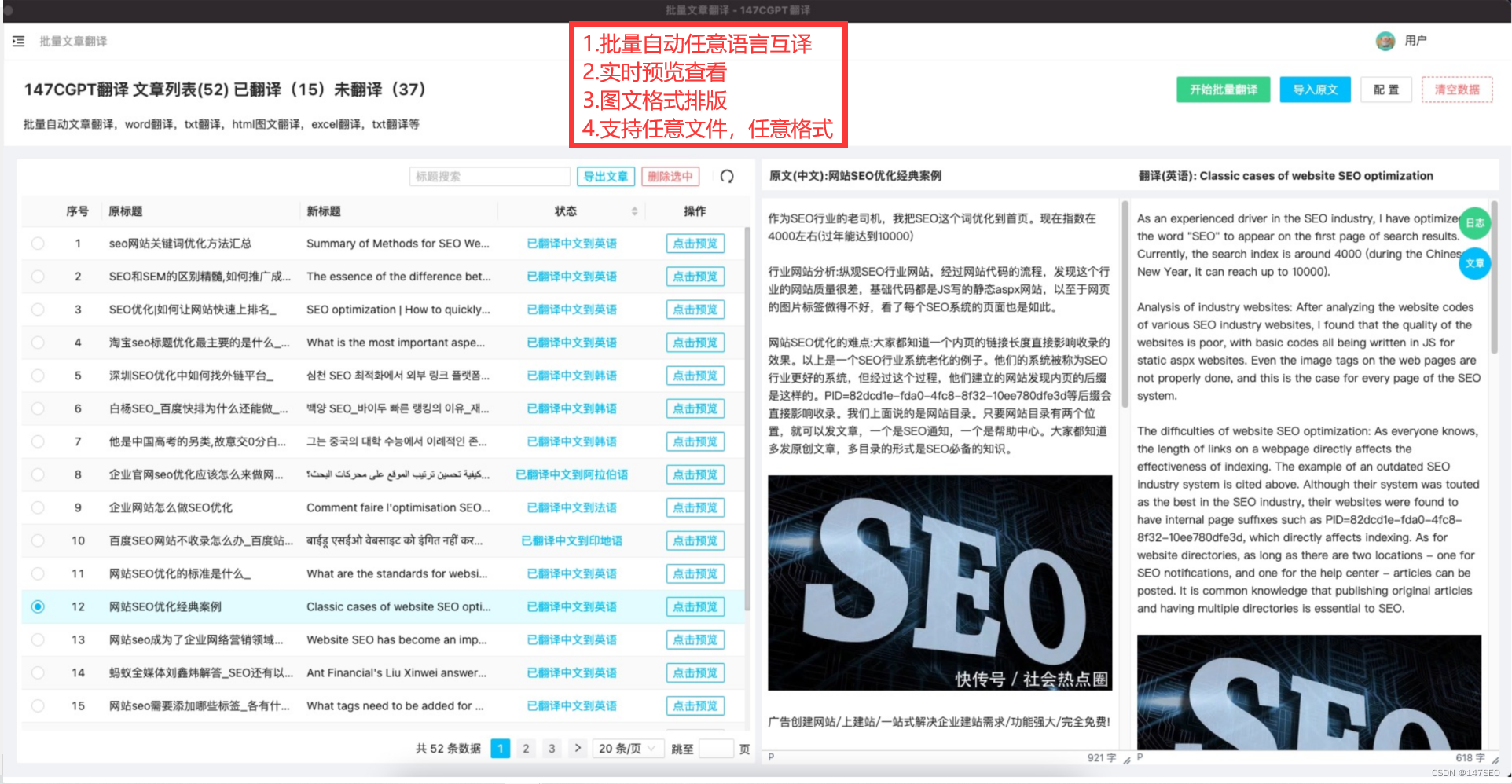
免费ChatGPT接入网站-网站加入CHATGPT自动生成关键词文章排名
网站怎么接入chatGPT 要将ChatGPT集成到您的网站中,需要进行以下步骤: 注册一个OpenAI账户:访问OpenAI网站并创建一个账户。这将提供访问API密钥所需的身份验证凭据。 获取API密钥:在您的OpenAI控制台中,您可以找到您…...

PostgreSQL的数据类型有哪些?
数据类型分类 分类名称说明与其他数据库的对比布尔类型PG支持SQL标准的boolean数据类型与MySQL中的bool、boolean类型相同,占用1字节存储空间数值类型整数类型有2字节的smallint、4字节的int、8字节的bigint;精确类型的小数有numeric;非精确…...

算法和数学模型转换在FPGA中实现问题
1.关于指数运算在FPGA中实现问题 比如,高斯函数,在FPGA直接实现指数函数会极大的消耗资源,并且延迟比较大; 这种一般的使用办法,就是使用LUT查找表来替换; 或者使用分段线性逼近法则; 或者使用泰…...

百考通AI智能聚类文献,告别碎片化罗列
撰写文献综述,是学术写作中承上启下的关键一步。它不仅要展示你对研究领域的了解程度,更要体现你的归纳能力、批判思维和问题意识。然而,现实中许多学生却因资料庞杂、逻辑混乱或时间不足,难以写出一篇真正“有据、有理、有深度”…...

深耕财税赋能+精准GEO推广 好账本兰宝玺双线发力助企破局
在数字经济飞速发展的当下,财税服务的专业性与营销推广的精准度,成为中小微企业稳健成长的两大核心支撑。深耕苏州、昆山财税领域八年的98后实干者兰宝玺,依托好账本财税平台的坚实后盾,不仅以精细化财税服务为创业者保驾护航&…...

避坑指南:注册个体户时,经营范围怎么选才不影响以后开票和接项目?
技术创业者必读:个体户经营范围选择的战略与实操指南 在数字经济蓬勃发展的今天,越来越多的技术从业者选择以个体户形式开启创业之路。作为企业合法经营的"身份证",营业执照中经营范围的填写看似简单,实则暗藏玄机。一个…...

C# 环境:深入解析与应用
C# 环境:深入解析与应用 引言 C#(读作“C Sharp”)是一种由微软开发的高级编程语言,广泛应用于Windows平台的应用程序开发。自从2002年推出以来,C#已经成为了全球开发者喜爱的编程语言之一。本文将深入解析C#环境,包括其特点、应用场景以及开发环境搭建等。 C#环境概述…...

中控SCADA的VBS脚本玩不转了?试试用Python来“降维打击”,搞定复杂数据处理与模型调用
中控SCADA的VBS脚本玩不转了?试试用Python来“降维打击”,搞定复杂数据处理与模型调用 在工业自动化领域,中控SCADA系统长期扮演着数据采集与监控的核心角色。然而,当项目需求从简单的数据记录升级到需要复杂分析、预测性维护或实…...

GitHub下载速度提升10倍:Fast-GitHub终极解决方案
GitHub下载速度提升10倍:Fast-GitHub终极解决方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 还在为GitHub的龟速下…...

SuperRDP完整指南:一键解锁Windows远程桌面多用户并发连接限制
SuperRDP完整指南:一键解锁Windows远程桌面多用户并发连接限制 【免费下载链接】SuperRDP Super RDPWrap 项目地址: https://gitcode.com/gh_mirrors/su/SuperRDP SuperRDP是基于RDPWrap技术的智能工具,专为突破Windows系统远程桌面功能限制而设计…...
)
仅限内部团队使用的Perplexity行业扫描协议(附可复用Prompt模板库+信源可信度评分表v2.3)
更多请点击: https://codechina.net 第一章:Perplexity行业扫描协议的定位与适用边界 Perplexity行业扫描协议(Perplexity Industry Scanning Protocol,简称PISP)并非通用型AI评估框架,而是一套面向垂直领…...

百考通:AI赋能期刊论文写作,智能生成优质内容
在学术研究领域,期刊论文的撰写是成果输出的关键环节,却也让众多科研工作者与学生倍感压力:选题迷茫、逻辑梳理困难、格式规范复杂、内容提炼耗时,严重拖慢了学术成果的发表节奏。百考通(https://www.baikaotongai.com…...